VLA数据集格式:HDF5数据格式以及向Lerobot数据格式的转换
我们在自采数据对VLA模型进行微调时候,难免会遇到数据集格式的问题。主流的VLA模型,使用的训练数据集格式不同,HDF5、RDLS、Lerobot这些数据集格式都有什么区别,他们之间该如何转换呢?最近在数据采集和转换方面遇到一些有关数据集格式的问题,通过数据采集拿到的HDF5格式的数据,想要查看并且向其他数据集格式进行转换,以便训练主流的VLA模型。
我们在自采数据对VLA模型进行微调时候,难免会遇到数据集格式的问题。主流的VLA模型,使用的训练数据集格式不同,HDF5、RDLS、Lerobot这些数据集格式都有什么区别,他们之间该如何转换呢?
最近在数据采集和转换方面遇到一些有关数据集格式的问题,通过数据采集拿到的HDF5格式的数据,想要查看并且向其他数据集格式进行转换,以便训练主流的VLA模型。
安装HDFViewer(Ubuntu20.04 LTS)
首先我们从官网 HDFView 3.3.2 | The HDF Group Support Site 进入GitHub上并找到HDFViewer v3.3.2 Release v3.3.2 · HDFGroup/hdfview 下载对应的版本
 解压并安装
解压并安装
tar -zxvf HDFView-3.3.2-Linux-x86_64.tar.gz
sudo dpkg -i hdfview_3.3.2_amd64.deb安装之后发现无法从图标打开,发现3.3.2不适合ubuntu 20,后续直接sudo apt install hdfview就可以了
随机打开一个.hdf5文件我们就可以对其进行可视化了
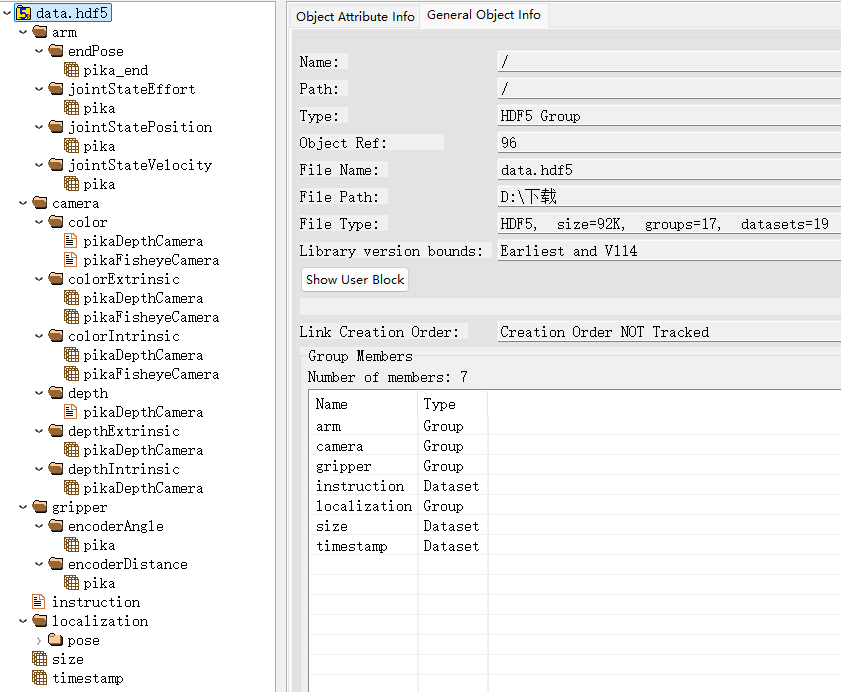
HDF5文件结构
特点
HDF5是一种用于存储大量数据的文件格式,具有以下特点:
- 层次结构:支持复杂的数据组织方式,类似于文件系统的目录结构。
- 可扩展性:能够存储任意大小的数据集。
- 跨平台:支持多种操作系统和编程语言。
- 高效性:优化了数据的读写性能。
结构
HDF5 文件可以被视为一个容器,其内部结构类似于文件系统,包含两种主要对象:
- 数据集 (Dataset):本质上是多维数组,用于存储实际的数据,例如图像像素、传感器读数等。
- 组 (Group):用于组织文件中的对象,可以包含其他组或数据集,形成一个层次化的结构,类似于文件系统中的文件夹。
典型结构示例
root
├── images/
│ ├── rgb[0..N]
│ └── depth[0..N]
├── actions/
│ └── action[0..N]
├── states/
│ ├── joint_pos[0..N]
│ └── joint_vel[0..N]
└── metadata/
└── camera_intrinsics
侧重点
HDF5 的侧重点在于其高性能、可扩展性和通用性。
- 高性能 I/O: 支持并行 I/O 操作,能够高效地读写大规模数据集,这对于动辄 TB 级的 VLA 数据集至关重要。它还支持数据切片(slicing),允许程序只读取所需的数据子集到内存中,而不是一次性加载整个庞大的文件。
- 可扩展性: 单个 HDF5 文件的大小理论上只受文件系统的限制,能够轻松存储海量数据。
- 通用性: 作为一种跨平台、多语言支持的标准格式,HDF5 在不同系统和编程环境(Python, C++, Java 等)中都有着良好的兼容性。
在 VLA 领域,HDF5 常被用于存储那些规模巨大、结构相对固定的离线数据集。由于其成熟和稳定,多用于仿真数据预处理。
HDF5格式向lerobot数据集格式的转换
Lerobot数据集格式
Lerobot数据集格式随着Lerobot框架的提出成为众多VLA模型的标准训练数据集格式之一。Lerobot 的诞生正是为了解决机器人学习领域数据集格式不统一、模型难以复现、社区贡献门槛高等痛点。
Lerobot数据集结构
Lerobot 的数据格式建立在业界标准之上,通常是以 Parquet 文件为核心,并结合 Zarr 等云原生格式,整体被封装在一个易于访问和操作的目录结构中。
- 数据集目录结构: 一个 Lerobot 数据集通常是一个文件夹,其中包含了多个 Parquet 文件(用于存储表格化的数据,如动作、奖励等)、一个
info.json文件(包含数据集的元数据,如特征描述、统计信息等)和一个dataset_info.json文件(描述数据集的配置和版本)。 - 分片与流式处理: 数据通常被分割成多个小的 Parquet 文件(shards)。这种设计天然支持流式处理(streaming)。与 HDF5 需要一次性下载整个大文件不同,Lerobot 可以边下载边处理数据,极大地降低了本地存储的需求和数据加载的启动时间,非常适合在云端或资源受限的环境中进行训练。
- 与 Hugging Face
datasets库深度集成: Lerobot 数据集可以被datasets库直接加载和处理,用户可以利用map,filter,shuffle等丰富的 API 对数据进行高效的预处理。
dataset_name/
├── train/
│ ├── episode_000001/
│ │ ├── frames/
│ │ │ ├── 000000.png
│ │ │ ├── 000001.png
│ │ │ └── ...
│ │ └── data.parquet
│ └── episode_000002/
│ ├── frames/
│ └── data.parquet
│
├── val/
│ └── episode_000101/ ...
│
├── metadata.json
└── stats.json侧重点
Lerobot 的核心侧重点在于易用性、标准化和社区协作。SmolVLA 和 0_fast是当前明确使用 LeRobot 数据格式训练的 VLA 模型。还有其他隶属于 LeRobot 项目并使用相同数据格式训练的模型,如 huggingface 推出的 act_aloha、diffusion_pusht 等。
HDF5数据格式转换到Lerobot数据集格式
在遥操作数据采集工作中我们不免会遇到采集到的数据集格式与想要微调的VLA模型要求的数据集格式不符的问题。anarnuri/hdf5_to_lerobot_converter 此工程可以解决hdf5向lerobot数据集格式的转换问题,Tavish9/any4lerobot: 🎁 A collection of utilities for LeRobot. 此工程解决了不同LeRobot数据集版本之间的转换、LeRobot数据集格式与RLDS数据集格式之间的互相转换以及各种主流数据集(如OXE)转换成LeRobot数据集格式。
尝试将hdf5向lerobot格式进行转换,首先更改envirionment.yml文件中的环境名称hdf5-to-lerobot,修改"lerobot == 0.3.2",然后创建conda环境。
name: hdf5-to-lerobot
channels:
- defaults
dependencies:
- _libgcc_mutex=0.1
conda env create -f environment.yml
conda activate hdf5-to-lerobot按照如下格式编辑config.yaml文件
repo_id: my-username/my-dataset-name
raw_data_dir: /path/to/hdf5/episodes
output_dir: /custom/output/path # optional, default: ~/.cache/huggingface/lerobot/<repo_id>
fps: 30 # optional, frames per second for video encoding
batch_size: 1 # optional, number of episodes per dataset batch修改文件中.hdf5文件的通配部分,使其适配你要转换的文件名
def run_conversion(self):
"""Run conversion with batch size validation"""
episode_files = sorted(
self.raw_data_dir.glob("episode_*.hdf5"),
key=lambda x: int(x.stem.split("_")[1])
)一件转换之后,输出lerobot格式文件位置在
~/.cache/huggingface/lerobot/repo_id这样我们在lerobot框架中本地训练模型的时候可以直接使用此repo_id进行训练。
参考资料
[2] NSMC HDF5使用简介
[3] VLA相关数据格式梳理 - 知乎

魔乐社区(Modelers.cn) 是一个中立、公益的人工智能社区,提供人工智能工具、模型、数据的托管、展示与应用协同服务,为人工智能开发及爱好者搭建开放的学习交流平台。社区通过理事会方式运作,由全产业链共同建设、共同运营、共同享有,推动国产AI生态繁荣发展。
更多推荐


 18
18 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)