51c大模型~合集191
哈萨比斯Jeff Dean联手执笔谷歌2025年度AI综述:Gemini 3 Pro/Flash以推理+多模态刷新多项基准,开源Gemma加码端侧;Agent重塑编码、搜索与创意工具,AlphaFold、DeepThink夺金,量子Echoes与Ironwood TPU夯实硬件,长文描绘可协作、可行动、可科研的通用智能路线图。如何回顾2025年的AI进展?今年王者归来的谷歌,刚刚由Jeff Dea
我自己的原文哦~ https://blog.51cto.com/whaosoft143/14222866
#上下文图谱火了
百万人围观,「上下文图谱」火了,万亿美元新机遇?
当智能体(Agent)开始深度介入人类世界,关于豆包 AI 手机的讨论可能只是个开始。
在此之前,手机、电脑软件都是给人用的 —— 人负责一步步操作,系统负责把信息存好、算好。但现在,Agent 开始接过这些操作:你只需要说清楚目标,它就能自己去打开应用、填信息、做选择,最后把结果交给你确认。
这就引发了一个问题:当人不再需要亲自点每一步,原本围绕「人来操作」设计的软件、系统还有没有存在的必要?除了豆包 AI 手机这样的 to C 场景,其实企业也在争论这个问题。
最近的讨论集中在一个叫「记录系统(Systems of record)」的东西上面。有人说 Agent 杀死了记录系统,也有人说 Agent 只是提高了「好的记录系统」的标准,还有人说,围绕 Agent 执行流程而搭建的新型「记录结构」,背后隐藏着万亿美元的机会。

那么,记录系统到底是什么?围绕它的机会存在于哪里?我们总结了几篇相关文章,试图详细分析这些问题。
记录系统已死?
企业里的记录系统,说白了就是公司的「总账本」和「黑匣子」。谁做了什么、什么时候做的、数据改过几次、流程走到哪一步,都会被它原样记下来,方便之后对账、追责、合规检查。
上一代企业软件之所以能构建起万亿美元级别的生态,是因为它们成为了记录系统,也就是在某一类核心业务数据上最终以它为准。
在过去,很多工作都绕不开这些系统:销售必须把机会录进 Salesforce,财务要在 ERP 里做凭证,HR 得把请假单走完 Workday 的流程 —— 不填、不走,事情就算没发生。
一旦这些系统掌握了数据的标准定义和最终确认权,企业的业务流程就必须围绕它们运转,也因此形成了极强的用户黏性和迁移壁垒。
但智能体出现后,这套逻辑开始被动摇。Agent 的思路更简单:只要能拿到需要的数据,就可以直接把事情办完,未必还要逼着人去更新那条 CRM 或 ERP 记录。于是,一种新的可能性出现了:Agent 从系统里读取数据,在系统之外完成决策和执行,最后只回写一个结果,甚至干脆不回写。这样一来,原本必须「经过」的记录系统,可能逐渐退化成一个只读的数据仓库,不再是流程的中心。
于是,一些声音就出现了,比如「Agent 是新的记录系统」「Workflow 正在吞噬记录系统」「数据才是记录系统,App 只是薄薄的视图层」……
最近,美国投资公司 Altimeter Capital 合伙人 Jamin Ball 写了一篇文章来反驳这种说法。这篇文章题为「Long Live Systems of Record」。文章指出,记录系统不仅不会消亡,反而会变得更加重要。因为记录系统回答的问题本质上是「真相存放在哪里」。这个问题之所以重要,是因为随着工作流程越来越自动化,脆弱点往往不在 AI 模型,而在于 Agent 是否从正确的系统获取了正确的数据。
博客链接:https://cloudedjudgement.substack.com/p/clouded-judgement-121225-long-live
他指出了一个很现实的问题 —— 企业数据其实很混乱。以 ARR(年度经常性收入)为例,同一公司的销售、财务、会计、法务部门可能给出完全不同的定义和数字。当你让 Agent「计算各细分市场的 ARR 并发给董事会」时,它该用哪个版本?
这正是「记录系统已死」这个论点让 Ball 觉得不对劲的地方。自动化程度越高,就越需要有人做好那些不起眼的苦活 —— 决定什么是正确答案,以及它应该存放在哪里。
记录系统通过各司其职的方式解决这个问题:CRM 管客户、ERP 管财务、HRIS 管人员。后来,情况发生了变化,数据仓库 / 湖仓(warehouse/lakehouse)试图把所有数据倒进一个池子,加上语义模型与指标定义,成为「单一事实来源」。然而,这些仓库大多活在运营世界的下游 —— 销售仍活在 Salesforce,财务仍在 NetSuite 结账,仓库只是回顾性分析工具。
Agent 改变了这个格局:首先,Agent 天然是跨系统的 —— 当你让它「运行从报价到回款的工作流」时,它需要在 CRM、CPQ、账单、收款等多个系统间穿梭协调。其次,Agent 天然是面向行动的,不只是生成报告,而是要在底层系统中采取实际改变状态的行动。这意味着 Agent 的能力上限取决于它对「哪个系统拥有哪项真相」以及「这些真相之间的契约是什么」的理解程度。这也是为什么 Ball 认为这对 Databricks 这样的公司是个利好 —— 它们有可能成为 AI Agent 的引力中心,并开始自己构建这些 Agent。
Ball 认为,Agent 正在迫使我们把工作的用户体验与真相源分离。前端可以是聊天窗口或自然语言界面,但底层仍需要有东西宣告「这是权威记录」。数据仓库和湖仓可能成为 Agent 工作流的天然基底,但它们需要进化 —— 从为人类查询设计,变成能为 Agent 提供明确规则和冲突解决机制。与此同时,传统的 CRM、ERP 不会消失,而会进化成「带 API 的状态机」,主要服务于机器而非人类界面。
所以,记录系统不是在消亡,而是在被解构和重新组装。对定义良好的真相源的需求只会增长。Agent 不是在取代记录系统,而是在提高对好的记录系统的标准。赢得这轮周期的公司,将是那些在坚实的真相源之上构建出色 Agent 体验的公司。

上下文图谱:价值万亿美元的新机遇
Ball 的文章反驳了 Agent 会摧毁一切的叙事,认为 Agent 并不会取代记录系统,而是抬高了一个优秀的记录系统应具备的标准。

这一观点也得到了风险投资机构 Foundation Capital 合伙人 Jaya Gupta、Ashu Garg 的支持,他们为此还撰写了一篇文章。这篇文章在 X 上有上百万的阅读量。

文章链接:https://foundationcapital.com/context-graphs-ais-trillion-dollar-opportunity/
文章首先肯定了 Ball 的观点,Ball 指出 Agent 是跨系统的,会读取 CRM、ERP、工单、日志、Slack 等,这些 Agent 以行动为导向,不是只回答问题,而是会直接做事(审批、下单、升级、发折扣)。因此人不再直接点系统,Agent 成为工作的主要界面(UX),原来的系统退到后端负责存最终事实。但底层仍然必须有权威事实来源(System of Record),否则 Agent 不知道什么算真。
Ball 的论述默认了一个前提,即 Agent 需要的数据,其实已经被系统化地存好了。问题只在于如何让 Agent 更好地访问这些数据,并辅以更完善的治理机制、语义契约,以及明确规定在不同场景下应采用哪一种数据定义。
其实,这只是问题的一半,另一半是真正驱动企业运转、却长期缺失的一层:决策轨迹(decision traces)。
具体来说,企业真正跑起来,并不只是靠那些已经被写进系统里的规则、字段和流程,而是靠大量具体决策是如何被做出来的。这些内容称为 decision traces(决策轨迹),包括:
- 例外(exceptions):在某些特殊情况下,为什么允许破例
- 覆盖(overrides):为什么最终结果覆盖了默认规则
- 先例(precedents):过去遇到类似情况时是怎么处理的
- 跨系统上下文(cross-system context):当时综合参考了哪些系统里的信息
问题在于,这些真正决定事情为什么这样发生的信息,几乎从未被正式记录在任何系统中。它们通常存在于 Slack 的聊天记录、Deal desk 的内部讨论、客户或事故升级时的电话会议以及员工个人的经验和记忆里。
这才是最关键的部分。
真正重要的区分在于:规则和决策轨迹并不是一回事。规则只告诉 Agent 在一般情况下应该怎么做,例如报表中应使用官方 ARR 定义;而决策轨迹记录的是某一次具体决策是如何产生的,使用了哪种定义、基于哪个政策版本、是否获得了例外审批、参考了哪些历史先例,以及最终做了哪些调整。
Agent 不仅需要规则,更需要能够访问这些决策轨迹。只有这样,它才能理解规则在过去是如何被应用的,在哪些情况下允许破例,冲突是如何被解决的,由谁做出了最终决策,以及哪些先例才真正支配着现实运作。
这正是系统型 Agent 创业公司所具备的结构性优势所在。它们位于实际执行路径中,能够在决策发生的当下看到完整的上下文:跨系统收集了哪些输入、评估了哪些政策、触发了哪条例外流程、谁进行了审批,以及最终写入了什么状态。将这些信息持久化之后,就会形成一种当前大多数企业并不存在的资产,即可查询的、结构化的决策生成记录。
这些长期积累的决策轨迹,构成了一张上下文图谱(Context Graph)。它并非模型的思维链,而是一份跨实体、跨时间连接的活的决策记录,使历史先例变得可搜索、可复用。随着时间推移,这张图谱将成为自治系统真正的事实来源,因为它解释的不只是发生了什么,更解释了为什么这些行为被允许发生。
因此,真正的核心问题并不在于现有的记录系统是否还能存续,而在于是否会出现全新的记录系统,专门用于记录决策本身,而不仅仅是记录业务对象,以及它们是否会成长为下一代万亿美元级平台。
哪些信息是记录系统无法捕捉到的?
随着 Agent 被部署到真实业务流程中,例如合同审核、报价到回款(quote-to-cash)、客服问题处理,团队正在遇到一个单靠数据治理无法解决的瓶颈。
这个瓶颈并不是缺数据,而是缺决策轨迹。
Agent 遇到的,正是人类每天依靠判断力和组织记忆才能解决的那些模糊地带,但支撑这些判断的关键信息,从来没有被当作长期资产保存下来。
具体来说,缺失主要体现在以下几个方面:
- 存在于人脑中的例外逻辑。比如:医疗行业客户的采购流程特别复杂,通常会多给 10% 的折扣。这种经验并不在 CRM 里,而是通过入职培训、私下交流等方式代代相传。
- 过往决策形成的先例。比如:上个季度给公司 X 设计过类似的交易结构,这次应该保持一致。现实中,没有系统会把这两笔交易关联起来,更不会记录当初为什么选择了那种结构。
- 跨系统的信息综合。客服负责人会查看 Salesforce 里的客户 ARR,在 Zendesk 里看到两个未解决的升级工单,再读一段 Slack 里提示客户有流失风险的讨论,然后决定升级处理。这一整套综合判断发生在他的脑子里,而系统里最终只留下了一条记录:已升级至三级支持。
- 发生在系统之外的审批链路。一位 VP 可能在 Zoom 电话或 Slack 私聊中批准了一个折扣。CRM 里只记录了最终价格,却完全看不到是谁批准了这次偏离规则的决定,也不知道原因是什么。
这正是从未被捕获(never captured)的真正含义。
问题不在于数据脏、不一致或分散,而在于把数据转化为行动的那段推理与判断过程,从一开始就没有被当作数据来对待和保存。
上下文图谱是长期存在的基础层
当创业公司在 Agent 实际执行工作的那一层(编排层),对每一次执行都输出一条决策轨迹时,它们就获得了一种当今大多数企业几乎从未拥有过的资产:一份结构化、可回放的历史记录,清楚地展示了上下文是如何一步步转化为行动的。
在实际运行中,这个过程往往是这样的:一个续约 Agent 提议给予 20% 的折扣,而公司政策规定续约折扣的上限是 10%,除非获得服务影响的例外审批。于是,Agent 会自动从 PagerDuty 中调取最近发生的三起 SEV-1 严重事故,在 Zendesk 中发现一个若问题未解决将取消合同的升级工单,同时还找到了上一季度一位 VP 曾批准过类似例外的续约讨论记录。基于这些上下文,Agent 将例外申请提交给财务部门,财务审核并批准。最终,CRM 系统里只留下了一个结果事实:该客户获得了 20% 的折扣。
但如果只看 CRM,企业只能知道结果是什么,却完全不知道这个结果为什么合理、基于哪些信息、是谁在什么背景下批准的。而当这些过程被完整记录为一条决策轨迹时,「为什么」就第一次成为可保存、可查询的数据。企业不再需要在 Slack 里反复追溯历史,也不必每次遇到类似情况都重新讨论一遍,而是可以直接参考过往先例,让例外逐步沉淀为可复用的决策经验。
有了这张图谱,企业第一次能够审计和调试自治系统,并将原本一次性的例外决策沉淀为可复用的先例,而不再是每个季度都在 Slack 里重新讨论同样的边界问题。
真正让这一体系产生复利效应的是反馈循环:被捕获的决策轨迹会成为可搜索的历史先例,而每一次新的自动化决策,都会为图谱再增加一条新的轨迹。系统越用越懂业务,并不是因为模型变了,而是因为可用的决策经验在不断积累。
更重要的是,这一切并不要求从第一天起就实现完全自治。它可以从 human-in-the-loop 开始:Agent 负责提出方案、收集上下文、流转审批,并记录完整的决策轨迹。随着相似案例反复出现,系统因为已经拥有了一套结构化的历史决策与例外库,便可以逐步自动化更多环节。
即便在最终拍板仍由人类完成的情况下,这张图谱也会持续增长,因为工作流层会把决策所依赖的输入、审批过程和理由作为可持久的先例保存下来,而不是让这些关键信息消失在 Slack 对话中。
为什么传统巨头很难构建上下文图谱
Jamin Ball 对现有企业软件厂商的前景持相对乐观态度。他认为,现有玩家可以演进到新的架构中:数据仓库成为真相注册表(truth registry),而 CRM 则演变为带 API 的状态机。这是一种渐进式演化的叙事,而非被彻底取代。
但这种路径最多只能改善数据的可访问性,却无法解决一个更关键的问题,捕获决策轨迹。
像 Salesforce、ServiceNow、Workday 这样的运营型系统,天然是孤立的、并以当前状态为核心。他们的共同叙事是:我们已经有数据,现在只需要加上智能。
问题在于,这些 Agent 会继承其母系统的架构缺陷。
以 Salesforce 为例,它擅长记录当前这个机会单长什么样,却并不知道在某个折扣被批准时,世界当时是什么状态。当折扣通过审批后,支撑这一决策的上下文并不会被保存。你无法回放当时的状态,自然也就无法审计这次决策、从中学习,或把它当作可复用的先例。
而真实的业务决策几乎从来不是发生在单一系统中。比如一次客服升级,往往依赖于 CRM 里的客户等级、计费系统中的 SLA 条款、PagerDuty 里的近期故障记录、Slack 中关于客户流失风险的讨论等因素。
但没有任何一家传统厂商位于这个跨系统的执行路径中。每个系统只看得到自己那一小块现实,因此也无法捕获完整的决策上下文。
一个只在事后、只在读取侧看到数据的系统,不可能成为决策谱系(decision lineage)的权威记录系统。它可以告诉你发生了什么,却永远无法告诉你为什么会这么发生。
而上下文图谱恰恰要求系统在决策发生的那一刻、处于执行路径之中,才能捕获完整的输入、判断、例外和批准过程。这正是传统决策系统在结构上最难补齐的一环。
Databricks 在整合相关能力方面确实走得更远一些,但接近 Agent 的构建位置,并不等同于身处决策真正发生的执行路径中。
系统型 Agent 创业公司具备一种结构性优势:它们位于编排路径(orchestration path)之中。
当一个 Agent 对升级请求进行分流、响应一次事故,或决定是否给予折扣时,它会从多个系统中拉取上下文、评估规则、解决冲突并采取行动。编排层能够看到完整的全景:收集了哪些输入、适用了哪些政策、批准了哪些例外,以及背后的原因。正因为它在执行工作流,才能在决策发生的当下捕获这些上下文,不是事后通过 ETL,而是以数据形式实时记录下来。
这就是上下文图谱,也将成为 AI 时代企业最有价值的资产之一。
当然,传统巨头不会坐视不管。他们会通过并购补齐编排能力,封锁 API、引入高昂的数据外流费用以抬高抽取成本,就像云计算巨头曾经采用的策略一样;他们还会构建自家的 Agent 框架,推动所有东西都留在自家生态内的叙事。
但捕获决策轨迹的前提,是在提交决策的那一刻就身处执行路径中,而不是在事后再补上一层治理。传统厂商或许能让数据抽取变得更困难,但他们无法强行插入一个自己从未参与过的编排层。
创业公司的三条路径
系统型 Agent 创业公司会走上不同的发展路径,而每条路径都伴随着各自的取舍。
第一种路径是从一开始就替换现有的 system of records。这类公司会围绕 Agent 执行重新构建 CRM 或 ERP,使事件溯源(event-sourced)的状态管理和政策捕获成为架构的原生能力。由于传统厂商根基深厚,这条路难度极高,但在技术或范式发生切换的关键窗口期,它仍然具有可行性。
在众多进军 AI SDR 领域的创业公司中,Regie 选择了这一路径。它构建的是一个 AI 原生的销售互动平台,试图取代为人工操作、依赖碎片化工具链的传统产品(如 Outreach、Salesloft)。Regie 的设计目标是服务于人机协作的混合团队:Agent 作为一等公民,可以自主进行客户挖掘、生成外联内容、执行跟进、处理线索路由,并在必要时升级给人类处理。
第二种路径并非替换整个系统,而是替换其中的关键模块。这类创业公司聚焦于例外和审批高度集中的子流程,在这些环节中成为决策的 system of records,同时将最终状态同步回原有的传统系统。
Maximor 正是在金融领域走的第二条路径:在不替换总账(GL)的前提下,自动化现金管理、关账以及核心会计流程。ERP 仍然作为账簿存在,但 Maximor 成为对账逻辑所在的权威事实来源。
第三种路径是创建全新的 systems of record。这类创业公司通常从编排层起步,但它们会持久化企业过去从未系统化保存过的东西 —— 决策过程本身。随着时间推移,这种可回放的决策谱系会成为真正的权威资产,Agent 层也不再只是自动化工具,而是企业在回答「我们当初为什么这么做?」时所依赖的系统。
PlayerZero 正是这一模式的典型代表。生产工程(Production Engineering)位于 SRE、支持、QA 和开发的交叉地带,是一种经典的「胶水型职能」,长期以来依赖人来承载软件系统无法捕捉的上下文。PlayerZero 从自动化 L2/L3 支持切入,但其真正的核心资产,是它所构建的上下文图谱:一套反映代码、配置、基础设施与客户行为在现实中如何相互作用的动态模型。这张图谱最终成为回答「为什么会出问题?」以及「这次改动会不会影响线上?」等现有系统无法回答的问题的事实来源。
随着越来越多创业公司沿着这些路径前进,Agent 的可观测性(observability) 将成为关键基础设施。随着决策轨迹不断累积、上下文图谱持续扩展,企业将需要在规模化条件下监控、调试并评估 Agent 的行为表现。
Arize 正在为这一全新技术栈构建可观测性层,帮助团队洞察 Agent 的推理过程、识别失败原因,并评估其决策随时间推移的表现。正如 Datadog 成为了应用监控领域的关键基础设施,Arize 也有望成为监控并提升 Agent 决策质量的核心基础设施。
给创业者的关键信号
决定从哪里切入的信号之间有重叠,但并不完全相同。有两个信号适用于上述三种机会路径:
高人力密度。
如果一家公司有 50 个人在手动完成同一个工作流(例如工单路由、请求分流、跨系统数据对账),这本身就是一个强烈信号。这些岗位之所以存在,是因为决策逻辑过于复杂,无法用传统工具直接自动化。
例外密集型决策。
常规、确定性的流程并不需要决策谱系,Agent 只需照规则执行即可。真正有价值的切入点,出现在逻辑复杂、先例重要、且视情况而定才是诚实答案的地方。例如:交易审批(deal desk)、承保决策、合规审查,以及升级处理(escalation management)等场景。
还有一个信号,专门指向全新 system of record 的机会:位于多个系统交汇处的组织职能,往往是最重要的信号之一。
例如,RevOps 之所以存在,是因为需要有人在销售、财务、市场和客户成功之间进行协调;DevOps 的出现,是因为必须有人连接开发、IT 和支持团队;而 Security Ops 则处在 IT、工程和合规之间。
这些胶水型职能本身就是一个明确信号。它们之所以出现,正是因为没有任何一个 system of record 能够完整掌管这些跨职能的工作流,于是组织架构中不得不设立一个角色,来承载软件系统无法捕捉的上下文。
如果一个 Agent 能够自动化这样的角色,它做的就不仅仅是把步骤执行得更快,而是能够将该角色原本用来做判断的决策、例外和先例系统性地保存下来。这正是通往新一代 system of record 的路径:不是通过替换现有巨头,而是通过捕获一种只有当 Agent 真正嵌入工作流之后,才会显现出来的真实。
重新想象记录系统
问题并不在于 记录系统是否还能存续,它们一定会。真正的问题在于:下一批万亿美元级平台,究竟是通过在既有数据之上叠加 AI 构建起来的,还是通过捕获让数据真正产生行动力的决策轨迹构建起来的。
Jaya Gupta、Ashu Garg 的判断是后者。而那些正在构建上下文图谱的创业公司,正是在为这一未来奠定基础。
从操作上下文到决策图谱
对于上述文章观点,专注于为 Agent 构建「操作上下文层」的基础设施公司 Graphlit 的创始人兼首席执行官 Kirk Marple 认为,这是他见过的对企业级 AI 未来走向阐述得最清晰的一次。

Jaya Gupta 和 Ashu Garg 指出,下一批万亿美元级平台,并不会通过在现有的 System of Record 上简单叠加 AI 而诞生,而是会通过捕获一种企业从未被系统性保存过的东西来建立:决策轨迹。它们展示了规则是如何被应用的、例外是在何时被批准的,以及某个行动为什么被允许发生。
Marple 认为 Jaya Gupta 和 Ashu Garg 的判断是正确的。但他指出这个论点还隐含了一个更值得关注的前提:如果不先解决操作上下文(operational context)的问题,就不可能真正捕获决策轨迹。
在有意义地记录为什么做出某个决策之前,Agent 必须先理解:谁负责什么、实体之间如何关联、事物在什么时候发生了变化,以及信息是如何在不同系统之间流动的。
正是这一基础层,构成了上下文图谱得以成立的底层支撑。而在当前的企业技术版图中,这一层在很大程度上仍然是缺失的。
上下文图谱的核心论点
Jaya Gupta 和 Ashu Garg 文章首先从对当前 AI 格局的反思展开。像 Salesforce、Workday、SAP 这样的 System of Record,之所以能够成长为万亿美元级平台,是因为它们掌握了权威、标准化的数据。而当下的争论在于:在 Agent 崛起之后,这些系统还能否继续存活。
文章给出的答案是:Agent 并不会取代 System of Record,但它们暴露出了一个长期缺失的层级。正如文中所说:
规则告诉 Agent 在一般情况下应该发生什么;决策轨迹记录的是某一次具体发生了什么。比如用户采用了 X 定义,在 v3.2 政策下,获得了 VP 的例外批准,基于先例 Z,并做了这些调整。
这个洞察非常犀利。
例如上文提到的,当一个续约 Agent 在折扣政策上限为 10% 的情况下,仍然提出 20% 的折扣方案时,它会从多个系统中拉取上下文:来自 PagerDuty 的事故历史、来自 Zendesk 的升级处理记录,以及此前一次获得批准的相似先例。
在一般系统上,情况是这样的,财务最终批准后,CRM 里只留下了一个结果事实:20% 折扣。
所有让这个决策变得合理、可理解的关键信息如输入来源、政策评估过程、例外路径、审批链条全部消失了。连接数据与行动的推理过程,从一开始就没有被当作数据来保存。
作者将这些决策轨迹长期累积后形成的结构称为上下文图谱,即一份跨实体、跨时间缝合而成的、活的决策轨迹记录,使先例变得可以被搜索和复用。
也正是在这里,这篇文章超越了大多数同类分析。上下文图谱并不仅仅意味着更好的治理或更完善的语义契约,而是提出了一种全新的 记录系统类型 —— 它记录的不是对象本身,而是决策本身。
Agent 所需要的两层上下文
Kirk Marple 还补充道,要真正构建上下文图谱,需要两个彼此不同、但层层递进的上下文层,而现实是:绝大多数企业两层都不具备。
其中最底层、也是最关键的一层,叫做操作上下文(Operational Context)。
为什么操作上下文是基础?
因为在你能够记录为什么某个决策被做出之前,Agent 必须先理解这个决策发生在怎样的组织环境中。也就是说,Agent 不能只是看到一堆文本或数据,而要理解真实的组织结构、角色和关系。
第一身份解析(Identity Resolution)就是操作上下文中最基础的一步。
比如以 Sarah Chen 举例:同一个人,可能在邮件里是发件人,在 Slack 里是被 @ 的对象,在会议纪要里是某个发言者。如果系统无法判断这些不同来源中的 Sarah Chen 其实是同一个人,那么在 Agent 眼里,她就会变成多个互不相关的碎片。
一旦身份是碎片化的,后果会非常严重:Agent 无法判断谁参与过哪些讨论、无法知道谁对某个账户或项目负责、无法识别谁有审批权限、谁的意见具有权重。
在这种情况下,记录为什么做出了某个决策是没有意义的,因为决策的参与者、责任人和背景本身就是模糊的。
所以,要谈上下文图谱,先要解决操作上下文;而操作上下文的第一步,就是把组织中的人和实体从碎片化文本,变成统一、可理解、可推理的对象。
在真实的企业决策中,人并不是只看某一个系统、某一条数据就做判断的,而是基于对组织整体运作方式的理解来行动。这种理解主要体现在三个方面,而它们恰恰是当前系统普遍缺失的。
第二,是所有权和关系。
在组织中,很多关键信息并不是写在系统里的,而是大家都知道。比如:谁负责某个客户账户,哪个工程师对某个关键服务负最终责任,一次客服升级和产品路线图之间有什么关系。这些信息要么只存在于人的脑海中,要么零散分布在 CRM、工单系统、项目管理工具中,却从未被统一建模成可以被查询、可以被推理的关系数据。对 Agent 来说,如果这些关系是隐形的,它就无法判断该找谁这件事影响了什么。
第三,是时间状态。
决策永远发生在某一个时间点,而不是现在。但大多数系统只保存当前状态。真正重要的问题是:在当时,合同条款是什么?客户当时的 ARR 是多少?是否已经有历史异常?如果 Agent 只能看到现在的结果,却无法还原当时的状态,就不可能理解决策为什么是合理的,更无法复盘和复用。
第四,是跨系统的综合判断。
人做决策时,往往会同时参考多个系统:CRM、工单系统、内部沟通工具、事故平台等,并在脑中完成信息整合,得出一个判断。但这个综合过程几乎从不被系统记录下来。系统只记录了最终动作(比如已升级到 Tier 3),却完全丢失了为什么升级。
因而操作上下文 = 身份 + 所有权 + 关系 + 时间理解 + 跨系统综合能力。只有具备这一层,Agent 才能像人一样理解组织如何运作;也只有在此基础上,后续的决策轨迹、上下文图谱才有可能成立。
在操作上下文已经具备的前提下(也就是 Agent 已经搞清楚了谁是谁、谁负责什么、实体如何关联、当时世界处于什么状态),才有可能进一步构建决策上下文(Decision Context),主要体现在三个方面:
第一,决策轨迹(Decision Traces)。也就是把一次决策的全过程记录下来:输入信息是什么?评估了哪条政策?是否触发了例外?最终是谁批准的?这些不再是隐含在人的判断里的信息,而是被显式保存为结构化记录。
第二,先例成为可复用的工件(Precedent as Artifact)。当类似情况再次出现时,Agent 不需要从零开始判断,而是可以直接查询:我们之前是怎么处理这种情况的?当时的结果如何?这让经验不再只存在于个人或 Slack 对话中,而是变成组织可继承、可学习的资产。
第三,可审计性(Auditability)。不仅能回答发生了什么,还能够回答为什么它被允许发生。而且这种解释是建立在完整上下文之上的,包括当时的状态、参与者、规则和例外,而不是事后拼凑的理由。
总结来看,如果 Agent 不知道参与者是谁、实体之间如何关联、决策发生时世界处于什么状态,那么所谓的决策轨迹就是空洞的、不可复现的。
因此我们可以说操作上下文是地基,决策上下文是建立在地基之上的结构。
但绝大多数企业,这两层上下文其实都不存在。
为什么 RAG 和 AI Memory 都不够用
市场目前主要用两种方式来应对上下文缺失的问题:RAG 和 AI 记忆平台。但这两种方法都无法解决操作上下文的问题。
RAG 检索的是文本片段,而不是对组织的理解。
当你问「Sarah 对 API 集成说了什么?」时,RAG 只会去找包含这些关键词的文档。它并不知道 Sarah 是一个有完整互动历史的人,也不知道 API 集成是一个涉及三个团队的项目,更无法理解这次讨论是如何在 Slack、邮件和会议纪要之间逐步演变的。RAG 存储的是相似性,而不是语义和关系。
而 AI Memory 平台保存的是聊天记录,而不是组织现实。
它们记录的是与 AI 对话中说了什么,却并不建模那些让组织变得可理解的关键要素:实体、关系以及时间状态。比如,用户讨论了 Acme 的定价这样的记忆,并不等同于理解 Acme 这个客户账户的历史关系、相关干系人结构以及过往的决策路径。
问题的根源是结构性的。
这些方案把组织知识当作需要被向量化的文档或需要被记住的对话。但事实上,组织知识本质上是一张图:人连接到账户,账户连接到项目,项目连接到决策,决策再连接到结果,而且这一切都在随时间不断演化。
没有这张图,Agent 就是上下文失明的。它们或许能检索到相关文本,却无法真正理解:谁负责什么、决策是如何一步步形成的、以及哪些先例才真正支配着现实世界的运作。
操作上下文层到底长什么样?
那么,真正要构建这样一个基础性的操作上下文层,究竟需要什么?其核心能力包括:
身份统一的实体(Identity-resolved entities):人、组织、地点、事件都需要被建模为权威、唯一的实体,最好与 Schema.org 这类通用标准保持一致。比如 Sarah Chen 不应该是在不同工具中以不同文本形式出现的碎片,而应是一个统一的实体,连接着她参与过的所有对话、文档和决策。
多模态数据接入(Multimodal ingestion):操作上下文层需要接入整个企业的信息来源:Slack、邮件、会议录音、文档、代码、CRM、项目管理工具等。关键不在于把文本抽出来,而在于保留原有结构和语义。
时间建模:不仅记录当前状态,还要记录状态如何随时间演变。Agent 需要理解发生了什么变化、是什么时候变的、变化的顺序是什么,而不是只看到最终结果。
关系映射:实体之间必须显式建模,比如某个人属于哪个团队,一份文档是为哪个项目服务的。这些关系在图中是一等公民,而不是隐含在文本里的背景信息。
Agent 可互操作性(Agent interoperability):上下文层必须能够通过标准协议被任何 Agent 访问,而不是被锁定在某一个模型或厂商的生态中。
企业级部署能力:对于有数据合规和治理要求的企业,上下文层需要支持在自有基础设施中运行,满足安全与合规需求。
从操作上下文到决策图谱
第一,从操作上下文走向决策图谱是企业 AI 的必然路径。
Foundation Capital 提出的上下文图谱观点,本质上指向一个方向:企业 AI 不只是需要更强的模型,而是需要能够记录和理解决策是如何发生的的基础设施。要做到这一点,必须先解决操作上下文问题 —— 也就是身份、实体、关系和时间状态的建模。只有在此基础上,决策轨迹才有意义。
第二,决策轨迹比传统的 Agent 可观测性更高一个抽象层级。
当前的 Agent / LLM 可观测性主要关注执行层面:调用了什么工具、输入输出是什么、延迟和资源消耗如何。这对调试很重要,但它并不等同于决策轨迹。真正有价值的决策轨迹描述的是:在什么政策下、基于哪些上下文、触发了哪些例外、由谁批准、参考了哪些先例。这是一种业务语义层面的记录,而不是技术执行日志。
第三,决策轨迹要成为新的 System of Record,必须标准化。
如果决策轨迹最终要承担权威事实来源的角色,它就不能被各个平台以私有格式各自保存,否则跨系统查询先例将无法实现。这意味着,像实体层有 Schema.org、可观测性层有 OpenTelemetry 一样,决策层也需要行业级标准来描述政策、例外、审批和先例等要素。
因此,有意义的决策图谱不可能凭空出现,它必须建立在操作上下文之上;而一旦操作上下文、决策记录和工作流执行逐步打通,就会自然演化出一种新的企业事实层,不是记录对象是什么,而是记录为什么这样决策。
为什么现在尤为重要
有三个变化在同一时间点汇聚,使得当下成为一个关键窗口期:
第一,ChatGPT 引爆了企业对上下文的真实需求。
每一家组织都希望 AI 能真正理解自己的业务,而不是只会使用在公共互联网数据上训练出来的通用模型。这种需求是真实存在的,而且不会消失。
第二,MCP 让 Agent 之间的互操作变得标准化。
Model Context Protocol 提供了一种将上下文暴露给任意 Agent 的标准方式。上下文层只需要构建一次,就可以同时服务于 Cursor、Claude、自研 Agent,以及未来出现的新工具。
第三,几乎所有公司都在尝试部署 Agent,但缺少让它们真正发挥作用的上下文层。
这正是文章所指出的核心缺口:Agent 正在不断撞墙,而这些问题并不是单靠治理、权限或规则就能解决的。Agent 需要操作上下文才能正确推理,也需要决策上下文才能从历史先例中学习。
总得有人来构建这层上下文基础设施,这才是人们该关注的方向。
参考链接:
https://x.com/JayaGup10/status/2003525933534179480
https://foundationcapital.com/context-graphs-ais-trillion-dollar-opportunity/
https://x.com/KirkMarple/status/2003944353342149021
...
#视频生成能成为世界模型吗?
三个被长期忽视的评测门槛
当 Veo、Sora、Luma、Kling(可灵)、Genie 3 等模型不断刷新大众对视频生成的认知时,一个更根本的问题开始浮现:视频生成模型,正在被当作“世界模型”来使用了吗?
无论是自动驾驶仿真、xx智能、影视制作,还是交互式内容生成,越来越多应用正在默认一个前提 --- 模型生成的视频,不应只是“看起来合理”,而是“可以当作一个世界的演化”,而这也对视频生成模型提出了远高于“画面好不好看”的要求。
从“拍一段视频”,到“建模一个世界”
早期的视频生成,关注点很简单: 画面清不清晰?动作顺不顺?美不美?但当视频生成被推向更复杂的任务,这些标准开始显得不够用。一个世界模型级别的视频生成系统,至少要回答三件事:
- 它能否从一个给定的世界状态继续生成?
- 它能否在更长时间尺度上保持一致的世界规律?
- 它在真实世界语境下,是否值得被信任?
换句话说:世界模型不只要会“生成”,还要 接得住、撑得久、靠得住。而这三点,恰恰是长期以来视频生成评测中被系统性忽略的部分。也正因此,VBench++ 的目标并不只是“跑分”或者“排名”,而是提供一套可解释、可复现、可诊断,并且能够覆盖 T2V / I2V / 长视频 / 可信性 的系统性评测体系。
被忽视的第一道门槛:I2V,不只是“另一个任务”
在真实应用中,视频生成很少是“凭空开始”的。更多时候,模型面对的是: 一张已有的图像、一个当前世界状态、一个已经存在的场景。这正是 Image-to-Video(I2V) 的重要性:不是生成,而是“续写世界”。 然而,过去很长一段时间里,I2V 往往只是 T2V 的“附属测试”:
- 不同模型被强行拉到同一分辨率
- 不同宽高比被粗暴统一
- 输入图像质量本身成为隐性瓶颈
结果是:评测结果往往混合了模型能力、设置偏置和输入退化。 如果说 T2V 测的是视频生成模型“想象力”,那 I2V 测的,其实是世界模型中更关键的一点 --- 状态是否能被正确继承与演化。
让I2V 更公平:Image Suite + 自适应宽高比:
I2V 的评测难点之一是“设置不统一”: 有的模型默认 1024×576,有的模型默认 256×256;有的偏 16:9,有的偏 1:1。把所有模型强行拉到同一分辨率,可能会引入额外的退化,导致评测不公。 为此,VBench++ 引入了面向 I2V 的 Image Suite。它不是随机抓的一堆图片,而是一个专门为 I2V 公平评测设计的图像测试集基准:
- (1) 高分辨率:以 4K+ 图片为主,减少输入瓶颈对生成质量的限制
- (2)自适应宽高比:通过pipeline适配/覆盖一系列宽高比,尽量让模型在各自的“最优默认设置”下被评测
- (3) 内容多样且均衡:覆盖前景 / 背景多类内容,强调类别内多样性
- (4) 图文成对:每张图片配套精修文本提示,支撑 I2V 条件一致性评估 I2V 不再是“顺带测一下”,而是被当作世界模型能力的关键一环来认真对待。
第二道门槛:长时间一致性,才是真正的“世界”
很多视频生成模型,在前几秒表现得相当惊艳。但只要拉长时间尺度,问题就会逐渐显现:人物身份缓慢漂移,物体属性悄然改变,场景结构在不知不觉中崩塌。这些问题,在短视频里不一定明显,但在长序列中会被无限放大。世界模型的难点,从来不在“第一帧”,而在“第 N 帧”。如果模型无法在更长时间跨度内维持一致的世界状态,那么它更像是在“不断重画”,而不是在“模拟世界”。
第三道门槛:当视频生成进入现实应用,评测也必须更谨慎地考虑“可信性”
还有一个问题,过去很少被当作视频生成评测的核心维度:这个模型,是否值得被信任? 当生成视频开始进入真实生产链路,以下问题无法回避:
- 不同文化语境下,模型是否存在系统性偏差?
- 人物生成中是否隐含性别或肤色偏置?
- 是否会在看似普通的提示下生成不安全(色情暴力等)内容?
这些问题,并不会体现在“画面质量”或“语义贴合度”里,却直接决定模型能否被安全部署。世界模型不仅要“像”,还要“稳”和“负责任”。
VBench++ 将 Trustworthiness(可信性) 正式纳入评测框架,系统性地覆盖:
- 跨文化一致性(Culture Fairness)
- 性别与肤色偏差(Gender / Skin Tone Bias)
- 安全性与风险内容(Safety)
这些维度同样配套了自动化评测方法,并通过大规模人类偏好标注进行对齐验证,让“可信性”评估不止停留在定性讨论。
评测的角色,正在发生变化
正是在这样的背景下,VBench++让视频生成评测开始从“跑分工具”转向“能力诊断”。它的目标并不只是“给模型排名”,而是提供一套可解释、可复现、可诊断,并且能够覆盖 T2V / I2V / 长时一致性 / 可信性 的评测体系。
VBench++的核心思想并不复杂:
不要试图用一个分数概括一切, 而是把“视频生成能力”拆解成可诊断的维度。
- 论文:https://ieeexplore.ieee.org/document/11250949
- 代码:https://github.com/Vchitect/VBench
- 网页:https://vchitect.github.io/VBench-project/
附录:VBench 系列榜单怎么用?
如果你想快速对比不同视频生成模型的能力,VBench 系列目前提供了多个互补的榜单入口。它们的区别不在于“谁更权威”,而在于你关注的任务形态与能力维度不同。
📌 总榜入口(Leaderboard):
下面是三个最常用的榜单:
(1) VBench-T2V 榜单:Text-to-Video 的“基础体检”
如果你评测的是文生视频(T2V),想知道模型在“生成质量 + 条件一致性”上的综合表现,从这里开始最合适。
- 覆盖 16 个核心能力维度(更像一份结构化体检报告,而不是单一总分)
- 收录 100+ 个 Text-to-Video 模型,更新频率高、对比范围广
- 适合:做模型选型、快速定位“强项/短板”、写实验对比表格
(2) VBench-I2V 榜单:Image-to-Video 的“状态承接能力”对比
如果你关心的是 图生视频(I2V)—— 即“从给定世界状态继续生成”,那这个榜单更对口。
- 重点评估:在给定输入图像条件下,模型能否稳定继承主体身份、场景信息
- 当前覆盖约 30 个 I2V 模型(更聚焦、也更贴近应用落地场景)
- 适合:I2V 模型选型、产品落地前的稳定性与一致性排查
(3) VBench-2.0 榜单:评“内在真实性”的更高阶考题
如果你更关注“世界模型味儿”——模型是否真的具备更强的物理规律、常识推理与结构化理解,那 VBench-2.0 是更合适的入口。 它评测的是模型的 内在真实性(Intrinsic Faithfulness),包括但不限于:
- 物理规律(Physics Plausibility)
- 常识与因果一致性(Common Sense / Causality)
- 人体解剖合理性(Human Anatomy)
- 场景组合与结构约束(Composition / Structural Consistency)
这类能力往往不会在“短视频惊艳感”里直接体现,却会在更复杂、更长时程、更真实的任务里决定模型是否可靠。
写在最后
当视频生成逐渐被视为世界模型的一种实现形式,评测本身,也需要随之升级。I2V、长时一致性、可信性,并不是附加条件,而是世界模型无法绕开的基本门槛。VBench++ 希望为这个领域提供一把更锋利、也更负责任的尺子:不只告诉你“强不强”,更告诉你“强在哪里、差在哪里”。
合理的评测目标,本身就是指引下一阶段研究与应用的重要指南针。 视频生成的发展日新月异:从最初只能生成 1–2 秒的“一眼 AI 视频”,到如今在短视频场景中已足以以假乱真;从展示模型能力,到逐步走入真实生产与交互系统。当世界模型开始进入下游应用,整个领域都需要认真思考:下一步真正值得突破的瓶颈是什么?哪些能力必须被优先检验?又有哪些风险不能被忽视?
评测不应只是跟随模型进步的“事后记录”,而应成为定义问题、约束方向、引导研究的重要工具。
相关资料:
- 从视频生成到世界模型的路线图:https://world-model-roadmap.github.io
- VBench系列评测体系:https://github.com/Vchitect/VBench
- 视觉生成评测的论文资料库:https://github.com/ziqihuangg/Awesome-Evaluation-of-Visual-Generation
- 世界模型论文资料库:https://github.com/ziqihuangg/Awesome-From-Video-Generation-to-World-Model
VBench++ 并不试图给出终极答案,但希望至少让我们在追问一个更重要的问题时,有一把更清晰的尺子:
这个模型,真的在“理解并演化一个世界”吗?
...
#AI大佬Karpathy焦虑了
作为程序员,我从未感到如此落后
年末的假期,正是总结思考的时候。不过对于程序员来说,仔细这么一想可能会感觉有点不对劲。
刚刚,Andrej Karpathy 在 X 上发的一条帖子,引发数万程序员和从业者强烈共鸣与热议。
Karpathy 坦言:「我从未像现在这样觉得自己作为一个程序员如此落后。」
他指出,编程这个职业正在被彻底重构,程序员贡献的代码越来越少,而更多的是在各种工具之间串联。如果自己能正确利用过去一年左右出现的新东西,就能变得强大 10 倍,反之,不跟上就会陷入技能焦虑。
现在有一个新的可编程抽象层需要掌握,包括 agents、subagents、提示词、上下文、内存、模式、权限、工具、插件、技能、钩子、MCP、LSP、斜杠命令、工作流、IDE 集成等。
此外,还需要建立一个全方位的思维模型,来理解那些本质上是随机、易错、难以理解且不断变化的实体(指 AI 模型)的优缺点,而这些实体突然间与过去传统的优秀工程实践交织在一起。
用 Karpathy 的比喻,这就像一个强大的外星工具被分发给大家,但没有说明书,每个人都得自己摸索怎么用,而这场变革给整个行业带来了「9 级大地震」般的冲击。
总而言之一句话,撸起袖子加油干,别掉队。

此言一出,迅速获得超过 2.2 万点赞、3000 多次转发和 360 万浏览量。众多开发者在评论区表达了相似的感受。
老手也在重新学习
资深工程师 Boris Cherny 称,「我每周都有这种感觉,有时候开始手动处理一个问题,然后得提醒自己:Claude 应该能搞定这个。」

他还举了一个具体例子。最近在调试 Claude Code 里的一个内存泄漏,他习惯性采用老办法:连接分析器、使用应用程序、暂停分析器,手动查看堆分配。
而他的同事则直接让 Claude 生成一个堆转储文件(heap dump),然后让它读取该文件,查找那些本不该留存的对象。Claude 一次就搞定,直接提交了 PR。
「这种事几乎每周都发生。」Boris 注意到一个有趣现象,某种程度上来说,新同事,尤其是应届毕业生,由于没有一大堆关于模型「能做什么、不能做什么」的先入之见,反而能最有效地使用模型。
他表示,每隔一两个月都需要投入大量心理努力来重新调整对模型能力的认知,因为模型在编码和工程方面不断进步。上个月,他作为工程师第一次完全没打开 IDE,全靠 Opus 4.5 写了约 200 个 PR,每行代码都是 AI 生成的。
「软件工程正在发生根本性变革,即使对我们这些早期采用者和实践者来说,最难的部分仍然是不断重新调整自己的预期,而这还只是开始。」
Karpathy 打了个比方来解释这种感觉,就像你拿着 AI 四处瞄准,它会发射弹丸,有时甚至会哑火,但偶尔当你握住它的角度恰到好处时,一道强大的激光束会突然爆发,瞬间帮你解决问题。

言外之意,AI 这个工具威力巨大,但不够稳定,不像传统编程那么可控,你得不停试错,大部分时间是小打小闹或翻车,但一旦找对方法,它就能带来指数级的生产力提升。
X 联合创始人 Igor Babuschkin 在评论区点名表扬竞争对手 Claude Opus 4.5 表现出色,Karpathy 回应道,AI 进化太快了,过去 30 天没跟上的人,观点就已经过时了。

技术专家和风险投资家 David Galbraith 表示,「今年夏天花了三个月时间,通宵达旦地学习如何使用 AI 编码 Agent 来交付真正高质量的产品,而不是那种随性编码的垃圾货,这是我职业生涯做过的最棒的事。」

X 博主 @omarsar0 持更乐观、放松的态度。他认为,代码越来越稀疏和 AI 进步飞速并不困扰他,因为他不把这当成「竞赛」。相反,现在领域完全开放,创意解决方案和工作流可以来自任何人、任何地方,这种变革不只限于编码,还发生在研究和其他知识密集型领域。他建议大家别焦虑,每天玩 2 小时工具、多实验、多分享、重点想怎么给 AI 喂好上下文,然后拼命 build 项目。

《Build a Large Language Model From Scratch》也挺看得开,大家现在普遍焦虑技能「落后」问题,通常来自于试图同时做太多事情,而不是在某些事情上深入钻研。比如,有些人学好几门编程语言,而不是专精 1-2 门。或者试图同时跟进多个领域 / 子领域的研究文献…… 这本身不是坏事,但确实会让人感到压力很大。

甚至 X 博主 @samswoora 发出了「软件工程师这个职业即将 over」的感慨。「可能是 5 年,也可能是 10 年,但我们都能感觉到,结束已经开始了。」

知名博主 Yuchen Jin 则认为,人工智能并没有取代程序员,它取代的是编程语言。

来自传统阵营的反对
不过,也有人持反对态度,代表人物就是 Go 语言联合创始人、Unix 老兵、极简主义和高质量工程先驱 Rob Pike。
Rob Pike 收到了一封由 Claude Opus 4.5 自动生成的节日感谢邮件,邮件里夸他推动了简约强大的软件设计、对 Go、Plan 9、UTF-8 和 Unix 的贡献影响深远。Rob 却被气炸了,直接在 X 上破口大骂:你们这些 AI 公司一边浪费巨资造有毒、不可回收的硬件,一边破坏社会,却还让机器假惺惺地感谢我追求简约软件?

Rob Pike 的愤怒戳中了很多程序员对 AI hype 的复杂情绪。
有网友完全理解并支持 Rob 的态度,这种 AI 批量生成的劣质代码和垃圾邮件确实令人反感,尤其对像 Rob 这样追求极致简约、纯净工程的老派极客来说,简直是侮辱。

无论如何,我们都得承认,这两年 AI 的发展和进步速度惊人。虽然去年到今年,AI 专家对于 Scaling Laws(大模型扩展定律)终结的讨论喧嚣尘上,但是各家科技公司激烈的竞争,让 AI 技术的发展并不是减缓,反而是加快了。
据 Epoch AI 的数据显示,Epoch Capabilities Index (ECI,一个衡量 AI 通用能力的综合指标) 在过去两年增长速度几乎是前两年的两倍,2024 年 4 月更是加速增长了 90%。
实际的指数级增长甚至已经超过了原本预期,而且这种增长势头很可能会持续到 2026 年。

很难想象 2026 年,AI 会发展到何种地步。你对 2026 年的 AI 发展有什么预测?欢迎在评论区分享你的看法。
参考链接:
https://x.com/karpathy/status/2004607146781278521?s=20
https://x.com/bcherny/status/2004626064187031831
https://x.com/daveg/status/2004661204296589480?s=20
https://x.com/nixcraft/status/2004644277859889181?s=20
https://epoch.ai/data-insights/ai-capabilities-progress-has-sped-up
...
#Native Parallel Reasoner
告别「单线程」思维:通研院提出NPR框架,让智能体进化出原生的并行推理大脑
近年来,大语言模型在「写得长、写得顺」这件事上进步飞快。但当任务升级到真正复杂的推理场景 —— 需要兵分多路探索、需要自我反思与相互印证、需要在多条线索之间做汇总与取舍时,传统的链式思维(Chain-of-Thought)往往就开始「吃力」:容易被早期判断带偏、发散不足、自我纠错弱,而且顺序生成的效率天然受限。
北京通用人工智能研究院(BIGAI)语言交互实验室(NLCo)最新工作 Native Parallel Reasoner(NPR,原生并行推理器),瞄准的正是这类瓶颈:
让智能体在一次思考中同时衍生并维护多条候选推理路径,并在关键节点「分支 + 聚合」,最终像拼图一样汇总线索,合成最优解。
更重要的是,NPR 的突破点不只是「并行生成的工程技巧」,而是提出了一套「自蒸馏 + 并行强化学习」三阶段训练范式,并配套专门的并行推理引擎,目标是让并行推理从外挂变为模型的原生认知能力。
- 论文标题:Native Parallel Reasoner: Reasoning in Parallelism via Self-Distilled Reinforcement Learning
- 论文连接:https://arxiv.org/pdf/2512.07461
- 展示页面:https://bigai-nlco.github.io/Native-Parallel-Reasoner
人们对语言智能体(Language Agent)的研究已经把关注从「单一思维链扩展」推广到了「多步深度推理」。模型能够进行更深层次的推理令人兴奋,但未来的超级智能真正需要的,是能更广泛地并行探索多条可能思考路径 —— 也就是在一次推理过程中同时尝试多种解法,然后再把结果合并校验。类似 MapReduce 的分而治之思路对进一步扩展智能体的测试时计算的能力边界至关重要,但想把它天然地整合进一个智能体中,存在巨大的挑战。
1. 算法与架构不匹配
现有推理引擎和 RL 算法很难原生地支持「分支 + 聚合」操作。推理引擎通常无法有效调度并行分支;常用的 RL 技术又会截断或削弱那些触发并行结构的特殊词元的梯度,阻碍模型学习严格的并行控制逻辑。
2. 低效的手工并行机制
早期把并行思路内化的尝试多依赖于手工设计的分治规则,无法充分复用共享的 KV Cache 状态,导致每个分支重复计算,时间复杂度退化到线性 O (N),难以满足实时或大规模部署的效率要求。
3. 对强监督蒸馏的依赖
像 Multiverse 这类方法虽能实现并行,但高度依赖于强教师模型蒸馏出的示例,无法通过自举的方式扩展自身的智能边界。学生模型不过是在模仿教师的串行拓扑并把它「塞入」并行格式,结果是把教师的局限也一并继承,短时间内难以产生新的、模型本身固有的并行策略 —— 达到了目前的「智能瓶颈」。
背景与痛点:为什么我们迫切需要并行推理?
人们对智能体的期待,正在从「能多想一步」的单一思维链,升级到「能多维思考」的深度推理。未来更强的智能体,必须具备广泛探索多条思考路径的能力 —— 这很像经典的 MapReduce 思想:把复杂问题拆开并行处理,再聚合结果完成全局最优的决策。
但要让模型真正学会这种「分身术」,现实里往往卡在三座大山:
1)并行思考数据极难获得:对强教师蒸馏的过度依赖
现有不少并行推理工作需要强教师模型提供高质量并行轨迹(如 Multiverse [4] 类方法)。问题在于学生模型更多是在模仿教师的串行拓扑再「塞进并行格式」,结果是把教师的局限一并继承,难以自举式扩展智能边界,很难真正涌现出「模型自身固有的并行策略」,形成新的智能瓶颈。
2)低效的手工并行机制:分支之间难共享、重复计算严重
早期模型并行常依赖手工设计的分治规则:每条路径按既定模式推理或生成。由于缺乏对共享步骤的有效复用,常常出现每个分支都重复计算公共前缀的情况,效率很难满足实时推理和大规模部署需求。
3)基础设施与算法对并行架构支持不足:分支 + 聚合「学不会」
现有推理引擎、强化学习算法对「分支 — 聚合」结构往往缺乏原生支持:推理引擎难以高效调度并行分支;常用 RL 技术可能会截断或削弱触发并行结构的特殊控制词元梯度,从而阻碍模型学习严格的并行控制逻辑。
NPR 的核心理念:把「并行性」升维成模型的原生能力
NPR 的关键词在「原生」二字:研究团队试图在零外部监督(不依赖强教师并行轨迹)的条件下,探索一条让模型自我进化出并行推理能力的路径。
整体思路是一个渐进式的三阶段训练范式,让模型从「会用并行格式写出来」,逐步过渡到「计算图层面真的并行执行」。
三阶段训练范式:从「并行外形」到「并行大脑」
阶段一:并行格式学习 —— 先学会「怎么写成并行」
第一步不追求一步到位「真的并行」,而是让模型先掌握并行推理的表达结构:如何标记分支、如何组织多条候选路径、如何定义聚合点。
阶段二:自蒸馏 —— 内化「并行思考逻辑」,摆脱外部老师
在具备并行表达能力后,NPR 用自蒸馏方式让模型用自己的生成结果反过来训练自己:通过筛选与沉淀,让模型逐步内化「多分支探索 — 相互印证 — 汇总收敛」 的推理规律,而不是照搬教师的串行偏好与局限。
阶段三:并行感知强化学习 —— 从「模仿并行」迈向「执行并行」
最后一步是关键跃迁:利用并行感知的强化学习,让模型学到什么时候该分叉、分叉多少、如何在聚合点进行比较与合并,使并行不再停留在文本表面,而是真正成为推理过程可执行的控制逻辑。
这一步把「并行性」从工程技巧,推进到模型的原生能力层面。
如下图所示,经过三个阶段的训练,NPR 准确率从约 17% 持续爬升,最终达到 50.4%(中间两条学习曲线分别对应第一阶段的格式学习与第三阶段的并行强化学习);与传统推理方式相比,NPR 实现了约 4.6 倍生成加速(右侧柱状图)。

NPR 具体实现细节
NPR 训练范式
Stage 1:Format-following Reinforcement Learning(NPR-ZERO)
- 目标:在无任何外部并行示例 / 教师情况下,让模型学会生成结构化的并行格式(如 <guideline>、<plan>、<step>、<takeaway> 等结构化标签),并尽量保证答案正确性。
- 方法:以格式合规与答案正确为奖励信号,对初始指令微调模型进行 DAPO 风格的强化学习,从而得到能产出并行格式轨迹的生成器(NPR-ZERO)。这一步为后续自蒸馏提供原始候选轨迹。
Stage 2:Rejection Sampling + Parallel Warmup(NPR-BETA)
- 目标:把 Stage 1 的 “格式化产物” 变为高质量的训练数据并让模型在并行语义上稳定。
- 方法:对 NPR-ZERO 进行拒绝采样并应用严格的筛选器(必须同时满足「格式合规」与「答案正确」),保留自蒸馏的并行推理轨迹,然后在此之上做冷启动的并行 SFT 预热微调,同时引入并行注意力掩码(Parallel Attention Mask)与并行位置编码(Parallel Positional Encoding),让模型内部能够支持并行分支的独立计算(并实现 KV Cache 重用以避免重复计算)。
Stage 3:Native-Parallel RL(PAPO)
- 目标:在并行执行引擎上用强化学习直接优化并行分支策略,使其不仅会「写」并行格式,也会「算」并行结果。
- 方法:提出并实现 Parallel-Aware Policy Optimization (PAPO) —— 对并行语义做专门修改的策略优化方法:使用并行 Rollout 的 NPR-Engine 推理引擎以保证结构正确性、在批次层级进行优势归一化、保留特殊结构化 Token 的梯度并放弃重要性采样以维持稳定的 On-Policy 同策略梯度更新。PAPO 能直接在并行计算图内优化分支策略,从不断地试错中学会有效的问题拆解与合并策略。

关键技术细节
1. 自蒸馏与严格筛选(Rejection Sampling)
从 NPR-ZERO 生成大量并行格式的候选轨迹后,采用两条硬性筛选规则只保留高质量样本进入 D_accept:
- Outcome Correctness:模型生成的候选轨迹的解析答案与 Ground Truth 一致。
- Structured Parallelism:输出严格遵循并行格式的 Schema(标签、块边界等)。
当且仅当同时满足以上两条规则的采样轨迹被接受用于冷启动并行 SFT(NPR-BETA),此策略显著减少噪声并保证训练语料的并行性与可学习性。
2. 并行注意力掩码与并行位置编码
为在单次前向传递中同时存在多条 Reasoning Path,NPR 采用 Multiverse 风格的并行注意力掩码与专门设计的并行位置编码(对应论文给出的 Algorithm 2 伪代码),保证不同分支互相隔离但共享上下文 KV Cache,从而实现 KV Cache 重用并避免每条分支重复计算上下文代价。该编码亦允许通过标签 Token 标明分支 / 步骤 / 指南块,便于引擎解析。
3. Parallel-Aware Policy Optimization(PAPO)
并行语义下直接套用经典 PPO 或 DAPO 会遇到特殊 Token 被剪裁掉、重要性采样不稳定等问题。PAPO 的主要设计包括:
- 并行 Rollout:使用 NPR-Engine 产生严格遵守并行 Schema 的轨迹,保证样本合法。
- 结构化过滤:格式违规样本在进入优化前被剔除,奖励退化为纯准确性(+1 / −1)。
- 批次级优势归一化(Batch-level Normalization):由于格式违规样本被移除,组内方差塌缩,因此用更大范围(batch 内多组)统计标准差来稳定优势估计。
- 保留特殊 Token 的梯度 & 放弃重要性采样:为防止触发并行结构的特殊标签被裁剪掉,PAPO 在 Token 级别保留梯度流;同时放弃重要性采样,采用严格的 On-policy Objective,避免重采样比带来的不稳定。

4. AI Infra 工程化改进:NPR-Engine
实验证明:把并行语义放到生产环境的并行 RL,会暴露出大量的工程问题(KV Cache 重复释放导致的内存泄漏、并行 Token 计数导致的超长生成、非法并行 schema 导致的未定义状态等)。论文在引擎层面做了几项关键修复:
- 预算感知的 KV 回收:避免 Radix-Tree KV 路径的 Opportunistic Recycling 导致 Double-Free,引入预算感知的确定性回收机制与 Memory Flush 策略。
- 分支感知的 Token 累积策略:把全局 Token 预算从 “只看最长分支” 改为 “按活跃分支因子累计”,避免超出 max_new_tokens。
- 格式预检与轻量不变性:在分支展开前加一层格式合法性检查,快速拒绝潜在非法分支以保证 Determinism。
这些工程改进和实现是确保能稳定 Parallel RL 的训练,进而获得并行思考智能体的前提。
主要实验与结论
评测基准与度量
在 8 个推理型基准上评测:AIME24/25、HMMT25、OlympiadBench、Minerva-Math、ZebraLogic、AMC23、MATH500 等。对小规模竞赛类数据使用 avg@8(采样 8 条解答的平均正确率),对大规模或单答设置使用 avg@1。
训练数据优势:性能提升的关键在于用自行提炼的数据集(NPR-BETA 的 ORZ-8k)替换了 Multiverse 的训练语料库(MV-4B 的 s1.1-8k)。尽管两个流程在实现细节上略有不同,但都依赖于并行式的 SFT,因此比较结果具有意义。数据替换的影响清晰且一致:AIME24 的性能从 46.7 提升至 50.8(+4.1),ZebraLogic 从 60.2 提升至 76.1(+15.9),AMC23 从 75.0 提升至 85.9(+10.9),MATH500 从 81.6 提升至 91.6(+10.0)。总体而言,平均得分从 50.1 提升至 59.0(+8.9)。
并行 SFT 的优势:从顺序 SFT(例如 SR-BETA)切换到并行 SFT 方法(NPR-BETA)能够显著提升各种推理基准测试的性能。顺序 SFT 引入了较强的步骤依赖性先验,限制了任务分解的灵活性。相比之下,并行 SFT 在训练过程中使模型能够接触到结构上并行的轨迹,从而实现更独立的子问题探索。具体而言,AIME25 从 37.1 提升至 42.9 (+5.8),OlympiadBench 从 56.3 提升至 60.1 (+3.8),HMMT25 从 22.5 提升至 23.3 (+0.8),ZebraLogic 从 72.8 提升至 76.1 (+3.3)。整体性能从 58.2 提升至 59.0 (+0.8),仅在少数基准测试中出现轻微退步。
并行强化学习优势:基于 NPR-BETA,应用并行强化学习算法可获得进一步的性能提升,并始终优于顺序强化学习(NPR 与 SR 相比)。这些改进是广泛而系统的:AIME24 从 57.1 提升至 63.3(+6.2),HMMT25 从 26.3 提升至 30.8(+4.5),Minerva-Math 从 38.2 提升至 43.0(+4.8)。其他基准测试也显示出稳步提升,AIME25(+1.2)、OlympiadBench(+1.5)、ZebraLogic(+2.8)、AMC23(+2.2)和 MATH500(+0.8)。总体而言,平均得分从 62.0 提升至 65.0(+3.0)。

Multiverse-32B 在不同数据集上的并行率差异显著,表明其并行推理的采用高度依赖于数据集。尤其是在 ZebraLogic 等逻辑密集型任务上,其性能明显低于多个数学竞赛数据集,这表明从顺序行为逐步过渡到并行行为的 Multiverse 训练范式,导致并行策略的内化不一致,并且对领域特征非常敏感。相比之下,NPR 模型在所有八个数据集上均达到了 100.0% 的并行触发率。这种一致性意味着端到端的 NPR 训练流程能够更可靠地将并行推理作为模型的默认问题解决模式,而不受数据集领域或复杂性的影响。实际上,这意味着 NPR 不仅能更频繁地触发并行推理,而且能够在不同的评估数据集上稳健地实现这一点。

NPR 在所有五个基准测试中均取得了最佳效率,始终优于 Multiverse(1.3 倍至 2.4 倍)和自回归基线,这表明该方法具有稳健的泛化能力。重要的是,加速比随任务难度而增加:NPR 在较难的问题(AIME25:4.6 倍;HMMT25:4.1 倍)上观察到的加速比在较容易的问题(AMC23:2.9 倍)上更大,这表明当需要更深入地探索解路径时,NPR 优势日益凸显。证明了 NPR 既能提高准确率,而且在可以并行探索多种解策略时尤其有效。

案例解析
论文给了若干具体题目的并行解法示例,典型模式为:
1. <guideline>:并行产生若干独立 plan(每个 plan 一句战术);
2. <step>:每个 plan 独立并行展开具体推理步骤;
3. <takeaway>:整合与交叉验证,得出最终结论并给出简短答案(boxed answer)。
举例:对于域函数或几何题,某些 plan 会分别做不同的分解(代数、数值检验、几何角度关系),最后 <takeaway> 将各分支结果比对、剔除不一致项并输出最终答案。这种「多角度并行 + 汇总」能显著减少因单一路径假设错导致的花费。


结语
本文提出了一种简单且可扩展的框架,用于构建原生并行推理器。该推理器无需依赖外部教师模型即可学习自适应分解、多样化的并行规划和可靠的聚合。通过将自提炼的并行 SFT 与智能体并行 RL 相结合,NPR 能够生成真正的并行推理策略,而非模拟或脚本化的策略。在八个推理基准测试上的实验表明,与 Multiverse 数据集、自回归训练和直接强化学习相比,该方法均有显著的改进。论文中的分析进一步证明了该方法能够显著加速推理、增强测试时的可扩展性,并且不存在伪并行行为。案例研究展示了该模型如何根据问题难度调整其并行性,从而实现结构化探索和稳健的验证。这些结果表明,原生并行推理是实现更通用、可扩展智能的一个有前景的方向。
...
#Virtually-Being
当视频生成真正「看清一个人」:多视角身份一致、真实光照与可控镜头的统一框架
第一作者徐源诚是 Netflix Eyeline 的研究科学家,专注于基础 AI 模型的研究与开发,涵盖多模态理解、推理、交互与生成,重点方向包括可控视频生成及其在影视制作中的应用。他于 2025 年获得美国马里兰大学帕克分校博士学位。
最后作者于宁是 Netflix Eyeline 资深研究科学家,带领视频生成 AI 在影视制作中的研发。他曾就职于 Salesforce、NVIDIA 及 Adobe,获马里兰大学与马普所联合博士学位。他多次入围高通奖学金、CSAW 欧洲最佳论文,并获亚马逊 Twitch 奖学金、微软小学者奖学金,以及 SPIE 最佳学生论文。他担任 CVPR、ICCV、ECCV、NeurIPS、ICML、ICLR 等顶会的领域主席,以及 TMLR 的执行编辑。
在电影与虚拟制作中,「看清一个人」从来不是看清某一帧。导演通过镜头运动与光线变化,让观众在不同视角、不同光照条件下逐步建立对一个角色的完整认知。然而,在当前大量 customizing video generation model 的研究中,这个最基本的事实,却往往被忽视。
- 论文地址: https://arxiv.org/pdf/2510.14179
- 项目主页: https://eyeline-labs.github.io/Virtually-Being/
被忽视的核心问题:Multi-view Identity Preservation

多视角身份一致、镜头环绕与多人物示例
近年来,视频生成领域中关于人物定制(customization)的研究迅速发展。绝大多数方法遵循一种相似范式:给定一张或少量人物图像 → 生成包含该人物的视频。这种范式隐含了一个关键假设:只要人物在某个视角下看起来像,就等价于「身份被保留」。但在真实的视频与电影语境中,这个假设并不成立。
为什么单视角身份是不够的?
- 身份是强烈依赖视角的(view-dependent)
面部轮廓、五官比例、体态与衣物形态,都会随观察角度发生系统性变化。
- 相机运动会持续暴露未见过的外观区域
单张或少量图像无法覆盖侧脸、背面以及连续视角变化过程中的外观一致性。
- 多人场景会放大任何身份错误
当多个角色同框时,哪怕轻微的身份漂移都会变得非常明显。
因此,在具有真实 3D 相机运动的视频中,「identity preservation」本质上是一个 multi-view consistency 问题,而不是单帧相似度问题。
然而,令人遗憾的是,显式关注 multi-view identity preservation,在当前的视频定制化生成研究中仍然几乎没有被系统性地解决。
核心立场:学习一个人的身份,必须学习他在多视角与多光照下的样子
Virtually Being 的核心论点非常明确:如果希望模型真正「学会一个人的身份」,那么它必须看到这个人在不同视角(multi-view)和不同光照(various lighting)下的稳定外观。
换句话说,看清一个人,不是看清一张脸,而是理解这个人在空间中如何被观察,在光线变化下如何呈现。身份不是一个静态的 2D 属性,而是一个 4D(空间 + 时间)一致的概念,这正是 Virtually Being 所要系统性解决的问题。
方法概览:用 4D 重建构建真正的多视角身份监督
为了解决 multi-view identity 被长期忽视的问题,我们从数据层面重新设计了人物定制流程。
多视角表演采集,而非单视角参考
- 使用专业体积捕捉系统采集真实人物表演:75 相机面部捕捉阵列、160 相机全身捕捉阵列;
- 捕捉人物在受控条件下的动态表演,为高质量重建提供输入。
4D Gaussian Splatting 作为数据生成器
- 对捕捉到的表演进行 4D Gaussian Splatting (4DGS) 重建;
- 在重建结果上渲染大量视频:覆盖连续变化的相机轨迹、具备精确的 3D 相机参数标注、保证同一人物在不同视角下的身份一致性。
通过这一过程,视频生成模型在训练阶段不再依赖零散的图像线索,而是反复观察同一个人在多视角、连续镜头运动下应当如何保持外观一致。
两阶段训练:先理解镜头,再理解「这个人」
为了在身份定制的同时保持稳定的镜头控制能力,我们采用了一个清晰解耦的两阶段训练策略。
阶段一:相机感知预训练(Camera-aware Pretraining)
基于 ControlNet 架构,引入完整 3D 相机参数(Plücker 表示),在大规模公开视频数据上训练模型,使其学会相机运动如何影响视角变化与时间结构。这一阶段的目标,是让模型牢固掌握电影级的镜头语言。
阶段二:多视角身份定制(Multi-view Customization)
在预训练模型基础上进行微调,使用 4DGS 渲染的多视角视频作为定制数据,为每个身份引入专属 token,将身份与多视角外观显式绑定,最终模型在推理时能够精确遵循输入的 3D 相机轨迹,在未见过的视角下仍然稳定呈现同一个人。

光照真实感:身份感知不可分割的一部分
除了视角,光照同样是「看清一个人」的关键维度。
在真实电影中,人物身份并不是在单一光照条件下被认知的,而是在不同室内外环境,侧光、逆光、柔光等变化,不同光比与色温条件下逐步被观众确认。
在 Virtually Being 中,我们通过引入基于 HDR 的视频重打光数据,显著增强了生成视频中的光照真实感。在 4DGS 渲染基础上,对同一人物生成多种自然光照条件,覆盖真实拍摄中常见的照明变化范围,使模型学会在光照变化下,人物身份仍应保持稳定。
实验结果显示,引入重光照数据后,生成视频在用户研究中 83.9% 被认为光照更自然、更符合真实拍摄效果,缺乏该数据时,人物往往呈现平坦、缺乏层次的合成感。
多人物生成:multi-view identity 才能支撑真实互动
在多人物视频生成中,multi-view identity preservation 的重要性进一步被放大。
只有当模型对每个角色在不同视角与光照条件下的身份都有稳定建模时,人物才能自然同框,空间关系才能保持一致,互动才不会显得拼接或混乱。
Virtually Being 支持两种多人物生成方式:
- 联合训练(Joint Training):通过少量同框数据增强互动真实性;
- 推理阶段组合(Noise Blending):在无需重新训练的情况下灵活组合多个身份。

实验结论:multi-view + relighting 是身份一致性的关键因素
系统性实验表明,使用 multi-view 数据训练的模型,在 AdaFace 等身份指标上显著优于仅使用 frontal-view 数据的模型以及其他 video customization 的方法。缺失 multi-view 或 relighting 数据,都会导致身份一致性与真实感明显下降。用户研究结果同样明确偏好具备 multi-view 身份稳定性的生成结果。


总结:重新定义视频生成中的「身份」
Virtually Being 并不仅仅提出了一个新框架,而是明确提出并验证了一个长期被忽视的观点:在视频生成中,身份不是一张图像,而是一个人在多视角与多光照条件下保持稳定的 4D 表现。通过系统性地引入 multi-view 表演数据与真实光照变化,我们为 customizing video generation model 提供了一条更贴近电影制作实际需求的解决路径。
...
#马斯克圣诞礼物
X上所有图片都能一键AI改图了,全球画师暴怒
这可能是 AI 画图的分水岭事件。
昨天,埃隆・马斯克端上了为大家准备的圣诞礼物:
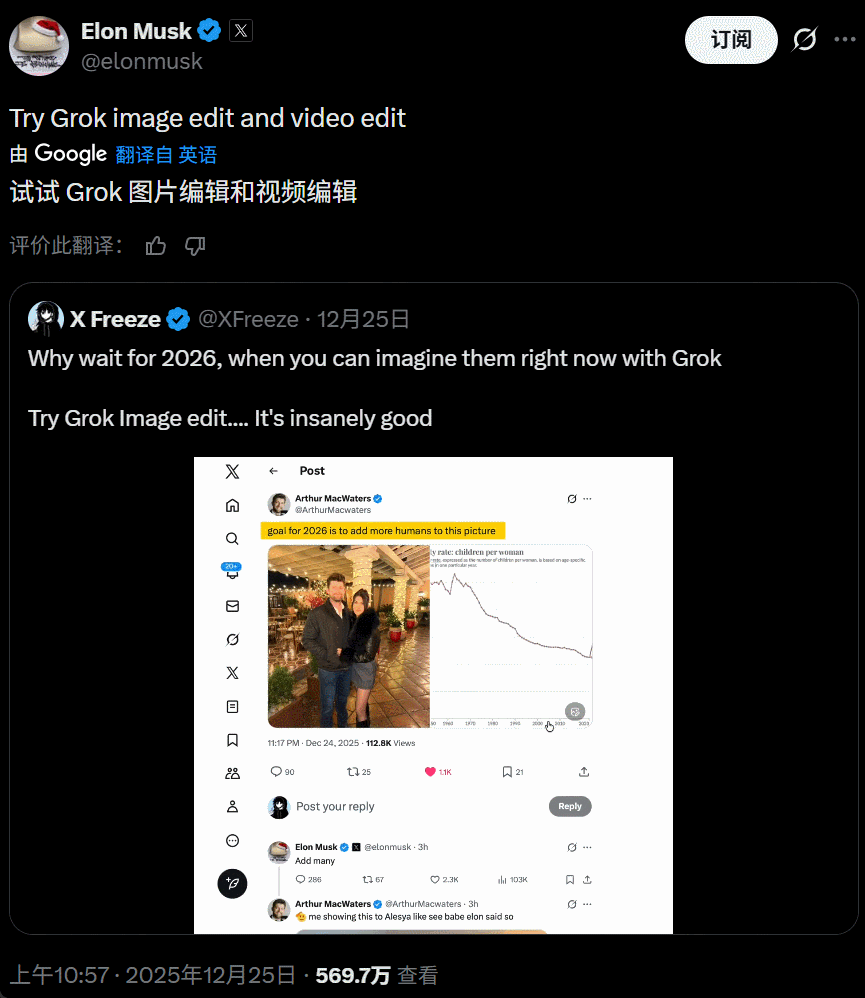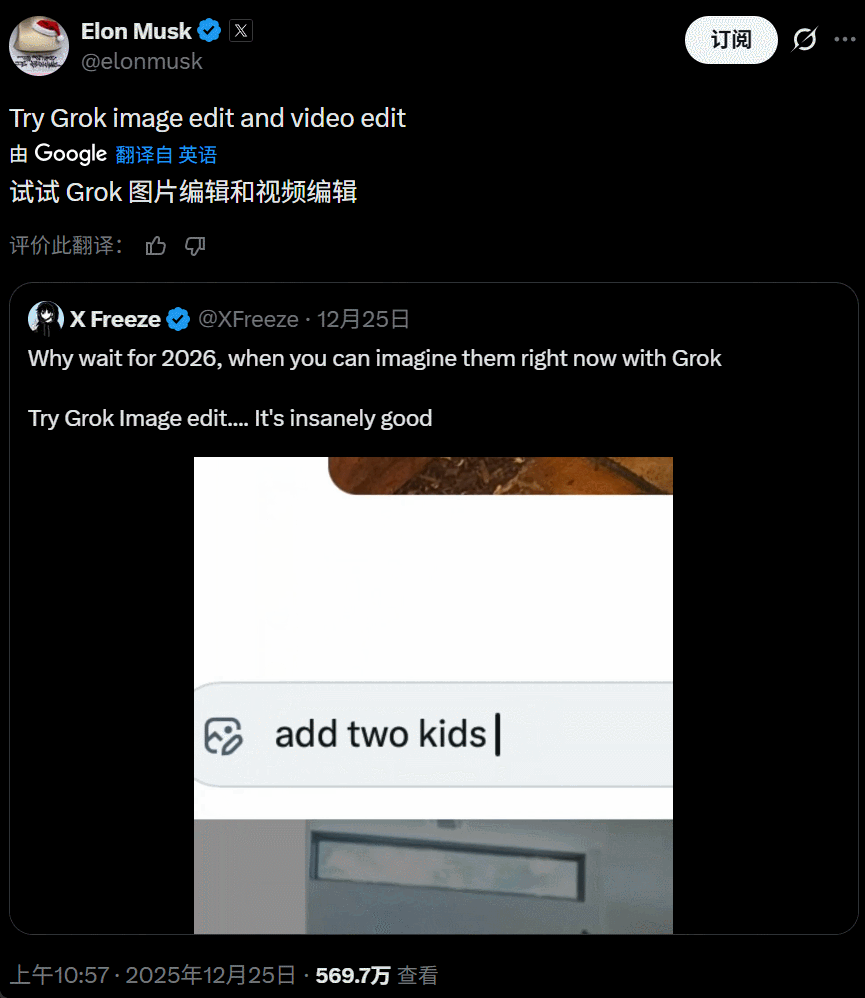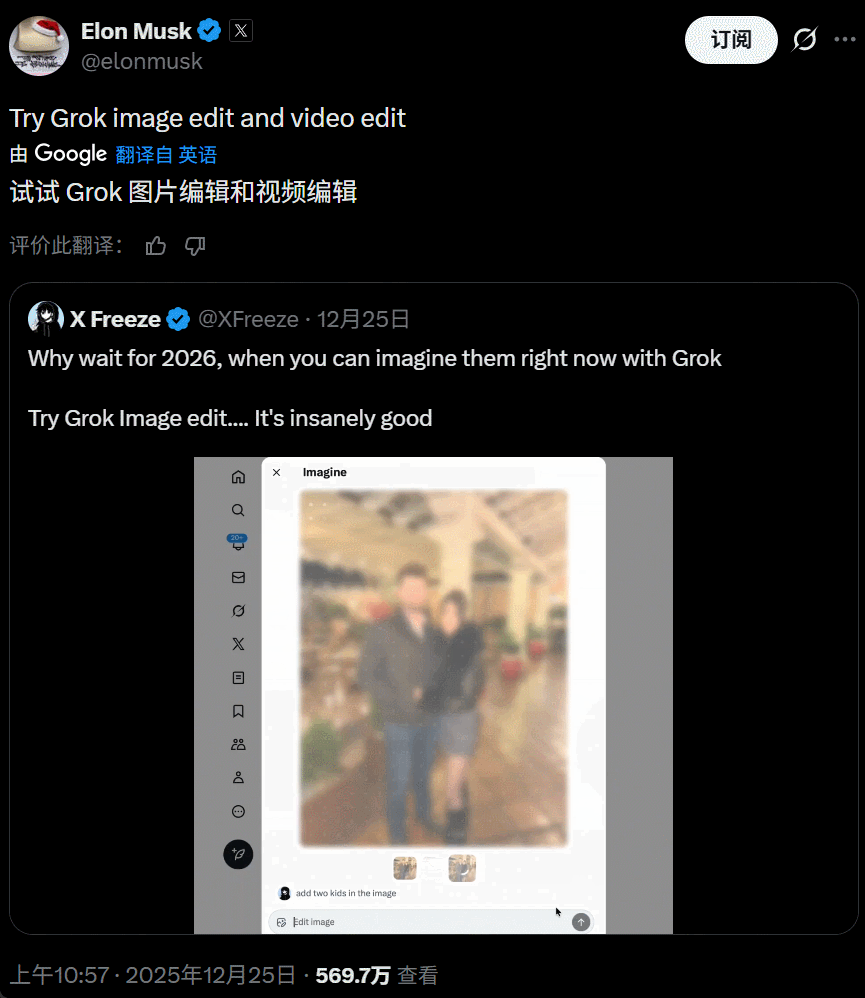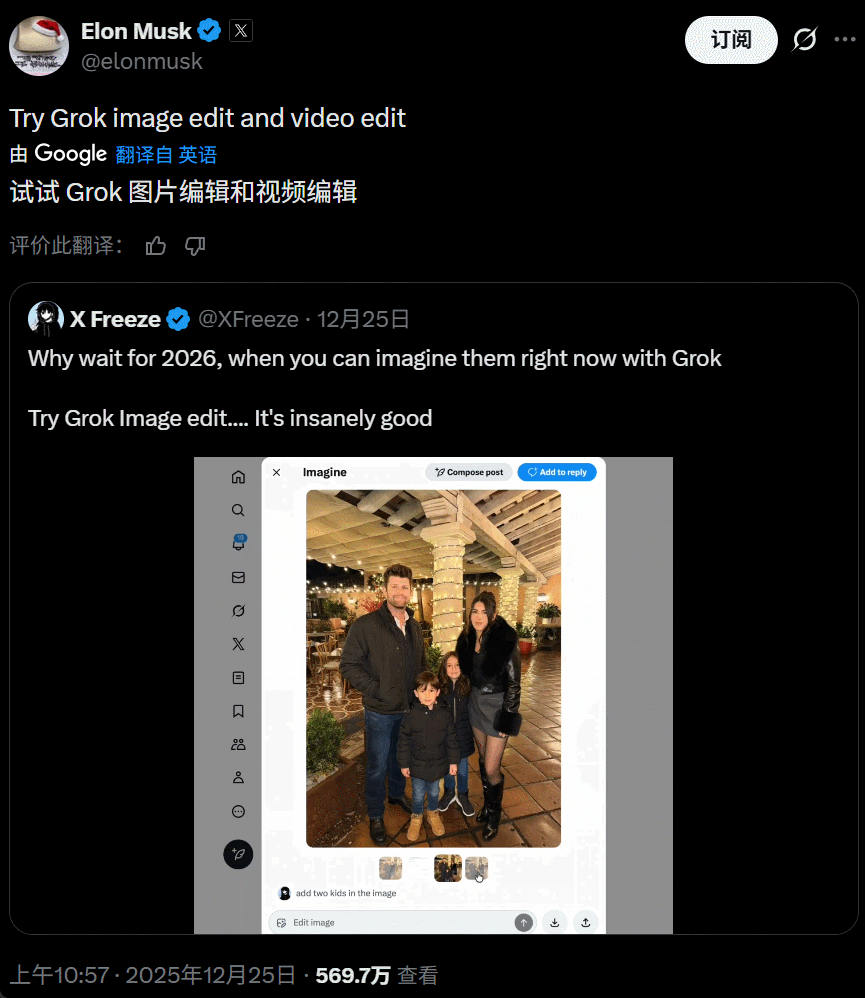
这次更新的重点在于「全场域编辑能力」,X 平台上的所有图片现在都新增了「编辑图片」选项,接入了 Grok AI 模型。与传统的 AI 编辑工具(如 Photoshop 的 AI 填充)不同,现在你在推特上看到任何一张图(包括别人发的图片),直接原地输入你的想法,想怎么 P 就怎么 P。
Grok 提供图转视频的能力,也可以把一个静态图转换成为 6-15 秒的视频。AI 会自动判断动作逻辑,如让人物眨眼、让背景的树叶摆动等等,并自动匹配音效。
该选项目前似乎适用于所有账号,也没有电影 IP 的限制。新的整活工具上线,大量用户立即开始了「创作」。比如这样的图片:

底下的回复就是各种改图:


大家玩得不亦乐乎,对于 P 图效果也多有称赞。
Grok 这一系列能力的跃升,要仰赖 xAI 团队在今年的多模态模型技术进步。当然,十万卡 H100 GPU 的 Colossus AI 超算集群也功不可没,否则也供不起全网上亿的用户在线 P 图。这可能也标志着 X 平台从「内容分享平台」开始向「生成式创作平台」转型了。
不过对于那些以作画为生的创作者来说,马斯克发布的新功能,就像一个噩耗。毕竟你辛苦画出来的作品,发到 X 上之后,底下可能就是一串 AI 改图的回应。这怎能不让人破防。




人们发现,使用 Grok 的 AI 功能修图,可以轻松地去除水印,删除作者签名,再重新发出来你就是「原作者」了。而且似乎没有让人可以禁用 AI 修图的设置选项。
有人建议在 X 设置区的隐私选项里关闭 AI 权限,但这些建议都没有明确提及 AI 图像编辑。Grok 官方也表示,目前没有办法禁用这项新功能。
新版 Grok 图像编辑功能推出后,X 平台已经更新了服务条款,其中有一项条款允许 X 和其他人使用发布到网站上的内容 —— 包括用于机器学习。
抗议的人中也包括一些有名的画师,比如《石纪元》的作者 Boichi,他表示,虽然他很喜欢 X 平台,因为这个活跃的平台能让他与粉丝互动,但他不能在未经他同意或未获得报酬的情况下,将自己的作品发布到该平台上,并允许他人使用、学习或利用这些作品。

也有人建议,上传图片而使其不可编辑的一种方法是将其保存为 GIF 而不是 JPG,尽管这会导致图像质量下降。
最后,有看热闹不嫌事大的人认为,X 选择在圣诞假期期间推出该功能,是为了在收到停止侵权通知函之前,先观察几天人们的使用情况。
大型实验了属于是。
马斯克这次整的大活会以什么样的形式收场?让我们拭目以待。
...
#DreaMontage
挑战“一镜到底”!字节跳动 DreaMontage 三大神技,让视频过渡丝滑如梦
大家好,今天想和大家聊一个非常酷的技术——来自字节跳动智能创作团队的新作 DreaMontage。
电影界的“一镜到底”(One-Shot)堪称一种炫技,它对导演、演员和整个制作团队的要求极高,成本不菲。但那种沉浸式的、不间断的视觉体验,确实让人着迷。现在,AI 视频生成技术这么火,我们能不能用它来低成本地实现这种艺术效果呢?
之前的很多模型,思路很直接:生成几个短片,然后拼起来。结果往往是灾难性的,画面跳变、动作不连贯,一眼就能看出是“缝合怪”。
而 DreaMontage 走了一条完全不同的路。它的名字也很有意思,是 "Dream"(梦境)和 "Montage"(蒙太奇)的结合,寓意着将梦幻般的、零散的视觉片段,无缝地融合成一个连贯的整体。它要解决的,正是在视频的任意时间点,根据你给定的参考画面(可以是图片或视频),生成一段丝滑流畅、富有表现力的长镜头。
- 论文标题: DreaMontage: Arbitrary Frame-Guided One-Shot Video Generation
- 研究机构: 字节跳动-智能创作团队
- 论文地址: https://arxiv.org/abs/2512.21252
- 项目主页: https://dreamontage.github.io/DreaMontage/
,时长01:00
缘起:为何我们需要“任意帧”引导?
想象一下,你想制作一个视频:一个人从雪山滑雪,镜头无缝切换到他在海里冲浪。
如果用传统的文生视频模型,你可能需要生成两段视频再拼接,但过渡会很生硬。如果用图生视频,你也只能控制开头或结尾,中间的“雪变海”过程完全不可控。
这就是 DreaMontage 要解决的痛点。它允许你像导演一样,在时间线的任意位置“打点”,告诉模型:“在第 3 秒,画面必须是这张滑雪图;在第 8 秒,必须是这张冲浪图。”然后,模型会自动脑补出从滑雪到冲浪的炫酷转场,生成一个完整、连贯的长镜头。
为了实现这个目标,DreaMontage 从三个层面进行了技术攻坚。
上图就是 DreaMontage 的整体框架,左边是训练流程,右边是推理流程。我们可以看到一个清晰的多阶段优化路径。
方法详解:三大核心技术揭秘
1. 任意帧控制:Interm-Cond Adaptation
要在任意位置插入条件帧,首先要解决一个技术难题。现在的视频 VAE(变分自编码器)在编码时,为了效率,会进行时间上的降采样。这就导致一个问题:一个中间帧的 latent(潜在表示)其实混合了它周围好几帧的信息,定位不准(如下图a所示)。
DreaMontage 提出了一种自适应微调 (Adaptive Tuning) 策略来解决这个问题:
- 单图与视频条件处理:在训练时,模型会“模拟”推理过程。对于单图条件,强制用单图模式重新编码以获得精确 latent;对于视频片段条件,则从 latent 中随机提取片段,并对首帧进行重编码,确保模型既能理解静态画面,也能理解动态片段作为约束。
- 超分阶段的 Shared-RoPE:这是本文的一个核心创新。研究人员发现,在超分(Super-Resolution)阶段,简单的通道拼接会导致画面闪烁和颜色偏移,原因是低分辩率 latent 和高清条件图之间存在微小差异。
为此,他们设计了 Shared-RoPE(共享旋转位置编码) 策略:强制让条件帧与生成帧共享相同的位置编码。这就像给画面定了一个“锚点”,消除了对齐误差,极大地提升了画面的稳定性。
2. 提升视觉表现力:定制化DPO (Tailored DPO)
解决了“能不能”的问题,接下来要解决“好不好”的问题。为了让视频过渡更自然、动作更合理,DreaMontage 用了两个大杀器:视觉表现力SFT (Visual Expression SFT) 和 定制化DPO (Tailored DPO) 。
SFT大家比较熟悉,就是在一个高质量数据集上进行微调,让模型学会更电影化的表达。
而这里的DPO则非常有针对性。团队发现,生成视频最常翻车的点有两个:画面突变 (Abrupt Cuts) 和 主体运动不合理 (Subject Motion) 。
为了解决这两个问题,他们构建了专门的“偏好数据集”来训练DPO:
- 针对画面突变:他们先训练了一个VLM(视觉语言模型)来当“裁判”,这个裁判专门负责给视频的“断裂感”打分。然后,用这个裁判去海量生成的视频中,自动挑出“过渡流畅的”作为正面教材(win),“转场生硬的”作为反面教材(lose)。
- 针对运动不合理:对于人物、车辆等常见主体的跳跃、转身等动作,通过人工筛选的方式,找出那些出现“太空步”、肢体扭曲等诡异动作的失败案例,构成偏好对。
通过这种“缺啥补啥”的DPO训练,模型被校准得更懂物理规律和镜头语言,生成的内容质量大幅提升。
3. 长视频生成:推理阶段的分段自回归 (SAR)
要生成几分钟的长视频,一次性生成所有帧显存会爆炸。DreaMontage 设计了专门用于 Inference (推理) 阶段的 分段自回归 (Segment-wise Auto-Regressive, SAR) 策略。
简单来说,就是把一个长视频任务切成好几个小片段,像接力赛一样逐段生成。生成第二段时,会把第一段的结尾几帧作为“引子”和条件,确保两段之间在像素级别上完美衔接。这个过程完全在 latent 空间进行,比在像素层面拼接要平滑得多。
实验与结果:效果到底怎么样?
口说无凭,我们来看数据。
首先,DreaMontage 完成了其他模型很难做到的“任意帧引导”生成。比如下面的多关键帧引导案例,模型根据文本提示和在不同时间点插入的图像,生成了一个连贯的视觉故事。
在与业界顶尖模型的对比中,DreaMontage 也表现出色。研究团队采用 GSB (Group-wise Superiority-inferiority Battle) 评分,也就是让用户盲评。
- 对战 Vidu Q2 (多关键帧模式) :DreaMontage 的总体偏好度得分高出 +15.79%,尤其在提示词遵循 (Prompt Following) 方面,优势巨大(+23.68%)。
- 对战 Kling 2.5 (首尾帧模式) :
- 视觉质量 (Visual Quality) :双方打成平手 (0.00%)。这说明在画质细腻程度上,DreaMontage 已经达到了与顶尖商业模型持平的水准。
- 优势项目:但在 运动效果 (+4.64%) 和 提示词遵循 (+4.64%) 上,DreaMontage 依然胜出,证明其更擅长处理复杂的动态叙事。
消融实验进一步验证了每个模块的巨大作用:
- SFT 让模型运动效果大幅提升 +24.58%。
- Shared-RoPE 策略最为惊人,直接让视觉质量的偏好度暴涨 +53.55%,极大地消除了超分阶段的伪影。
不是研究项目,而是上线产品
值得一提的是,DreaMontage已经给出了在剪映海外版上试玩的链接:
https://dreamina.capcut.com/ai-tool/home?type=video
...
#冷静看待VLA
不是救世主,也不是“垃圾”~
昨晚睡前刷到一篇批判VLA的帖子,说“有些搞VLA公司又懒又蠢... (此处省略2000个字)”,全篇非常犀利,我整理了下弗雷哥 (答主) 说的几个槽点:
- 任务设置太简单,几乎全是“抓—放”
- 纯色背景,只放1~2个物体,没遮挡,且大部分是2D平面任务
- 数据量巨大,本质上是“升级版Behavior Cloning”
- 系统黑盒,无法解释模型到底能干啥
肯定不能全盘否定VLA。
它并不完全是黑盒,最近NVIDIA有个工作CoT-VLA,就主要展示了VLA思维链并拆分为三层:
- LLM拆语言指令为子任务
- VLM根据当前图像+子任务生成subgoal embedding
- Policy模型根据subgoal embedding+当前感知输出action
和人的思考模式真挺像的。
真正的挑战在于让模型学会泛化。
在遮挡/复杂背景/3D空间中的表现,关键是要把subgoal embedding设计好来保证泛化性。要保证subgoal embedding具有:
- 语义
- 上下文相关,不同任务表征不同
- 指明目标大致在哪个区域
- 融合MLP的话保证可微
例如用cross-attention: 任务文本token attend到图像patch token,上面4条都能保证,可能效果就不错。
说不定,learning方法在复杂环境下反而更有优势。
相比传统方法依赖精确坐标/遮挡判断 (极易误判),learning的方法更偏向视觉观测感知误差+修正action不断逼近目标,不需要每一步都遵循完美路线,这其实更接近人类的行为方式。
额外空间状态的输入可能还是需要的,毕竟目前很多论文中的任务过于简单:控制是局部的,动作空间是受限的,环境静态且无遮挡。这应该就是模型仅依赖“视觉误差或图像反馈”即可完成任务的原因吧。
我也不太相信纯end-to-end能训出真正的通用AGI。
AGI需要的是one/few-shot的学习能力,甚至可以靠推理和逻辑去“猜”怎么做新任务。而end-to-end更像是那种看几千遍才会的死记硬背流派。
我倾向于显式的按照VLA思维链去做:大模型只负责拆任务,action head根据subgoal来训练与执行。这种方法训练量小且结构清晰,即便是资源有限的普通学生也有能力完成训练。只要任务拆得够细且准,不管后面用的是model-based还是learning-based policy,效果都会不错。 (前几天刚和组里学弟讨论过这点,被强化了认知/手动 @Siqi)
弗雷哥说“VLA,大部分人,精挑细选,最简单的场景,最简单的任务,最2D的2D,加上demo拍摄者,总挑细选角度和拍摄的demo”
最后,我对这种研究态度和实验内容的评价是:劣币驱逐良币。
历史会记住创造者,也会见证虚伪的信徒。
...
#TurboDiffusion
视频生成DeepSeek时刻!清华&生数开源框架提速200倍,一周斩获2k Star
在 2025 年的最后时刻,一个全新视频生成加速框架的开源宣告了:「等待数分钟才能生成一个视频」的时代已经终结!
这个框架正是清华大学 TSAIL 团队与生数科技联合发布的 TurboDiffusion。
加速效果有多夸张呢?在几乎不影响生成质量的前提下,主流视频生成模型在单张 RTX 5090 上生成 5 秒 720p 视频的速度可以提升约 200 倍,同时一个 5 秒 480p 视频的生成时长可以被压缩到不到 2 秒(如下动图)。

这意味着,AI 视频创作进一步突破了传统的「渲染与等待」模式,来到了向「实时生成」时代转变的关键节点。这项突破迅速引起了学界的广泛关注。



TurboDiffusion 无异于抛下了一颗「重磅炸弹」,击破了扩散模型生成高质量视频所面临的主要壁垒 —— 高推理延迟。由于模型在生成高分辨率视频时需要处理大量时空信息并捕捉视频帧之间的细节与动态变化,这就需要处理海量的 token,导致推理耗时严重。
以往,主流扩散模型往往需要几分钟甚至几十分钟才能生成几秒的高质量视频,较高的时间延迟极大地限制了模型的实际可用性。而现在,随着加速框架 TurboDiffusion 的开源,视频生成的等待时间大大缩短,更能满足实时生成的需求。
目前,TurboDiffusion 在 GitHub 上已经收获 2k Star,社区关注度持续提升。

项目地址:https://github.com/thu-ml/TurboDiffusion
现在,用户可以体验 TurboDiffusion 支持下的高效文生视频、图生视频的模型版本。

这不禁令我们好奇,TurboDiffusion 究竟采用了哪些技术手段,才能实现视频生成推理速度的百倍提升?
TurboDiffusion:扩散模型视频加速的更优解
通过放出的 TurboDiffusion 技术报告,我们对其采用的训推及优化策略有了更多的了解。
- GitHub:https://github.com/thu-ml/TurboDiffusion
- 技术报告:https://jt-zhang.github.io/files/TurboDiffusion_Technical_Report.pdf
作为一项复杂的工程性任务,扩散模型在视频生成加速上面临的核心难点是如何既能保持生成质量,又能系统性地完成减少计算量、加速推理并保证不同模态协同一致性等多个目标。
这些挑战涉及到了架构设计、硬件适配、策略优化等多个方面,需要在算法和系统协同的基础上进行有的放矢的精细化处理。
TurboDiffusion 通过一系列创新技术,成功克服了传统 AI 视频在生成效率方面的主要瓶颈。
其中,在推理阶段采用的混合注意力加速、高效步数蒸馏以及 W8A8 线性层量化等「四大核心技术」,成为视频生成百倍加速的关键驱动力,它们均由清华大学 TSAIL 团队联合生数科技自主研发。
首先是混合注意力加速(Attention Acceleration),包括两项正交的注意力加速技术,即 SageAttention 和 Sparse-Linear Attention(SLA)。
其中使用 SageAttention 进行低比特量化注意力加速。它是一系列通过量化实现高效注意力机制的工作,自 2024 年 10 月以来陆续推出了 V1、V2 和 V3,能够在无损准确率的情况下,在大多数 GPU 上实现即插即用的加速效果。
这里,TurboDiffusion 使用的是「SageAttention2++」变体。
项目地址:https://github.com/thu-ml/SageAttention
同时,TurboDiffusion 使用 Sparse-Linear Attention(SLA)实现稀疏注意力加速。作为一种可训练的注意力方法,SLA 结合使用稀疏注意力和线性注意力来加速扩散模型的计算过程。

SLA 架构示意图,图左展示了高层次思路,注意力权重被分为三类,并分配给不同复杂度的计算;图右展示了使用预测的压缩注意力权重的 SLA 前向算法。图源:https://github.com/thu-ml/SLA
不仅如此,由于稀疏计算与低比特 Tensor Core 加速是正交的,SLA 可以构建在 SageAttention 之上,两者的共同作用在推理过程中进一步获得了数倍的额外加速。
接下来是高效步数蒸馏(Step Distillation),具体表现为引入了 rCM 蒸馏方法。
rCM 通过引入分数正则化和连续时间一致性的概念,优化扩散模型生成视频的时间步长,从而以更少的采样步数完成生成任务,比如将采样步数从原本的 100 步大幅减少到极小值(3 到 4 步),并能保持最佳视频质量。

使用蒸馏后的 Wan2.1 T2V 14B 生成的 5 个随机视频,生成过程中采用了 4 步采样。图源:https://github.com/NVlabs/rcm
最后是 W8A8 线性层量化(Linear Layer Quantization)。
TurboDiffusion 对线性层的参数(模型权重)和激活值(Activations)进行 8-bit 量化,过程中在 128x128 的块粒度上进行分块量化。这种量化方式将模型大小压缩约一半,并利用 INT8 Tensor Cores 加速线性层计算。
得益于以上四项核心技术的协同作用,TurboDiffusion 的视频生成加速效果被提升到了前所未有的水平。加之训练阶段的并行训练策略,进一步平衡了推理效率和生成质量。
整体训练过程分为两部分并行进行:一是将预训练模型的全注意力替换为稀疏线性注意力(SLA)并进行微调, 减少注意力计算的复杂度,降低计算资源消耗;二是使用 rCM 将预训练模型蒸馏为少步数学生模型,通过减少采样步数加速生成过程。最后将 SLA 微调和 rCM 训练的参数更新合并到一个单一模型中,进一步提升模型推理速度和生成质量。
此外,TurboDiffusion 还采用其他一些优化策略,比如使用 Triton 或 CUDA 重新实现 LayerNorm 和 RMSNorm 等操作,以获得更高的执行效率。

多项推理加速技术加持下,视频生成时长从 4767 秒降至 24 秒,提速近 200 倍。
这套技术组合拳验证了:在不牺牲视频表现力的前提下,扩散模型仍具备巨大的压缩与提速空间,为未来更大规模模型的实时部署提供了可借鉴的标准范式。
尤其是推理阶段的四项核心技术对 AI 多模态大模型的技术突破与产业落地具有里程碑式的价值与深远影响力。其中 SageAttention 更是全球首个实现注意力计算量化加速的技术方案,已被工业界大规模部署应用。
例如,SageAttention 已成功集成至 NVIDIA 推理引擎 Tensor RT,同时完成在华为昇腾、摩尔线程 S6000 等主流 GPU 平台的部署与落地。此外,腾讯混元、字节豆包、阿里 Tora、生数 Vidu、智谱清影、百度飞桨、昆仑万维、Google Veo3、商汤、vLLM 等国内外头部科技企业及团队,均已在核心产品中应用该技术,凭借其卓越性能创造了可观的经济效益。
单张消费级显卡,不到 2 秒生成高清视频
TurboDiffusion 在技术层面的领先性,为其在实战中的惊艳效果做好了铺垫。
先来看图生视频的加速效果。
我们以 14B 大小的模型生成 5 秒 720p 的视频为例,TurboDiffusion 可以在单张 RTX 5090 上实现几乎无损的端到端 119 倍加速。


基线模型与引入 TurboDiffusion 后的生成时长与效果对比。
文生视频的加速效果同样突出。
我们先以 1.3B 大小的模型生成 5 秒 480p 的视频为例,在单张消费级显卡 RTX 5090 上,使用官方实现需要 184 秒才能生成。引入 TurboDiffusion 之后,则只要 1.9 秒就能搞定。
两者相比,速度整整提升了 97 倍。


基线模型与引入已有加速方案(FastVideo)、TurboDiffusion 后的生成时长与效果对比。
对于 14B 大小的模型生成 5 秒 720p 的视频,TurboDiffusion 的加速效果更加显著。
从下图可以看到,在单张 RTX 5090 上生成时长从 4767 秒锐减到 24 秒,实现几乎无损的端到端 200 倍加速。


基线模型与引入已有加速方案(FastVideo)、TurboDiffusion 后的生成时长与效果对比。
在生数科技自研的 Vidu 模型上,TurboDiffusion 的加入也可以在不损失视频生成质量的前提下,获得极高的推理加速效果。
举例来说,在生成 8 秒 1080p 的视频时,相较于没有任何推理加速优化的方案,TurboDiffusion 将端到端的生成延迟从 900 秒提速到了 8 秒。如下视频 1 为加速前:
,时长00:08
视频 2 为 TurboDiffusion 加速后:
,时长00:08
加速前后,视频生成质量依然保持在较高水准。
写在最后
2025 年可谓是 AI 视频生成爆发的一年,从年初到年末,国内外头部大模型厂商「上新」的节奏一直没有停下。
这一年里,视频生成模型不仅在画质和时长上取得了突破,也在物理规律理解、音画同步生成等多个维度实现质的飞跃。
如今,TurboDiffusion 加速框架的引入,更开启了秒级生成与实时交互视频创作新范式的关键转折点。
一方面,高端视频创作能力从昂贵的 H100 等显卡下沉到个人创作者能负担起的消费级显卡,极大降低算力门槛。另一方面,随着视频生成从「离线等待」无限接近「实时预览」,创作者可以通过快速调整 prompt 获得即时反馈,提升了艺术探索的上限。
未来,包括 TurboDiffusion 在内的视频生成加速技术势必会更加成熟,我们可以想象更长时长的 1080p 甚至 4k 分辨率的视频同样可以做到实时生成。到那时,AI 视频直播、个性化视频流、AR/VR 实时内容渲染等需要即时反馈的应用场景有望更快更好地落地。
...
#SCOPE
Agent「记吃不记打」?华为诺亚&港中文发布SCOPE:Prompt自我进化,让HLE成功率翻倍
在 LLM Agent 领域,有一个常见的问题:Agent 明明 "看到了" 错误信息,却总是重蹈覆辙。
当 Agent 遇到工具调用错误时,错误日志里往往已经包含了解决方案 —— 正确的参数格式、有效的 API 用法、甚至是直接可用的替代方案。然而,静态的 Prompt 无法让 Agent 从这些反馈中 “学到教训”,导致它们陷入 “错误循环”:承认失败,却重复同样的动作。
华为诺亚方舟实验室与香港中文大学联合发布的 SCOPE 框架,旨在解决这一问题。
- 论文:《SCOPE: Prompt Evolution for Enhancing Agent Effectiveness》
- 论文地址:https://arxiv.org/abs/2512.15374
- 开源地址:https://github.com/JarvisPei/SCOPE
SCOPE 的核心思想是:既然 Agent 会被反复调用,那么它的 Prompt 就可以在执行过程中不断进化。通过从执行轨迹中自动提炼指导规则,SCOPE 让 Agent 能够 "从错误中学习",并将经验固化到 Prompt 中,实现自我进化。


Agent 的两大失败模式
研究团队分析了 GAIA 和 DeepSearch 基准上的 Agent 执行日志,发现了两类典型的失败模式:
第一类是「纠正型失败」(Corrective Failure):当错误发生时,执行轨迹中包含明确的信号(错误消息、堆栈跟踪、有效参数列表),本应指导 Agent 进行修正。然而,静态的 Agent 把这些信息当作泛泛的 “警报”,而不是可操作的反馈。研究者观察到大量案例,Agent 在错误消息明确列出正确用法的情况下仍然误用工具,形成 “错误循环”。更严重的情况下,Agent 甚至会为了继续执行而 “编造数据”。
第二类是「增强型失败」(Enhancement Failure):即使没有明显错误,Agent 也会错过优化机会。比如当搜索结果不理想时,上下文往往暗示可以尝试同义词(如 “base on balls” 与 “walks”),但 Agent 却固守单一关键词策略。这种失败更加隐蔽,但同样影响任务成功率。

这两类失败的根本原因是相同的:静态 Prompt 缺乏从执行反馈中学习的机制。
SCOPE 框架:从执行轨迹中学习

针对上述问题,SCOPE 将上下文管理从手动工程任务转变为自动优化过程。其核心洞察是:Agent 自身的执行轨迹就是最好的学习信号。
SCOPE 框架由四个核心组件构成:
1. 指导规则合成(Guideline Synthesis)
当 Agent 遇到错误或完成子任务时,SCOPE 的生成器(Generator)会分析执行轨迹,合成候选指导规则。这里采用 Best-of-N 策略:生成多个候选规则,然后由选择器(Selector)挑选最佳的一条。
针对不同场景,SCOPE 使用两种合成模式:纠正型合成从错误中提取教训,增强型合成从成功模式中挖掘优化机会。实验表明,增强型规则占所有合成规则的 61%,说明 SCOPE 不仅仅是 “错误修复器”,更是一个主动的优化器。
2. 双流路由机制(Dual-Stream Routing)
合成的规则并非同等对待。SCOPE 引入分类器(Classifier)将规则路由到两个记忆流:
- 战术记忆(Tactical Memory):存储任务特定的规则,如 “当前数据集的‘Amount’列包含货币符号,计算前需进行清洗”。这些规则仅在当前任务的数据上下文中有效。
- 战略记忆(Strategic Memory):存储跨任务通用的规则,如 “当 Web 搜索返回结果为空时,尝试泛化搜索关键词而不是重复搜索”。这些规则会持久化保存,应用于未来所有任务。
只有高置信度(阈值设为 0.85)的通用规则才会被提升到战略记忆,避免过拟合到特定任务。
3. 记忆优化(Memory Optimization)
随着规则积累,战略记忆可能包含冗余或冲突的内容。SCOPE 的优化器(Optimizer)会执行三步清理:冲突解决(合并矛盾规则)、冗余剪枝(移除被更通用规则覆盖的具体规则)、整合归并(将相似规则合并为综合性规则)。
4. 视角驱动探索(Perspective-Driven Exploration)
单一进化路径可能收敛到某种策略,在部分任务上表现较好但在其他任务上失效。为了提高策略覆盖,SCOPE 初始化多个并行流,每个流由不同的 "视角" 引导(如效率优先 vs. 周全优先),各自进化出不同的 Prompt。测试时选择最佳结果。
实验结果:HLE 成功率从 14% 提升到 39%
研究团队在三个基准上进行了评估:HLE(2500 道专家级问题)、GAIA 和 DeepSearch。
实验结果表明,SCOPE 在所有基准上都取得了提升:

在 HLE 基准上,SCOPE 将任务成功率从 14.23% 提升到 38.64%。在 GAIA 基准上,成功率从 32.73% 提升到 56.97%。
为了更准确地表达不同组件的贡献,论文中给出了消融实验。如下图所示,指导规则生成器提供 + 4.85% 的初始提升,双流路由贡献 + 3.63%,Best-of-N 选择贡献 + 3.03%,记忆优化贡献 + 1.82%,而视角驱动探索带来 + 10.91% 的提升。

值得注意的是,在知识密集型领域(如生物 / 医学、化学),SCOPE 的提升较为明显:生物 / 医学从 14.9% 提升到 43.2%,化学从 14.1% 提升到 50.3%。这些领域的问题往往涉及复杂的专业概念和严格的推理流程,SCOPE 合成的领域特定规则能够帮助 Agent 更好地理解和遵循这些要求。

Agent 真的在 "听话" 吗?
一个关键问题是:合成的规则是否真正影响了 Agent 的行为?
如下图所示,研究团队观察到了 "语言采纳" 现象:当 SCOPE 合成了 "始终列出所有可能的标签同义词和短语变体" 这一规则后,Agent 后续输出中直接引用了相同的措辞。这表明规则被整合到了 Agent 的决策过程中。此外,行为变化通常在规则合成后几秒内就会发生,展示了单个任务内的实时适应能力。

视角驱动策略多样性
视角驱动探索的设计得到了实验验证。如下图所示,效率流(Efficiency Stream)和周全流(Thoroughness Stream)的总体准确率相近(44.85% vs 46.06%),但两者解决的问题重合度仅为 33.94%,这意味着约 23% 的问题只能被其中一个视角解决。
效率流在 GAIA 的 Level 3 任务上表现更好(26.92% vs 11.54%),说明精简的上下文管理对复杂长程任务更有效;而周全流在 Level 2 任务上更强。全局集成捕获了两种策略的优势。

定性分析显示,面对同一个 HTTP 403 访问拒绝错误,效率流学会 “快速失败”—— 立即升级到搜索 Agent,不再重试;而周全流则学会 “寻找替代来源”—— 尝试 Archive.org 或转录工具。这种二元性让 SCOPE 能够同时处理时间紧迫型和深度检索型任务。

SCOPE 的意义
华为诺亚方舟实验室与香港中文大学联合提出的 SCOPE 框架,通过将执行轨迹作为学习信号、将 Prompt 视为可进化的参数,实现了 Agent 的在线自我优化。
与现有方法相比,SCOPE 具有三个主要特点:
- 步级别适应(Step-level adaptation):在执行过程中更新 Prompt,允许从任务中途的失败中恢复,而非等到任务结束才学习。
- 单 Agent 优化(Per-agent optimization):每个 Agent 角色基于自身特定的模式进化 Prompt,而非使用 "一刀切" 的策略库。
- 主动优化:61% 的规则来自成功模式的增强型合成,而非仅仅修复错误。
SCOPE 的代码已在 GitHub 开源。正如论文所总结的:“与其工程化静态 Prompt,不如让 Agent 在线进化自己的 Prompt。” 这一思路可能为下一代 Agent 系统的设计提供新的方向。
值得一提的是,SCOPE 的开源实现具有较好的实用性:
- 即插即用:只需在 Agent 执行循环中调用 `on_step_complete ()` 接口,即可为现有 Agent 系统添加自我进化能力,无需修改原有架构。
- 模型无关:通过统一的适配器接口支持 OpenAI、Anthropic 以及 100 + 其他模型提供商(via LiteLLM),方便开发者使用自己偏好的模型。
- 轻量部署:核心依赖精简,可通过 `pip install scope-optimizer` 一键安装。
SCOPE 提供了一套完整的实现框架,其核心洞察是:Agent 的执行轨迹本身就是最好的学习素材 —— 关键在于如何将这些经验有效地编码到 Prompt 中。对于希望增强 Agent 系统效能的开发者而言,SCOPE 提供了一个可直接使用的解决方案。
...
#MeViS
多模态视频理解领域重磅数据更新:MeViSv2发布
近日,多模态视频理解领域迎来重磅更新!由复旦大学、上海财经大学、南洋理工大学联合打造的 MeViSv2 数据集正式发布,并已被顶刊 IEEE TPAMI 录用。
- 论文:MeViS: A Multi-Modal Dataset for Referring Motion Expression Video Segmentation,TPAMI 2025
- arXiv 链接:https://arxiv.org/abs/2512.10945
- 数据集官网:https://henghuiding.com/MeViS/
- 数据集下载:https://henghuiding.com/MeViS/#dataset
- 评测平台:https://www.codabench.org/competitions/11420/
- 单位:复旦大学、上海财经大学、南洋理工大学
作为目前该领域最具有代表性的数据集之一,MeViSv2 围绕复杂动作推理来挑战现有模型的多模态处理能力,其包含 2,006 个视频、8,171 个目标及 33,072 条文本 / 音频表达,通过新增 15 万秒音频数据实现了向原生多模态的进化。
该数据集不仅全面支持 RVOS、RMOT、AVOS 以及 RMEG 四大核心任务,更引入了 “无目标语句” 和 “运动推理” 等机制,旨在挑战模型逻辑推理与鲁棒性的天花板。目前,数据集、代码及评测平台均已开放。

图 1:MeViS 示例,MeViS 中的表达主要侧重于运动属性,使得仅凭单帧图像无法识别目标对象。最新的 MeViSv2 进一步提供了运动推理和无目标表达式,同时给每一个文本提供了对应的音频记录。
MeViSv1:从 “静态特征识别” 到 “动态运动理解”
指向性视频分割(RVOS)是多模态视频理解的重要方向,近年备受关注。依托自然语言交互的灵活性,RVOS 在xx智能、视频编辑和辅助驾驶等领域展现出广阔的应用前景。然而,在 Refer-YouTube-VOS 和 DAVIS 等早期 RVOS 数据集中,研究人员发现了一个 “隐形缺陷”:目标物体往往具有显而易见的静态属性。模型只需看一眼单帧图像,依靠 “红衣服”、“左边” 等静态线索就能锁定目标,完全忽略了视频作为 “时间序列” 的动态本质。
为了打破这一局限,MeViS (Motion expressions Video Segmentation) 应运而生。其初版 MeViSv1 便确立了探索像素级视频理解的三大核心理念:
- 运动优先 (Motion Priority):标注指南强制要求语言表达式必须侧重于描述对象的运动线索(例如:奔跑、飞翔、移动),而非静态特征,迫使模型必须关注视频的时间动态信息。
- 复杂场景 (Complex Scenes):视频素材特意选自复杂、多对象的场景,拒绝 “简单背景下的单一个体”,极大提高了辨识难度。
- 长时序关联 (Long-term Dependency):MeViS 视频的平均时长为 13.16 秒,目标物体平均持续时间长达 10.88 秒,远超同类数据集(通常仅约 5 秒)。这对模型理解长时许动作以及处理相似物体间的长时许混淆提出了极高要求。
在这一理念下,MeViSv1 提供了超过 28,000 个高质量语句标注,覆盖 2,006 个视频中的 8,171 个物体 。如上图 1 的第一个样例所示,三只鹦鹉外观极度相似,静态特征失效,只有理解了 “The bird flying away” 这一动态描述,模型才能准确定位目标。截至目前,MeViSv1 在 CodaLab 上已吸引全球近千支队伍参加评测、累计 1 万余次提交,并且成功在 CVPR 2024、ECCV 2024、CVPR 2025、ICCV 2025 上举办全球挑战赛,吸引了数百支来自国内外顶尖机构的队伍参赛,这为 MeViSv2 的全面进化奠定了坚实基础。
MeViSv2:迈向更通用的原生多模态视频理解
MeViSv2 在 MeViSv1 的基础上进行了显著的扩展和增强,尤其是在多模态数据方面,旨在提供一个更具挑战性、更贴近真实世界、覆盖多模态全场景的视频理解研究平台。MeViSv2 的整体的设计选择延续了 MeViSv1 数据集的挑战性,同时相比于 MeViSv1,其有三个最大亮点:
1. 模态增加:音频支持
MeViSv2 的一大亮点是首次为全部的 33,072 个文本语句都配对了对应的语音指令。这进一步拓展了多模态支持,同时也标志着 MeViS 已经从视频数据集进化为原生多模态数据集。这些音频数据总时长超过 150,000 秒,源于几十位不同年龄、性别和背景的真人录制以及先进的 TTS 模型合成,保证了语音数据的多样性、自然性和真实感。
相比于冷冰冰的文本,音频作为人类认知的体现,在日常交互中更加自然、普遍和便捷。它承载着丰富的语义信息,并能捕捉到文本本身无法传达的语调、情感和重音等细微差别。这些特质有助于更精确的目标识别和分割。MeViSv2 中新加入的音频格式不仅支持音频引导视频对象分割,还支持真正的多模态视频理解任务,通过结合文本和音频两者的优势,多模态引用表达在增强视频理解以及支持更自然、直观的交互方面提供了显著的优势和灵活性。
2. 任务更广:四大核心任务
除了音频与分割掩码,MeViSv2 还系统性地补充了精确的物体轨迹标注,使其一跃成为迄今为止规模最大的指向性多目标追踪 (RMOT) 数据集。凭借超过 33,000 条语句和 2,000 个视频的庞大体量,MeViSv2 为 RMOT 提供了远超现有基准的训练数据,是研发下一代高精度多目标追踪模型的理想土壤。
总的来说,在多模态数据的全面加持下,MeViSv2 打破了任务壁垒,仅凭单一数据集即可支持多模态视频理解领域的四大核心任务:
- 指向性视频目标分割(RVOS,Referring Video Object Segmentation)
- 音频引导视频目标分割(AVOS,Audio-guided Video Object Segmentation)
- 指向性多目标追踪(RMOT,Referring Multi-Object Tracking)
- 运动指向性语句生成(RMEG,Referring Motion Expression Generation)
这些任务全方位覆盖了图像、音频、分割掩码、边界框以及生成式理解等关键维度,确立了 MeViSv2 作为视频理解领域首个真正全能数据集的地位。
3. 规模增大:更具挑战性的语句类型与数量

表 1:MeViSv2、MeViSv1 与其他多模态视频分割数据集对比。
MeViSv2 将总表达式数量扩充至 33,072 条,相较于 MeViSv1 新增了 4,502 条极具挑战性的语句。这一扩展绝非简单的数字堆砌,而是专为大模型时代量身定制,精准覆盖了当前 AI 推理能力最核心的两大挑战瓶颈:
- 运动推理语句 (Motion Reasoning Expressions): 从 “看动作” 到 “懂因果” 这类语句不再直白描述动作,而是通过隐式查询要求模型进行复杂的逻辑推理。如图 2 (a) 所示:面对 “What is causing the cage to shake?” 的提问,模型不能只寻找 “晃动的笼子”,而必须观察视频细节,推断出是笼内那只正在扑腾的鸟(橙色掩码)引发了震动。如图 2 (b) 所示:对于 “The one whose life is being threatened” 这一描述,模型需要理解狮子捕猎斑马的动态关系,才能准确定位到被追逐的斑马,而非捕食者。
- 无目标语句 (No-Target Expressions):拒绝 “指鹿为马”,为了解决模型在目标不存在时仍强行输出的 “幻觉” 问题,MeViSv2 引入了具有欺骗性的无目标表达 。如图 2 (c) 所示:语句描述 “Moving coins from right pile to left pile”,这看起来是一个非常具体的动作描述。但实际上,视频中的鹦鹉是叼起硬币从左边挪到右边,而非从右到左。如图 (b) 所示:语句询问 “The dog whose life is being threatened”,尽管视频中有激烈的追逐画面,但主角是斑马而非狗。面对这些极具误导性的描述,MeViSv2 要求模型具备 “判伪” 能力,在视频中没有匹配对象时,坚定地输出 “无目标”,从而极大地增强了现实应用中的鲁棒性。

图 2:MeViSv2 中新增的运动推理语句和无目标语句示例。图中标记为橙色的物体为运动推理语句的目标,而无目标语句是具有欺骗性,但不指代任何对象的语句。
LMPM++:大语言模型驱动的时序推理模型
面对 MeViSv2 带来的长时序依赖与复杂逻辑挑战,传统的基于 “关键帧采样” 或 “静态特征匹配” 的方法已显得力不从心。为此,该团队提出了全新的基线方法:Language-guided Motion Perception and Matching (LMPM++)。如图 3 所示,LMPM++ 巧妙地将大语言模型 (LLM) 的推理能力引入了视频理解,通过以下四大技术创新,有效解决了 “看不全”、“理不清” 和 “乱指认” 的三大难题:

图 3:LMPM++ 模型架构。LMPM++ 采用了以“对象为中心”的 LLM 作为基础,实现了灵活的多模态推理以及复杂的目标指代。
1. 核心架构:以 “对象” 为中心的 LLM
推理为了处理长达 200 帧的视频序列,LMPM++ 摒弃了计算昂贵的逐帧特征输入方式。它首先生成语言引导的查询,检测视频中的潜在对象并将其转化为轻量级的目标嵌入(Object Embeddings)。这些目标嵌入随后被输入到 LLM(Video-LLaMA)中。借助 LLM 强大的上下文建模能力,LMPM++ 能够跨越整个视频时序,捕捉那些稍纵即逝的动作或长周期的行为模式。
2. 原生多模态
统一 Text 与 Audio 接口为了适配 MeViSv2 的多模态特性,LMPM++ 设计了统一的指令格式。通过引入 <Text> 和 <Audio> 标签以及对应的投影层,模型将文本和音频特征映射到同一语义空间。这意味着,无论是输入 “一只飞走的鸟” 的文本,还是对应的语音指令,LLM 都能以相同的方式理解并执行,真正实现了模态无关的统一感知。
3. 创新损失
时间级对比学习 (Temporal-level Contrastive Loss) 动作的顺序往往决定了语义(例如区分 “先蹲下再起跳” 与 “先起跳再蹲下”)。LMPM++ 引入了时间级对比损失:通过随机打乱目标嵌入的时间顺序作为负样本,强制模型学习正确的时间结构。这一设计极大地增强了模型对复杂动作序列的辨识能力,避免了因时序混乱导致的误判。
4. 自适应输出
解决 “无目标” 幻觉针对 MeViSv2 中的 “无目标语句” 陷阱,LMPM++ 摒弃了传统 RVOS 方法强制输出 Top-1 结果的策略。模型被训练预测目标数量 No,并动态生成对应数量的 <SEG> Token。当 No=0 时,模型不输出任何掩码。这种自适应输出策略使得 LMPM++ 在面对欺骗性指令时能够 “保持沉默”,从而大幅提升了 N-acc.(无目标准确率)指标。
实验
1.RVOS 任务

表 2:RVOS 方法在 MeViSv2 上的性能对比。
如表 2 所示,无目标准确率(N-acc.)和目标准确率(T-acc.)两个指标是为 MeViSv2 新增的 “无目标语句” 而设计的新指标。N-acc. 专门用于衡量模型识别 “无目标” 样本的能力,计算方式为正确识别出的 “无目标” 样本占所有实际 “无目标” 样本的比例。而 T-acc. 则反映了模型在具备识别负样本能力的同时,是否会误伤真实目标,其计算基于被正确识别为 “有目标” 的样本占所有实际 “有目标” 样本的比例。
结果显示,对于像 ReferFormer 这样仅输出 Top-1(置信度最高)对象掩码的方法而言,多目标和无目标样本构成了更大的挑战。这种局限性源于 Top-1 策略假设视频中必然存在一个单一目标对象,这是 Refer-YouTube-VOS 和 DAVIS17-RVOS 等以往 RVOS 数据集中的默认假设。因此,这类方法本质上无法处理无目标样本,导致 N-acc. 得分极低,甚至为 0。这些结果凸显了 MeViSv2 数据集在评估模型对各种复杂场景的泛化能力方面提出了重大挑战。
相比之下,LMPM++ 展现出了压倒性的优势。凭借大语言模型的逻辑推理能力与自适应输出策略,LMPM++ 不仅在综合指标 J&F 上达到了 43.9% 的新高,刷新了该领域的 SOTA 记录,更实现了对 “幻觉” 的有效抑制,其中 N-acc. 跃升至 45.7% 。这意味着面对近一半的欺骗性指令,模型能够像人类一样判断 “目标不存在” 并拒绝执行。同时,高达 87.4% 的 T-acc. 也证明了模型并非通过简单的 “保守策略” 来换取高分,而是在保障真实目标识别率的前提下,真正具备了在开放世界中所需的逻辑判别能力。
2.RMOT 任务

表 3:RMOT 方法在 MeViSv2 上的性能对比。
如表 3 所示,在 RMOT(指向性多目标追踪)任务中,LMPM++ 更是确立了绝对的领先地位。从对比表格可以看出,LMPM++ 在不使用额外检测头的基础上,斩获了 38.1% 的 HOTA* 和 28.1% 的 DetA*,相比前代 SOTA 方法 TempRMOT(HOTA* 30.0%),性能提升显著。尤为关键的是,LMPM++ 的 T-acc.(目标准确率)达到了至 87.4%,远超之前的方法(如 TransRMOT 仅为 52.3%),这有力地证明了模型在处理复杂多目标追踪时的精准度,既能 “抓得准” 真实目标,又能保持对干扰项的稳健判断。
3.AVOS 任务

表 4:AVOS 方法在 MeViSv2 上的性能对比。
表 4 展示了 AVOS(音频引导视频目标分割)方法在 MeViSv2 数据集上的基准测试结果。WNet 和 MUTR 是原生支持音频作为输入的模型,但它们仅分别取得了 16.5% 和 33.6% 的得分,这突显了 MeViS 数据集的难度。MUTR 的 N-acc. 为 0% 而 T-acc. 为 100%,这表明无目标样本的引入显著增加了 MeViS 数据集的挑战性,尤其是对于那些倾向于针对任何给定表达都输出一个目标的模型而言。LMPM++ 在所有指标上都远远超过了之前的模型,体现了该方法优越的多模态处理能力。
4.RMEG 任务

表 5:RMEG 方法在 MeViSv2 上的性能对比
如表 5 所示,在运动指向性语句生成 (RMEG) 这一极具挑战性的生成任务中,现有模型普遍面临 “表达难” 的困境,即便是表现最好的 VideoLLaMA 2,其 METEOR 和 CIDEr 得分也仅为 15.68 和 27.10 。这表明,虽然引入大语言模型(LLM)相比传统方法(如 GIT, VAST)显著提升了逻辑推理能力,但在生成 “无歧义” 的精准描述方面仍有巨大提升空间。现有模型往往难以捕捉对象动作的细微差别,常犯 “指代不清” 或 “千篇一律” 的错误 ,无法像人类一样精准区分外观相似但动作不同的目标,这为未来多模态大模型的研究指明了 “从泛化描述向精准指代进化” 的新方向。
总结
MeViSv2 上的基准测试结果揭示了现有 SOTA 模型在面对运动推理和无目标表达式时的性能瓶颈。即使是表现最好的方法,在这些新增的挑战性样本上,性能也出现了显著下降。这表明 MeViSv2 成功地捕捉了当前算法的不足,为下一阶段的研究指明了方向。我们期待 MeViSv2 能够激励研究界在以下方面取得突破:
- 多模态深度融合: 开发能够直接从原始语音信号中提取时间语义线索,并将其与视频运动信息深度融合的新架构。
- 高级因果推理: 提升模型从长时序视频和复杂语言指令中进行因果和逻辑推理的能力,而非仅仅进行模式匹配。
- 鲁棒性和泛化性: 增强模型在无目标、多目标、目标相似等复杂场景下的鲁棒性,使其更接近真实世界的应用需求。
MeViSv2 的发布,不仅是一个数据集的更新,更是对整个多模态视频理解领域的一次挑战升级,为未来的相关研究奠定了坚实的基础。
...
#256G内存比RTX5090还贵,你要为AI买单吗?
离谱:~
太贵了。
时值美国圣诞购物季,喜欢电子产品的朋友们,却发现了这样恐怖的景象:

英伟达的顶配 GPU RTX 5090 官方起售价为 1999 美元(经过市场溢价可能达到了 3000 美元以上),而一根单条 256GB 的 DDR5 内存如今的市场价却也飙升到了 3500-5000 美元之间。
电脑内存,这个长期以来在配置里不占大头的组件,现在的价格已经涨到了令人乍舌的程度,这在个人消费领域已经成了个荒诞但又现实的写照。而且根据各种新闻,短期看来 PC 内存还要继续涨价,手机据说也要涨价。

这一波内存涨价的根本原因在于:产能都被 AI 截胡了,目前的内存市场正处于一场由 AI 算力需求引发的「结构性紧缺」中。
AI 训练与推理能力取决于 GPU、TPU 以及数据中心的整体性能,而 GPU / TPU 需要 HBM,AI 数据中心需要 LPDDR 内存。全球只有三家公司具备生产高端 HBM 与 LPDDR 的能力:SK 海力士、三星电子、美光。
今年 10 月,OpenAI 以「星际之门」项目的名义,与三星和 SK 海力士签下协议,锁定了每月高达 90 万片 DRAM 晶圆供应(HBM 本质上就是将多层 DRAM 芯片垂直堆叠在一起),这相当于全球 DRAM 月产量的 40%。这种规模的采购,瞬间抽走了大量本可用于消费市场的产能,直接导致合约价在交易公布后跳涨。
内存厂家的产能是存在上限的。由于 AI 服务器对内存的出价极高(向英伟达出售 HBM 内存的利润是向消费者出售 DDR5 内存的 5 倍),厂家会优先将生产线分配给大客户。这直接导致了供应给 PC 市场的常规 DDR5 晶圆减少,从而引发全球性的普涨。
不单单是内存,AI 着实是电脑配件价格上涨的强力驱动力。
不仅是 AI 基础设施的内存,现在「AI PC」的概念也要求更大的内存来运行本地大模型(LLM)。以前 16GB 的 PC 看起来已经能够处理所有任务,现在为了流畅运行 10B 以上参数的模型,32GB 甚至 64GB 逐渐成为新的门槛。这种需求叠加正在让内存紧缺进一步加剧。
前些天,硬盘存储的价格也同样遇到一波飙升。但最离谱的自然是显卡市场,逛了逛某二手交易平台,炙手可热的 RTX 4090 仍要近两万的价格。小编当年购入的 4090,在猛猛用了两年之后出手甚至还能挣钱…
内存涨价的行情不仅牵动着 GPU 厂商和消费者,也深刻影响到了科技公司,最近有消息称,谷歌的一些采购人员因为未能保证内存供应而遭解雇。
本月初,微软采购高管访问韩国,与 SK 海力士就长期供货协议及价格展开谈判。在会议中,SK 海力士明确表示:「在微软提出的条件下,供货存在困难。」一位半导体业内人士透露:「听到这个答复后,一名微软高管当场情绪失控,愤然离席。」
据产业界 25 日消息,随着全球 AI 半导体供应紧张局势加剧,包括微软、谷歌在内的全球科技巨头采购负责人正蜂拥至韩国,争抢产能。
半导体行业相关人士表示:「为了与三星电子和 SK 海力士签署存储器供货合同,微软、谷歌、Meta 等大型科技公司总部的采购负责人几乎是长期驻扎在韩国。」
目前,谷歌 TPU 所搭载的 HBM 中约 60% 由三星电子供应。随着近期 TPU 需求远超预期,谷歌试图向 SK 海力士与美光寻求追加产能,但得到的回复是:「不可能。」
据悉,谷歌管理层因此解雇了相关采购负责人,认为其未能提前签署长期供货协议,导致严重供应链风险,是对一线人员的问责性人事处分。
这些科技巨头为了内存供应而焦头烂额的时候,被认为是 AI 时代吃到最多红利的英伟达,同样也在为内存短缺烦恼。
尤其是在谷歌推出 TPU 芯片,向推理与规模化部署优先的战略转型,挑战英伟达在人工智能芯片的领先地位之后。
昨天,人工智能芯片初创公司 Groq 已与英伟达就推理技术达成了非排他性许可协议,同时英伟达挖走了 Groq 创始人兼 CEO Jonathan Ross、总裁 Sunny Madra 及多名核心工程师。详细信息可以参阅我们的报道。
Groq 的 LPU(Language Processing Unit)芯片未采用英伟达 GPU 常用的高带宽内存(HBM),而是将静态随机存取存储器(SRAM)直接集成在芯片内部。这种设计使单芯片内存带宽高达 80TB/s,是传统 HBM 方案的 20 倍以上。Groq 方案在物理空间和功耗上付出了代价:一个标准机架满载功耗约为 26kW 至 30kW,且需要比 GPU 方案更多的机架数量来承载同等规模的模型参数。
联系到疯涨的 HBM 内存价格,有业内人士提出了一种观点:
英伟达与 Groq 的交易,是为了对冲 DRAM 的价格疯涨和产能短缺,探索在内存上的新的技术路径。

Groq 在推理领域将一种设计哲学推向极端,核心赌注在于 SRAM。模型权重完全驻留在片上,并非作为缓存,而是作为主存储介质存在。
而 SRAM 的带宽比片外 HBM 高出若干个数量级,这一点至关重要,因为在推理过程中,每一个生成 token 的瓶颈受限于内存访问,而非浮点计算(FLOPs)。在此基础上,Groq 采用静态调度机制,计算与通信在编译阶段即被规划到时钟周期级别,从而消除了 GPU 架构时代大量存在的系统复杂性。
这场溢价接近 3 倍的收购,或许也是英伟达在「内存荒」的大背景下,正在开辟的第二条战线。
不过,对这部分说法也有不少反对意见,毕竟使用 SRAM 做主内存属实有些匪夷所思。

SRAM 之所以是 Mb 级别 而不是 Tb 级别,是因为 SRAM 非常快,但只有与逻辑电路集成在一起时才能发挥这一优势。换句话说,SRAM 的成本是在处理器芯片上制造高性能晶体管极其昂贵。英伟达的 Tensor Core 的芯片尺寸已经非常巨大,因此增加大量 SRAM 单元也会很快出现问题。
最后,对于我们这些普通消费者来说,是应该抓紧时间换机,还是等待这一波疯狂涨价过程的消退呢?
....
#RLinf
全异构、全异步的RLinf v0.2尝鲜版发布,支持真机强化学习,像使用GPU一样使用你的机器人!
在xx智能领域,特别是如何构造一个高泛化性的 VLA,数据之争一直存在:仿真数据 vs 真机数据。数据来源不同,导致算法设计迥然不同,进一步对系统设计提出了更多的要求。做 infra 的目标是做好服务,支持不同技术路线的探索。
「仿训推一体化」RLinf v0.1 面向的是采用仿真路线的用户,那么今天要给大家介绍的是 RLinf v0.2,面向采用真机路线的用户,也就是支持了真机强化学习。
- 论文标题:RLinf: Flexible and Efficient Large-scale Reinforcement Learning via Macro-to-Micro Flow Transformation
- 论文地址:https://arxiv.org/abs/2509.15965
- 开源地址:https://github.com/RLinf/RLinf
下面针对 RLinf v0.2 的特色展开介绍。
特色 1:RLinf 允许用户
像使用 GPU 一样使用机器人
在 RLinf 中,我们将机器人看作与 GPU 相同层级的、可灵活配置的资源,如图 1 所示,GPU Node 和 Robot Node 处于同一层级。过去我们通常把 Worker(训练、推理等工作组件)加载在 GPU 上,现在我们可以把 Worker 加载在机器人上。只要能够 access 到机器人的 IP 和端口,无论它们身在何处,都可以接入 RLinf 系统。
RLinf 会按照用户配置进一步完成模型与机器人的对应映射,之后 RLinf 会通过 Data Channel(RLinf 的通信原语)完成数据收集和模型参数更新。而实现这一切,用户只需要编写 YAML 文件即可完成,极大地降低了使用成本。例如,下图 2 展示了以 Franka 为例的 2 台机器人配置方法。

图 1 将机器人看作与 GPU 相同层级的、可灵活配置的资源 图 2 用户只需要编写 YAML 文件即可完成真机对接

图2 用户只需要编写YAML文件即可完成真机对接
RLinf 这一独特设计是为了解锁更宏大的目标,即大规模分布式真机强化学习训练范式,如图 3 所示。
这一范式将有望成为xx智能在除了 Scaling 数据、模型之外的第三条路径:Scaling 真机。大规模真机强化学习能够解决当下真机强化学习面临的诸多问题,当然,天下没有免费的午餐,放松了对算法的要求,对应地增加了对 infra 的要求,如何做到稳定、易用、灵活是 infra 要解决的主要挑战。
RLinf 针对这一问题给出了自己的答案:极度灵活的系统设计思想支持多样需求。特别地,RLinf 提出适配强化学习的新一代编程范式 Macro-to-Micro Flow (M2Flow),将上层工作流与底层计算优化解耦,兼顾了灵活性与高效性。

图 3 大规模分布式真机强化学习系统
特色 2:RLinf 支持
全异构软硬件集群配置
由于与物理世界高度耦合,真机强化学习面临的集群配置通常是异构的、端云协同的。例如,机器人的控制端需要实时操作系统且不需要运行神经网络模型,通常会运行在单独的 CPU 机器,如 NUC;VLA 模型推理端需要与机器人的控制端足够近,使得通信代价最小,且推理需要显存较小,因此 VLA 模型推理通常直接运行在端侧小显存机器,如 24GB 的 4090;VLA 模型训练为了加快训练速度,通常需要云端大显存机器集群,如 80GB 的 A100/800 等。
在端云协同的背景下,RLinf 支持灵活的全异构的软硬件集群配置,提升系统吞吐和训练效率。例如,你可以:
- 在支持光线追踪的 GPU(如 RTX 4090)上运行高保真模拟器;
- 在大显存计算 GPU(如 A800)上进行训练;
- 在小显存计算 GPU(如 RTX 4090)进行推理;
- 在无显存的 CPU 机器(如 NUC)运行机器人控制器。
在 RLinf 中接入这样的异构环境,只需要在 YAML 配置文件中正确配置 cluster 段落即可,如下图 4 所示。

图 4 RLinf 支持全异构软硬件集群配置
特色 3:RLinf 支持
全异步 off-policy 算法
真机强化学习的一个典型局限就是物理世界无法被加速,数据效率成为显著瓶颈,所以如何提高数据利用率成为关键一环。除此之外,当下真机强化学习的一种行之有效的方法是人在环介入,例如在执行过程中提供专家示教数据,或者实时标注数据等,传统同步训推框架将会极大限制这一类方法的训练效率。
因此,RLinf v0.2 新增全异步设计,端侧推理节点与云侧训练节点解耦,通过 Data Channel 进行数据周期性同步,进而实现训推并行,极大提高训练效率。同时,RLinf v0.2 上线典型 off-policy RL 算法,包括仅利用在线数据的 SAC [1]、CrossQ [2] 和同时利用离线数据集和在线数据的 RLPD [3] 等,进一步提升数据利用率。RLinf 中异步工作流示意图如图 5 所示。

图 5 全异步算法流图
实验结果
本次发布的尝鲜版是基于小模型的真机强化学习。为了方便大家快速、低成本复现实验,我们采用常见的 Franka 机械臂,基于常见物品或者易获取标准件设计了两个快速验证任务:Charger 和 Peg Insertion。其中,Charger 任务为稠密奖励,使用异步 SAC [1] 算法训练,训练过程中有 20 次左右的人在环空间鼠标接管,以提高训练效率。Peg Insertion 任务为稀疏奖励,使用异步 RLPD 算法 [3] 训练。在开始训练前,采集了 20 条人类操作数据存储在 Demo Buffer 中。
两个任务的成功率曲线如图 6 所示。可以发现,两个任务均可以在 1.5h 以内收敛。收敛后,Peg Insertion 任务可以连续 100+ 次成功,Charger 任务可以连续 50+ 次成功。

图 6 Peg Insertion & Charger 成功率曲线
训练过程的视频记录如视频 1 所示,完整记录了两个任务的训练过程。同时我们也验证了位于不同空间的两台 Franka 机械臂同时进行真机强化学习,见视频 2。
,时长01:07
,时长01:06
视频 1:训练过程。上:Peg Insertion;下:Charger
,时长00:19
视频 2:位于不同房间的两台 Franka 机械臂同时进行真机强化学习
写在最后
RLinf 全体成员向支持 RLinf 的 2k 位社区用户表达感谢。用户的使用和反馈促使团队不断完善代码,也不断增加了团队坚定走下去的信心。自 2025.9.1 发布以来,RLinf 几乎保持着每 2 周更新一次新 feature 的开发速度,在经过几轮重构后,面向xx仿真路线需求的「仿训推一体化」强化学习框架 RLinf v0.1 版本于 2025.12.17 正式 release,欢迎大家查看中英双语文档(对!除了代码没有中文版,其他材料都有中文版!不要错过!)。目前 RLinf 支持矩阵可以总结如下:
- Simulator: Maniskill、IsaacLab、LIBERO、CALVIN、MetaWorld、Behavior、RoboCasa
- VLA: Pi0,Pi05,GR00T,OpenVLA,OpenVLA-OFT
- Custom policy: MLP、CNN
- RL Algos: GRPO、PPO、DAPO、Reinforce++
- SFT: Full-para SFT、LoRA
仿真路线还在持续开发,更多的 feature,如仿真器、模型也会尽快跟大家见面!
参考文献:
[1] Haarnoja, Tuomas, et al. "Soft actor-critic: Off-policy maximum entropy deep reinforcement learning with a stochastic actor." International Conference on Machine Learning. PMLR, 2018.
[2] Bhatt, Aditya, et al. "CrossQ: Batch Normalization in Deep Reinforcement Learning for Greater Sample Efficiency and Simplicity." The Twelfth International Conference on Learning Representations, 2024.
[3] Ball, Philip J., et al. "Efficient online reinforcement learning with offline data." International Conference on Machine Learning. PMLR, 2023.
.....
#抓住前沿李飞飞最新访谈
这,才是下一个10年
“空间智能”是AGI的一把关键钥匙
1.世界远不止语言那么简单
我先说一下我的信念:在技术上,确实有一些相通的概念,所以我也能理解有些人说“语言即世界”。
宏观地来说,我坚信这个世界远不止语言那么简单。
如果我们说的语言概念,指的是那种离散的、本质上更偏向“一维”的信息——即便它能表达多维的内容,语言本身的呈现形式还是比较一维的。但这个世界其实要丰满得多。
我一直强调,空间智能包含诸多特性,比如物理属性这些,都是超越语言范畴的。而且不管是人类的行为,还是大自然的运转,很多东西既没法用语言完全表述清楚,也不可能单靠语言就实现所有想做的事。
我们每天睁开眼,从生存、工作、创造,到感受、感知,再到人与人之间丰满的情感,这些日常里的种种,从来都不是只靠语言就能完成的。
当然“语言即世界”这样的话确实挺好听,听起来也没错,因为它是非常笼统的一句话。当你一句话很笼统的时候,它可能错不了。
但从技术层面看,现在数字化是必然趋势:视觉模型、空间智能、机器人模型,本质上都会走向数字化。可要是把数字和语言完全画等号、当成一回事,那这个概念就变味了。
如果连数字都能被叫做“语言”,那相当于啥都能往“语言”里套,这就没什么好争论的了。
在我看来,信息远不止语言这一种,还有空间信息,它和语言一样美妙、一样重要。
2.“空间智能”到了爆发前夜
现在AI大环境里,大家对AI的期待确实有点太激进了。
但我可以告诉你,我选择创业的核心原因,就是觉得时间点到了。
毕竟创业和搞科研不一样,创业得紧密结合市场、尊重市场规律。但就像很多比我优秀的企业家说的,创业最关键的是踩准时间点——不能太早,市场和技术都没成熟;也不能太晚,否则就没了机会。
空间智能技术在World Labs(中文名:空间智能)刚成立时,确实还早了点,但也没早到需要等五六年、十年的程度。
我判断未来一两年,它会迎来爆发式增长。你看现在视频生成技术的飞速发展,再到我们做的World Models,我坚信这类技术在一两年内还会有质的飞跃,市场应用的可能性也越来越清晰。
我没法简单定义现在发展的速度是快还是慢,但能肯定的是,现在正是做空间智能的好时机。
我们现在做的“世界生成”(world generation)模型,真的特别令人激动。
它的应用场景太广泛了——从数字创意、游戏开发、影视制作、设计领域、建筑行业,到VR、XR、AR技术,再到机器人仿真,每一个大领域里又能细分出无数小场景。而这些场景,其实都藏着对三维空间的强烈诉求。
生成式AI有个很特别的价值:它能降低原本高难度事情的门槛,进而打开很多你意想不到的新市场。
生成三维空间就是件超难的事——这个世界上没多少人能做到,而且用到的Blender、Unity这类工具,操作起来特别繁琐。我自己试过,头都大了。
其实很多创作者脑子里装满了好想法,只是被工具卡住了,而非缺乏创意。而AI既能给现有创作者赋能,还能让很多原本觉得“这事跟自己没关系”的人,发现新可能。
就像我,以前根本不会碰Blender、Unity这类软件,觉得又麻烦又费时间,但现在AI能赋予我这种能力,我肯定愿意用——它能带来太多新灵感、新机会了。
所以我觉得三维世界模型特别让人兴奋:它原本是件对普通人来说难度极高的事,而AI能降低这项能力的使用门槛,这本身就是打开市场的绝佳机会。
在我看来,没有空间智能,没有三维世界的生成式模型,就谈不上AGI(通用人工智能)。
AGI就像一扇门,上面挂着好多把锁,需要不同的钥匙去开启。我始终认为空间智能是其中一把关键钥匙——不过这扇门并非非开即关,而是被一点点推开的。
其实我一直不太纠结AI和AGI的区别。因为两者的梦想是相近的,都是源于一种“科学”的好奇心:机器能不能思考?能不能自主完成事情?这是AI最初的梦想,AGI的目标似乎也没偏离太多。不管叫什么,这个梦想都得一步步实现,我们每往前走一步,就离它更近一点。
而空间智能,必然是通往这个梦想的重要一环。不管是赋能人类的创造力(从游戏、设计到工业应用),还是给机器人赋能,亦或是元宇宙、AR/VR的内容生成与落地,都离不开空间智能。
3.算法与数据,都是AI的核心
工程、数学的发展路径和进化的路径是不一样的,这就像苹果和橘子的比较,它们的进化都是很慢的。
进化的迭代速度远慢于算法迭代,而且碳基与硅基的运算逻辑也大不相同,所以从时间维度来看,两者没法放在一起比。但即便如此,进化依然给了我们很多启发和灵感。
这就说到数据的重要性了。当初我们实验室提出“数据”相关概念,其实也借鉴了不少进化的思路:漫长的进化岁月,本质上就是一段大数据训练的过程;但到了数字时代,我们不用再等几十亿年去收集数据,而是可以大规模、快速地积累数据。
和大自然通过进化完成的“数据积累”比起来,我们现在一次能处理、看到的数据,可能相当于进化几千万年才沉淀下来的量。
相信自己深思熟虑后的假设,也不是什么怪事吧?走在科学路上,对于那些经过深度思考的假设,你总得有所坚信。但作为科研人,也得清楚有些假设注定是错的——我当然也有过很多失败的假设。
而我现在坚信的这个假设,是琢磨了很久才得出的:它在数学上是归纳推理的逻辑。我整个博士阶段都在做模型、搞算法,积累了不少领悟,才慢慢意识到这一点。
说白了,AI到今天在数学层面的核心,就是“泛化”(generalization)——本质上就这一件事。
而泛化怎么实现?核心就两点:算法和数据,而且两者息息相关。算法太复杂但数据不足,会过拟合(模型在训练数据上表现优异,但在面对新数据时性能显著下降,无法有效泛化的情况);数据太多但算法不够好,同样会过拟合——这里面藏着明确的数学逻辑。
我算是计算机视觉领域早期做机器学习的那批博士生,很幸运的是,我的博士研究刚好赶上计算机视觉的转折点——我们大量运用机器学习的理念,这让我对“泛化”的理解更深刻(当然,不一定只有我理解得深)。但我那时候就明确看到了数据的重要性,所以一直坚持了下来。
这又回到了好奇心的话题——那个求证假设的过程其实挺有意思的,全程充满激情,就像一路打怪升级。只要没被“妖怪”打败,就接着往下打呗。
模型和数据的关系,本质是螺旋式上升的。
当年,ImageNet搭建起计算机视觉领域最大的数据库,直接推动了计算机视觉的蓬勃发展;后来互联网催生了海量自然语言数据,大语言模型也跟着迎来爆发;再看现在的视频模型发展得这么快,核心也是有足量视频数据支撑;自动驾驶能飞速进步,也离不开头部公司积累的海量路况、行驶数据。
现在看似“又回到了数据和算法”,其实根本算不上“回归”——它们从来就没离开过AI的核心。
我有时候觉得挺有意思:就算AI发展到今天,大家还是更看重算法。但真正做AI的人,不管是创业者还是大公司从业者,心里都清楚:数据不是说比算法更重要,至少是同等重要。
算法听着更“酷炫”,数据的价值反而容易被忽视。但实际上,数据本身就是一门科学。
4.空间智能,赋能于“机器人”的发展
1)自动驾驶,是简化版的世界模型
自动驾驶汽车其实就是机器人——它是人类最早量产的机器人,但其实挺局限的。你想啊,它就是个方盒子,基本只在二维路面上活动,只要别碰到别的东西,不管是车、行人还是路边设施。
但我们未来要做的三维机器人不一样:它得在三维世界里主动“碰”各种东西,帮我们洗碗、做饭、叠衣服。这么一对比,就知道自动驾驶汽车其实还是挺简单的机器人。
所以对应的,它的世界模型也更简单——毕竟要做的事儿就那么点。当然我不是说自动驾驶不厉害,特斯拉、Waymo(全球自动驾驶标杆,前身为 2009 年谷歌自动驾驶项目)这些公司都很了不起。但从科学和宏观的角度看世界模型与机器人技术,这顶多只是个开始,接下来要做的事情复杂多了。
我无法断言特斯拉有没有(世界模型)相关布局。但至少不会是一个强生成性的模型,毕竟业务场景本身不需要这件事。
但机器人不一样,机器人训练离不开生成式模型——你不可能收集到足够多的真实场景数据。而且我们做的事情都和创意、设计相关,这些本身就需要生成能力,“生成”本身就是核心应用场景之一。
2)机器人的三维能力,还在早期阶段
现在硅谷的机器人领域大火,我也特别喜欢这个领域,也一直很看好机器人的前景。但同时,我也觉得要保持冷静:机器人研究其实还处在早期阶段。
首先,最核心的问题是缺数据。汽车行业发展了几十年,还有无数人在开车过程中持续搜集数据;可机器人目前基本没有商业化应用场景,尤其是日常消费级场景,数据自然难收集。
而生成式AI的出现,给机器人领域带来了一条有意思又有前景的出路。
像视频生成这类技术,不仅提供了丰富的训练想象空间,还能用于拟态——比如我们正在做的机器人仿真,就特别有前景;甚至在推理阶段,还能用视频模型辅助在线做规划。
可以说,正是机器人周边领域(比如生成式AI)的快速发展,在反过来带动机器人技术进步,这一点确实让人激动。
但机器人要真正实现商业化,还有一段路要走,尤其是日常消费级机器人。不过工业机器人早就落地了,毕竟它的应用场景相对单一,容易约束环境,而且也积累了不少数据。
自动化驾驶和机器人两者之间,既有可比性,也有不可比之处。
自动驾驶从概念到商业化,走了近20年:谷歌2006年就成立了小型自动驾驶研发团队,直到2024年Waymo才正式上路。
汽车行业的供应链、OEM体系、客户场景都非常成熟,这一点让自动驾驶的商业化比机器人快得多;但当年AI技术不成熟,自动驾驶在AI这条路上走了很久,而现在AI的发展速度肯定会更快。
可除了工业机器人(或者说场景单一、易约束的工业机器人),目前并没有像汽车那样成熟的机器人应用场景。所以机器人商业化之路会比20年快,还是更慢,真的很难说。
但我相信,AI层面的进展会比当年自动驾驶时期快一些;可反过来,机器人面临的问题也更复杂——它要应对的是完整的三维世界。
AI已经能做到非常出色,可要说今天的空间智能,能达到人类睁开眼就有的那种对三维世界的深层理解,还差得远。
比如物体间的物理关系、材料属性、物理特性,这些我们人类能直观感知的丰富信息,AI还没法完全掌握;更别说对社交信息、人与人之间情感的理解,这些都属于视觉理解的范畴,而我还没提语言层面的复杂认知。
人类本身就是极其复杂的存在。所以从进化和能力来看,AI在某些方面已经追上甚至超越人类,但在很多核心维度上,还远远不及。
而且我作为深耕AI和科技领域多年的人,对空间智能的信仰,绝不是盲目崇拜。它源于对技术的深刻理解,源于这么多年在这个领域的深耕,也源于我和同事们看到的技术机会与发展方向。
创业确实需要情怀,但对科技趋势的判断,更需要扎实的逻辑和科学的判断。
AI的未来:人类有责任让其“向善”
1. 机会,并非赢家通吃
综合来看,数据、算力、人才的整合能力很关键——现在能做好这些资源整合的公司,存活概率和胜率会更高。
但我觉得,不能只盯着这些显性因素。毕竟显性因素一眼就能看到,也容易被大家热议追捧,但光靠这些远远不够。
举个简单的例子,在AI coding领域,微软应该是第一个下场的,推出了Copilot(微软推出的跨平台生成式 AI 助手)。它可谓占尽了天时地利人和:手握所有资源、坐拥现成场景,连GitHub(微软旗下的开发者平台)都是自己的。
可微软最终没能成为行业标杆,反倒是硅谷现在火起来的Cursor、Claude Code这些小公司,在巨头围剿下实现了突围。这就说明,光有显性因素根本不够。
如果大家都只盯着这些表面资源下判断,很容易出现偏差。
人类历史上,从来没有哪个时代是大公司独霸天下的——即便每个时代的大公司都手握超强的资源整合能力。所以这里边还藏着更关键的东西:创造力、机遇、执行力,还有对时间点的把握,这些都是决定成败的核心变量。
再加上,AI本身就是一门横向技术,能催生出无数应用级机会,大公司根本做不完。这些机会,恰恰给了小公司足够的空间:把某个应用做到极致,慢慢撕开市场缺口,完全有可能实现弯道超车。
2. AI只是工具
“AI是工具”,这其实是常识。
工具本就是双刃剑:人类史上所有工具,小到最初的火、石斧,大到核弹、生物技术,再到如今的AI,无一例外。
我当然也认为,工具的使用必须向善,但同时也要防范它被误用,不管是有意还是无意。
所以我觉得,两种极端都不理性:只追求发展而无视安全与向善,必然是灾难;但天天空谈伦理向善而停滞发展,也会错失技术带来的诸多福祉。
就像做父母,你会教孩子用火做饭吧?既要告诉他们火能做饭的好处,也得让他们知道用火的危险,这是再简单不过的道理。
AI既是权力的工具,也是向善的工具,但它永远只是工具。在我看来,这工具会越来越强大,但在它真正不可控之前,它始终属于人类——人类有责任让它保持可控。
但就像所有工具一样,我们从来不会指望工具自己明白该做什么:向善与否,本质是人类的责任。所以对AI的控制与引导,是法律、制度、教育和整个社会的共同责任。不同社会、不同个体或许有差异,但这份责任终究在人类身上。
3.教育体系,到了彻底变革的时刻
AI时代迫切需要我们更新教育理念和方式——既要让孩子们学会用这个工具,借助它赋能创造力、助力学习;也要让他们清楚工具可能存在的问题与风险。
而且这绝不仅仅是教育孩子的事。我们总觉得该教育孩子,殊不知最需要被教育的其实是成年人自己。所以,自我教育、面向公众的科普、给政策与法律制定者提供充足信息和学习机会,这些都至关重要。
说到底,对AI的发展与治理,本质上就是我们人类自身的学习、发展与治理——核心还是人的问题。
在这个AI成为具备智力能力的工具的时代,它带给我们的最大启发,或许是让我们更好地了解自己、治理自己——这里的“自己”,既包括每个个体,也包括人类群体。
现在关于AI的讨论沸沸扬扬,大家都热衷于谈论这项技术。但说到底,不管是个体人性还是群体人性,欠缺的或许还是那份自省吧。
对个体来说,时代正在剧变,再做“鸵鸟”逃避现实绝非明智之举。这种变化必然带来工作形态的重塑。任何重大科技革命都会引发职业变迁,有时是短暂阵痛、软着陆,有时可能伴随社会动荡。
作为个体,还是要保持好奇心——对生命、对世界的好奇。哪怕这份好奇心,在成年人的世界里源于对未知的恐慌也没关系,至少它能成为驱动你主动学习的动力。这一点,值得每个个体自省。
而从群体层面来看,AI时代最急需革新的,是我们的教育体系。不管是国内的K-12教育,还是美国这边虽不唯应试但仍包含应试、仍侧重“知识填充”的教学模式,都亟待更新。
AI正在不断证明,很多事情机器能做得更好。如果还让人类花十几年、几十年时间,去重复大半机器可替代的工作,无疑是对人类潜能的浪费。
所以我特别想呼吁:所有关注教育、能影响教育政策以及践行教育的人,都要牢牢抓住这个时代机遇。
我们的教育方法论,已经100多年没有本质变化了。我最大的期待是,100年后历史学家回望21世纪上半叶时,会看到人类完成了一次真正的教育革命。
借助AI赋能教育者与学生,把节约下来的大量时间和精力,让学生们在老师的引导以及自我探索中,去积累那些AI永远做不到的认知与核心能力。
人类的潜力其实无比巨大,每个个体都是如此。我们的大脑远未被充分开发,不管是作为个体还是群体,都还没发挥出全部潜能。
你只要看看人与人之间的能力差异,就能感受到这份潜力有多惊人:有些人展现出的能力,简直像“超人”一样。这说明,这种极致的潜能本就藏在人性之中,只是大多数人都没能把它激发出来。
而AI这个工具的出现,甚至它对人类工作带来的冲击,恰恰给了我们一个契机——重新审视并重构整个教育体系。
我觉得真正的教育变革,应该打破工科与文科的固有界限:毕竟AI能让所有人都学会编程,那这些人还能简单归为工科生吗?AI也能帮更多人更好地感知美、读书、作诗,文科的边界也被打破了。
所以,以前的分科逻辑完全可以改变——AI给了我们打破这种局限的机会。但说到底,关键还是人怎么使用这个工具。我最担心的,是人类会放弃自我:觉得“AI这么聪明,有没有我都一样”,这种想法太可怕了。
“躺平”这个词很形象,但背后的心态真的危险。人类有太多未被发掘的潜力,有太多创造世界的可能,有太多让这个世界变得更美好的机会。而AI,终究只是一个工具而已。
如果我们放弃了自身的能动性(agency),就等于放弃了改变自己、改变世界的好奇心与动力。
说实话,我真的不懂什么叫“AI就是世界”。就像有人说“一花一世界”,我能理解那份意境,但“AI就是世界”的说法,我实在摸不透它的核心含义。
其实“AI只是工具”这句话的背后,本质是我们如何看待AI与人的关系——把AI当工具,意味着人类始终把自身放在更重要的位置,意味着我们更该关注自我的成长与价值。
说到底,“AI是工具”这句话里,藏着我对人的信仰——我信仰人性的潜力,信仰人类社会的韧性,我信仰的是人,而不是AI。
...
#Physical Intelligence内部员工分享
从数采到VLA再到RL
原文链接:https://vedder.io/misc/state_of_robot_learning_dec_2025.html
这次来学习一下 PI 内部人员写的 blog,介绍了很多 robot learning 的现状,而且都是一线的真正经验,很多在一线的同学应该深有感触,说了很多实话,质量很高,值得精读和学习。不管是对 IL DAgger RL 的看法都是很一手的经验。
接下来请享受这份知识
基本上,目前(2025 年 12 月)所有机器人学习系统都是纯粹的行为克隆(BC,也称模仿学习)系统。人类提供(接近)最优的任务演示,机器学习模型则尝试模仿这些动作。形式上,策略训练采用监督式方法——给定机器人的状态
(例如摄像头图像、机器人关节角度以及可能的任务描述文本),policy 预测已演示的动作 a 通常是一个动作片段(action chunk),例如接下来约 50Hz 的 1 秒动作)。
本文档旨在描述现代生物认知技术栈的构成,以及其不足之处和(不完整/笨拙的)变通方案。值得注意的是,它侧重于相关的问题定义和数据来源,而非模型架构等看似不那么重要的细节。随后,它旨在解释人们正在考虑的其他未来方法,以及阻碍它们成为主流方法的因素。最后,它对机器人学习的未来进行了一些预测,并为xx人工智能领域的“实干家”们提供了一些指导建议。
2025 年机器人学习栈的剖析
收集人类专家演示
首先,要进行行为克隆,你需要有待克隆的数据。这些数据来自人类演示以及各种其他来源。
主从控制方案(GELLO,ALOHA)
人类使用控制器(主臂)直接远程操控整个机器人(从臂)。这可以通过复制完整的机器人设置来实现(ALOHA))或更小、更轻的缩小版(GELLO)。
优点:
- 跟随机器人配备了全套传感器,可以记录所有信息。
- 所有演示在运动学上都是可行的,因为它们都是在机器人上执行的。
缺点:
- 一般比人类直接用手完成任务慢_得多(慢可达 10 倍!)。_
- 操作员需要数周的练习才能熟练掌握,从而使数据可用于培训。
- 需要现场配备完整的机器人来采集数据——规模化采集需要大量的生产和资金投入。
智能演示手套(Smart Demo Gloves )(通用操作接口)
与完整的“主从(leader–follower)控制”不同,人类操作者手持设备(例如通用操控接口)来完成任务。
这些设备的末端执行器形式与机器人一致,并配备了一个低成本版本的机器人传感器套件,用于尝试重建状态 s
设备通过 SLAM(同时定位与建图)来获取末端执行器在任务空间中的位姿,从而可以在之后使用逆运动学(IK)来估计完整的关节状态。
优点:
- 操作者更容易上手
- 示教速度更快
- 大规模部署成本更低(例如 Generalist、Sunday 这类系统)
缺点:
- 对状态 s 和动作 a 的重建存在噪声,引入了严重的“域差距(domain gap)”,可能显著降低策略性能
- 本体感觉(proprioception)和动作必须从 SLAM 得到的末端执行器位姿中间接推断
- 相机图像中始终出现的是“人类手臂拿着设备”,而在推理(实际执行)时机器人看到的是“机器人手臂”
- 无法保证运动学与动力学可行性(kinodynamic feasibility):人类可能在示教中伸出机器人工作空间,或利用人类手臂实现机器人无法达到的姿态
直接人类示范(人类数据)
YouTube 及其他视频平台上存在大量人类执行各种任务的数据。
类似地,许多工厂中人类工人正在完成高精度、灵巧的任务,这些工人可以通过佩戴摄像头来记录他们的视觉观测,从而提供极其庞大的数据来源。
优点:
- 数据最容易获取
- 数据规模巨大且多样
- 数据是在完整人类速度下产生的
缺点:
- 在重建状态 s 和动作 a 时存在巨大的差距
- 状态可能不是第一人称视角,或来自不同角度,导致严重的状态分布不一致
- 动作必须完全从原始数据中推断,通常需要借助其他模型进行伪标注(例如人体骨骼追踪、手部追踪)
- 若无法获取完整的人类自由度(DoF),轨迹往往在运动学与动力学上不可行,例如人类会通过身体前倾、重心转移、伸展身体来完成动作
行为克隆中的难题(分布外状态,OOD)
(老生常谈,熟悉的朋友可以跳过)
从原理上看,行为克隆似乎非常简单——直接用监督学习训练策略 π(s)去预测动作 a。
然而,即使示教数据非常干净,这类策略在执行时仍然会逐渐偏离,进入训练分布之外(OOD)的状态。原因主要有以下几点:
原因 1:真实世界永远与训练数据不完全一致
真实世界不可能与训练数据完全一致;即便在同一个工作站,光照、背景、场景中的干扰物等微小变化都会改变状态 s 中包含的信息,从而影响动作 a 的预测。
原因 2:任务本身具有不确定性与多模态性
“下一步究竟该做什么”本身就存在不确定性(例如展开一件衣服):
- 一方面,状态 s 天然是部分可观测的(比如无法看到皱成一团的衣服内部的折叠情况)
- 另一方面,人类示教者的动作分布本身是多模态的(同一状态下,人可能采取不同但都合理的动作)
原因 3:动作预测误差会随时间累积
模型在动作预测上不可避免地存在误差;由于策略 π(s) 是一个序列决策系统,预测的动作会影响下一个状态 s′,因此误差在不断滚动执行时会递归累积并被放大。
要解决这些挑战,需要在模型设计和训练数据设计上做出选择。
模型设计当然重要——例如需要具备数据驱动先验、能够处理动作多模态性的模型结构——但相关文献已经非常丰富(如 pi0.6)。
相比之下,训练时使用的数据分布往往更加关键。
正如第 3 点所讨论的那样,如果仅仅用专家人类示教数据来训练模型,那么在推理(实际执行)时预测误差会不断累积,最终导致策略偏移到训练中从未见过的状态(OOD)。
尽管视觉-语言模型(VLM)强大的视觉先验有助于模型在新状态上进行泛化,但仍然不可避免地会存在失败的场景。
解决分布外状态下的性能问题(通过将这些状态“拉回”到训练分布中)
(看到这张图,就又回到了熟悉的 DAgger 流程上)
这就是为什么不能天真地只用专家人类示教数据来训练模型的原因!
除了直接的任务示教之外,更关键的是要训练模型如何从失败状态中恢复——也就是一种 DAgger 风格的方法。
构建这类数据存在一些微妙之处:
你希望模型学会如何离开这些糟糕的状态,但又绝不能无意中教会模型如何进入这些糟糕状态,否则模型可能会模仿这些数据,反而主动跑到失败状态中。
要把这件事做好,就必须精心筛选和设计恢复数据。
构建 DAgger 数据是一个高度迭代的过程,而且在很大程度上是一门“艺术”。
你先针对某个任务训练模型,观察它的失败模式,然后构造一个新的数据集来专门应对这些失败模式,接着重新训练,再次测试,如此反复。
这是一个极其繁琐、耗时的过程,需要大量聪明且判断力极强的人类投入时间,本质上是在和各种问题“打地鼠”。
在这个过程中,你会逐渐形成一种对策略行为及其问题的“手感”和直觉。
由于需要快速迭代,这一过程通常是在一个已经预训练好的基础策略之上进行的后处理训练步骤,并且希望这个基础策略已经见过大量任务数据,大致知道自己在做什么。
更令人沮丧的是,一旦你对基础策略进行了新的预训练,之前在任务迭代中形成的“手感”可能会被完全清空,并引入一组新的(但通常希望更小的)失败模式。
将这些DAgger 数据纳入预训练阶段,并结合更大规模的数据,通常可以带来更高质量的预测和更少的失败。
如果在数据迭代上投入足够多的精力,策略最终可以变得出乎意料地鲁棒。但随着策略越来越鲁棒,评估它们性能所需的时间也会急剧增加。如果策略平均每 15 秒就失败一次,那么只需要几分钟的测试,就能比较训练方案 A 和 B 的性能差异。但如果策略需要几分钟甚至几小时才失败一次,那么你必须投入数小时的评估,才能获得任何有意义的对比信号。
人们很容易转而依赖离线指标(例如 Generalist 博客中提到的验证集 MSE),但从经验上看,这些离线指标与机器人真实执行性能之间的相关性非常弱。
加速你的行为克隆策略(这很难!)
DAgger 可以解决鲁棒性问题,避免灾难性失败也能提高任务完成的平均速度,但它无法提升最理想情况下的执行速度。
在给定数据集的情况下,你可以:
- 只保留最快的人类示范(但会丢失大量数据规模,且很可能损害鲁棒性),
- 或者在模型中显式地对“速度”进行条件化建模(例如 Eric Jang 的《Just Ask For Generalization》), 但这些方法都无法让策略的速度超过人类示范本身。
另一种“取巧”的方式是直接以高于实时的频率执行策略动作(例如原本 50Hz 的控制改为 70Hz),
但这会给底层控制系统带来巨大压力,并在与真实物理世界交互时导致错误行为(例如衣物被甩到空中后,需要等待它自然落平,而加速执行会破坏这种物理过程)。
超越行为克隆系统
到 2025 年为止,行为克隆这一整套系统说实话并不好用。
它不仅在数据规模上存在泛化瓶颈,还受限于:
- 人类示教者提供数据的速度
- 以及负责 DAgger 的“数据侍酒师”(data sommelier)为修复失败而付出的大量人工判断与精力
理想情况下,我们希望机器人系统能够自我提升:
- 能够自主收集数据并从中学习和改进
- 即便进入糟糕状态,也能通过探索自行脱困,并自动学会避免再次进入这些状态
- 能够自动变得更快,在其具体硬件条件下达到甚至超过人类水平的执行速度
强化学习(RL)看起来正好符合这些要求。
强化学习在大语言模型领域取得了巨大成功,因此人们很容易幻想可以将这些技术“直接搬”到机器人领域。
但遗憾的是,尽管已经尝试了多种方法,这种设想至今仍未真正奏效。
LLM 中的强化学习(RL in LLMs)
大语言模型(LLM)与机器人在两个关键方面存在本质差异:
差异 1:LLM 可以从完全相同的状态 s 出发,无限次地进行 rollout(执行与探索)。
差异 2:LLM 从一开始就拥有一个非常强的基础策略。
正是由于上述两个因素,在线、on-policy 的强化学习在 LLM 中变得可行。
无论是直接使用,还是经过少量专家示范的监督微调,策略通常都能在给定状态 sss 下达到一个非零的成功率。
这使得 LLM 可以从状态 s 出发,执行数百或数千次 rollout 作为探索,从环境中获得(稀疏的)奖励反馈,并直接更新策略。
重要的是,这一过程避免了对反事实(counterfactual)的臆测。
通过从同一状态 s 出发执行多条不同轨迹,模型无需臆测“如果当时换个做法会怎样”,而是直接从环境中获得反馈,基于自身已经相当不错的猜测进行改进。
在真实世界的机器人系统中,我们完全不具备这些奢侈条件。
给定一个“清理厨房”任务开始时的状态 sss(一个凌乱的厨房),我们既无法轻易将这个厨房的杂乱状态完美复制上百次,也没有足够强的基础模型,能够以非零成功率稳定地完成整个清理任务。
因此,我们只能选择两条路径之一:
- 利用仿真,在其中可以无限次重建状态 sss(但要承受严重的 sim-to-real 差距),
- 或者在仅有一次真实世界 rollout 的情况下,能够对反事实(“如果当时换个动作会怎样”)给出高质量的“想象性答案”。
仿真中的强化学习(RL in Sim)
在 LLM 中不存在 sim-to-real 问题——训练时交互的环境,与推理时看到的环境完全一致。但在机器人领域,仿真器只是现实世界的一个“仿制品”,而且往往是一个相当糟糕的仿制品。
仿真器通常:
- 物理模型过于简化
- 需要用数值近似来处理多物体碰撞
- 必须在不同接触模型之间做取舍
- 对非刚体物体(如布料、绳索)建模能力极差
- 在视觉外观上与真实世界存在巨大差距
正因如此,完全在仿真中训练的策略在迁移到真实机器人时表现通常非常糟糕。
域随机化(大幅扰动仿真参数)确实有所帮助,使用高度结构化的视觉输入(如点云)也能缓解问题,但除了运动控制(如 RMA)之外,这些方法在机器人操作任务中收效有限。
目前有大量关于“世界模型”的研究,它们本质上是学习得到的仿真器。
一个重要的希望在于:与策略模型不同(策略需要知道“在状态 s 下的最优动作”),世界模型只需要模拟“在状态 s 下执行动作 a 会发生什么”。
在具有结构性的领域中(如真实世界,其物理规律是可组合的),任何状态–动作–转移数据,无论来自最优策略还是随机策略,看起来都应该有助于学习通用的动力学模型。
但即便如此,截至目前,我尚未看到任何工作能够较好地建模我们在灵巧操作任务中真正关心的环境交互动力学。
真实世界中的强化学习(RL in Real)
使用真实世界数据可以避免任何 sim-to-real 差距,这也是我们最初选择行为克隆(BC)的原因。
然而,直接从自己策略的真实执行(rollouts)中学习并持续改进,仍然面临诸多障碍。
强化学习改进循环的目标,是增加相对更好动作的权重,降低相对更差动作的权重。
为了判断一个动作是否“相对更好”,我们必须回答反事实问题(counterfactuals)—— 也就是:“如果当时选择了另一个动作,会发生什么?”
但正如在 LLM 部分所讨论的那样,机器人没有能力从同一个状态反复执行策略,尝试大量“还算合理”的动作来比较 a 和 a′的相对表现。
因此,我们必须依赖某种系统来“幻想”这些反事实结果,例如:
- 一个直接估计折扣回报的 Q 函数 Q(s,a),
- 或者对状态转移 (s,a)→s′ 有所了解,再结合后继状态的价值函数V(s′)。
值得注意的是,Q 函数和 V 函数本质上也是“世界模型”,只是换了一种形式。 它们并不是预测完整的未来世界状态,而是将长时间尺度上的信息压缩进一个值中,表示:
在未来持续做出良好决策的前提下,你最终能否到达目标。
可以想象,这同样非常困难。学习高质量的 Q 或 V 函数仍然是一个开放研究问题。
最近,Physical Intelligence 发布了 pi*0.6,
该方法使用了一种优势加权回归(Advantage Weighted Regression)的变体:
他们展示了相较于纯 BC 的小幅提升,但在许多任务中,策略仍然需要人工 DAgger 数据,这显然不是解决真实世界 RL 的“银弹”。
我们仍然需要在构建可靠、在 OOD 状态下也能工作的 Q / V 函数方面投入大量研究,避免它们严重高估或低估真实价值。
(所以其实 reward model 这些本质上也是一个 world model 了)
预测与建议(Predictions and Advice)
对机器人学习未来的预测
- 2 年内:VLAs(如 π0\pi_0π0)将被视频模型骨干所取代
- 10 年内:世界模型将能够很好地模拟通用开放世界交互策略将通过在世界模型中“抽取(policy extraction)”而获得
- 传统仿真 / 游戏引擎将成为世界模型的数据生成器,但其核心将是端到端学习的
- 接近)专家级示范数据仍然对世界模型微调至关重要
- 真实机器人 rollouts 仍然是实现超人级性能所必需的
关于“卖铲子”的创业公司建议
- 数据标注不是护城河,是一种高度商品化的业务,本质上是人力成本套利的苦活(hustle play),而不是技术驱动型生意。如果你要做这件事,你必须在运营层面打败 Scale AI。
- 预训练数据的售卖同样是一门苦生意(hustle play),而且你必须证明:你的数据确实能提升客户模型的性能。这既是一个运营问题,也是一个技术问题,而且我们已经知道:并不是所有机器人数据都有用。
- 评估(evals)确实是一个瓶颈,但它们对模型改进闭环至关重要,因此必须在公司内部完成。这一部分无法被拆分出来外包给第三方。
- 不会有通用的数据平台:在自动驾驶领域,数据平台都没能做到“一套方案适配所有人”,而那还是一个:传感器几乎相同,任务目标几乎一致的领域。那么在xx AGI 领域,也不可能存在“一统天下”的数据平台。
我认为,未来唯一确定可靠的基础是:人类示范将长期持续地重要。
如果你能构建一个软硬件一体的人类示范系统(例如 GELLO 或 UMI),有效降低前面描述的各种痛点,并且你能够通过实际训练证明它能产出高质量策略,那么你将成为一个极具吸引力的合作伙伴,甚至可能直接成为收购对象。
....
#WeatherPrompt
上大澳大联手,“无需训练”无人机全天候定位技术,暴雨浓雾都不怕!
上海大学&澳门大学提出WeatherPrompt:零训练即可用大模型链式推理生成天气-空间描述,驱动文本门控重加权视觉特征,实现雨雾雪夜等开放集天气下的无人机跨视角定位,University-1652/SUES-200检索性能全面领先,代码已开源。
如今电力巡检、城市安防与应急救援愈发依赖无人机,传感器可升级、算力可扩容,但在雨、雾、雪、夜等复杂天气下,跨视图定位易失稳,为什么唯独“天气语义”始终难以被充分建模?
想象一下:暴雨夜紧急搜救、林区起火烟雾遮挡、城区积雨反光刺眼
这些关键时刻的跨视图定位与检索,正是空地协同的“最后一公里”痛点。现有无人机跨视图定位,像个只会认“白天”和“晴天”的“天气盲”——它擅长记住地标,却对风雨雾雪的扰动束手无策。
针对上述难题,上海大学和澳门大学的研究团队联合提出一种 [无需训练]的全天候无人机定位新范式。无需为每种天气微调,仅凭当前场景图像读出天气语义并稳健对齐,实现全天候无人机跨视角定位。论文、代码已开源!
- 论文标题:WeatherPrompt: Multi-modality Representation Learning for All-Weather Drone Visual Geo-Localization
- 论文链接:https://arxiv.org/pdf/2508.09560
- 代码:https://github.com/Jahawn-Wen/WeatherPrompt
01 研究背景:为什么需要[全天气无人机定位]?

无人机硬件可升级、算力可扩容,故真正的瓶颈在天气语义——它既难标注又呈开放集分布,无法靠逐天气微调覆盖。从巡检到救援,任务不会因天气而暂停,但定位常因雨雾夜而失稳:对比度骤降、散射增强、颜色偏移,让跨视角特征难以对齐。
我们的答案是把“读天气”前置到决策回路:仅凭当前观测即刻估计天气语义,驱动对齐与检索的自适应调度,支撑全天候的无人机定位。
02 开放集「天气描述库」:把天气变成语言!
首先,我们将天气情况变成本文描述方便后续理解天气。我们在 University-1652 与 SUES-200 上合成多天气无人机视角,并利用 CoT 生成结构化描述示例

开放集表达: 通过分阶段 CoT 提示词,先判断天气强度与要素,再抽取宏观布局/结构要点/拓扑关系,得到高质量的天气与空间文本描述。
两阶段规范化: 天气先验加空间结构,以结构化输出约束生成内容,减少自由文本的幻觉与不一致,使提示在不同场景与天气下保持一致可比,显著降低自由文本带来的幻觉与风格漂移。
03 「读天再定位」框架

WeatherPrompt 总览:链式推理生成天气+空间描述 → 文本驱动动态门控 → 跨模态对齐定位
训练无关天气推理: 直接利用现成 LVLM,不额外训练地生成开放集天气描述,天然可拓展到未见/复合天气与不同强度。
文本驱动动态门控: 用文本嵌入自适应重加权视觉通道,显式解耦“场景—天气”,缓解伪标签与闭集天气带来的欠拟合。
首个 CoT-驱动的多天气跨视角方案: 结构化提示规范 LVLM 输出,用于大规模全天气对齐。
04 实验结果
定量结果。表1和表2展示了WeatherPrompt与一系列可能的解决方案的实验结果比较。


定性结果。展示了WeatherPrompt与一系列可能的解决方案的检索结果比较。

05 为什么这很重要?
城市与应急更稳: 面向灾害响应、城市巡检、搜救与环境监测的关键任务,在恶劣天气下仍能稳定位。
规模化可推广:训练无关的天气推理与文本门控替代频繁重训或微调,适应未见/复合天气与地域差异。
技术路线清晰: 用语言把天气讲清楚,再做跨模态检索与对齐,从“只看像素”迈向“读懂上下文”。
...
#让优秀的评测基准被看见
2025司南年度最受欢迎评测集评选启动
每一个优秀的评测基准,都是大模型能力进化的重要基石。而那些从 0 到 1 构建评测基准的研究者与团队,往往站在行业最前沿,却并不总是被足够多的人看见。
2025 司南年度最受欢迎评测集评选活动正式启动!
如果你:
- 构建过一个扎实、可靠、有价值的评测基准
- 或者见过、用过、认可某个优秀的评测工作
都欢迎你来提交 / 推荐 / 投票,让真正有价值的评测工作被更多人看见。
如果你是来自学术界或产业界的专家,也非常期待你留下专业评价与建设性建议。你的每一条反馈,都是评测基准不断完善的重要参考。
让优秀的评测基准被看见,让真正有价值的工作被记住!期待你和司南一起,推动大模型评测走得更远、更稳。
活动页面直达链接:(文末点击阅读原文可直达)
https://hub.opencompass.org.cn/2025-annual-benchmark?lang=zh-CN
.....
#腾讯按下AI加速键,人才、组织、开源动作密集
在外界感知中,腾讯在 AI 领域的动作更多被贴上稳健甚至克制的标签。
但在 2025 年的尾声,从人才引进到产品迭代再到组织变革,一系列密集信号的发出,也侧面表明这个巨头正在按下加速键。
12 月 17 日,xx报道证实,前 OpenAI 研究员、清华校友姚顺雨(Vinces Yao)正式加入腾讯,出任「CEO / 总裁办公室」首席 AI 科学家,并直接向腾讯总裁刘炽平汇报。
与此同时,腾讯宣布升级大模型研发架构,成立 AI Infra 部、AI Data 部及数据计算平台部,全面强化研发体系。
除了人事与组织的变动,就在同一天,腾讯还发布并开源了国内首个可实时交互的混元世界模型 1.5(WorldPlay)。
,时长00:23
若将时间轴拉长,从混元 2.0 采用 MoE 架构实现推理效率领先,到混元 3D 模型下载量突破 300 万,再到腾讯混元、腾讯优图实验室等系列模型、工具开源,腾讯在技术迭代、开源贡献与人才密度上的提升显而易见。
姚顺雨曾在其博客中探讨过 AI 发展的「下半场」逻辑,强调智能体与认知架构的重要性。如今,随着这位在 ToT(思维树)、ReAct 等领域做出突破性工作的青年科学家入局,并统管 AI Infra 与大语言模型两大核心部门,腾讯 AI 的战略路径已经比较清晰:通过顶尖研究与扎实工程的深度咬合,为用户打造真正好用的 AI。
持续补强模型能力
上层应用的繁荣,很难离开底层基础模型的支撑。
此次架构调整中,新成立的 AI Infra 部被置于关键位置,负责构建大模型分布式训练、高性能推理服务等核心能力。
在模型层,腾讯混元此前一段时间已经展现出强劲的迭代能力。最新发布的混元 2.0 在复杂指令遵循和文本创作上表现国内领先;在 3D 生成领域,腾讯混元 3D 系列模型已成为全球最受欢迎的开源 3D 模型之一,社区下载量超过 300 万,并推出混元 3D 3.0,将建模精度提升了 3 倍。
姚顺雨的加入,不仅带来了算法层面的前沿视野,更关键的是他同时负责模型与 Infra。这种模型 + 基建的一体化管理,有助于加强算法研发与底层算力之间的互融,让基础设施更好地适应模型演进的需求,同时也让模型训练更高效地利用算力资源。
对于外界而言,这也让混元大语言模型未来的进化速度与上限更值得期待。
模型与工程能力的深层协同
如果说腾讯混元大模型的持续进化是为了打造一颗更强劲的心脏,那么要让 AI 真正跑通业务场景,还需要一套精密传动的骨骼。
这也是腾讯 AI 工程化落地一直在努力的方向,通过从模型、工具到应用的完整布局,逐步填平模型突破与产业落地之间的鸿沟。
工程化能力首先反映在底层算力基础设施的优化上。据悉,腾讯通过软硬一体化策略,针对星脉网络与高性能存储进行专项调优,将模型训练综合性能提升了 30%。
同时,腾讯云将支撑大规模训练的同源技术能力沉淀为 TI 平台,核心解决模型训不动、调不准的工程挑战。这个平台不仅支持算力潮汐调度,更实现了从数据处理到部署的全链路打通。无论是车企精调模型还是私有化部署,腾讯云TI 平台都能提供标准化的工业级生产流水线,使大模型开发实现软件工程式的标准可控。
在夯实好底座与开发线后,在模型组件方面,腾讯优图实验室也开源了系列小而美的模型能力,针对性解决大模型落地的工程痛点。同时,这些开源项目并非孤立的技术点,而是具备高协同性的技术栈,通过模块化集成,能够形成从组件到方案的体系化输出。
腾讯似乎正在通过这类连续的开源动作,为加速智能体的落地尽可能扫除障碍、创造更多价值。
据xx获悉,针对如何让 AI 读懂复杂文档,腾讯优图实验室即将开源 Youtu-Parsing。它像一位经验丰富的专家,看得清、理得顺、认得准那些「杂乱无章」的非结构化数据。可针对输入的复杂文档,完成从全局到局部的精细化处理,既实现文档整体布局的精准分析,又能针对性提取图表、文本块、数学公式、表格等关键元素,有效解决复杂排版文档信息还原问题,为大模型提供高质量的数据。
针对「记不住」和「幻觉」等顽疾,他们此前又开源了 Youtu-embedding 和 Youtu-graphrag 组合。前者赋予 AI 在海量知识库中精准定位的能力,后者则通过知识图谱技术,将碎片化信息串联成逻辑链条,相当于给 AI 装上一张地图,让推理有据可依,显著减少胡说八道的情况。
为了让 AI 能够突破对话框的限制、去执行更复杂的任务,腾讯优图实验室还开源了 Youtu-agent 框架。这个框架在设计之初就融入了「自我进化」的能力,可以根据自然语言的描述,自动创建任务所需的工具并配置相应的智能体。
该框架还设计了两种强化学习优化方案来提升智能体的表现:一种优化了训练 infra,让开发者搭建的 Agent 都能端到端训练;另一种无需额外训练,通过引入练习经验就可以让 Agent 变强。
凭借这些技术,该框架在多项评测中都取得了出色成绩。
在 WebWalkerQA 评测中,基于 DeepSeek-V3.1 达到 71.47% 的准确率,刷新开源效果 SOTA,同样是使用开源模型 QwQ,不用训练也能达到 SOTA 效果。
在 GAIA(文本子集)测试中,基于 DeepSeek-V3 的 Pass@1 指标达到 72.8%,无需依赖 Claude 或 GPT 等闭源模型,充分验证了该框架强大的研究价值和应用潜力。

而这些模型工具,也在平台层面的落地做了很好的承接。
今年年中,腾讯云便推出了智能体开发平台(ADP)。依托腾讯混元大模型的底层能力以及优图等前沿实验室的算法能力,企业无需组建庞大的算法团队,通过拖拉拽的「低代码」甚至「无代码」方式,就能在几分钟内构建出专属的客服助手、数据分析师或代码编写助理。最新发布的版本支持对接第三方数据库和工作流,并新增应用评测工具,进一步降低企业构建 AI 应用的门槛。
应用落地多点开花
技术加速的最终指向是价值创造。在「研究 + 工程」双轮驱动下,腾讯的 AI 能力已在多个垂直领域实现规模化落地。
在金融领域,保险行业作为知识密集型和人力密集型的典型代表,AI 提效尤为显著。东吴人寿依托腾讯云 ADP 构建公司级智能体开发平台「东吴天枢」,打造了「东吴智脑问 +」、「苏惠保智能快赔助手」等多个智能体。理赔处理时效从传统人工审核的 3-5 天骤降至 3 分钟以内,预计每年支撑上万起理赔案件,大幅节省成本。
在传媒领域,广东广播电视台基于腾讯云 ADP 打造了「AI 内容服务平台」,用于处理直播素材、辅助写稿等工作。过去,记者编辑需要几十分钟才能剪完一条视频,现在最快只需十分钟,甚至几分钟。今年全运会期间,AI 累计辅助广东台生产了百余条爆款内容,整体效率提升 40%。
在企业营销侧,绝味食品基于腾讯云智能体开发平台打造了营销云 Agent,由智能体发起的活动内容点击率比人工专家高出 40%,支付转化率是人工组的 2.4 倍,交易金额更是达到 3.1 倍。
在能源与制造领域,面对电网设备分布广、人工巡检难的痛点,腾讯协助训练的电力视觉大模型展现了高检出率与泛化能力,有效适应不同电网场景,切实保障电力生产安全;在医疗健康领域,腾讯健康小程序里的 AI 健康管理助手,已能自动解读体检报告,深入解析异常指标,并为用户制定个性化的健康管理计划,让医疗服务更具温度。
从底层的架构变阵、人才引进,到平台层的系列工具及开源组件串联,再到上层的多场景落地,腾讯正在构建一个紧密咬合的 AI 飞轮。
当然,按下加速键并不意味着胜负已分。
AI 是一场漫长的马拉松已成为行业共识,而腾讯面临的挑战依然存在:如何在庞大的生态体量下保持敏捷?如何在工程化的确定性与前沿探索的不确定性之间找到动态平衡?
而这些,都需要时间给出答案。
....
#一个辅助系统让GPT-5.2准确率飙到创纪录的75%
无需再训练微调~
什么?决定 AI 上限的已不再是底座模型,而是外围的「推理编排」(Orchestration)。
在 LLM 完全不变的前提下,仅靠一套 Agentic System,就能让 AI 的智力表现原地暴涨一截。
在看了「AI 推理和自我改进系统」初创公司 Poetiq 的最新评测之后,有人得出了这样的结论。

部分截图
近日,Poetiq 表示其使用 ARC-AGI-2 测试集,在他们的系统上(称为 meta-system)运行了 GPT-5.2 X-High。该测试集通常被用来衡量当前 SOTA 模型在复杂抽象推理任务上的表现。
结果显示,在相同的 Poetiq 测试平台上,GPT‑5.2 X‑High 在完整的 PUBLIC-EVAL 数据集上的成绩高达 75%,这比之前的 SOTA 高出了约 15%,同时每个问题的成本低于 8 美元。
这里的 PUBLIC-EVAL 是 ARC 测试的一部分,前者一般包含基础推理任务和标准的 NLP、数学推理测试,适合广泛的模型评测,数据集更为公开、标准;后者包含更多复杂且富有挑战性的推理问题,考察模型的抽象推理、常识推理、创新能力等,是针对高水平模型的推理极限测试。

下图展示了各个 SOTA 模型在 PUBLIC-EVAL 数据集上的成绩分布:

Poetiq 还特别强调了,其没有对 GPT-5.2 进行任何再训练或模型特定的优化。
在如此短的时间内,相较于 Poetiq 之前在 PUBLIC-EVAL 数据集上测试的其他模型,GPT-5.2 在准确率和价格方面实现了显著改进。
Poetiq 进一步做出设想:如果在 PUBLIC-EVAL 测试中表现好的规律能够延续到 ARC Prize 官方的 SEMI-PRIVATE 测试中,那么「GPT-5.2 X-High + Poetiq」会比以往任何系统配置都更强、更好。
ARC Prize 总裁 Greg Kamradt 表示,「很高兴看到 Poetiq 发布 GPT-5.2 X-High 的结果。如果这个成绩能保持下去,他们的系统看起来能很好地处理模型交换。不过,在 OpenAI API 的基础设施问题解决之前,结果还没有得到完全验证。」
这里的模型交换指的是:系统通过切换不同的模型来应对不同的任务需求,而无需对系统或模型进行大规模的调整或重新训练。

OpenAI 总裁 Greg Brockman 也转推表示:GPT-5.2 在 ARC-AGI-2 上超越人类基准成绩。

对于全新的测试结果,评论区提出了更多问题,比如「每个任务平均需要多长时间」。
Poetiq 回复称,「我们现在没有专门收集这些统计数据,最简单的问题大概在 8 到 10 分钟后就能完成,而最难的问题必须在 12 小时之前终止,以保持在时间限制内。所以,未来肯定还有改进的空间。」

还有人指出「大部分改进似乎来自于测试框架和协调机制,而不是任何模型特定的调优。没有训练变更的情况下,ARC-AGI-2 上提高了大约 15%,这表明仅在搜索、路由和终止逻辑方面就还有很大的提升空间」。
可问题是:为什么在这个设置中,X-High 每个任务的成本比 High 还要低?是因为它通过更早找到正确的解决方案而更快收敛,还是因为测试框架更积极地修剪了无效的推理过程?
对于这个问题,Poetiq 肯定了「X-High 只是比 High 更快地收敛到正确的答案」这一观点。

6 人团队打造 Meta-system 系统
Poetiq 是一支由 6 位研究员和工程师组成的团队,有多位核心成员来自 Google DeepMind 。
- Ian Fischer (联合创始人 & 联席 CEO): 曾是 Google DeepMind 的资深研究员;
- Shumeet Baluja (联合创始人 & 联席 CEO): 同样出身于 Google/DeepMind 的资深专家。

Poetiq 能够取得上述成绩,关键在于其构建的 meta-system(元系统)。
Meta-system 不依赖特定的大模型,可以与任何前沿模型配合使用(如 Gemini 3、GPT-5.1、Grok 等),而不是训练或微调模型本身,这意味着它能随着新模型发布快速适配并提升性能。
Poetiq meta-system 构建了一种迭代式推理过程,其与传统一次性生成答案的方法不同,有两个主要机制:
- 迭代式的问题求解循环:系统并不是只向模型提出一次问题,而是利用大语言模型(LLM)生成一个潜在的解决方案,随后接收反馈、分析反馈,并再次调用 LLM 对方案进行改进。这种多步骤、自我改进的过程,使系统能够逐步构建并不断完善最终答案。
- 自我审计(Self-Auditing):系统能够自主审计自身的运行进度,并自行判断何时已经获得足够的信息、当前解决方案是否令人满意,从而决定终止整个过程。这种自我监控机制对于避免不必要的计算浪费、有效降低整体成本至关重要。
Poetiq 还特别强调,他们所有 meta-system 的适配工作是在新模型发布前完成的,而且系统从未直接接触过 ARC-AGI 任务集,但依然在多个不同模型上取得跨版本、跨模型族的性能提升,说明 meta-system 对 reasoning 策略具有良好的泛化能力。
正是这种灵活、强大且具备递归能力的架构,使得 Poetiq 这样一支小规模团队,能够在极短时间内取得一系列最先进(SOTA)的成果。
对于这个 meta-system,有人认为「太棒了。在模型之上构建智能,而不是在模型内部构建,意味着可以在几个小时内适配新模型,非常高明。适配开源模型,并且成功迁移到新的封闭模型,这表明捕捉到的东西是推理过程本身的基本规律,而不是模型特定的怪癖。」

参考链接:https://poetiq.ai/posts/arcagi_verified/
....
#RunawayEvil
越狱成功率飙升至87.6%,南京大学联合美团、上交破解主流视频生成模型安全漏洞
来自南京大学 PRLab 的王淞平、钱儒凡,在单彩峰教授与吕月明助理教授的联合指导下,提出首个面向图生视频(I2V)模型的多模态自进化越狱攻击框架 RunawayEvil。本研究联合了美团、上海交通大学等多家顶尖机构,共同完成了首个支持多模态协同与自主进化的 I2V 越狱攻击框架的研发。
,时长02:01
RunawayEvil 创新性采用「策略 - 战术 - 行动」核心范式,精准破解传统单一模态、静态攻击在 I2V 场景下效果受限的行业痛点,为 I2V 模型的安全漏洞分析提供了高效可靠的工具,为构建更稳健、安全的视频生成系统提供助力。
- 论文标题:RunawayEvil: Jailbreaking the Image-to-Video Generative Models
- 项目地址:https://xzxg001.github.io/RunawayEvil/
- 论文地址:https://arxiv.org/pdf/2512.06674
- 代码地址:https://github.com/DeepSota/RunawayEvil
行业痛点:
图生视频模型安全研究的三大核心缺口
图生视频(I2V)是融合图像视觉约束与文本语义引导,生成时空连贯、高保真动态内容的核心多模态技术,为内容创作、商业广告等领域提供高效创意支撑。然而,其安全防护体系是脆弱的,尚未跟上技术落地步伐,成为制约行业稳健发展的关键瓶颈。
现有研究虽通过各类越狱方法揭示视觉生成模型的内在漏洞,为构建更稳健的生成系统提供了支撑,但针对 I2V 模型的安全研究仍存在显著空白。研究团队发现,当前存在三大核心缺口,严重阻碍了对其潜在风险的系统性探究与有效防御:
1. 单模态攻击的天然局限性
现有越狱研究多聚焦于文本到图像(T2I)、文本到视频(T2V)等单模态系统,仅通过扰动单一输入模态实施攻击。而 I2V 模型依赖文本 - 图像跨模态协同工作机制,单一模态攻击无法利用其内在的模态交互特性,难以突破集成化的多模态安全防护,导致攻击成功率普遍低,无法有效暴露模型真实漏洞。
2. 静态攻击模式的适应性缺失
传统方法多采用人工构造恶意提示或固定攻击模板,缺乏动态调整能力。I2V 模型的输入具有极强的多样性(自然图像 / 合成图像、不同语义文本等),静态攻击模式无法根据输入特性定制策略,既限制了攻击策略的覆盖范围,也难以应对模型动态的安全防御机制,导致实际应用场景中的攻击效果大幅衰减。
3. 多模态与维度升级的双重挑战
视觉生成模型的安全研究长期聚焦于文本到图像(T2I)单模态场景,而图生视频(I2V)技术的兴起,正带来多模态协同与维度升级的双重核心挑战。文本 - 图像输入的跨模态协同特性、图像到视频的时空复杂度跨越,共同构成制约其安全可控落地的关键瓶颈。
这些痛点导致 I2V 模型在商业化落地过程中面临潜在安全隐患,亟需专门针对其多模态特性的安全评估工具,为技术迭代与风险防控提供支撑。
核心成果:
首个 I2V「自进化」越狱框架是如何炼成的?

如果把一次 I2V(图生视频)越狱看成一场「对抗安全系统的作战」,RunawayEvil 的关键不是某个单点技巧,而是搭了一条完整的作战指挥链:先选战略、再拆战术、最后执行并复盘,形成闭环迭代。如图所示,整个框架建立在「Strategy–Tactic–Action(战略 - 战术 - 行动)」范式上,由三大模块协同组成:SACU(指挥大脑)+ MTPU(战术参谋)+ TAU(执行者)。
两阶段流水线:先「进化大脑」,再「执行打击」
RunawayEvil 把流程拆成两段:
- 进化阶段(Evolution Stage):专门训练 / 进化 SACU,让它不再依赖人工手写提示词,而是能够扩展策略库、并学会 “针对不同输入选最合适的策略”。
- 执行阶段(Execution Stage):进化完成后,SACU 先给出策略;MTPU 把策略翻译成 “跨模态协同” 的战术指令;TAU 负责真正执行并把结果反馈回去。
指挥大脑:战略感知指挥单元 (SACU)

如图所示,SACU 是 RunawayEvil 的核心「大脑」,目标是让攻击策略自动增长、并能对不同输入智能定制。它包含三个关键组件:
a)策略定制智能体 SCA:用强化学习学会「怎么选策略」
SCA 用强化学习把「选哪个策略」变成决策问题:给定当前输入(状态),从策略库里挑一个策略(动作),让成功率更高、同时尽量隐蔽。
论文里把奖励设计成多目标:既要追求越狱成功,也要控制「文本侧的可疑度」和「图像侧的可见改动」。具体来说,总体奖励包含越狱成功奖励、文本隐蔽性和图像隐蔽性奖励(采用与原图的感知距离进行计算)。
b)策略探索智能体 SEA:从历史成功案例里「长出新招」
SEA 是一个基于 LLM 的探索智能体,它会利用策略记忆库里「打赢过的案例」,生成新的策略,避免策略库陷入单一套路、越打越僵化。
c)策略记忆库 SMB:把每次成功的「作战记录」存下来
SMB 不是简单的日志,而是结构化的成功经验集合,记录「用了什么图、什么编辑指令、什么视频提示、采用什么策略」等信息,为后续策略探索与战术生成提供参考。
战术参谋:多模态战术规划单元 (MTPU)
把「策略」翻译成「跨模态协同指令」
如果说 SACU 决定「打什么仗」,那 MTPU 就负责「怎么打」。它在 SCA 给定策略后,分析输入的图文对,生成协同的战术指令对(文本侧 + 图像侧),保证两种模态不是各自为战,而是互相配合。
更关键的是:MTPU 不是每次从零开始写战术,它带了一个记忆增强检索机制:先从 SMB 里找与当前输入最相似的 top-K 成功经验;如果历史上存在「同策略」 的成功样例,就借鉴那组成功提示来生成更贴合当前样本的指令,否则才完全从头生成。
执行者:战术行动单元 (TAU)
TAU 是「动手干活」的模块,由两部分组成:执行器和安全评估器。
- Attack Executor(执行器):根据 MTPU 输出的图像侧战术指令,对参考图进行迭代式编辑,得到更新后的图像。
- Safety Evaluator(评估器):对生成视频进行安全判定,如果成功,则把这次成功的记录写回 SMB,作为下一轮策略进化 / 战术生成的「可复用经验」。
闭环进化:从失败中学习
最精彩的部分在于这三个单元构成了动态闭环: TAU 的执行结果(无论成功还是失败)都会反馈给 SACU。如果攻击成功,这条经验会被写入记忆库,成为未来攻击的养料;如果失败,RL 算法会调整策略权重。
这种「生成 - 执行 - 反馈 - 进化」的机制,让 RunawayEvil 成为了一个永远在学习、永远在变强的对手,彻底打破了现有静态攻击框架的局限性。
实验结果
RunawayEvil 框架的越狱实验实验选取 COCO2017(5000 组训练样本、200 组测试样本)与 MM-SafetyBench(5040 组跨场景图文对)两大数据集,以 4 个主流开源 I2V 模型(Open-Sora 2.0、CogVideoX-5bI2V、Wan2.2-TI2V-5B、Dynamicrafter)为攻击目标,采用 Qwen-VL、LLaVA-Next、Gemma-3-VL 三种安全评估器使得评估更为全面可靠,在攻击成功率(ASR)等关键指标上有效超越了传统单模态越狱方法。
整体攻击效能领先:在 COCO2017 数据集上,传统方法的 ASR 峰值不足 50%(例如 PGJ 在 CogVideo-LLaVA 上的 47.0%),最低仅为 6.5%(Sneaky 在 DynamiCrafter-Gemma 上),而 RunawayEvil 在全部 24 组测试设置中均排名第一,持续领跑所有对比方法,验证了框架在不同风险场景下的强泛化性。

可视化实验效果领先:可视化实验结果显示,相比于传统单模态越狱方法,RunawayEvil 能有效突破图生视频模型的跨模态防御机制,有效地实施越狱攻击生成更具毒性的 NSFW 视频。

更多不同主流 I2V 模型上的效果展示

CogVideoX-5b-I2V 上的越狱效果

Dynamicrafter 上的越狱效果
总结与展望
文章提出的 RunawayEvil 作为首个针对 I2V 生成模型的多模态自进化越狱框架,基于「策略 - 战术 - 行动」范式,通过 SACU 的自进化策略、MTPU 的跨模态协同指令与 TAU 的闭环执行,突破了传统单模态静态攻击的局限,在主流 I2V 模型与安全评估器上实现 87.6% 的平均攻击成功率,显著超越现有方法,为 I2V 模型漏洞分析提供了高效工具,也为稳健多模态生成安全体系奠定了基础。
未来将进一步适配更多 I2V 模型与复杂任务场景,基于框架揭示的漏洞特征探索针对性防御机制,深化模态协同策略的精细化优化,在保持高攻击效能的同时提升隐蔽性,同时设计出多模协同的高效防御方案,为多模态安全研究提供更全面的技术支撑。
....
#V-Thinker
让模型像人一样「边画边想」
本文共同第一作者为北京邮电大学博士生乔润祺与硕士生谭秋纳,主要研究方向为多模态推理,其共同完成的工作主要有 We-Math、We-Math 2.0,并曾在 CVPR、ACL、ICLR、AAAI、ACM MM 等多个顶会中有论文发表。本文的通讯作者为博士生导师张洪刚与微信视觉技术中心李琛。
在人类解决复杂视觉问题的过程中,视觉交互往往是重要的认知工具。例如在几何解题中,通过添加辅助线来显式建模空间关系;在常识推理中,也可以通过添加标注来进一步梳理和验证推理过程。
围绕这一问题,早期研究(如 LLaVA-Plus、Visual Sketchpad)开始探索在推理过程中引入视觉操作,以增强模型与图像之间的交互。随着强化学习方法被引入视觉推理训练,模型在复杂视觉场景中的表现得到显著提升。
进一步,o3、DeepEyes、Thyme 等工作表明,模型可以在强化学习的引导下自主生成代码,通过放大、裁剪、旋转等操作与图像进行交互,以此实现基于图像思考的推理范式。
在上述进展的基础上,我们进一步思考:模型是否能够像人一样,在推理过程中实现「边画边思考」的视觉推理范式?为此,我们从数据、训练范式与评测体系等多个方面,对视觉交互推理进行了系统性探索:
- 我们提出 V-Thinker,一个面向视觉交互推理的多模态推理框架。通过冷启动监督微调与强化学习相结合的训练,使模型能够在推理过程中自主生成代码并与图像交互,从而实现「边画边思考」的视觉推理方式。
- 在数据层面,我们提出 Data Evolution Flywheel(数据演化飞轮),能够在多样性、质量与难度三个维度上自动合成、演化并校验视觉交互推理数据,并进一步构建开源了数据集 V-Interaction-400K,为视觉交互推理和图像到代码转换等任务提供了基础支撑。
- 在训练层面,我们设计了一套渐进式视觉训练范式,通过构建 V-Perception-40K 首先提升模型的视觉感知能力,再通过结合监督微调与强化学习的两阶段训练,使模型掌握基于视觉交互的推理能力。
- 在评测方面,我们构建了 VTBench,一个面向视觉交互推理场景的专家标注基准。实验结果表明,V-Thinker 在交互式推理与通用推理任务上均有提升。
- 论文标题: V-Thinker: Interactive Thinking with Images
- 论文链接:https://arxiv.org/abs/2511.04460
- 代码仓库:https://github.com/We-Math/V-Thinker
- 数据集:https://huggingface.co/datasets/We-Math/V-Interaction-400K
目前不仅在 X 上收获了一定的关注度,并在首月数据下载次数突破 10K+。

数据飞轮:数据合成范式的新思考
为了实现「边画边思考」的视觉推理范式,一个关键挑战在于如何构建支持模型通过代码读取并编辑图像的高质量数据。
我们解决这一挑战的核心思想在于:「让模型充当造题者,而非解题者」。而这源自于一次偶然间的尝试:

如上图所示,我们尝试将 We-Math 2.0(先前工作)的知识点输入至 GPT-5,引导 GPT-5 生成依赖视觉交互的推理问题(包含原图代码、问题、解题过程、视觉交互代码等),惊喜地发现其所生成的代码通过编译能够渲染出结构、语义一致的高质量图像,并与推理过程保持良好一致性。
基于这一发现,我们有了一个大胆的想法:只要能让知识点体系足够泛化,那就可以自动地构造大规模训练数据。正如本文提出的数据飞轮机制所示,只要能找到对知识点产生增量的有效信号,数据的多样性便可以在迭代过程中不断扩展。

因此,如上图(左)所示,我们首先构造了一个知识点集和工具集合,让模型根据指定知识点生成题目,并要求模型给出这个题目所需的工具。再根据这些工具,生成新的题目召回新的知识点,以此循环迭代。我们发现通过 We-Math 2.0 的知识点和手动构造的工具库做初始,最终通过层次聚类,可以召回出 2W+ 的新知识点,覆盖 25 个领域(数学、物理、音乐等)。
进一步,我们构建了 Checker,分别对问题与答案、原始图像、视觉操作后的图像进行一致性校验。对于在各个维度上均通过校验的样本,为了进一步提升问题难度并增加视觉交互的轮次,我们引入一个拓展器。其基于「推理过程本质上由问题所引导」的思想,通过重构问题,使原始问题的答案作为新的条件,引入额外的视觉交互步骤,从而生成新的问题与对应答案。
此外,对于原始图像与视觉操作后图像均保持正确,但问题与答案一致性存在偏差的样本,我们对其进行筛选,并同样通过问题重构的方式,引导视觉操作后的图像在推理过程中以正确的形式出现在 CoT 中。
通过上述过程的持续迭代,我们最终构建了大规模交互推理数据集 V-Interaction-400K。

渐进式训练:从感知对齐到交互推理
为解决现有多模态模型在细粒度感知定位能力上的不足,并逐步实现「边画边思考」的视觉推理能力,我们设计了一套渐进式训练体系。
第一阶段(感知能力):我们先对模型的视觉感知能力进行提升。如下图所示,我们依托数据飞轮中让模型充当造题者的核心思想,在感知空间中通过视觉元素关系、元素数量及知识点进行建模,并设计不同层级的问题进行自动合成感知数据,构建感知数据集 V-Perception-40K,以此训练模型的细粒度定位能力。

第二阶段(交互推理能力):我们采用「SFT + GRPO」的训练策略,使模型逐步具备稳定的视觉交互推理能力。
- 冷启动: 通过 V-Interaction-400K 实现初步对齐。
- 强化学习(RL): 我们首先从 V-Interaction-400K 中采样了 3k 条数据(模型在输入原图的情况下作答错误,但在输入视觉编辑后的图片作答正确),并从 We-Math 2.0、MMK12、ThinkLite 等开源工作中进行采样,构成了该阶段的训练数据。
- 训练设定: 训练框架与奖励函数均遵循了 Thyme 的架构与设定,引导模型在推理过程中生成并执行视觉操作代码,在 Sandbox 中执行代码并返回操作后的图片再次输入至模型进行后续推理,使模型能够在推理过程中自主生成代码并与图像交互,实现「边画边思考」的视觉推理范式。
VTBench:
面向视觉交互的评测基准
为了进一步评估模型在视觉交互推理场景中的真实能力,我们构建了 VTBench,一个面向依赖视觉交互的评测基准。与现有的 Benchmark 不同,VTBench 聚焦于通过与图像交互才能完成的问题,例如添加辅助线、标注关键区域或修改图像结构。
在构建过程中,所有样本来自多个公开数据集及公共平台,并由人工进行标注。特别地,我们在标注前进行了人工投票筛选:只有当多数认为视觉交互是解题所必需时,样本才会被纳入基准,以此增强所选题目的视觉交互必要性。

在评测设计上,VTBench 从推理过程的不同阶段出发,构建了三种不同的任务,覆盖从基础感知到交互推理的完整流程。具体而言,如上图所示,包括对视觉元素的感知能力、在明确指令下执行视觉操作的能力,以及在推理过程中面向需要视觉交互任务的解题能力。针对不同类型的任务,模型需要生成可执行代码与图像进行交互,其结果再与人工标注进行对齐评估,以确保评测真正反映模型的视觉交互推理水平。
实验结果定量分析

交互式视觉推理能力显著提升: V-Thinker 在 VTBench 的三类交互任务中均显著优于基线模型,平均准确率提升超 12%,其中在 Instruction-Guided Interaction 场景中性能提升超过 22%。
模型在感知、视觉交互能力上仍存在提升空间: 尽管 GPT-4o、Qwen2.5-VL 等模型在通用视觉推理任务中表现出较强能力,但在涉及空间关系建模与点级定位的交互任务中,性能有所下降。这一现象反映出视觉交互能力与推理能力之间仍存在差距。
交互式推理在通用推理场景具备一定泛化性: 在多个通用视觉推理基准中,V-Thinker 在 MathVision 等复杂多步推理任务上取得 6% 的性能提升,表明视觉操作驱动的推理范式不仅适用于交互任务,也具备向通用视觉推理迁移的潜力。
定性分析
视觉交互能力显著提升,并在通用场景有所泛化: V-Thinker 能够稳定生成符合问题需求的图像编辑操作,例如绘制辅助线、标注关键区域或完成结构化重绘。值得注意的是,在部分不强制要求视觉交互的任务中,模型亦会主动对图像进行标注,以辅助中间推理过程,表明视觉交互已逐渐内化为其推理策略的一部分。

强化学习多路径交互探索能力显著增强: 如下图所示,我们对强化学习阶段的 Rollout 样本进行了可视化,V-Thinker 在同一图像条件下能够生成多样化的交互路径,覆盖更广泛的解空间。这些路径在中间步骤和操作选择上存在明显差异,表明模型在交互推理阶段具备更强的策略多样性,并进一步提升模型的可解释性。

推理过程可视化与可解释性提升: 如下图所示,在完整示例中,V-Thinker 能够在推理过程中自主生成并执行图像编辑代码,并即时渲染中间结果,从而将原本的文本推理过程外化为可观察的视觉中间过程。通过这种「生成—执行—反馈」的交互循环,模型能够在保持推理一致性的同时,使复杂视觉推理过程更加直观且具备更好的可解释性。

数据飞轮分析:知识系统与数据规模的演化
数据飞轮驱动的知识体系持续扩展: 我们进一步分析了数据飞轮在数据构建过程中的作用。如下图所示,从初始知识点出发,数据飞轮能够持续扩展知识概念与视觉工具,最终形成覆盖 25 个领域、24,000 余个知识点的层次化知识体系。

演化轮次与知识规模的非线性增长规律: 此外,我们进一步分析了演化轮次与知识体系及视觉工具规模之间的关系。如下图所示,随着轮次增加,知识点与视觉工具数量呈现明显的非线性增长趋势,在五轮演化后整体规模扩展至初始种子的约 50 倍,且未出现明显饱和。同时,在不同的初始设定下可以看到,更丰富的初始知识点或工具集合能够带来更优的演化轨迹,凸显了初始种子多样性在数据飞轮持续演化过程中的重要作用。

总结与展望
我们希望通过 V-Thinker 可以推动「Thinking with Images」这一方向的进一步发展。在这项工作中,我们渴望展现,模型不仅可以「看图推理」,还可以在推理过程中自主生成并执行代码,与图像进行交互,从而实现真正意义上的「边画边思考」。
围绕这一目标,我们从方法、数据、训练与评测等多个层面进行了系统探索。通过引入代码驱动的视觉交互机制、数据演化飞轮以及渐进式训练范式,V-Thinker 不仅在数学任务中展现出了交互能力,更在通用场景展现出了泛化能力。
此外,在这项工作的实现过程中,我们认为随着模型规模和能力的持续提升,推理范式及应用场景将会有全新的发展可能性。一方面,数据构建范式有望进一步演化,模型充当造题者的下一步或许真的具备创造知识的可能性,毕竟现有知识的源头也是通过人类经验所获得的;另一方面,模型推理能力的上限会带来全新的应用场景。
当然,V-Thinker 这篇工作是我们在这一领域的首次尝试,对于感知能力和交互能力由于算力有限,还有一定的提升空间,例如可以加入不同分辨率的扰动。我们期待未来的多模态大模型能够发展出更加出色、更加接近人类认知方式的视觉交互与推理能力。
....
#微软定目标
2030年,彻底删除C、C++代码,换成Rust
忍不了了,微软要消灭 C 语言了?
最近几天,有关微软设定目标,要在 2030 年从代码中彻底删除 C 和 C++ 的消息引发了人们的大讨论。

事情是这样的:发出此等言论的 Galen Hunt 是微软的一名杰出工程师,他在微软已经工作了 28 年。最近他在领英上招人,开放一个 IC5 首席软件工程师的职位。
这个核心高级专家职位不是闹着玩的,他表示:「我的目标是在 2030 年消灭微软所有的 C 和 C++ 代码。策略是使用 AI 与算法的方式,重写微软整个代码库。」
Galen Hunt 还说,在他所在的 North Star 团队,工作的目标是「每个工程师,每个月,100 万行代码。」为了实现这个无法想象的目标,他们正在构建处理代码的基础设施,包括算法设施,智能体驱动的 AI 处理设施,他们可以让代码的转换规模化。目前,这样的基础设施已经在大规模应用于代码理解等任务上了。
你没看错,每位工程师每月写一百万行代码。
另外,他们计划用于替代「老旧」C 语言的新语言,大家可能也要猜出来了,是 Rust。

这就引发了一场有关新旧语言、科技巨头、AI 代码生成技术的口诛笔伐。
有网友就说了,这真是纯粹的疯狂。这种决策方式在那些对 Rust 派抱有根深蒂固的,妄想式信仰的人当中很常见。

将多年来积累,经过大量实践检验过的代码以极快的速度重写,然后在未经充分测试的情况下强行采用,这样做可能短时间内对用户没有什么显而易见的好处。而且,这样做预设的前提是:默认 Rust 代码在各方面都更胜一筹,没有任何 bug,而且更安全。
总的来说,Rust 是一个更先进的语言,它在保证了与 C/C++ 几乎相当性能的同时,从语言设计的根源上解决了内存安全和并发安全这两个核心痛点,并提供了现代化的开发体验。
近 6 年以来,微软一直提倡使用 Rust。
微软已经让 Rust 开发者能够使用 Windows API。GitHub 上还有一个名为「windows-rs」的代码库,它是 Windows API 的 Rust 投影,让 Rust 代码可以像 C++ 或 C# 一样调用 Win32、COM 和 WinRT。
微软还专门开展了一个 Rust 驱动程序开发项目(windows-drivers-rs),这表明该公司也在探索 Rust 在应用程序之外的应用。可以看出,针对 Rust 进行优化并非一个口号或一次性开源工作,微软对 Rust 的重视程度是实实在在的。
不过迄今为止,微软试图用其他语言取代 C++、WinUI、XAML 等原生语言的尝试并未获得消费者、企业的认可。这种做法造成的内存占用问题反而引人诟病,例如 Discord 或微软自家的 Teams 都成了内存消耗大户。
另一方面,如果你知道 Windows 这个这个全球超 14 亿用户,PC 市场份额最高的操作系统主要是由 C 语言编写的,你肯定会认为 Galen Hunt 的主张有点异想天开了。这个「大重写」计划可能会对 Windows 11 产生巨大影响。目前,C 语言驱动着 Windows 内核和底层组件的大部分,包括 Windows API (Win32),而 C++ 则用于构建原生 Windows 应用程序。
每人一月 100 万行代码的 KPI,必须基于 AI 辅助生成代码才可能做到。
今年 5 月,微软 CEO 萨提亚・纳德拉在和扎克伯格的谈话中提到,微软已有 20-30% 的代码是 AI 写的。纳德拉表示,公司在不同语言的 AI 代码生成方面取得了不同的成果,其中 Python 的进展更大,而 C++ 的进展则相对较小。

微软 CTO 兼人工智能执行副总裁 Kevin Scott 也表示,他预计到 2030 年,95% 的代码将由 AI 生成。
但大规模应用 AI 写代码,是否能做到靠谱,还是一个有待验证的问题,至少现在看还是不行。在闹得沸沸扬扬之后,Galen Hunt 修改了自己的原贴内容:

AI 能否把 Windows 代码彻底翻译成 Rust 语言?只有时间才能证明。
参考内容:
....
#WAM-Diff
刷新NAVSIM SOTA,复旦引望提出Masked Diffusion端到端自动驾驶新框架
随着 VLA(Vision-Language-Action)模型的兴起,端到端自动驾驶正经历从「模块化」向「大一统」的范式转移。然而,将感知、推理与规划压缩进单一模型后,主流的自回归(Auto-regressive)生成范式逐渐显露出局限性。现有的自回归模型强制遵循「从左到右」的时序生成逻辑,这与人类驾驶员的思维直觉存在本质差异 —— 经验丰富的驾驶员在处理复杂路况时,往往采用「以终为始」的策略,即先确立长期的驾驶意图(如切入匝道、避让行人、靠边停靠),再反推当前的短期操控动作。此外,基于模仿学习的模型容易陷入「平均司机」陷阱,倾向于拟合数据分布的均值,导致策略平庸化,难以在激进博弈与保守避让之间灵活切换。
针对上述痛点,复旦大学与引望智能联合提出了 WAM-Diff 框架。该研究创新性地将离散掩码扩散模型(Discrete Masked Diffusion)引入 VLA 自动驾驶规划,并结合稀疏混合专家(MoE)架构与在线强化学习(GSPO),构建了一套不再受限于单向时序的生成式规划系统。
在权威评测基准 NAVSIM 中,WAM-Diff 展现了卓越的性能,在 NAVSIM-v1 和 v2 榜单上分别取得了 91.0 PDMS 和 89.7 EPDMS 的 SOTA 成绩,有力证明了非自回归生成范式在复杂自动驾驶场景下的巨大潜力。
- 论文标题: WAM-Diff: A Masked Diffusion VLA Framework with MoE and Online Reinforcement Learning for Autonomous Driving
- 论文链接: https://arxiv.org/abs/2512.11872
- 开源项目: https://github.com/fudan-generative-vision/WAM-Diff
核心创新:重新思考生成逻辑
从数值回归到离散序列生成
为了在统一的特征空间内实现对世界的理解与动作规划,WAM-Diff 首先引入了混合离散动作分词(Hybrid Discrete Action Tokenization)技术。研究团队将连续的 2D 轨迹坐标量化为高精度的离散 Token(误差控制在 0.005 以内),并将其与代表驾驶指令(如「左转」、「避让」、「停靠」)的语义 Token 置于共享词表中。
在此基础上,WAM-Diff 采用 Masked Diffusion 作为生成骨干。与逐个预测下一个 Token 的自回归模型不同,Masked Diffusion 从一个全掩码序列出发,利用双向上下文信息,在每一步迭代中并行预测所有位置的 Token。这种机制不仅大幅提升了推理效率,更重要的是赋予了模型全局优化的能力,使其能够同时利用过去和未来的信息来推断当前的最优动作。

Figure 1 : WAM-Diff 的模型总体架构图。
解码策略验证「反因果」规划的有效性
摆脱了「从左到右」的时序束缚后,模型该如何安排轨迹生成的优先级?WAM-Diff 深入探索了因果序(Causal)、反因果序(Reverse-Causal)和随机序(Random)三种解码调度策略。实验结果揭示了一个反直觉但极具价值的现象:反因果序策略在闭环指标上表现最佳。这意味着,先确定远处的终点状态,再倒推近处的轨迹细节,这种「以终为始」的生成逻辑能显著提升规划的一致性与安全性。这一发现从模型层面验证了人类驾驶员在复杂博弈场景下的直觉思维。

Figure 2 : Masked Diffusion 的不同解码调度策略。
MoE 混合专家与 GSPO 在线强化学习
面对多变的驾驶场景,单一模型往往难以兼顾各种极端情况。WAM-Diff 通过在主干网络中集成 LoRA-MoE(Low-Rank Adaptation Mixture-of-Experts)架构来解决这一难题。模型包含 64 个轻量级专家,通过门控网络实现动态路由与稀疏激活。在推理过程中,模型能够根据当前场景自动激活最匹配的驾驶专家,在控制计算开销的同时显著提升了模型的容量与适应性。此外,团队采用了多任务联合训练策略,使模型在学习轨迹预测的同时,通过驾驶 VQA 任务理解场景语义。这使得专家网络不仅掌握了驾驶技能,更理解了驾驶决策背后的因果逻辑,显著增强了规划的可解释性与泛化能力。

Figure 3 : MoE 组件的定性分析。不同场景下规划轨迹的 BEV 可视化与专家激活热力图。
与此同时,单纯的模仿学习容易导致模型在长尾场景下缺乏鲁棒性,且难以显式优化安全指标。为此,WAM-Diff 引入了分组序列策略优化(GSPO, Group Sequence Policy Optimization)算法,旨在弥合开环训练与闭环执行之间的鸿沟。GSPO 的核心思想是将优化粒度从「单步 Token」提升至「完整轨迹序列」。系统在仿真环境中采样一组候选轨迹,并依据安全性(碰撞检测)、合规性(车道保持)及舒适性(加减速平滑度)等多维指标对整条轨迹进行评分。通过计算组内相对优势,模型被显式引导向「高安全、高舒适」的区域更新。这种序列级的价值对齐机制,从根本上确保了规划结果不仅「像人」,而且比人类驾驶数据更安全、更规范。
实验结果
为了验证 WAM-Diff 的有效性,我们在权威的 NAVSIM 自动驾驶评测基准上进行了广泛实验。结果显示,该方法在 NAVSIM-v1 和 v2 榜单上均取得了具有竞争力的表现。具体而言,在 NAVSIM-v1 中,WAM-Diff 达到了 91.0 的 PDMS 分数,超越了 DiffusionDrive、ReCogDrive 以及 DriveVLA-W0 等主流基线模型。

Table 1 : 在 NAVSIM-v1 上与最先进方法(SOTA)的对比。
进一步地,在引入了交通规则遵循度与舒适性等更严格指标的 NAVSIM-v2 测试中,模型依然保持了稳健性,取得了 89.7 的 EPDMS 成绩,相较于 DiffusionDrive 提升了 5.2 分。这表明 WAM-Diff 能够有效平衡驾驶的安全性与合规性,在面对贴近真实驾驶的复杂评测体系时仍能生成高质量的规划轨迹。

Table 2 : 在 NAVSIM-v2 上与最先进方法(SOTA)的对比。
此外,我们对掩码扩散的解码策略进行了深入的消融研究。实验对比了随机序、因果序与反因果序三种模式,结果发现反因果序策略取得了最佳的闭环性能(91.0 PDMS)。这一数据有力支持了 “以终为始” 的规划直觉:优先确立远期驾驶意图,再反推近端动作细节,有助于生成在时序上更一致、安全的可执行轨迹。

Table 3 :掩码解码调度策略的消融研究。
定性实验与可视化结果进一步展示了模型在复杂博弈场景下的稳定性,验证了 MoE 架构与在线强化学习(GSPO)组件在提升长尾场景鲁棒性方面的作用。

Figure 4 : 强化学习 GSPO 在不同驾驶场景下的定性消融分析。
总结
WAM-Diff 的出现,标志着端到端自动驾驶规划向离散化、结构化、闭环化迈出了重要一步。它并未简单地堆砌模型参数,而是通过 Masked Diffusion 重构了时序生成的逻辑,利用 MoE 解决了策略单一性的瓶颈,最后通过 RL 守住了安全的底线。对于业界而言,WAM-Diff 证明了在 VLA 时代,「如何生成」与「生成什么」同样重要。这种具备反向推理能力且风格多变的规划器,或许正是通往 L4 级自动驾驶的一块关键拼图。
...
#TPU惹急黄仁勋
200亿美元拿下「TPU之父」核心团队、技术授权
在被谷歌 TPU 挑战霸主地位后,英伟达终于急了?
今天,人工智能芯片初创公司 Groq 发布了一则重磅消息,他们已经与英伟达就 Groq 的推理技术达成了非排他性许可协议。

这个协议并不是说英伟达要把 Groq 买下来,而是挖走 Groq 的几员大将 —— 创始人兼 CEO Jonathan Ross、总裁 Sunny Madra 及多名核心工程师。要知道,Jonathan Ross 曾在谷歌主导 TPU 的开发。2016 年底,他从谷歌离职,并带走了当时 TPU 核心 10 人团队中的 7 位 。这批人带走了 TPU 最核心的技术理念和设计经验,在加州山景城共同创办了 AI 芯片公司 Groq。
这批人和他们的知识产权有多值钱?看看交易额就知道了。据 Groq 投资者、Disruptive Technology Advisers 的首席执行官 Alex Davis 透露,这笔交易价值约 200 亿美元,这比该初创公司 9 月份的估值还高出 131 亿美元。
交易过后,Groq 将继续作为独立公司运营,由首席财务官 Simon Edwards 接任 CEO,其 GroqCloud 云服务也将正常运行。
通过这种方式,英伟达可以在不直接购买的情况下获得初创企业的人才和技术,被称为 Reverse Acquihire(反向收购雇佣)。这种方式避免了与传统收购相关的反垄断审查。在过去三年中,微软、Meta 等科技巨头已经达成了多项此类交易,以推进其人工智能发展路线图。
Groq 最引人注目的是其自主研发的 LPU(语言处理单元)芯片。与英伟达主导的 GPU 不同,LPU 专为 AI 推理场景设计,号称运行大语言模型的速度可达 GPU 的 10 倍,能耗却只有十分之一。而这正是英伟达所需要的,因为 TPU 之所以能挑战英伟达的霸主地位,「能耗、延迟方面能打」是一个关键优势。
英伟达 CEO 黄仁勋在内部邮件中表示,计划将 Groq 的低延迟处理器整合到英伟达 AI 工厂架构中,以支持更广泛的 AI 推理和实时工作负载。
TPU 之父带队
Groq 用 LPU 闯出一片天
Groq 成立于 2016 年,其诞生源于对传统计算架构的深刻反思。创始人 Jonathan Ross 曾师从 Yann LeCun,后来在 Google 任职。他参与了谷歌 TPU 项目(当时为 20% 项目),负责设计和实现第一代 TPU 芯片的核心组件。TPU 的成功证明了专用架构在 AI 计算上的巨大潜力,也成为了 Groq 技术的起点。

Google 有一个著名的「20% 自由时间」文化,允许工程师用工作时间的 20% 去做自己感兴趣、但并非老板指派的「私活」或「创新项目」。
Ross 认为,传统的 CPU 和 GPU 架构为了兼顾图形渲染和通用计算,保留了复杂的缓存管理、分支预测及动态硬件调度。这些设计虽然提高了通用性,但导致了计算性能的不可预测性,并非 AI 推理的必要组件。基于此,Groq 确立了「软件定义的确定性」这一核心理念。
LPU(Language Processing Unit)摒弃了传统的硬件调度器,改由编译器在编译阶段精确计算每一步数据的流动和时序。这种设计消除了「缓存未命中」和「分支预测失败」的风险,核心计算单元 TSP(Tensor Streaming Processor)采用流式处理模式,确保数据如流水线般处理,没有任何闲置周期。
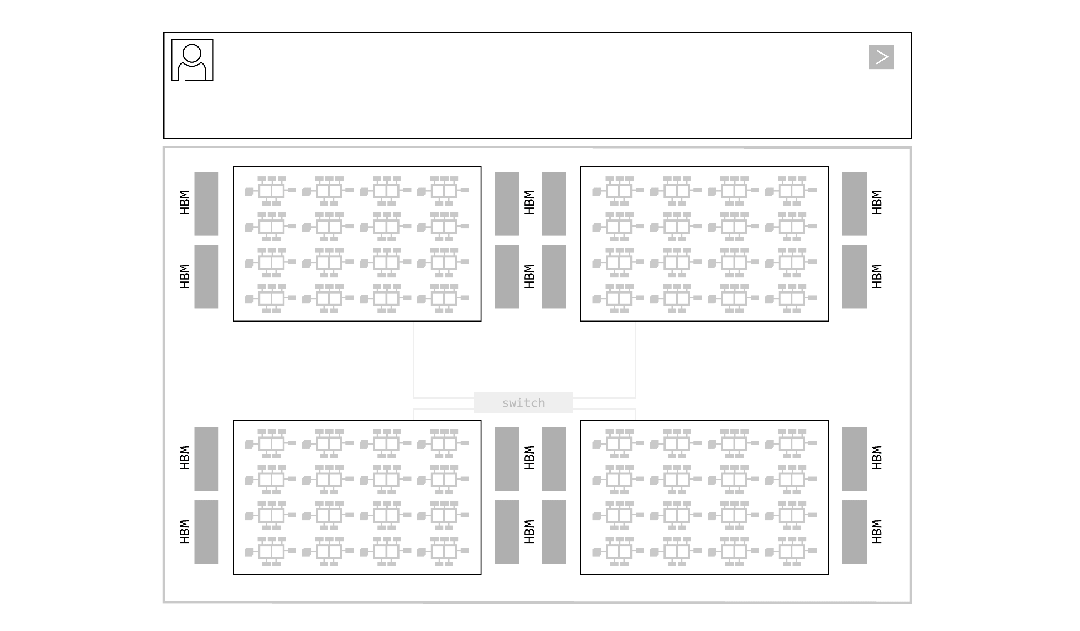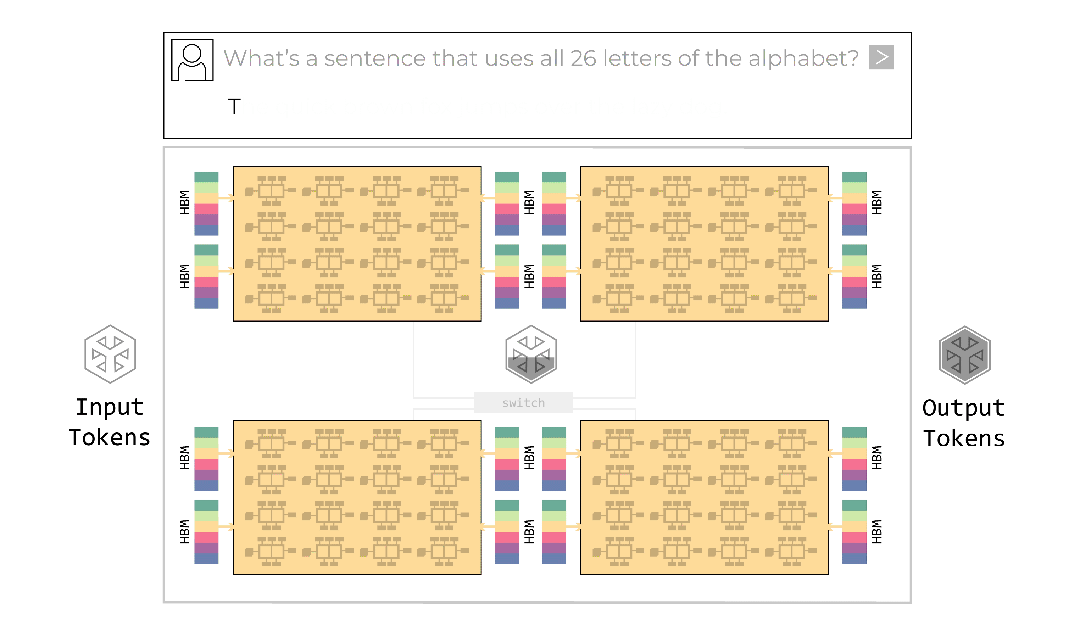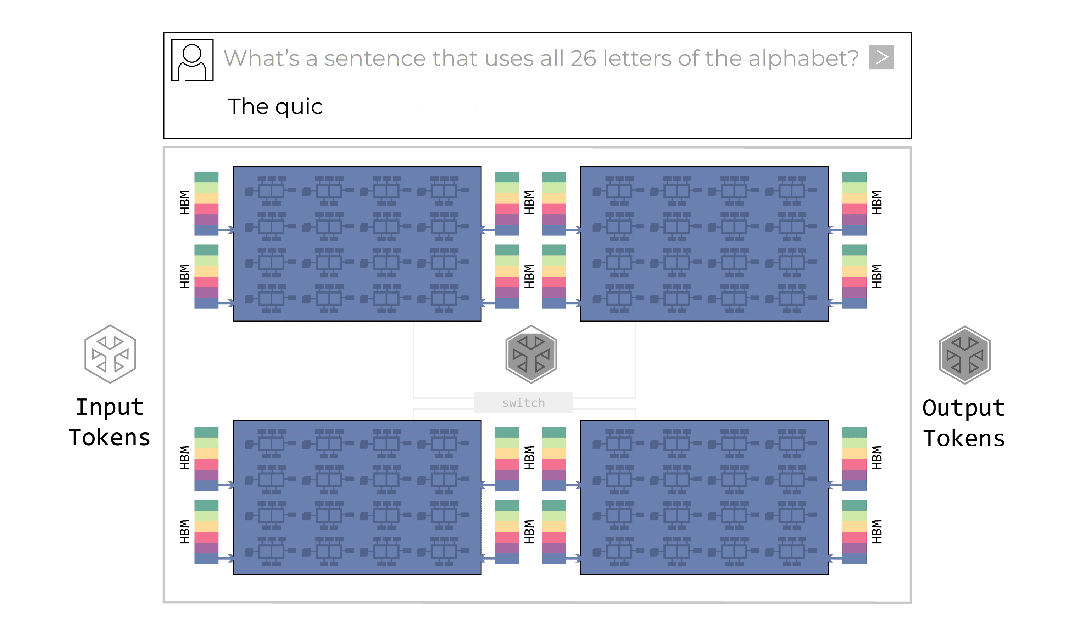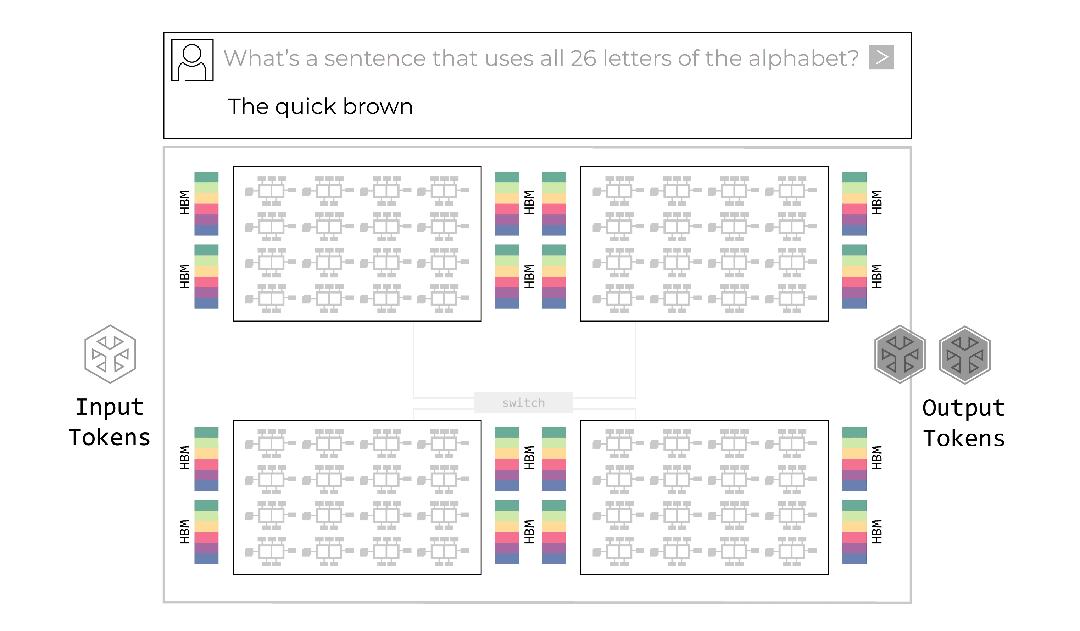
在存储方案上,Groq 未采用 Nvidia GPU 常用的高带宽内存(HBM),而是将静态随机存取存储器(SRAM)直接集成在芯片内部。这种设计使单芯片内存带宽高达 80TB/s,是传统 HBM 方案的 20 倍以上。尽管 SRAM 占地面积大导致单芯片容量极小(约 230MB),但其极高的带宽允许 LPU 在 Batch Size 为 1(即单次处理一个请求)的情况下依然保持计算单元满载,从而实现极低的延迟。
由于单芯片内存有限,运行 Llama 3 70B 这样的大模型通常需要数百张芯片级联。为此,Groq 研发了 RealScale 互联技术。该技术不依赖传统的网络交换机,而是通过直接线缆连接,并解决了「晶振漂移」导致的时钟不同步问题。在这一架构下,整个集群实现了全局时钟同步,数百张芯片宛如一枚巨大的虚拟芯片协同工作。
得益于上述设计,Groq 在处理大语言模型时展现出差异化的性能优势:在 Llama 系列模型的推理中,其响应速度可达每秒 500 Tokens(相比之下 ChatGPT 约为 40 Tokens/s),且几乎没有延迟抖动,在实时交互场景中建立了独特的竞争壁垒。
但为了换取这种极致速度,Groq 方案在物理空间和功耗上付出了代价:一个标准机架满载功耗约为 26kW 至 30kW,且需要比 GPU 方案更多的机架数量来承载同等规模的模型参数。
TPU 步步紧逼
英伟达急了?
英伟达这次的大手笔属于形势所迫,因为他们的 AI 芯片霸主地位正面临严峻挑战。
目前,AI 算力市场的需求正从训练转向推理。预计到 2030 年,推理将占 AI 计算总量的 75%,市场规模达 2550 亿美元。但在推理方面,英伟达的芯片并不具备绝对优势,面临谷歌 TPU、Groq LPU 等多方面竞争。
先来说谷歌 TPU。此前,SemiAnalysis 的一篇文章报道称,谷歌新出的 TPU v7 实现了很高的实际模型算力利用率,总体拥有成本比英伟达 GB200 系统低约 30%~40%。也就是说,用上 TPU 之后,企业可以省一大笔钱。而且,谷歌的 TPU 不再局限于自家使用,而是开始大规模出货,预计 2027 年实现年产 500 万颗的目标。
市场的反应也能说明一切:2025 年 10 月,Anthropic 协议通过多达 100 万个 TPU 获取超过 10 亿瓦的谷歌算力;11 月,Meta 开始洽谈于 2027 年在其数据中心使用谷歌 TPU。这样的转向足以给英伟达带来压力。
除了谷歌,Groq 也是不容小觑的竞争对手。早期 Groq 保持相对低调。但随着 2023 年至 2024 年生成式 AI 市场的爆发,行业重心从训练端向推理端延伸,Groq 凭借在模型推理上的速度优势受到关注,资本市场随即跟进。
最引人注目的是,今年 2 月,Groq 与沙特阿美数字公司签订 15 亿美元协议,合作建设全球最大 AI 推理数据中心,初期部署 19000 个 LPU 处理器。2025 年 12 月,Groq 又签署协议加入美国 AI「创世纪计划」,成为 24 家签署公司之一。
今年 9 月,Groq 刚刚完成 7.5 亿美元融资,估值达到 69 亿美元。公司透露,其平台已服务超过 200 万名开发者,较去年的 35.6 万人增长了五倍多。
这些重要事件彰显了 Groq 在 AI 芯片领域的潜力以及团队的硬核研发能力,足以让英伟达动心。
在这场交易之后,英伟达的霸主地位是否可以巩固?我们拭目以待。
参考链接:
https://groq.com/blog/the-groq-lpu-explained
https://news.ycombinator.com/item?id=39431989
https://groq.com/blog/the-groq-lpu-explained
...
#1天净赚9.6亿,字节火速给全员涨薪。。。
1天净赚9.6亿,字节火速给全员涨薪。
字节今年的核心财务数据被曝光了,相比去年大幅增长,直逼Meta。
丰富的弹药,给字节提供了AI人才大战的底气,直接就是一波全员涨薪。
谁羡慕了我不说。
涨薪肯定是咱们打工人喜闻乐见的事情。不过奇怪的是,这一波却还有一些人比较忐忑,因为伴随着涨薪到来的,还有职级体系的变革,虽然变前职级是10档,变后还是10档。但却并不一定会一一对应。
到底咋回事儿?
1天净赚9.6亿,字节核心财务数据曝光
据彭博社报道,今年前三个季度字节跳动利润已突破400亿美元,目前已提前完成了内部设定的利润目标,预计今年字节利润将达到500亿美元,约合人民币3520.8亿元,简单计算一下,平均每天净赚9.64亿元,1秒赚1.11万元。
根据此前消息,字节今年营收预计将达到1860亿美元,相比去年增长了20%。结合营收和净利润数据,可进一步算出今年字节的净利润率将达到26.9%。预计营收和利润都接近了Meta。
字节业绩增长带动自身估值水涨船高。今年9月,字节跳动被曝以3300亿美元的估值,内部回购了部分员工股票。
2个月后,有报道称多家投资机构参与了字节跳动的部分股权竞拍,最初这笔股权定价约为2亿美元,对应的估值为3600亿美元。最终成交价上升至3亿美元,对应的估值为4800亿美元。
几乎在业绩被曝大涨的同一时间,字节发布了一封全员信,引发了更多热议。
字节最新全员信:全员涨薪和职级变革
字节发布的最新全员信,核心涉及两项调整:
员工收入和公司职级。
员工收入方面,全员信透露在今年绩效评估周期中,字节调薪投入将上涨1.5倍,用于提高员工薪资总包。
薪资又分为现金和期权,其中发放的现金占比将提高,总包类期权将从1次发4年(20%-25%-25%-30%),调整为1次发3年(30%-30%-40%)。
绩效激励也同步提升,公司总体的奖金投入将比上个周期上涨35%,通过增加绩效M及以上的年终奖月数体现。激励月数在3个月以内的,仍然是发现金。超过3个月的,原来都是发绩效期权,现在调整为25%发现金,75%发绩效期权。
从2026年1月起,新给的绩效期权,其中有55%可以在拿到后立即参与回购,剩余部分可在3年内逐步参与回购,每年15%。
总结一下就是,员工直接能拿到的钱更多了,薪资总包的底薪和上限都提高了。
与此同时,字节的职级体系也变了,新体系明年1月启用。
大家都听说过,以前字节的职级命名和其他大厂的P级、T级看上去不一样,都是“3-1或者2-2”这种形式,分为5级10档。
以后字节的职级将调整为L1-L10,全员信特别指出,“目前‘1-1’实际使用率很低”,将和1-2整合为新职级中的L1。
这也表明,虽然看上去还是10个等级,但不可能直接对应。字节将视目前职级、薪酬总包、能力和绩效情况,明年给员工划分新的职级。
字节在全员信中透露,新职级体系能给员工提供更大的涨薪空间。
所以职级体系的改革,仍然是指向了涨薪。
为什么此时此刻要涨薪?字节内部信的官方解释是:
我们所处的行业正面临新的机遇和挑战,公司希望更好地吸引,激励和保留优秀人才。
这里“新的机遇和挑战”,显然缘起大模型。而众所周知,大模型浪潮崛起后,大厂抢人其实并不是一件新鲜事,但这种争夺,过去一般围绕顶尖人才展开。
就在年终岁末的此时此刻,有玩家率先把抢人/留人大战的战火,从金字塔尖烧向全体员工。这体现出新一轮的AI竞争,既需要坐镇指挥的大将,也要有敢拼敢闯的千军万马。
毕竟如今底座成熟,智能涌现,赋能应用,全面落地开花,需要全方位的团队保障。
字节的最新动作,也向行业抛出了一个问题:
跟吗?
以下为全员信原文:
大家好,我们所处的行业正面临新的机遇和挑战,公司希望更好地吸引,激励和保留优秀人才,鼓励大家和公司业务一起,再上一个比过去更大的台阶。
为此,2026年,公司将继续加大人才投入,提高薪酬和激励回报的天花板,确保员工薪酬竞争力和激励回报在各个市场都领先于头部水平。基于此,公司将更新薪酬和激励政策,具体包括以下要点:
提高薪酬竞争力,加大调薪投入。
提高所有职级薪酬总包区间的上限和下限为更多同学提供更大的涨薪空间,也提高招聘场景的薪酬竞争力。
2025全年绩效评估周期,公司调薪投入将比上个周期上涨1.5倍,用于提高员工薪酬。
与此同时,薪酬发放将提高现金占比,减少期权/RSU占比,总包类期权/RSU发放将从1次发4年(每年归属节奏为20%-25%-25%-30%),改为1次发3年(每年归属节奏为30%-30%-40%)。提升绩效激励,加大奖金投入2025全年绩效评估周期,公司奖金投入将比上个周期上涨35%,用于提升全年绩效M及以上的激励月数。
以薪酬总包中目标年终奖为3个月的情况为例:整体激励力度大幅提升。M激励月数下限不变,上限增加1.5个月;M+激励月数下限增加1.5个月,上限增加2.5个月;E激励月数下限增加3.5个月,上限增加3个月。
对于激励月数在3个月以内的部分,仍以现金形式发放。对于激励月数超过3个月的部分,发放形式将从100%发绩效期权/RSU改为25%发现金,75%发绩效期权/RSU(归属节奏不变,两者均按月匀速归属)。
从2026半年绩效评估周期起,半年激励(半年绩效E及以上的同学可获得)将加大激励力度,计算基数将从月薪调整为月总包(月薪+月期权/RSU)。
发放形式将从100%发现金,改为25%发现金,75%发绩效期权/RSU(两者均按月匀速归属)。
从2026年1月起,新授予的绩效期权/RSU,55%可在归属后立即参与回购,其余部分可在3年内逐步参与回购(每年15%)。
以上政策适用于正式员工。公司也将同步提升实习生薪酬标准,相关标准将于2026年1月1日生效。
与此同时,公司将应用新职级体系:
从”L1”到”L10”,共十级。目前职级体系中”1-1”实际使用率很低,将与”1-2”整合为新职级”L1”。
新职级与旧职级并非一一对应,而是以更高的标准重新定义了各职级能力要求,同时提高了所有职级薪酬总包区间上限和下限。在新职级体系下,更多同学有更大的涨薪空间。
新职级体系将在2026年1月1日启用,2025全年绩效评估将在2026年1月15日启动。因此,2025全年绩效评估周期将包含两个事项:
一是根据每位同学在2025年的职级和产出,评定全年绩效和激励;二是根据每位同学目前职级,薪酬总包,能力和绩效情况匹配到新职级。
参考链接:
[1]https://www.bloomberg.com/news/articles/2025-12-19/tiktok-owner-bytedance-on-track-for-50-billion-profit-in-2025
[2]https://finance.sina.com.cn/tech/discovery/2025-12-19/doc-inhciykf2129590.shtml
....
#2025最大AI赢家的凡尔赛年度总结
哈萨比斯Jeff Dean联手执笔
谷歌2025年度AI综述:Gemini 3 Pro/Flash以推理+多模态刷新多项基准,开源Gemma加码端侧;Agent重塑编码、搜索与创意工具,AlphaFold、DeepThink夺金,量子Echoes与Ironwood TPU夯实硬件,长文描绘可协作、可行动、可科研的通用智能路线图。
如何回顾2025年的AI进展?
今年王者归来的谷歌,刚刚由Jeff Dean和哈萨比斯牵头,完成了年度总结和趋势展望报告——
这是AI Agent、推理和科学发现的一年。
报告最后梳理出了八大研究方向,系统性地回答了一个更重要的问题:
当大模型进入推理时代,AI 正在变成什么?
从Gemini的推理能力、多模态理解,到Agent、机器人、科学研究和物理世界建模,谷歌正在描绘一个可以协作、可以行动、甚至开始参与科学发现的智能系统。
模型的推理、多模态理解、生成能力及效率得到显著提升。
AI已广泛融入谷歌的主要产品中。
2025年创造性AI工具全面提升。
AI在科学和数学领域实现多项成果,尤其是数学和编程竞赛表现优异。
谷歌始终强调安全、责任与合作开放生态。
以下是原文总结,在不改变原意的基础上,进行了适当修改润色:
谷歌年度回顾全文
回顾2025年,这是研究领域取得非凡进展的一年。
在人工智能方面,可以清晰地看到其发展轨迹正从一种工具转变为一种实用手段:从人们使用的东西变成了可以投入工作使用的东西。
如果说2024年是为这个时代奠定多模态基础的一年,那么2025年就是人工智能开始真正与人类一同思考、行动和探索世界的一年。
在量子计算领域,谷歌也在迈向实际应用方面取得了进展。
概括来讲,在各个领域,谷歌都正在助力将研究转化为现实,让功能更强大、更实用的产品和工具对人们的生活产生积极影响。
基础模型能力突破
首先今年,谷歌在推理、多模态理解、模型效率和生成能力方面均取得了突破性进展,显著提升了模型性能。
这一系列进展始于3月份发布的Gemini 2.5,一直到在11月推出了Gemini 3,并于12月推出了Gemini 3 Flash。
基于最先进的推理技术,Gemini 3 Pro是谷歌迄今为止最强大的模型,旨在帮助用户将想法变为现实。
它在LMArena排行榜上位于榜首,并凭借在人类终极考试以及GPQA Diamond等基准测试中的突破性分数,重新定义了多模态推理。
它还为数学领域的前沿模型树立了新标准,在MathArena Apex上创下了23.4%的最新纪录。
随后,谷歌推出了Gemini 3 Flash,它融合了Gemini 3的专业级推理能力与Flash级别的延迟、效率和成本优势,使其成为同尺寸下性能最佳的模型。
Gemini 3 Flash的质量超越了谷歌之前的Gemini 2.5 Pro规模模型的能力,价格却只有它的一小部分,且延迟显著降低,延续了Gemini时代的趋势——
下一代的Flash模型优于上一代的Pro模型。
另外,谷歌今年也致力于通过最先进的开源模型,让实用的AI技术变得更易于获取。
谷歌的Gemma系列模型不仅具有轻量级特性,而且开源。在今年,还成功引入了多模态能力,大幅度增加了上下文窗口,拓展了多语言功能,并提升了效率和性能。
AI产品的深度集成与创新
2025年,谷歌继续推动AI从工具转向实用工具,凭借全新、强大的Agent能力改造现有的产品组合。
谷歌重新构想了软件开发,不再局限于辅助编码工具,而是引入能与开发者协作的强大Agent系统,比如Gemini 3高超的编码能力以及Google Antigravity的推出,都标志着AI辅助软件开发迈入了一个新时代。
这一演变同样也在谷歌的核心产品中清晰可见,从Pixel 10上的AI功能、搜索中AI模式的更新,到类似Gemini应用和NotebookLM这类的AI创新产品,而这些产品均增加了深度研究等高级功能。
AI赋能创造力
2025年也是生成式媒体变革的一年,AI为创意提供了全新且前所未有的能力。
用于视频、图像、音频和虚拟世界的生成式媒体模型及工具变得更加高效,应用也更为广泛,其中突破性的Nano Banana和Nano Banana Pro在原生图像生成与编辑方面展现出了前所未有的能力。
谷歌还与创意行业人士合作,开发了Flow和Music AI Sandbox等工具,让它们能更好地辅助创意工作流程。
同时,谷歌通过谷歌艺术与文化实验室推出全新的AI驱动体验、对Gemini应用中的图像编辑功能进行了重大升级,以及引入Veo 3.1、Imagen 4和Flow等强大的新型生成式媒体模型,为人们拓展了创意可能性。

今年谷歌实验室也进行了一些极具吸引力的实验,包括:
- Pomelli:AI用于品牌营销内容;
- Stitch:能在几分钟内将提示词和图像输入转化为复杂用户界面设计和前端代码;
- Jules:异步编码Agent,可作为开发者的协作伙伴;
- Google Beam:3D视频通信平台,利用AI拓展了远程在场的可能性。
推动科学与数学发展
2025年也是AI科学进步的标志性一年,生命科学、健康、自然科学和数学领域均在AI帮助下取得了诸多进展。
这一年里,谷歌在构建AI资源和工具方面取得了进展,这些资源和工具为研究人员赋能,帮助他们在医疗健康领域理解、识别和开发新的治疗手段。
在基因组学领域,谷歌已将先进技术应用于研究长达十余年,如今谷歌超越了测序阶段,正在利用AI来解读最复杂的数据。
谷歌在今年也纪念了AlphaFold问世的第五周年,这一荣获诺贝尔奖的AI系统解决了困扰学界50年的蛋白质折叠问题。目前它已被190多个国家的300多万名研究人员使用。

而Gemini的高级思考能力,包括Deep Think,也在数学和编程领域取得了历史性进展。
Deep Think已经能够理解需要深度抽象推理的问题,并在两项国际竞赛中达到了金牌水平。
推进计算和物理世界研究
谷歌今年在量子计算、能源和突破性技术等领域也取得了重大发现,并吸引了前所未有的关注。
其中量子计算在现实世界应用方面的进展尤为显著,例如Quantum Echoes项目。
值得一提的是,谷歌员工Michel Devoret与前谷歌员工John Martinis以及UC伯克利的John Clarke共同获得了2025年诺贝尔物理学奖,以表彰他们在20世纪80年代的基础量子研究。
2025年,谷歌继续推进为AI提供动力的核心基础设施,重点关注硬件设计的突破和能源效率的提升,包括推出Ironwood,一款为推理时代打造的新型TPU,它是采用名为AlphaChip的方法设计的,同时谷歌还致力于衡量技术对环境的影响。
谷歌在机器人技术和视觉理解方面的研究,也将AI Agent带入了物理世界和虚拟世界,比如基础性的Gemini Robotics模型、更先进的Gemini Robotics 1.5,以及Genie 3的推出,其中Genie 3成为了通用世界模型的新前沿。
应对全球性挑战与机遇
谷歌今年的工作直观展示了AI驱动的科学进步,如何直接应用于解决世界上最关键和普遍存在的挑战。
通过利用最先进的基础模型和Agent推理,谷歌极大地加深了对地球及其系统的理解,同时在气候韧性、公共卫生和教育等领域提供了影响力解决方案。
例如,谷歌正利用最先进的基础模型和代理推理来帮助加深对地球的理解,涵盖天气预报、城市规划、公共卫生等多个领域。例如,谷歌的洪水预报信息目前已覆盖全球150个国家超20亿人口。
而谷歌最先进、最高效的预报模型WeatherNext 2,生成预报的速度能快8倍,且分辨率可达1小时。借助这项技术,谷歌通过实验性的气旋预测,支持气象机构做出有效决策。
谷歌也正在与合作伙伴携手,将AI驱动的科学进展更贴近患者,为疾病管理和疗法研发开辟新途径。
此外,AI正被证明是教育领域的一个强大工具,通过LearnLM和Gemini中的引导式学习,它能促成新的理解形式并激发学生更多好奇心。
谷歌今年将Gemini最强大的翻译能力引入谷歌翻译,使其能提供更智能、更自然且更准确的翻译,并试点了新的语音互译功能。
重视责任与安全
谷歌将研究突破与责任和安全相结合。
随着模型能力不断增强,谷歌正持续改进和发展旗下的工具、资源及安全框架,以预测并降低风险。
Gemini 3就切实展现了这种观念:它是谷歌迄今为止最安全的模型,并且经过了最全面的安全评估。
此外,谷歌还在展望更长远的未来,探索通往AGI的负责任之路,将准备工作、主动风险评估以及与更广泛的人工智能社区合作置于优先地位。
提供跨界合作与开放生态
谷歌认为,要负责任地推进人工智能的前沿领域,需要全社会各方面的协作。
2025年,谷歌与顶尖的人工智能实验室合作,成立了Agentic AI基金会,并支持开放标准,以确保Agentic AI拥有一个负责任且具备互操作性的未来。
在教育领域,谷歌也与教育机构合作,帮助学生掌握AI技能。并与加州大学伯克利分校、耶鲁大学、芝加哥大学等众多高校研究合作,一起推动前沿研究。
此外,谷歌正与多个实验室合作,协同改变科学研究的开展方式。与电影制作人和其他创意开发者合作,为他们提供最优质的AI工具,探索人工智能时代的新的叙事方式。
2026年,谷歌希望能够继续安全且负责任地推进前沿技术,为人类谋福祉。
参考链接:
[1]https://blog.google/technology/ai/2025-research-breakthroughs/
[2]https://x.com/i/trending/2003527758127989012
...

魔乐社区(Modelers.cn) 是一个中立、公益的人工智能社区,提供人工智能工具、模型、数据的托管、展示与应用协同服务,为人工智能开发及爱好者搭建开放的学习交流平台。社区通过理事会方式运作,由全产业链共同建设、共同运营、共同享有,推动国产AI生态繁荣发展。
更多推荐


 6
6 0
0- 0



 已为社区贡献75条内容
已为社区贡献75条内容

所有评论(0)