Ultralytics 代码库深度解读【五】:数据预处理与增强Pipeline
1. 前言
从整个计算机视觉任务的流程分类来说,本篇属于训练部分,准确说是训练的前置工作。
正文开始之前,有2点需要说明:
- 本帖所讲的代码库亚博智能的jetson orin super开发套件的时候附赠的代码库,并非官方标准版,但因其Ultralytics官方代码相差不大,对官方代码的学习仍然具有参考价值。
- 本帖以常见的YOLO V8模型训练为例,其他模型训练同理。
在计算机视觉任务中,数据预处理与增强是提升模型性能的关键环节。Ultralytics YOLO框架提供了强大而灵活的数据预处理与增强Pipeline,显著提高模型的泛化能力和鲁棒性。本文将深入解析Ultralytics中的数据预处理与增强机制,包括其整体架构设计、核心增强技术实现、标准化流程以及自定义扩展方法。
假设我们需要训练一个YOLO V8的网络。
1.如果我们需要使用预训练的模型,可以使用这样的命令:
yolo train model=yolov8n.pt data=coco8.yaml epochs=100 batch=16 imgsz=640
2.如果我们不需要使用预训练的模型,可以使用这样的命令:
yolo train model=yolov8n.yaml data=coco8.yaml epochs=200 batch=16 imgsz=640 pretrained=False
时,整个软件的执行过程如下:
- 命令行入口:操作系统执行
/bin/yolo脚本 - 模块导入:脚本导入
ultralytics.cfg:entrypoint函数 - 参数解析:entrypoint函数解析命令行参数,得到
overrides = {'mode': 'train', 'model': 'yolov8n.pt', 'data': 'coco8.yaml', 'epochs': 100, 'batch': 16, 'imgsz': 640} - 模型创建:根据参数创建
YOLO实例 - 训练启动:调用
model.train()方法 - 训练器初始化:创建
DetectionTrainer实例 - 数据集构建:调用
build_yolo_dataset函数创建数据集 - 变换流水线构建:数据集的
build_transforms方法调用v8_transforms构建预处理与增强Pipeline - 数据加载器创建:通过
get_dataloader方法创建数据加载器 - 训练循环:在训练循环中,每个
batch的数据都会经过预处理与增强Pipeline处理
整个过程的函数调用关系如下: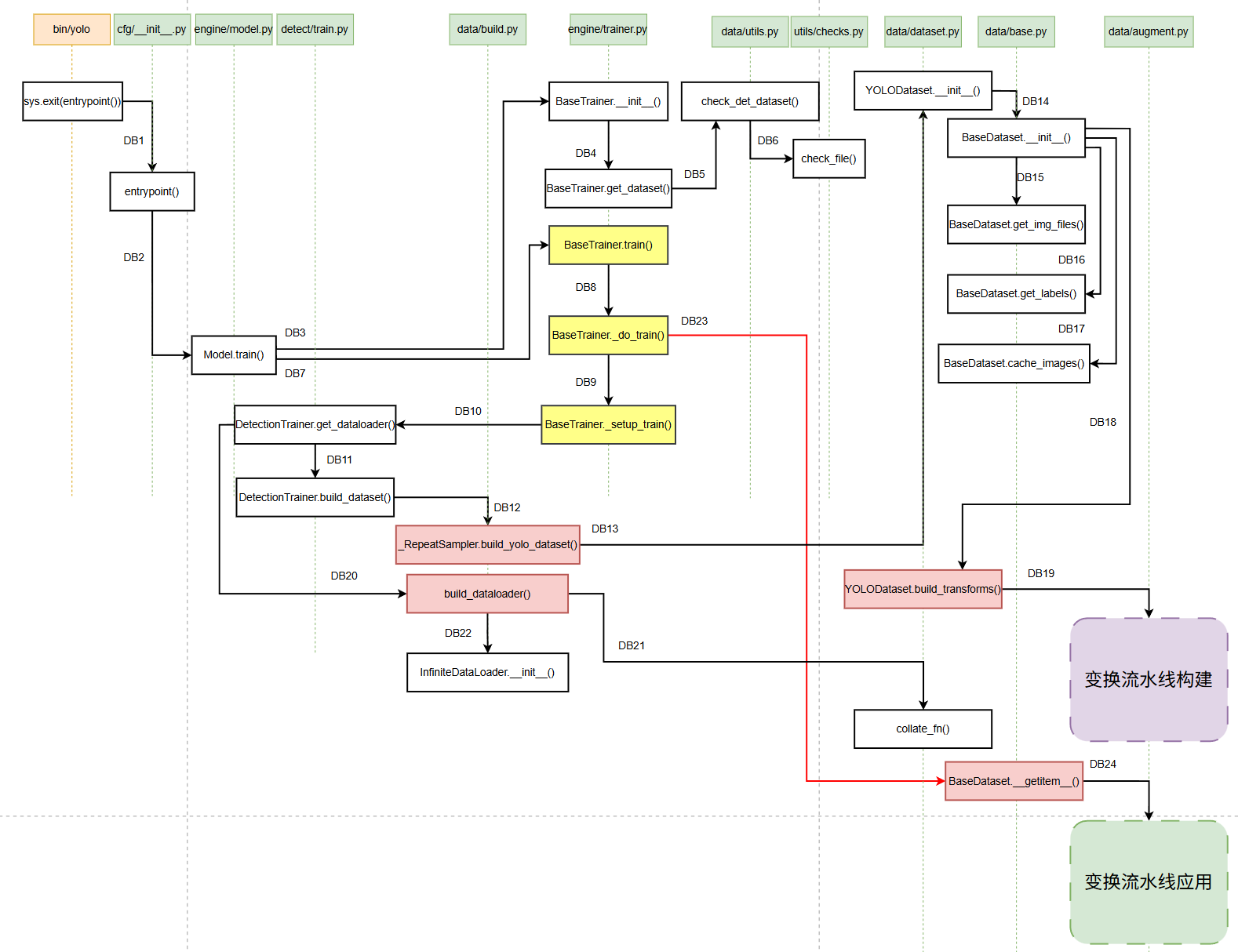
变换流水线的构建与应用这部分是重点,并且也稍微复杂一些,就单独画了函数的调用关系图:
2. Pipeline整体架构设计
2.1 Pipeline整体架构与工作流程
- Compose类:用于组合多个变换操作,形成完整的处理流水线。
- BaseMixTransform类:混合变换的基类,为Mosaic和MixUp等混合增强技术提供统一接口。
- 各类具体增强类:如Mosaic、MixUp、RandomHSV、RandomFlip等,实现具体的增强算法。
整个Pipeline的工作流程如下:
- 数据集初始化时根据配置构建变换流水线
- 在训练过程中,每个batch的数据都会经过预定义的变换序列处,变换操作既包括单图增强(如颜色调整、翻转),也包括多图混合(如Mosaic、MixUp)
训练阶段与验证阶段的Pipeline是不一样的:
-
训练阶段 Pipeline:以“提升泛化性”为核心,由“基础预处理 + 随机增强”组成。基础预处理确保数据格式合规,随机增强则通过多样化变换生成新样本,典型流程为:读取原始图片 → 随机增强(Mosaic/MixUp/翻转等)→ 标准化(归一化、格式转换)→ 输出模型输入。
-
验证/推理阶段 Pipeline:以“保证结果一致性”为核心,仅包含“基础预处理”,无任何随机操作。目的是让模型在固定条件下输出可复现的结果,典型流程为:读取原始图片 → 尺寸调整(LetterBox 保持比例)→ 标准化 → 输出模型输入。
2.1 Pipeline核心控制类Compose
Compose 类是 Pipeline 的“控制器”,负责接收变换列表,在调用时按顺序执行每个变换,并传递图片、标签等数据。其核心逻辑如下:
class Compose:
"""组合多个数据变换操作,按顺序执行并传递额外参数"""
def __init__(self, transforms: List[Transform]):
self.transforms = transforms # 变换操作列表
def __call__(self, data):
"""执行变换流水线:按顺序调用每个变换,更新图片和标签"""
for t in self.transforms:
# 每个变换都接收图片、标签和额外参数,返回更新后的数据
data = t(data)
return data
通过 Compose,我们可以轻松构建自定义 Pipeline,例如:
# 构建训练用增强流水线
train_transforms = Compose([
Mosaic(), # 马赛克变换
RandomFlip(), # 随机翻转
RandomCrop(), # 随机裁剪
ColorJitter(), # 色域变换
Resize(imgsz=640), # 尺寸调整
Normalize() # 归一化
])
# 构建验证用预处理流水线(无增强)
val_transforms = Compose([
Resize(imgsz=640),
Normalize()
])
在源代码中,构建了这样的Pipeline:
return Compose(
[
pre_transform,
MixUp(dataset, pre_transform=pre_transform, p=hyp.mixup),
Albumentations(p=1.0),
RandomHSV(hgain=hyp.hsv_h, sgain=hyp.hsv_s, vgain=hyp.hsv_v),
RandomFlip(direction="vertical", p=hyp.flipud),
RandomFlip(direction="horizontal", p=hyp.fliplr, flip_idx=flip_idx),
]
) # transforms
其中的预变换是马赛克变换和仿射变换的组合。
pre_transform = Compose([mosaic, affine])
所以本文也是基于这几类变换徐徐展开的。
3. 关键变换方法深度解析
YOLO 的增强策略围绕“几何变换”和“像素变换”两大类设计,几何变换(如马赛克、翻转)改变目标位置和形态,像素变换(如色域调整)改变像素值分布,二者结合实现全方位的数据扩充。以下从核心变换入手,详细解析其实现逻辑与作用。
3.1 预处理一:Mosaic(马赛克)变换
Mosaic增强是Ultralytics中最具特色的增强技术之一,它将4张或9张图像拼接成一张大图,使模型在训练时同时学习多个目标的特征,尤其能提升小目标检测性能。其核心优势在于:① 无需额外增加数据集规模,即可扩充场景多样性;② 拼接处的目标截断能增强模型对目标局部特征的识别能力。
3.1.1 BaseMixTransform预处理
首先是在构建变换流水线的时候,调用Mosaic.__init()__方法,在该方法中定义了一些相关的属性。
class Mosaic(BaseMixTransform):
def __init__(self, dataset, imgsz=640, p=1.0, n=4):
assert 0 <= p <= 1.0, f"The probability should be in range [0, 1], but got {p}."
assert n in {4, 9}, "grid must be equal to 4 or 9."
super().__init__(dataset=dataset, p=p)
self.imgsz = imgsz
self.border = (-imgsz // 2, -imgsz // 2) # width, height
self.n = n
- 🍭
dataset数据集对象。 - 🍭
imgszMosaic增强后输出图像的尺寸 - 🍭
P图片被用来马赛克增强的概率,默认为100% - 🍭
n决定Mosaic拼接的图像数量和布局,只能是4(2x2网格)或9(3x3网格)
其次是在训练正式开始后,每次迭代,都要更新神经网络的输入图像,这个时候按道理会调用Mosaic.__call()__方法,但Mosaic并没有__call()__这个时候就会调用父类BaseMixTransform的__call()__方法,我们看看这个方法的实现:
def __call__(self, labels):
if random.uniform(0, 1) > self.p:
return labels
# Get index of one or three other images
indexes = self.get_indexes()
if isinstance(indexes, int):
indexes = [indexes]
# Get images information will be used for Mosaic or MixUp
mix_labels = [self.dataset.get_image_and_label(i) for i in indexes]
if self.pre_transform is not None:
for i, data in enumerate(mix_labels):
mix_labels[i] = self.pre_transform(data)
labels["mix_labels"] = mix_labels
# Update cls and texts
labels = self._update_label_text(labels)
# Mosaic or MixUp
labels = self._mix_transform(labels)
labels.pop("mix_labels", None)
return labels
BaseMixTransform.__call__() 方法是混合增强变换的核心执行逻辑,采用了模板方法的设计模式。
🚩1. 概率控制
if random.uniform(0, 1) > self.p:
return labels
简洁明了,生成一个随机数,如果大于我们设定的概率,就不对其进行处理。
🚩2. 获取其他图像索引
indexes = self.get_indexes()
if isinstance(indexes, int):
indexes = [indexes]
🚩3. 获取其他图像数据
mix_labels = [self.dataset.get_image_and_label(i) for i in indexes]
🚩4. 应用预变换
if self.pre_transform is not None:
for i, data in enumerate(mix_labels):
mix_labels[i] = self.pre_transform(data)
labels["mix_labels"] = mix_labels
检查是否存在预变换self.pre_transform,如果存在,则对每个mix_labels中的数据应用预变换,将处理后的mix_labels添加到主标签中。
🚩5. 更新标签文本
# Update cls and texts
labels = self._update_label_text(labels)
🚩6. 执行混合变换(核心)
labels = self._mix_transform(labels)
🚩7. 清理临时数据
labels.pop("mix_labels", None)
return labels
第6步中调用了self._mix_transform(labels)方法,然而这个方法在BaseMixTransform类中并未实现,所以会跳到子类Mosaic的_mix_transform()方法中。我们看看这个方法:
def _mix_transform(self, labels):
assert labels.get("rect_shape", None) is None, "rect and mosaic are mutually exclusive."
assert len(labels.get("mix_labels", [])), "There are no other images for mosaic augment."
return (
self._mosaic3(labels) if self.n == 3 else self._mosaic4(labels) if self.n == 4 else self._mosaic9(labels)
) # This code is modified for mosaic3 method.
先检查传入的标签信息是否合法,如果合法,就根据Mosaic拼接的图像数量和布局分配到相关的变换方法中对图像进行处理。参数n默认为4,所以我们下面小节我们详细看看_mosaic4()这个方法是如何进行处理的。
3.1.2 核心逻辑详解
马赛克变换的核心步骤为:
① 随机选择 3 张辅助图片;
② 确定拼接中心点和各图片的拼接区域;
③ 按区域拼接图片并融合标签;
④ 处理拼接处的像素过渡(可选)。
具体代码如下:
def _mosaic4(self, labels):
mosaic_labels = []
s = self.imgsz
yc, xc = (int(random.uniform(-x, 2 * s + x)) for x in self.border) # mosaic center x, y
for i in range(4):
labels_patch = labels if i == 0 else labels["mix_labels"][i - 1]
# Load image
img = labels_patch["img"]
h, w = labels_patch.pop("resized_shape")
# Place img in img4
if i == 0: # top left
img4 = np.full((s * 2, s * 2, img.shape[2]), 114, dtype=np.uint8) # base image with 4 tiles
x1a, y1a, x2a, y2a = max(xc - w, 0), max(yc - h, 0), xc, yc # xmin, ymin, xmax, ymax (large image)
x1b, y1b, x2b, y2b = w - (x2a - x1a), h - (y2a - y1a), w, h # xmin, ymin, xmax, ymax (small image)
elif i == 1: # top right
x1a, y1a, x2a, y2a = xc, max(yc - h, 0), min(xc + w, s * 2), yc
x1b, y1b, x2b, y2b = 0, h - (y2a - y1a), min(w, x2a - x1a), h
elif i == 2: # bottom left
x1a, y1a, x2a, y2a = max(xc - w, 0), yc, xc, min(s * 2, yc + h)
x1b, y1b, x2b, y2b = w - (x2a - x1a), 0, w, min(y2a - y1a, h)
elif i == 3: # bottom right
x1a, y1a, x2a, y2a = xc, yc, min(xc + w, s * 2), min(s * 2, yc + h)
x1b, y1b, x2b, y2b = 0, 0, min(w, x2a - x1a), min(y2a - y1a, h)
img4[y1a:y2a, x1a:x2a] = img[y1b:y2b, x1b:x2b] # img4[ymin:ymax, xmin:xmax]
padw = x1a - x1b
padh = y1a - y1b
labels_patch = self._update_labels(labels_patch, padw, padh)
mosaic_labels.append(labels_patch)
final_labels = self._cat_labels(mosaic_labels)
final_labels["img"] = img4
return final_labels
随机选取一个中心点,横纵坐标都是(-x, 2 * s + x)之间的随机数,其中x=-320, s=640,即(320, 960)这个区间。
yc, xc = (int(random.uniform(-x, 2 * s + x)) for x in self.border) # mosaic center x, y
📕经过后面的计算可以知道,这里的中心点指的并不是最终拼接而成的图片的几何坐标中心,而是这4张图片的交汇点。
然后通过循环加载图片和相关标签信息。并进行拼接,在第一次循环的时候,需要创建一个画布(1280*1280):
if i == 0: # top left
img4 = np.full((s * 2, s * 2, img.shape[2]), 114, dtype=np.uint8) # base image with 4 tiles

🐾每次计算中的large image坐标,指的是裁剪下来的图片在最终图片上的坐标区域。
🐾每次计算中的small image坐标,指的是需要裁剪的区域在原图中的坐标范围。
我们通过一个例子来说明整个拼接过程:
我们假设中心点的坐标为(340,400),h和w也各为640,那么通过迭代,计算的各个坐标具体如下:
🎲第一次迭代:
x1a = 0, y1a = 0, x2a = 340, y2a = 400
x1b = 300, y1b = 240, x2b = 640, y2b = 640
🎲第二次迭代:
x1a = 340, y1a = 0, x2a = 980, y2a = 400
x1b = 0, y1b = 240, x2b = 640 ,y2b = 640
🎲第三次迭代:
x1a = 0, y1a = 400, x2a = 340, y2a = 1040
x1b = 300, y1b = 0, x2b = 640, y2b = 640
🎲第四次迭代:
x1a = 340, y1a = 400, x2a = 980, y2a = 1040
x1b = 0, y1b = 0, x2b = 640, y2b = 640
整个裁剪✂️,拼接🌍的过程如下:
📐选取中心点
📐放置左上角图片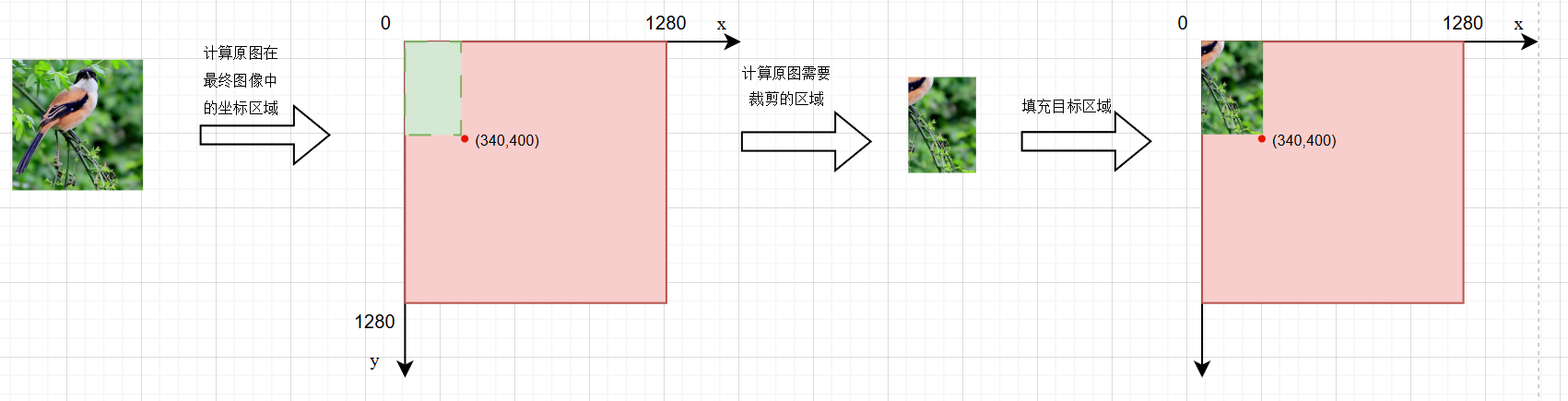
📐放置右上角图片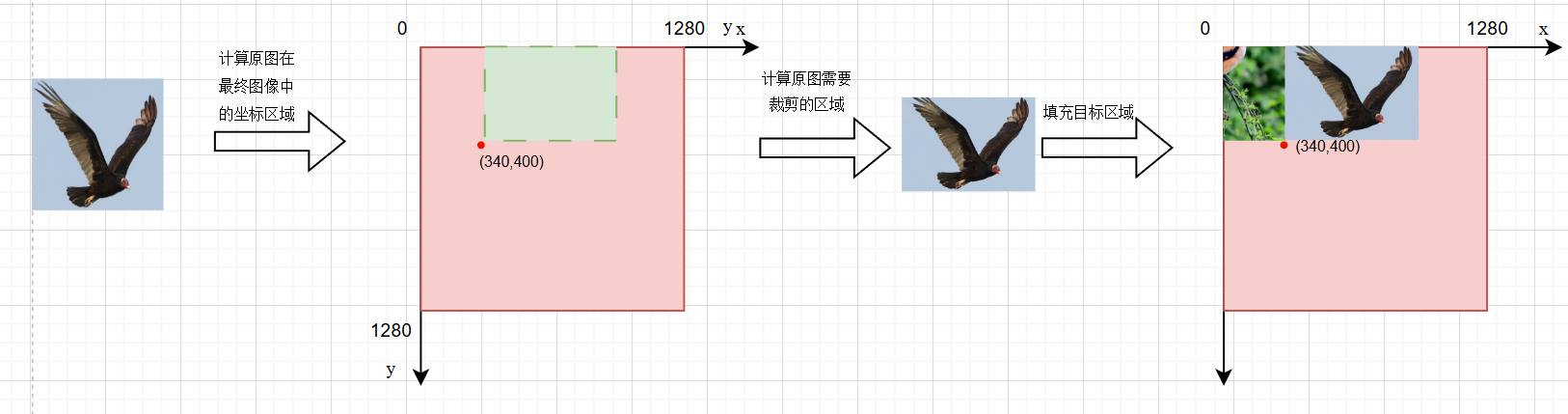
📐放置左下角图片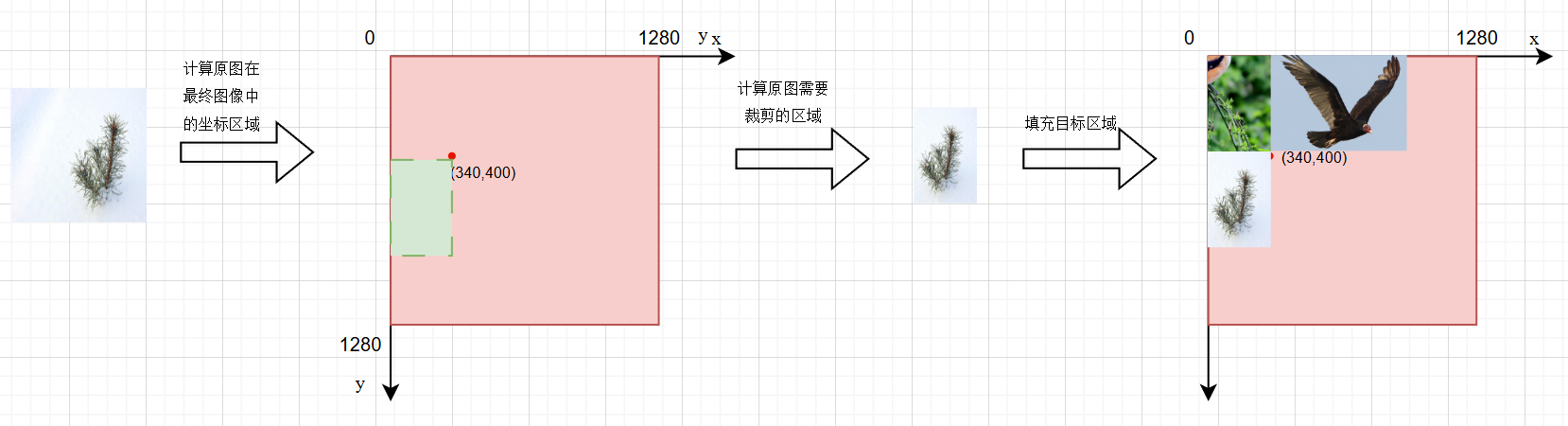
📐放置右下角图片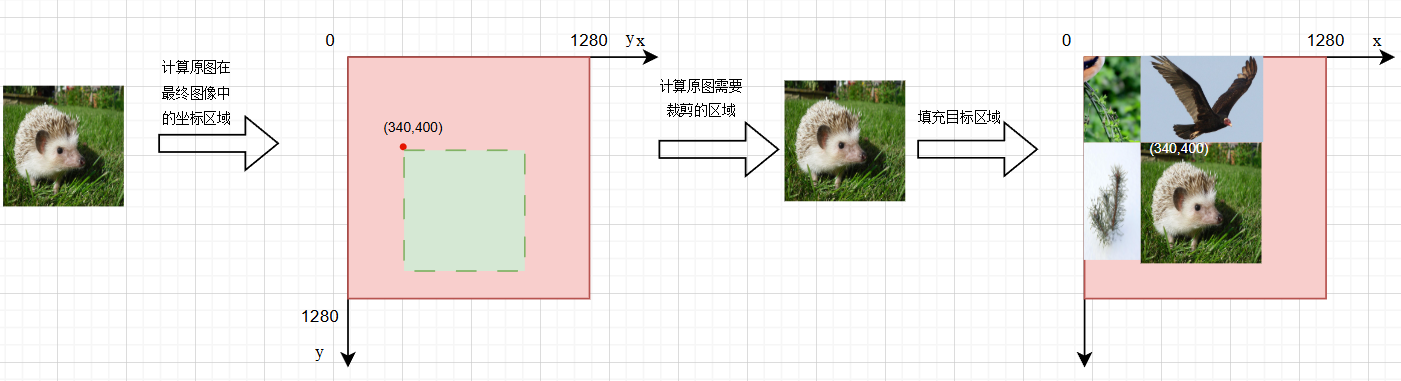
注:没有填充的粉红色区域无需再填充,创建画布的时候已经默认填充了,实际上是灰色,粉红色只是为了辨认。
从上述的马赛克图片拼接过程中会发现一个神奇的现象,就是如果原图需要裁剪,一般都是裁剪图片的↖️左上部分,而保留右下部分。至于为什么选择裁剪左上部分,目前没有比较合理的解释。
3.1.3 关键细节与优化
-
拼接区域控制:通过mosaic_border 限制中心点范围,避免某张图片占比过小(如小于 1/4),确保4张图片的特征都能被模型学习;
-
标签坐标转换:核心是“尺度缩放+位置偏移”,需严格同步图片的缩放比例和放置位置,避免标签与目标错位;
-
无效标签过滤:裁剪后过滤超出画布的标签,防止无效标签影响模型训练;
-
画布初始化:使用灰度值 114 填充画布(接近自然图像的平均像素值),减少拼接处的像素突变对模型的干扰。
3.2 预处理二:随机视角RandomPerspective
RandomPerspective是一种强大的数据增强技术,通过对图像进行随机的透视和仿射变换来增加数据多样性。
3.2.1 核心参数
def __init__(
self, degrees=0.0, translate=0.1, scale=0.5, shear=0.0, perspective=0.0, border=(0, 0), pre_transform=None
):
self.degrees = degrees
self.translate = translate
self.scale = scale
self.shear = shear
self.perspective = perspective
self.border = border # mosaic border
self.pre_transform = pre_transform
- 🍭
degrees: 随机旋转角度范围(度) - 🍭
translate: 平移比例(相对于图像尺寸) - 🍭
scale: 缩放因子范围 - 🍭
shear: 剪切角度(度) - 🍭
perspective: 透视变形因子 - 🍭
border: 边界尺寸
3.2.2 核心逻辑详解
与Mosaic处理方法不同,RandomPerspective 有自己的__call__方法,包含了整个核心的处理流程。
def __call__(self, labels):
if self.pre_transform and "mosaic_border" not in labels:
labels = self.pre_transform(labels)
labels.pop("ratio_pad", None) # do not need ratio pad
img = labels["img"]
cls = labels["cls"]
instances = labels.pop("instances")
# Make sure the coord formats are right
instances.convert_bbox(format="xyxy")
instances.denormalize(*img.shape[:2][::-1])
border = labels.pop("mosaic_border", self.border)
self.size = img.shape[1] + border[1] * 2, img.shape[0] + border[0] * 2 # w, h
# M is affine matrix
# Scale for func:`box_candidates`
img, M, scale = self.affine_transform(img, border)
bboxes = self.apply_bboxes(instances.bboxes, M)
segments = instances.segments
keypoints = instances.keypoints
# Update bboxes if there are segments.
if len(segments):
bboxes, segments = self.apply_segments(segments, M)
if keypoints is not None:
keypoints = self.apply_keypoints(keypoints, M)
new_instances = Instances(bboxes, segments, keypoints, bbox_format="xyxy", normalized=False)
# Clip
new_instances.clip(*self.size)
# Filter instances
instances.scale(scale_w=scale, scale_h=scale, bbox_only=True)
# Make the bboxes have the same scale with new_bboxes
i = self.box_candidates(
box1=instances.bboxes.T, box2=new_instances.bboxes.T, area_thr=0.01 if len(segments) else 0.10
)
labels["instances"] = new_instances[i]
labels["cls"] = cls[i]
labels["img"] = img
labels["resized_shape"] = img.shape[:2]
return labels
📐条件检查
if self.pre_transform and "mosaic_border" not in labels:
labels = self.pre_transform(labels)
labels.pop("ratio_pad", None) # do not need ratio pad
条件检查:只有在没有mosaic_border且存在预变换时才应用预变换
预变换应用:可能包括LetterBox等预处理步骤
清理数据:移除ratio_pad字段
📐提取更多信息
img = labels["img"]
cls = labels["cls"]
instances = labels.pop("instances")
# Make sure the coord formats are right
instances.convert_bbox(format="xyxy")
instances.denormalize(*img.shape[:2][::-1])
border = labels.pop("mosaic_border", self.border)
self.size = img.shape[1] + border[1] * 2, img.shape[0] + border[0] * 2 # w, h
图像数据:提取输入图像img
类别信息:提取类别标签cls
实例对象:弹出并处理实例对象(边界框)
坐标格式化:确保边界框格式为xyxy并反归一化
尺寸计算:计算变换后的图像尺寸
🌈我们看看坐标转换是如何实现的:
def convert(self, format):
"""Converts bounding box format from one type to another."""
assert format in _formats, f"Invalid bounding box format: {format}, format must be one of {_formats}"
if self.format == format:
return
elif self.format == "xyxy":
func = xyxy2xywh if format == "xywh" else xyxy2ltwh
elif self.format == "xywh":
func = xywh2xyxy if format == "xyxy" else xywh2ltwh
else:
func = ltwh2xyxy if format == "xyxy" else ltwh2xywh
self.bboxes = func(self.bboxes)
self.format = format
先调用了这个函数,我们需要的目标格式是xyxy,也就是用两个点来表示bounding box,所以如果bounding box表示方法不统一,需要统一一下,假设是不统一的,所以我们调用了xywh2xyxy()函数来进行处理。
这里直接将函数名称赋值给func,这种语法在C或者C++中就是函数指针,因为无法提前预知需要调用哪个函数,这样表示会比较方便,先选定函数,再在后面进行调用。
接着看看xywh2xyxy()函数的定义
def xywh2xyxy(x):
assert x.shape[-1] == 4, f"input shape last dimension expected 4 but input shape is {x.shape}"
y = empty_like(x) # faster than clone/copy
xy = x[..., :2] # centers
wh = x[..., 2:] / 2 # half width-height
y[..., :2] = xy - wh # top left xy
y[..., 2:] = xy + wh # bottom right xy
return y
首先定义了一个与x同维度的张量y,x就是表示边界框的list,然后取出原来的中心点坐标切片(list),作为新的xy坐标(list)。然后再将原来的sh都➗️2,这样便可以直接用来就计算左上角和右下角的两个点了。
🌈我们看看坐标反归一化是如何实现的:
instances.denormalize(*img.shape[:2][::-1])
这个传入参数的含义是先取连两个参数,反转,然后在解包。
比方说一个图像的尺寸表示是(480, 640, 3),那么取前2个元素,就是(480, 640),反转变成(640,480),然后解包变成数据,也就是说,相当于函数中传入了:
instances.denormalize(640,480)
数组索引约定: NumPy中 [行, 列] 对应 [高度, 宽度],这个很容易理解,行数越多,像素累积高度越高,所以横向表示的是高度,纵向反而是宽度。
由于边界框的表示有可能是归一化的格式,所以需要利用尺寸数据将边界框反归一化。
def denormalize(self, w, h):
"""Denormalizes boxes, segments, and keypoints from normalized coordinates."""
if not self.normalized:
return
self._bboxes.mul(scale=(w, h, w, h))
self.segments[..., 0] *= w
self.segments[..., 1] *= h
if self.keypoints is not None:
self.keypoints[..., 0] *= w
self.keypoints[..., 1] *= h
self.normalized = False
与目标检测相关的,其实只有self._bboxes,所以其他部分不用看。这个就很简单了:
def mul(self, scale):
if isinstance(scale, Number):
scale = to_4tuple(scale)
assert isinstance(scale, (tuple, list))
assert len(scale) == 4
self.bboxes[:, 0] *= scale[0]
self.bboxes[:, 1] *= scale[1]
self.bboxes[:, 2] *= scale[2]
self.bboxes[:, 3] *= scale[3]
直接用归一化后的坐标分别*整个图片的尺寸大小,即可完成反归一化,也就是具体的像素坐标。
📐应用仿射变换
# M is affine matrix
# Scale for func:`box_candidates`
img, M, scale = self.affine_transform(img, border)
调用核心变换affine_transform方法执行仿射变换img:变换后的图像M:3x3仿射变换矩阵scale:缩放因子
affine_transform是RandomPerspective类的核心,负责生成和应用仿射变换矩阵。
def affine_transform(self, img, border):
# Center
C = np.eye(3, dtype=np.float32)
C[0, 2] = -img.shape[1] / 2 # x translation (pixels)
C[1, 2] = -img.shape[0] / 2 # y translation (pixels)
# Perspective
P = np.eye(3, dtype=np.float32)
P[2, 0] = random.uniform(-self.perspective, self.perspective) # x perspective (about y)
P[2, 1] = random.uniform(-self.perspective, self.perspective) # y perspective (about x)
# Rotation and Scale
R = np.eye(3, dtype=np.float32)
a = random.uniform(-self.degrees, self.degrees)
# a += random.choice([-180, -90, 0, 90]) # add 90deg rotations to small rotations
s = random.uniform(1 - self.scale, 1 + self.scale)
# s = 2 ** random.uniform(-scale, scale)
R[:2] = cv2.getRotationMatrix2D(angle=a, center=(0, 0), scale=s)
# Shear
S = np.eye(3, dtype=np.float32)
S[0, 1] = math.tan(random.uniform(-self.shear, self.shear) * math.pi / 180) # x shear (deg)
S[1, 0] = math.tan(random.uniform(-self.shear, self.shear) * math.pi / 180) # y shear (deg)
# Translation
T = np.eye(3, dtype=np.float32)
T[0, 2] = random.uniform(0.5 - self.translate, 0.5 + self.translate) * self.size[0] # x translation (pixels)
T[1, 2] = random.uniform(0.5 - self.translate, 0.5 + self.translate) * self.size[1] # y translation (pixels)
# Combined rotation matrix
M = T @ S @ R @ P @ C # order of operations (right to left) is IMPORTANT
# Affine image
if (border[0] != 0) or (border[1] != 0) or (M != np.eye(3)).any(): # image changed
if self.perspective:
img = cv2.warpPerspective(img, M, dsize=self.size, borderValue=(114, 114, 114))
else: # affine
img = cv2.warpAffine(img, M[:2], dsize=self.size, borderValue=(114, 114, 114))
return img, M, s
🚩1. 中心化变换
# Center
C = np.eye(3, dtype=np.float32)
C[0, 2] = -img.shape[1] / 2 # x translation (pixels)
C[1, 2] = -img.shape[0] / 2 # y translation (pixels)
创建3x3单位矩阵
设置平移变换,将图像中心移到原点
img.shape[1]是宽度,img.shape[0]是高度
🚩2. 透视变换
# Perspective
P = np.eye(3, dtype=np.float32)
P[2, 0] = random.uniform(-self.perspective, self.perspective) # x perspective (about y)
P[2, 1] = random.uniform(-self.perspective, self.perspective) # y perspective (about x)
创建透视变换矩阵
随机生成透视参数
用于模拟近大远小的效果
透视变换由一个矩阵来描述
P = [[1, 0, 0],
[0, 1, 0],
[px, py, 1]]
其中px和py是控制透视效果的参数:
- px: 控制水平方向的透视效果
- py: 控制垂直方向的透视效果
当px为正值时,图像右侧会被拉近,左侧被推远
当px为负值时,图像左侧会被拉近,右侧被推远
当py为正值时,图像下侧会被拉近,上侧被推远
当py为负值时,图像上侧会被拉近,下侧被推远
🚩3. 旋转变换和缩放
# Rotation and Scale
R = np.eye(3, dtype=np.float32)
a = random.uniform(-self.degrees, self.degrees)
s = random.uniform(1 - self.scale, 1 + self.scale)
R[:2] = cv2.getRotationMatrix2D(angle=a, center=(0, 0), scale=s)
生成随机旋转角度和缩放因子
使用OpenCV的getRotationMatrix2D生成2D旋转缩放矩阵
将2x3矩阵填充到3x3矩阵的前两行
🚩4. 剪切变换
# Translation
# Shear
S = np.eye(3, dtype=np.float32)
S[0, 1] = math.tan(random.uniform(-self.shear, self.shear) * math.pi / 180) # x shear (deg)
S[1, 0] = math.tan(random.uniform(-self.shear, self.shear) * math.pi / 180) # y shear (deg)
生成随机剪切角度
转换为弧度并计算正切值
设置剪切变换参数
剪切变换也使用3x3的矩阵:
S = [[1, tan(θx), 0],
[tan(θy), 1, 0],
[0, 0, 1]]
其中:
θx: 水平剪切角度
θy: 垂直剪切角度
tan(θ): 角度的正切值
水平剪切 (tan(θx)): 图像沿水平方向倾斜,上下边缘保持水平,但左右边缘变成斜线
垂直剪切 (tan(θy)): 图像沿垂直方向倾斜,左右边缘保持垂直,但上下边缘变成斜线
当两个方向都有剪切时,图像会产生平行四边形的效果
🚩
5. 平移变换
# Translation
T = np.eye(3, dtype=np.float32)
T[0, 2] = random.uniform(0.5 - self.translate, 0.5 + self.translate) * self.size[0] # x translation (pixels)
T[1, 2] = random.uniform(0.5 - self.translate, 0.5 + self.translate) * self.size[1] # y translation (pixels)
生成随机平移参数
基于图像尺寸计算实际平移像素值
🚩6. 组合变换矩阵
# Combined rotation matrix
M = T @ S @ R @ P @ C # order of operations (right to left) is IMPORTANT
按照特定顺序组合所有变换矩阵
顺序很重要:从右到左应用变换
变换顺序:中心化 → 透视 → 旋转缩放 → 剪切 → 平移
变换顺序非常重要,因为矩阵乘法不满足交换律。
🚩7. 应用变换
# Affine image
if (border[0] != 0) or (border[1] != 0) or (M != np.eye(3)).any(): # image changed
if self.perspective:
img = cv2.warpPerspective(img, M, dsize=self.size, borderValue=(114, 114, 114))
else: # affine
img = cv2.warpAffine(img, M[:2], dsize=self.size, borderValue=(114, 114, 114))
return img, M, s
检查是否需要应用变换,然后根据是否有透视变换选择不同的OpenCV函数,执行完变换后,返回变换后的图像、变换矩阵和缩放因子。
🔴为方便理解各种变换所产生的效果,看一组示例图片。

分别是原图,旋转变换,缩放变换,透视变换,平移变换,剪切变换。
最后是2个综合变换的例子。
📐标签变换
既然图像都执行了仿射变换,那么原图所对应的bounding box坐标肯定也要跟着变,所以这部分就是边界框的变换。
bboxes = self.apply_bboxes(instances.bboxes, M)
segments = instances.segments
keypoints = instances.keypoints
# Update bboxes if there are segments.
if len(segments):
bboxes, segments = self.apply_segments(segments, M)
if keypoints is not None:
keypoints = self.apply_keypoints(keypoints, M)
new_instances = Instances(bboxes, segments, keypoints, bbox_format="xyxy", normalized=False)
# Clip
new_instances.clip(*self.size)
- 🐾边界框变换:使用
apply_bboxes方法变换边界框 - 🐾
分割掩码处理:如果有分割数据,使用(目标检测中不涉及)apply_segments方法处理 - 🐾
关键点处理:如果有关键点数据,使用(目标检测中不涉及)apply_keypoints方法处理 - 🐾实例重建:创建新的Instances对象
- 🐾边界裁剪:确保所有标注都在图像边界内
其他的部分都很容易理解,重点看看这个边界框是怎么跟着变的。
def apply_bboxes(self, bboxes, M):
n = len(bboxes)
if n == 0:
return bboxes
xy = np.ones((n * 4, 3), dtype=bboxes.dtype)
xy[:, :2] = bboxes[:, [0, 1, 2, 3, 0, 3, 2, 1]].reshape(n * 4, 2) # x1y1, x2y2, x1y2, x2y1
xy = xy @ M.T # transform
xy = (xy[:, :2] / xy[:, 2:3] if self.perspective else xy[:, :2]).reshape(n, 8) # perspective rescale or affine
# Create new boxes
x = xy[:, [0, 2, 4, 6]]
y = xy[:, [1, 3, 5, 7]]
return np.concatenate((x.min(1), y.min(1), x.max(1), y.max(1)), dtype=bboxes.dtype).reshape(4, n).T
📐后处理和过滤
# Filter instances
instances.scale(scale_w=scale, scale_h=scale, bbox_only=True)
# Make the bboxes have the same scale with new_bboxes
i = self.box_candidates(
box1=instances.bboxes.T, box2=new_instances.bboxes.T, area_thr=0.01 if len(segments) else 0.10
)
labels["instances"] = new_instances[i]
labels["cls"] = cls[i]
labels["img"] = img
labels["resized_shape"] = img.shape[:2]
return labels
- 🐾原始实例缩放:按变换比例缩放原始边界框
- 🐾候选框过滤:使用box_candidates方法过滤不合适的边界框
- 🐾数据更新:更新标签字典中的各项数据
- 🐾返回结果:返回变换后的标签
3.3 MixUp增强
MixUp通过对两张图像及其标签进行加权混合,生成新的训练样本,有助于提高模型的泛化能力。同Mosaic(马赛克)变换一样,MixUp类也是没有__call_()方法,在训练中每次加载数据,并利用MixUp方法进行变换的时候,调用的是BaseMixTransform中的__call_()方法,然后再通过接口调用,来实现MixUp增强,具体是通过MixUp._mix_transform()接口来实现的。
def _mix_transform(self, labels):
r = np.random.beta(32.0, 32.0) # mixup ratio, alpha=beta=32.0
labels2 = labels["mix_labels"][0]
labels["img"] = (labels["img"] * r + labels2["img"] * (1 - r)).astype(np.uint8)
labels["instances"] = Instances.concatenate([labels["instances"], labels2["instances"]], axis=0)
labels["cls"] = np.concatenate([labels["cls"], labels2["cls"]], 0)
return labels
r = np.random.beta(32.0, 32.0) # mixup ratio, alpha=beta=32.0
使用Beta(32, 32)分布生成混合比例
Alpha和Beta参数均为32,生成的r值通常接近0.5
这意味着两张图像的贡献大致相等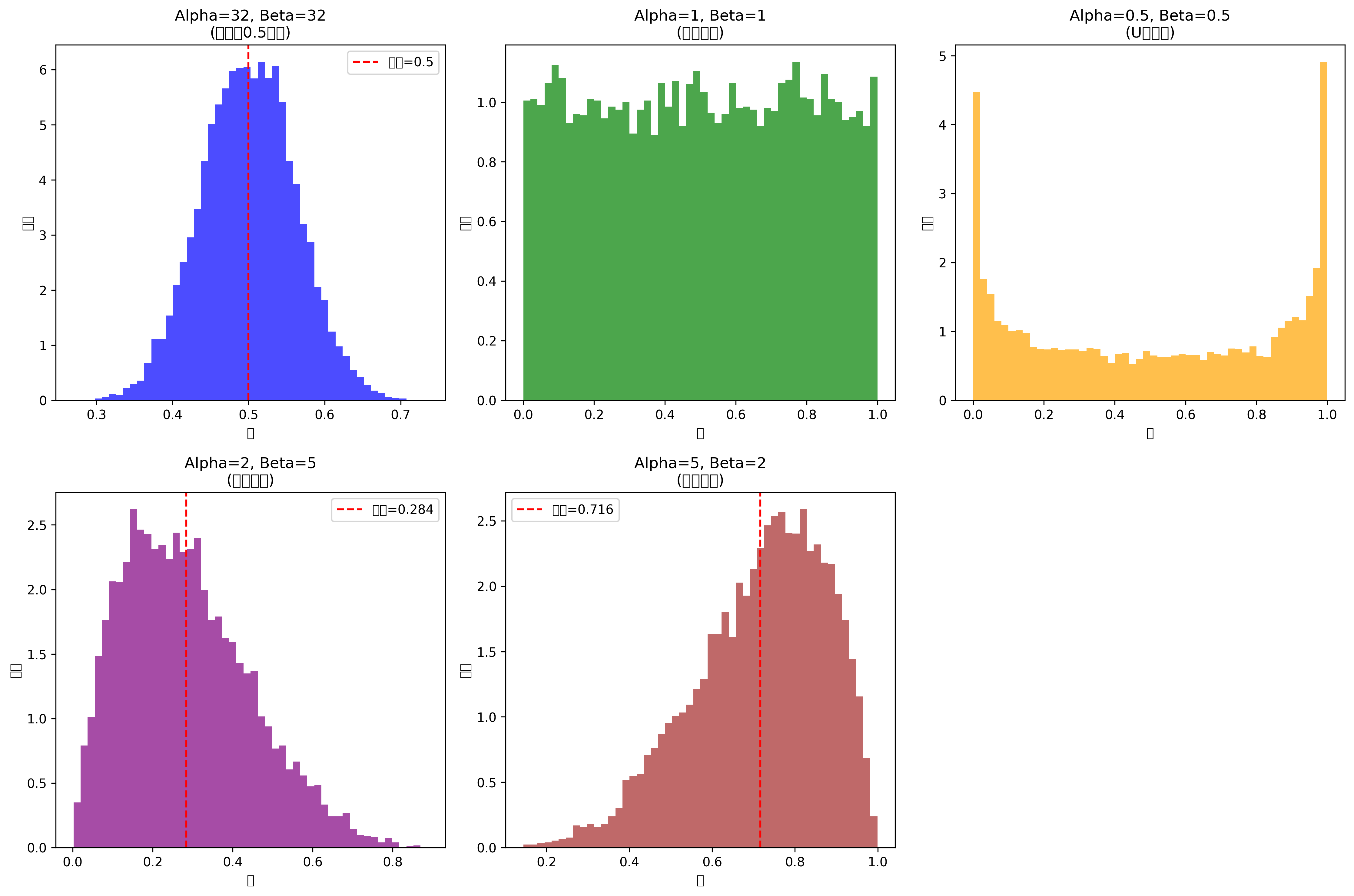
r是一个随机数,该值服从Beta分布,Beta分布是一个定义在区间0,1上的连续概率分布,有两个形状参数:α(alpha)和β(beta),当两个参数相等且都较大时(如α=β=32),Beta分布具有以下特性:
🎯对称性:分布关于0.5对称
🎯集中性:大部分概率质量集中在0.5附近
🎯尖峰性:在0.5处达到峰值
很明显此时的Beta分布有点类似于正态分布,那为什么为什么不用最为常用的正态分布呢?
主要是因为此时定义域严格限定在[0,1]区间,生成的r值天然满足 0 ≤ r ≤ 1。如果是正态分布,则需要做截断处理。
labels["img"] = (labels["img"] * r + labels2["img"] * (1 - r)).astype(np.uint8)
这是MixUp的核心操作:
第一张图像乘以比例r
第二张图像乘以比例(1-r)
两者相加得到混合图像
转换为uint8类型确保像素值在0-255范围内
labels["instances"] = Instances.concatenate([labels["instances"], labels2["instances"]], axis=0)
labels["cls"] = np.concatenate([labels["cls"], labels2["cls"]], 0)
保留两张图像的所有边界框
保留两张图像的所有类别标签
变换示例:
3.4 Albumentations
Albumentations 是一款基于OpenCV开发的高效、灵活、轻量级计算机视觉数据增强库,专为深度学习训练优化(支持分类、检测、分割、关键点检测等全场景任务)。其核心目标是通过对训练数据进行多样化的自动变换,扩充数据分布、提升模型泛化能力,同时兼顾速度与易用性,已成为 PyTorch、TensorFlow 等框架的主流数据增强工具(尤其在目标检测、语义分割等复杂任务中应用广泛)。
def __call__(self, labels):
if self.transform is None or random.random() > self.p:
return labels
if self.contains_spatial:
cls = labels["cls"]
if len(cls):
im = labels["img"]
labels["instances"].convert_bbox("xywh")
labels["instances"].normalize(*im.shape[:2][::-1])
bboxes = labels["instances"].bboxes
# TODO: add supports of segments and keypoints
new = self.transform(image=im, bboxes=bboxes, class_labels=cls) # transformed
if len(new["class_labels"]) > 0: # skip update if no bbox in new im
labels["img"] = new["image"]
labels["cls"] = np.array(new["class_labels"])
bboxes = np.array(new["bboxes"], dtype=np.float32)
labels["instances"].update(bboxes=bboxes)
else:
labels["img"] = self.transform(image=labels["img"])["image"] # transformed
return labels
这部分软件很有意思😆,首先判断是否需要进行空间转换:
- 🎲如果需要,则需要对图像和边界框一起做变换。
- 🎲如果不需要,则只对图像做变换。
那么self.contains_spatial变量的值由什么确定呢?在__init__()中能找到答案。
self.contains_spatial = any(transform.__class__.__name__ in spatial_transforms for transform in T)
先迭代T中的元素,如果T的类元素在spatial_transforms中也包含了,那么就存在空间转换,否则不存在。
我们看看这个T中都有啥:
# Transforms
T = [
A.Blur(p=0.01),
A.MedianBlur(p=0.01),
A.ToGray(p=0.01),
A.CLAHE(p=0.01),
A.RandomBrightnessContrast(p=0.0),
A.RandomGamma(p=0.0),
A.ImageCompression(quality_lower=75, p=0.0),
]
Blur: 模糊处理,概率0.01MedianBlur: 中值模糊,概率0.01ToGray: 转换为灰度图,概率0.01CLAHE: 对比度受限自适应直方图均衡化,概率0.01RandomBrightnessContrast: 随机亮度对比度调整,概率0.0(默认禁用)RandomGamma: 随机伽马变换,概率0.0(默认禁用)ImageCompression: 图像压缩,概率0.0(默认禁用)
基本上全都和色彩有关,不存在什么空间转换。所以直接进入else分支。
else:
labels["img"] = self.transform(image=labels["img"])["image"] # transformed
也就直接进入到了最核心的变换,我们看看这个变换器是怎么构建的:
self.transform = (
A.Compose(T, bbox_params=A.BboxParams(format="yolo", label_fields=["class_labels"]))
if self.contains_spatial
else A.Compose(T)
)
刚刚已经讨论过了,不存在空间变换,所以这个变换器就退化成了:
self.transform = (A.Compose(T))
A就是albumentations图像处理专用库,在__init__()中导入了该库:
def __init__(self, p=1.0):
self.p = p
self.transform = None
prefix = colorstr("albumentations: ")
try:
import albumentations as A
3.5 随机HSV(RandomHSV)变换
与RGB一样,HSV颜色空间也是图像颜色的一种表示形式。那么为什么在这里不用最为常见的RGB进行颜色变换,而是要用HSV呢?
- Hue(色相)颜色的 “本质”(如红、绿、蓝、黄),对应色轮上的角度。
- Saturation(饱和度)颜色的 “纯度”(鲜艳程度),0 为灰度(无颜色),1 为纯色。
- Value(明度)颜色的 “亮度”(明暗程度),0 为黑色,1 为对应色相的最亮状态。
从HSV的定义就可以看出,随机HSV(RandomHSV)变换能更好地模拟不同气象条件,或者不同光照条件下事物所呈现的视觉效果。
- 🎯光照强度变化(如逆光、阴影、晴天 / 阴天):不会改变物体的颜色类别(比如红色汽车在阴影下还是红色,只是变暗);
- 🎯颜色鲜艳度变化(如雾霾天、相机曝光偏差):比如雾霾天物体颜色更暗淡(S 降低),不会让红色变成绿色;
- 🎯轻微色相偏移(如不同光源色温:白炽灯偏黄、荧光灯偏蓝):对应微调Hue(色相)(通常只调整 ±5°~±10°),模拟光源颜色的轻微差异,而非改变物体本身的颜色。
def __call__(self, labels):
img = labels["img"]
if self.hgain or self.sgain or self.vgain:
r = np.random.uniform(-1, 1, 3) * [self.hgain, self.sgain, self.vgain] + 1 # random gains
hue, sat, val = cv2.split(cv2.cvtColor(img, cv2.COLOR_BGR2HSV))
dtype = img.dtype # uint8
x = np.arange(0, 256, dtype=r.dtype)
lut_hue = ((x * r[0]) % 180).astype(dtype)
lut_sat = np.clip(x * r[1], 0, 255).astype(dtype)
lut_val = np.clip(x * r[2], 0, 255).astype(dtype)
im_hsv = cv2.merge((cv2.LUT(hue, lut_hue), cv2.LUT(sat, lut_sat), cv2.LUT(val, lut_val)))
cv2.cvtColor(im_hsv, cv2.COLOR_HSV2BGR, dst=img) # no return needed
return labels
📐变换条件过滤
HSV三个参数的值都不能为0
if self.hgain or self.sgain or self.vgain:
📐生成增益变换因子
r = np.random.uniform(-1, 1, 3) * [self.hgain, self.sgain, self.vgain] + 1 # random gains
生成了3个[-1,1]之间的随机数,然后再乘以原来的系数。
📐颜色空间转换
hue, sat, val = cv2.split(cv2.cvtColor(img, cv2.COLOR_BGR2HSV))
R G B → H S V RGB→HSV RGB→HSV
📐生成查找表
x = np.arange(0, 256, dtype=r.dtype)
lut_hue = ((x * r[0]) % 180).astype(dtype)
lut_sat = np.clip(x * r[1], 0, 255).astype(dtype)
lut_val = np.clip(x * r[2], 0, 255).astype(dtype)
先创建0-255的数组[0, 1, 2, …, 255],再生成查找表
例如:
如果r[0]=0.97,则lut_hue[100] = (100 *0.97)%180 = 97
如果r[1]=1.35,则lut_sat[100] = clip(100 *1.35, 0, 255) = clip(135, 0, 255) = 135
如果r[2]=0.96,则lut_val[100] = clip(100 *0.96, 0, 255) = clip(96, 0, 255) = 96
n p . c l i p ( x ∗ r [ 1 ] , 0 , 255 ) . a s t y p e ( d t y p e ) np.clip(x * r[1], 0, 255).astype(dtype) np.clip(x∗r[1],0,255).astype(dtype)
这种运算,将x的值限制在[0,255]区间内,然后再将其转换为int8类型的数值。
📐应用变换
im_hsv = cv2.merge((cv2.LUT(hue, lut_hue), cv2.LUT(sat, lut_sat), cv2.LUT(val, lut_val)))
使用查找表进行快速变换,变换后再将各个通道合并。
3.6 随机翻转(RandomFlip)变换
随机翻转分为水平翻转和垂直翻转两类,从软件中可以很明显看到,此次两种我们都用到了。
return Compose(
[
pre_transform,
MixUp(dataset, pre_transform=pre_transform, p=hyp.mixup),
Albumentations(p=1.0),
RandomHSV(hgain=hyp.hsv_h, sgain=hyp.hsv_s, vgain=hyp.hsv_v),
RandomFlip(direction="vertical", p=hyp.flipud),
RandomFlip(direction="horizontal", p=hyp.fliplr, flip_idx=flip_idx),
]
) # transforms
随机翻转变换也是由RandomFlip类自己的__call__()方法来实现的。
def __call__(self, labels):
img = labels["img"]
instances = labels.pop("instances")
instances.convert_bbox(format="xywh")
h, w = img.shape[:2]
h = 1 if instances.normalized else h
w = 1 if instances.normalized else w
# Flip up-down
if self.direction == "vertical" and random.random() < self.p:
img = np.flipud(img)
instances.flipud(h)
if self.direction == "horizontal" and random.random() < self.p:
img = np.fliplr(img)
instances.fliplr(w)
# For keypoints
if self.flip_idx is not None and instances.keypoints is not None:
instances.keypoints = np.ascontiguousarray(instances.keypoints[:, self.flip_idx, :])
labels["img"] = np.ascontiguousarray(img)
labels["instances"] = instances
return labels
📐 1.前置工作
img = labels["img"]
instances = labels.pop("instances")
instances.convert_bbox(format="xywh")
h, w = img.shape[:2]
h = 1 if instances.normalized else h
w = 1 if instances.normalized else w
从标签中取出图片,然后进行bounding box坐标格式的变换,这个变换在前文中有提及,原理几乎几乎是一样的,只不过是反变换,将用两个点表示的边界框格式换成了中心点的横纵坐标和宽高。
def xyxy2xywh(x):
assert x.shape[-1] == 4, f"input shape last dimension expected 4 but input shape is {x.shape}"
y = empty_like(x) # faster than clone/copy
y[..., 0] = (x[..., 0] + x[..., 2]) / 2 # x center
y[..., 1] = (x[..., 1] + x[..., 3]) / 2 # y center
y[..., 2] = x[..., 2] - x[..., 0] # width
y[..., 3] = x[..., 3] - x[..., 1] # height
return y
📐 2. 执行翻转
# Flip up-down
if self.direction == "vertical" and random.random() < self.p:
img = np.flipud(img)
instances.flipud(h)
if self.direction == "horizontal" and random.random() < self.p:
img = np.fliplr(img)
instances.fliplr(w)
# For keypoints
if self.flip_idx is not None and instances.keypoints is not None:
instances.keypoints = np.ascontiguousarray(instances.keypoints[:, self.flip_idx, :])
判断需要翻转的类型,如果需要垂直翻转就执行垂直翻转,如果需要执行水平翻转就执行垂直翻转,keypoints不需要管,大概率是和关键点检测有关系。
先看看上下翻转是如何实现的:
如果是图像的翻转,直接调用NumPy的库函数实现翻转:
img = np.flipud(img)
如果是边界框的翻转,就需要自己写函数实现:
def flipud(self, h):
if self._bboxes.format == "xyxy":
y1 = self.bboxes[:, 1].copy()
y2 = self.bboxes[:, 3].copy()
self.bboxes[:, 1] = h - y2
self.bboxes[:, 3] = h - y1
else:
self.bboxes[:, 1] = h - self.bboxes[:, 1]
self.segments[..., 1] = h - self.segments[..., 1]
if self.keypoints is not None:
self.keypoints[..., 1] = h - self.keypoints[..., 1]
刚刚已经进行了坐标变换,所以当前bounding box的坐标格式并不是“xyxy”,而是“xywh”,所以执行else分支的语句:
self.bboxes[:, 1] = h - self.bboxes[:, 1]
这个切片表示,对所有边界框中心点的纵坐标执行相同操作
y n e w = h − y y_{new}=h-y ynew=h−y
再来看看左右翻转是如何实现的:
和上下翻转几乎一模一样,图像的翻转直接调用库函数,边界框自己手写函数实现:
def fliplr(self, w):
if self._bboxes.format == "xyxy":
x1 = self.bboxes[:, 0].copy()
x2 = self.bboxes[:, 2].copy()
self.bboxes[:, 0] = w - x2
self.bboxes[:, 2] = w - x1
else:
self.bboxes[:, 0] = w - self.bboxes[:, 0]
self.segments[..., 0] = w - self.segments[..., 0]
if self.keypoints is not None:
self.keypoints[..., 0] = w - self.keypoints[..., 0]
同样,对所有边界框中心点的横坐标执行相同操作
x n e w = w − x x_{new}=w-x xnew=w−x
📐 3. 更新标签,返回变换结果
labels["img"] = np.ascontiguousarray(img)
labels["instances"] = instances
return labels
这样,图像翻转变换就完成了。
4. 自定义方法扩展
Ultralytics提供了良好的扩展机制,允许开发者轻松添加自定义增强方法,假设我们自己定义了一个变换方法,命名为CustomTransform类。
class CustomTransform(BaseTransform):
def __init__(self, param1=0.5, param2=0.5):
super().__init__()
self.param1 = param1
self.param2 = param2
def __call__(self, labels):
# 实现自定义变换逻辑
img = labels["img"]
# 应用变换
labels["img"] = transformed_img
return labels
然后采用insert()方法,就可以将我们的变换直接集成到原本的Pipeline中,轻松实现定制化流水线。
transforms.insert(0, CustomTransform())
5. 总结
本篇围绕 Ultralytics 中数据预处理与增强的核心链路展开了完整解析:先是从 Pipeline 的整体架构与核心控制类 Compose 入手,理清了这一环节的工作流程;随后逐一拆解了 Mosaic 变换、RandomPerspective、MixUp 等关键增强手段的核心逻辑、参数细节与优化思路,同时也覆盖了 Albumentations 集成、HSV 变换、随机翻转等常用预处理方法,最后还补充了自定义方法扩展的实现方向。通过对这些环节的深度拆解,我们得以摸清 Ultralytics 中数据预处理与增强的底层逻辑 。
而预处理后的数如何高效流转到训练流程?下一篇Ultralytics 代码库深度解读【六】:数据加载机制深度解析将聚焦数据加载的底层链路,继续拆解其高效加载的实现逻辑,欢迎持续关注❤️❤️❤️

魔乐社区(Modelers.cn) 是一个中立、公益的人工智能社区,提供人工智能工具、模型、数据的托管、展示与应用协同服务,为人工智能开发及爱好者搭建开放的学习交流平台。社区通过理事会方式运作,由全产业链共同建设、共同运营、共同享有,推动国产AI生态繁荣发展。
更多推荐


 9
9 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)