深度学习基础知识总结(三):池化层(Pooling)与特征下采样全解析
操作作用常用位置最大池化(Max Pooling)强特征提取、增强鲁棒性CNN 中间层平均池化(Avg Pooling)平滑特征旧架构或辅助层全局平均池化(GAP)替代全连接、减少参数模型末端步长卷积(Stride Conv)池化的可学习替代现代 ResNet/ConvNeXt卷积让网络看得更多,池化让网络看得更远。下期预告:全连接层(Fully Connected Layer)关注我一起学习深度
在前两篇文章中,我们已经依次介绍了:
-
卷积(Convolution):负责从图像中提取局部特征
-
激活函数(Activation Function):赋予模型“非线性思考能力”
当卷积层不断堆叠时,特征图的大小会非常大。如果不加控制,网络的参数量会爆炸,计算量也会以几何级增长。
为了让网络:
-
更快
-
更稳定
-
更不容易过拟合
-
对输入更有鲁棒性
我们需要用到深度学习中的另一块基础积木:
池化层(Pooling)。
它是 CNN 中最简洁、却又最具代表性的操作之一。
一、池化层是什么?
池化(Pooling)是 CNN 中用来 降低特征图空间大小(宽、高) 的操作,同时保留最重要的信息。
从直觉上看:
池化 = 信息压缩器
它把一个小区域(例如 2×2、3×3)压缩成一个单值,用来代表该区域的主要特征。
它不会引入新的参数,也不会改变通道数(channels),因此计算成本极低。
常见用途包括:
-
下采样(Downsampling)
-
降低模型计算量
-
提高特征对平移/微小变形的鲁棒性
-
减少过拟合
可以理解为:
池化让网络关注更“粗”的信息,而不是一砖一瓦的具体像素点。
二、池化为什么重要?(直观理解)
假设你有一张 1000 × 1000 的大图,如果每一层卷积都保持同样分辨率,那么网络的计算量会非常高。
例如:
输入:1000 × 1000 × 3 卷积 20 层 中间特征图依旧 1000 × 1000 × 64显然 内存爆炸 + 计算爆炸。
池化的主要目标之一就是:
每经过几层卷积,就把特征图缩小一次,让网络只关注更“抽象”的特征。
比如把 1000×1000 → 500×500 → 250×250 → ...
这也是为什么经典的 CNN(VGG、ResNet)里,池化层是必不可少的一环。
三、常见的池化方式
池化的方式非常多,但有两个最常见的版本:
1️⃣ 最大池化(Max Pooling)
定义:
取区域中的最大值。
例如一个 2×2 窗口:
[1, 5
3, 2] → 最大值 = 5
特点:
-
保留最强特征
-
对噪声敏感度低
-
更能突出关键信息(如边缘、纹理)
-
图像任务中使用最广泛
在 CNN 里,Max Pooling 基本是“标配”。
2️⃣ 平均池化(Average Pooling)
定义:
对窗口内所有值求平均。
例如:
[1, 5
3, 2] → 平均值 = 2.75
特点:
-
更平滑
-
不会偏向极值
-
在旧 CNN 架构中常用(LeNet 等)
但在现代深度学习中,Avg Pooling 已不再常用于中间层,
更多出现在网络末端作为“全局平均池化”。
3️⃣ 全局平均池化(Global Average Pooling, GAP)
这是现代 CNN 最重要的池化方式之一。
定义:
对每个通道,求整个特征图的平均值。
例如输入为 7×7×512,则输出为 1×1×512。
最大优势:
-
大幅减少参数
-
避免使用全连接层导致的过拟合
-
是 ResNet、MobileNet、Inception 等模型的标准组件
它几乎成为“替代全连接层”的主流方案。
四、池化层的三个关键参数
和卷积类似,池化也有以下参数:
1. Kernel(窗口大小)
例如常用的:
-
2×2
-
3×3
窗口越大,下采样越强烈。
2. Stride(步长)
表示窗口每次移动的距离。
常见:
-
stride = 2(最常用)
-
stride = 1(很少用,因为不降采样)
举例:
如果池化窗口为 2×2、stride=2,则输入大小将缩小一半:
输入: 32×32
输出: 16×16
3. 填充(Padding)
池化层的 padding 通常比卷积少见,一般用 valid(无填充)。
五、池化和卷积的区别是什么?
| 操作 | 是否有参数 | 目的 | 常见使用位置 |
|---|---|---|---|
| 卷积(Conv) | 有参数 | 提取特征 | 各层 |
| 池化(Pooling) | 无参数 | 降维、增强鲁棒性 | 每几层一次 |
| 全局平均池化(GAP) | 无参数 | 替代全连接层 | 网络末端 |
一句话总结:
卷积负责“提取”,池化负责“压缩”。
两者相辅相成。
六、为什么最大池化 > 平均池化?
最大池化选“最强响应”,更能反映:
-
边缘
-
角点
-
纹理
-
模式出现的强度
平均池化会把信息“平滑化”,弱化特征,导致:
-
边缘变弱
-
特征不明显
-
模型不够敏感
因此在视觉任务中:
Max Pooling 比 Avg Pooling 更符合人类视觉特征提取机制。
这也是现代 CNN 选择 Max Pooling 的原因。
七、池化的三个核心作用(面试必问)
1. 降低计算量
减少宽 × 高,降低 FLOPs。
2. 增强模型鲁棒性
如:
-
输入图像稍微移动
-
亮度略微变化
-
噪声干扰
池化都能帮助模型“忽略细枝末节”。
3. 减少过拟合
通过压缩特征图,迫使网络关注更高层次的模式。
因此即使在 Transformer 接管视觉任务之前,池化层一直是 CNN 的“黄金组件”。
八、池化后的维度变化公式
设输入大小为 H×W,池化参数为:
-
kernel = k
-
stride = s
-
padding = p
输出大小为:
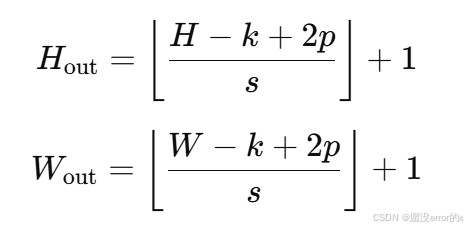
这是 CNN 网络结构设计中必须掌握的公式。
九、PyTorch 中的 Pooling 代码示例
最大池化
import torch.nn as nn
max_pool = nn.MaxPool2d(kernel_size=2, stride=2)
平均池化
avg_pool = nn.AvgPool2d(kernel_size=2, stride=2)
全局平均池化
gap = nn.AdaptiveAvgPool2d((1, 1))
十、现代趋势:不要池化?
自从 ResNet 之后,一些网络开始采用:
步长卷积(stride conv)替代池化下采样
原因如下:
-
可学习参数更多,表达能力更强
-
不依赖硬编码的窗口操作
-
和卷积结构更加统一
比如:
nn.Conv2d(in_channels, out_channels, kernel_size=3, stride=2, padding=1)
这种卷积也可以把特征图缩小一半,但有可学习参数,因此更灵活、效果更好。
但在轻量化网络(MobileNet)或大模型里,GAP 依旧是不可替代的核心操作。
十一、总结
| 操作 | 作用 | 常用位置 |
|---|---|---|
| 最大池化(Max Pooling) | 强特征提取、增强鲁棒性 | CNN 中间层 |
| 平均池化(Avg Pooling) | 平滑特征 | 旧架构或辅助层 |
| 全局平均池化(GAP) | 替代全连接、减少参数 | 模型末端 |
| 步长卷积(Stride Conv) | 池化的可学习替代 | 现代 ResNet/ConvNeXt |
一句话总结:
卷积让网络看得更多,池化让网络看得更远。
下期预告:全连接层(Fully Connected Layer)
关注我一起学习深度学习,我们一起进步~~~

魔乐社区(Modelers.cn) 是一个中立、公益的人工智能社区,提供人工智能工具、模型、数据的托管、展示与应用协同服务,为人工智能开发及爱好者搭建开放的学习交流平台。社区通过理事会方式运作,由全产业链共同建设、共同运营、共同享有,推动国产AI生态繁荣发展。
更多推荐



 25
25 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)