论文Review VLA OpenVLA | 开源具身智能端到端VLA机械臂方案 | 斯坦福、UC伯克利、谷歌、MIT出品!众星闪耀!
斯坦福大学、UC伯克利和丰田研究院联合发布了OpenVLA,这是一个开源的7B参数视觉-语言-动作模型。OpenVLA基于Llama2语言模型,融合DINOv2和SigLIP视觉特征,在97万真实机器人演示数据上训练。实验显示,OpenVLA在29个任务中比55B参数的RT-2-X模型性能高16.5%,且参数少7倍。该模型支持高效微调,在消费级GPU上通过LoRA和量化技术实现适配,性能优于扩散策
基本信息
题目:OpenVLA: An Open-Source Vision-Language-Action Model
来源:arXiv
学校:Stanford University, UC Berkeley, Toyota Research Institute
是否开源:https://github.com/openvla/openvla
摘要:开源机械臂VLA
在互联网规模的视觉语言数据和多样化的机器人演示相结合的基础上预训练的大型策略有可能改变我们教授机器人新技能的方式:而不是从零开始训练新的行为,我们可以微调这些视觉语言动作( VLA )模型,以获得鲁棒的、可泛化的视觉运动控制策略。然而,在机器人技术中广泛采用VLA一直是具有挑战性的,因为1 )现有的VLA基本上是闭源的,无法被公众使用,2 )先前的工作未能探索有效的方法来微调VLA以适应新任务,这是采用的关键部分。为了应对这些挑战,我们引入了OpenVLA,这是一个7B参数的开源VLA,它是在不同的970k真实机器人演示集合上训练的。OpenVLA建立在Llama 2语言模型的基础上,结合了一个融合DINOv2和SigLIP预训练特征的视觉编码器。作为增加的数据多样性和新的模型组件的产物,OpenVLA在通用操作中显示出强大的效果,在29个任务和多个机器人实施方案中的绝对任务成功率比RT-2-X ( 55B )等封闭模型高16.5%,参数少7倍。我们进一步表明,我们可以有效地对OpenVLA进行微调,特别是针对新的设置在涉及多个对象的多任务环境和语言基础能力强的情况下,泛化能力强,比扩散策略等表达性的从头模仿学习方法高出20.4%。我们还探讨了计算效率;作为单独的贡献,我们表明OpenVLA可以通过现代低秩自适应方法在消费级GPU上进行微调,并通过量化有效地服务,而不会影响下游的成功率。最后,我们在Open X-Embodiment数据集上发布了模型检查点、微调笔记本和内置VLA训练支持的PyTorch代码库。

Introduction
机器人学习操作策略的关键问题是它们泛化能力较弱:虽然现有的针对个人技能或语言指令训练的策略有能力将行为外推到新的初始条件,如物体位置或照明,但它们缺乏对场景干扰物或新物体的鲁棒性,并且难以执行不可见的任务指令。然而,除了机器人学之外,现有的视觉和语言基础模型,如CLIP、SigLIP 和Llama 2 等,都能够实现这些类型的泛化,更多的是来自其互联网规模的预训练数据集捕获的先验。虽然为机器人技术重现这种规模的预训练仍然是一个开放的挑战--即使是最大的机器人操作数据集也只有100K到1M的例子--这种不平衡表明了一个机会:使用现有的视觉和语言基础模型作为训练机器人策略的核心构建模块,可以泛化到其训练数据以外的对象、场景和任务中。
为了实现这一目标,现有工作探索了将预训练的VLM集成到robotic representation learning 中,并将其融入到任务规划planning和执行execution的模块化系统中。最近,它们已被用于直接学习视觉语言-动作模型[ VLAs]用于控制。VLAs提供了使用预训练的机器人视觉和语言基础模型的直接实例化,直接微调视觉条件语言模型( visual conditioned language models,VLMs ),如PaLI,以生成机器人控制动作。 通过建立在互联网规模数据上训练的强大基础模型,VLAs,如RT - 2显示出令人印象深刻的鲁棒性结果,以及泛化到新的对象和任务的能力,为通用机器人策略制定了新的标准。然而,有两个关键原因阻碍了现有VLA的广泛使用:1 )目前的模型是非开源的,对模型结构、训练过程和数据混合的可视性有限;2 )现有工作没有提供将VLA部署和适应新的机器人、环境和任务的最佳实践- -特别是在商品硬件(例如,消费级GPU)上。我们认为,为了为未来的研究和发展建立一个丰富的基础,机器人技术需要开源的、通用的VLA,支持有效的微调和适应。(伟大!无需多言!)
为此,我们引入了OpenVLA,这是一个7B参数的开源VLA,为通用型机器人操纵策略建立了新的SOTA。OpenVLA由一个预训练的visually-conditioned language model backbone组成,它以多种粒度捕获视觉特征,并在Open - X Embodiment数据集的970k个机器人操作轨迹的大型多样的数据集上进行微调。该数据集涵盖了广泛的机器人实施方案、任务和场景。作为数据多样性增加和新的模型组件的产物,OpenVLA比55B参数RT-2-X模型 (目前最先进的VLA )高出16.5%的绝对成功率,在WidowX和Google Robot的29个评估任务上都有体现。此外,我们还研究了VLA的有效微调策略,这是先前工作中没有探索到的一个新的贡献,它跨越了从物体拾取和放置到清理桌子的7种不同的操作任务。我们发现,微调后的OpenVLA策略明显优于微调后的Octo等预训练策略。相比于采用扩散策略的无痕模仿学习,微调后的OpenVLA在涉及语言到行为的任务上表现出了实质性的提升。根据这些结果,我们首先证明了利用低秩自适应[ LoRA ,26)和模型量化[ 27 ]的计算高效的微调方法的有效性,以便在不影响性能的情况下,在消费级GPU上而不是在大型服务器节点上适应Open VLA模型。作为最后的贡献,我们开源了所有模型,部署和微调的笔记本,以及用于大规模训练VLA的OpenVLA代码库,希望这些资源能够使未来的工作探索和适应用于机器人技术的VLA。
[26] E. J. Hu, Y. Shen, P. Wallis, Z. Allen-Zhu, Y. Li, S. Wang, L. Wang, and W. Chen. Lora: Low-rank adaptation of large language models. arXiv preprint arXiv:2106.09685, 2021.
[27] T. Dettmers, A. Pagnoni, A. Holtzman, and L. Zettlemoyer. Qlora: Efficient finetuning of quantized llms. Advances in Neural Information Processing Systems, 36, 2024.
Related Works
Visually-Conditioned Language Models
视觉条件语言模型( Visually-conditioned language models,VLMs )在互联网规模的数据上训练,用于从输入图像和语言提示生成自然语言,已被用于从视觉问答到物体定位的无数应用中。最近的VLMs的关键进展之一是模型架构,它将预训练的视觉编码器的特征与预训练的语言模型联系起来,直接利用计算机视觉和自然语言建模的进步来创建强大的多模态模型。虽然早期的工作探索了视觉和语言特征之间交叉连接的各种架构,但新的开源VLMs收敛于一种更简单的" patch-as-token "方法,其中来自预训练的视觉转换器的patch特征被视为token,然后被投影到语言模型的输入空间。这种简单性使得现有的语言模型训练工具可以很容易地在VLM训练规模上进行重新配置。我们在工作中使用这些工具来扩展VLA训练,并特别使用Karamcheti等人[ 44 ]的VLM作为我们的预训练骨干,因为它们是从多分辨率视觉特征中训练的,融合了来自DINOv2 [ 25 ]的低级空间信息和来自SigLIP [ 9 ]的高级语义,以帮助视觉泛化。
[44] S. Karamcheti, S. Nair, A. Balakrishna, P. Liang, T. Kollar, and D. Sadigh. Prismatic vlms: Investigating the design space of visually-conditioned language models. arXiv preprint arXiv:2402.07865, 2024.
[25] M. Oquab, T. Darcet, T. Moutakanni, H. Vo, M. Szafraniec, V. Khalidov, P. Fernandez, D. Haziza, F. Massa, A. El-Nouby, et al. Dinov2: Learning robust visual features without supervision. arXiv preprint arXiv:2304.07193, 2023.
[9] X. Zhai, B. Mustafa, A. Kolesnikov, and L. Beyer. Sigmoid loss for language image pretraining. In International Conference on Computer Vision (ICCV), 2023.
Generalist Robot Policies
最近,机器人学的一个趋势是在大量不同的机器人数据集上训练多任务"通才"机器人策略,涵盖了许多不同的机器人实施方案。值得注意的是,Octo [ 5 ]训练了一个通用的策略,可以控制多个机器人out-of-the-box(开箱即用),并允许对新的机器人设置进行灵活的微调。这些方法与OpenVLA的一个关键区别是模型架构。Octo等先前的工作通常由预训练的组件组成,如语言嵌入或视觉编码器,以及初始化的额外模型组件,在策略训练过程中学习将它们"缝合"在一起。与这些工作不同的是,OpenVLA采用了一种更加端到端的方法,直接微调VLM,将其作为语言模型词汇表中的token来生成机器人动作。我们的实验评估表明,这种简单但可扩展的流水线比以前的泛型策略显著地提高了性能和泛化能力。
[5] Octo Model Team, D. Ghosh, H. Walke, K. Pertsch, K. Black, O. Mees, S. Dasari, J. Hejna, C. Xu, J. Luo, T. Kreiman, Y. Tan, D. Sadigh, C. Finn, and S. Levine. Octo: An open-source generalist robot policy. https://octo-models.github.io, 2023.
Vision-Language-Action Models
许多工作探索了VLMs在机器人中的应用,例如,用于视觉状态表示,物体检测,高层规划,以及提供反馈信号。另一些研究者将VLM直接集成到端到端的视觉运动控制策略中,但将显著结构集成到策略架构中或需要标定相机,限制了其适用性。最近的一些工作探索了与我们相似的方案,并直接微调了用于预测机器人动作的大型预训练VLM。这类模型通常被称为视觉-语言-动作模型( VLAs ),因为它们直接将机器人控制动作融合到VLM主干中。这有三个关键的好处:
- 它在一个大型的互联网规模的视觉语言数据集上执行预训练的视觉和语言组件的对齐;
- 使用一个通用的架构,而不是为机器人控制定制的,允许我们利用现代VLM训练的可扩展基础设施和规模,以最小的代码修改来训练十亿参数的策略;
- 它为机器人技术提供了直接的途径,以从VLM的快速改进中受益。
现有的关于VLA的工作要么集中在单个机器人或模拟设置中进行训练和评估,缺乏通用性;要么是封闭的,不支持对新的机器人设置的有效微调。最相关的是,RT-2-X [ 1 ]在Open X-Embodiment数据集上训练了一个55B参数的VLA策略,并展示了最先进的泛型操纵策略的性能。然而,我们的工作与RT-2-X有许多重要的不同之处:
- 结合了一个强开放的VLM。在我们的实验中,OpenVLA比RT-2-X拥有更丰富的机器人预训练数据集,而比RT-2-X小一个数量级;
- 全面考察了OpenVLA模型对新目标设置的微调,而RT-2-X没有考察微调设置;
- 我们首次证明了现代参数有效的VLA微调和量化方法的有效性;
- OpenVLA是第一个开源的通用VLA,因此支持未来关于VLA训练、数据混合、目标和推理的研究。
3 The OpenVLA Model
3.1 Preliminaries: Vision-Language Models
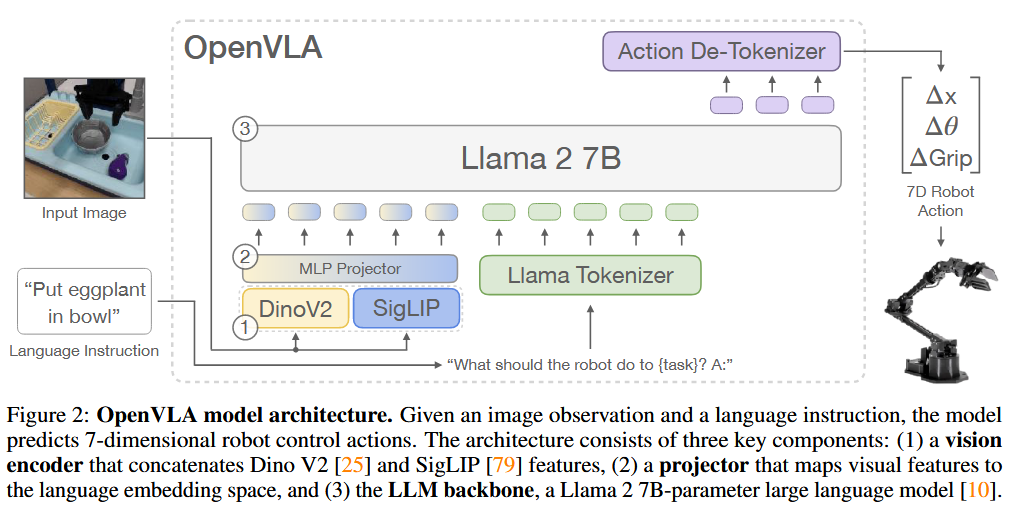
视觉-语言模型(VLM)是OpenVLA的基础,其架构通常包括三个主要部分(见论文中的图2):
- 视觉编码器(Visual Encoder):将图像输入转化为“图像块嵌入”(image patch embeddings)。OpenVLA使用Prismatic-7B VLM作为骨干,其视觉编码器结合了预训练的 SigLIP 和 DinoV2 模型。这两个模型分别处理图像,生成的特征向量在通道维度上进行拼接。相比常用的CLIP或SigLIP编码器,DinoV2的加入显著提升了模型的空间推理能力,这对机器人控制任务尤其重要。
- 投影器(Projector):将视觉编码器的输出嵌入映射到语言模型的输入空间。Prismatic使用一个小型的2层MLP(多层感知器)作为投影器。
- 大型语言模型(LLM)backbone:OpenVLA采用7亿参数的 Llama 2 语言模型作为语言处理核心。
Prismatic VLM 的训练数据基于 LLaVA 1.5 数据混合,包含约100万张图像-文本和纯文本数据,来自多个开源数据集(如LLaVA、CLIP等)。这些数据的来源通常是互联网上收集的大规模图像-文本对,具体细节未公开。
3.2 OpenVLA Training Procedure
OpenVLA通过在预训练的Prismatic-7B VLM基础上进行微调,适配机器人动作预测任务。具体流程如下:
- 动作预测任务:将机器人动作预测定义为一个视觉-语言任务,输入为观察图像和自然语言任务指令,输出为机器人动作序列。
- 动作离散化:为了让语言模型能够预测连续的机器人动作,论文采用了 Brohan et al. [7] 的方法,将每个动作维度离散化为256个区间(bins)。区间范围基于训练数据动作的1%和99%分位数(quantiles),以避免异常值影响离散化精度。
- 词汇表调整:由于Llama 2的标记器(tokenizer)只有100个“特殊标记”可用,远少于256个动作标记,论文选择覆盖Llama标记器词汇表中最后256个最不常用的标记,用以表示动作标记。
- 训练目标:使用标准的下一标记预测目标(next-token prediction objective),通过交叉熵损失(cross-entropy loss)优化动作标记的预测。
3.3 Training Data
OpenVLA的训练数据集基于 Open X-Embodiment(OpenX)数据集,这是一个包含70多个机器人数据集、超过200万个机器人轨迹的大型社区数据集。为了确保训练效率和一致性,论文对数据集进行了以下筛选和处理:
- 统一输入输出空间:仅选择包含至少一个第三人称摄像头视角的操纵任务数据集,并使用单臂末端执行器控制。
- 数据混合平衡:参考 Octo [5] 的数据混合权重,优先选择任务和场景多样性较高的数据集,降低或移除多样性较低的数据集。新加入的数据集(如 DROID [11])以较低权重(10%)加入,但由于其动作标记预测准确率较低,最终在训练后三分之一阶段被移除。
最终数据集旨在覆盖多种机器人形态、场景和任务,以实现模型的通用性和对新机器人设置的快速适应能力。
3.4 OpenVLA Design Decisions
论文在开发OpenVLA时进行了多项小规模实验(基于 BridgeData V2 数据集),总结了以下关键设计决策:
- VLM骨干选择:
- 测试了多种VLM骨干,包括 IDEFICS-1、LLaVA 和 Prismatic。
- LLaVA 在多物体场景的语言理解任务中表现优于IDEFICS-1,成功率高出35%。
- Prismatic 进一步提升了约10%的成功率,归因于其SigLIP-DinoV2融合编码器的空间推理能力。
- Prismatic的代码库模块化且易用,因此被选为最终骨干。
- 图像分辨率:
- 比较了224×224像素和384×384像素的输入图像,发现性能差异不大,但后者训练时间增加3倍。因此选择224×224像素以降低计算成本。
- 视觉编码器微调:
- 与传统VLM训练中冻结视觉编码器的做法不同,OpenVLA需要微调视觉编码器以捕捉更精细的空间细节,这对精确的机器人控制至关重要。
- 训练轮数(Epochs):
- 通常VLM训练只进行1-2个轮次,但OpenVLA需要更多的轮次(最终为27轮),以确保动作标记预测准确率超过95%。
- 学习率:
- 通过多次实验确定固定学习率2e-5(与VLM预训练一致)效果最佳,未发现学习率预热(warmup)的明显优势。
3.5 Infrastructure for Training and Inference
- 训练:
- OpenVLA在64个A100 GPU集群上训练14天,总计21,500 A100小时,批大小为2048。
- 推理:
- 使用bfloat16精度时,模型需要15GB GPU内存。
- 在NVIDIA RTX 4090 GPU上,推理速度约为6Hz(未使用编译、推测解码等加速技术)。
- 通过量化和远程推理服务器,可进一步降低内存需求并实现实时动作预测流式传输,适用于无需强大本地计算设备的机器人控制场景。
- 远程推理解决方案已作为开源代码发布。
实验
实验的目标是测试OpenVLA作为一个强大的多机器人控制策略的“开箱即用”能力(即无需额外训练直接部署),以及其作为微调初始化的有效性。具体而言,论文旨在回答以下三个问题:
- 与先前通用机器人策略的比较:在多个机器人平台和各种泛化类型(如视觉、运动、物理和语义泛化)上的表现如何?
- 在新机器人设置和任务上的微调效果:OpenVLA能否有效微调,并与最先进的数据高效模仿学习方法(如Diffusion Policy)比较?
- 参数高效微调和量化的计算优化:是否能通过这些技术降低训练和推理的计算需求?性能与计算的权衡如何?
这些问题反映了VLA模型在机器人领域的实际应用挑战:泛化能力、适应性和计算效率。实验使用真实机器人平台(如WidowX、Google机器人和Franka臂),并通过数百次 rollout( rollout 指一次完整的任务执行尝试)量化性能,成功率基于任务完成度计算。
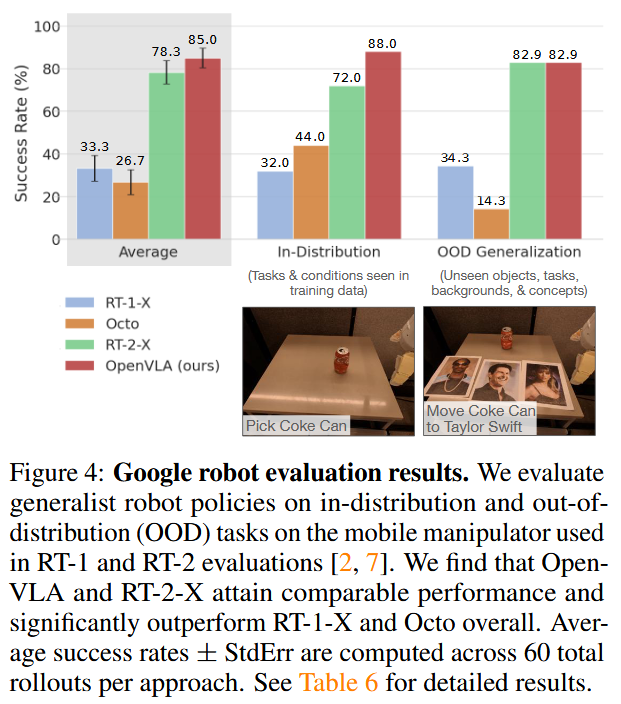
5.1 Direct Evaluations on Multiple Robot Platforms
评估OpenVLA的“开箱即用”性能,即使用预训练模型直接在未见过的机器人和任务上部署,而不进行额外微调。
机器人设置与任务设计:
- 机器人平台:
- WidowX机器人:来自BridgeData V2评估[6],固定臂机器人(见论文图1左侧)。
- Google机器人:移动操纵机器人,来自RT-1和RT-2评估[2,7](见图1中间)。
- 这些平台在先前工作中广泛用于测试通用机器人策略,确保结果的可比性。
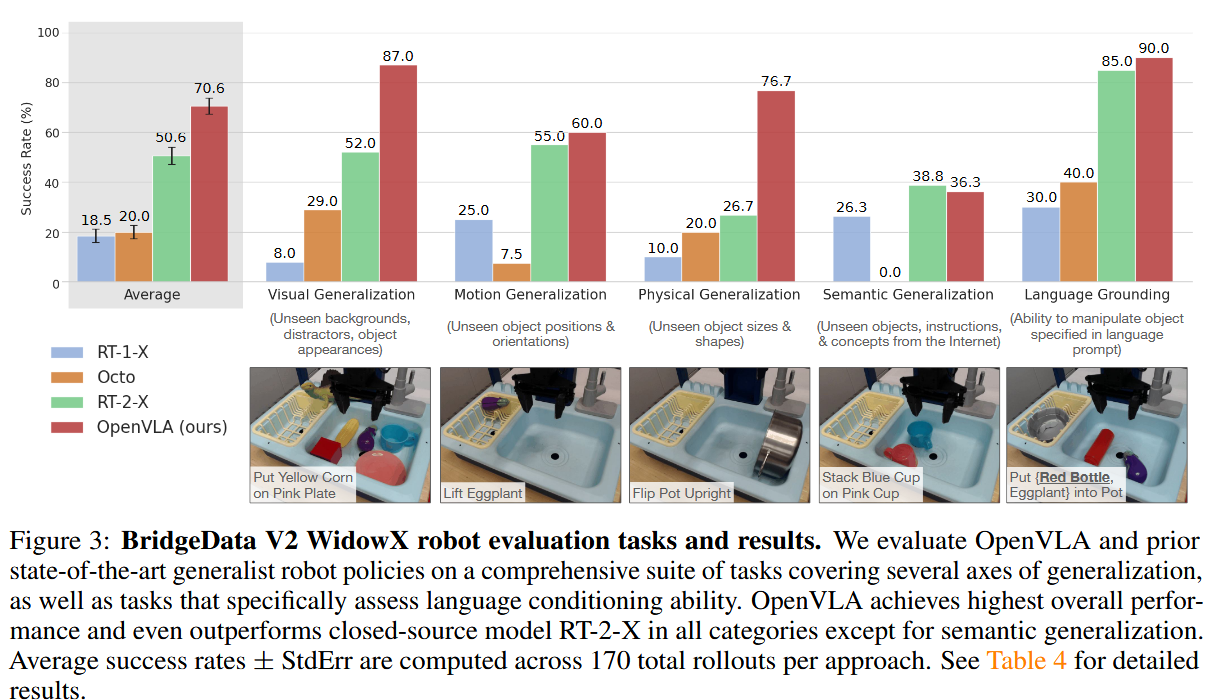
- 任务设计:
- 覆盖多种泛化轴线:
- 视觉泛化:未见过的背景、干扰物体、物体颜色/外观。
- 运动泛化:未见过的物体位置/方向。
- 物理泛化:未见过的物体大小/形状。
- 语义泛化:未见过的目标物体、指令,以及从互联网概念(如特定物体名称)。
- 评估语言条件能力:在多物体场景中,测试模型是否能根据用户提示操纵正确的目标物体。
- 示例任务见论文图3和图4底部:如拾取物体、放置到指定位置等。
- 覆盖多种泛化轴线:
- 评估规模:
- BridgeData V2:170次 rollout(17个任务,每任务10次尝试)。
- Google机器人:60次 rollout(12个任务,每任务5次尝试)。
- 所有任务与训练数据有差异,详细 breakdown 在附录中。
关键含义:
[2] A. Brohan, N. Brown, J. Carbajal, Y. Chebotar, J. Dabis, C. Finn, K. Gopalakrishnan, K. Hausman, A. Herzog, J. Hsu, J. Ibarz, B. Ichter, A. Irpan, T. Jackson, S. Jesmonth, N. Joshi, R. Julian, D. Kalashnikov, Y. Kuang, I. Leal, K.-H. Lee, S. Levine, Y. Lu, U. Malla, D. Manjunath, I. Mordatch, O. Nachum, C. Parada, J. Peralta, E. Perez, K. Pertsch, J. Quiambao, K. Rao, M. Ryoo, G. Salazar, P. Sanketi, K. Sayed, J. Singh, S. Sontakke, A. Stone, C. Tan, H. Tran, V. Vanhoucke, S. Vega, Q. Vuong, F. Xia, T. Xiao, P. Xu, S. Xu, T. Yu, and B. Zitkovich. Rt-1: Robotics transformer for real-world control at scale. In arXiv preprint arXiv:2212.06817, 2022.
[6] H. Walke, K. Black, A. Lee, M. J. Kim, M. Du, C. Zheng, T. Zhao, P. Hansen-Estruch, Q. Vuong, A. He, V. Myers, K. Fang, C. Finn, and S. Levine. Bridgedata v2: A dataset for robot learning at scale, 2023.
[7] A. Brohan, N. Brown, J. Carbajal, Y. Chebotar, X. Chen, K. Choromanski, T. Ding, D. Driess, A. Dubey, C. Finn, P. Florence, C. Fu, M. G. Arenas, K. Gopalakrishnan, K. Han, K. Hausman, A. Herzog, J. Hsu, B. Ichter, A. Irpan, N. Joshi, R. Julian, D. Kalashnikov, Y. Kuang, I. Leal, L. Lee, T.-W. E. Lee, S. Levine, Y. Lu, H. Michalewski, I. Mordatch, K. Pertsch, K. Rao, K. Reymann, M. Ryoo, G. Salazar, P. Sanketi, P. Sermanet, J. Singh, A. Singh, R. Soricut, H. Tran, V. Vanhoucke, Q. Vuong, A. Wahid, S. Welker, P. Wohlhart, J. Wu, F. Xia, T. Xiao, P. Xu, S. Xu, T. Yu, and B. Zitkovich. Rt-2: Vision-language-action models transfer web knowledge to robotic control. In arXiv preprint arXiv:2307.15818, 2023.
5.2 Data-Efficient Adaptation to New Robot Setups
评估OpenVLA在新机器人设置和任务上的微调效果,比较其与从零训练或其它通用策略的性能。
机器人设置:
- 目标平台:Franka机器人臂,广泛用于机器人学习社区。
- 两种变体:安装在固定桌子上(5Hz非阻塞控制器)和安装在可移动站立桌子上(15Hz控制器)。
- 选择Franka是因为其流行性,便于OpenVLA作为微调目标。
比较方法:
- Diffusion Policy:最先进的数据高效模仿学习方法,从零训练。使用两步观察历史(图像+本体感知状态),预测未来动作块(action chunking),并执行receding horizon控制(预测T个未来动作,执行前X个)。
- Diffusion Policy (matched):匹配OpenVLA的输入输出规格:单图像输入、无本体信息、无历史,预测单个相对位置动作,无动作块。
- Octo :当前最佳支持微调的通用策略,在目标数据集上微调(RT-2-X不支持微调)。
- OpenVLA:在目标数据集上微调预训练模型。
- OpenVLA (scratch):消融实验,直接微调基础Prismatic VLM,而非OpenX预训练的OpenVLA,评估大规模机器人预训练的益处。
结果分析(见论文图5,详细任务 breakdown 在附录表7):
- 性能比较:
- Diffusion Policy在狭窄单指令任务(如“Put Carrot in Bowl”或“Pour Corn into Pot”)中表现优异或相当,动作更平滑精确(得益于动作块和时序平滑)。
- 但在涉及多物体的多样化任务中,预训练通用策略(Octo和OpenVLA)表现更好,因为它们更好地适应语言 grounding(语言理解)。
- OpenVLA (scratch)性能较低,证明OpenX预训练的重要性。
- OpenVLA平均性能最高,且是唯一在所有任务中成功率至少50%的方法,表明其在多样语言指令任务中的鲁棒性。
- 局限与未来方向:Diffusion Policy在高灵巧任务中更精确;OpenVLA可通过集成动作块和时序平滑提升灵巧度(见第6节讨论)。
关键含义:
- OpenVLA作为预训练初始化,能高效适应新设置,尤其在需要语言理解的任务中优于从零训练方法。微调使用8个A100 GPU,5-15小时/任务,计算量远低于预训练。
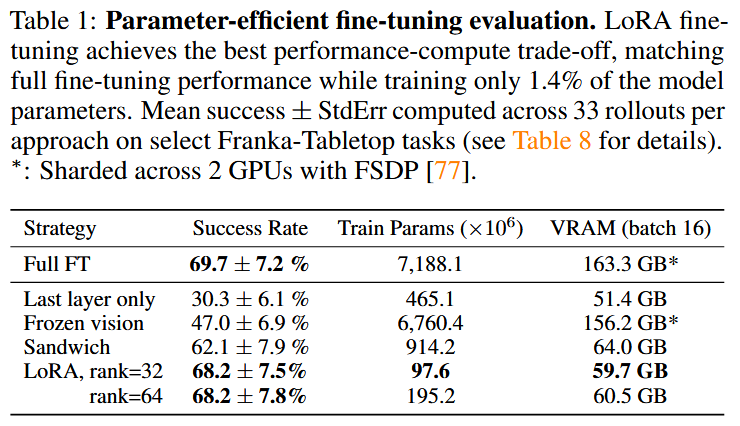
5.3 Parameter-Efficient Fine-Tuning
探索更高效的微调方法,以降低计算需求,同时保持性能。
方法比较:
- Full FT:全微调所有权重(如5.2节所述)。
- Last layer only:仅微调transformer最后层和标记嵌入矩阵。
- Frozen vision:冻结视觉编码器,微调其它权重。
- Sandwich:微调视觉编码器、标记嵌入矩阵和最后层。
- LoRA [26]:低秩适应技术,应用于所有线性层,测试不同秩r(32和64)。
评估指标(见表1:在选定Franka-Tabletop任务上,33次 rollout/方法):
- 成功率、训练参数数、GPU内存(批大小16)。
- 结果:
- Last layer only:30.3% ± 6.1%,参数465.1M,内存51.4GB——性能差,表明仅调整输出层不足。
- Frozen vision:47.0% ± 6.9%,参数6760.4M,内存156.2GB——性能一般,证明视觉特征适应至关重要。
- Sandwich:62.1% ± 7.9%,参数914.2M,内存64.0GB——性能更好,内存更低。
- LoRA (r=32):68.2% ± 7.5%,参数97.6M,内存59.7GB——最佳权衡,匹配Full FT (69.7%),仅微调1.4%参数。
- LoRA (r=64):类似性能,参数稍多。
- 推荐:默认r=32,使用LoRA可在单A100 GPU上10-15小时完成微调,计算减少8倍。
关键含义:
- LoRA提供最佳性能-计算权衡,证明参数高效方法能使OpenVLA更易访问,尤其在资源有限的环境中。
- 注:这里使用简化版OpenVLA(SigLIP视觉骨干,非融合DinoSigLIP),但性能仍强劲。
5.4 Memory-Efficient Inference via Quantization
优化推理阶段,减少内存需求,提高部署可及性。
方法:
- 默认:bfloat16精度加载,内存减半(16GB GPU即可运行)。
- 测试量化:8-bit和4-bit精度,使用LLM服务技术[27,88]。
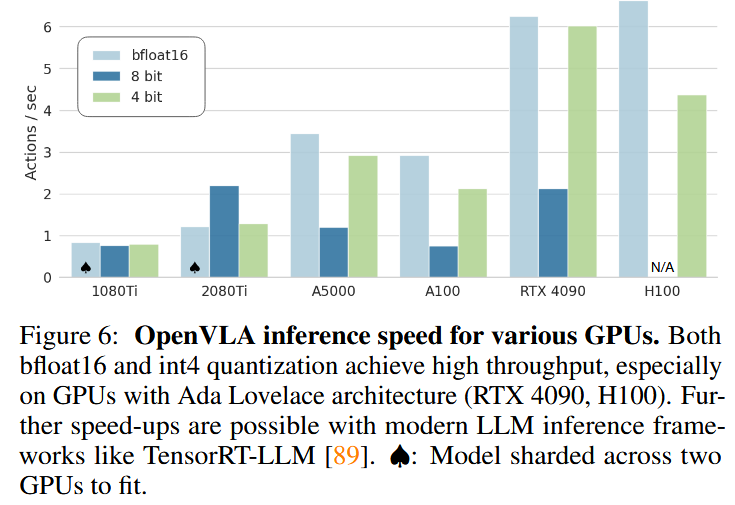
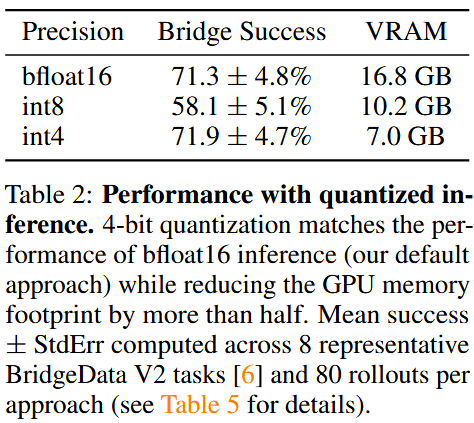
评估(见表2:在8个BridgeData V2任务上,80次 rollout/方法;见图6:不同GPU推理速度):
- 性能与内存:
- bfloat16:71.3% ± 4.8%,内存16.8GB。
- int8:58.1% ± 5.1%,内存10.2GB——性能下降,因为推理变慢(A5000 GPU上仅1.2Hz),改变系统动态。
- int4:71.9% ± 4.7%,内存7.0GB——匹配bfloat16性能,内存减半;速度更高(A5000上3Hz),接近训练动态。
- 速度:4-bit在Ada Lovelace架构GPU(如RTX 4090、H100)上吞吐高;可进一步用TensorRT-LLM[89]加速。
关键含义:
- 这一设计强调OpenVLA的通用性:模型训练于OpenX数据集,能直接适应不同机器人形态,而无需特定平台数据。这突出了VLA模型的优势——通过大规模预训练实现跨平台泛化。
- 4-bit量化是最佳选择:显著降低内存(<7GB),不牺牲性能,使OpenVLA可在消费级GPU上运行,拓宽应用范围。
- 注:量化可能引入速度开销,但4-bit平衡良好。
初体验
TODO
参考文献

魔乐社区(Modelers.cn) 是一个中立、公益的人工智能社区,提供人工智能工具、模型、数据的托管、展示与应用协同服务,为人工智能开发及爱好者搭建开放的学习交流平台。社区通过理事会方式运作,由全产业链共同建设、共同运营、共同享有,推动国产AI生态繁荣发展。
更多推荐



 14
14 1
1- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)