深度学习入门(8):yolov4、yolov5
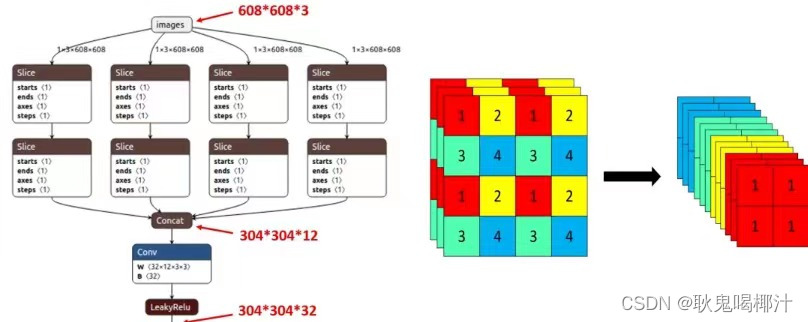
Focus模块在YOLOv5中是图片进入Backbone前,对图片进行切片操作,具体操作是在一张图片中每隔一个像素拿到一个值,类似于邻近下采样,这样就拿到了四张图片,四张图片互补,长得差不多,但是没有信息丢失,这样一来,将W、H信息就集中到了通道空间,输入通道扩充了4倍,即拼接起来的图片相对于原先的RGB三通道模式变成了12个通道,最后将得到的新图片再经过卷积操作,最终得到了没有信息丢失情况下的二
引言
发现了野生大佬对yolo前五个系列的总结,我给个传送门,本篇只是作为自己复习用,大量借鉴大佬的。
【YOLO系列】--YOLOv4超详细解读/总结(网络结构)-CSDN博客
YOLOv5【网络结构】超详细解读总结!!!建议收藏✨✨!-CSDN博客
正文
yolov4
Yolov4相较于Yolov3改进的地方:
(1)主干特征由DarkNet53改为CSPDarkNet53,主要在残差块进行了改进,引入了大残差块;
(2)加入了SPP和PANNnet网络,用来增加图像的特征提取量,反复提取特征,并且SPP网络也可以增大感受野。
(3)在激活函数方面:从Yolov3的Leaky_relu函数,在Yolov4使用新的Mish激活函数(Mish激活函数是一种自正则的非单调神经激活函数,平滑的激活函数允许更好的信息深入神经网络,从而得到更好的准确性和泛化。论文中提出,相比Swish有0.494%的提升,相比ReLU有1.671%的提升;该方法也在yolov4中得到了验证;)。
除了以上改进的地方,Yolov4还采用Mosaic数据增强,CIOU,学习率余弦退火衰减、标签平滑防止过拟合等操作。
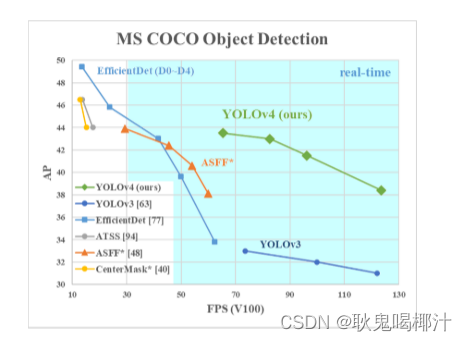
速度改进后与其他模型对比如下(YOLOv4和其他最先进的物体探测器的比较。YOLOv4的运行速度是EfficientDet的两倍,性能相当。将YOLOv3的AP和FPS分别提高10%和12%。)
spp 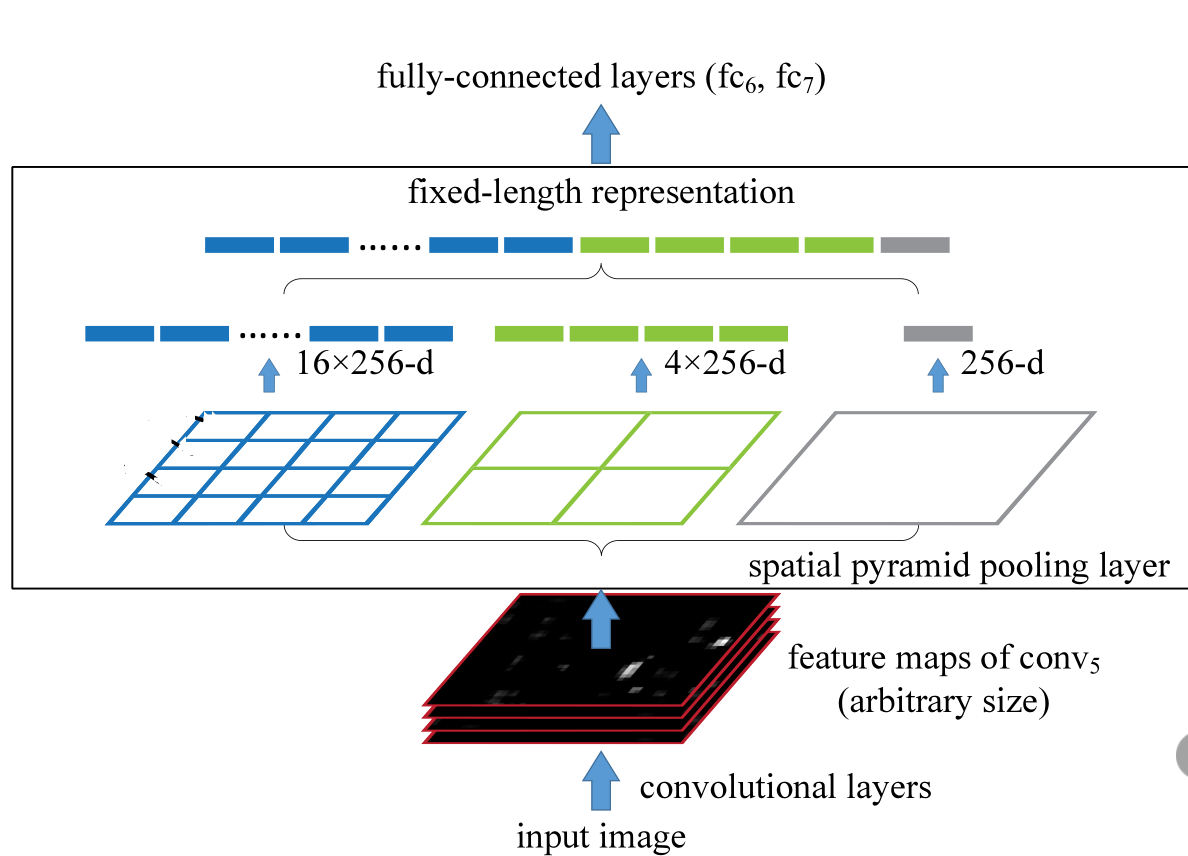
SPP 是一种空间金字塔池化结构,用于在卷积神经网络中将不同尺寸的特征图转化为固定长度的向量,从而可以接入全连接层,无需固定输入尺寸。
其做法为:
- 在最后一个卷积层的特征图上做不同尺度的划分(类似金字塔结构)。
- 比如划分为:
- 1×1(全局池化)
- 2×2(每个2x2块做池化)
- 4×4(划成16个块,每块池化)
- 在每个子区域上做 最大池化(max pooling),得到每个区域的特征向量。
- 把这些池化后的向量 拼接 成一个固定长度的向量,送入全连接层。
Pannet
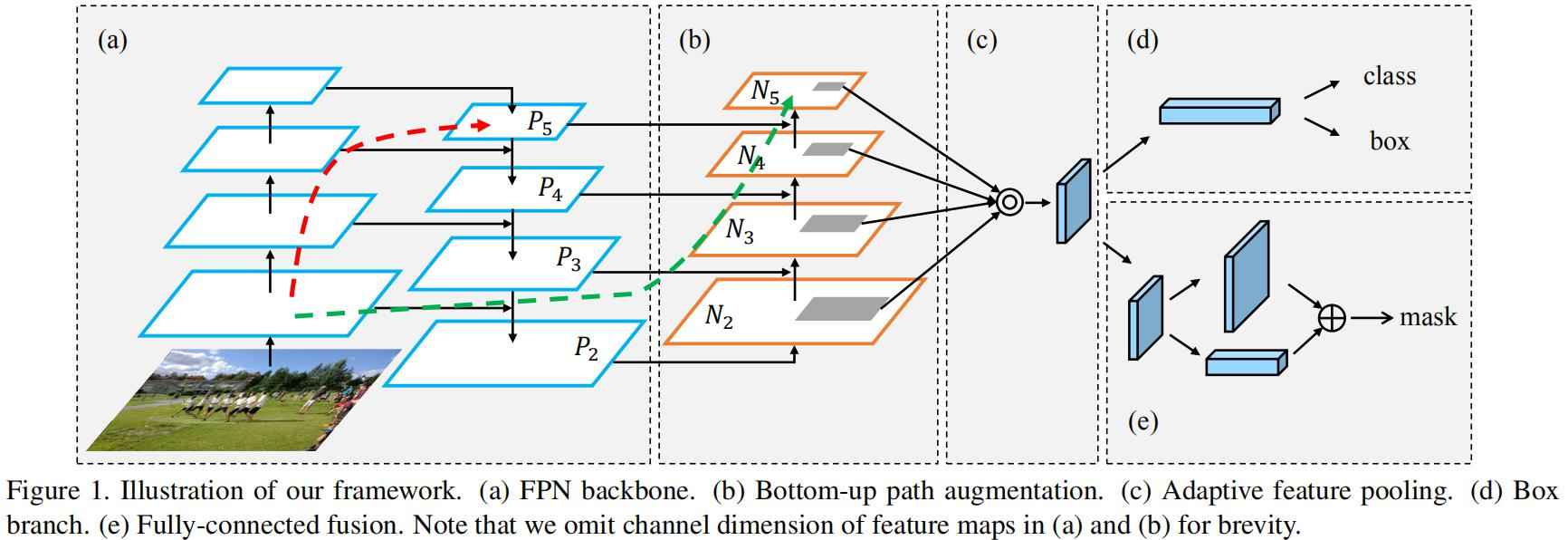
pannet的目标是:更有效地融合来自不同层次的特征,提高检测和分割性能,特别是对小目标的感知能力。从上图网络架构就能清晰感受到。
Mish激活函数: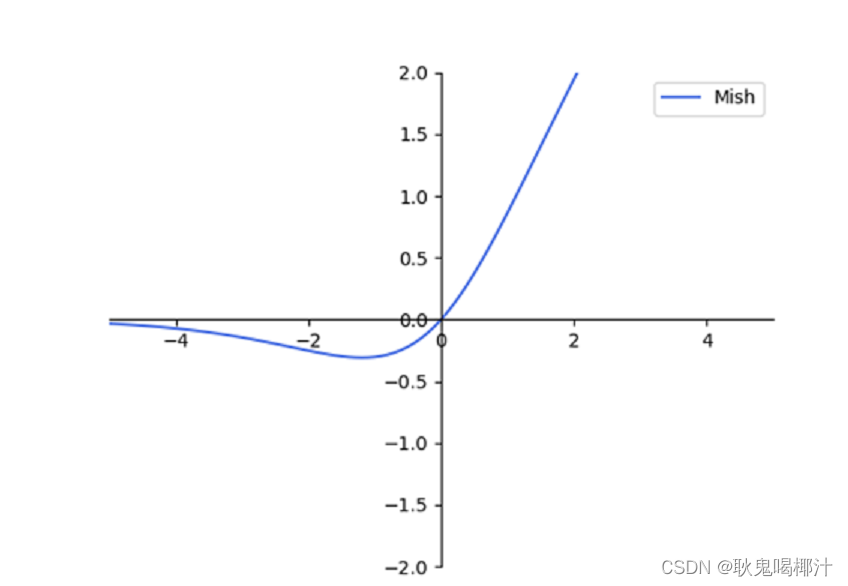 Mish 是一个平滑、非单调的激活函数,相比 ReLU 和 Swish,更有利于梯度传播和特征表达(因为他平滑,而且保留小负值),尤其在深层网络(非单调可学习更多)和目标检测中表现出更强性能。
Mish 是一个平滑、非单调的激活函数,相比 ReLU 和 Swish,更有利于梯度传播和特征表达(因为他平滑,而且保留小负值),尤其在深层网络(非单调可学习更多)和目标检测中表现出更强性能。
Mosaic数据增强
Yolov4中使用的Mosaic是参考2019年底提出的CutMix数据增强的方式,但CutMix只使用了两张图片进行拼接,而Mosaic数据增强则采用了4张图片,随机缩放、随机裁剪、随机排布的方式进行拼接。Mosaic解决在整体的数据集中,小、中、大目标的占比并不均衡。-在平时项目训练时,小目标的AP一般比中目标和大目标低很多。而Coco数据集中也包含大量的小目标,但比较麻烦的是小目标的分布并不均匀。针对这种状况,Yolov4的作者采用了Mosaic数据增强的方式,使大、中、小目标分配更加均匀。
CutMix数据增强的原因:在平时项目训练时,小目标的AP一般比中目标和大目标低很多。而Coco数据集中也包含大量的小目标,但比较麻烦的是小目标的分布并不均匀。Coco数据集中小目标占比达到41.4%,数量比中目标和大目标都要多。但在所有的训练集图片中,只有52.3%的图片有小目标,而中目标和大目标的分布相对来说更加均匀一些。
核心思想:将一部分区域cut掉但不填充0像素,而是随机填充训练集中的其他数据的区域像素值,分类结果按一定的比例分配。
处理方式:对一对图片做操作,随机生成一个裁剪框Box,裁剪掉A图的相应位置,然后用B图片相应位置的ROI放到A图中被裁剪的区域形成新的样本,ground truth标签会根据patch的面积按比例进行调整。
Self-Adversarial Training--SAT自对抗训练
通过引入噪音点进行数据增强:

Label Smoothing类标签平滑
原因:对预测有100%的信心可能表明模型是在记忆数据,而不是在学习。如果训练样本中会出现少量的错误样本,而模型过于相信训练样本,在训练过程中调整参数极力去逼近样本,这就导致了这些错误样本的负面影响变大。
具体做法:标签平滑调整预测的目标上限为一个较低的值,比如0.9。它将使用这个值而不是1.0来计算损失。这样就缓解了过度拟合。说白了,这个平滑就是一定程度缩小label中min和max的差距,label平滑可以减小过拟合。所以,适当调整label,让两端的极值往中间凑凑,可以增加泛化性能。

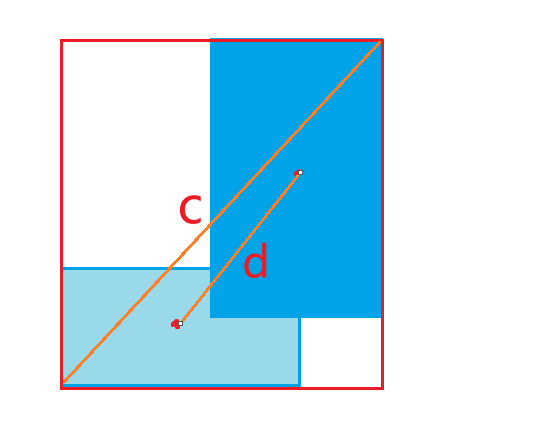
CIOU
公式为:
其中:
(1). d 为预测框和真实框中心点的距离,c 为最小外接矩形的对角线距离。
,
,其中
是比例因子,
是为了修正宽高比例过大过小的问题。
余弦退火学习率 (摘自狗都会用的余弦退火(CosineAnnealingLR)学习率调节算法讲解-CSDN博客)
余弦退火学习率的作者认为神经网络在刚开始训练时,并非如同理想的情况(见下图)一样,只需要确定一个方向即可。模型参数在初始化时,是非常不稳定的,因此在刚开始时需要选用小的学习率。但是小的学习率会让训练过程非常缓慢,因此这里会采用以较低学习率逐渐增大至较高学习率的方式实现网络训练的“热身”阶段,称为 warm up stage。
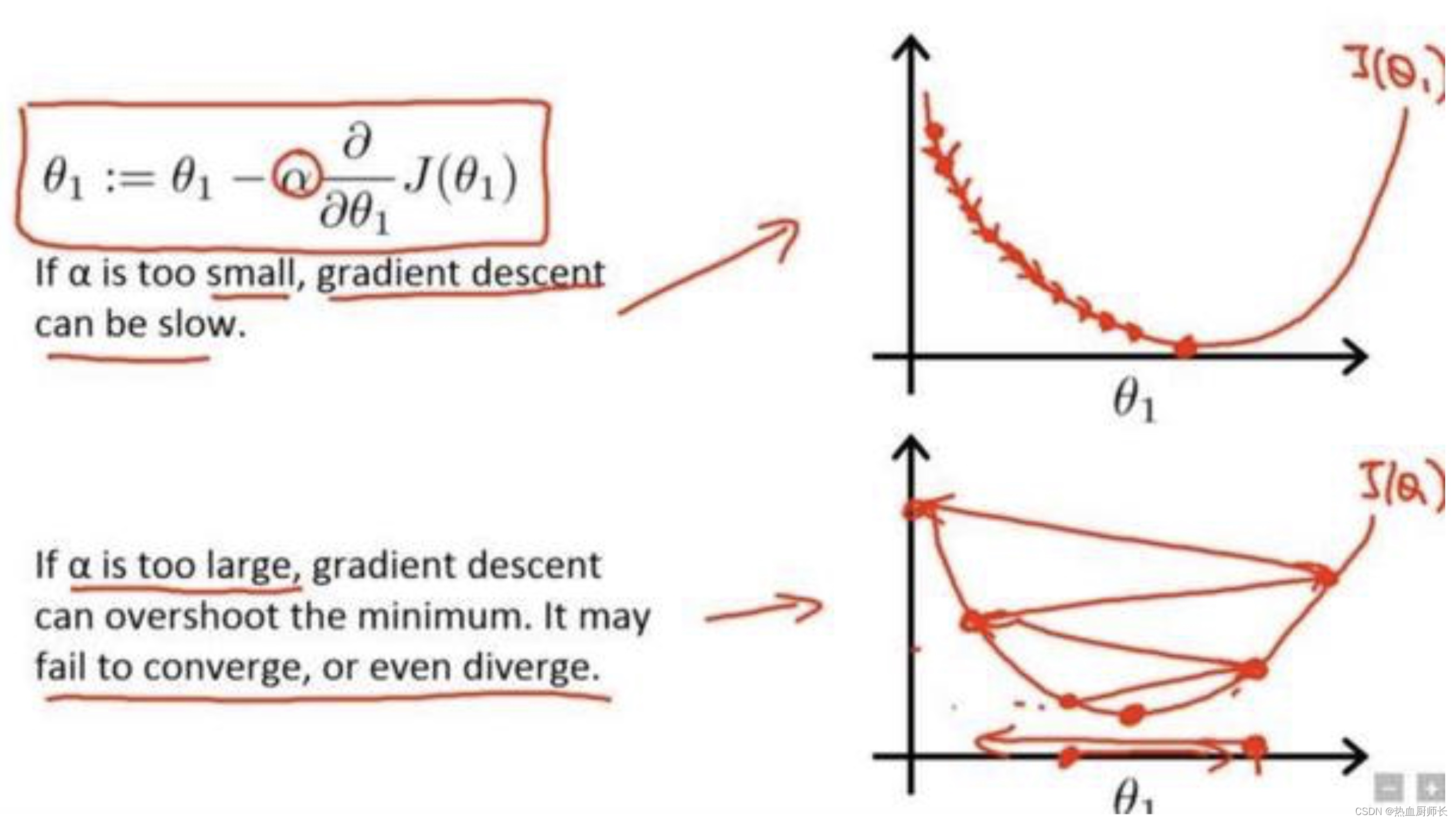
如果我们使得网络训练的 loss 最小,那么一直使用较高学习率是不合适的,因为它会使得权重的梯度一直来回震荡,很难使训练的损失值达到全局最低谷。所以学习率还是需要下降,可以通过余弦函数来降低学习率。余弦函数中随着x的增加余弦值首先缓慢下降,然后加速下降,再次缓慢下降。这种下降模式能和学习率配合,以一种十分有效的计算方式来产生很好的效果。
上述过程就称为余弦退火。
yolov5
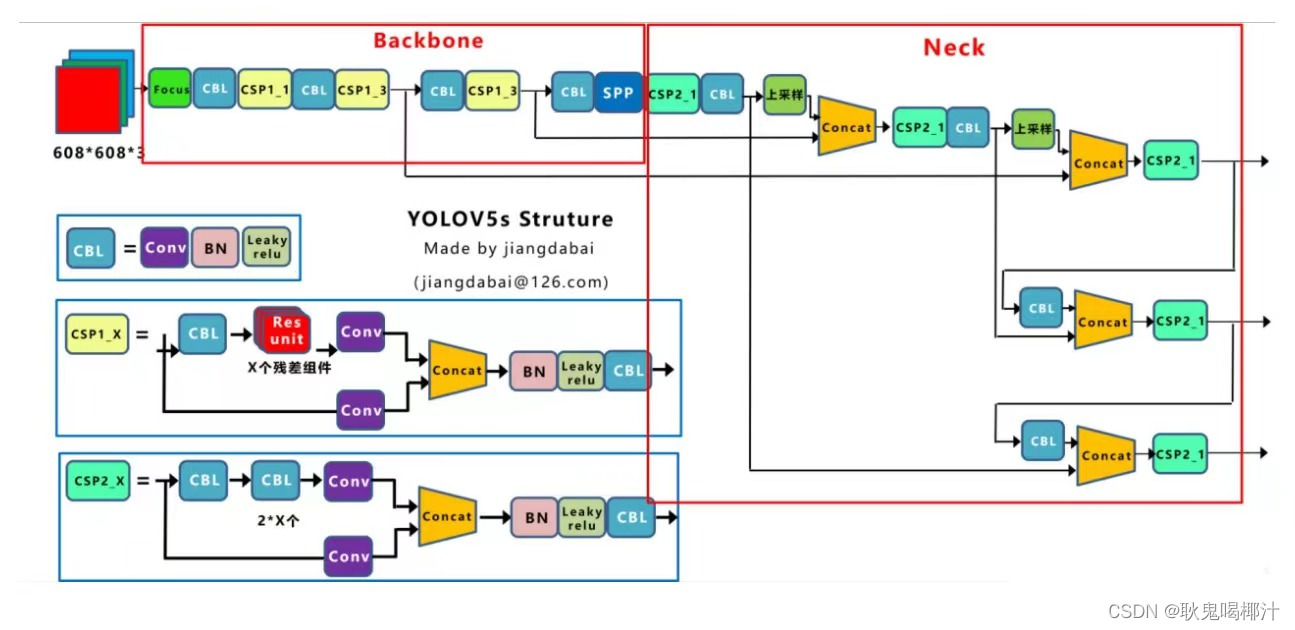
YOLOv5 网络结构
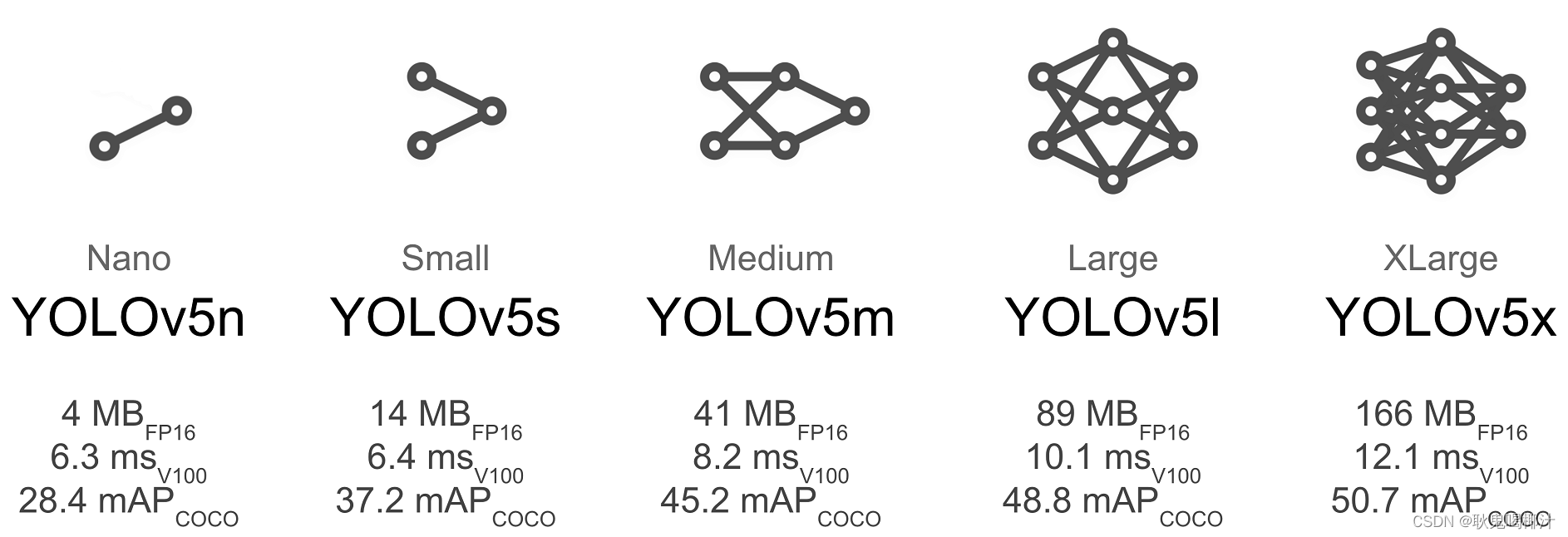
Yolov5官方代码中,给出的目标检测网络中一共有4个版本,分别是Yolov5s、Yolov5m、Yolov5l、Yolov5x四个模型。如下图所示:这几个模型的结构基本是一样的,不同的是(depth_multiple)模型深度和width_multiple(模型宽度)这两个参数。YOLOv5s网络是YOLOv5系列中深度最小,特征图的宽度最小的网络。其他的三种都是在此基础上不断加深,不断加宽。
结构改进:
| 模块 | YOLOv4 | YOLOv5 |
|---|---|---|
| Backbone | CSPDarknet53 | Focus + CSP Bottleneck |
| Neck | PANet | PANet(更轻量) |
| Head | YOLO Head | YOLO Head |
| 激活函数 | Mish / LeakyReLU | SiLU(Swish) |
SiLU激活函数:
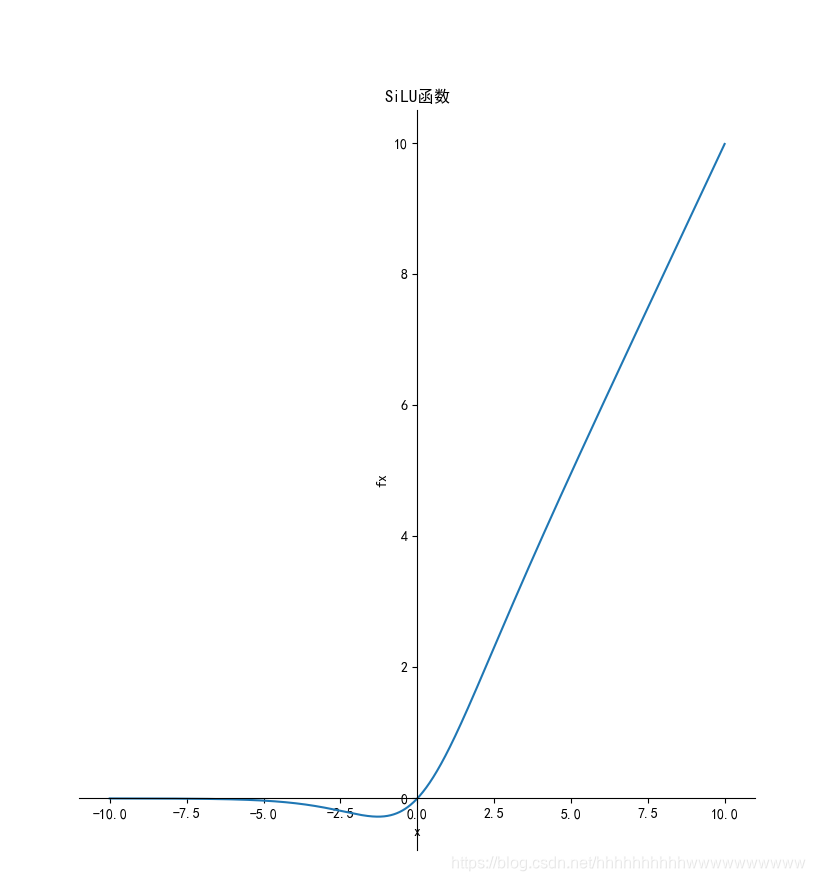
其特点是平滑且非单调,小于0也能保持一部分数据。
Focus结构:
Focus模块在YOLOv5中是图片进入Backbone前,对图片进行切片操作,具体操作是在一张图片中每隔一个像素拿到一个值,类似于邻近下采样,这样就拿到了四张图片,四张图片互补,长得差不多,但是没有信息丢失,这样一来,将W、H信息就集中到了通道空间,输入通道扩充了4倍,即拼接起来的图片相对于原先的RGB三通道模式变成了12个通道,最后将得到的新图片再经过卷积操作,最终得到了没有信息丢失情况下的二倍下采样特征图。
以YOLOv5s为例,原始的640 × 640 × 3的图像输入Focus结构,采用切片操作,先变成320 × 320 × 12的特征图,再经过一次卷积操作,最终变成320 × 320 × 32的特征图。
切片操作如下:
Anchor自动聚类
YOLOv5 自动计算 Anchor 框,通过 K-means + 置信度评估方式寻找最佳 Anchor 尺寸,减少了手动调整 Anchor 的麻烦。
CSP结构
CSPNet主要是将feature map拆成两个部分,一部分进行卷积操作,另一部分和上一部分卷积操作的结果进行concate。
在之前的YOLOv4网络结构中,借鉴了CSPNet的设计思路,在主干网络中设计了CSP结构。下图是YOLOv4的网络结构图:
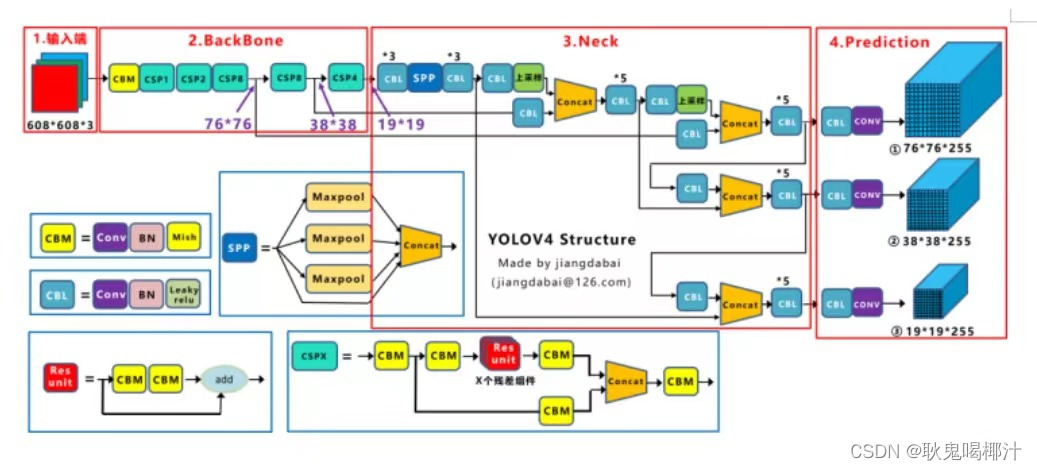
在目标检测问题中,使用CSPNet作为Backbone带来的提升比较大,可以有效增强CNN的学习能力,同时也降低了计算量。
虽然YOLOv4与YOLOv5都是用了CSP结构,但YOLOv5与其不同点在于:YOLOv4中只有主干网络使用了CSP结构。 而YOLOv5中设计了两种CSP结构,以YOLOv5s网络为例,CSP1_ X结构应用于Backbone主干网络,而CSP2_X结构则应用于Neck中。下图清楚的表示出来了:

魔乐社区(Modelers.cn) 是一个中立、公益的人工智能社区,提供人工智能工具、模型、数据的托管、展示与应用协同服务,为人工智能开发及爱好者搭建开放的学习交流平台。社区通过理事会方式运作,由全产业链共同建设、共同运营、共同享有,推动国产AI生态繁荣发展。
更多推荐


 22
22 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)