【具身智能】ConRFT:基于一致性策略的 VLA 强化微调方法
ConRFT 是一种高效、安全、实用的VLA模型强化微调方法,只需 20 个演示+ 1 小时在线训练,就能让机器人在复杂真实任务中达到 96% 成功率,比传统方法快、稳、强。后续可探索 “更智能的奖励设计”“感知 - 动作联合微调”,进一步提升 VLA 模型的通用操控能力。
ConRFT:基于一致性策略的 VLA 强化微调方法
- 论文题目:ConRFT: A Reinforced Fine-tuning Method for VLA Models via Consistency Policy
- arXiv:2502.05450
- Accepted: RSS 2025
- 单位:自动化所 & 中国科学院大学
- https://cccedric.github.io/conrft/
- 更多论文每日解读关注 v 公众号:https://mp.weixin.qq.com/s/hG1ZBrWfNkFo1gFka-HOVQ

ConRFT 是一种两阶段强化微调方法,用于将预训练的 VLA 模型高效适应到真实机器人操控任务中,仅需 20-30 个人类演示,在 45-90 分钟在线训练后,平均成功率达 96.3%,比传统监督微调提升 144%。
::: block-1
一致性策略(Consistency Policy)
- 不是直接输出动作,而是从噪声中“去噪”出动作。
- 类似扩散模型,但更快、更轻。
- 好处:能处理不一致/次优演示,比扩散模型快。
:::
方法:ConRFT
两阶段框架:
| 阶段 | 名称 | 目标 | 数据 | 关键技术 |
|---|---|---|---|---|
| 离线阶段 | Cal-ConRFT | 用少量演示初始化策略和价值函数 | 20-30个人类演示 | 行为克隆 + Q学习 + 一致性策略 |
| 在线阶段 | HIL-ConRFT | 在线强化微调,提升性能 | 在线交互 + 人类干预 | 一致性策略 + 人类干预 + 任务奖励 |
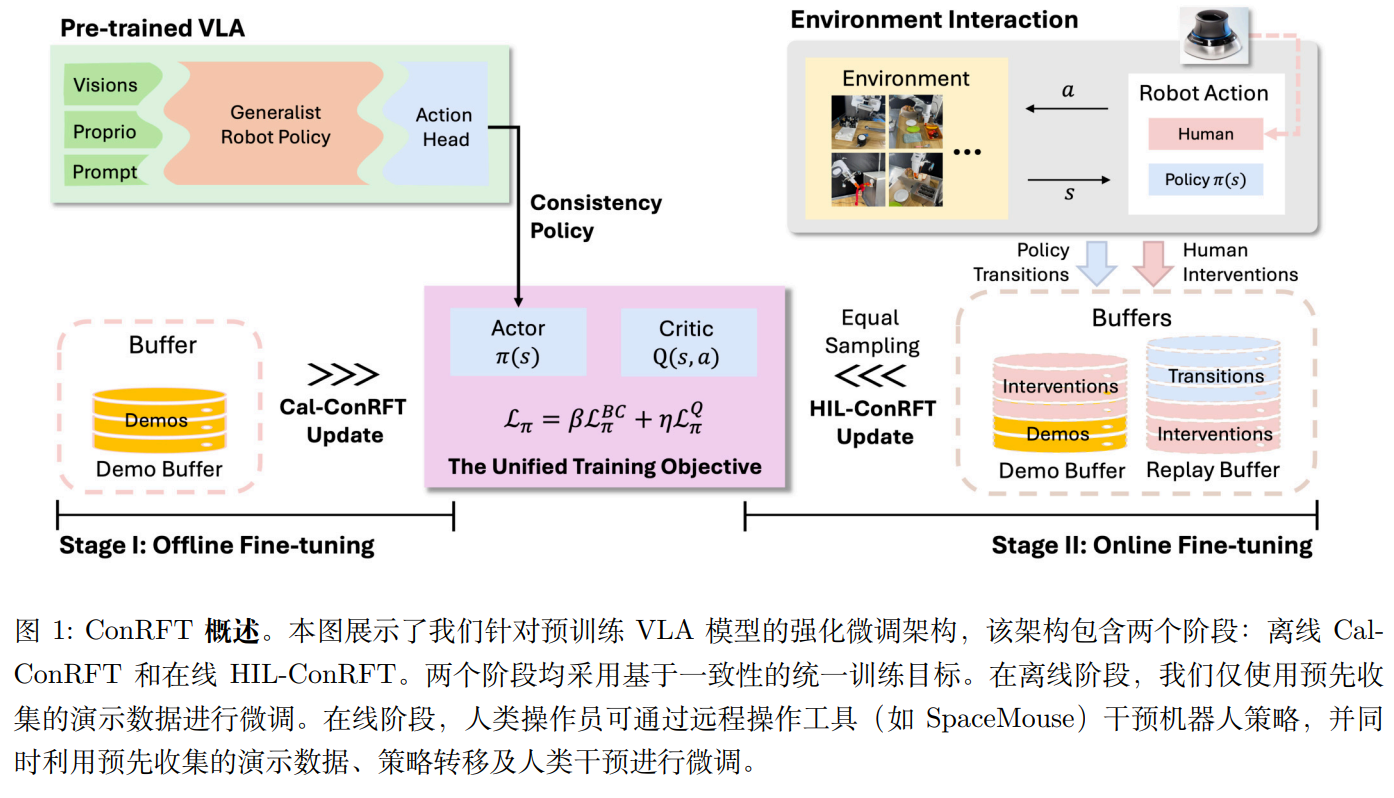
第一阶段:离线微调(Cal-ConRFT)—— 用少量演示打基础
目标:用 20-30 个少量人类演示,训练出一个 “稳定的初始策略 + 价值函数”,避免在线阶段 “从零探索” 的风险。
方法:结合行为克隆(BC)和 Q 学习,从少量示范中有效提取策略并稳定值估计。使用 Calibrated Q-Learning (Cal-QL) 方法,通过在预收集的数据集上训练 Q 函数,减少时间差(TD)误差,并添加一个正则化器,惩罚超出参考策略值的 OOD 动作。
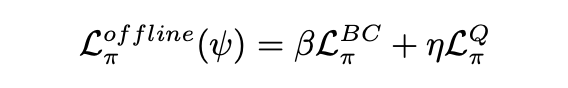
改进: 通过引入 BC 损失,鼓励模型模仿示范行为,提供额外的监督信号,特别是在接触丰富的操作任务中,控制精度至关重要。
离线微调阶段的输出:一个 “能应对基础场景、价值估计稳定” 的初始策略,为在线阶段减少 90% 以上的无效探索。
第二阶段:在线微调(HIL-ConRFT)—— 真实环境安全探索
目标:在真实机器人上与环境交互,用 “任务奖励 + 人类干预” 优化策略,适配离线阶段未覆盖的场景(如 “轮子位置偏移”“面包沾在烤面包机里”)。
方法:
-
双缓冲区 + 对称采样
- 保留离线阶段的 “演示缓冲区(D)”,新增 “在线回放缓冲区(R)”(存储机器人与环境交互的新数据);
- 每次训练时,从 D 和 R 中 “等比例采样” 数据,避免在线数据过多导致 “策略偏离演示”
-
动态调整损失权重
- 在线阶段逐渐 “降低 BC 损失权重、提高 Q 损失权重”:初期靠 BC 保证动作不跑偏,后期靠 Q 损失优化 “任务奖励”(比如 “更快插好轮子”“不损坏面包”)。
-
Human-in-the-Loop 干预
- 当机器人出现 “危险动作”(如撞桌子、用力过猛压坏面包)或 “卡住”(如插轮子半天对不上)时,人类通过远程工具(如 SpaceMouse)接管控制,修正动作;
- 人类修正的动作会存入 “演示缓冲区(D)”,相当于给模型 “实时补充高质量数据”,加速收敛(实验中能减少 50% 以上的在线训练时间)。
实验
作者在8 个真实机器人操控任务上验证了 ConRFT 的效果,任务覆盖 “简单拾取”(捡香蕉、勺子)、“接触操作”(开抽屉、按烤面包机)、“高精度装配”(插椅子轮子、挂中国结),硬件用 7 自由度 Franka 机械臂,预训练 VLA 模型为 Octo-small。

核心对比结果
论文用 “成功率”“ episode 长度(完成任务的步数,越短效率越高)”“训练时间” 三个指标,对比了主流基线方法(SFT、HG-DAgger、PA-RL、HIL-SERL),结果如下:
| 方法 | 平均成功率 | 平均步数 | 训练时间 |
|---|---|---|---|
| 监督微调(SFT) | 39.4% | 59.9步 | - |
| HG-DAgger(人类纠正) | 65% | 56.3步 | - |
| PA-RL(RL优化动作) | 71.3% | 51.1步 | - |
| ✅ ConRFT(本文) | 96.3% | 30.7步 | 45-90分钟 |
关键实验结论
| 问题 | 答案 |
|---|---|
| 比监督学习强多少? | 成功率提升 144%,步数缩短 1.9倍 |
| 比从头训练RL强? | 是,HIL-SERL 成功率仅31.9%,ConRFT 达96.3% |
| 演示数据少行不行? | 行,20个演示就能训出高性能策略 |
| 能迁移到其他VLA? | 可以,已在 RoboVLM + Kosmos-2/PaliGemma 上验证 |
局限性
| 问题 | 说明 |
|---|---|
| 奖励函数敏感 | 用二分类器做奖励,容易被“骗”(奖励黑客) |
| 视觉编码器冻结 | 为了实时性,ConRFT 冻结了 VLA 模型的 “视觉编码器” 和 “Transformer backbone”,仅微调 “动作头”;,可能导致无法优化感知能力,限制泛化 |
| 人类干预依赖 | 虽然高效,但仍需人类在场纠正 |
总结
ConRFT 是一种高效、安全、实用的VLA模型强化微调方法,只需 20 个演示+ 1 小时在线训练,就能让机器人在复杂真实任务中达到 96% 成功率,比传统方法快、稳、强。
后续可探索 “更智能的奖励设计”“感知 - 动作联合微调”,进一步提升 VLA 模型的通用操控能力。

魔乐社区(Modelers.cn) 是一个中立、公益的人工智能社区,提供人工智能工具、模型、数据的托管、展示与应用协同服务,为人工智能开发及爱好者搭建开放的学习交流平台。社区通过理事会方式运作,由全产业链共同建设、共同运营、共同享有,推动国产AI生态繁荣发展。
更多推荐



 11
11 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)