浩瀚深度:从 ClickHouse 到 Doris, 支撑单表 13PB、534 万亿行的超大规模数据分析场景
摘要: 浩瀚深度企业级大数据平台采用Apache Doris替换ClickHouse,成功应对超大规模数据处理挑战。其最大集群部署于117节点,单表数据量突破13PB、534万亿行,日均导入145TB,峰值158TB,稳定运行半年。测试表明,Doris在前缀索引、二级索引场景下性能达ClickHouse的2-5倍,全表扫描表现接近。迁移通过调整写入组件和SQL适配实现平滑过渡,并针对大批量写入和C
作者:浩瀚深度应用产品线大数据团队(浩瀚深度 [SHA: 688292])

导读
浩瀚深度旗下企业级大数据平台选择 Apache Doris 作为核心数据库解决方案,目前已在全国范围内十余个生产环境中稳步运行,**其中最大规模集群部署于 117 个高性能服务器节点,单表原始数据量超 13PB,行数突破 534 万亿,日均导入数据约 145TB,节假日峰值达 158TB,是目前已知国内最大单表。**凭借 Apache Doris 的高可靠、高性能与高可扩展能力,该集群已持续稳定运行半年以上,充分验证了其在超大规模数据场景下的卓越表现。
浩瀚深度作为国内互联网流量解析与数据智能化领域的领军企业,深耕行业三十余载,持续为国内互联网提供高性能、高精度、高可靠的整体解决方案。公司业务覆盖网络可视化、AI 智能、数据治理、数据价值挖掘及安全防护,是一家集软硬件产品研发、生产、销售和服务于一体的大型高科技企业。
顺水云大数据平台(StreamCloud)作为浩瀚深度自主研发的企业级大数据平台产品,涵盖从数据采集、存储、处理、挖掘、治理到共享的完整数据开发流程,帮助企业客户快速构建 PB 级数据中台。目前已在通信、金融、交通等领域落地部署 100+ 项目,管理超过 130PB 数据,集群节点规模近万个。
为满足客户每日写入及查询万亿级增量数据的严苛需求,顺水云对 MPP 数据库产品进行多轮选型测试,曾尝试 Greenplum、ClickHouse 等方案,最终选定 Apache Doris 作为核心数据库解决方案。目前该方案已在全国十余个生产环境上线,最大集群部署于 117 个高性能服务器节点,单表原始数据量超 13PB,行数突破 534 万亿,日均导入约 145TB,节假日峰值约 158TB,且已持续稳定运行半年以上。](https://i-blog.csdnimg.cn/direct/5bfdaf2c14c5487393d16527a2c4eea2.png)
早期架构以及痛点
早期架构中,数据主要来源为用户上网日志,经采集设备解析还原后发送到接口机,再由接口机程序接入 HDFS 集群,基于 Apache Spark 加工、回填、合成不同类型话单,最终写入 ClickHouse,用于日志存储与快速查询、流量质量分析、政企用户画像及精准营销等场景。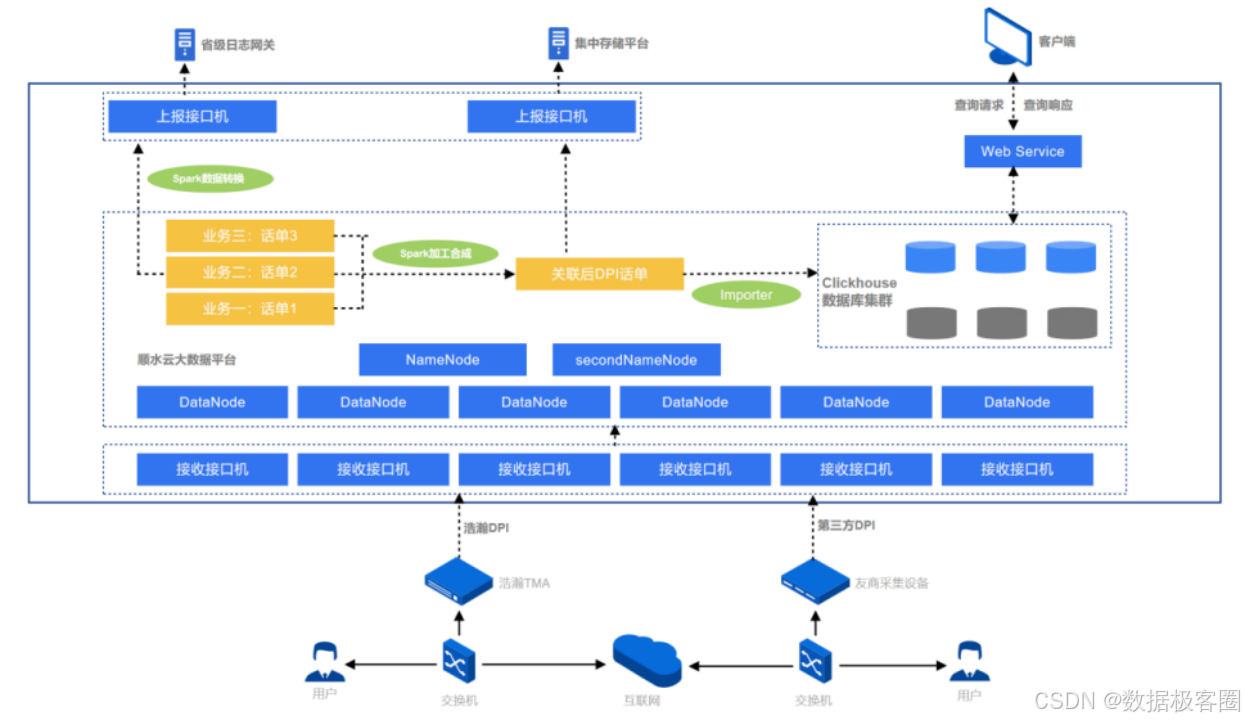
随着业务数据体量增长,对高吞吐写入、亿级数据秒级响应、海量数据关联查询的需求愈发迫切,ClickHouse 体系逐渐暴露以下痛点:
- 写入稳定性差且存储成本高:尝试 ZSTD 压缩以降低成本,但高压缩比导致性能开销,频繁出现 “too many parts” 及数据入库积压;为保障稳定,不得不使用默认 LZ4 压缩,增加存储成本。
- 运维成本高:自研入库工具因接口机数据量和导入性能差异,导致集群节点数据不均衡;ClickHouse 架构限制,坏盘时数据无法自动迁移,需人工持续干预。
- 并发查询能力不足:并发查询较多时性能下降明显,无法满足业务需求。
- JOIN 能力不足:自身设计限制,无法支持多表或大表 Join 查询,难以满足关联查询需求。
Apache Doris vs. ClickHouse 对比测试
测试准备
使用三台物理机模拟生产环境,对比 Doris 与 ClickHouse 的写入和查询性能,测试分为前缀索引、二级索引、全表扫描三部分。
-
前缀索引文档详情:https://doris.apache.org/zh-CN/docs/table-design/index/prefix-index
-
二级索引文档详情:
测试参数:, ZSTD 压缩后 1.8TB (双副本))](https://i-blog.csdnimg.cn/direct/a0f1cdb9e6c24a759974684ddc137734.png)
建表信息:
Doris 2.0.0+ 支持倒排索引,在表数据量和字段一致的前提下,针对不同排序键与索引类型测试查询速度: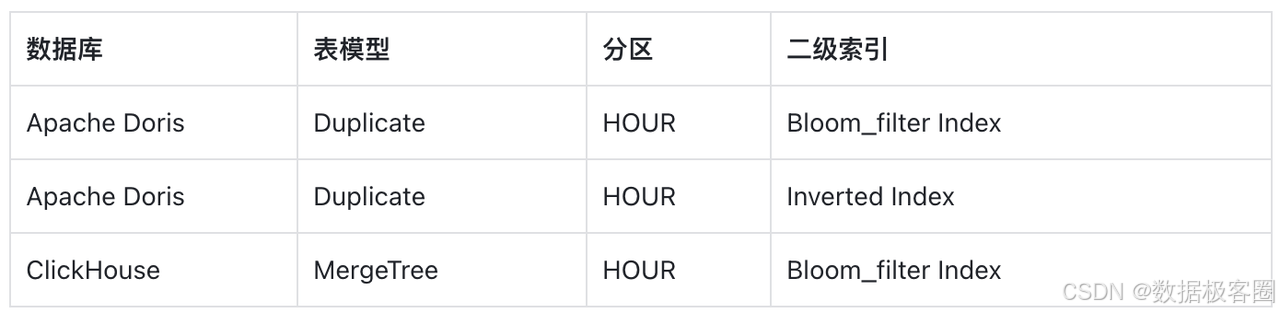
测试一:前缀索引
前缀索引加速等值查询和范围查询,Doris 建表时自动取表 Key 前 36 个字节作为前缀索引。测试为 3 次冷查询,结果如下: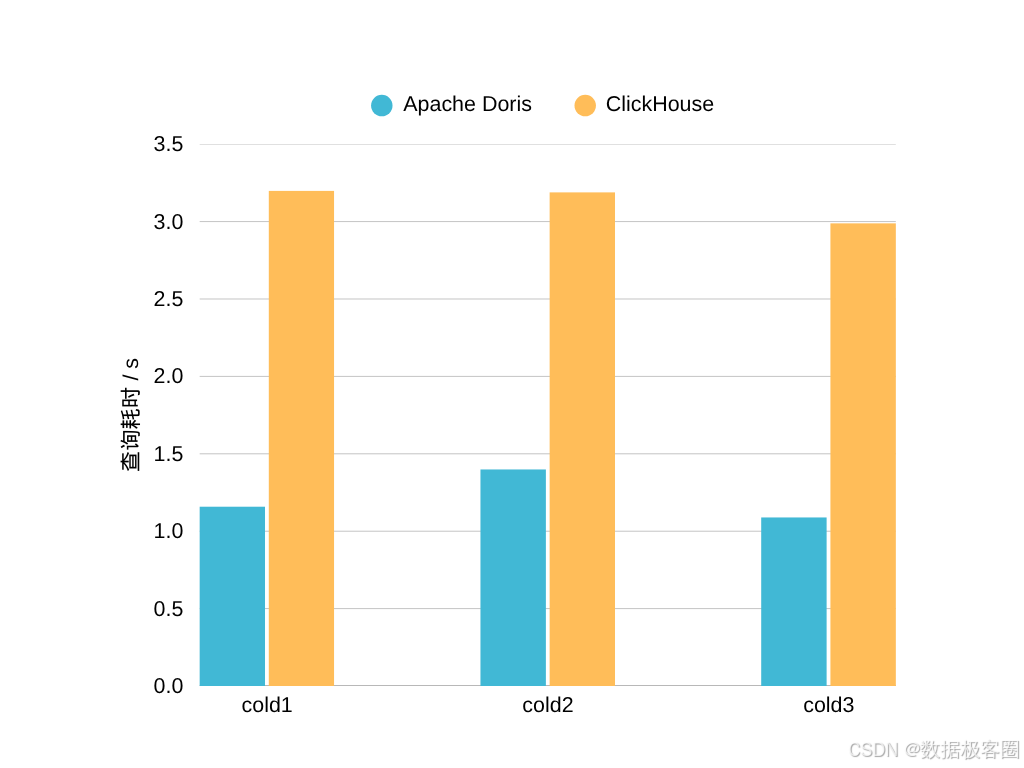
测试二:二级索引
-
BloomFilter Index:基于 BloomFilter 跳过不满足条件的数据块,减少 I/O。
-
Inverted Index:支持文本全文检索、数值 / 日期等值范围查询,快速过滤满足条件的行。
测试为 3 次冷查询,结果如下:
](https://i-blog.csdnimg.cn/direct/1c71bdcda1fc44c49a88b3eec5da916f.png)
测试三:全表扫描
测试常用业务场景:like 模糊查询和 IP 函数。结果显示,IS_IP_ADDRESS_IN_RANGE 函数查询中 ClickHouse 略胜。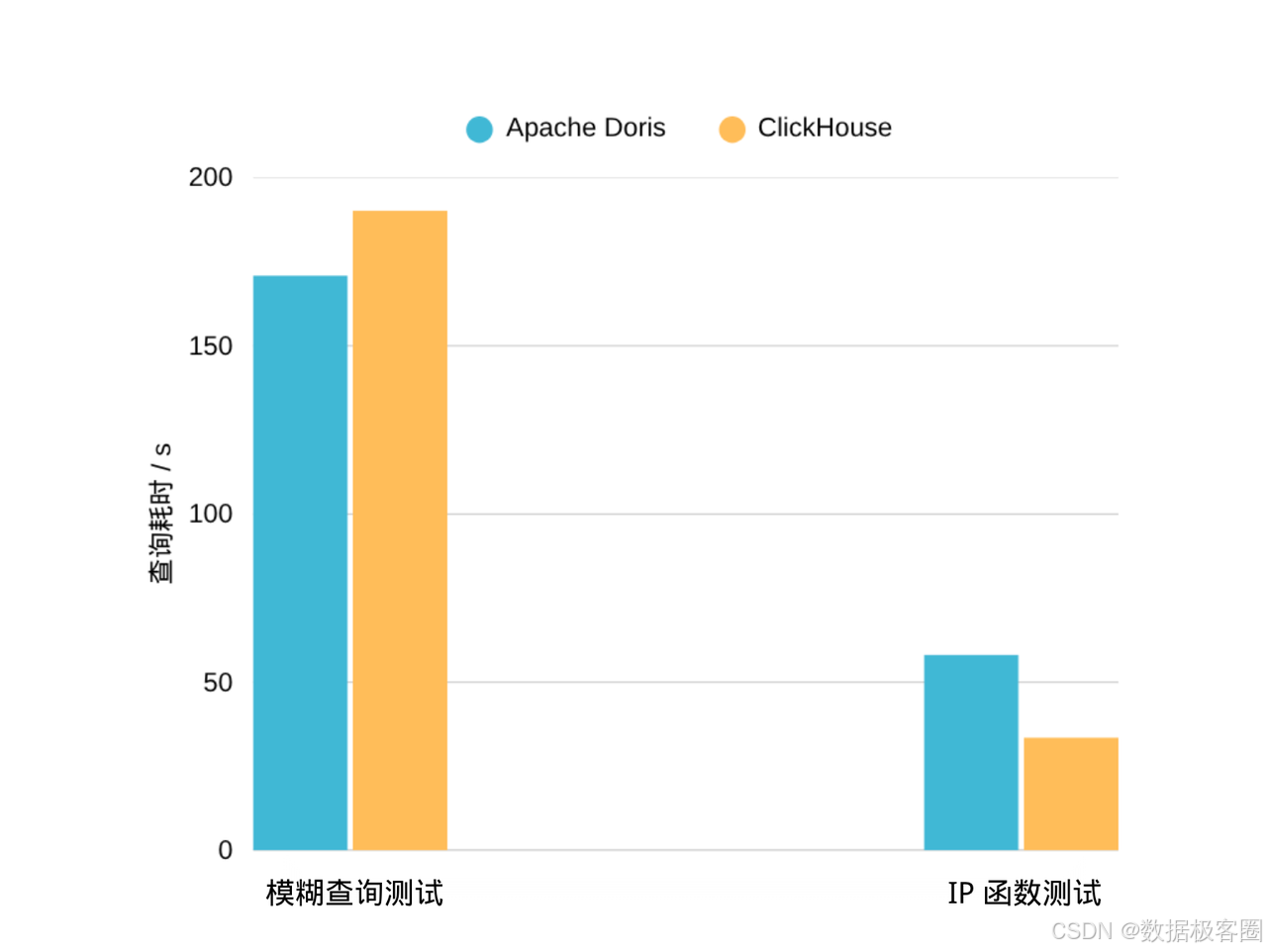
结果分析
合理配置索引时,Doris 在关键场景表现显著优势:
-
前缀索引:Doris 查询速度是 ClickHouse 的 2 倍以上。
-
二级索引:
-
BloomFilter 索引:Doris 速度领先 ClickHouse 达 2 倍。
-
倒排索引:Doris 性能是 ClickHouse 的 5 倍以上。
-
-
全表扫描:两者性能接近,ClickHouse 在特定函数调用上略占优势。
综合来看,Doris 的前缀索引、BloomFilter 和倒排索引性能全面优于 ClickHouse,迁移后查询响应速度预计提升超 2 倍。
Doris 替换实践
因 ClickHouse 与 Doris 均为 MPP 架构,且 Doris 支持 MySQL 语法,架构变化小、迁移便捷:
-
调整上游 Importer 写入组件配置,直接写入 Doris 表;
-
更新下游查询服务 SQL 以适配 Doris 语法,实现无缝迁移。
考虑生产环境数据量级和新组件不确定性,初期采用 ClickHouse 与 Doris 并行运行,压测中解决以下问题:
实践一:解决大批量写入报错问题
30 台接口机并发导入时,出现如下异常:
| Plain Textorg.apache.doris.common.UserException: errCode = 2, detailMessage = get tableList write lock timeout, tableList=(Table [id=885211, name=td_home_dist, type=OLAP]) [INTERNAL_ERROR]cancelled: tablet error: tablet writer write failed, tablet_id=24484509, txn_id=3078341, err=[E-216]try migration lock failed, host: *** |
|---|
与社区沟通后,参考官方《日志存储和分析》模块参数调优,导入任务恢复正常。
实践二:Compaction 压力过载优化
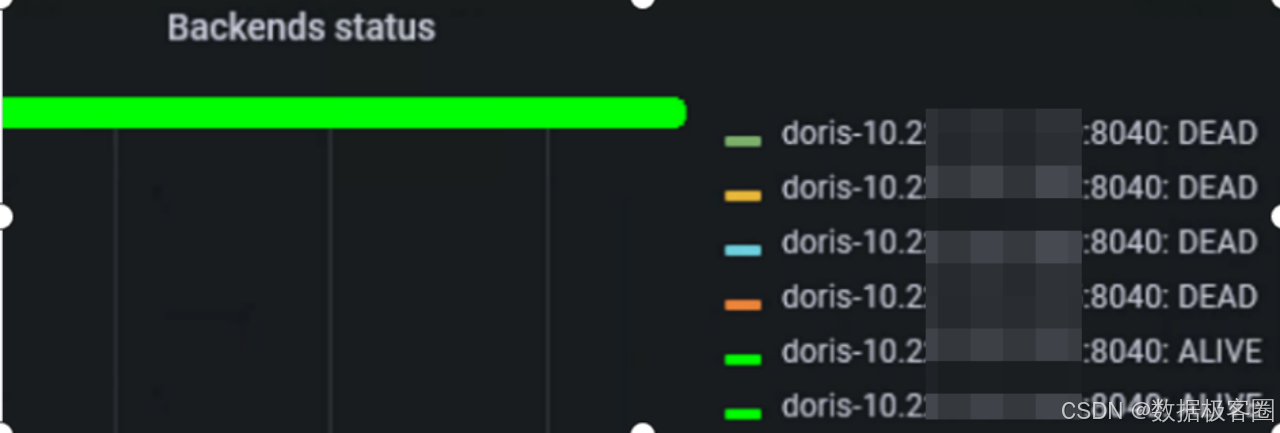
持续导入后,BE 节点异常,监控及 top -H 显示 Compaction 占用过多 CPU,导致 BE 假死。排查发现与 Bucket 数量相关:按 ClickHouse 合并后文件数量设置 Bucket 为 480,导致 Tablet 过多。
结合业务场景和高峰期数据量,将 Bucket 缩减为 280,Compaction 资源占用恢复正常,BE 节点平稳运行。
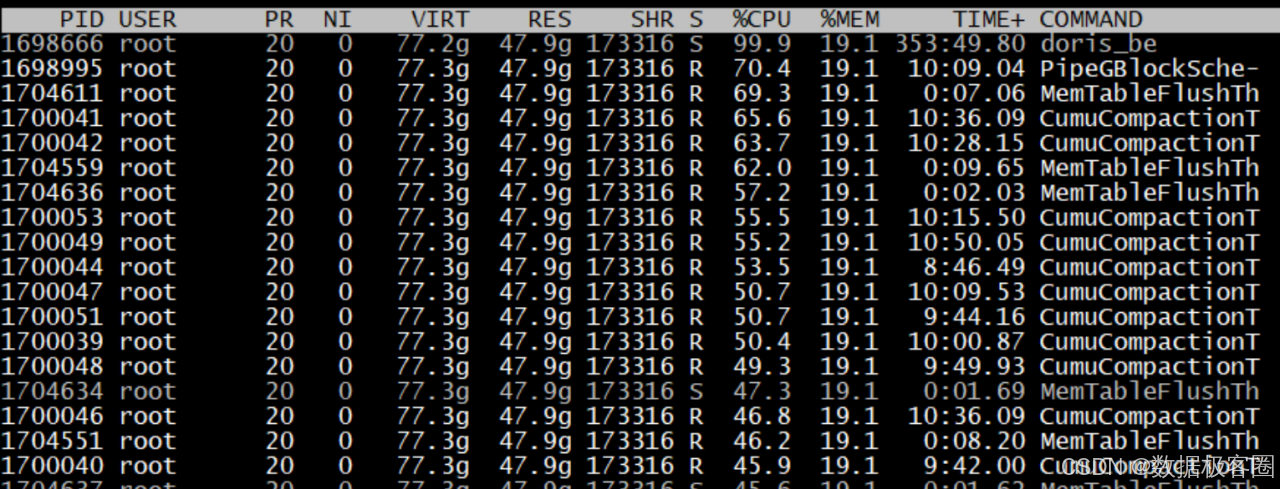
实践三:导入异常问题排查
压测中出现事务卡住,异常如下:
| Plain TexterrCode = 2, detailMessage = current running txns on db 10194 is 10000, larger than limit 10000 |
|---|
根据报错内容引导处理,我们调整了单个 DB 下的事务数量,发现不是根本原因。随后,我们将问题反馈给社区同学,在他们的协助下,很快定位到了问题根源。具体定位步骤如下:
- 找到一个具体的事务 ID

- 登录 FE 的主节点,搜索事务对应的具体 BE
grep "16788479" /opt/install/doris-2.15/fe/log/fe.log

3. 登录到具体 BE,在日志中搜索该事务 ID
grep "16788479" /opt/install/doris-2.15/be/be.INFO

排查发现,事故起因是某台机器磁盘写满,导致集群开始将该节点的写入和副本调度至其他节点,而当前写入压力较大,进而引发了事务积压。此外,由于磁盘上仍残留部分 ClickHouse 数据,进一步加剧了磁盘空间分布不均的问题。
实践四:使用 Broker Load 解放接口机
初期使用 Stream Load 导入本地文件,后发现 Broker Load 更契合业务:系统数据存储于 HDFS,Broker Load 可直接拉取,减少一次数据传输,解放接口机。需打通 Doris 与 HDFS 网络,部署 Broker,编写数据检测与提交脚本。
目前上线上百台 Broker 节点并行拉取 HDFS 数据,写入性能优异。需注意:默认子任务失败会导致整个目录导入失败,HDFS 数据按 15 分钟粒度存储,需做好失败检测与重试。
机器成本方面,ClickHouse 导入需 32 台接口机,Doris 仅需 23 台,资源节省超 28%。
架构升级成果
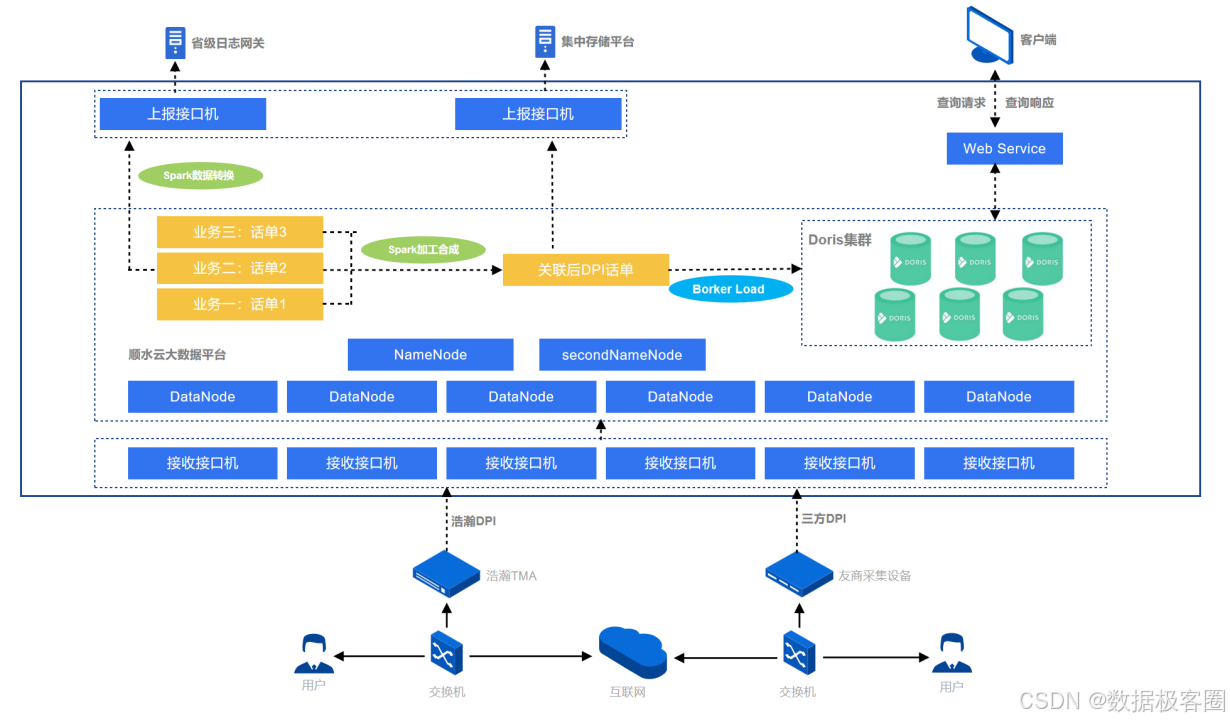
目前,浩瀚深度已在某运营商客户环境使用 Doris 替换 ClickHouse 构建了新的查询分析平台,服务器规模超百台,并实现日增数据量峰值近 158TB 的数据导入。采用双副本 + 倒排索引 + ZSTD 压缩后,存储量约 6.5PB,和原始数据相比,Doris 中单个副本的压缩率在 4 倍左右,且目前已稳定运行半年多,这次升级带来查询响应、并发能力、稳定性和运维效率等多方面的收益,成果显著。
- 显著降低硬件资源成本:利用 Doris Broker Load 高效导入机制,释放原 ClickHouse 所需的 32 台专用接口机,这些资源可灵活用于计算或存储,整体硬件成本节超 28%。采用 ZSTD 高压缩比格式,在未出现写入瓶颈的前提下,存储资源消耗相较 ClickHouse(LZ4 压缩)降低了 6%。
- 大幅提升查询效率:Doris 卓越的索引优化(前缀索引、Bloom Filter、倒排索引)及多表 JOIN 性能全面超越 ClickHouse。单 SQL 查询响应速度提升近 2 倍。批量查询任务执行效率提升近 30%。
- 有效降低运维复杂度与成本:服务器宕机或坏盘时,Doris 自动完成副本切换与写入重定向,保障服务连续性。集群扩缩容时,Doris 自动实现 Tablet 均衡分布,快速恢复集群负载均衡。通过 Doris 原生 Web UI 与 Grafana 监控,异常节点与磁盘故障可被快速定位。
未来规划
未来,浩瀚深度将从以下方面重点发展:
- 持续深化 Doris 的湖仓一体化应用:通过 Doris 的 Hive Catalog 功能整合数据仓库资源,统一数据访问接口,实现对全量数据的统一查询与分析;
- 复杂查询加速:在多维度分析、聚合计算等复杂查询场景下,依托 Doris 强大的整合能力提升查询效率,加速报表生成;
- 成本优化:利用 Doris 的冷热数据分层存储等特性,在持续优化查询性能的同时,进一步降低总体存储成本。
最后,衷心感谢飞轮科技技术团队与 Doris 社区对浩瀚深度的持续、专业的技术支持,有力推动了我们的国产化架构转型进程。 我们热忱期待更多同仁加入 Apache Doris 的应用实践与社区贡献行列,共同丰富其功能生态、扩展函数支持,助力 Apache Doris 在全球 MPP 数据库领域绽放璀璨光芒!

魔乐社区(Modelers.cn) 是一个中立、公益的人工智能社区,提供人工智能工具、模型、数据的托管、展示与应用协同服务,为人工智能开发及爱好者搭建开放的学习交流平台。社区通过理事会方式运作,由全产业链共同建设、共同运营、共同享有,推动国产AI生态繁荣发展。
更多推荐



 0
0 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)