LeetCode华为2025年秋招AI大模型岗刷题(一)
本文整理了华为2025秋招AI大模型实习岗推荐的15类算法题型及解题思路:1)递归(爬楼梯、路径总和);2)分治(合并K个链表);3)单调栈(每日温度);4)并查集(省份数量);5)滑动窗口(最小子数组);6)前缀和(中心下标);7)差分(拼车问题);8)拓扑排序(课程表);9)字符串(最长回文);10)二分查找(旋转数组);11)BFS(单词接龙);12)DFS&回溯(最短桥);13)动
本文针对华为2025年秋招AI大模型实习岗的推荐题库进行针对性学习:

一.递归:
Leetcode 70, 爬楼梯

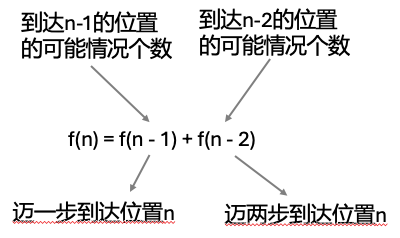
初始值:f(1) = 1,f(2) = 2
class Solution:
def climbStairs(self, n: int) -> int:
a,b=1,1
for _ in range(n-1):
a , b= b, a+b
return bLeetcode 112. 路径总和
递归(深度优先搜索)DFS(Depth First Search)
# Definition for a binary tree node.
# class TreeNode:
# def __init__(self, val=0, left=None, right=None):
# self.val = val
# self.left = left
# self.right = right
class Solution:
def hasPathSum(self, root: Optional[TreeNode], targetSum: int) -> bool:
if not root:
return False
if not root.left and not root.right:
return root.val == targetSum
return self.hasPathSum(root.left, targetSum- root.val) or self.hasPathSum(root.right, targetSum- root.val)用堆栈的方式解决:
栈:用一个列表表示[]
进栈:stack.append()
出栈 out=stack.pop()
class Solution:
def hasPathSum(self, root: Optional[TreeNode], targetSum: int) -> bool:
if not root:
return False
stack = [(root, root.val)]
while stack:
node,s = stack.pop()
if not node.left and not node.right:
if s == targetSum:
return True
if node.right:
stack.append((node.right, s + node.right.val))
if node.left:
stack.append((node.left, s + node.left.val))
return False二.分治:
23. 合并 K 个升序链表Leetcode 23. 合并 K 个升序链表

解题思路:
首先将K个列表合并的问题简化为2个有序列表合并的问题merge_two
生成一个dummy的node用于记录两个列表的合并,
比较两个列表的当前节点,L1和L2。选择较小的那个,将新键node的next附加到较小的那个节点,并把Lx节点往后推移一个
然后再把cur往后推移一个,继续循环
如果有一个表结束了,那么直接把剩下的附加上
对于K个这样的表,采取分治的方法。分别合并[left,mid]和[mid+1, right]的子集合,然后把这两个left和right表再合并
# Definition for singly-linked list.
# class ListNode:
# def __init__(self, val=0, next=None):
# self.val = val
# self.next = next
class Solution:
def mergeKLists(self, lists: List[Optional[ListNode]]) -> Optional[ListNode]:
if not lists:
return None
return self.merge_range(lists, 0, len(lists)-1)
def merge_two(self,L1, L2):
dummy = ListNode(0)
cur= dummy
while L1 and L2:
if L1.val <= L2.val:
cur.next = L1
L1 = L1.next
else:
cur.next = L2
L2 = L2.next
cur = cur.next
cur.next = L1 if L1 else L2
return dummy.next
def merge_range(self, lists, left, right):
if left == right:
return lists[left]
mid = (left+right) // 2
L1 = self.merge_range(lists, left, mid)
L2 = self.merge_range(lists, mid+1, right)
return self.merge_two(L1,L2)三.单调栈:
Leetcode 739. 每日温度
思路:
创建一个栈用于存放天数id,每新加一天的温度,就和栈顶天数的温度比较,如果比栈顶温度高,则弹出那天的id,其answer就是和当前天数id的差值。
走出这个循环后,将当天的id加入stack。
操作:
栈: stack=[]
栈顶: stack[-1]
出栈:stack.pop()
入栈:stack.append(i)
class Solution:
def dailyTemperatures(self, temperatures: List[int]) -> List[int]:
n = len(temperatures)
ans = [0]*n
stack = []
for i , temp in enumerate(temperatures):
while stack and temp > temperatures[stack[-1]]:
idx = stack.pop()
ans[idx] = i -idx
stack.append(i)
return ans四. 并查集
Leetcode 547.省份数量
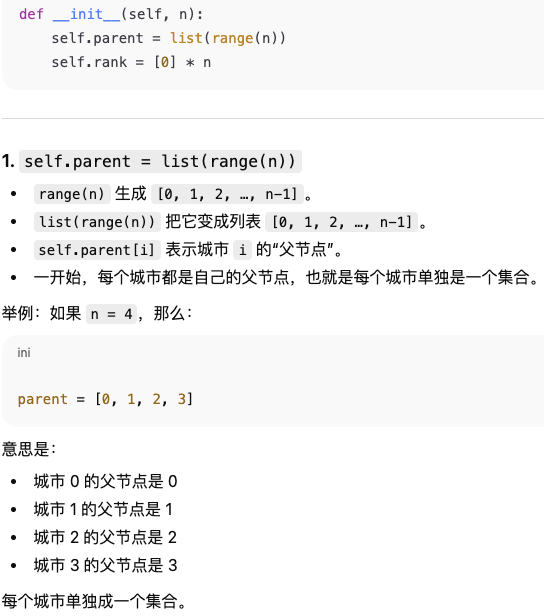

解题思路:主要是构建一个parent和rank的数组结构。对于connected的城市,找到其parent节点。在遍历完上三角后,求出unique的parent节点的数量,即为省份数量
class unionFind:
def __init__(self, n):
self.parent = list(range(n))
self.rank = [0]*n
def find(self, x):
# 寻找根节点
if self.parent[x] != x:
self.parent[x] = self.find(self.parent[x]) # 路径压缩
# 直到self.parent[x] == x,也就是根节点的id
return self.parent[x]
def union(self, x, y):
# 合并函数
px, py = self.find(x), self.find(y)
if px == py: # 根节点相同
return
# 两个城市相连,但是还未合并时:按秩合并
# 把低的树挂到高的树下面,这样不会增加树的高度
if self.rank[px] < self.rank[py]:
self.parent[px] = py # 小的挂到大的上
elif self.rank[px] > self.rank[py]:
self.parent[py] = px
else: # 两个rank一样 # 如果高度相等,任意挂一边,并把高度 +1
self.parent[py] = px
self.rank[px] += 1
class Solution:
def findCircleNum(self, isConnected: List[List[int]]) -> int:
n = len(isConnected)
uf = unionFind(n)
for i in range(n):
for j in range(i + 1, n): # 上三角即可,避免重复
if isConnected[i][j] == 1:
uf.union(i, j)
# 统计不同的根节点数量
return len(set(uf.find(i) for i in range(n)))五. 滑动窗口
Leetcode 209,长度最小的子数组
给定一个含有 n 个正整数的数组和一个正整数 target 。
找出该数组中满足其总和大于等于 target 的长度最小的 子数组 [numsl, numsl+1, ..., numsr-1, numsr] ,并返回其长度。如果不存在符合条件的子数组,返回 0 。
思路:设置left边界和right边界,不断平移right边界,记录框选区域的和,当框选区域的和超过target时,就右移left边界,直到right边界达到最右侧。
class Solution:
def minSubArrayLen(self, target: int, nums: List[int]) -> int:
n = len(nums) # 用于记录最短长度
left =0
curr_sum = 0
min_len = n+1
for right in range(n):
curr_sum += nums[right]
while curr_sum >= target: # 如果超过target,则去掉左侧
min_len = min(min_len, right-left+1)
curr_sum -= nums[left]
left+=1 # 左侧边界右移
return min_len if min_len <= n else 0六. 前缀和
Leetcode 724,寻找数组的 中心下标
给你一个整数数组 nums ,请计算数组的 中心下标 。
数组 中心下标 是数组的一个下标,其左侧所有元素相加的和等于右侧所有元素相加的和。
如果中心下标位于数组最左端,那么左侧数之和视为 0 ,因为在下标的左侧不存在元素。这一点对于中心下标位于数组最右端同样适用。
如果数组有多个中心下标,应该返回 最靠近左边 的那一个。如果数组不存在中心下标,返回 -1 。
思路:先求出数组总长,然后用left来记录左侧所有数的和,并不断右移,直到left的值等于right数的和。
class Solution:
def pivotIndex(self, nums: List[int]) -> int:
total = sum(nums)
left = 0 # 左侧数的和
for i, x in enumerate(nums):
if left == total - left - x:
return i
else:
left += x
return -1七. 差分
Leetcode 1094,拼车
车上最初有 capacity 个空座位。车 只能 向一个方向行驶(也就是说,不允许掉头或改变方向)
给定整数 capacity 和一个数组 trips , trips[i] = [numPassengersi, fromi, toi] 表示第 i 次旅行有 numPassengersi 乘客,接他们和放他们的位置分别是 fromi 和 toi 。这些位置是从汽车的初始位置向东的公里数。
当且仅当你可以在所有给定的行程中接送所有乘客时,返回 true,否则请返回 false。
思路:这题很简单。只需要记录车行驶的路程。以及在每个节点上下车的diff情况,然后对diff遍历前缀和并与capacity比较即可。
trips = [[2, 1, 5], [3, 3, 7]]
capacity = 4

class Solution:
def carPooling(self, trips: List[List[int]], capacity: int) -> bool:
# 创建位置数组和diff数组
maxPos = 0
for num, start, end in trips:
maxPos = max(maxPos, end)
diff = [0] * (maxPos + 1)
# 记录每个上下节点,车上人数的变化
for num, start, end in trips:
diff[start] += num
diff[end] -= num
# 计算前缀和
current = 0
for x in diff:
current += x
if current > capacity:
return False
return True八. 拓扑排序
Leetcode 210,课程表II
现在你总共有 numCourses 门课需要选,记为 0 到 numCourses - 1。给你一个数组 prerequisites ,其中 prerequisites[i] = [ai, bi] ,表示在选修课程 ai 前 必须 先选修 bi 。
- 例如,想要学习课程
0,你需要先完成课程1,我们用一个匹配来表示:[0,1]。
返回你为了学完所有课程所安排的学习顺序。可能会有多个正确的顺序,你只要返回 任意一种 就可以了。如果不可能完成所有课程,返回 一个空数组 。
思路:
BFS : Breadth First Search 的缩写,中文叫广度优先搜索

思路:创建一个graph,用于记录所有课程的后继课程。创建一个indegree数组,用于基于所有课程的前置课程个数。
创建一个队列,放入所有入度为0(可以直接学习)的课程。用head从前往后输出值,输出的值放入学习顺序的数组order。并把该课程的后续课程的入度减一。如果后续课程入度减到0,则将其加入到队列末尾。一直将该队列遍历完即可。
class Solution:
def findOrder(self, numCourses: int, prerequisites: List[List[int]]) -> List[int]:
# 建图与入度
graph = [[] for _ in range(numCourses)] # graph 存放课程id的后续课程next
indegree = [0] * numCourses # 课程id的入度,代表还需要学习的前置课程数量
for a, b in prerequisites:
graph[b].append(a) # 加入后续课程
indegree[a] += 1
# 手写一个简单队列(用列表)
queue = []
for i in range(numCourses):
if indegree[i] == 0:
queue.append(i) # 初始化可以学的课程(入度为0
head = 0 # 用 head 指针代替 popleft,提高性能
order = []
# BFS 拓扑排序
while head < len(queue): # 遍历列队列
course = queue[head]
head += 1
order.append(course) # 学习顺序
# 所有直接后继课程入度减一
for nxt in graph[course]:
indegree[nxt] -= 1
if indegree[nxt] == 0:
queue.append(nxt) # 入度为0时表示可以学习了,加入队列
# 判断是否完成所有课程
if len(order) == numCourses:
return order
return []九. 字符串
Leetcode 5,最长回文子串
回文性
如果字符串向前和向后读都相同,则它满足 回文性。
给你一个字符串 s,找到 s 中最长的 回文 子串。
思路:对每个位置,把它当成中心,向两侧扩展;记录扩展出的最长回文,最后返回最大的那一个。
需要分出奇数中心和偶数中心两种情况。
利用expand()函数,从中心开始向两边扩展,判断左右是否相等
class Solution:
def longestPalindrome(self, s: str) -> str:
if not s:
return ""
start = 0
max_len = 1
def expand(l, r):
while l >= 0 and r < len(s) and s[l] == s[r]:
l -= 1
r += 1
return l + 1, r - 1
for i in range(len(s)):
# 奇数回文
l1, r1 = expand(i, i)
if r1 - l1 + 1 > max_len:
start, max_len = l1, r1 - l1 + 1
# 偶数回文
l2, r2 = expand(i, i + 1)
if r2 - l2 + 1 > max_len:
start, max_len = l2, r2 - l2 + 1
return s[start:start + max_len]十. 二分查找
Leetcode 10,搜索旋转排序数组
整数数组 nums 按升序排列,数组中的值 互不相同 。(严格递增)
在传递给函数之前,nums 在预先未知的某个下标 k(0 <= k < nums.length)上进行了 向左旋转,使数组变为 [nums[k], nums[k+1], ..., nums[n-1], nums[0], nums[1], ..., nums[k-1]](下标 从 0 开始 计数)。例如, [0,1,2,4,5,6,7] 下标 3 上向左旋转后可能变为 [4,5,6,7,0,1,2] 。
给你 旋转后 的数组 nums 和一个整数 target ,如果 nums 中存在这个目标值 target ,则返回它的下标,否则返回 -1 。(查找目标值)
你必须设计一个时间复杂度为 O(log n) 的算法解决此问题。
思路:
分别设置left和right指标,建立循环while left<=right。
通过不断找中点mid,判断哪一侧的数组有序,在有序的那边找target即可
若找不到,则最后返回-1
class Solution:
def search(self, nums: List[int], target: int) -> int:
if nums == []:
return -1
left = 0
right = len(nums)-1
while left<=right:
mid = (left+right) //2
if nums[mid] == target:
return mid
else:
if nums[left] <= nums[mid]:
if nums[left] <= target < nums[mid]:
right = mid - 1
else:
left = mid + 1
else: # 右侧有序
if nums[mid] < target <= nums[right]:
left = mid + 1
else:
right = mid - 1
return -1十一. BFS(广度优先搜索)
Leetcode 127.单词接龙
字典 wordList 中从单词 beginWord 到 endWord 的 转换序列 是一个按下述规格形成的序列 beginWord -> s1 -> s2 -> ... -> sk:
- 每一对相邻的单词只差一个字母。
- 对于
1 <= i <= k时,每个si都在wordList中。注意,beginWord不需要在wordList中。 sk == endWord
给你两个单词 beginWord 和 endWord 和一个字典 wordList ,返回 从 beginWord 到 endWord 的 最短转换序列 中的 单词数目 。如果不存在这样的转换序列,返回 0 。
思路:
把 beginWord 逐步变化成 endWord
每次只能改一个字母
变出的中间单词必须在 wordList 中
要求最少步数(最短路径)(广度优先搜索的深度就是路径长度,因此用BFS)
这就是 BFS 最擅长的场景。
BFS 广度优先搜索 在python中用队列来实现
queue = [(beginWord, 1)] # 记录word和step
head = 0 用 head 指针代替队列的出列,每访问一次,head就加上1
思路:
构造pattern list用于查找

构造队列,用于广度优先搜索
建立visited 数组,避免重复寻找
class Solution:
def ladderLength(self, beginWord: str, endWord: str, wordList: List[str]) -> int:
if endWord not in wordList:
return 0
L = len(beginWord)
# 构建通配符映射
pattern_dict = {}
for word in wordList:
for i in range(L):
# 构造模式
pattern = word[:i] + "*" + word[i+1:]
if pattern not in pattern_dict:
pattern_dict[pattern] = []
# 所有能匹配同一个模式的单词,只相差一个字母
pattern_dict[pattern].append(word) # *ot: ["hot", "dot", "lot"]
# BFS 队列,用普通列表模拟
queue = [(beginWord, 1)] # word, steps
visited = set([beginWord])
head = 0 # 用 head 指针代替 pop(0) 提升效率
while head < len(queue):
# 队列操作
word, steps = queue[head]
head += 1
for i in range(L):
pattern = word[:i] + "*" + word[i+1:]
if pattern not in pattern_dict:
continue
for next_word in pattern_dict[pattern]:
if next_word == endWord:
return steps + 1
# 只查找没有visited的部分
if next_word not in visited:
visited.add(next_word)
queue.append((next_word, steps + 1))
# 避免重复使用同一个 pattern,提升性能
pattern_dict[pattern] = [] # 某个模式已经使用过一次后,就不需要再用第二次。
return 0十二. DFS(深度优先搜索)&回溯
Leetcode 934 最短的桥
给你一个大小为 n x n 的二元矩阵 grid ,其中 1 表示陆地,0 表示水域。
岛 是由四面相连的 1 形成的一个最大组,即不会与非组内的任何其他 1 相连。grid 中 恰好存在两座岛 。
你可以将任意数量的 0 变为 1 ,以使两座岛连接起来,变成 一座岛 。
返回必须翻转的 0 的最小数目。

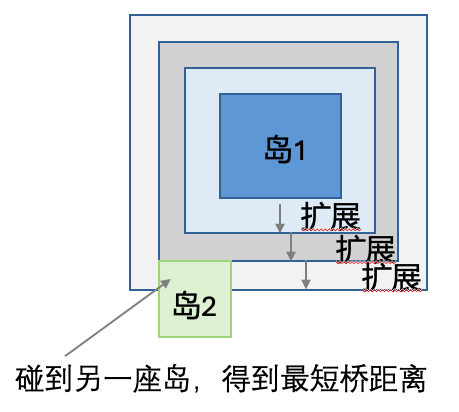
算法思路:
这一题需要同时用到深度优先搜索和广度优先搜索
1,首先通过深度优先搜索来找到第一个岛,并将其标记为visited
2,通过队列来实现广度优先搜索,将岛向外扩展,并记录扩展距离,直到碰到另一个岛(没有visited并且值等于1),此时的step就是最短距离。
class Solution:
def shortestBridge(self, grid: List[List[int]]) -> int:
n = len(grid)
visited = [[False] * n for _ in range(n)]
dirs = [(1,0), (-1,0), (0,1), (0,-1)] # 用于简洁地遍历四邻居
# DFS 找第一座岛
def dfs(x, y, island):
if x < 0 or x >= n or y < 0 or y >= n:
return
if visited[x][y] or grid[x][y] == 0:
return
visited[x][y] = True # 如果是岛,则找
island.append((x, y))
for dx, dy in dirs:
dfs(x + dx, y + dy, island) # 深度优先搜索 DFS
# 找第一座岛
island = []
found = False
for i in range(n):
if found:
break
for j in range(n):
if grid[i][j] == 1:
dfs(i, j, island)
found = True
break
# BFS 用列表模拟队列
queue = []
for x, y in island:
queue.append((x, y, 0)) # 距离为 0
# 开始多源 BFS
head = 0
while head < len(queue):
x, y, step = queue[head]
head += 1
for dx, dy in dirs:
nx, ny = x + dx, y + dy
if nx < 0 or nx >= n or ny < 0 or ny >= n:
continue
if visited[nx][ny]:
continue
visited[nx][ny] = True
if grid[nx][ny] == 1:
return step
queue.append((nx, ny, step + 1))十三. 动态规划
Leetcode 213. 打家劫舍II
你是一个专业的小偷,计划偷窃沿街的房屋,每间房内都藏有一定的现金。这个地方所有的房屋都 围成一圈 ,这意味着第一个房屋和最后一个房屋是紧挨着的。同时,相邻的房屋装有相互连通的防盗系统,如果两间相邻的房屋在同一晚上被小偷闯入,系统会自动报警 。
给定一个代表每个房屋存放金额的非负整数数组,计算你 在不触动警报装置的情况下 ,今晚能够偷窃到的最高金额。
这是一个动态规划的问题,没一步都取决于前面的字步骤
dp[i]表示偷盗的价值
dp[i] 完全由它的前置情况决定:
1,要么是dp[i-1]的值,并且当前第i步不偷,最后的值为dp[i-1]
2,要么是dp[i-2]的值,当前就可以偷,最后的值是dp[i-2]+nums[i]
对这两种情况选取最大值

对于这个环形版本,只需分两个情况讨论即可

动态规划算法思路:
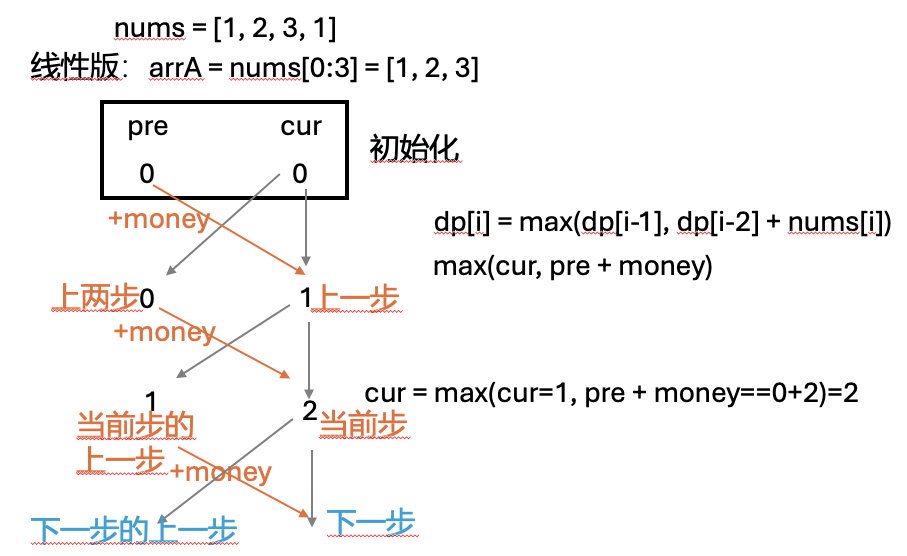
class Solution:
def rob(self, nums: List[int]) -> int:
n = len(nums)
if n == 1:
return nums[0]
# 线性 rob,只是辅助函数
def rob_line(arr):
pre, cur = 0, 0
for money in arr:
pre, cur = cur, max(cur, pre + money)
return cur
# 两种方案取最大的
return max(
rob_line(nums[:-1]), # 不偷最后一间
rob_line(nums[1:]) # 不偷第一间
)
十四. 贪心算法
Leetcode 55.跳跃游戏
给你一个非负整数数组 nums ,你最初位于数组的 第一个下标 。数组中的每个元素代表你在该位置可以跳跃的最大长度。
判断你是否能够到达最后一个下标,如果可以,返回 true ;否则,返回 false 。
思路:使用贪心(Greedy)
核心思想:
维护当前能到达的最远位置
max_reach
每次往前移动时,都记录下最远能移动的距离

由于不需要记录具体的跳法,因此只需要判断max_reach即可
class Solution:
def canJump(self, nums: List[int]) -> bool:
max_reach = 0
n = len(nums)
for i in range(n):
if i > max_reach:
return False
max_reach = max(max_reach, i + nums[i])
return True十五. 字典树:
Leetcode 820,单词的压缩编码
单词数组 words 的 有效编码 由任意助记字符串 s 和下标数组 indices 组成,且满足:
words.length == indices.length- 助记字符串
s以'#'字符结尾 - 对于每个下标
indices[i],s的一个从indices[i]开始、到下一个'#'字符结束(但不包括'#')的 子字符串 恰好与words[i]相等
给你一个单词数组 words ,返回成功对 words 进行编码的最小助记字符串 s 的长度 。
这是经典的最短编码长度问题。思路是在于:如果某个单词是另一个单词的后缀,就不需要单独编码它。
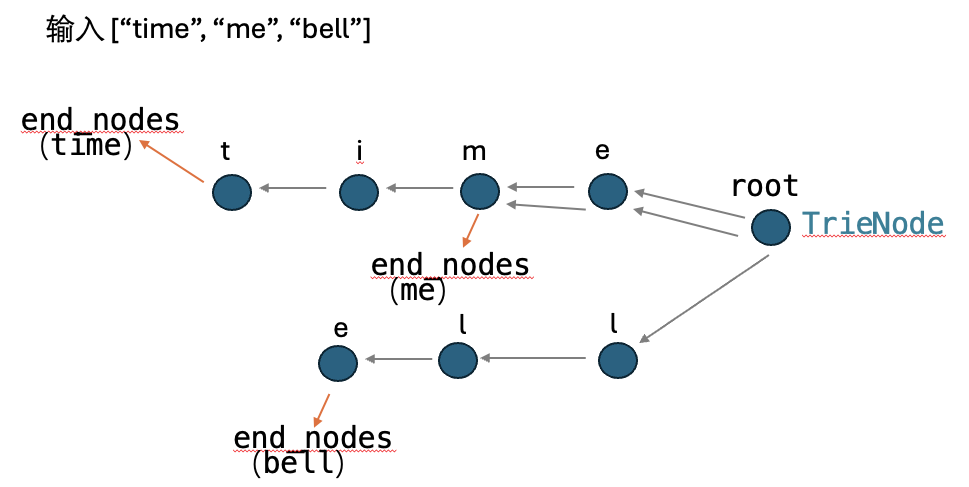
class TrieNode:
def __init__(self):
self.children = {}
class Solution:
def minimumLengthEncoding(self, words: List[str]) -> int:
# 去重
words = list(set(words))
root = TrieNode()
# 保存每个单词对应的结束节点
end_nodes = []
for w in words:
cur = root
# 倒序插入
for ch in w[::-1]: # w[start:end:step]当 step 为 -1 时 表示反向遍历整个字符串。
if ch not in cur.children:
cur.children[ch] = TrieNode()
cur = cur.children[ch]
end_nodes.append((cur, len(w))) # word长度和叶子节点
total = 0
# 判断哪些是叶子节点
for node, length in end_nodes:
if len(node.children) == 0: # 如果该单词是一个结束节点,则记录
total += length + 1
return total
魔乐社区(Modelers.cn) 是一个中立、公益的人工智能社区,提供人工智能工具、模型、数据的托管、展示与应用协同服务,为人工智能开发及爱好者搭建开放的学习交流平台。社区通过理事会方式运作,由全产业链共同建设、共同运营、共同享有,推动国产AI生态繁荣发展。
更多推荐


 19
19 0
0- 0



 已为社区贡献7条内容
已为社区贡献7条内容

所有评论(0)