基于BERT的中文情感分析
HuggingFace模型微调训练
前言
BERT,这位“语言天才”,它通过海量文本数据的预训练,学会了如何理解语言的上下文关系,仿佛是一个经过无数书籍洗礼的“语言大师”。借助Hugging Face的transformers库,我们只需为BERT“微调”一下,就能让它精准捕捉中文文本中的情绪脉络。本文详细的描述了整个神经网络从数据准备到训练的全过程,可以更好的理解模型的架构,以及如何来做一个自己的下游任务。
一、数据准备
数据集使用huggingface上下载的情感二分类文本数据。
1. load_dataset
load_dataset是hf提供的在线加载。
下载下来数据,它会是训练集,验证集,测试集做好了分类,每个文件里都是以arrow为后缀的文件。 每个文件里都是arrow。
每个文件里都是arrow。

2. load_from_disk
下来的数据是hf格式的,需要转成csv的格式。
load_from_disk是本地加载数据。
from datasets import load_dataset,load_from_disk
#在线加载数据
dataset = load_dataset(path="NousResearch/hermes-function-calling-v1",split="train")
print(dataset)
#转存为CSV格式
dataset.to_csv(path_or_buf=r"D:\demo\data\hermes-function-calling-v1.csv")
#加载csv格式数据
# dataset = load_dataset(path="csv",data_files=r"D:\demo\data\hermes-function-calling-v1.csv")
# print(dataset)
#加载缓存数据
dataset = load_from_disk(r"D:\demo\data\ChnSentiCorp")
print(dataset)
test_data = dataset["train"]
for data in test_data:
print(data)
数据集的样式,就是一个二分类的情感分析,0是负面,1是正面,截取几条,就是如下样式。
{'text': '键盘手感没有开始的时候好了, 散热一般,机器硬盘温度一度达到58度', 'label': 0}
{'text': '10多年来住过的近百家3星酒店中,这家酒店的服务、房间、餐饮简直是“好”的无话可说!!! 向大堂经理反映问题,大堂经理的答复是“去315投诉吧”(入住当天是3月12日),真强悍!!!', 'label': 0}
{'text': '1.上了半天网,都上不去,问酒店,答曰坏了。气愤! 2.晚上入住适逢变天,天气变冷,开了半天空调,竟然还是冷风,问酒店,答曰晚上关空调。晕!床上只有一床单被,到处找被子,无。问酒店要,半小时催了三次电话才来。还是冷,要求在加一床被子,服务员去后再也没回,打到总台,又等了半天,回复没被子了。不把顾客当人啊。 3.一晚没睡成,凌晨5点多,被不知道哪里来的低沉的轰鸣声吵醒。在房间找了半天没查出哪里来得声音,叫来服务员,(半小时催了三四次才来,人都要疯掉)。六点多服务员才来,也解决不了。就这么一夜没睡。买气受来了。 4.到总台要求当班经理来解释,换了几个人来,说了几遍,酒店不断去落实事情真相,最后才来一个自称客服经理的,说却有其事,表示道歉,做了一小时的冷板凳,一口热水没喝,口都讲干了。这就是他们的诚意。 总结:硬件老旧,服务太差。', 'label': 0}
{'text': '该酒店达不到五星水准。价格高,环境差,服务一般', 'label': 0}
二、构建、设计模型
1. 编码
1,AutoTokenizer
适用于所有分词器,不管是BERT模型,GPT,还是transformer等。
2,BertTokenizer
只适用于BERT模型
3,token.batch_encode_plus
编码,讲文本转为计算机可识别的向量数值。
字典也是从hf上下载,这里用的是models–bert-base-chinese,里面包含了中文模型的识别,model.safetensors,和一个中文分词器所用的向量表vacab.txt。
模型目录里面模型和字典
字典就是vocab.txt,总共21128个编码。
里面主要是汉字编码,还有一些日语平假名片假名和特殊符号。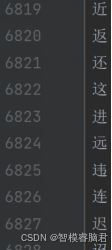
讲文本转向量代码示例
from transformers import AutoTokenizer,BertTokenizer
#加载字典和分词器
token = BertTokenizer.from_pretrained(r"D:\demo\model\bert-base-chinese\models--bert-base-chinese\snapshots\c30a6ed22ab4564dc1e3b2ecbf6e766b0611a33f")
# print(token)
sents = ["价格在这个地段属于适中, 附近有早餐店,小饭店, 比较方便,无早也无所",
"房间不错,只是上网速度慢得无法忍受,打开一个网页要等半小时,连邮件都无法收。另前台工作人员服务态度是很好,只是效率有得改善。"]
#批量编码句子
out = token.batch_encode_plus(
batch_text_or_text_pairs=[sents[0],sents[1]],
add_special_tokens=True,
#当句子长度大于max_length时,截断
truncation=True,
max_length=50,
#一律补0到max_length长度,因为我们给到的数据是一个矩阵,所以多退少补。
padding="max_length",
#可取值为tf,pt,np,默认为list
return_tensors=None,
#返回attention_mask
return_attention_mask=True,
return_token_type_ids=True,
return_special_tokens_mask=True,
#返回length长度
return_length=True
)
#input_ids 就是编码后的词
#token_type_ids第一个句子和特殊符号的位置是0,第二个句子的位置1()只针对于上下文编码
#special_tokens_mask 特殊符号的位置是1,其他位置是0
# print(out)
for k,v in out.items():
print(k,";",v)
#解码文本数据
print(token.decode(out["input_ids"][0]),token.decode(out["input_ids"][1]))
打印输出这两句话,可以看到每个字都转成了vocab里面对应的向量,先打印编码,然后再打印解吗,和我们输入做对比,看看是否编解码正确。[CLS]对应的就是101,语句的开头,[SEP]102语句结尾,[PAD]就是补全的0.
C:\Users\gyton\anaconda3\envs\langchain-learn\python.exe G:\demo\token_test.py
input_ids ; [[101, 817, 3419, 1762, 6821, 702, 1765, 3667, 2247, 754, 6844, 704, 117, 7353, 6818, 3300, 3193, 7623, 2421, 117, 2207, 7649, 2421, 117, 3683, 6772, 3175, 912, 117, 3187, 3193, 738, 3187, 2792, 102, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0], [101, 2791, 7313, 679, 7231, 117, 1372, 3221, 677, 5381, 6862, 2428, 2714, 2533, 3187, 3791, 2556, 1358, 117, 2802, 2458, 671, 702, 5381, 7552, 6206, 5023, 1288, 2207, 3198, 117, 6825, 6934, 816, 6963, 3187, 3791, 3119, 511, 1369, 1184, 1378, 2339, 868, 782, 1447, 3302, 1218, 2578, 102]]
token_type_ids ; [[0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0], [0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0]]
special_tokens_mask ; [[1, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1], [1, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 1]]
length ; [35, 50]
attention_mask ; [[1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0], [1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1]]
[CLS] 价 格 在 这 个 地 段 属 于 适 中, 附 近 有 早 餐 店, 小 饭 店, 比 较 方 便, 无 早 也 无 所 [SEP] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [CLS] 房 间 不 错, 只 是 上 网 速 度 慢 得 无 法 忍 受, 打 开 一 个 网 页 要 等 半 小 时, 连 邮 件 都 无 法 收 。 另 前 台 工 作 人 员 服 务 态 [SEP]
可以看到第二句子截断了,因为我们max最大是50,如果想保留可以更新这个参数。
2. 微调
将预训练好的模型参数作为初始参数,然后在特定任务的数据集上进行进一步训练。例如,将一个预训练的语言模型用于文本分类任务,通过在分类任务的标注数据上继续训练,调整模型的参数,使其更好地适应这个特定任务。我们就用情感二分类。
1,什么是微调
只调整模型的一部分结构(参数),为了让模型能够适应我当前的任务。
2,为什么微调
因为我想白嫖模型已经训练好的参数,以此来缩短我自己训练的时间。
3,增量微调
在模型原有的结构基础上,增加一部分结构,然这部分结构来完成我们自己的任务。
3. 模型设计
先加载BERT模型,定义设备,可以是CPU,最好是GPU。然后加载预训练模型,放到设备上。可以往后面增加模型,定义下游任务。主要构造模型,输入就是bert的输出,768维,可以打印模型,看到bert输出。
from transformers import BertModel
import torch
#定义设备信息
DEVICE = torch.device("cuda" if torch.cuda.is_available() else "cpu")
print(DEVICE)
#加载预训练模型
pretrained = BertModel.from_pretrained(r"D:\model\bert-base-chinese\models--bert-base-chinese\snapshots\c30a6ed22ab4564dc1e3b2ecbf6e766b0611a33f").to(DEVICE)
print(pretrained)
#定义下游任务(增量模型)
class Model(torch.nn.Module):
def __init__(self):
super().__init__()
#设计全连接网络,实现二分类任务
self.fc = torch.nn.Linear(768,2)
def forward(self,input_ids,attention_mask,token_type_ids):
#冻结Bert模型的参数,让其不参与训练
with torch.no_grad():
out = pretrained(input_ids=input_ids,attention_mask=attention_mask,token_type_ids=token_type_ids)
#增量模型参与训练
out = self.fc(out.last_hidden_state[:,0])
return out
4 . 构建数据
一共三步,流程固定。
1,加载数据
三个文件夹,训练集,验证集,测试集。
2,返回数据长度
3,取数据
通过键,返回test的内容,和标签label的值。
#自定义数据集
from torch.utils.data import Dataset
from datasets import load_from_disk
class MyDataset(Dataset):
def __init__(self,split):
#从磁盘加载数据
self.dataset = load_from_disk(r"D:\demo\data\ChnSentiCorp")
if split == 'train':
self.dataset = self.dataset["train"]
elif split == "test":
self.dataset = self.dataset["test"]
elif split == "validation":
self.dataset = self.dataset["validation"]
def __len__(self):
return len(self.dataset)
def __getitem__(self, item):
text = self.dataset[item]['text']
label = self.dataset[item]['label']
return text,label
打印信息,可以看到数据已取出。只有每条的text和label。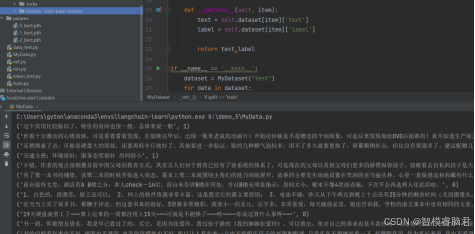
三、训练
1. 加载模型
加载模型,加载数据。
加载分词器。导入优化器。
创建数据集,修改参数。主要是batch_size,根据显存性能调整。
2. 计算损失
前向计算,数据输入模型,得到输出,根据输出,计算损失。
根据损失,优化参数。这个也是训练的目的,主要就是前向传播计算损失,然后在反向传播,调整参数,最后让损失逐渐变小,最后让模型
3. 梯度清零
在神经网络的训练过程中,每次更新模型参数时,都需要先清空(归零)梯度。这是因为梯度是一个特殊的变量,它不能被直接覆盖,只能被清空后重新计算。
#模型训练
import torch
from MyData import MyDataset
from torch.utils.data import DataLoader
from net import Model
from transformers import BertTokenizer,AdamW
#定义设备信息
DEVICE = torch.device("cuda" if torch.cuda.is_available() else "cpu")
#定义训练的轮次
EPOCH= 30000
token = BertTokenizer.from_pretrained(r"D:\demo\model\bert-base-chinese\models--bert-base-chinese\snapshots\c30a6ed22ab4564dc1e3b2ecbf6e766b0611a33f")
def collate_fn(data):
sents = [i[0]for i in data]
label = [i[1] for i in data]
#编码
data = token.batch_encode_plus(
batch_text_or_text_pairs=sents,
truncation=True,
max_length=500,
padding="max_length",
return_tensors="pt",
return_length=True
)
input_ids = data["input_ids"]
attention_mask = data["attention_mask"]
token_type_ids = data["token_type_ids"]
labels = torch.LongTensor(label)
return input_ids,attention_mask,token_type_ids,labels
#创建数据集
train_dataset = MyDataset("train")
train_loader = DataLoader(
dataset=train_dataset,
batch_size=600,
shuffle=True,
#舍弃最后一个批次的数据,防止形状出错
drop_last=True,
#对加载进来的数据进行编码
collate_fn=collate_fn
)
if __name__ == '__main__':
#开始训练
print(DEVICE)
model = Model().to(DEVICE)
#定义优化器
optimizer = AdamW(model.parameters())
#定义损失函数
loss_func = torch.nn.CrossEntropyLoss()
for epoch in range(EPOCH):
for i,(input_ids,attention_mask,token_type_ids,labels) in enumerate(train_loader):
#将数据存放到DEVICE上
input_ids, attention_mask, token_type_ids, labels = input_ids.to(DEVICE),attention_mask.to(DEVICE),token_type_ids.to(DEVICE),labels.to(DEVICE)
#前向计算(将数据输入模型,得到输出)
out = model(input_ids=input_ids,attention_mask=attention_mask,token_type_ids=token_type_ids)
#根据输出,计算损失
loss = loss_func(out,labels)
#根据损失,优化参数
optimizer.zero_grad()
loss.backward()
optimizer.step()
#每隔10个批次输出训练信息
if i%10==0:
out = out.argmax(dim=1)
acc = (out==labels).sum().item()/len(labels)
print(f"epoch:{epoch},i:{i},loss:{loss.item()},acc:{acc}")
#每训练完一轮,保存一次参数
torch.save(model.state_dict(),f"params/{epoch}_bert.pth")
print(epoch,"参数保存成功!")
可以用nvitop实时查看显存占用情况,在90%利用率为最佳,因为在多个epoch之后,会做一次验证,如果超过95%,一旦验证,显存容易炸,所以预留点空间。
查看训练情况
epoch:2,i:10,loss:0.31175675988197327,acc:0.8733333333333333
2 参数保存成功!
epoch:3,i:0,loss:0.28985902667045593,acc:0.8816666666666667
epoch:3,i:10,loss:0.27806833386421204,acc:0.88
3 参数保存成功!
epoch:4,i:0,loss:0.2828723192214966,acc:0.8816666666666667
epoch:4,i:10,loss:0.3123853802680969,acc:0.8733333333333333
4 参数保存成功!
epoch:5,i:0,loss:0.26086121797561646,acc:0.8966666666666666
查看显存
最大是16384,现在使用到16028,已经100%了,我这里用batch是600.没有炸,就这么一直训练吧,要是中间停了话就把size减少50。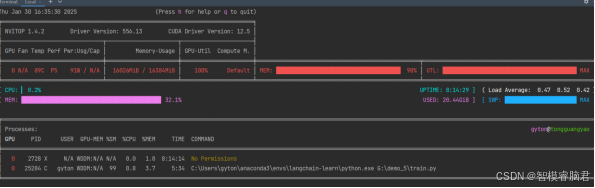
四、测试评估
1. 测试
加载分词器,实例化模型,文本编码。
测试代码
import torch
from net import Model
from transformers import BertTokenizer
#定义设备信息
DEVICE = torch.device("cuda" if torch.cuda.is_available() else "cpu")
print(DEVICE)
token = BertTokenizer.from_pretrained(r"D:\PycharmProjects\disanqi\demo_5\model\bert-base-chinese\models--bert-base-chinese\snapshots\c30a6ed22ab4564dc1e3b2ecbf6e766b0611a33f")
names = ["负向评价","正向评价"]
model = Model().to(DEVICE)
def collate_fn(data):
sents = []
sents.append(data)
#编码
data = token.batch_encode_plus(
batch_text_or_text_pairs=sents,
truncation=True,
max_length=500,
padding="max_length",
return_tensors="pt",
return_length=True
)
input_ids = data["input_ids"]
attention_mask = data["attention_mask"]
token_type_ids = data["token_type_ids"]
return input_ids, attention_mask, token_type_ids
def test():
#加载训练参数
model.load_state_dict(torch.load("params/1_bert.pth",map_location=DEVICE))
#开启测试模式
model.eval()
while True:
data = input("请输入测试数据(输入‘q’退出):")
if data == 'q':
print("测试结束")
break
input_ids, attention_mask, token_type_ids = collate_fn(data)
input_ids, attention_mask, token_type_ids = input_ids.to(DEVICE), attention_mask.to(DEVICE), \
token_type_ids.to(DEVICE)
with torch.no_grad():
out = model(input_ids, attention_mask, token_type_ids)
out = out.argmax(dim=1)
print("模型判定:",names[out],"\n")
if __name__ == '__main__':
test()
2. 评估
用cmd当测试窗口,这里我就用主观当评估,直接对比测试结果,看看训练的效果。训练过程中内存使用率非常高。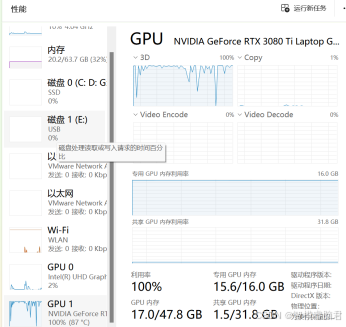
epoch:68,i:0,loss:0.1814458966255188,acc:0.9316666666666666
epoch:68,i:10,loss:0.21883216500282288,acc:0.9066666666666666
68 参数保存成功!
epoch:69,i:0,loss:0.18294715881347656,acc:0.9333333333333333
epoch:69,i:10,loss:0.17409978806972504,acc:0.9266666666666666
69 参数保存成功!
epoch:70,i:0,loss:0.20037733018398285,acc:0.9266666666666666
epoch:70,i:10,loss:0.18265597522258759,acc:0.93
70 参数保存成功!
epoch:71,i:0,loss:0.16623246669769287,acc:0.9416666666666667
大概跑了5个小时左右,下午5.30,现在10.30.跑70轮,现在给停掉,就拿最后一次保存的pth试试效果。可以看到,在第一轮的时候损失3.1,精度0.87,到第70轮,损失降到0.16,精度提高到0.94.上面测试程序,把所有用的模型路径copy进去即可。
找几条是原始数据集的,测完和数据集lable对比,都正确,然后自己编点话进去,看看解过反馈。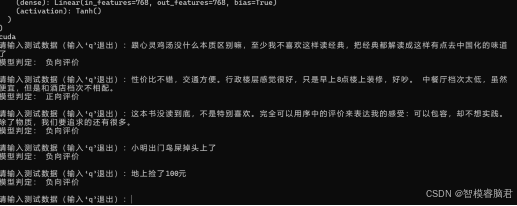
把原始的拿出来,对比下结果,随机找的几条都正确,也可以再多测测。
之所以用主观评估,是因为主观评估适合于需要考虑复杂背景、情感因素或个性化体验的场景,但需要警惕偏见和不一致性。
客观评估适合于需要标准化、可量化和公正性的场景,但可能无法完全涵盖复杂性和灵活性。这个就根据项目自己定制就可以了。
五、总结
神经网络的训练是一个复杂而系统的过程,涉及数据准备、模型设计、训练优化、评估和部署等多个步骤,通过此项目训练,能更好的理解下面几个重点过程,知道为什么这么干,怎么干,最后是什么结果。
• 反向传播:计算损失对参数的梯度。
• 优化算法(梯度下降法):根据梯度更新参数,减小损失。
• 训练过程:通过不断调整参数,让模型的预测值接近真实值。
• 最终目标:模型对新数据的预测结果与真实结果非常接近。

魔乐社区(Modelers.cn) 是一个中立、公益的人工智能社区,提供人工智能工具、模型、数据的托管、展示与应用协同服务,为人工智能开发及爱好者搭建开放的学习交流平台。社区通过理事会方式运作,由全产业链共同建设、共同运营、共同享有,推动国产AI生态繁荣发展。
更多推荐


 23
23 0
0- 0



 已为社区贡献5条内容
已为社区贡献5条内容

所有评论(0)