深度学习RNN详解:原理、变体、应用
在深度学习领域,卷积神经网络(CNN)凭借强大的空间特征提取能力,成为图像、视频等网格结构数据处理的首选;而针对**序列数据**——比如文本、语音、时间序列(股票价格、气象数据),循环神经网络(Recurrent Neural Network, RNN)则占据了核心地位。与CNN的“静态特征提取”不同,RNN最大的优势的是“**记忆性**”,它能利用历史序列信息,捕捉数据中的**时序依赖关系**,
目录
深度学习RNN详解:原理、变体、应用
在深度学习领域,卷积神经网络(CNN)凭借强大的空间特征提取能力,成为图像、视频等网格结构数据处理的首选;而针对序列数据——比如文本、语音、时间序列(股票价格、气象数据),循环神经网络(Recurrent Neural Network, RNN)则占据了核心地位。与CNN的“静态特征提取”不同,RNN最大的优势的是“记忆性”,它能利用历史序列信息,捕捉数据中的时序依赖关系,比如理解一句话中上下文的逻辑、预测下一个时间点的温度、生成连贯的文本。
很多初学者在入门RNN时,容易被“循环”“隐藏状态”“梯度消失”等概念困住,也难以区分RNN与LSTM、GRU的差异,更不清楚不同场景下该如何选择和使用RNN。
一、RNN基础入门:什么是RNN?核心定位是什么?
先抛开复杂的公式和结构,我们用一个生活化的例子理解RNN的核心逻辑:当你阅读这句话时,你不会孤立地看待每个字——看到“下雨”,后面看到“要带”,就会自然联想到“伞”;看到“今天”,后面看到“温度”,就会预期接下来是具体的数值。这种“利用前面的信息,理解后面的内容”的能力,就是RNN的核心——时序记忆能力。
从定义来看,RNN是一种专门处理序列数据(Sequence Data)的深度学习模型,其网络结构中包含“循环连接”,允许信息在网络中持续传递,从而实现对历史序列信息的记忆和利用。序列数据的核心特点是“顺序至关重要”,比如文本的语序、语音的时序、时间序列的先后顺序,一旦打乱,数据的含义就会发生改变,而RNN正是为适配这种特性而设计的。
1.1 为什么需要RNN?传统神经网络的局限性
在RNN出现之前,传统的全连接神经网络(FCN)也被尝试用于处理序列数据,但存在两个致命缺陷,无法满足实际需求:
-
输入输出长度固定:传统FCN要求输入和输出的维度是固定的,而现实中的序列数据长度往往不固定(比如一句话可能3个字,也可能10个字;一段语音可能1秒,也可能10秒),无法直接适配;
-
无法捕捉时序依赖:传统FCN会将序列数据“扁平化”处理(比如将一句话的所有字向量拼接成一个长向量输入),完全忽略了数据的顺序和上下文关联——比如“我吃苹果”和“苹果吃我”,扁平化后输入相同,但含义完全相反,传统FCN无法区分。
RNN的出现,正是为了解决这两个问题:它允许输入和输出长度不固定,并且能通过循环结构,将历史序列的信息“存储”起来,用于当前的预测和判断,完美适配序列数据的特性。
1.2 RNN的核心结构(直观理解)
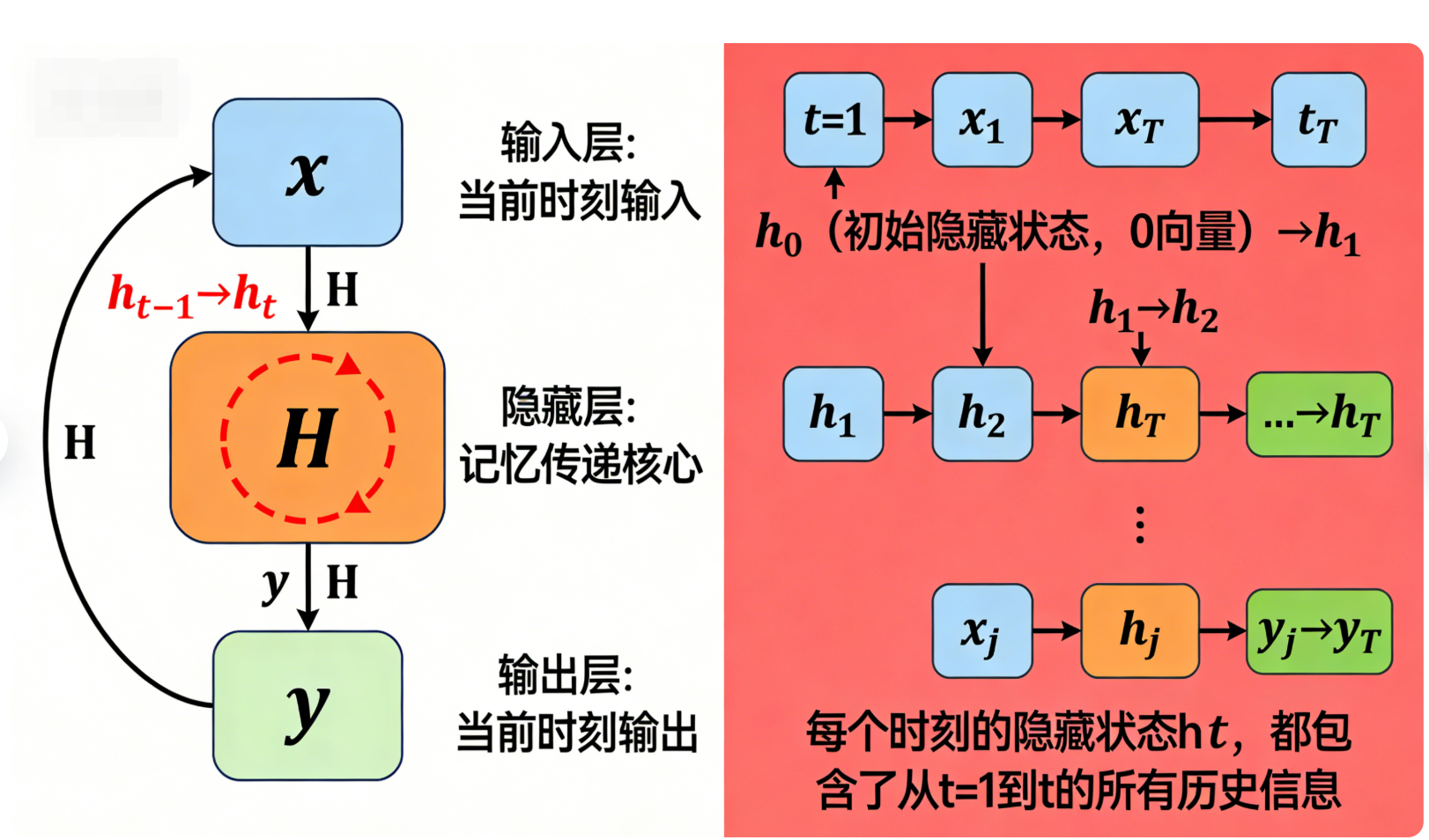
RNN的基础结构非常简洁,核心由三部分组成:输入层(Input Layer)、隐藏层(Hidden Layer)、输出层(Output Layer),与传统FCN的最大区别是:隐藏层的输出会反馈到自身,形成循环。
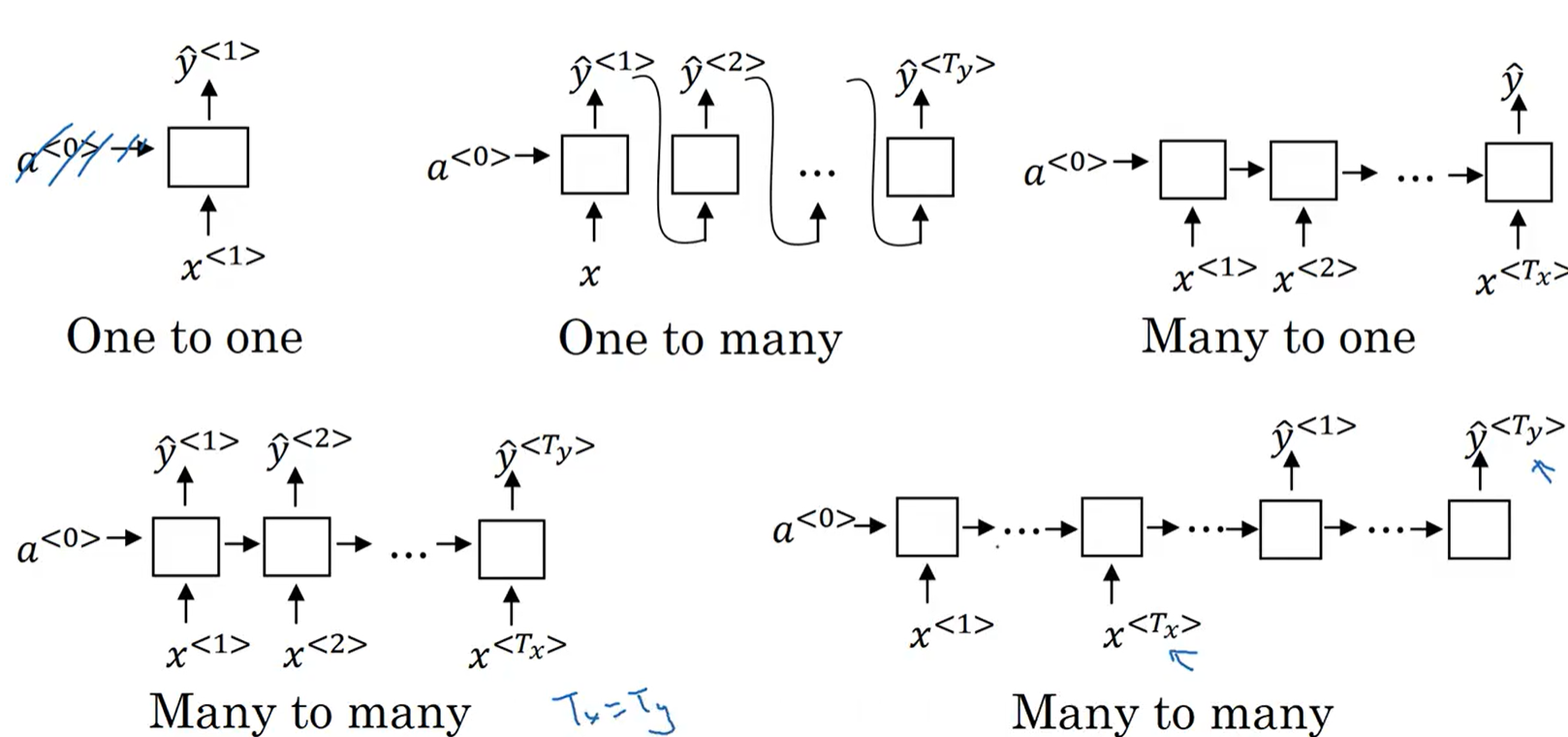
我们用“时序分步”的视角来拆解这个结构(假设处理一个长度为T的序列,t=1,2,…,T代表序列的每个时刻):
-
输入层:每个时刻t,输入一个特征向量xₜ(比如处理文本时,xₜ是第t个汉字的词向量;处理时间序列时,xₜ是第t个时刻的特征值);
-
隐藏层:接收两个输入——当前时刻的输入xₜ,以及上一个时刻隐藏层的输出hₜ₋₁(历史记忆信息);通过激活函数处理后,输出当前时刻的隐藏状态hₜ(更新后的记忆信息);
-
输出层:接收当前时刻的隐藏状态hₜ,输出当前时刻的预测结果yₜ(比如预测下一个字、下一个时刻的数值)。
这里的关键是“隐藏状态hₜ”:它相当于RNN的“记忆单元”,存储了从序列开始到当前时刻t的所有历史信息(或者说,是历史信息的压缩表示);每个时刻的记忆都会根据当前输入更新,再传递到下一个时刻,这就是RNN“记忆性”的来源。
二、RNN核心原理:数学公式+隐藏状态的传递逻辑
理解了RNN的直观结构后,我们通过数学公式,精准拆解隐藏状态的更新逻辑和输出计算过程——这是掌握RNN的核心,也是后续理解“梯度消失/爆炸”和RNN变体的基础。
2.1 核心符号定义(先明确每个符号的含义)
假设我们处理一个长度为T的序列,每个时刻的核心符号定义如下:
-
xₜ ∈ Rⁿ:第t时刻的输入向量,n是输入特征维度(比如词向量维度为100,n=100);
-
hₜ ∈ Rᵏ:第t时刻的隐藏状态向量,k是隐藏层神经元数量(可自定义,比如k=128);
-
yₜ ∈ Rᵐ:第t时刻的输出向量,m是输出维度(比如文本分类任务m=10,代表10个类别);
-
Wₓₕ ∈ Rᵏˣⁿ:输入层到隐藏层的权重矩阵;
-
Wₕₕ ∈ Rᵏˣᵏ:隐藏层到自身(循环)的权重矩阵;
-
Wₕᵧ ∈ Rᵐˣᵏ:隐藏层到输出层的权重矩阵;
-
bₕ ∈ Rᵏ:隐藏层的偏置向量;
-
bᵧ ∈ Rᵐ:输出层的偏置向量;
-
σ(·):激活函数(隐藏层常用tanh、sigmoid;输出层根据任务选择,分类用softmax,回归用恒等函数)。
2.2 隐藏状态更新公式(核心中的核心)
RNN的隐藏状态hₜ,是由“当前时刻输入xₜ”和“上一时刻隐藏状态hₜ₋₁”共同决定的,更新公式如下:
h t = σ ( W x h x t + W h h h t − 1 + b h ) h_t = \sigma(W_{xh}x_t + W_{hh}h_{t-1} + b_h) ht=σ(Wxhxt+Whhht−1+bh)
公式解读(通俗理解):
-
第一项 W x h x t W_{xh}x_t Wxhxt :将当前时刻的输入xₜ,通过权重矩阵Wₓₕ,映射到隐藏层的维度(相当于“提取当前输入的特征”);
-
第二项 W h h h t − 1 W_{hh}h_{t-1} Whhht−1 :将上一时刻的隐藏状态hₜ₋₁(历史记忆),通过权重矩阵Wₕₕ,映射到当前隐藏层维度(相当于“调用历史记忆”);
-
加上偏置bₕ后,通过激活函数σ(·)处理,得到当前时刻的隐藏状态hₜ(相当于“融合当前特征和历史记忆,更新新的记忆”)。
这里有两个关键注意点:
-
初始隐藏状态h₀:序列的第一个时刻(t=1),没有上一时刻的隐藏状态,通常将h₀设为全0向量(也可通过模型初始化自定义);
-
激活函数的选择:隐藏层不能用ReLU激活函数(容易导致梯度爆炸),早期常用tanh(输出范围[-1,1],梯度稳定),也可用sigmoid(输出范围[0,1]);激活函数的作用是引入非线性,让RNN能拟合复杂的时序依赖关系(如果没有激活函数,隐藏状态的更新就是线性变换,无法捕捉复杂模式)。
2.3 输出层计算公式
当前时刻的输出yₜ,仅由当前时刻的隐藏状态hₜ决定(因为hₜ已经包含了所有历史信息),公式如下:
y t = σ ′ ( W h y h t + b y ) y_t = \sigma'(W_{hy}h_t + b_y) yt=σ′(Whyht+by)
公式解读:
-
σ ′ ( ⋅ ) \sigma'(·) σ′(⋅) 是输出层的激活函数,与隐藏层的σ(·)可不同:
-
分类任务(比如文本情感分类、语音识别):用softmax激活,输出每个类别的概率(总和为1);
-
回归任务(比如股价预测、温度预测):用恒等函数(即不使用激活函数),输出连续值;
-
二分类任务:也可用sigmoid激活,输出单个概率值(0~1)。
2.4 RNN的训练原理:反向传播通过时间(BPTT)
RNN的训练方法是传统反向传播(BP)的变体,称为“反向传播通过时间(Backpropagation Through Time, BPTT)”。核心逻辑与BP一致:通过前向传播计算输出yₜ,对比真实标签计算损失(比如交叉熵损失、MSE损失),再通过反向传播更新所有权重(Wₓₕ、Wₕₕ、Wₕᵧ)和偏置(bₕ、bᵧ),最小化损失。
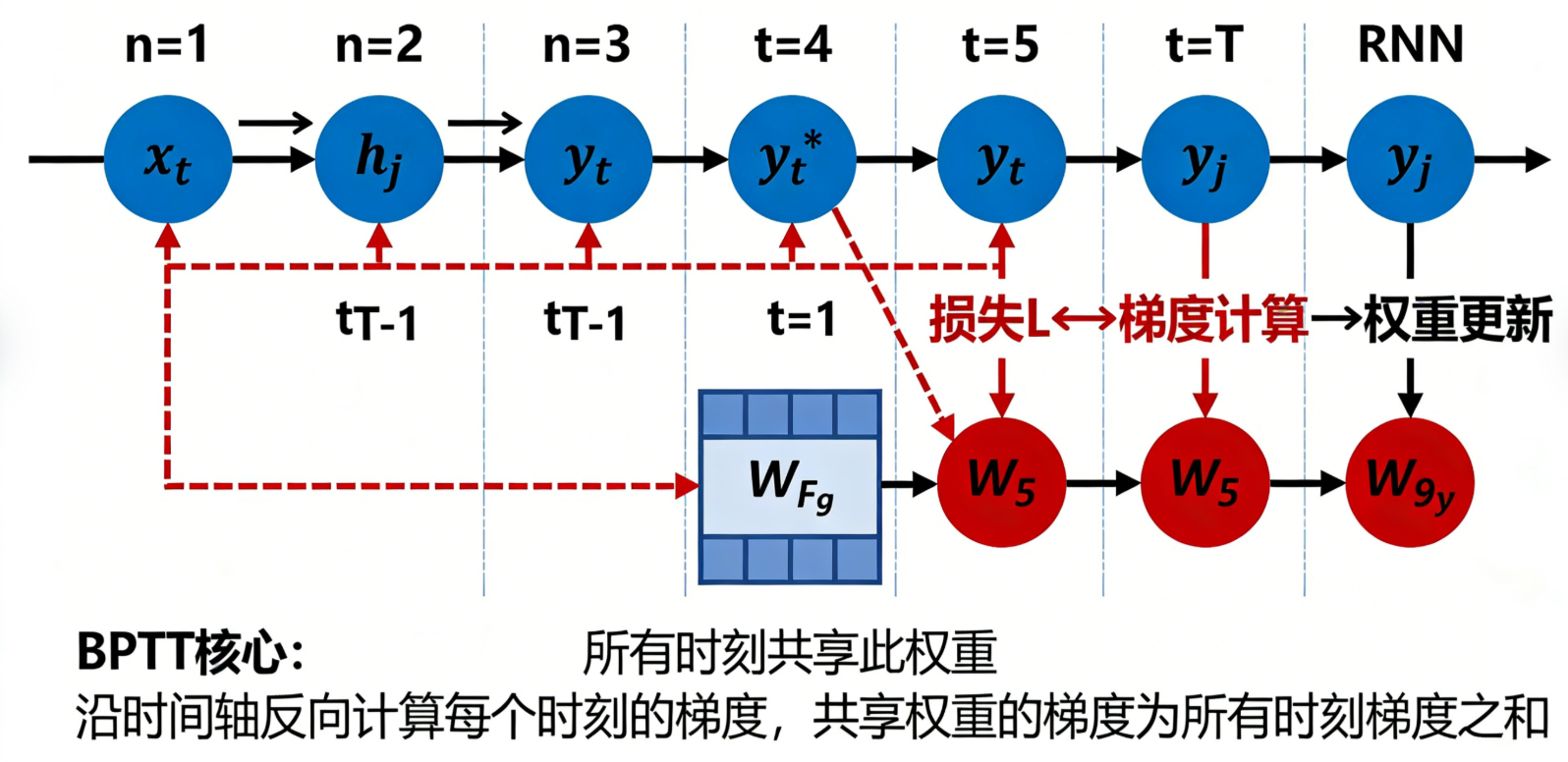
与传统BP的最大区别是:RNN的损失是所有时刻输出损失的总和( L = ∑ t = 1 T L t L = \sum_{t=1}^T L_t L=∑t=1TLt ,Lₜ是第t时刻的损失),反向传播时,需要“沿着时间轴”反向计算每个时刻的梯度,更新权重——因为权重Wₕₕ(循环权重)在所有时刻都被共享,每个时刻的梯度都会影响这个权重的更新。
2.5 RNN的致命缺陷:梯度消失与梯度爆炸
虽然RNN的设计理念完美适配序列数据,但传统RNN( vanilla RNN)在实际应用中,很难处理长序列(比如长度超过20的文本、时间序列),核心原因是BPTT训练过程中会出现“
梯度消失”或“梯度爆炸”问题——这也是后续LSTM、GRU等变体出现的核心动力。
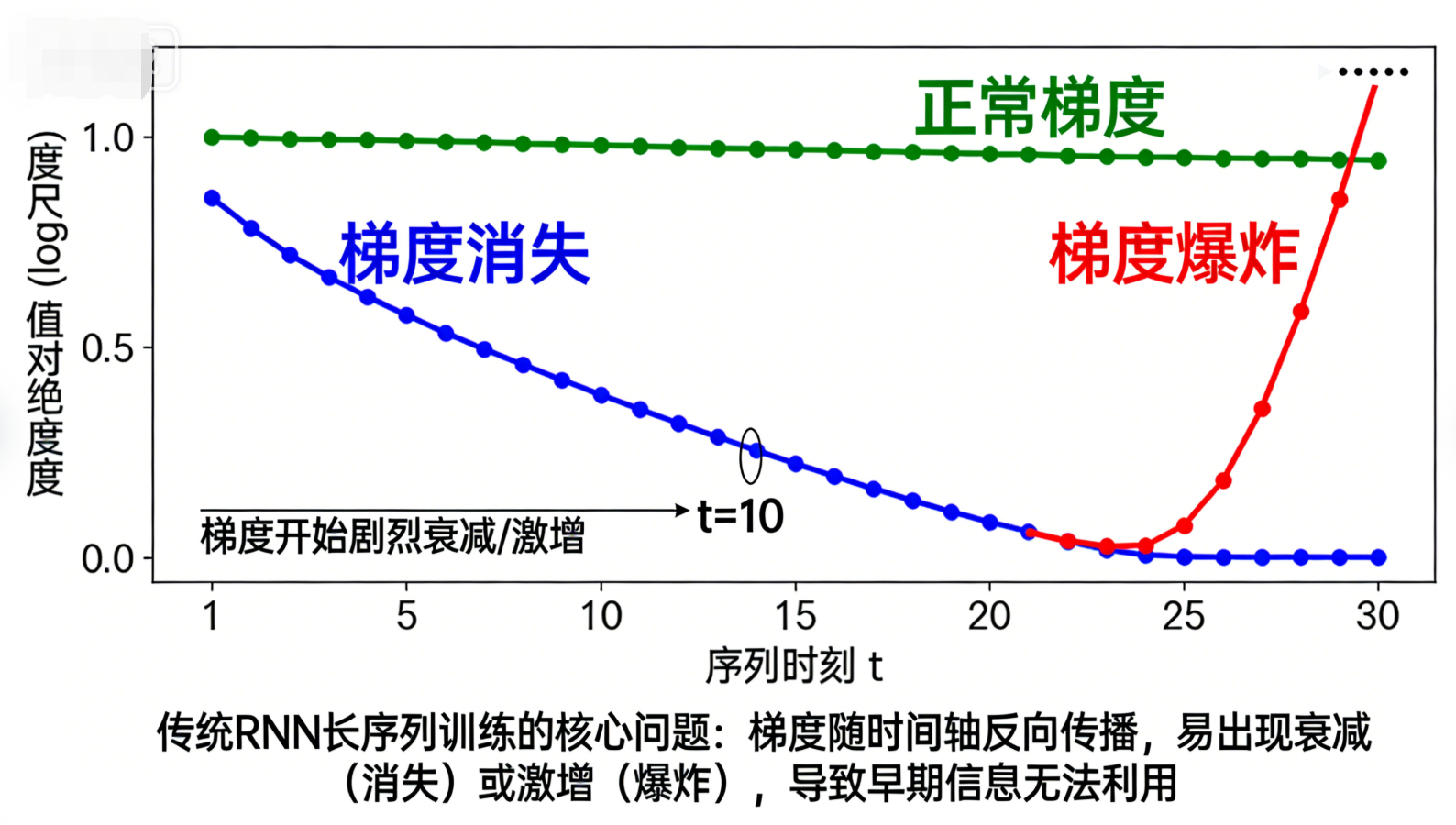
1. 梯度消失(最常见)
梯度消失是指:当序列过长时,反向传播的梯度会随着时间轴逐渐衰减,最终趋近于0。这会导致“早期时刻的输入信息无法影响权重更新”----比如处理一句话“我昨天去公园,看到了一只____”,RNN无法利用“公园”这个早期信息,预测出“鸟”“猫”等合理答案,相当于“忘记了”早期的记忆。
核心原因:隐藏层激活函数(tanh、sigmoid)的梯度范围很小(tanh梯度范围[-1,1],sigmoid梯度范围[0,0.25]);而BPTT中,梯度的计算会涉及权重矩阵Wₕₕ的多次幂(沿时间轴反向传播一次,就会多乘一次Wₕₕ)。当Wₕₕ的特征值小于1时,多次幂后会趋近于0,导致梯度消失;当特征值大于1时,多次幂后会趋近于无穷大,导致梯度爆炸。
2. 梯度爆炸(较少见,但更致命)
梯度爆炸是指:梯度随着时间轴反向传播,逐渐增大到无穷大,导致权重更新时出现“数值溢出”,模型直接无法训练(比如权重变成NaN、无穷大)。
解决方案(临时缓解,非根本解决):
-
梯度裁剪(Gradient Clipping):当梯度的绝对值超过某个阈值时,将梯度裁剪到阈值范围内,避免梯度过大;
-
权重初始化:采用合适的权重初始化方法(比如Xavier初始化),让Wₕₕ的特征值尽量接近1,减少梯度消失/爆炸的概率;
-
缩短序列长度:将长序列截断或分段处理,减少时间轴的长度,降低梯度衰减/激增的幅度。
注意:以上方法只能临时缓解问题,无法从根本上解决传统RNN的梯度缺陷——这也是LSTM、GRU等变体诞生的核心原因,它们通过设计更复杂的“记忆单元”,实现了对长期信息的有效记忆,彻底解决了梯度消失问题。
三、RNN的核心变体:LSTM、GRU详解(解决梯度消失的关键)
为了解决传统RNN的梯度消失问题,研究者们提出了多种RNN变体,其中最常用、最核心的两种是:长短期记忆网络(Long Short-Term Memory, LSTM)和门控循环单元(Gated Recurrent Unit, GRU)。它们的核心思想一致:通过“门控机制”,自主控制历史信息的“遗忘”和当前信息的“更新”,实现对长期信息的有效记忆,同时避免梯度消失。
其中,LSTM是最早提出(1997年)、结构最完善的变体,GRU是2014年提出的简化版LSTM,结构更简洁、计算效率更高,两者在实际应用中都非常广泛,我们分别详细拆解。
3.1 LSTM详解:长短期记忆网络(最常用)
LSTM的核心改进是:将传统RNN的“单一隐藏状态hₜ”,替换为“隐藏状态hₜ + 细胞状态cₜ(Cell State)”,并引入了三个“门控单元”(输入门、遗忘门、输出门),通过门控单元的开关,控制细胞状态的更新和信息的传递——细胞状态相当于LSTM的“长期记忆仓库”,门控单元相当于“仓库的管理员”,决定哪些信息可以进入仓库、哪些信息可以被丢弃、哪些信息可以被输出。
与传统RNN相比,LSTM的梯度传播更顺畅:细胞状态的更新过程中,梯度可以直接通过细胞状态“直连”传播,避免了权重矩阵的多次幂导致的梯度衰减,从而彻底解决了梯度消失问题,能够有效处理长序列。
3.1.1 LSTM的核心结构(门控单元+细胞状态)
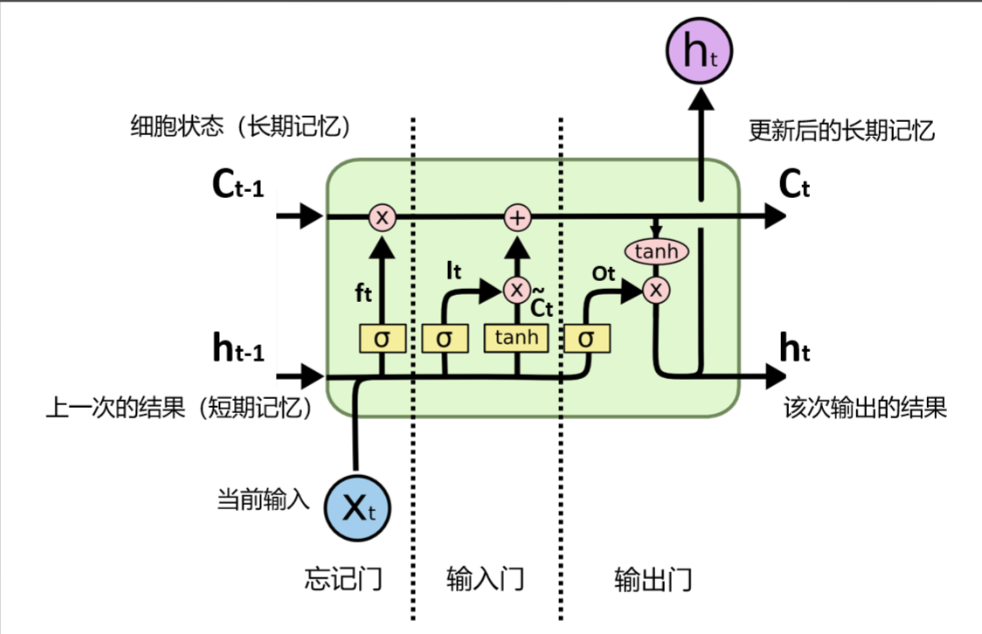
LSTM的结构比传统RNN复杂,我们先明确其核心组成:
-
细胞状态cₜ:LSTM的“长期记忆”,相当于一条“信息高速公路”,信息可以在上面直接传递,梯度也可以通过它顺畅传播;细胞状态的更新由遗忘门和输入门共同控制;
-
三个门控单元(输入门、遗忘门、输出门):每个门控单元都是一个“神经网络层”,输入是当前时刻的输入xₜ和上一时刻的隐藏状态hₜ₋₁,输出是一个0-1之间的向量(通过sigmoid激活),向量中的每个元素对应一个“开关”——0表示完全关闭(禁止信息通过),1表示完全打开(允许信息通过),0~1之间表示部分允许;
-
候选细胞状态 c ~ t \tilde{c}_t c~t :根据当前输入xₜ和上一时刻隐藏状态hₜ₋₁,计算得到的“候选长期记忆”,用于更新细胞状态cₜ;
-
隐藏状态hₜ:LSTM的“短期记忆”,由输出门和细胞状态共同控制,用于输出当前时刻的信息;
-
输出yₜ:与传统RNN一致,由当前时刻的隐藏状态hₜ计算得到。
3.1.2 LSTM的数学公式(详细拆解每个环节)
我们按“门控计算→细胞状态更新→隐藏状态更新→输出计算”的顺序,拆解LSTM的数学公式,所有符号的定义与传统RNN一致(新增符号单独说明):
- 遗忘门(Forget Gate):决定上一时刻的细胞状态cₜ₋₁中,哪些信息需要被遗忘(丢弃)
f t = σ ( W x f x t + W h f h t − 1 + b f ) f_t = \sigma(W_{xf}x_t + W_{hf}h_{t-1} + b_f) ft=σ(Wxfxt+Whfht−1+bf)
解读:
fₜ ∈
Rᵏ(与隐藏层神经元数量一致),每个元素都是0~1之间的值;值越接近0,对应位置的cₜ₋₁信息越需要被遗忘;值越接近1,对应位置的cₜ₋₁信息越需要被保留。
- 输入门(Input Gate):决定当前时刻的候选细胞状态 c ~ t \tilde{c}_t c~t 中,哪些信息需要被添加到新的细胞状态cₜ中
i t = σ ( W x i x t + W h i h t − 1 + b i ) i_t = \sigma(W_{xi}x_t + W_{hi}h_{t-1} + b_i) it=σ(Wxixt+Whiht−1+bi)
解读:iₜ ∈ Rᵏ,每个元素都是0~1之间的值;值越接近1,对应位置的 c ~ t \tilde{c}_t c~t
信息越需要被添加到cₜ中;值越接近0,对应位置的 c ~ t \tilde{c}_t c~t 信息越需要被丢弃。
- 候选细胞状态 c ~ t \tilde{c}_t c~t :计算当前时刻的候选长期记忆,包含当前输入的新信息
c ~ t = tanh ( W x c x t + W h c h t − 1 + b c ) \tilde{c}_t = \tanh(W_{xc}x_t + W_{hc}h_{t-1} + b_c) c~t=tanh(Wxcxt+Whcht−1+bc)
解读: c ~ t \tilde{c}_t c~t ∈
Rᵏ,通过tanh激活,输出范围[-1,1];它包含了当前时刻输入xₜ和上一时刻隐藏状态hₜ₋₁的新特征,是待添加到细胞状态cₜ中的“候选信息”。
- 细胞状态更新:融合遗忘门的“遗忘决策”和输入门的“新增决策”,更新得到当前时刻的细胞状态cₜ
c t = f t ⊙ c t − 1 + i t ⊙ c ~ t c_t = f_t \odot c_{t-1} + i_t \odot \tilde{c}_t ct=ft⊙ct−1+it⊙c~t
解读: ⊙ \odot ⊙ 表示“元素-wise乘法”(对应位置相乘);
第一项 f t ⊙ c t − 1 f_t \odot c_{t-1} ft⊙ct−1 :上一时刻的细胞状态cₜ₋₁,按遗忘门fₜ的决策,丢弃无用信息(fₜ中0对应的位置,cₜ₋₁的信息被置为0);
第二项 i t ⊙ c ~ t i_t \odot \tilde{c}_t it⊙c~t :当前时刻的候选细胞状态 c ~ t \tilde{c}_t c~t ,按输入门iₜ的决策,保留有用信息(iₜ中1对应的位置, c ~ t \tilde{c}_t c~t 的信息被保留);
两者相加,得到新的细胞状态cₜ——既保留了上一时刻的有用长期记忆,又添加了当前时刻的新信息。
-
输出门(Output Gate):决定当前时刻的细胞状态cₜ中,哪些信息需要被输出到隐藏状态hₜ中:
o t = σ ( W x o x t + W h o h t − 1 + b o ) o_t = \sigma(W_{xo}x_t + W_{ho}h_{t-1} + b_o) ot=σ(Wxoxt+Whoht−1+bo)
解读:oₜ ∈
Rᵏ,每个元素都是0~1之间的值;值越接近1,对应位置的cₜ信息越需要被输出到hₜ中;值越接近0,对应位置的cₜ信息越需要被隐藏。
- 隐藏状态更新:根据输出门的决策,从细胞状态cₜ中提取信息,得到当前时刻的隐藏状态hₜ
h t = o t ⊙ tanh ( c t ) h_t = o_t \odot \tanh(c_t) ht=ot⊙tanh(ct)
解读:先将细胞状态cₜ通过tanh激活,将值映射到[-1,1]范围(标准化),再按输出门oₜ的决策,提取有用信息,得到隐藏状态hₜ;hₜ既包含了当前时刻的短期信息,也包含了细胞状态中的长期信息。
- 输出层计算:与传统RNN一致
y t = σ ′ ( W h y h t + b y ) y_t = \sigma'(W_{hy}h_t + b_y) yt=σ′(Whyht+by)
3.1.3 LSTM的核心优势(对比传统RNN)
-
彻底解决梯度消失问题:细胞状态cₜ的更新过程中,梯度可以直接通过cₜ“直连”传播(无需经过权重矩阵的多次幂),梯度衰减被大幅抑制,能够有效处理长序列(比如长度为100+的文本);
-
自主控制记忆的遗忘与更新:通过三个门控单元,LSTM可以自主决定“遗忘哪些历史信息、保留哪些历史信息、添加哪些新信息”,更贴合实际序列数据的特性(比如处理文本时,会自动遗忘无关的虚词,保留关键的名词、动词);
-
长期记忆与短期记忆分离:细胞状态cₜ存储长期记忆,隐藏状态hₜ存储短期记忆,两者分工明确,能够更好地捕捉序列中的长短期依赖关系。
3.2 GRU详解:门控循环单元(简化版LSTM)
GRU是2014年由Cho等人提出的RNN变体,它的核心思想是:简化LSTM的结构,将LSTM的三个门控单元(遗忘门、输入门、输出门)简化为两个门控单元(重置门、更新门),同时去掉细胞状态cₜ,将长期记忆和短期记忆整合到隐藏状态hₜ中。
GRU的结构比LSTM更简洁,计算量更小(减少了一个门控单元和细胞状态的计算),训练速度更快;同时,它保留了LSTM的核心优势——解决梯度消失问题、捕捉长短期依赖关系,在很多场景下(比如文本分类、语音识别),GRU的性能与LSTM相差不大,因此被广泛应用于对计算效率有要求的场景。
3.2.1 GRU的核心结构(两个门控单元)
GRU的核心组成是“隐藏状态hₜ”和两个门控单元(重置门、更新门),没有细胞状态cₜ,结构更简洁:
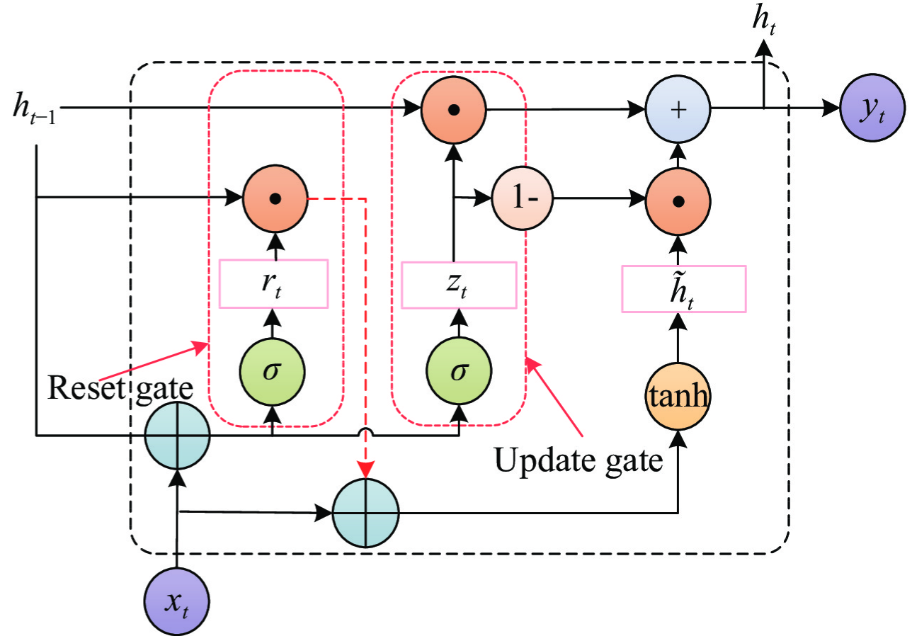
-
重置门(Reset Gate, rₜ):控制“是否忽略上一时刻的隐藏状态hₜ₋₁”——相当于LSTM遗忘门和输入门的部分功能,决定当前时刻的计算是否需要利用历史记忆;
-
更新门(Update Gate, zₜ):控制“上一时刻的隐藏状态hₜ₋₁和当前时刻的候选隐藏状态 h ~ t \tilde{h}_t h~t ,各占当前隐藏状态hₜ的比例”——相当于LSTM遗忘门和输出门的部分功能,决定历史记忆和新信息的融合比例;
-
候选隐藏状态 h ~ t \tilde{h}_t h~t :根据当前时刻的输入xₜ和“经过重置门筛选后的上一时刻隐藏状态”,计算得到的候选隐藏状态,包含当前输入的新信息;
-
隐藏状态hₜ:GRU的唯一记忆单元,整合了历史记忆(hₜ₋₁)和当前新信息( h ~ t \tilde{h}_t h~t ),同时承担了LSTM细胞状态和隐藏状态的功能。
3.2.2 GRU的数学公式(详细拆解)
GRU的公式比LSTM更少,我们按“门控计算→候选隐藏状态→隐藏状态更新→输出计算”的顺序拆解,符号定义与传统RNN、LSTM一致(新增符号单独说明):
- 重置门(rₜ):决定是否忽略上一时刻的隐藏状态hₜ₋₁
r t = σ ( W x r x t + W h r h t − 1 + b r ) r_t = \sigma(W_{xr}x_t + W_{hr}h_{t-1} + b_r) rt=σ(Wxrxt+Whrht−1+br)
解读:rₜ ∈
Rᵏ,每个元素都是0~1之间的值;值越接近0,越忽略hₜ₋₁的信息(相当于“重置”历史记忆,只利用当前输入xₜ);值越接近1,越保留hₜ₋₁的信息(相当于“保留”历史记忆,结合当前输入xₜ)。
- 更新门(zₜ):决定hₜ₋₁和 h ~ t \tilde{h}_t h~t 在hₜ中的融合比例
z t = σ ( W x z x t + W h z h t − 1 + b z ) z_t = \sigma(W_{xz}x_t + W_{hz}h_{t-1} + b_z) zt=σ(Wxzxt+Whzht−1+bz)
解读:zₜ ∈ Rᵏ,每个元素都是0~1之间的值;值越接近1,hₜ越接近hₜ₋₁(保留更多历史记忆);值越接近0,hₜ越接近
h ~ t \tilde{h}_t h~t (保留更多当前新信息)。
- 候选隐藏状态 h ~ t \tilde{h}_t h~t :结合当前输入和筛选后的历史记忆,计算新信息
h ~ t = tanh ( W x h x t + W h h ( r t ⊙ h t − 1 ) + b h ) \tilde{h}_t = \tanh(W_{xh}x_t + W_{hh}(r_t \odot h_{t-1}) + b_h) h~t=tanh(Wxhxt+Whh(rt⊙ht−1)+bh)
解读: h ~ t \tilde{h}_t h~t ∈ Rᵏ,通过tanh激活(输出范围[-1,1]);核心是 r t ⊙ h t − 1 r_t \odot h_{t-1} rt⊙ht−1
——先通过重置门rₜ筛选hₜ₋₁的信息,再与xₜ结合,得到包含当前新信息的候选隐藏状态。
- 隐藏状态更新:融合历史记忆和当前新信息,得到hₜ
h t = ( 1 − z t ) ⊙ h ~ t + z t ⊙ h t − 1 h_t = (1 - z_t) \odot \tilde{h}_t + z_t \odot h_{t-1} ht=(1−zt)⊙h~t+zt⊙ht−1
解读:这是GRU的核心公式, ( 1 − z t ) (1 - z_t) (1−zt) 和zₜ分别是 h ~ t \tilde{h}_t h~t 和hₜ₋₁的权重(两者之和为1);
-
第一项 ( 1 − z t ) ⊙ h ~ t (1 - z_t) \odot \tilde{h}_t (1−zt)⊙h~t :当前新信息的贡献比例;
-
第二项 z t ⊙ h t − 1 z_t \odot h_{t-1} zt⊙ht−1 :历史记忆的贡献比例;
-
两者相加,得到当前时刻的隐藏状态hₜ——既保留了历史记忆,又融入了当前新信息,同时实现了“遗忘”和“更新”的功能。
- 输出层计算:与传统RNN、LSTM一致
y t = σ ′ ( W h y h t + b y ) y_t = \sigma'(W_{hy}h_t + b_y) yt=σ′(Whyht+by)
3.2.3 GRU与LSTM的对比(如何选择?)
GRU和LSTM都是解决传统RNN梯度消失问题的核心变体,两者性能相近,但结构和计算效率不同,实际应用中如何选择?我们从多个维度对比:
| 对比维度 | LSTM | GRU |
|---|---|---|
| 门控单元数量 | 3个(遗忘门、输入门、输出门) | 2个(重置门、更新门) |
| 记忆单元 | 细胞状态cₜ + 隐藏状态hₜ(双记忆单元) | 仅隐藏状态hₜ(单记忆单元) |
| 计算复杂度 | 高(参数更多,计算步骤更繁琐) | 低(参数更少,计算效率高,训练速度快) |
| 长序列处理能力 | 强(细胞状态梯度传播更稳定,适合极长序列) | 较强(性能接近LSTM,适合一般长序列) |
| 适用场景 | 极长序列(比如长度>100)、对性能要求极高的场景(比如机器翻译、文本生成) | 一般长序列、对计算效率要求高的场景(比如文本分类、语音识别、实时预测) |
| 易用性 | 稍复杂(参数多,调参难度略高) | 更简单(参数少,调参难度低,易实现) |
总结:如果你的任务是极长序列(比如机器翻译、长文本生成),且计算资源充足,优先选择LSTM;如果是一般的序列任务(比如文本分类、语音识别),且希望提升计算效率、简化调参,优先选择GRU;实际应用中,也可以同时尝试两者,根据验证集性能选择更优的模型。
3.3 其他常见RNN变体(简要介绍)
除了LSTM和GRU,还有一些其他RNN变体,针对特定场景进行了优化,简要介绍如下,方便你全面了解:
-
Bi-RNN(双向RNN):核心是“同时利用过去和未来的序列信息”——传统RNN、LSTM、GRU都是“单向”的,只能利用当前时刻之前的历史信息;而Bi-RNN包含两个单向RNN(一个正向、一个反向),正向RNN处理序列从t=1到t=T,反向RNN处理序列从t=T到t=1,两者的输出拼接后作为最终输出,适合需要上下文双向信息的场景(比如文本翻译、情感分析);
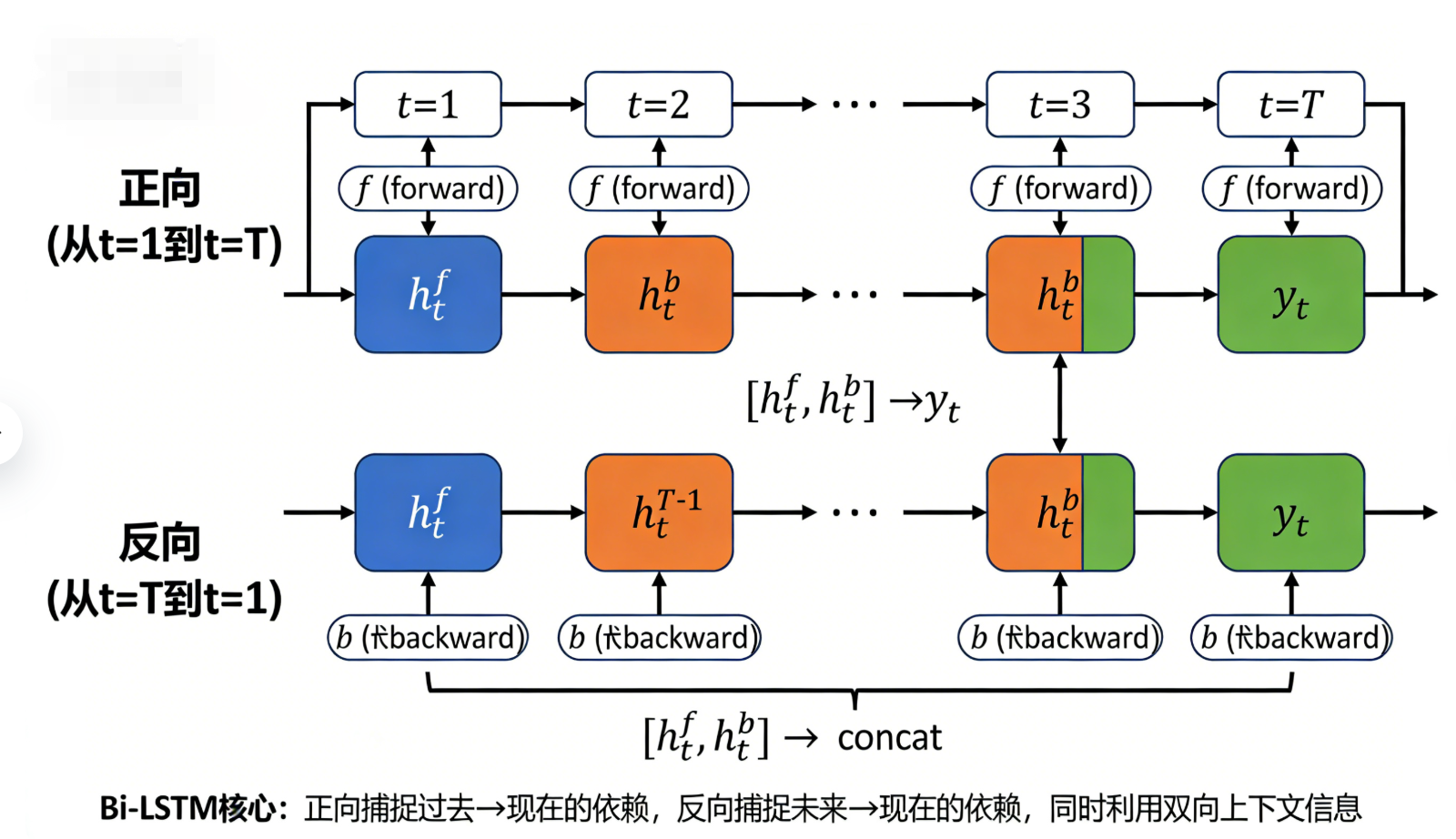
-
Bi-LSTM/Bi-GRU:双向RNN与LSTM、GRU的结合,是实际应用中最广泛的RNN结构——比如文本分类、命名实体识别、机器翻译,几乎都用Bi-LSTM或Bi-GRU,既能捕捉长短期依赖,又能利用双向上下文信息;
-
Stacked RNN(堆叠RNN):将多个RNN/LSTM/GRU层堆叠起来,上层RNN的输出作为下层RNN的输入,相当于“深层RNN”,能够提取更复杂的序列特征,适合复杂的序列任务(比如长文本生成、语音合成);但计算复杂度更高,容易过拟合,需要搭配Dropout等正则化方法。
四、RNN模型效果评估方法
RNN及其变体(LSTM、GRU、Bi-LSTM等)的核心应用场景是处理序列数据(文本、语音、时间序列等),其模型效果评估与CNN(图像任务)有共性,但更需适配“序列时序依赖”“输出与输入长度关联”的特性——评估的核心逻辑是:不仅要衡量模型预测结果的准确性,还要评估模型对序列上下文、时序关系的捕捉能力。
与传统机器学习或CNN评估不同,RNN评估需区分“任务类型”(分类、回归、序列生成),同时规避“只看单一指标、忽略时序特性”的误区。下面从“评估核心原则、分任务评估方法、序列专属评估指标、实战注意事项”四个维度,详细拆解RNN模型的评估逻辑和具体方法,结合前文RNN结构(LSTM、GRU)的应用场景,让评估方法更具实操性。
4.1 评估核心原则(适配RNN特性)
RNN的评估需围绕“序列特性”展开,核心遵循3个原则,避免评估偏差:
-
时序一致性优先:评估时需保留序列的原始顺序,不可打乱数据(如文本分类不可打乱句子中单词顺序、时间序列预测不可打乱时间先后),否则会丢失RNN核心捕捉的时序依赖信息;
-
区分输入输出长度:针对“输入输出长度不一致”的任务(如文本生成、机器翻译),需采用适配变长序列的评估指标,不可直接套用固定长度输出的评估方法;
-
兼顾拟合状态:RNN(尤其深层LSTM)易出现过拟合(训练集指标优异、测试集指标骤降),评估时需同时关注训练集、验证集、测试集的指标变化,结合泛化能力判断模型效果,而非仅看单一数据集。
4.2 分任务评估方法
RNN的应用任务可分为三大类:序列分类、序列回归、序列生成/标注,不同任务的评估方法差异较大,结合前文RNN应用场景(文本分类、语音识别、时间序列预测等),逐类拆解具体指标和用法。
4.2.1 序列分类任务(最常用,如文本分类、语音情感识别)
核心任务:将整个序列(如一句话、一段语音)分类到指定类别,输入是序列,输出是单一类别标签(如正面/负面、体育/娱乐),与CNN图像分类逻辑类似,但需保留序列时序性。
核心评估指标(与分类任务通用,但需适配序列):
- 准确率(Accuracy):最基础指标,计算测试集中“预测正确的序列数/总序列数”,适用于类别分布均衡的场景(如正负样本比例接近1:1);
公式: A c c u r a c y = T P + T N T P + T N + F P + F N Accuracy = \frac{TP + TN}{TP + TN + FP + FN} Accuracy=TP+TN+FP+FNTP+TN (TP:真阳性,TN:真阴性,FP:假阳性,FN:假阴性);
注意:RNN序列分类中,“预测正确”指整个序列的类别预测正确,而非单个序列元素,如文本分类中“句子整体情感预测正确”才算TP/TN。
- 精确率(Precision)、召回率(Recall)、F1分数(F1-Score):解决类别不均衡问题(如正面样本90%、负面样本10%),重点关注少数类的预测效果;
公式:
P r e c i s i o n = T P T P + F P Precision = \frac{TP}{TP + FP} Precision=TP+FPTP (预测为正的样本中,实际为正的比例,避免“假阳性”);
R e c a l l = T P T P + F N Recall = \frac{TP}{TP + FN} Recall=TP+FNTP (实际为正的样本中,预测为正的比例,避免“假阴性”);
F 1 = 2 × P r e c i s i o n × R e c a l l P r e c i s i o n + R e c a l l F1 = 2 \times \frac{Precision \times Recall}{Precision + Recall} F1=2×Precision+RecallPrecision×Recall (精确率和召回率的调和平均数,综合两者,取值0~1,越接近1效果越好);
适配场景:如垃圾邮件识别(垃圾邮件为少数类),需重点关注Recall(避免漏判垃圾邮件)和F1分数;文本情感识别(中性样本少数),需用F1分数综合评估。
-
混淆矩阵(Confusion Matrix):直观展示各类别的预测分布, rows为真实类别,columns为预测类别,可快速发现模型误判的类别(如将“中性”频繁误判为“正面”),为调参提供方向;
-
AUC-ROC曲线:适用于二分类任务,衡量模型的“区分能力”,AUC值越接近1,模型区分正负类的能力越强;尤其适用于序列分类中“类别不均衡+需量化区分能力”的场景(如疾病预测基于生理时序数据)。
实操注意:序列分类评估时,需将测试集按“完整序列”输入模型,不可拆分序列元素(如不可将一句话拆分为单个单词分别预测),否则会破坏时序依赖,导致评估结果失真。
4.2.2 序列回归任务(如时间序列预测、语音波形预测)
核心任务:输入是一段序列(如过去7天的气温),输出是连续的数值序列(如未来3天的气温),输出为连续值,核心评估模型对“时序趋势”的预测能力,适配前文LSTM/GRU处理长序列的场景。
核心评估指标(适配连续值序列,无类别概念):
- 均方误差(MSE):最常用指标,计算预测序列与真实序列对应位置数值的“平方差的平均值”,衡量预测值与真实值的整体偏差,值越小效果越好;
公式: M S E = 1 n ∑ i = 1 n ( y i − y ^ i ) 2 MSE = \frac{1}{n} \sum_{i=1}^{n} (y_i - \hat{y}_i)^2 MSE=n1∑i=1n(yi−y^i)2 ( y i y_i yi :真实值, y ^ i \hat{y}_i y^i :预测值,n:序列长度);
注意:对异常值敏感,若序列中存在极端值(如气温骤升骤降),MSE会被放大,需结合其他指标使用。
- 均方根误差(RMSE):MSE的平方根,解决MSE“量纲平方”的问题(如气温单位为℃,MSE单位为℃²,RMSE单位为℃),更直观反映预测偏差,值越小越好;
公式: R M S E = 1 n ∑ i = 1 n ( y i − y ^ i ) 2 RMSE = \sqrt{\frac{1}{n} \sum_{i=1}^{n} (y_i - \hat{y}_i)^2} RMSE=n1∑i=1n(yi−y^i)2 。
- 平均绝对误差(MAE):计算预测序列与真实序列对应位置数值的“绝对差的平均值”,对异常值不敏感,适合序列中存在极端值的场景(如电力负荷预测、股价预测);
公式: M A E = 1 n ∑ i = 1 n ∣ y i − y ^ i ∣ MAE = \frac{1}{n} \sum_{i=1}^{n} |y_i - \hat{y}_i| MAE=n1∑i=1n∣yi−y^i∣ 。
- 决定系数(R²):衡量模型对时序趋势的拟合程度,取值0~1,越接近1表示模型能越好地捕捉序列的变化趋势(如气温的升降趋势、负荷的峰谷变化);
公式: R 2 = 1 − ∑ i = 1 n ( y i − y ^ i ) 2 ∑ i = 1 n ( y i − y ˉ ) 2 R^2 = 1 - \frac{\sum_{i=1}^{n} (y_i - \hat{y}_i)^2}{\sum_{i=1}^{n} (y_i - \bar{y})^2} R2=1−∑i=1n(yi−yˉ)2∑i=1n(yi−y^i)2 ( y ˉ \bar{y} yˉ :真实序列的平均值)。
实操注意:时间序列预测评估时,需保留时间顺序,采用“滚动预测”(如用第1-7天预测第8天,再用第2-8天预测第9天),而非随机划分测试集,确保评估贴合实际应用场景。
4.2.3 序列生成/标注任务(最复杂,如文本生成、机器翻译、命名实体识别)
核心任务:输入是一段序列,输出是另一段序列(输入输出长度可一致或不一致),核心评估模型对“序列连贯性、语义准确性、时序逻辑性”的捕捉能力,适配Bi-LSTM、GRU的多场景应用。
核心评估指标(序列专属,无通用替代):
- 困惑度(Perplexity, PPL):序列生成任务的核心指标,衡量模型对“真实序列”的预测难度,困惑度越低,模型生成的序列越接近真实序列(越连贯、越符合逻辑);
核心逻辑:困惑度是“模型预测序列概率的倒数”,反映模型对每个序列元素的预测不确定性,如文本生成中,PPL越低,生成的句子越通顺;
公式: P P L = e − 1 n ∑ i = 1 n log p ( y i ∣ x 1 : i , θ ) PPL = e^{-\frac{1}{n} \sum_{i=1}^{n} \log p(y_i | x_{1:i}, \theta)} PPL=e−n1∑i=1nlogp(yi∣x1:i,θ) ( p ( y i ) p(y_i) p(yi) :模型预测第i个元素的概率,θ:模型参数,n:序列长度);
适配场景:文本生成、语音合成、机器翻译(评估翻译序列的流畅度),是LSTM/GRU生成类任务的必备评估指标。
- 编辑距离(Edit Distance):又称莱文斯坦距离,衡量“预测序列”与“真实序列”的相似度,计算将预测序列转换为真实序列所需的最少操作数(插入、删除、替换),操作数越少,序列相似度越高;
适配场景:命名实体识别(如将“北京”预测为“北景”,编辑距离为1,相似度高)、短文本生成,尤其适合输入输出长度不一致的场景。
- BLEU分数(Bilingual Evaluation Understudy):机器翻译、文本摘要任务的专属指标,衡量“预测序列与参考序列(真实序列)的n-gram重叠度”,n通常取1~4(1-gram衡量单个元素匹配,4-gram衡量长片段匹配);
取值范围0~1,越接近1表示预测序列与参考序列的重叠度越高,语义越一致,避免生成“通顺但语义偏离”的序列(如将“我爱吃苹果”翻译为“我爱吃香蕉”,通顺但语义错误,BLEU分数低)。
- ROUGE分数(Recall-Oriented Understudy for Gisting Evaluation):文本摘要、文本生成任务的补充指标,与BLEU互补,重点关注“参考序列中的元素是否被预测序列覆盖”(召回率角度),分为ROUGE-N(n-gram)、ROUGE-L(最长公共子序列);
适配场景:长文本生成、文本摘要(如将100字原文摘要为20字,ROUGE分数衡量摘要是否覆盖原文核心信息)。
4.3 序列专属辅助评估方法(提升评估全面性)
除上述核心指标外,结合RNN的时序特性,需补充2类辅助评估方法,避免单一指标的局限性,尤其适配深层LSTM/GRU模型:
-
时序注意力可视化:针对带注意力机制的RNN(如Attention-Bi-LSTM),通过可视化注意力权重,观察模型是否重点关注序列中的关键元素(如文本分类中关注“很棒”“很差”等情感词、时间序列预测中关注峰值/谷值时刻),若注意力权重集中在无关元素,说明模型未捕捉到核心时序信息,需优化结构;
-
梯度趋势评估:评估RNN训练过程中“梯度的变化趋势”,若梯度持续衰减至接近0(梯度消失),说明模型深层未有效学习(如LSTM门控单元未发挥作用);若梯度突然暴涨(梯度爆炸),说明模型不稳定,
五、RNN的实际应用场景(附案例说明)
RNN及其变体(LSTM、GRU、Bi-LSTM)的核心优势是处理序列数据,因此被广泛应用于自然语言处理(NLP)、语音处理、时间序列预测等多个领域,涵盖我们生活的方方面面。下面结合具体案例,详细介绍RNN的主要应用场景,感受RNN的实用价值。
4.1 自然语言处理(NLP):RNN最核心的应用领域
自然语言处理的核心是“理解文本的时序逻辑”(文本是典型的序列数据,字/词的顺序决定含义),RNN及其变体几乎主导了NLP的所有核心任务,常见应用如下:
1. 文本分类/情感分析
核心任务:将一段文本(序列)分类到指定类别,比如情感分析(正面/负面/中性)、新闻分类(体育/娱乐/财经)、垃圾邮件识别等。
应用案例:电商平台的商品评论情感分析——输入用户评论“这个手机续航很棒,拍照也清晰,非常推荐”,模型输出“正面情感”;输入“续航很差,经常卡顿,不建议购买”,模型输出“负面情感”。
常用模型:Bi-LSTM、Bi-GRU(利用双向上下文信息,提升分类准确率),搭配词向量(比如Word2Vec、BERT词向量)作为输入。
2. 命名实体识别(NER)
核心任务:从文本中识别出指定类型的实体(比如人名、地名、机构名、时间、金额),是信息抽取的基础任务。
应用案例:新闻文本中的实体识别——输入“张三于2023年访问了美国,在华盛顿会见了拜登总统”,模型识别出“张三(人名)

魔乐社区(Modelers.cn) 是一个中立、公益的人工智能社区,提供人工智能工具、模型、数据的托管、展示与应用协同服务,为人工智能开发及爱好者搭建开放的学习交流平台。社区通过理事会方式运作,由全产业链共同建设、共同运营、共同享有,推动国产AI生态繁荣发展。
更多推荐



 13
13 0
0- 0



 已为社区贡献10条内容
已为社区贡献10条内容

所有评论(0)