大模型的新数据飞轮:大模型半监督学习 SemiEvol
🔥北大&UCLA团队提出大模型半监督进化!一张显卡也能做的大模型科研!🥳SemiEvol可以让大模型也能进行半监督学习,高效利用少量标注数据和大量未标注数据,形成数据飞轮,真正实现大模型的自我进化!
🔥🔥 北大&UCLA团队提出大模型半监督进化!
🥳🥳 一张显卡也能做的大模型科研!
传统思路:SFT进行大模型域适配
SFT(Supervised Fine-Tuning)作为大模型适配领域的标配方法,其优势与局限性早已为业内熟知。在传统 SFT 的框架下,模型通过少量标注数据进行领域适配,强化对任务的指令理解能力。然而,SFT 的核心痛点——标注数据昂贵、未标注数据难以高效利用,使得这种方法在数据有限的场景下显得捉襟见肘。
最近,一种名为 SemiEvol 的半监督微调框架为 SFT 提供了全新的可能。通过对 SFT 的痛点精准切入,SemiEvol 引入了“知识传播与自适应选择”的双层策略,为大模型微调带来了显著的效率与效果提升。以下将结合 SFT 的工作流程与 SemiEvol 的技术创新,为你逐步解读这一突破。
SemiEvol:混合数据场景的持续进化
SemiEvol 的核心设计
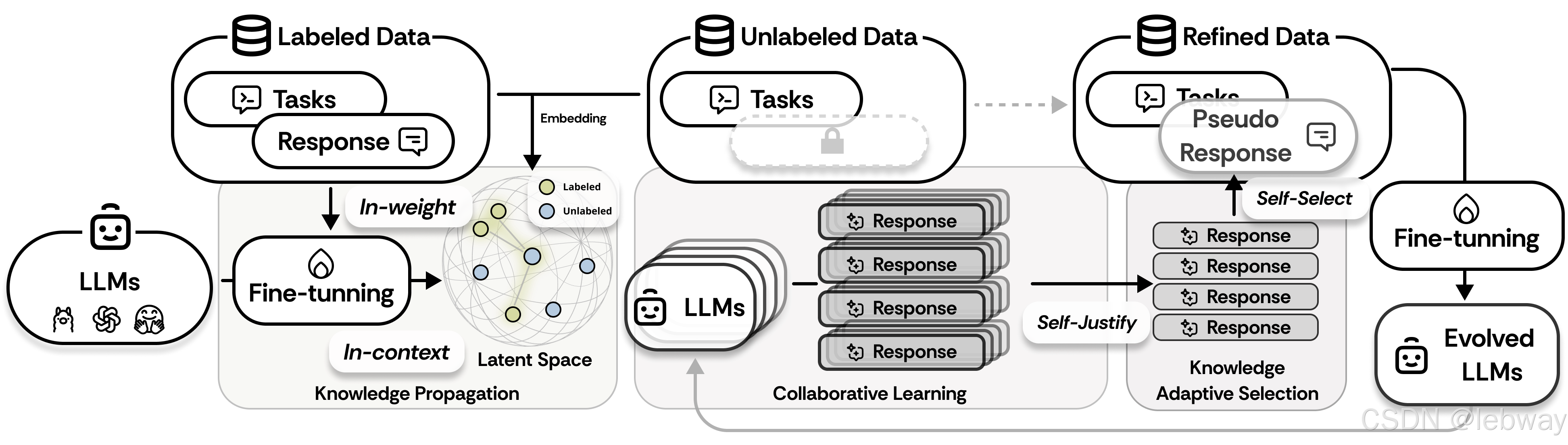
SemiEvol 在传统 SFT 框架的基础上,针对数据利用率的问题,引入了以下核心技术:
-
知识传播:标注数据的价值最大化
- 权重传播(In-weight Propagation):通过对标注数据的微调,调整模型权重,使其对目标任务具有更高的适应性。
- 上下文传播(In-context Propagation):利用标注数据的嵌入空间,通过 k 近邻方法为未标注数据生成上下文参考,从而提升模型的推理能力。
-
协作学习:用多视角构建伪标签
- 多个模型以不同的设置对未标注数据进行推理,并通过协作生成高置信度的伪标签。这种“老师互助”的方式有效提高了伪标签的质量,避免了单一模型可能带来的误差积累。
-
自适应选择:挑出最优数据
- 通过计算模型生成的伪标签的响应熵,SemiEvol 自动筛选出高置信度的伪标签,避免噪声数据对模型的负面影响。
SemiEvol 的优势
-
多场景适配能力强
- 实验显示,SemiEvol 在多个通用和领域数据集上表现优异,例如 MMLU、USMLE、ConvFinQA 等。相比传统 SFT,模型性能提升显著,尤其是在数据稀缺或任务复杂的情况下。
-
可持续进化
- 得益于半监督框架,SemiEvol 能够随着未标注数据的增加不断改进模型表现。这种持续演化能力使其非常适合动态数据场景。
-
对现有模型的兼容性
- 无论是开源模型如 Llama,还是商用模型如 GPT-4o-mini,SemiEvol 都能提供稳定的性能提升。
启示:
- SFT的核心是数据:半监督框架可以有效得综合利用标注数据和无标注数据,形成数据飞轮!
- 更符合实际场景的模型进化:半监督进化框架可以有效处理混合数据场景,实现迭代进化和持续进化!
- 普适的改进:在各类数据集和各类模型上都能体现改进,为大模型的高效适配指明了方向!
相关资源
论文链接:HuggingFace
论文链接:https://arxiv.org/abs/2410.14745
代码仓库:https://github.com/luo-junyu/SemiEvol

魔乐社区(Modelers.cn) 是一个中立、公益的人工智能社区,提供人工智能工具、模型、数据的托管、展示与应用协同服务,为人工智能开发及爱好者搭建开放的学习交流平台。社区通过理事会方式运作,由全产业链共同建设、共同运营、共同享有,推动国产AI生态繁荣发展。
更多推荐


 22
22 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)