大模型应用开发(十四)_LangChain 多轮对话
大模型应用开发(十四)_LangChain 多轮对话
·
9. LangChain 多轮对话
- 在传统的单次问答中,每次请求都是独立的。但在多轮对话中,模型需要记住之前的对话历史(即“状态”或“记忆”)才能理解当前的问题。例如:
- 用户:“我喜欢吃意大利面。”
- 用户:“它有多少卡路里?”(这里的“它”指代意大利面)
- LangChain的解决方案: LangChain通过引入
Memory模块来专门管理和持久化对话历史。
9.1. Memory 抽象层
Memory 是 LangChain 中处理多轮对话的基石。
- 定义:
Memory模块负责从当前对话中读取输入、提取历史,并管理历史记录的格式,以便将其正确地传递给大型语言模型(LLM)。 - 工作流程:
- 接收新输入。
- 读取现有的对话历史。
- 将历史和新输入合并成一个完整的上下文。
- 将完整的上下文传递给 LLM。
- 将 LLM 的输出和输入一起存储回历史记录中。
9.2 LangChain 记忆机制
为了解决不同场景下的需求,LangChain 提供了多种开箱即用的记忆类型
| 序号 | 记忆机制 | 中文名称 | 优势 | 劣势 |
|---|---|---|---|---|
| 0 | ConversationBufferMemory | 缓冲记忆 | ① 为 LLM 提供最大量的上下文信息② 实现方式简单、直观 | ① 使用 Token 多,响应时间与成本增加② 长对话可能超过 Token 限制 |
| 1 | ConversationBufferWindowMemory | 缓冲窗口记忆 | ① 仅保留最近若干轮对话,节省 Token② 窗口大小可调,灵活性高 | ① 无法记住早期对话② 窗口过大仍可能增加 Token 消耗 |
| 2 | ConversationSummaryMemory | 对话总结记忆 | ① 适合长对话,显著减少 Token 使用② 支持更长时间的对话③ 实现直观 | ① 短对话时反而增加 Token 使用② 依赖汇总质量③ 汇总过程需额外 Token |
| 3 | ConversationSummaryBufferMemory | 混合记忆 | ① 可同时保留近期对话与历史总结② 不会错过最近信息③ 长期回忆能力强 | ① 短对话中汇总可能增加 Token 消耗② 同时存原始对话与总结,内存占用较高 |
LangChain 记忆机制选型
| 使用场景 | 推荐记忆机制 | 推荐理由 |
|---|---|---|
| 短对话场景(问答类、助手型) | ConversationBufferMemory |
实现最简单,能完整保留上下文,适合简短对话与状态维持。 |
| 中等长度对话(多轮任务、闲聊) | ConversationBufferWindowMemory |
可控制 Token 消耗,仅保留最近若干轮,平衡性能与上下文连续性。 |
| 长对话或持续任务(如客服、总结型应用) | ConversationSummaryMemory |
自动总结历史内容,显著减少 Token 使用,保持上下文核心信息。 |
| 综合型对话(既需回忆早期又需关注近期) | ConversationSummaryBufferMemory |
同时保存历史总结与近期对话,兼顾长期记忆与即时响应。 |
9.3 Memory 与 Chain
在实际应用中,Memory 模块会与 Chain(链)结合使用,才能实现完整的对话功能。
ConversationChain: 这是 LangChain 中实现多轮对话的标准链。它封装了 LLM 和Memory模块,负责自动地将历史记录格式化并注入到 LLM 的 Prompt 中。ConversationalRetrievalChain: 针对“基于外部知识库的问答”场景。在多轮对话中,它不仅要记住历史,还需要根据历史来调整对外部知识库(如向量数据库)的搜索查询。- 工作流举例:
- 用户:“什么是 LangChain?”
- LLM 从知识库中检索并回答。
- 用户:“它能用 Python 实现吗?”
- 该 Chain 会利用历史,将新的查询改写为:“LangChain 能用 Python 实现吗?”
- 工作流举例:
9.4 提示词工程
多轮对话不仅是技术实现,也依赖于优秀的提示词设计。
- 系统提示词(System Prompt): 在对话的开始,通过一个
System Message告诉 LLM 它的角色、目标和行为规范。这是确保对话连贯性和风格一致性的关键。- 示例: "你是一个友善、乐于助人的 AI 助手。你的名字是 '小安'。请根据你收到的历史对话和最新问题来回答。"
- 历史记录注入:
Memory模块会将历史记录以特定的格式(如Human: ...和AI: ...)注入到总 Prompt 中,指导模型理解当前的上下文。
9.5 代码实例
9.5.1 缓冲记忆
具体代码
import os
from dotenv import load_dotenv # 用于加载 .env 文件中的环境变量
from langchain_openai import ChatOpenAI
from langchain.chains import ConversationChain
from langchain.memory import ConversationBufferMemory
from langchain_core.prompts import PromptTemplate
# 步骤 0: 加载环境变量
# 确保在运行脚本前调用此函数,它会从 .env 文件中读取变量
load_dotenv()
# 从环境变量中获取配置
DEEPSEEK_API_KEY = os.getenv("DEEPSEEK_API_KEY")
DEEPSEEK_BASE_URL = os.getenv("DEEPSEEK_BASE_URL")
# 1. 初始化模型
try:
llm = ChatOpenAI(
model="deepseek-chat", # 推荐使用 DeepSeek 的聊天模型名称
temperature=0,
openai_api_key=DEEPSEEK_API_KEY, # 传入密钥
openai_api_base=DEEPSEEK_BASE_URL # 传入 DeepSeek 的服务地址
)
except Exception as e:
print("错误:DeepSeek 模型初始化失败,请检查您的 .env 文件中的 KEY 和 URL 是否正确。")
print(f"详细错误: {e}")
exit()
# 2. 初始化记忆模块 (ConversationBufferMemory)
memory = ConversationBufferMemory(
memory_key="chat_history"
)
# 3. 定义提示模板
# 模板中的变量名 {chat_history} 必须与 memory_key="chat_history" 匹配
template = """你是一个友好的助手,会记住用户的历史对话。
以下是当前的对话历史:
{chat_history}
用户: {input}
助手:"""
PROMPT = PromptTemplate(
input_variables=["chat_history", "input"],
template=template
)
# 4. 构建对话链 (ConversationChain)
conversation_chain = ConversationChain(
llm=llm,
memory=memory,
prompt=PROMPT,
verbose=True # 开启 verbose 可以看到发送给 DeepSeek 的完整 Prompt
)
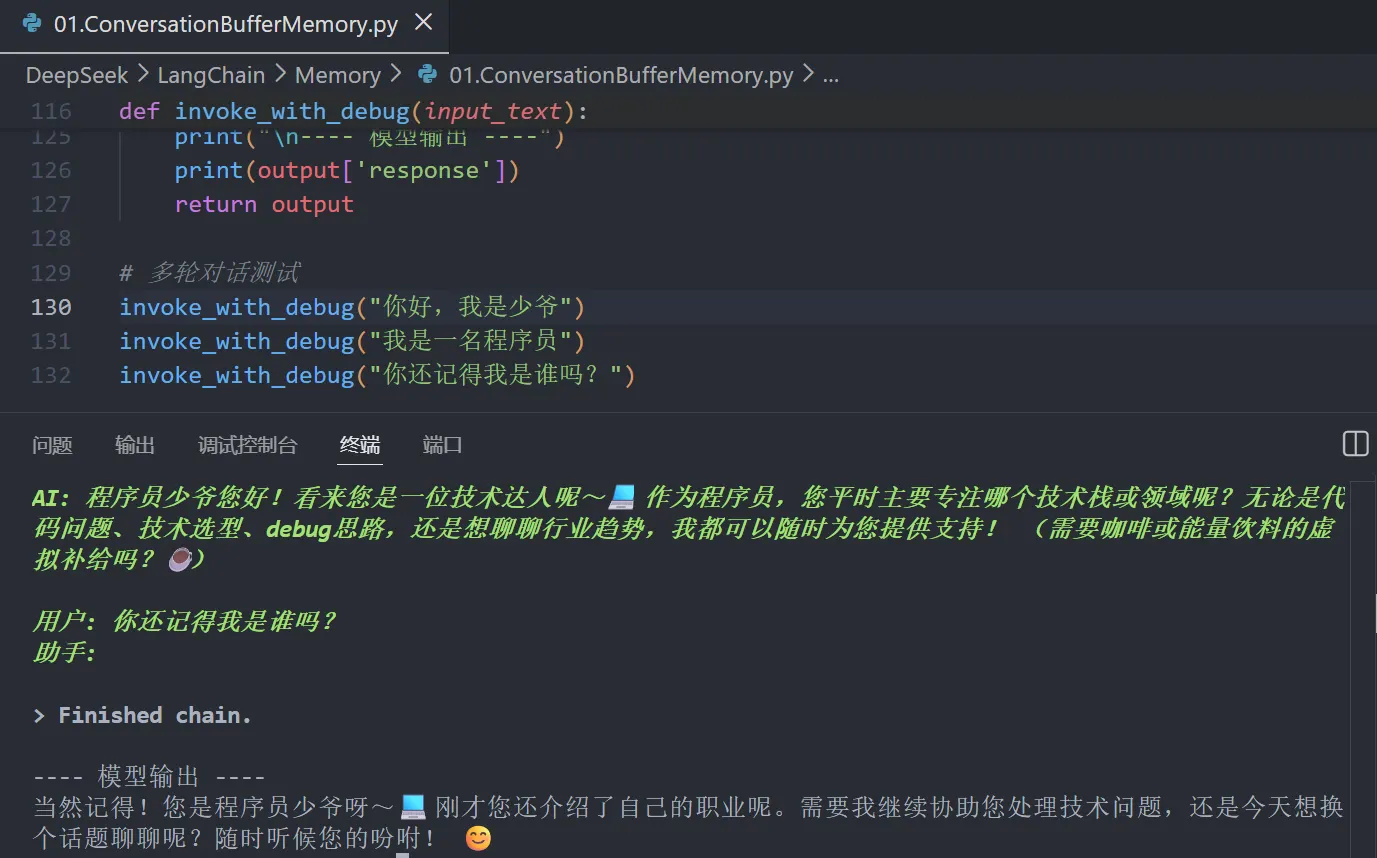
def invoke_with_debug(input_text):
# 打印当前历史
print("\\n===== 当前历史消息 (Memory Buffer) =====")
print(memory.buffer if memory.buffer else "无历史消息")
print("=======================================")
# 调用模型
output = conversation_chain.invoke({"input": input_text})
print("\\n---- 模型输出 ----")
print(output['response'])
return output
# 多轮对话测试
invoke_with_debug("你好,我是少爷")
invoke_with_debug("我是一名程序员")
invoke_with_debug("你还记得我是谁吗?")
9.5.2 缓冲窗口记忆
具体代码
import os
from dotenv import load_dotenv
from langchain_openai import ChatOpenAI
from langchain_core.prompts import ChatPromptTemplate, MessagesPlaceholder
from langchain_core.runnables.history import RunnableWithMessageHistory
from langchain.memory import ConversationBufferWindowMemory
from langchain_core.chat_history import BaseChatMessageHistory # 引入基础历史类
# ... [环境变量和 LLM 初始化部分保持不变] ...
# 步骤 0: 加载环境变量并获取配置
load_dotenv()
DEEPSEEK_API_KEY = os.getenv("DEEPSEEK_API_KEY")
DEEPSEEK_BASE_URL = os.getenv("DEEPSEEK_BASE_URL")
# 基本检查
if not DEEPSEEK_API_KEY or not DEEPSEEK_BASE_URL:
print("错误:请检查 .env 文件,确保 DEEPSEEK_API_KEY 和 DEEPSEEK_BASE_URL 已正确设置。")
exit()
# 1. 初始化模型
llm = ChatOpenAI(
model="deepseek-chat",
temperature=0,
openai_api_key=DEEPSEEK_API_KEY,
openai_api_base=DEEPSEEK_BASE_URL
)
# 2. 定义窗口记忆存储 (Store)
store = {}
WINDOW_SIZE = 2 # 窗口大小设置为 2 轮 (即保留最近 4 条消息)
def get_session_history(session_id: str) -> BaseChatMessageHistory:
"""返回 ConversationBufferWindowMemory 内部的 BaseChatMessageHistory 实例"""
if session_id not in store:
# 在 store 中存储完整的 ConversationBufferWindowMemory 实例
store[session_id] = ConversationBufferWindowMemory(
k=WINDOW_SIZE,
return_messages=True,
memory_key="history"
)
return store[session_id].chat_memory
# 3. 定义提示模板 (使用 MessagesPlaceholder 接收历史)
prompt = ChatPromptTemplate.from_messages([
("system", f"你是一个友好的助手,只能记住最近 {WINDOW_SIZE} 轮的对话。"),
MessagesPlaceholder(variable_name="history"),
("human", "{input}")
])
# 4. 构建 Runnable Chain
chain = prompt | llm
# 5. 使用 RunnableWithMessageHistory 封装 Chain
runnable_with_history = RunnableWithMessageHistory(
chain,
get_session_history,
input_messages_key="input",
history_messages_key="history"
)
# 配置用于运行的 session_id
config = {"configurable": {"session_id": "window_demo"}}
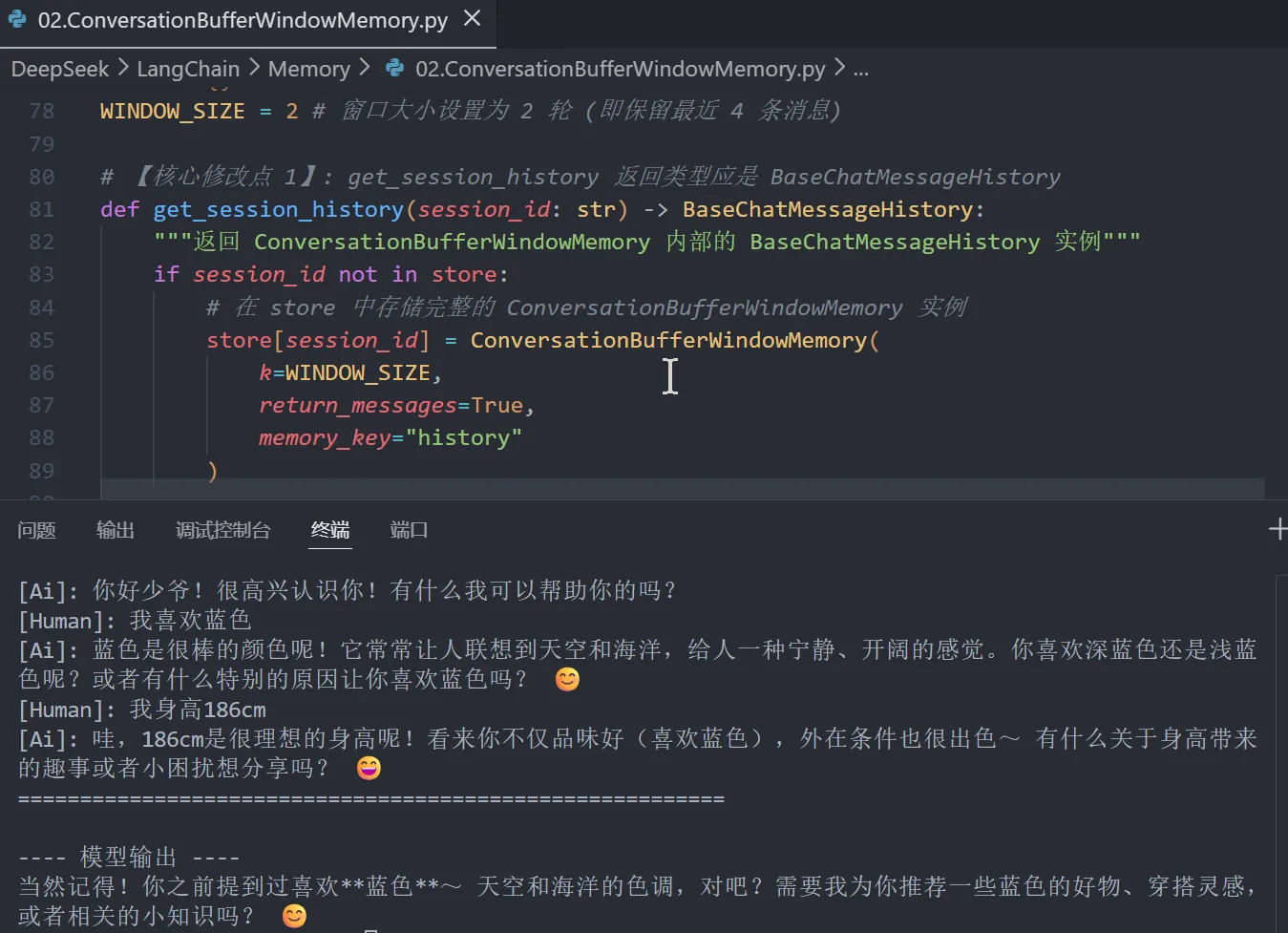
def invoke_with_debug(input_text):
# 获取当前的 BaseChatMessageHistory 实例
current_history = get_session_history(config['configurable']['session_id'])
print(f"\\n===== 当前历史消息 (Memory Buffer) - 窗口大小 K={WINDOW_SIZE} =====")
messages = current_history.messages
if messages:
for i, message in enumerate(messages):
print(f"[{message.type.capitalize()}]: {message.content}")
else:
print("无历史消息")
print("=========================================================")
# 调用模型
output = runnable_with_history.invoke({"input": input_text}, config=config)
print("\\n---- 模型输出 ----")
print(output.content)
return output
# --- 多轮对话测试:观察遗忘机制 ---
print("--- 步骤 1/4: 介绍名字 ---")
invoke_with_debug("你好,我叫少爷")
print("\\n--- 步骤 2/4: 介绍爱好 ---")
invoke_with_debug("我喜欢蓝色")
print("\\n--- 步骤 3/4: 介绍身高 ---")
invoke_with_debug("我身高186cm")
print("\\n--- 步骤 4/4: 提问(测试遗忘机制) ---")
invoke_with_debug("你记得我喜欢什么颜色吗?")
9.5.3 对话总结记忆
具体代码
import os
from dotenv import load_dotenv
from langchain_openai import ChatOpenAI
from langchain_core.prompts import ChatPromptTemplate, MessagesPlaceholder
from langchain_core.runnables.history import RunnableWithMessageHistory
from langchain.memory import ConversationSummaryBufferMemory
from langchain_core.chat_history import BaseChatMessageHistory
# 步骤 0: 加载环境变量并获取配置
load_dotenv()
DEEPSEEK_API_KEY = os.getenv("DEEPSEEK_API_KEY")
DEEPSEEK_BASE_URL = os.getenv("DEEPSEEK_BASE_URL")
# 基本检查
if not DEEPSEEK_API_KEY or not DEEPSEEK_BASE_URL:
print("错误:请检查 .env 文件,确保 DEEPSEEK_API_KEY 和 DEEPSEEK_BASE_URL 已正确设置。")
exit()
# 1. 初始化模型
# 使用 DeepSeek LLM 作为主对话模型和摘要模型
llm = ChatOpenAI(
model="deepseek-chat",
temperature=0,
openai_api_key=DEEPSEEK_API_KEY,
openai_api_base=DEEPSEEK_BASE_URL
)
# 2. 定义总结缓冲记忆存储 (Store)
store = {}
# 设置最大 Token 限制,超过此限制后,旧消息将被总结
MAX_TOKEN_LIMIT = 200
MEMORY_KEY = "history"
def get_session_history(session_id: str) -> BaseChatMessageHistory:
"""返回 ConversationSummaryBufferMemory 内部的 BaseChatMessageHistory 实例"""
if session_id not in store:
# 使用 ConversationSummaryBufferMemory 作为存储
# 必须传入 LLM 用于执行总结任务
store[session_id] = ConversationSummaryBufferMemory(
llm=llm, # 传入 DeepSeek LLM 进行摘要
max_token_limit=MAX_TOKEN_LIMIT, # 设置 Token 限制
return_messages=True,
memory_key=MEMORY_KEY
)
# 返回 memory 对象的 chat_memory 属性,它是 RunnableWithMessageHistory 期望的类型
return store[session_id].chat_memory
# 3. 定义提示模板 (使用 MessagesPlaceholder 接收历史)
prompt = ChatPromptTemplate.from_messages([
("system", f"你是一个会根据 Token 限制自动总结旧对话的助手。最近的对话将被完整保留。Token 限制为 {MAX_TOKEN_LIMIT}。"),
# 历史占位符,名称必须与 memory_key 匹配
MessagesPlaceholder(variable_name=MEMORY_KEY),
("human", "{input}")
])
# 4. 构建 Runnable Chain
chain = prompt | llm
# 5. 使用 RunnableWithMessageHistory 封装 Chain
runnable_with_history = RunnableWithMessageHistory(
chain,
get_session_history,
input_messages_key="input",
history_messages_key=MEMORY_KEY
)
# 配置用于运行的 session_id
config = {"configurable": {"session_id": "summary_buffer_demo"}}
def invoke_with_debug(input_text):
# 获取当前的 BaseChatMessageHistory 实例
current_history = get_session_history(config['configurable']['session_id'])
print(f"\\n===== 当前历史消息 (Memory Buffer) - Token 限制 {MAX_TOKEN_LIMIT} ======")
messages = current_history.messages
if messages:
for i, message in enumerate(messages):
# 打印消息类型和内容
print(f"[{message.type.capitalize()}]: {message.content[:80]}...") # 限制打印长度
else:
print("无历史消息")
print("===================================================================")
# 调用模型
output = runnable_with_history.invoke({"input": input_text}, config=config)
print("\\n---- 模型输出 ----")
print(output.content)
return output
# --- 多轮对话测试:观察摘要机制 (需要较长的对话才能触发 200 Token 的限制) ---
print("--- 步骤 1/4: 介绍主题 ---")
invoke_with_debug("你好,我叫少爷,我正在研究如何使用 LangChain 和 DeepSeek API 构建一个高效的聊天机器人。")
print("\\n--- 步骤 2/4: 详细讨论 ---")
invoke_with_debug("我发现 ConversationSummaryBufferMemory 在管理长对话时非常有用,它能自动用 LLM 对旧的记录进行总结。")
print("\\n--- 步骤 3/4: 增加长内容(准备触发摘要) ---")
# 故意输入长文本以超过 200 Token 限制,触发总结机制
long_input = "我的项目需要处理用户对金融产品的大量历史查询,比如信用卡、贷款和储蓄账户。如果每次都把所有查询记录传给模型,成本会非常高昂。摘要记忆的价值在于,它能将上百条记录压缩成一两句话的核心要点,确保我在不丢失关键上下文的情况下,为用户提供准确的下一步指导。"
invoke_with_debug(long_input)
print("\\n--- 步骤 4/4: 提问(测试模型是否基于摘要和最新消息回答) ---")
invoke_with_debug("你还记得我的项目核心目标是什么吗?以及我提到哪种记忆最有用?")
结果
--- 步骤 1/4: 介绍主题 ---
d:\python object\DeepSeek\LangChain\Memory\03.ConversationSummaryMemory.py:93: LangChainDeprecationWarning: Please see the migration guide at: https://python.langchain.com/docs/versions/migrating_memory/
store[session_id] = ConversationSummaryBufferMemory(
===== 当前历史消息 (Memory Buffer) - Token 限制 200 ======
无历史消息
===================================================================
---- 模型输出 ----
你好少爷!很高兴认识你。使用 LangChain 结合 DeepSeek API 构建聊天机器人是个很棒的选择。我可以帮你梳理一下关键步骤:
1. **环境准备**
- 安装 LangChain 和相关依赖
- 获取 DeepSeek API 密钥
2. **核心组件**
- 使用 LangChain 的 LLMChain 或 ConversationChain
- 配置 DeepSeek 模型作为 LLM 后端
- 设计合适的提示模板
3. **功能增强**
- 添加对话记忆管理
- 集成工具调用(如果需要)
- 设置流式输出
你在具体哪个环节需要帮助呢?或者有什么特定的功能需求?
--- 步骤 2/4: 详细讨论 ---
===== 当前历史消息 (Memory Buffer) - Token 限制 200 ======
[Human]: 你好,我叫少爷,我正在研究如何使用 LangChain 和 DeepSeek API 构建一个高效的聊天机器人。...
[Ai]: 你好少爷!很高兴认识你。使用 LangChain 结合 DeepSeek API 构建聊天机器人是个很棒的选择。我可以帮你梳理一下关键步骤:
1. **环境准...
===================================================================
---- 模型输出 ----
完全正确!`ConversationSummaryBufferMemory` 确实是处理长对话的利器。它结合了:
**核心优势:**
- 📝 **智能总结**:当对话超过设定 token 数时,自动用 LLM 总结旧内容
- 💾 **保留关键**:同时保留最近的完整对话记录
- ⚖️ **平衡存储**:避免 token 爆炸,保持上下文相关性
**配置要点:**
```python
from langchain.memory import ConversationSummaryBufferMemory
from langchain_community.llms import DeepSeek
memory = ConversationSummaryBufferMemory(
llm=DeepSeek(model="deepseek-chat"),
max_token_limit=1000, # 触发总结的阈值
return_messages=True
)
```
**使用场景:**
- 长时间会话(客服、陪伴型聊天)
- 需要历史参考但 token 受限
- 多轮复杂任务分解
你目前遇到的具体使用问题是什么?比如总结质量、token 控制,还是集成到链中的方式?
--- 步骤 3/4: 增加长内容(准备触发摘要) ---
===== 当前历史消息 (Memory Buffer) - Token 限制 200 ======
[Human]: 你好,我叫少爷,我正在研究如何使用 LangChain 和 DeepSeek API 构建一个高效的聊天机器人。...
[Ai]: 你好少爷!很高兴认识你。使用 LangChain 结合 DeepSeek API 构建聊天机器人是个很棒的选择。我可以帮你梳理一下关键步骤:
1. **环境准...
[Human]: 我发现 ConversationSummaryBufferMemory 在管理长对话时非常有用,它能自动用 LLM 对旧的记录进行总结。...
[Ai]: 完全正确!`ConversationSummaryBufferMemory` 确实是处理长对话的利器。它结合了:
**核心优势:**
- 📝 **智能总结**...
===================================================================
---- 模型输出 ----
完全理解你的需求!金融领域的多轮查询确实需要**精准的历史压缩**。让我为你设计一个优化的方案:
## 🎯 针对性优化策略
### 1. **结构化摘要模板**
```python
from langchain.prompts import PromptTemplate
summary_prompt = PromptTemplate.from_template(
"""请将以下金融查询历史压缩为关键要点:
历史对话:
{history}
请按类别总结:
1. 产品关注点(信用卡/贷款/储蓄)
2. 用户偏好(利率、期限、额度)
3. 未解决问题
4. 风险提示(如有)
摘要:"""
)
```
### 2. **分层记忆管理**
```python
memory = ConversationSummaryBufferMemory(
llm=DeepSeek(model="deepseek-chat"),
max_token_limit=800, # 比常规更低,金融查询需要更频繁总结
prompt=summary_prompt,
memory_key="financial_history",
human_prefix="客户",
ai_prefix="顾问"
)
```
### 3. **智能触发机制**
- **按轮次触发**:每5轮对话强制总结一次
- **按主题切换触发**:当检测到产品类型变化时(信用卡→贷款)
- **关键信息标记**:利率数字、期限要求等永不丢失
## 📊 实际效果示例
**原始记录(可能20+条):**
- 用户询问信用卡A的年费
- 比较信用卡B的积分政策
- 咨询贷款C的审批时间
- ...
**压缩后摘要:**
> “客户近期关注信用卡年费和积分政策,同时咨询贷款审批流程。偏好低年费产品,对审批效率敏感。需跟进贷款材料要求。”
## 🔧 成本控制对比
| 方案 | 每次查询token | 历史完整性 |
|------|--------------|-----------|
| 完整历史 | 2000-5000+ | 100% |
| 摘要记忆 | 300-800 | 核心信息95%+ |
| **节省** | **70%-85%** | 几乎无损 |
## 💡 进阶建议
1. **向量检索增强**:对历史摘要建立向量库,实现跨会话检索
2. **关键数据持久化**:将利率、期限等结构化数据单独存储
3. **摘要验证机制**:定期让LLM自我评估摘要完整性
你觉得这个方向符合你的需求吗?需要我在某个具体环节提供更详细的代码示例吗?
--- 步骤 4/4: 提问(测试模型是否基于摘要和最新消息回答) ---
===== 当前历史消息 (Memory Buffer) - Token 限制 200 ======
[Human]: 你好,我叫少爷,我正在研究如何使用 LangChain 和 DeepSeek API 构建一个高效的聊天机器人。...
[Ai]: 你好少爷!很高兴认识你。使用 LangChain 结合 DeepSeek API 构建聊天机器人是个很棒的选择。我可以帮你梳理一下关键步骤:
1. **环境准...
[Human]: 我发现 ConversationSummaryBufferMemory 在管理长对话时非常有用,它能自动用 LLM 对旧的记录进行总结。...
[Ai]: 完全正确!`ConversationSummaryBufferMemory` 确实是处理长对话的利器。它结合了:
**核心优势:**
- 📝 **智能总结**...
[Human]: 我的项目需要处理用户对金融产品的大量历史查询,比如信用卡、贷款和储蓄账户。如果每次都把所有查询记录传给模型,成本会非常高昂。摘要记忆的价值在于,它能将上百条记录...
[Ai]: 完全理解你的需求!金融领域的多轮查询确实需要**精准的历史压缩**。让我为你设计一个优化的方案:
## 🎯 针对性优化策略
### 1. **结构化摘要模板...
===================================================================
---- 模型输出 ----
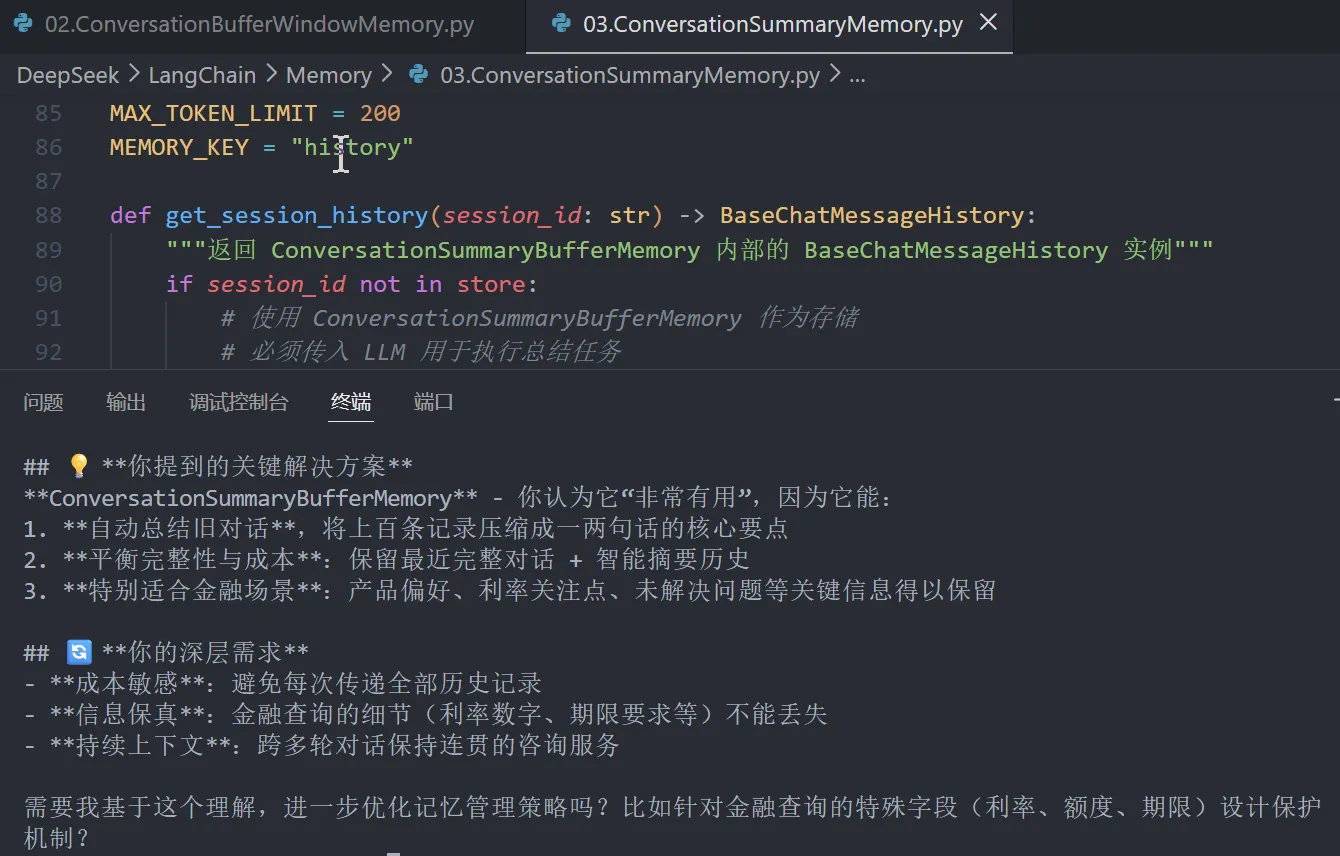
是的,完全记得!让我准确复述你的项目需求:
## 🎯 **你的核心目标**
**构建金融领域的高效聊天机器人**,专门处理用户对信用卡、贷款、储蓄账户等金融产品的**大量历史查询**。 核心挑战是:在**控制API成本**的前提下,确保不丢失关键上下文,为用户提供准确的下一步指导。
## 💡 **你提到的关键解决方案**
**ConversationSummaryBufferMemory** - 你认为它“非常有用”,因为它能:
1. **自动总结旧对话**,将上百条记录压缩成一两句话的核心要点
2. **平衡完整性与成本**:保留最近完整对话 + 智能摘要历史
3. **特别适合金融场景**:产品偏好、利率关注点、未解决问题等关键信息得以保留
## 🔄 **你的深层需求**
- **成本敏感**:避免每次传递全部历史记录
## 💡 **你提到的关键解决方案**
**ConversationSummaryBufferMemory** - 你认为它“非常有用”,因为它能:
1. **自动总结旧对话**,将上百条记录压缩成一两句话的核心要点
2. **平衡完整性与成本**:保留最近完整对话 + 智能摘要历史
3. **特别适合金融场景**:产品偏好、利率关注点、未解决问题等关键信息得以保留
## 🔄 **你的深层需求**
## 💡 **你提到的关键解决方案**
**ConversationSummaryBufferMemory** - 你认为它“非常有用”,因为它能:
1. **自动总结旧对话**,将上百条记录压缩成一两句话的核心要点
2. **平衡完整性与成本**:保留最近完整对话 + 智能摘要历史
3. **特别适合金融场景**:产品偏好、利率关注点、未解决问题等关键信息得以保留
## 💡 **你提到的关键解决方案**
**ConversationSummaryBufferMemory** - 你认为它“非常有用”,因为它能:
1. **自动总结旧对话**,将上百条记录压缩成一两句话的核心要点
2. **平衡完整性与成本**:保留最近完整对话 + 智能摘要历史
## 💡 **你提到的关键解决方案**
**ConversationSummaryBufferMemory** - 你认为它“非常有用”,因为它能:
1. **自动总结旧对话**,将上百条记录压缩成一两句话的核心要点
## 💡 **你提到的关键解决方案**
## 💡 **你提到的关键解决方案**
**ConversationSummaryBufferMemory** - 你认为它“非常有用”,因为它能:
1. **自动总结旧对话**,将上百条记录压缩成一两句话的核心要点
## 💡 **你提到的关键解决方案**
## 💡 **你提到的关键解决方案**
**ConversationSummaryBufferMemory** - 你认为它“非常有用”,因为它能:
1. **自动总结旧对话**,将上百条记录压缩成一两句话的核心要点
2. **平衡完整性与成本**:保留最近完整对话 + 智能摘要历史
**ConversationSummaryBufferMemory** - 你认为它“非常有用”,因为它能:
1. **自动总结旧对话**,将上百条记录压缩成一两句话的核心要点
2. **平衡完整性与成本**:保留最近完整对话 + 智能摘要历史
2. **平衡完整性与成本**:保留最近完整对话 + 智能摘要历史
3. **特别适合金融场景**:产品偏好、利率关注点、未解决问题等关键信息得以保留
3. **特别适合金融场景**:产品偏好、利率关注点、未解决问题等关键信息得以保留
## 🔄 **你的深层需求**
## 🔄 **你的深层需求**
## 🔄 **你的深层需求**
- **成本敏感**:避免每次传递全部历史记录
- **信息保真**:金融查询的细节(利率数字、期限要求等)不能丢失
- **持续上下文**:跨多轮对话保持连贯的咨询服务
需要我基于这个理解,进一步优化记忆管理策略吗?比如针对金融查询的特殊字段(利率、额度、期限)设计保护 机制?9.5.4 混合记忆
import os
from dotenv import load_dotenv
from langchain_openai import ChatOpenAI
from langchain_core.prompts import ChatPromptTemplate, MessagesPlaceholder
from langchain_core.runnables.history import RunnableWithMessageHistory
from langchain.memory import ConversationSummaryBufferMemory
from langchain_core.chat_history import BaseChatMessageHistory
# 步骤 0: 加载环境变量并获取配置
load_dotenv()
DEEPSEEK_API_KEY = os.getenv("DEEPSEEK_API_KEY")
DEEPSEEK_BASE_URL = os.getenv("DEEPSEEK_BASE_URL")
# 基本检查
if not DEEPSEEK_API_KEY or not DEEPSEEK_BASE_URL:
print("错误:请检查 .env 文件,确保 DEEPSEEK_API_KEY 和 DEEPSEEK_BASE_URL 已正确设置。")
exit()
# 1. 初始化模型
# 使用 DeepSeek LLM 作为主对话模型和摘要模型
llm = ChatOpenAI(
model="deepseek-chat",
temperature=0,
openai_api_key=DEEPSEEK_API_KEY,
openai_api_base=DEEPSEEK_BASE_URL
)
# 2. 定义总结缓冲记忆存储 (Store)
store = {}
# 设置最大 Token 限制。这是触发总结的阈值。
# 注意:实际使用中,该值应远大于 200,以便有足够的对话来触发总结。
MAX_TOKEN_LIMIT = 200
MEMORY_KEY = "history"
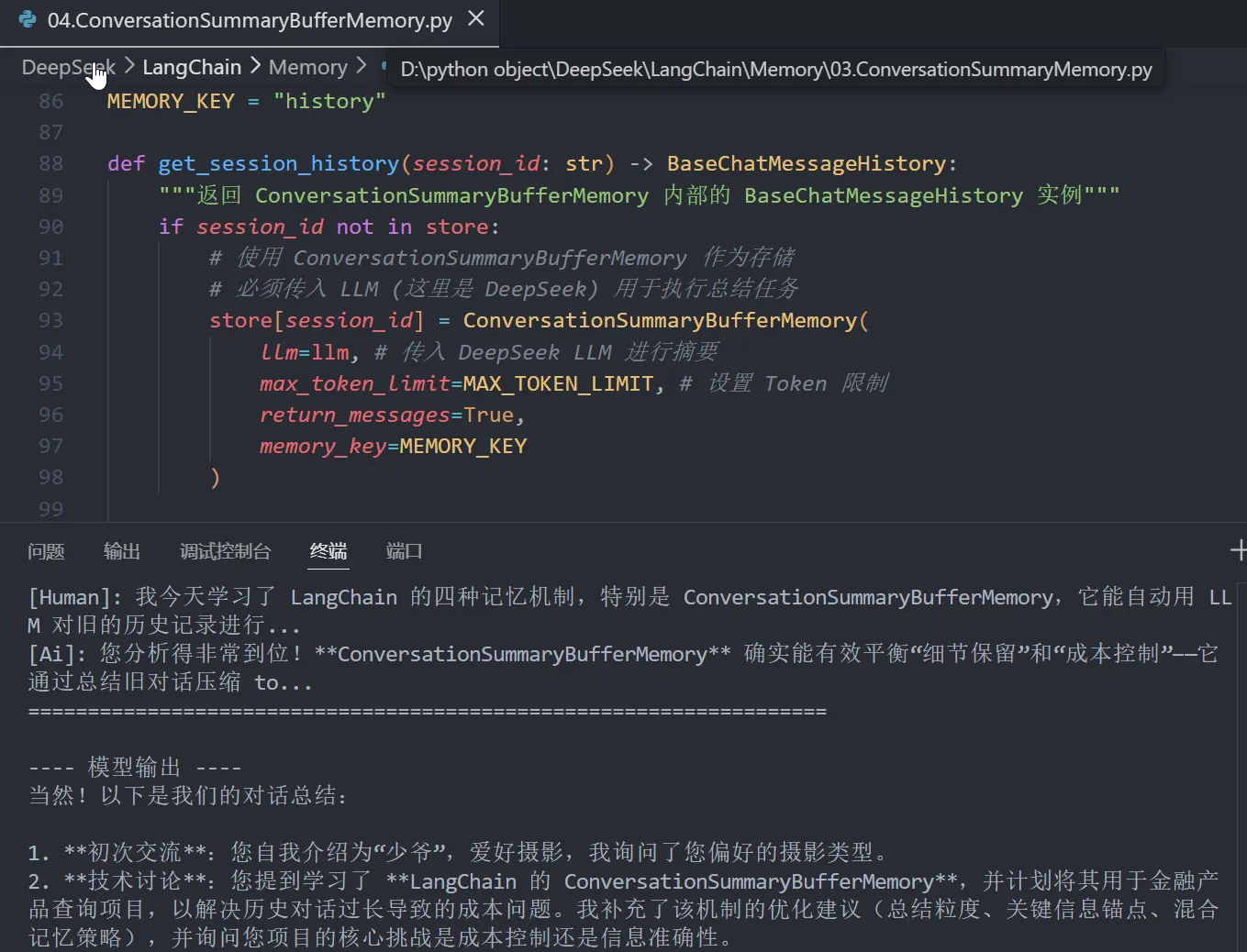
def get_session_history(session_id: str) -> BaseChatMessageHistory:
"""返回 ConversationSummaryBufferMemory 内部的 BaseChatMessageHistory 实例"""
if session_id not in store:
# 使用 ConversationSummaryBufferMemory 作为存储
# 必须传入 LLM (这里是 DeepSeek) 用于执行总结任务
store[session_id] = ConversationSummaryBufferMemory(
llm=llm, # 传入 DeepSeek LLM 进行摘要
max_token_limit=MAX_TOKEN_LIMIT, # 设置 Token 限制
return_messages=True,
memory_key=MEMORY_KEY
)
# 官方推荐的方式:返回 memory 对象的 chat_memory 属性
return store[session_id].chat_memory
# 3. 定义提示模板
prompt = ChatPromptTemplate.from_messages([
("system", f"你是一个既能记住近期对话,又能总结旧内容的智能助手。历史记忆限制为 {MAX_TOKEN_LIMIT} tokens。"),
# 历史占位符,名称必须与 memory_key 匹配
MessagesPlaceholder(variable_name=MEMORY_KEY),
("human", "{input}")
])
# 4. 构建 Runnable Chain
chain = prompt | llm
# 5. 使用 RunnableWithMessageHistory 封装 Chain
runnable_with_history = RunnableWithMessageHistory(
chain,
get_session_history,
input_messages_key="input",
history_messages_key=MEMORY_KEY
)
# 配置用于运行的 session_id
config = {"configurable": {"session_id": "summary_buffer_demo"}}
def invoke_with_debug(input_text):
# 获取当前的 BaseChatMessageHistory 实例
current_history = get_session_history(config['configurable']['session_id'])
print(f"\\n===== 当前历史消息 (Memory Buffer) - Token 限制 {MAX_TOKEN_LIMIT} ======")
# 打印消息列表
messages = current_history.messages
if messages:
for i, message in enumerate(messages):
# 打印消息类型和内容。如果消息是 System 消息,则它是摘要。
print(f"[{message.type.capitalize()}]: {message.content[:80]}...")
else:
print("无历史消息")
print("===================================================================")
# 调用模型
output = runnable_with_history.invoke({"input": input_text}, config=config)
print("\\n---- 模型输出 ----")
print(output.content)
return output
# --- 多轮对话测试:观察摘要机制 ---
print("--- 步骤 1/3: 介绍个人信息 ---")
invoke_with_debug("你好,我是少爷,我喜欢摄影。")
print("\\n--- 步骤 2/3: 讨论技术主题(输入长文本以触发摘要) ---")
long_input = "我今天学习了 LangChain 的四种记忆机制,特别是 ConversationSummaryBufferMemory,它能自动用 LLM 对旧的历史记录进行总结。我认为这个机制对于我的项目至关重要,我的项目需要处理用户对金融产品的大量历史查询,如果每次都把所有查询记录传给模型,成本会非常高昂。"
invoke_with_debug(long_input)
print("\\n--- 步骤 3/3: 提问(测试模型是否基于摘要和最新消息回答) ---")
# 此时,如果 Token 限制被触发,第 1 轮消息(少爷、摄影)将被总结为摘要。
invoke_with_debug("你能总结一下我们聊了什么吗?")
9.6 示例:Clone ChatGPT
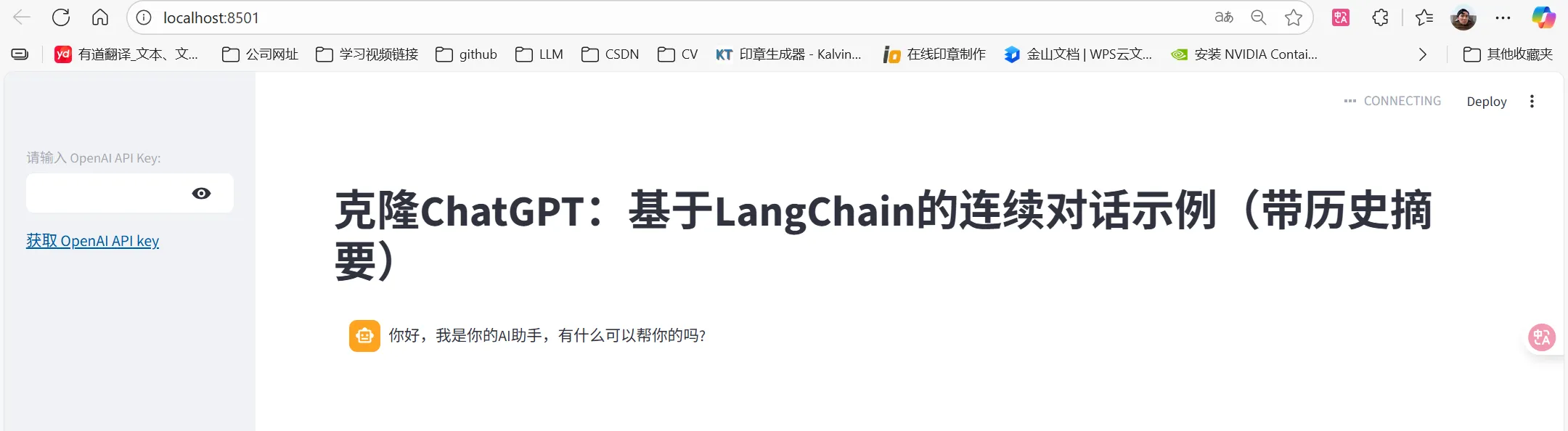
# ------------------------------------------------------
# 文件路径:DeepSeek/LangChain/CloneChatGPT/main.py
# 启动命令:streamlit run main.py
# ------------------------------------------------------
# main.py
import streamlit as st
from utils import get_chat_response
st.set_page_config(page_title="克隆ChatGPT", layout="wide")
st.title("克隆ChatGPT:基于LangChain的连续对话示例(带历史摘要)")
# 侧边栏输入 OpenAI API Key
with st.sidebar:
openai_api_key = st.text_input(
"请输入 OpenAI API Key:", type="password"
)
st.markdown("[获取 OpenAI API key](<https://platform.openai.com/account/api-keys>)")
# 初始化 session_state
if "messages" not in st.session_state:
st.session_state["messages"] = [
{"role": "ai", "content": "你好,我是你的AI助手,有什么可以帮你的吗?"}
]
# 显示历史消息
for message in st.session_state["messages"]:
st.chat_message(message["role"]).write(message["content"])
# 聊天输入
prompt = st.chat_input("输入消息...")
if prompt:
if not openai_api_key:
st.info("请输入你的 OpenAI API Key")
st.stop()
# 显示用户消息
st.chat_message("human").write(prompt)
st.session_state["messages"].append({"role": "human", "content": prompt})
# 调用 utils 获取 AI 响应
with st.spinner("AI正在思考中,请稍等..."):
response_text, summary_text = get_chat_response(
user_input=prompt,
openai_api_key=openai_api_key,
session_id="streamlit_session"
)
# 显示 AI 响应
st.chat_message("ai").write(response_text)
st.session_state["messages"].append({"role": "ai", "content": response_text})
# 显示摘要记忆
if summary_text:
st.chat_message("ai").write(f"【摘要记忆】{summary_text}")
# utils.py
import logging
from langchain_openai import ChatOpenAI
from langchain_core.chat_history import InMemoryChatMessageHistory
from langchain_core.prompts import ChatPromptTemplate
from langchain_core.runnables.history import RunnableWithMessageHistory
logging.basicConfig(level=logging.INFO)
# 简单内存存储历史
store = {}
def summarize_messages(messages, summary_llm):
"""对多条消息进行摘要"""
texts = [m["content"] for m in messages]
joined = "\\n".join(texts)
logging.info(f"[summarize_messages] 历史消息数: {len(messages)}")
result = summary_llm.invoke(f"请用一句话总结以下对话:\\n{joined}")
summary = getattr(result, "content", "").strip()
return summary or "无可用摘要"
def get_history(session_id, summary_llm):
"""获取历史消息,并在必要时生成摘要"""
if session_id not in store:
store[session_id] = InMemoryChatMessageHistory()
history = store[session_id]
# 超过 6 条消息则做摘要压缩
if len(history.messages) > 6:
old_msgs = [{"role": m.role, "content": m.content} for m in history.messages[:-4]]
summary = summarize_messages(old_msgs, summary_llm)
# 压缩历史 + 保留最近 4 条
history.messages = [
("system", f"摘要记忆:{summary}")
] + history.messages[-4:]
logging.info(f"[get_history] session_id: {session_id}, 历史消息数: {len(history.messages)}")
return history
def get_chat_response(user_input, openai_api_key, session_id="default"):
"""获取 AI 响应"""
llm = ChatOpenAI(
openai_api_key=openai_api_key,
model="gpt-3.5-turbo",
temperature=0.7
)
summary_llm = ChatOpenAI(
openai_api_key=openai_api_key,
model="gpt-3.5-turbo",
temperature=0
)
# 构建 prompt
prompt_template = ChatPromptTemplate.from_messages([
("system", "你是一个智能助手,能回答用户问题并记住历史对话。"),
("human", "{input}")
])
# 构建 RunnableWithMessageHistory
chain_runnable = prompt_template | llm
runnable = RunnableWithMessageHistory(
chain_runnable,
get_session_history=lambda: get_history(session_id, summary_llm),
input_messages_key="input",
history_messages_key="history"
)
# 调用模型生成响应
logging.info(f"[get_chat_response] user_input: {user_input}")
result = runnable.invoke({"input": user_input})
response_text = getattr(result, "content", "")
# 获取摘要
history = get_history(session_id, summary_llm)
summary_text = None
if len(history.messages) > 1:
summary_text = summarize_messages(
[{"role": m.role, "content": m.content} for m in history.messages], summary_llm
)
logging.info(f"[summarize_messages] 摘要内容: {summary_text}")
return response_text, summary_text

魔乐社区(Modelers.cn) 是一个中立、公益的人工智能社区,提供人工智能工具、模型、数据的托管、展示与应用协同服务,为人工智能开发及爱好者搭建开放的学习交流平台。社区通过理事会方式运作,由全产业链共同建设、共同运营、共同享有,推动国产AI生态繁荣发展。
更多推荐


 59
59 0
0- 0



 已为社区贡献8条内容
已为社区贡献8条内容

所有评论(0)