Informer2020项目解读+跑通+换自己数据集跑通
Informer2020项目解读+跑通+换自己数据集跑通
Informer: Beyond Efficient Transformer for Long Sequence Time-Series Forecasting (AAAI'21 Best Paper)的项目解读+跑通+换自己数据集跑通
2021评选AAAI最牛逼论文,我看看有多牛逼
项目开源地址
https://github.com/zhouhaoyi/Informer2020
项目论文
https://arxiv.org/abs/2012.07436
项目核心
解码器和编码器的优化创新点
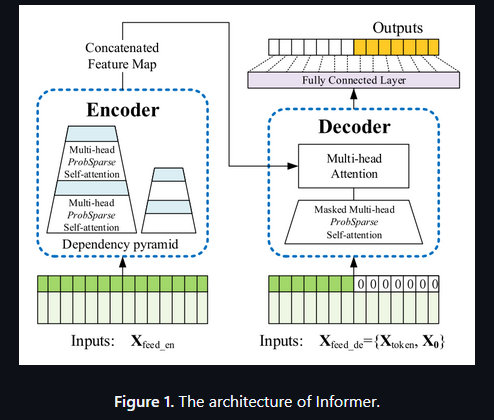
对于QKV,作者研究对于Q与K之间相乘得到一个向量去看这俩是否有关系。
但是作者研究发现大部分的Q与K之间没啥关系,就导致之前的transformer运行慢。
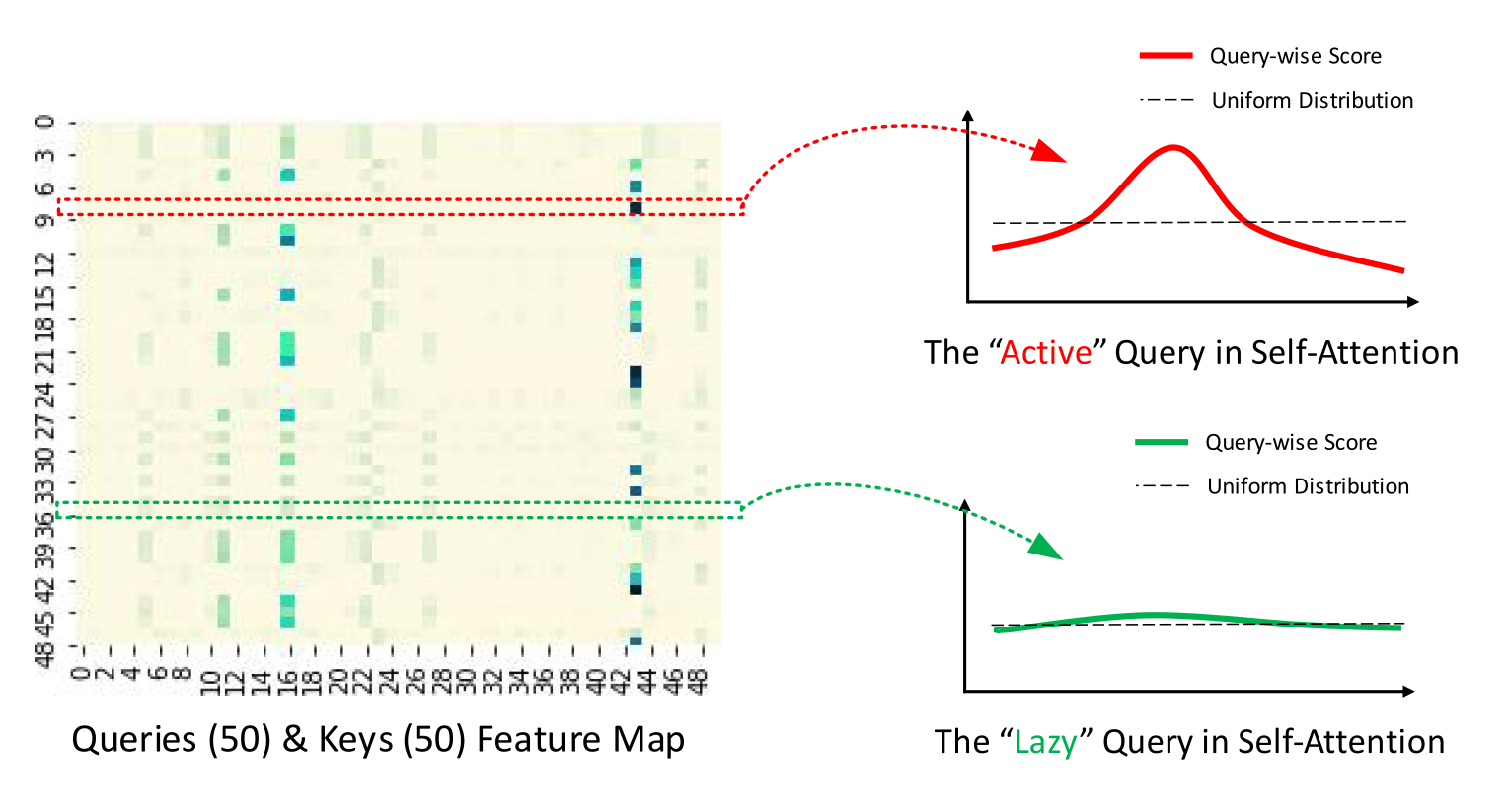
然后作者随机选了几个K去找和所有Q的关系(算两者之间的向量乘积然后看他的分布)
按效果进行排序,选与均匀分布差异最大的,效果好的就留下来,效果不好的就近似与均匀分布,这部分直接不要了,用均匀分布的均值来直接替换这部分
然后再去用这些剩下的K去进行下一步的操作。
下载了数据集解压缩看看
先按照README文件里面要求的环境配好,其实也不用配,用你常用的环境能跑就完事了

我复现一下跑WTH数据集,去这里面下载这个数据集
我把这个文件放在了data目录下
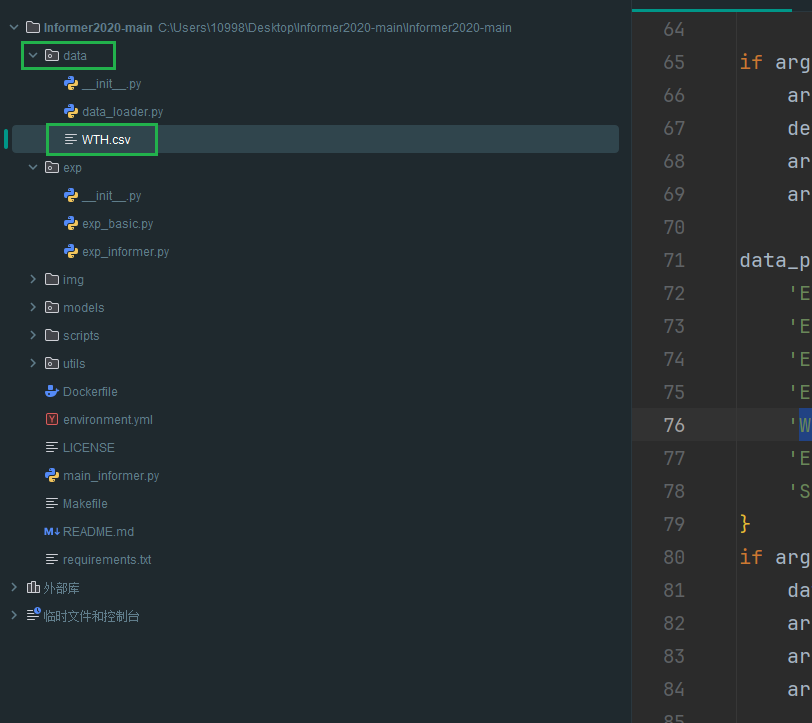
打开main_informer文件,看一下我们要改的地方是什么。
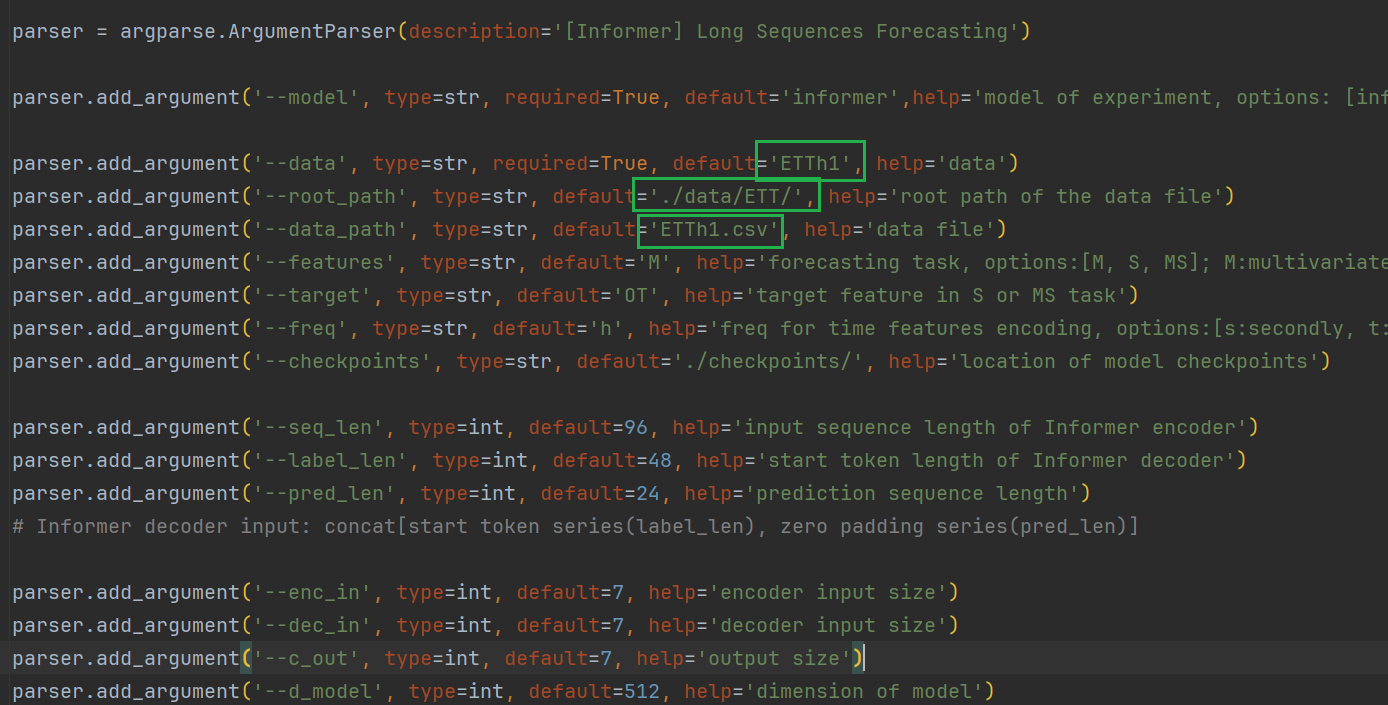
parser.add_argument('--data', type=str, required=True, default='ETTh1', help='data')
parser.add_argument('--root_path', type=str, default='./data/ETT/', help='root path of the data file')
parser.add_argument('--data_path', type=str, default='ETTh1.csv', help='data file') 改成
parser.add_argument('--data', type=str, required=True, default='WTH', help='data')
parser.add_argument('--root_path', type=str, default='./data/', help='root path of the data file')
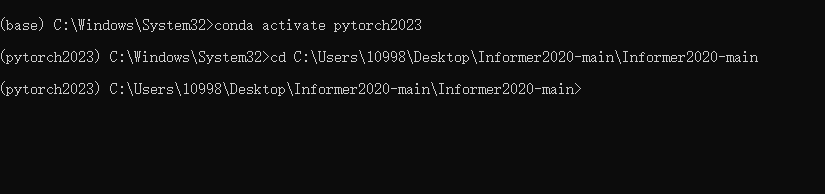
parser.add_argument('--data_path', type=str, default='WTH.csv', help='data file') 然后打开anaconda prompt,切换到你用的Python虚拟环境
conda activate your_env_name将运行目录找到你的main_informer运行主程序下的地址,方便进行指令控制
cd C:\Users\xxx\xxx\xxx\xx完成后就是这样
然后打开readme看一下运行指令是什么
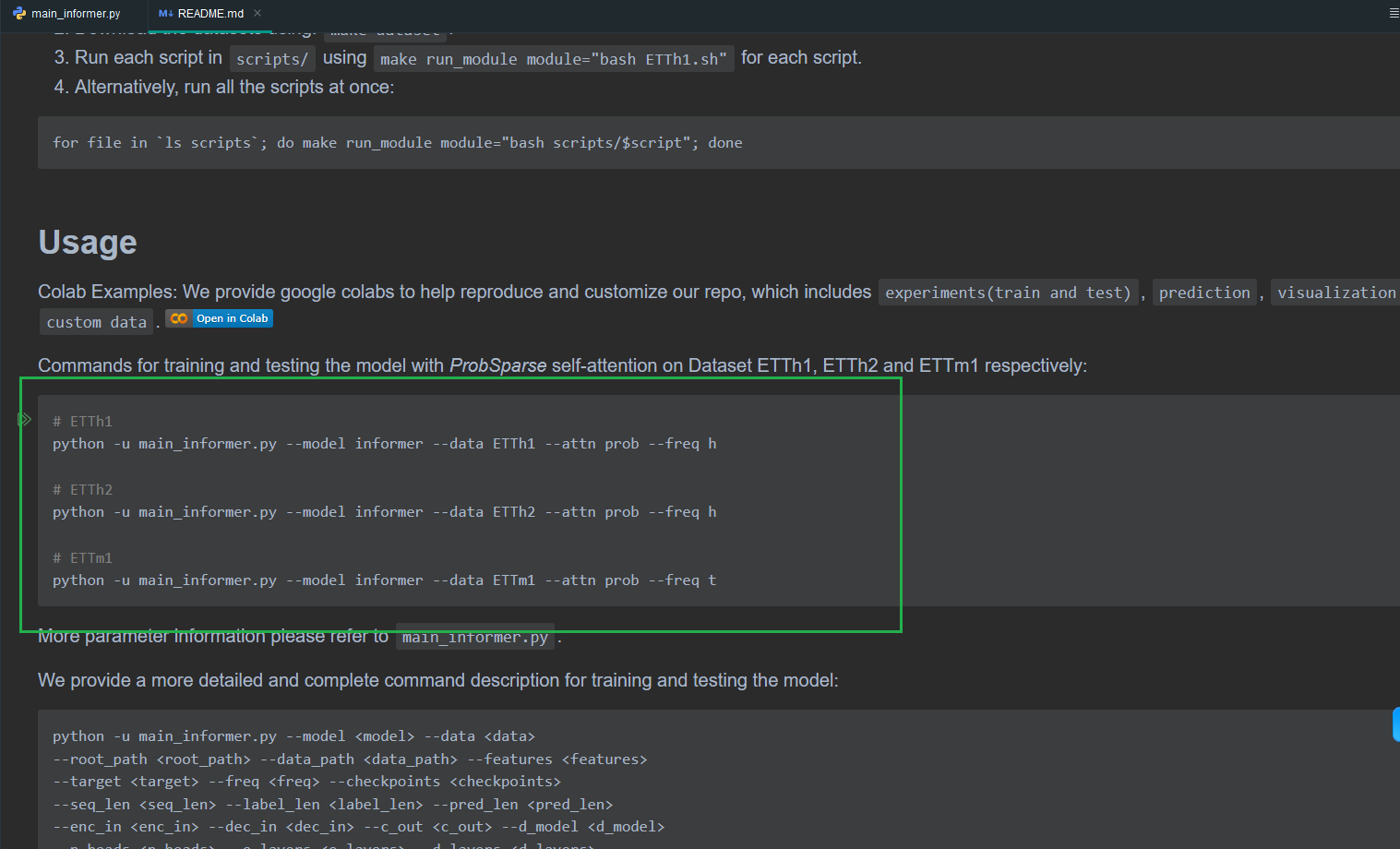
没给WTH的,照猫画虎自己编
python -u main_informer.py --model informer --data WTH --attn prob --freq hpython -u XXX就是启动什么程序,我们填我们的主程序main_informer
--model xxx就是选你要跑的模型 我们肯定跑这次的主角informer
--data xxx就是你的数据集名字
--attn prob 就是注意力机制用哪个模型,他论文就是这个改进后的模型不用改
--freq XXX就是数据集的尺度,要是分钟就写t,小时就写h
将指令输入到anaconda prompt中
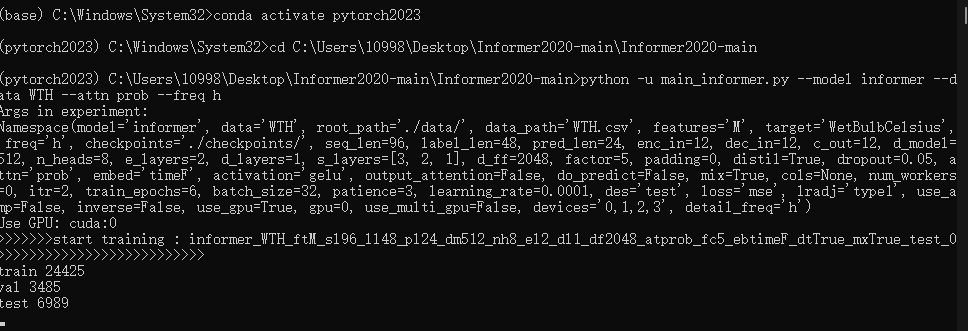
跑起来了,如果不能用GPU跑的,自己弄教程也不会,花米去某鱼或某宝找人弄一下就行。
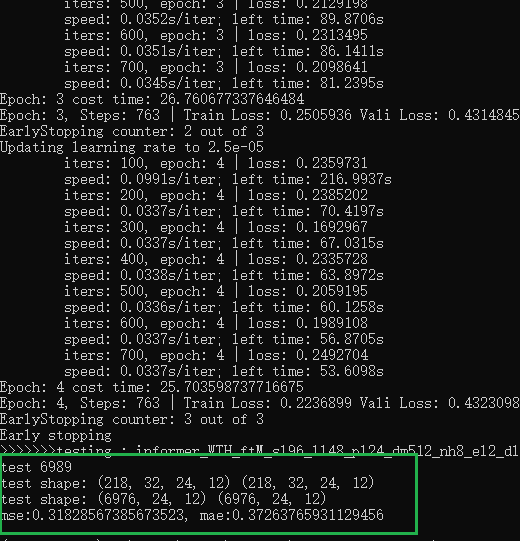
跑完。
然后换自己数据集,我用最简单的为例,纯预测流量
| date | flow |
| 9/19/2016 0:00 | 13 |
| 9/19/2016 0:20 | 6 |
| 9/19/2016 0:40 | 9 |
第一列为时间,第二列为流量。
还是把数据集放在data目录下,然后看一下需要改什么

这三个改成你数据集的目录

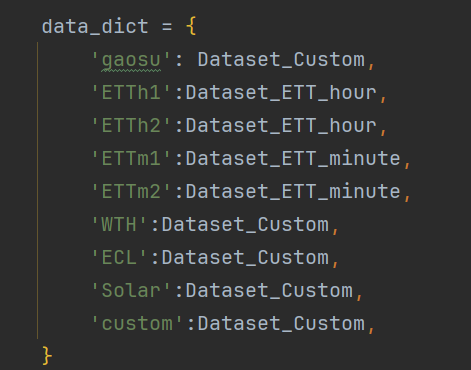
这里面加一行你的数据集的东西
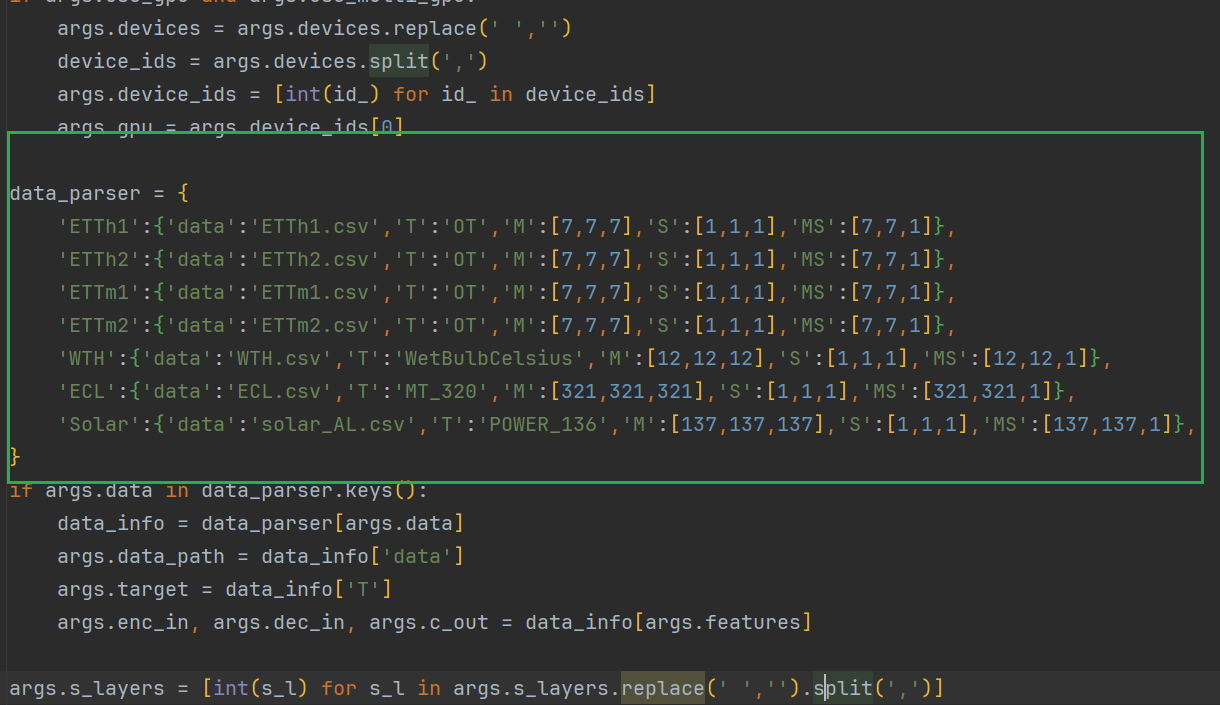
如下
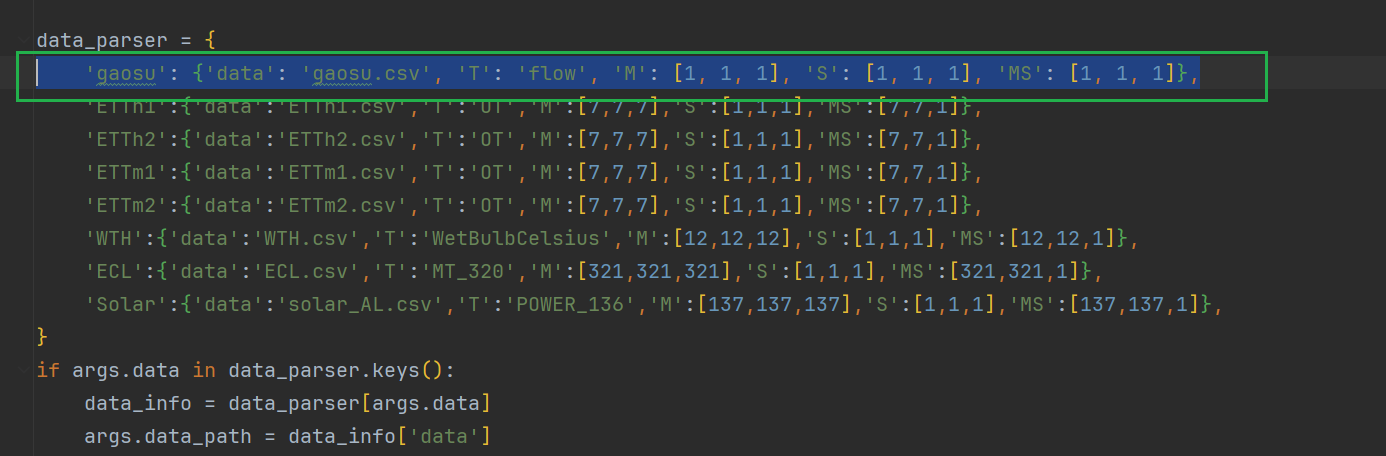
'数据集名称': {'data': '数据集文件名', 'T': '你要预测的内一列的表头名字', 'M': [1, 1, 1], 'S': [1, 1, 1], 'MS': [1, 1, 1]},
后面的M,S,MS就是单变量还是多变量预测,对于M,S来说里面全填除了你时间内一列还有几列,我除了时间内列就是流量,所以全填1
对于MS来说,前两个空填除了你时间内一列还有几列,最后一个空填1
在exp_informer里面加一行你的数据集的
然后去编运行指令
python -u main_informer.py --model informer --data gaosu --attn prob --freq tpython -u XXX就是启动什么程序,我们填我们的主程序main_informer
--model xxx就是选你要跑的模型 我们肯定跑这次的主角informer
--data xxx就是你的数据集名字
--attn prob 就是注意力机制用哪个模型,他论文就是这个改进后的模型不用改
--freq XXX就是数据集的尺度,要是分钟就写t,小时就写h
直接把指令输入到anaconda prompt,开跑
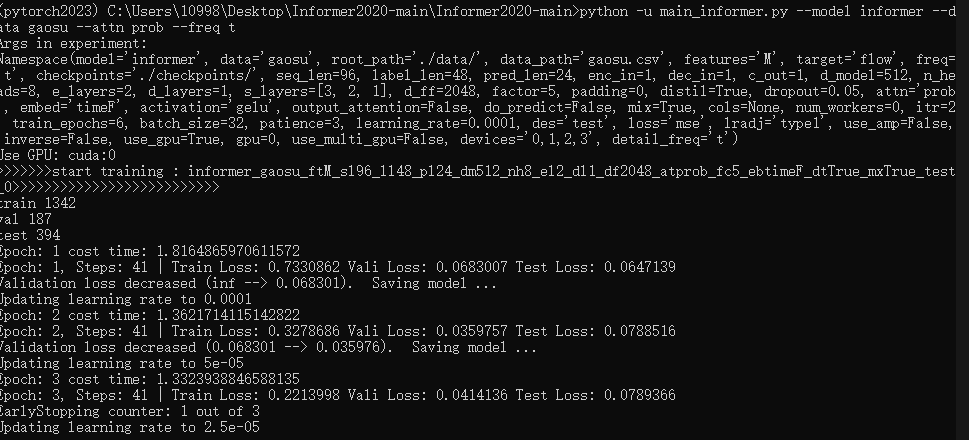
跑完了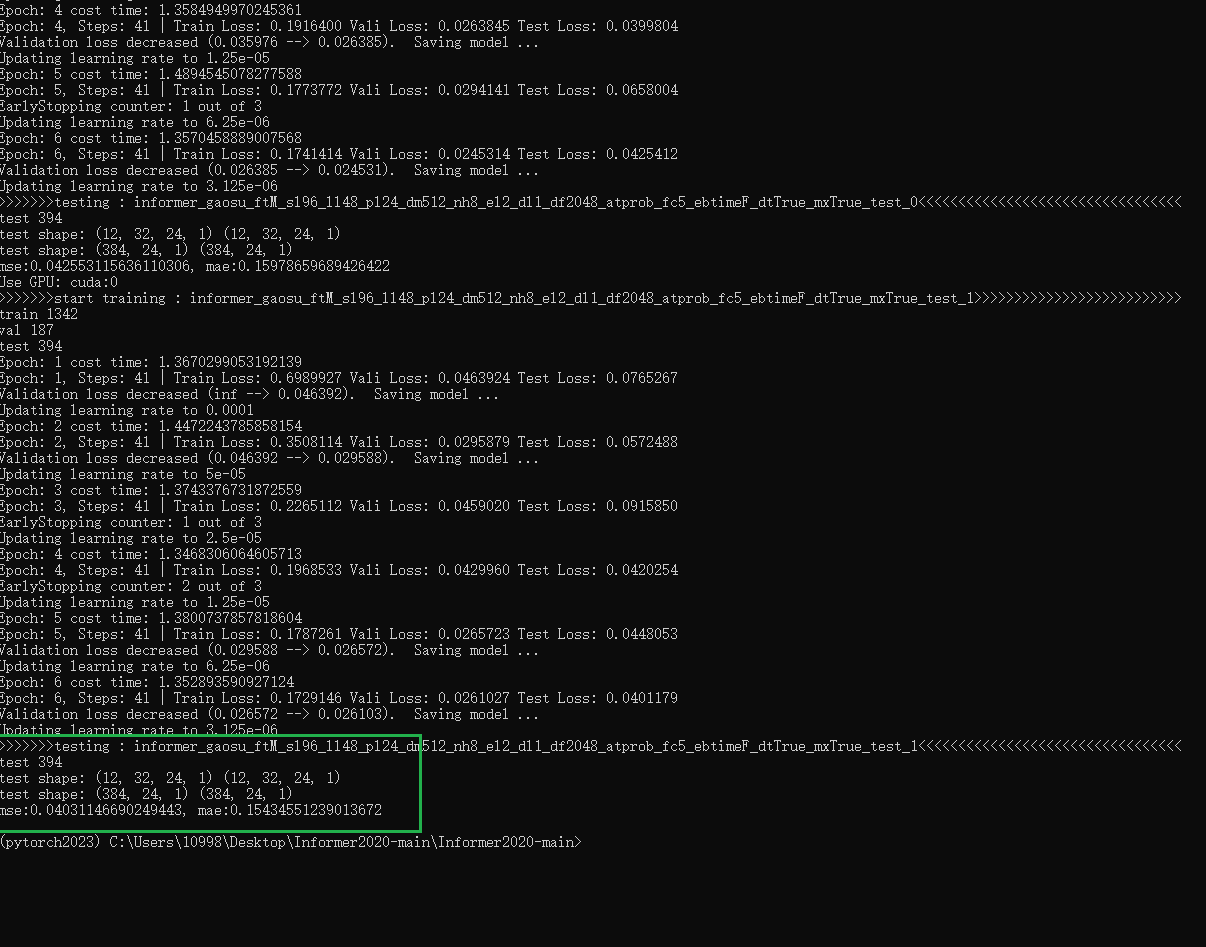

魔乐社区(Modelers.cn) 是一个中立、公益的人工智能社区,提供人工智能工具、模型、数据的托管、展示与应用协同服务,为人工智能开发及爱好者搭建开放的学习交流平台。社区通过理事会方式运作,由全产业链共同建设、共同运营、共同享有,推动国产AI生态繁荣发展。
更多推荐


 19
19 0
0- 0



 已为社区贡献5条内容
已为社区贡献5条内容

所有评论(0)