Java数据结构详解:从基础到高级应用
一、数据结构概述
数据结构是计算机存储、组织数据的方式,直接影响程序性能。Java通过集合框架(java.util)提供了高效实现:
![]()
二、线性数据结构详解
1. 数组(Array)
特点:连续内存、固定大小、随机访问O(1)
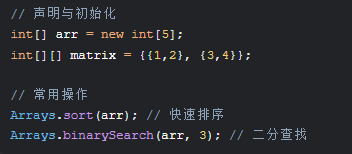
应用场景:高频随机访问(如图像处理像素矩阵)
2. 链表(LinkedList)
特点:非连续内存、动态扩容、插入删除O(1)
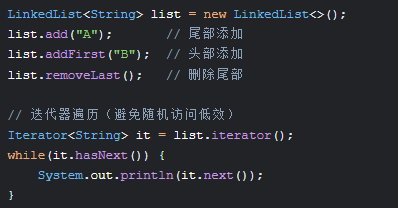
源码关键:Node<E>类含item, next, prev指针
应用场景:LRU缓存、浏览器历史记录
3. 栈(Stack)
特点:LIFO(后进先出)
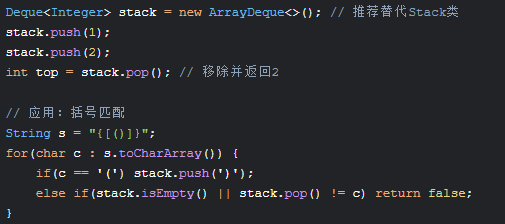
4. 队列(Queue)
类型:
-
普通队列:
LinkedList -
优先队列:
PriorityQueue(最小堆实现) -
双端队列:
ArrayDeque

三、树形数据结构
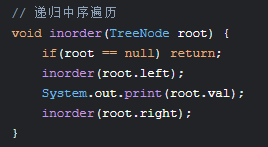
1. 二叉树(Binary Tree)
遍历方式:
-
前序:根→左→右
-
中序:左→根→右(二叉搜索树有序)
-
后序:左→右→根
2. 红黑树(TreeMap/TreeSet)
特性:自平衡二叉搜索树,保证增删查O(log n)
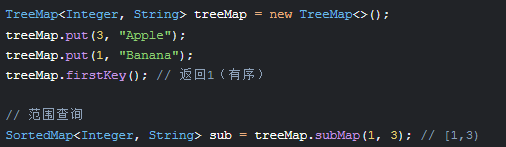
应用场景:需要有序键值的场景(如排行榜)
四、哈希表(HashMap/HashSet)
原理:数组+链表/红黑树(JDK8优化)
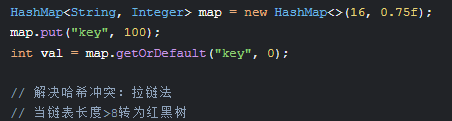
重要方法:
-
hash(key):高16位异或降低碰撞 -
resize():2倍扩容并重哈希
应用场景:缓存系统(Redis底层)、快速查找
五、图(Graph)
表示方式:
-
邻接矩阵:二维数组
-
邻接表:数组+链表
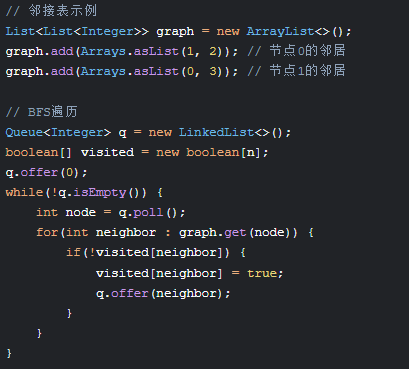
应用场景:社交网络、路径规划(Dijkstra算法)
六、高级数据结构
| 数据结构 | 实现类 | 时间复杂度 | 适用场景 |
|---|---|---|---|
| 跳表(SkipList) | ConcurrentSkipListMap |
O(log n) | 高并发有序数据 |
| 并查集(Union-Find) | 自定义 | O(α(n)) | 连通性问题(朋友圈分组) |
| Trie树 | 自定义 | O(L) | 前缀匹配(自动补全) |
七、实战:选择最佳数据结构
-
高频查询 →
HashMap -
有序数据 →
TreeMap -
线程安全 →
ConcurrentHashMap -
生产者消费者 →
BlockingQueue -
前缀搜索 →
Trie
性能黄金法则:
读多写少 → 红黑树(TreeMap)
写多读少 → 哈希表(HashMap)
小编建议掌握数据结构核心在于:
-
理解底层实现(如HashMap的桶结构)
-
分析时间复杂度(选择最优操作)
-
结合实际场景(如并发环境选线程安全类)
-
利用工具类(
Collections.synchronizedMap()包装同步)
通过合理选择数据结构,可提升程序性能10倍以上!建议结合源码调试(如HashMap.resize())加深理解。

魔乐社区(Modelers.cn) 是一个中立、公益的人工智能社区,提供人工智能工具、模型、数据的托管、展示与应用协同服务,为人工智能开发及爱好者搭建开放的学习交流平台。社区通过理事会方式运作,由全产业链共同建设、共同运营、共同享有,推动国产AI生态繁荣发展。
更多推荐


 8
8 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)