人工神经网络基本原理
最近谷歌升级版AlphaGo打败众多国内外围棋高手,那狗又火了一把,再次引起大家的关注。作为一个对技术有追求的人,嗯,是时候好好学习当前最火的人工智能与机器学习的相关技术了。学习一项技术,仅仅了解其技术原理是远远不够的,从技术实践中建立感性认识,才能对技术原理有深入的理解。因此,本文先介绍神经网络基本原理,后面系列文章将详细介绍神经网络的成熟算法及网络结构(比如:BP神经网络、RBF、CNN等)并
转载请注明出处:http://blog.csdn.net/tyhj_sf/article/details/54134210
声明:
(1)该博文为个人学习总结,部分内容(包括数学公式)是来自书籍及网上的资料。具体引用的资料请看参考文献。具体的版本声明也参考原文献。
(2)本文仅供学术交流,非商用。所以每一部分具体的参考资料并没有详细对应,更有些部分本来就是直接从其他博客复制过来的。如果某部分不小心侵犯了大家的版权,还望海涵,并联系本人删除或修改。
引言
最近谷歌升级版AlphaGo打败众多国内外围棋高手,那狗又火了一把,再次引起大家的关注。作为一个对技术有追求的人,嗯,是时候好好学习当前最火的人工智能与机器学习的相关技术了。学习一项技术,仅仅了解其技术原理是远远不够的,从技术实践中建立感性认识,才能对技术原理有深入的理解。因此,本文先介绍神经网络基本原理,后面系列文章将详细介绍神经网络的成熟算法及网络结构(比如:BP神经网络、RBF、CNN等)并编程实现之。
神经元模型
以监督学习为例,假设我们有训练样本集 (x(i),y(i) <script type="math/tex" id="MathJax-Element-1">(x^{(i)},y^{(i)}</script>) ,那么神经网络算法能够提供一种复杂且非线性的假设模型 hW,b(x) <script type="math/tex" id="MathJax-Element-2"> h_{W,b}(x)</script>,它具有参数 W,b <script type="math/tex" id="MathJax-Element-3">W, b</script>,可以以此参数来拟合我们的数据。
为了描述神经网络,我们先从最简单的神经网络讲起,这个神经网络仅由一个“神经元”构成,以下即是这个“神经元”的图示
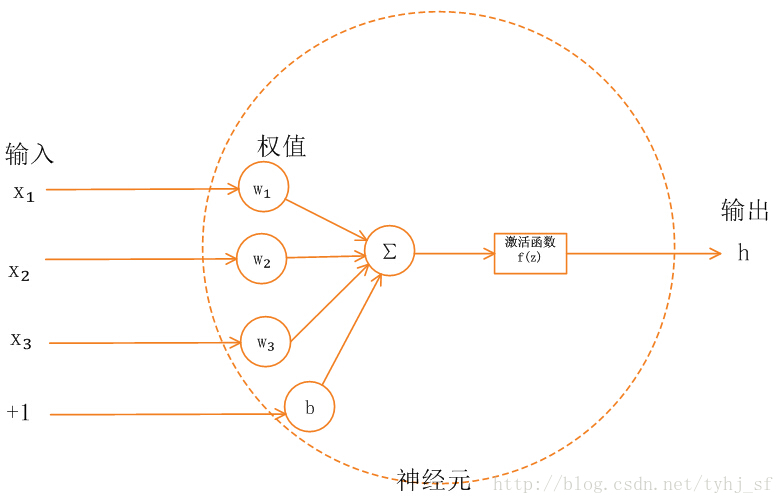
后文我们会介绍有多个神经元的神经网络,因此单个神经元模型我们后面会简化成如下图:
这个“神经元”是一个以 x1,x2,x3 <script type="math/tex" id="MathJax-Element-4"> x_1, x_2, x_3</script> 及截距 +1 <script type="math/tex" id="MathJax-Element-5">+1</script> 为输入值的运算单元,其输出为 hW,b(x)=f(WTx)=f(∑3i=1Wixi+b) <script type="math/tex" id="MathJax-Element-6">h_{W,b}(x) = f(W^Tx) = f(\sum_{i=1}^3 W_{i}x_i +b)</script> ,其中函数 f:R↦R <script type="math/tex" id="MathJax-Element-7"> f : \Re \mapsto \Re</script>被称为“激活函数”。在本教程中,我们选用sigmoid函数作为”激活函数” f(⋅) <script type="math/tex" id="MathJax-Element-8"> f(\cdot)</script>
sigmoid函数:
sigmoid函数图像如下:
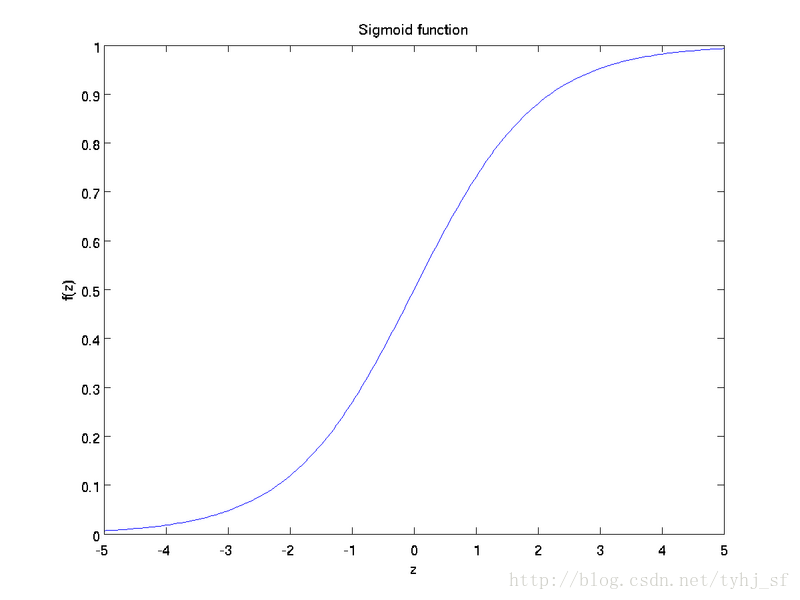
可以看出,这个单一“神经元”的输入-输出映射关系其实就是一个逻辑回归(logistic regression)。
虽然本系列教程采用sigmoid函数,但你也可以选择双曲正切函数(tanh).
tanh函数:
tanh函数的图像如下:
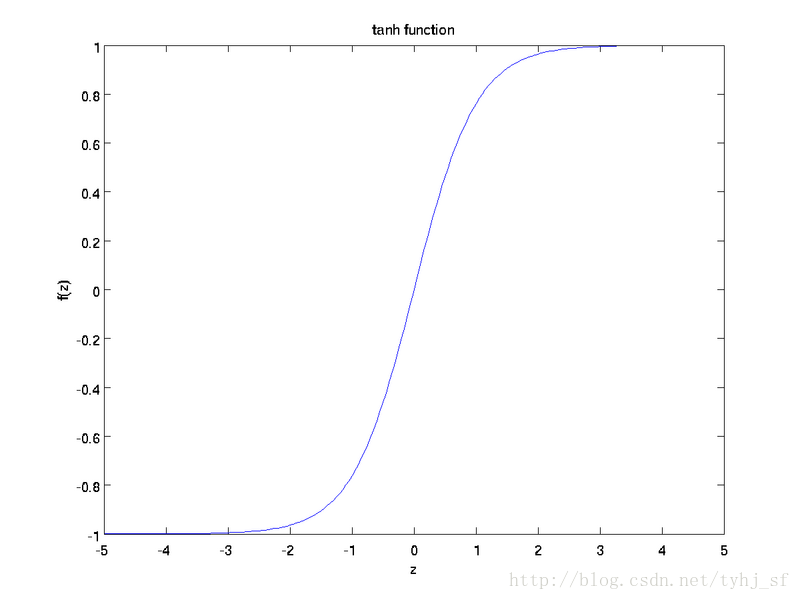
tanh(z) <script type="math/tex" id="MathJax-Element-11"> \tanh(z) </script> 函数是sigmoid函数的一种变体,它的取值范围为 [−1,1] <script type="math/tex" id="MathJax-Element-12"> [-1,1]</script> ,而不是sigmoid函数的 [0,1] <script type="math/tex" id="MathJax-Element-13"> [0,1]</script>。
注意,这里我们不再令 x0=1 <script type="math/tex" id="MathJax-Element-14"> x_0=1</script> 。取而代之,我们用单独的参数 b <script type="math/tex" id="MathJax-Element-15"> b</script> 来表示截距。
最后要说明的是,有一个等式我们以后会经常用到:如果选择
神经网络模型
所谓神经网络就是将许多个单一“神经元”联结在一起,这样,一个“神经元”的输出就可以是另一个“神经元”的输入。例如,下图就是一个简单的神经网络: 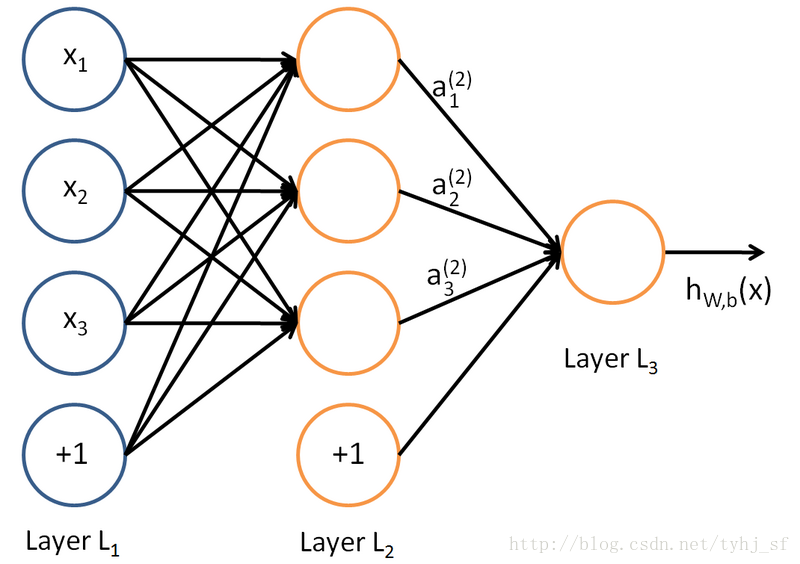
我们使用蓝色圆圈来表示神经网络的输入,标上“ +1 <script type="math/tex" id="MathJax-Element-137"> +1</script>”的圆圈被称为”’偏置节点”’,也就是截距项。神经网络最左边的一层叫做”’输入层”’,最右的一层叫做”’输出层”’(本例中,输出层只有一个节点)。中间所有节点组成的一层叫做”’隐藏层”’,因为我们不能在训练样本集中观测到它们的值。同时可以看到,以上神经网络的例子中有3个”’输入单元”’(偏置单元不计在内),3个”’隐藏单元”’及一个”’输出单元”’。
本例约定:
(1)我们用 nl <script type="math/tex" id="MathJax-Element-138"> {n}_l </script> 来表示网络的层数,本例中 nl=3 <script type="math/tex" id="MathJax-Element-139"> n_l=3</script> 。
(2)我们将第 l <script type="math/tex" id="MathJax-Element-140"> l</script> 层记为
(3)本例神经网络有参数 (W,b)=(W(1),b(1),W(2),b(2)) <script type="math/tex" id="MathJax-Element-144"> (W,b) = (W^{(1)}, b^{(1)}, W^{(2)}, b^{(2)})</script>,其中 W(l)ij <script type="math/tex" id="MathJax-Element-145"> W^{(l)}_{ij}</script>(下面的式子中用到)是第 l <script type="math/tex" id="MathJax-Element-146"> l</script>层第
(4)我们用
(5)我们用 z(l)i <script type="math/tex" id="MathJax-Element-168"> z^{(l)}_i</script> 表示第 l <script type="math/tex" id="MathJax-Element-169"> l</script> 层第
这样我们就可以得到一种更简洁的表示法。这里我们将激活函数 f(⋅) <script type="math/tex" id="MathJax-Element-173"> f(\cdot)</script> 扩展为用向量(分量的形式)来表示,即 f([z1,z2,z3])=[f(z1),f(z2),f(z3)] <script type="math/tex" id="MathJax-Element-174"> f([z_1, z_2, z_3]) = [f(z_1), f(z_2), f(z_3)]</script> ,那么,上面的等式可以更简洁地表示为:
我们将上面的计算步骤叫作”前向传播(forward propagation)”。回想一下,之前我们用 a(1)=x <script type="math/tex" id="MathJax-Element-176"> a^{(1)} = x</script> 表示输入层的激活值,那么给定第 l <script type="math/tex" id="MathJax-Element-177"> l</script> 层的激活值
:
将参数矩阵化,使用矩阵-向量运算方式,我们就可以利用线性代数的优势对神经网络进行快速求解。
目前为止,我们讨论了一种神经网络,我们也可以构建另一种”结构”的神经网络(这里结构指的是神经元之间的联接模式),也就是包含多个隐藏层的神经网络。最常见的一个例子是 nl <script type="math/tex" id="MathJax-Element-182"> n_l</script> 层的神经网络,第 1 <script type="math/tex" id="MathJax-Element-183"> 1</script> 层是输入层,第
复杂一点儿的神经网络也可以有多层隐藏层和多个输出单元。比如,下面的神经网络有两层隐藏层: L2 <script type="math/tex" id="MathJax-Element-190"> L_2</script> 及 L3 <script type="math/tex" id="MathJax-Element-191"> L_3</script> ,输出层 L4 <script type="math/tex" id="MathJax-Element-192"> L_4</script> 有两个输出单元。
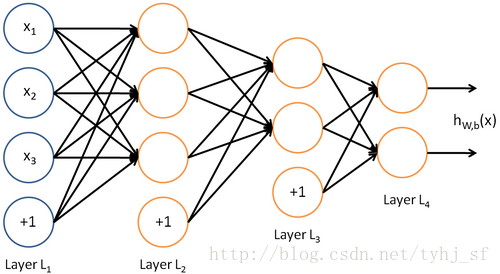
要求解这样的神经网络,需要样本集 (x(i),y(i)) <script type="math/tex" id="MathJax-Element-193"> (x^{(i)}, y^{(i)})</script> ,其中 y(i)∈R2 <script type="math/tex" id="MathJax-Element-194"> y^{(i)} \in \Re^2</script> 。如果你想预测的输出是多个的,那这种神经网络很适用。(比如,在医疗诊断应用中,患者的体征指标就可以作为向量的输入值,而不同的输出值 yi <script type="math/tex" id="MathJax-Element-195"> y_i</script> 可以表示不同的疾病存在与否。)
题外话,数学公式的编辑真是个非常坑爹的事情……….
参考资料:
(1)《人工智能:一种现代的方法》第二版.
(2)UFLDL.

魔乐社区(Modelers.cn) 是一个中立、公益的人工智能社区,提供人工智能工具、模型、数据的托管、展示与应用协同服务,为人工智能开发及爱好者搭建开放的学习交流平台。社区通过理事会方式运作,由全产业链共同建设、共同运营、共同享有,推动国产AI生态繁荣发展。
更多推荐



 113
113 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)