三台ubuntu22.0.4虚拟机搭建Hadoop+Hive集群
前言
在搭建 Hadoop 和 Hive 集群的过程中,笔者遇到了一些常见的坑。为了帮助其他同学减少踩坑的机会,特此总结这篇文章,希望能帮助大家顺利完成环境搭建。
Hadoop 集群搭建
1. 创建虚拟机
使用 VMware 创建一台至少 2 核 4 GB 内存的 Ubuntu 虚拟机,主机命名为 master,然后克隆两台虚拟机,分别命名为 slave1 和 slave2。
1.1 如何更改主机名
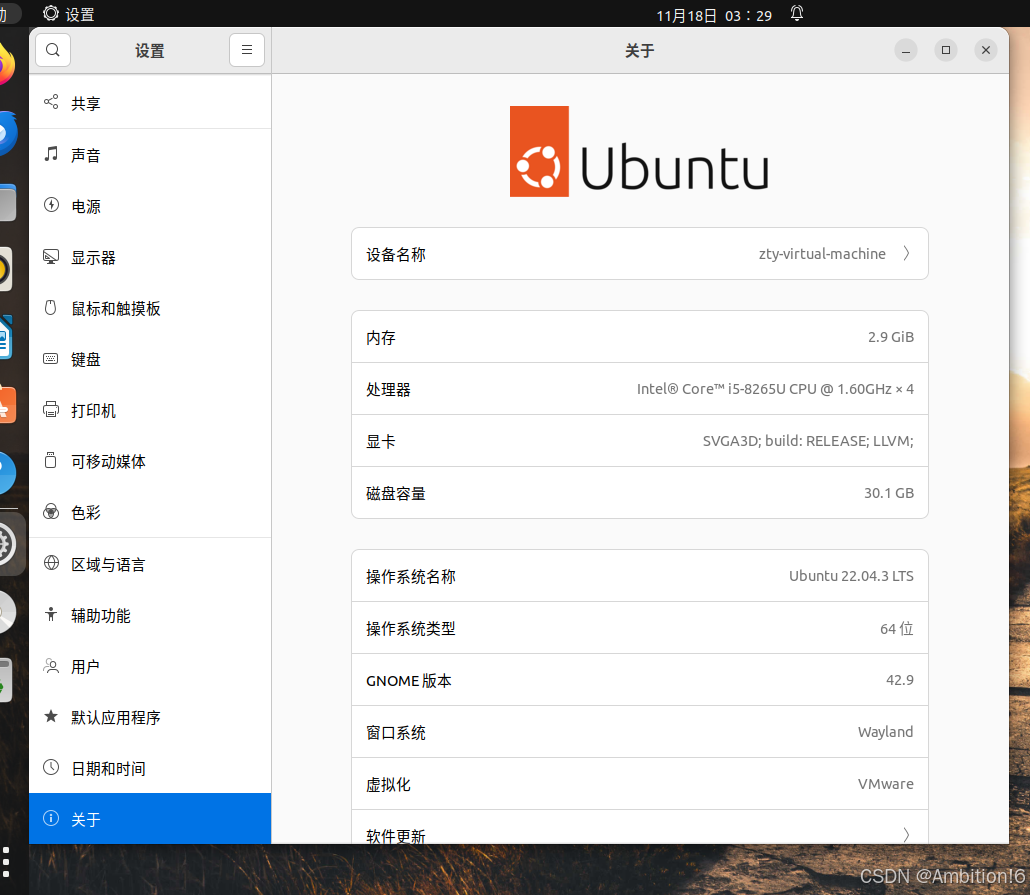
可视化界面更改
点击设置,选择 “关于”,然后点击 “设备名称” 进行修改。
终端界面更改
执行以下命令编辑主机名:
vim /etc/hostname
将文件中的内容替换为新的主机名。
1.2 修改 /etc/hosts 文件
在所有三台主机上都需要修改此文件。使用 ifconfig 查看每台机器的局域网 IP 地址,然后编辑 hosts 文件:
vim /etc/hosts
以下是修改示例,记得将 IP 地址替换为自己机器的实际 IP:
192.168.219.128 master
192.168.219.129 slave1
192.168.219.130 slave2
修改完后,重启每台主机:
reboot
2. 配置 SSH 免密登录
为三台机器配置 SSH 密钥,实现远程无密码访问。
2.1 安装 SSH 服务
sudo apt-get install openssh-server # 安装 SSH 服务
sudo /etc/init.d/ssh restart # 启动 SSH 服务
sudo ufw disable # 关闭防火墙
2.2 生成 SSH 密钥并分发
在每台节点上生成 SSH 密钥,并将公钥分发到其他机器。
首先生成密钥:
ssh localhost
cd ~/.ssh
rm ./id_rsa*
ssh-keygen -t rsa
然后将公钥添加到 authorized_keys 文件:
cat $HOME/.ssh/id_rsa.pub >> $HOME/.ssh/authorized_keys
接着将 master 主机上的公钥传送到 slave1 和 slave2:
scp ~/.ssh/id_rsa.pub hadoop@slave1:~/
scp ~/.ssh/id_rsa.pub hadoop@slave2:~/
最后,在 slave1 和 slave2 上执行以下命令:
cat ~/id_rsa.pub >> ~/.ssh/authorized_keys
这样就完成了免密登录配置。
3. 安装 Java 环境
sudo apt update
sudo apt install openjdk-8-jdk
4. 安装 Hadoop
可以通过 wget 下载 Hadoop,但可能速度较慢。建议在本地官网下载,然后上传到虚拟机。
wget https://downloads.apache.org/hadoop/common/hadoop-3.3.5/hadoop-3.3.5.tar.gz
tar -xzvf hadoop-3.3.5.tar.gz
sudo mv hadoop-3.3.5 /usr/local/hadoop
5. 配置环境变量
vim ~/.bashrc
编辑 ~/.bashrc 文件,添加以下内容:
export HADOOP_HOME=/usr/local/hadoop
export PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin
export JAVA_HOME=/usr/lib/jvm/java-8-openjdk-amd64
使配置生效:
source ~/.bashrc
6. 配置 Hadoop
在 /usr/local/hadoop/etc/hadoop/ 目录下配置以下文件:
6.1 core-site.xml
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://master:9000</value>
</property>
<property>
<name>hadoop.proxyuser.hadoop.hosts</name>
<value>*</value>
</property>
<property>
<name>hadoop.proxyuser.hadoop.groups</name>
<value>*</value>
</property>
</configuration>
6.2 hdfs-site.xml
<configuration>
<property>
<name>dfs.replication</name>
<value>2</value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>file:///usr/local/hadoop/hdfs/namenode</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>file:///usr/local/hadoop/hdfs/datanode</value>
</property>
</configuration>
6.3 mapred-site.xml
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<property>
<name>yarn.app.mapreduce.am.env</name>
<value>HADOOP_MAPRED_HOME=$HADOOP_HOME</value>
</property>
<property>
<name>mapreduce.map.env</name>
<value>HADOOP_MAPRED_HOME=$HADOOP_HOME</value>
</property>
<property>
<name>mapreduce.reduce.env</name>
<value>HADOOP_MAPRED_HOME=$HADOOP_HOME</value>
</property>
</configuration>
6.4 yarn-site.xml
<configuration>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.scheduler.maximum-allocation-mb</name>
<value>2048</value>
</property>
<property>
<name>yarn.scheduler.minimum-allocation-mb</name>
<value>2048</value>
</property>
<property>
<name>yarn.nodemanager.vmem-pmem-ratio</name>
<value>2.1</value>
</property>
<property>
<name>mapred.child.java.opts</name>
<value>-Xmx1024m</value>
</property>
<property>
<name>yarn.nodemanager.resource.memory-mb</name>
<value>4096</value>
</property>
</configuration>
6.5 workers
master
slave1
slave2
6.6 hadoop-env.sh 和 yarn-env.sh
编辑 hadoop-env.sh 和 yarn-env.sh,将以下内容添加进去:
export JAVA_HOME=/usr/lib/jvm/java-8-openjdk-amd64
7. 格式化 HDFS
在主节点执行以下命令:
hdfs namenode -format
在两台从节点执行以下命令:
hdfs datanode -format
8. 启动 Hadoop
启动 Hadoop 的 HDFS 和 YARN:
start-dfs.sh
start-yarn.sh
通过执行 jps 命令检查是否启动成功。
Hive 配置
1. 安装 MySQL(用于存储元数据)
Hive 需要一个关系型数据库来存储元数据。这里使用 MySQL。
1.1 安装 MySQL
sudo apt install mysql-server
sudo mysql_secure_installation
1.2 创建 Hive 数据库和用户
CREATE DATABASE hive;
CREATE USER 'hiveuser'@'localhost' IDENTIFIED BY 'hivepassword';
GRANT ALL PRIVILEGES ON hive.* TO 'hiveuser'@'localhost';
FLUSH PRIVILEGES;
2. 安装 Hive
wget https://downloads.apache.org/hive/hive-3.1.2/apache-hive-3.1.2-bin.tar.gz
tar -xzvf apache-hive-3.1.2-bin.tar.gz
sudo mv apache-hive-3.1.2-bin /usr/local/hive
3. 配置 Hive
3.1 修改 hive-site.xml
<configuration>
<property>
<name>javax.jdo.option.ConnectionURL</name>
<value>jdbc:mysql://localhost:3306/hive?useSSL=false</value>
</property>
<property>
<name>javax.jdo.option.ConnectionDriver.Name</name>
<value>com.mysql.cj.jdbc.Driver</value>
</property>
<property>
<name>javax.jdo.option.ConnectionUserName</name>
<value>hiveuser</value>
</property>
<property>
<name>javax.jdo.option.ConnectionPassword</name>
<value>hivepassword</value>
</property>
</configuration>
3.2 设置环境变量
编辑 Hive 环境变量配置文件,确保 Hive 能正确识别 Hadoop 和 Hive 的配置文件路径。
mv /usr/local/hive/conf/hive-env.sh.template /usr/local/hive/conf/hive-env.sh
vi /usr/local/hive/conf/hive-env.sh
在 hive-env.sh 中追加以下两行内容:
export HADOOP_HOME=/usr/local/hadoop
export HIVE_CONF_DIR=/usr/local/hive/conf
3.3 创建相关目录和赋予权限
在 Hadoop 中创建 Hive 所需的目录,并设置适当的权限。此步骤必须在启动 Hadoop 后执行:
hadoop fs -mkdir /tmp
hadoop fs -mkdir -p /user/hive/warehouse
hadoop fs -chmod g+w /tmp
hadoop fs -chmod g+w /user/hive/warehouse
这些目录是 Hive 存储数据和临时文件的地方,必须确保 Hive 用户对它们有写入权限。
4. 初始化 Hive 数据库
schematool -dbType mysql -initSchema
nohup hive --service metastore &
nohup hiveserver2 &
5. 验证 Hive
验证 Hive 是否正常工作,可以使用 Beeline 或其他 Hive 客户端连接到 HiveServer2。
5.1 使用 Beeline 连接 HiveServer2
Beeline 是 Hive 提供的一个 JDBC 客户端工具,可以用来连接 HiveServer2 并执行 SQL 查询。
beeline -u jdbc:hive2://localhost:10000
5.2 执行简单查询验证安装
连接成功后,执行以下查询以验证 Hive 是否正常运行:
SHOW DATABASES;
总结
本文介绍了如何在 VMware 上搭建一个简单的 Hadoop 集群和 Hive 环境。关键步骤包括配置主机名、设置 SSH 免密登录、安装 Java 和 Hadoop、配置 Hive 与 MySQL,以及启动相关服务。完成这些步骤后,你将拥有一个可以处理大数据的基础环境,能够使用 Hive 进行 SQL 查询和数据分析。如果遇到问题,可以根据提示解决或随时提问!

魔乐社区(Modelers.cn) 是一个中立、公益的人工智能社区,提供人工智能工具、模型、数据的托管、展示与应用协同服务,为人工智能开发及爱好者搭建开放的学习交流平台。社区通过理事会方式运作,由全产业链共同建设、共同运营、共同享有,推动国产AI生态繁荣发展。
更多推荐


 23
23 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)