python爬虫之动态加载获取药品监督管理局
·
本次爬取实现使用request模块爬取国家药品监督管理局的企业信息数据并存入到Excel表格中
爬取目标网站 http://scxk.nmpa.gov.cn:81/xk/#
分析页面:
打开网页查看首页数据,上下翻页时发现网址没有发生任何变化,可知页面数据都是通过ajax动态加载出来的,并且首页中的数据只包含了企业名称、许可证编号等信息,但不包含企业的详细信息,下图为首页页面。
此次爬取目标是所有企业的详细信息,若要得到企业的详细信息只能通过点击超链接查看,通过F12可以看出此处请求是通过企业id获取企业详细信息
爬取思路:
首先准备一个list集合用于存储所有企业的id,第一次for循环遍历每一页的企业信息,获取每个企业的id存入list集合里面。第二次for循环遍历存有各个企业id的list集合,使用每个id去请求页面获取企业详细信息并存入列表,最后使用xlwt把列表中所有企业存入到表格中
代码:
由于数据量较大,此处只爬取前20页的数据
import requests
import xlwt
import json
def main():
all_data_list = getDate() # 获取企业详情数据
savepath = ".\\国家药品监控管理局.xls" # 表格路径
saveData(all_data_list, savepath) # 写入表格
def getDate() :
url = "http://scxk.nmpa.gov.cn:81/xk/itownet/portalAction.do?method=getXkzsList"
headers = { # UA伪装,模拟浏览器
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/83.0.4103.106 Safari/537.36'
}
id_list = [] # 存储企业的id
all_data_list = [] # 存储所有所有的企业详情数据
# 获取1-5页的企业id号
for page in range(1, 21):
page = str(page)
data = { # 请求参数
'on': 'true',
'page': page,
'pageSize': '15',
'productName': '',
'conditionType': '1',
'applyname': '',
'applysn': ''
}
json_ids = requests.post(url=url, data=data, headers=headers).json() # 发送请求,返回json数据
for dic in json_ids['list']: # 循环list字典
id_list.append(dic['ID']) # ID号存入id_list
post_url = "http://scxk.nmpa.gov.cn:81/xk/itownet/portalAction.do?method=getXkzsById"
# 遍历ID列表,用每个ID去请求企业数据
for ID in id_list:
data = {
'id': ID
}
# 请求返回json数据
detail_json = requests.post(url=post_url, data=data, headers=headers).json()
data_list = list()
data_list.append(detail_json['epsName']) # 企业名称
data_list.append(detail_json['productSn']) # 许可证编号
data_list.append(detail_json['certStr']) # 许可项目
data_list.append(detail_json['epsAddress']) # 企业住所
data_list.append(detail_json['epsProductAddress']) # 生产地址
data_list.append(detail_json['businessLicenseNumber']) # 社会信用代码
data_list.append(detail_json['legalPerson']) # 法定代表人
data_list.append(detail_json['businessPerson']) # 企业负责人
data_list.append(detail_json['qualityPerson']) # 质量负责人
data_list.append(detail_json['qfManagerName']) # 发证机关
data_list.append(detail_json['xkName']) # 签发人
data_list.append(detail_json['rcManagerDepartName']) # 日常监督管理机构
data_list.append(detail_json['rcManagerUser']) # 日常监督管理人员
data_list.append(detail_json['xkDate']) # 有效期至
data_list.append(detail_json['xkDateStr']) # 发证日期
data_list.append(detail_json['xkType']) # 状态
data_list.append(detail_json['isimport']) # 是否进口
all_data_list.append(data_list)
print(data_list)
return all_data_list
def saveData(all_data_list, savepath):
style = xlwt.XFStyle
style = xlwt.easyxf('font: bold on') # 第一行加粗显示
book = xlwt.Workbook(encoding="utf-8",style_compression=0) # 创建workbook对象
sheet = book.add_sheet('sheet1',cell_overwrite_ok=True) # 创建工作表 cell_overwrite_ok 单元格覆盖内容
col = ("企业名称", "许可证编号", "许可项目", "企业住所", "生产地址", "社会信用代码", "法定代表人", "企业负责人",
"质量负责人", "发证机关", "签发人", "日常监督管理机构", "日常监督管理人员", "有效期至", "发证日期", "状态", "是否进口",)
for i in range(0, len(col)):
sheet.write(0, i, col[i], style) # 写入列名
for i in range(0, len(all_data_list)):
data = all_data_list[i]
for j in range(0, len(col)):
sheet.write(i+1, j, data[j]) # 写入行数据
book.save(savepath)
if __name__ == "__main__":
main()
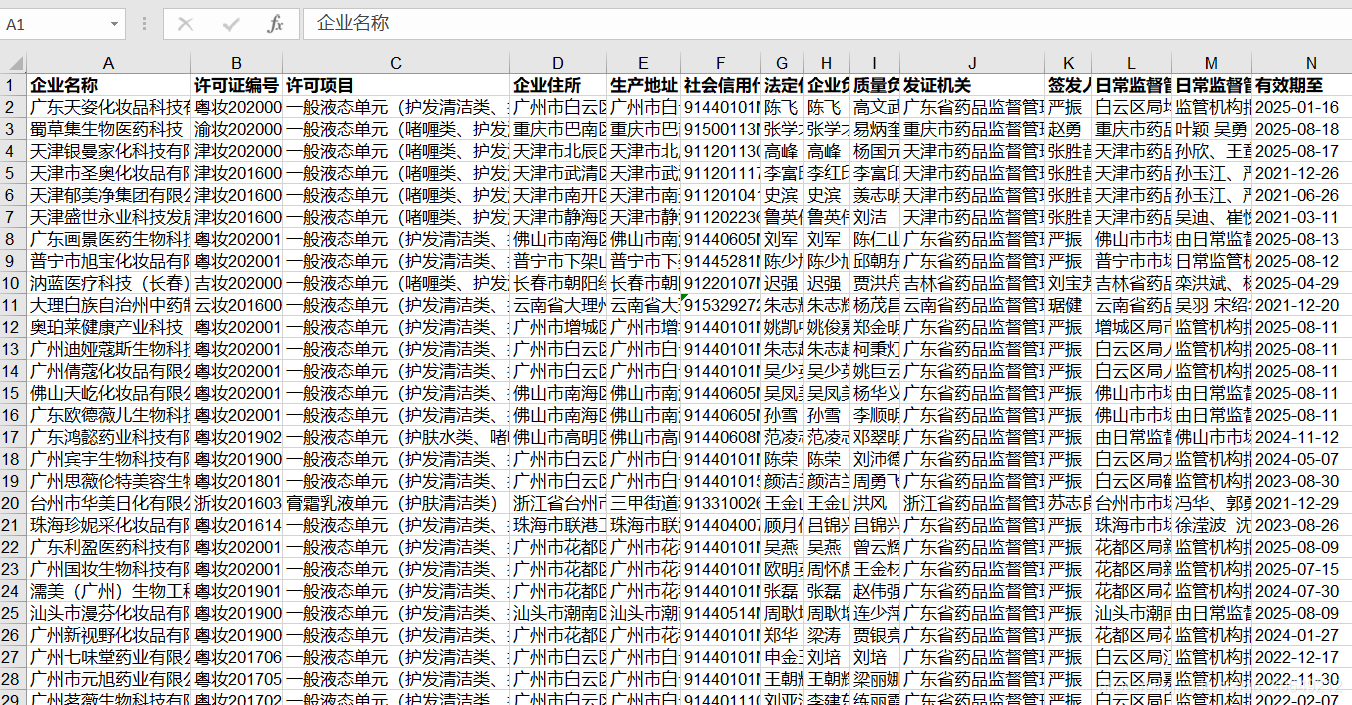
print("over")效果图

魔乐社区(Modelers.cn) 是一个中立、公益的人工智能社区,提供人工智能工具、模型、数据的托管、展示与应用协同服务,为人工智能开发及爱好者搭建开放的学习交流平台。社区通过理事会方式运作,由全产业链共同建设、共同运营、共同享有,推动国产AI生态繁荣发展。
更多推荐


 9
9 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)