应用实战|大模型驱动的智能知识引擎
动态演化:自主更新知识库,减少人工干预因果推理:突破相关性局限,实现深度决策人机协同:自然语言交互 + 可视化分析所以作为一个软件开发者,立即动手构建属于自己的第一个知识引擎刻不容缓,现在就开始动手起来吧。
引言
大模型(LLM)时代的知识引擎革命、技术的突破性进展,正在重塑知识管理与应用的范式。从海量非结构化数据中提炼结构化知识,实现精准检索、推理与决策支持,已成为企业智能化转型的核心竞争力。本文将通过技术解析、代码示例与实战案例,深入探讨如何构建基于大模型的智能知识引擎。
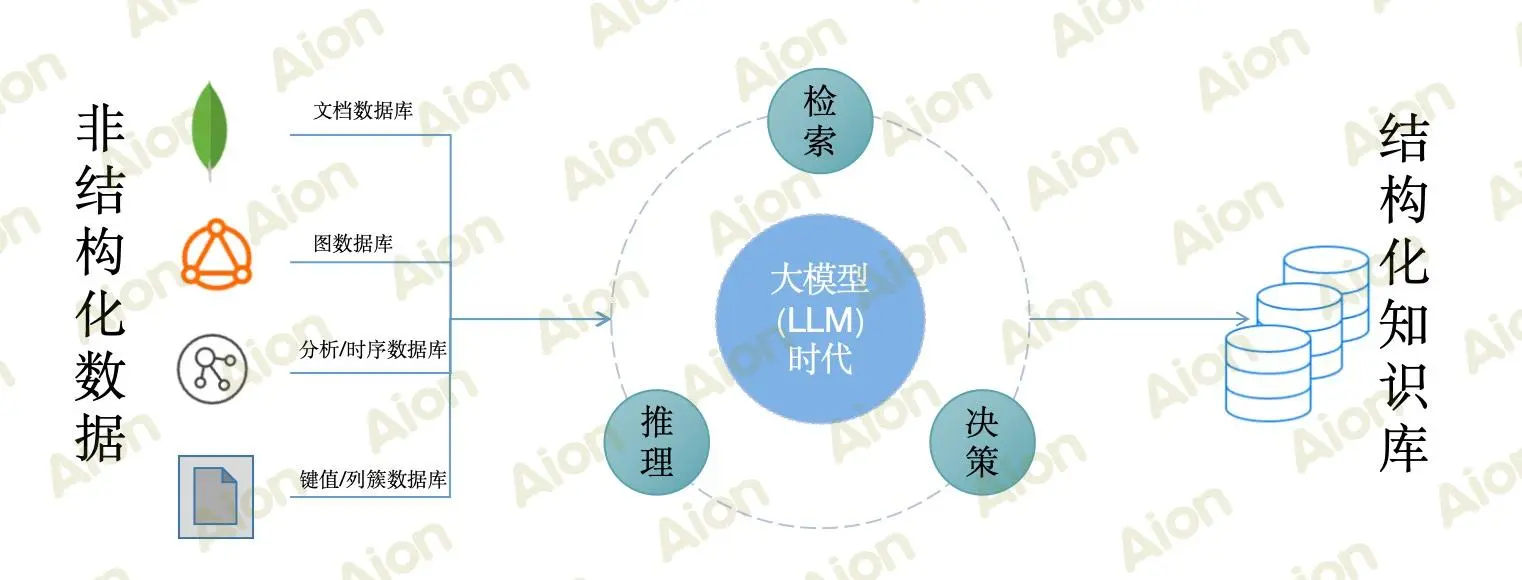
构建前准备
-
运行工具:VSCode 版本: 1.97.2 (Universal)
-
构建语言:Python 3.12
-
环境依赖:Transformers、PyTorch、以及需要的依赖 torch、torchvision、torchaudio、sentencepiece、accelerate等等
知识图谱构建
知识构建的开始是从非结构化数据到语义网络,知识图谱是知识引擎的骨架,大模型可显著提升实体识别与关系抽取效率。
技术方案
-
数据预处理:使用大模型清洗、归一化多源数据(文本、表格、PDF等)。
-
实体关系抽取:通过Prompt工程或微调模型(如Llama-3、Falcon)提取三元组(实体-关系-实体)。
-
知识融合:对齐不同来源的实体,消除歧义(如“小米”指公司还是食物)。
基于大模型的实体抽取
大模型在实体抽取的大体步骤有:选择模型架构 → 加载分词器 → 配置量化/分片策略 → 封装任务逻辑。
代码示例如下:
from transformers import pipeline
# 初始化大模型抽取器
extractor = pipeline("text2text-generation", model="google/flan-t5-xxl")
# 需要抽取的数据源语料
text = "小米成立于2010年,CEO是雷军,主要产品包括XIAOMI SU7和XIAOMI SU7 Ultra。"
prompt = f"从文本中提取实体和关系,输出为JSON格式:{text}"
result = extractor(prompt, max_length=200)
print(result[0]['generated_text'])
# 输出示例:
# {
# "entities": ["小米", "雷军", "Model S", "Cybertruck"],
# "relations": [
# {"head": "小米", "type": "创始人", "tail": "雷军"},
# {"head": "小米", "type": "产品", "tail": "XIAOMI SU7"},
# {"head": "小米", "type": "产品", "tail": "XIAOMI SU7 Ultra"}
# ]
# }利用自然语言处理技术从预处理后的数据中提取实体、关系和属性。这一步骤通常涉及到命名实体识别(NER)、关系抽取和属性抽取等任务。例如,可以使用像spaCy这样的NLP库来识别文本中的实体及其关系。
1 安装spaCy
~ pip3 install -i https://mirrors.aliyun.com/pypi/simple spacy
➜ hub pip3 list | grep spacy
spacy 3.8.4
spacy-legacy 3.0.12
spacy-loggers 1.0.5
spacy_pkuseg 1.0.0
➜ hub2 下载模型
选择中文实体模型,也可以在官网直接测试官方提供的示例,我在Huggingface中下载的是通用模型,下载后本地导入会报错,错误如下:
ERROR: Invalid requirement: 'zh-core-web-md==any': Expected end or semicolon (after name and no valid version specifier)
zh-core-web-md==any然后在Github上直接下载 .whl 文件然后继续安装即可,对比了下两份文件,从Huggingface中下载的无版本号,而在Github上下载有版本号的:zh_core_web_md-3.8.0-py3-none-any.whl 。
Github地址:https://github.com/explosion/spacy-models/releases
执行安装命完成后即可使用
pip3 install ./zh_core_web_md-3.8.0-py3-none-any.whl3 测试结果
最终的测试结果如下(还得找一个实用的模型来得实在~):

注意⚠️:如果在当前环境没有引入Python中安装的transformers,则会提示无法引入依赖。
需要注意的风险
尽管知识图谱(Knowledge Graphs, KGs)在数据整合、信息检索和决策支持等方面提供了巨大的潜力,但在构建和应用过程中也存在一些挑战和潜在的弊病。比如数据质量问题、数据复杂性问题、理解的局限性问题、安全与隐私问题、扩展性问题、适用性问题等等。
垂直领域的知识适配
通用大模型有很多种类和单一用途,独特的大模型需结合领域数据微调,才能满足专业场景需求,例如行业数据需求、特种数据需求。
微调策略
-
数据增强:混合通用语料(如Wikipedia)与行业数据(如医疗文献)。
-
参数高效微调(PEFT):使用LoRA或Adapter技术,降低训练成本。
-
评估指标:准确率、F1值、推理延迟(如医疗QA需高精确度)。
代码示例:LoRA微调流程
from peft import LoraConfig, get_peft_model
from transformers import AutoModelForCausalLM
# 加载基础模型
model = AutoModelForCausalLM.from_pretrained("meta-llama/Meta-Llama-3-8B")
# 添加LoRA适配器,可以根据具体的业务或者需求来设定适配器的参数
lora_config = LoraConfig(
r=8,
lora_alpha=32,
target_modules=["q_proj", "v_proj"],
lora_dropout=0.05
)
# 加载设定参数的模型
model = get_peft_model(model, lora_config)
# 训练代码(简化版)
trainer = Trainer(
model=model,
args=TrainingArguments(per_device_train_batch_size=4, learning_rate=3e-4),
train_dataset=dataset
)
trainer.train()超越文本的知识整合
多模态数据融合在近期一直是一个热门的话题,结合文本、图像、语音等多模态数据,构建全景知识视图。这种全景的知识视图不仅限于传统的书面或数字文本内容,还涵盖了图像、音频、视频、传感器数据等多种模态的数据。其核心目标是通过结合这些不同来源和类型的信息,创建一个更加全面、深入且多维度的知识体系。
架构设计
-
编码器层:
-
文本:BERT、GPT
-
图像:CLIP、ViT
-
表格:TabTransformer
-
融合策略:
-
早期融合:拼接多模态特征
-
晚期融合:交叉注意力机制
跨模态检索
代码示例如下:
import torch
from transformers import CLIPModel, CLIPProcessor
model = CLIPModel.from_pretrained("openai/clip-vit-base-patch32")
processor = CLIPProcessor.from_pretrained("openai/clip-vit-base-patch32")
# 图像与文本联合编码
image = Image.open("product.jpg")
text = ["黑色运动鞋", "蓝色连衣裙"]
inputs = processor(text=text, images=image, return_tensors="pt", padding=True)
outputs = model(**inputs)
# 计算相似度
logits_per_image = outputs.logits_per_image
probs = logits_per_image.softmax(dim=1)
print("匹配概率:", probs)从实验室到生产环境
知识引擎需平衡性能与资源消耗。
关键技术
-
模型压缩:量化(FP16/INT8)、剪枝、蒸馏
-
推理加速:vLLM、TGI(Text Generation Inference)
-
缓存策略:Redis缓存频繁查询结果
vLLM服务化
部署示例
# 启动推理服务
vllm-server --model meta-llama/Meta-Llama-3-8B --quantization awq --gpu-memory-utilization 0.9
# 客户端调用
curl http://localhost:8000/generate \
-d '{"prompt": "心脏病的常见症状有哪些?", "max_tokens": 50}'应用案例
1. 医疗知识引擎
-
应用:在医疗诊断中结合病人的症状描述(文本)、X光片(图像)和心电图(信号数据)来进行更精确的诊断。
-
输入:患者病历、医学影像,等等
-
输出:诊断建议、用药推荐
-
技术栈:
-
知识图谱:SNOMED CT + 本地医院数据
-
模型:微调的Med-PaLM
-
2. 金融风控引擎
-
应用:信用卡消费金额,根据用户的历史消费行为、偏好以及其他个人消费信息,提供高度定制化的服务和产品推荐。
-
输入:财报、新闻、市场数据
-
输出:企业信用评分、风险预警
-
技术栈:
-
多模态融合:文本情感分析 + 时序预测
-
实时计算:Flink流处理
-
未来思考、挑战与解决方案
|
思考 |
挑战 |
解决思路 |
|
有哪些数据需要整合、清洗、转换 |
数据质量参差不齐 |
大模型数据清洗 + 人工校验 |
|
有哪些术语需要统一 |
行业术语理解偏差 |
领域词典注入 + 对比学习 |
|
业务需求、实时性、准确性、及时性 |
实时性要求高 |
增量学习 + 边缘计算部署 |
|
其他业务需求 |
可解释性需求 |
注意力可视化 + 推理路径追踪 |
结语
知识引擎的未来演进道路多且艰辛,随着MoE架构、世界模型等技术的发展,知识引擎将呈现三大趋势:
-
动态演化:自主更新知识库,减少人工干预
-
因果推理:突破相关性局限,实现深度决策
-
人机协同:自然语言交互 + 可视化分析
所以作为一个软件开发者,立即动手构建属于自己的第一个知识引擎刻不容缓,现在就开始动手起来吧。

魔乐社区(Modelers.cn) 是一个中立、公益的人工智能社区,提供人工智能工具、模型、数据的托管、展示与应用协同服务,为人工智能开发及爱好者搭建开放的学习交流平台。社区通过理事会方式运作,由全产业链共同建设、共同运营、共同享有,推动国产AI生态繁荣发展。
更多推荐



 10
10 0
0- 0



 已为社区贡献14条内容
已为社区贡献14条内容

所有评论(0)