Unet(三)_语义分割数据集准备
Unet(三)_语义分割数据集准备
参考博主源码
git clone <https://github.com/bubbliiiing/unet-pytorch.git>
第一次用的公开的数据集
VOC拓展数据集的百度网盘如下:
链接: <https://pan.baidu.com/s/1vkk3lMheUm6IjTXznlg7Ng>
提取码: 44mk
3.1标注数据集
3.1.1数据集文件结构
文件结构如下:
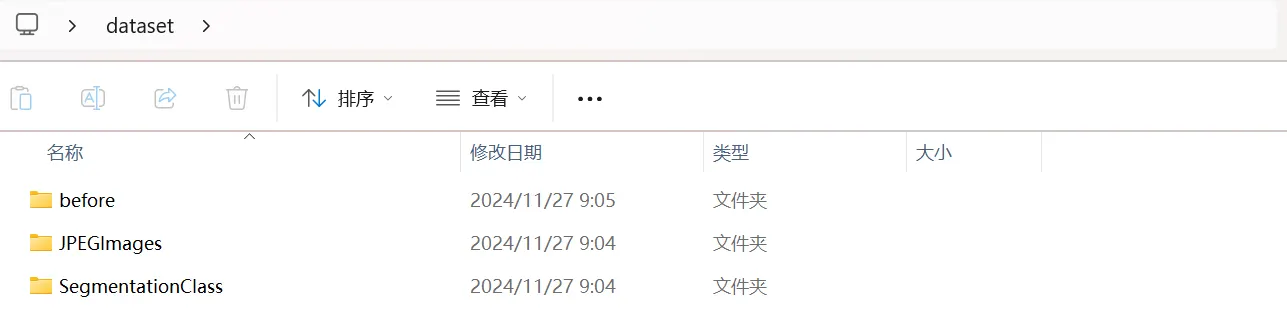
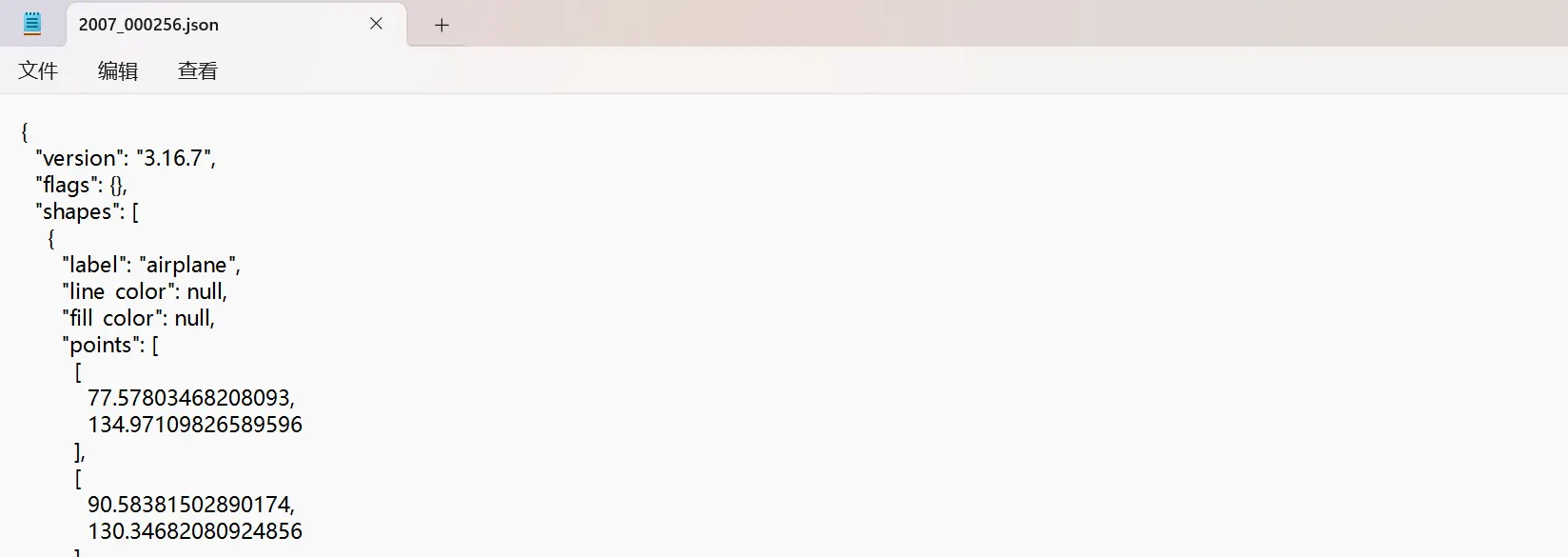
- before:存放图片和标注json文件
- JPEGImages:JPG图片
- SegmentationClass:存放语义分割标签
原始数据如下:
3.1.2打开labelme标注
使用labelme标注
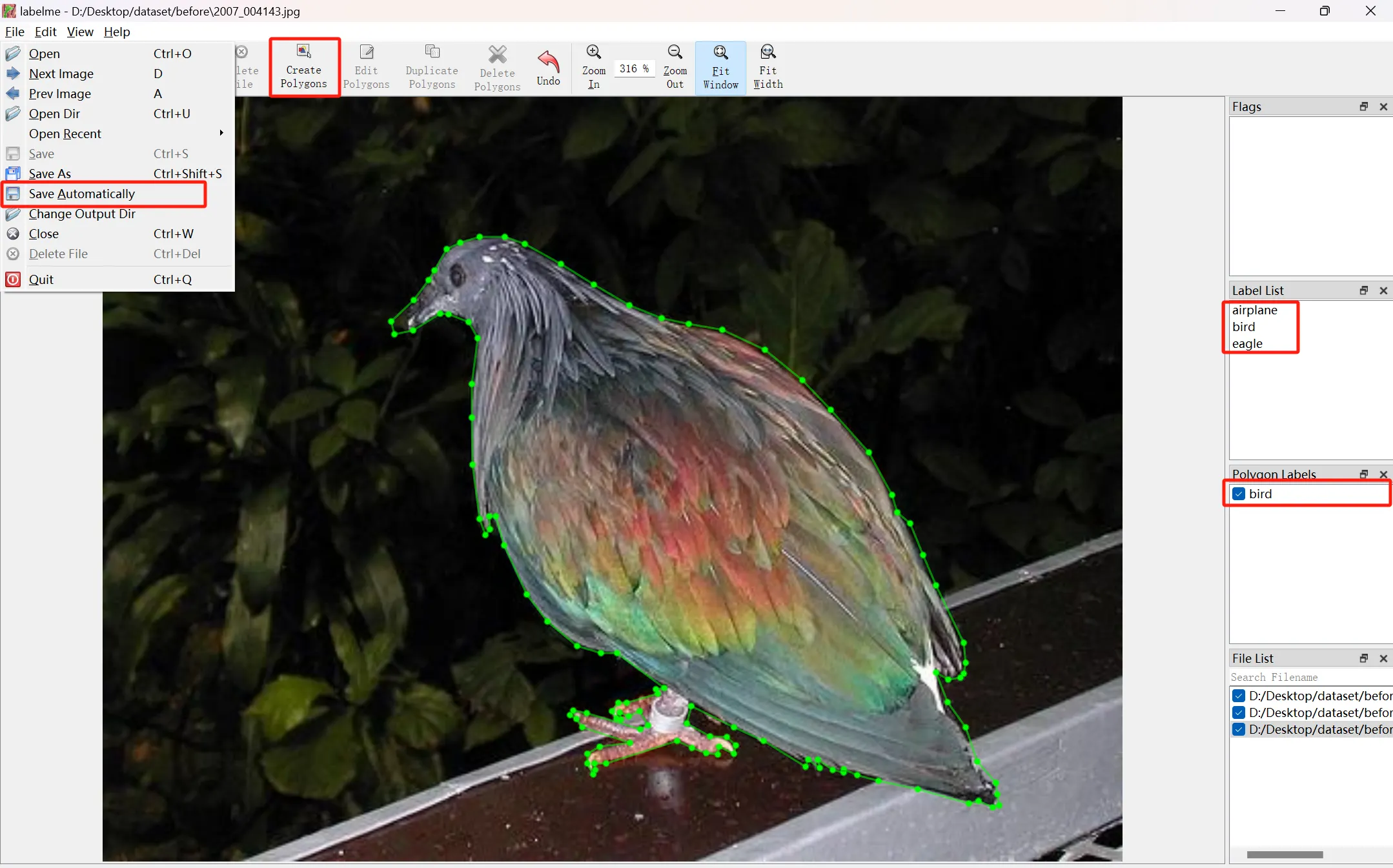
标注后文件有json文件生成
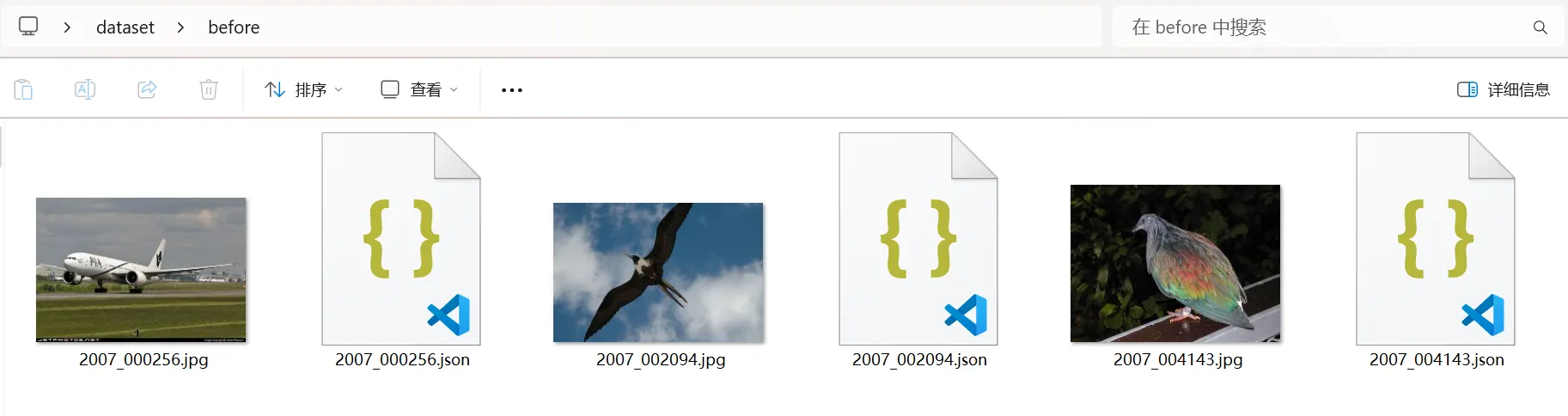
json文件格式
3.1.3制作语义分割标签
将以上标注好的数据,进行格式转换
(1)执行格式转换脚本:json_to_datasets.py
需要修改的地方有5处:
1)jpgs_path = "D:\dataset/JPEGImages":保存的jpg图片路径。
2)pngs_path = "D:\dataset/SegmentationClass":保存的png图片路径。
3)classes = ["background","airplane","eagle","bird"]:标注类别。
4)count = os.listdir("D:\dataset/before/") :原始文件存放位置。获取目录 中的所有文件和文件夹的名称,并以列表的形式返回。
5)path = os.path.join("D:\dataset/before", count[i]):原始文件存放位置。拼接成一个完整的路径。
import base64
import json
import os
import os.path as osp
import numpy as np
from PIL import Image
from labelme import utils
def process_file(json_path, jpgs_path, pngs_path, classes):
with open(json_path, 'r') as f:
data = json.load(f)
if data.get('imageData'):
image_data = data['imageData']
else:
image_path = osp.join(osp.dirname(json_path), data['imagePath'])
with open(image_path, 'rb') as img_file:
image_data = base64.b64encode(img_file.read()).decode('utf-8')
img = utils.img_b64_to_arr(image_data)
# 创建动态标签映射,确保标签值连续
label_name_to_value = {'_background_': 0}
for shape in data['shapes']:
label_name = shape['label']
if label_name not in label_name_to_value:
label_name_to_value[label_name] = len(label_name_to_value)
print(f"Classes from JSON: {label_name_to_value.keys()}")
print(f"Classes in script: {classes}")
# 确保 JSON 标签和 classes 可以正确匹配
if not set(label_name_to_value.keys()).issubset(set(classes)):
print(f"Error: JSON labels {label_name_to_value.keys()} contain undefined classes.")
return
# 生成标签图
lbl = utils.shapes_to_label(img.shape, data['shapes'], label_name_to_value)
base_name = osp.splitext(osp.basename(json_path))[0]
Image.fromarray(img).save(osp.join(jpgs_path, f"{base_name}.jpg"))
# 创建新的标签图
new_lbl = np.zeros_like(lbl, dtype=np.uint8)
for name, index_json in label_name_to_value.items():
if name in classes:
index_all = classes.index(name)
new_lbl[lbl == index_json] = index_all
else:
print(f"Warning: '{name}' not in classes list, skipping.")
print("Unique values in label image:", np.unique(new_lbl))
utils.lblsave(osp.join(pngs_path, f"{base_name}.png"), new_lbl)
print(f"Saved {base_name}.jpg and {base_name}.png")
if __name__ == '__main__':
jpgs_path = r"D:\\desktop\\dataset\\JPEGImages"
pngs_path = r"D:\\desktop\\dataset\\SegmentationClass"
json_dir = r"D:\\desktop\\dataset\\before"
classes = ["_background_", "airplane", "eagle", "bird"]
os.makedirs(jpgs_path, exist_ok=True)
os.makedirs(pngs_path, exist_ok=True)
json_files = [f for f in os.listdir(json_dir) if f.endswith('.json')]
for json_file in json_files:
json_path = osp.join(json_dir, json_file)
try:
process_file(json_path, jpgs_path, pngs_path, classes)
except Exception as e:
print(f"Error processing {json_file}: {e}")
- 为什么要生成两个文件jpg和png呢?
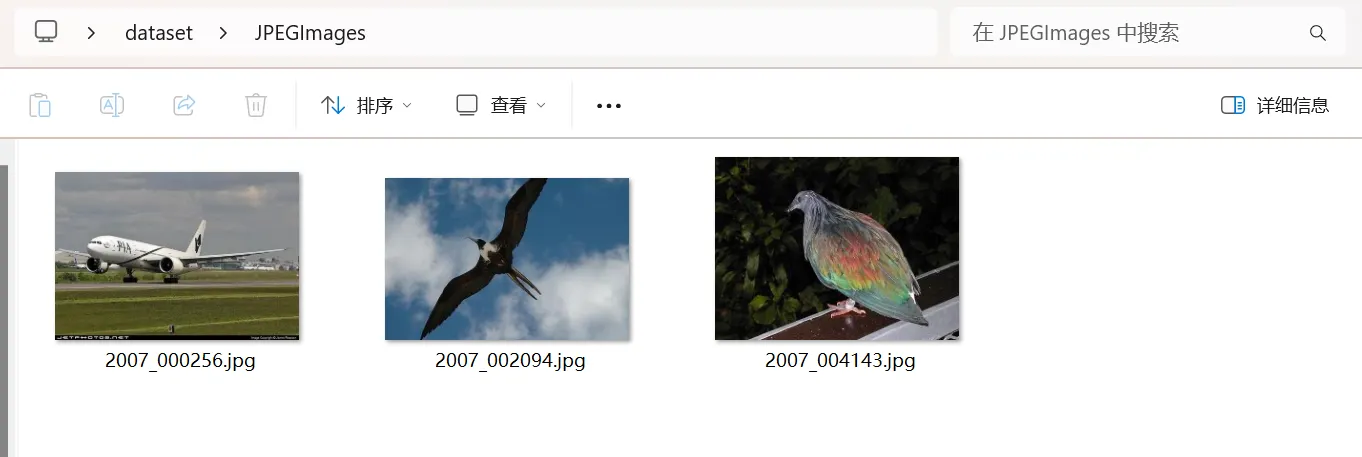
JPEG 文件:保存原始图像数据,用于展示或作为模型的输入。
PNG 文件:保存标签信息,作为模型训练过程中的标注数据。
1)JPEG 文件 (.jpg):
- 用途:JPEG 文件是图像数据的实际可视化,通常用于展示图像内容。
- 内容:包含了从 JSON 文件中提取的原始图像数据(通过 Base64 编码或直接读取图像文件)。这些图像数据展示了图像的实际内容,比如飞机、鸟等物体。
2)PNG 文件 (.png):
- 用途:PNG 文件是标签图像,用于表示图像中每个像素的类别。这是语义分割任务中的标签图(Ground Truth),通常用于训练机器学习模型,尤其是深度学习模型(如语义分割模型)。
- 内容:PNG 文件中的每个像素的值对应于图像中的某个类别,通常通过颜色或灰度值来表示不同的类别。在本例中,标签图像是一个灰度图,像素值表示图像中每个区域的类别。
为什么需要这两个文件:
1)模型训练:在语义分割中,我们需要两个信息来训练模型:
1.输入图像:模型需要通过图像来学习和识别其中的内容。
2.标签图像:每个像素的类别标签是监督学习的“目标”或“真实标签”,用来计算损失并进行训练。
2)实际应用:
- JPEG 图像:用于实际显示或推理,可以输入到训练好的模型中进行预测。
- PNG 标签图像:通常用于作为训练数据的标签,用于监督模型学习哪个像素属于哪个类别。
(2)执行后文件夹内容如下
1)before:原始图像及标签。
2)JPEGImages:保存原始图像数据,用于展示和作为模型的输入。
3)SegmentationClass:保存标签信息,作为模型训练过程中的标注数据。
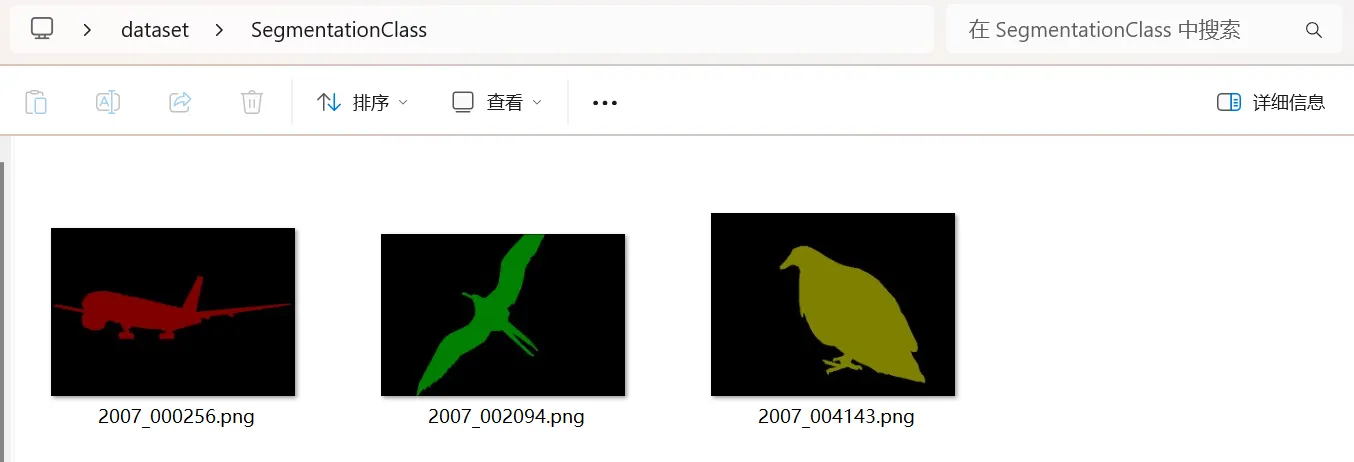
到这里我们的语义分割数据集就准备完成了!
3.1.4训练集和验证集划分
运行脚本:voc_annotation.py
划分好后的位置:/unet-pytorch/VOCdevkit/VOC2007/ImageSets/Segmentation/train.txt
该目录下的txt文件为用于训练、验证、测试的图片名称。
3.1.5数据上传
上传到项目中即可

魔乐社区(Modelers.cn) 是一个中立、公益的人工智能社区,提供人工智能工具、模型、数据的托管、展示与应用协同服务,为人工智能开发及爱好者搭建开放的学习交流平台。社区通过理事会方式运作,由全产业链共同建设、共同运营、共同享有,推动国产AI生态繁荣发展。
更多推荐


 33
33 0
0- 0



 已为社区贡献8条内容
已为社区贡献8条内容

所有评论(0)