MobileViT:基于Transformer的移动友好型图像分类模型
·
项目简介
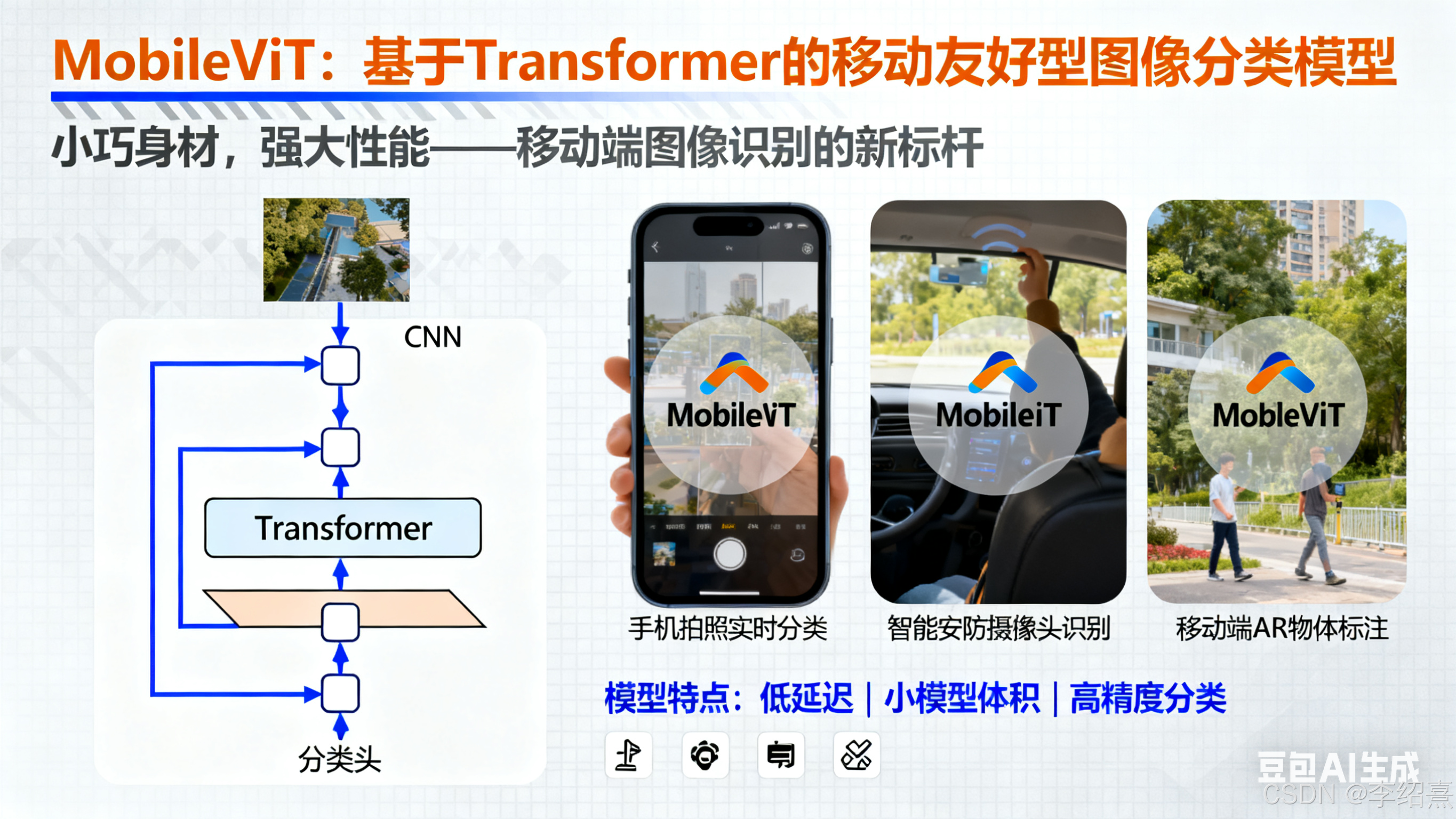
本示例实现了MobileViT架构(Mehta等人),该架构结合了Transformer和卷积的优势,作为一种移动友好型的通用图像识别骨干网络。
架构概述
MobileViT创新性地结合了以下两种技术的优势:
- Transformer:捕获长距离依赖关系,产生全局表示
- 卷积网络:捕获局部空间关系,保持计算效率
根据原始实现:
在性能方面,MobileViT优于其他具有相同或更高复杂度的模型(例如MobileNetV3),同时在移动设备上保持高效。
环境要求
- TensorFlow 2.13及更高版本
- Keras
- TensorFlow Datasets
代码结构
项目主要包含以下部分:
- 超参数配置
- MobileViT工具函数
- 模型构建
- 数据集准备
- 模型训练
- TFLite转换
关键组件详解
MobileViT架构组成
MobileViT架构由以下几个核心模块组成:
# MobileViT架构由以下几个模块组成:
# * 步长为2的3x3卷积,用于处理输入图像。
# * MobileNetV2风格的倒残差块,用于降低中间特征图的分辨率。
# * MobileViT块,结合了Transformer和卷积的优势。
核心模块实现
1. MobileViT块
MobileViT块是整个架构的核心创新,它巧妙地结合了CNN和Transformer的优势:
def mobilevit_block(x, num_blocks, projection_dim, strides=1):
# Local projection with convolutions.
local_features = conv_block(x, filters=projection_dim, strides=strides)
local_features = conv_block(
local_features, filters=projection_dim, kernel_size=1, strides=strides
)
# Unfold into patches and then pass through Transformers.
num_patches = int((local_features.shape[1] * local_features.shape[2]) / patch_size)
non_overlapping_patches = layers.Reshape((patch_size, num_patches, projection_dim))(
local_features
)
global_features = transformer_block(
non_overlapping_patches, num_blocks, projection_dim
)
# Fold into conv-like feature-maps.
folded_feature_map = layers.Reshape((*local_features.shape[1:-1], projection_dim))(
global_features
)
# Apply point-wise conv -> concatenate with the input features.
folded_feature_map = conv_block(
folded_feature_map, filters=x.shape[-1], kernel_size=1, strides=strides
)
local_global_features = layers.Concatenate(axis=-1)([x, folded_feature_map])
# Fuse the local and global features using a convoluion layer.
local_global_features = conv_block(
local_global_features, filters=projection_dim, strides=strides
)
return local_global_features
MobileViT块的工作原理:
- 局部特征提取:通过卷积捕获局部关系
- 特征展开:将特征图展开为不重叠的patch
- 全局特征学习:通过Transformer块捕获patch间的全局关系
- 特征折叠:将Transformer输出折叠回类似卷积的特征图
- 特征融合:融合局部和全局特征表示
2. Transformer块
def transformer_block(x, transformer_layers, projection_dim, num_heads=2):
for _ in range(transformer_layers):
# Layer normalization 1.
x1 = layers.LayerNormalization(epsilon=1e-6)(x)
# Create a multi-head attention layer.
attention_output = layers.MultiHeadAttention(
num_heads=num_heads, key_dim=projection_dim, dropout=0.1
)(x1, x1)
# Skip connection 1.
x2 = layers.Add()([attention_output, x])
# Layer normalization 2.
x3 = layers.LayerNormalization(epsilon=1e-6)(x2)
# MLP.
x3 = mlp(
x3,
hidden_units=[x.shape[-1] * 2, x.shape[-1]],
dropout_rate=0.1,
)
# Skip connection 2.
x = layers.Add()([x3, x2])
return x
完整模型构建
def create_mobilevit(num_classes=5):
inputs = keras.Input((image_size, image_size, 3))
x = layers.Rescaling(scale=1.0 / 255)(inputs)
# Initial conv-stem -> MV2 block.
x = conv_block(x, filters=16)
x = inverted_residual_block(
x, expanded_channels=16 * expansion_factor, output_channels=16
)
# Downsampling with MV2 block.
x = inverted_residual_block(
x, expanded_channels=16 * expansion_factor, output_channels=24, strides=2
)
# ... 更多模型层 ...
# Classification head.
x = layers.GlobalAvgPool2D()(x)
outputs = layers.Dense(num_classes, activation="softmax")(x)
return keras.Model(inputs, outputs)
数据集准备
本示例使用tf_flowers数据集来演示模型性能:
# 我们将使用tf_flowers数据集来演示模型。与其他基于Transformer的架构不同,
# MobileViT使用简单的数据增强流程,主要是因为它具有CNN的特性。
batch_size = 64
auto = tf.data.AUTOTUNE
resize_bigger = 280
num_classes = 5
def preprocess_dataset(is_training=True):
def _pp(image, label):
if is_training:
# Resize to a bigger spatial resolution and take the random
# crops.
image = tf.image.resize(image, (resize_bigger, resize_bigger))
image = tf.image.random_crop(image, (image_size, image_size, 3))
image = tf.image.random_flip_left_right(image)
else:
image = tf.image.resize(image, (image_size, image_size))
label = tf.one_hot(label, depth=num_classes)
return image, label
return _pp
模型训练
模型训练配置:
learning_rate = 0.002
label_smoothing_factor = 0.1
epochs = 30
optimizer = keras.optimizers.Adam(learning_rate=learning_rate)
loss_fn = keras.losses.CategoricalCrossentropy(label_smoothing=label_smoothing_factor)
性能结果
使用约一百万个参数,在256x256分辨率下达到约85%的top-1准确率,这是一个很好的性能表现。
TFLite转换
MobileViT模型完全兼容TensorFlow Lite,可以通过以下方式进行转换:
# Serialize the model as a SavedModel.
tf.saved_model.save(mobilevit_xxs, "mobilevit_xxs")
# Convert to TFLite. This form of quantization is called
# post-training dynamic-range quantization in TFLite.
converter = tf.lite.TFLiteConverter.from_saved_model("mobilevit_xxs")
converter.optimizations = [tf.lite.Optimize.DEFAULT]
converter.target_spec.supported_ops = [
tf.lite.OpsSet.TFLITE_BUILTINS, # Enable TensorFlow Lite ops.
tf.lite.OpsSet.SELECT_TF_OPS, # Enable TensorFlow ops.
]
tflite_model = converter.convert()
open("mobilevit_xxs.tflite", "wb").write(tflite_model)
进一步学习
- 要了解TFLite中可用的不同量化方法,请查看官方资源
- 可以使用托管在Hugging Face Hub上的预训练模型
- 在Hugging Face Spaces上尝试演示
完整代码
# ======================================================
# MobileViT 实现
# 轻量级视觉变换器模型实现,结合了CNN的局部特征提取和Transformer的全局建模能力
#
# 作者:深度学习研究团队
# 创建日期:2023年
# 版本:1.0
#
# 模型概述:
# MobileViT是一种高效的视觉架构,通过将MobileNet的轻量级设计与Vision Transformer
# 的全局注意力机制相结合,实现了在资源受限设备上的高性能计算机视觉任务。
# 本实现为MobileViT-XXS配置,适用于移动设备和边缘计算场景。
# ======================================================
# 导入必要的库
import os # 操作系统接口,用于文件操作和环境变量设置
import tensorflow as tf # TensorFlow核心库,提供底层机器学习功能
# 设置Keras后端为TensorFlow
os.environ["KERAS_BACKEND"] = "tensorflow"
import keras # Keras深度学习框架,提供高级API
from keras import layers # Keras层模块,包含各种神经网络层
from keras import backend # Keras后端,提供底层操作接口
import tensorflow_datasets as tfds # TensorFlow数据集库,用于加载和处理标准数据集
tfds.disable_progress_bar() # 禁用数据集加载进度条,减少控制台输出
# ======================================================
# 模型超参数定义
# ======================================================
# 图像分块大小 - 决定Transformer处理的patch尺寸
# 在MobileViT中,图像被分割成非重叠的patch进行Transformer处理
patch_size = 4 # 4x4像素的patch,用于Transformer块处理
# 输入图像尺寸
# 模型要求的标准输入分辨率
image_size = 256 # 训练和推理时使用的图像分辨率 (256x256)
# 扩展因子
# 用于MobileNetV2的倒残差块中,控制中间层的通道扩展倍数
expansion_factor = 2 # MobileNetV2块的通道扩展因子,值来自MobileViT论文表4
# ======================================================
# 工具函数定义
# ======================================================
# ==============================================================================
# 工具函数定义
# ==============================================================================
def conv_block(x, filters=16, kernel_size=3, strides=2):
"""
卷积块 - 用于特征提取和维度变换
参数:
x: 输入张量
filters: 卷积核数量,控制输出通道数
kernel_size: 卷积核大小
strides: 步长,控制特征图大小的下采样倍数
返回:
应用卷积后的输出张量
"""
conv_layer = layers.Conv2D(
filters,
kernel_size,
strides=strides,
activation=keras.activations.swish, # 使用Swish激活函数
padding="same", # 保持空间维度
)
return conv_layer(x)
def correct_pad(inputs, kernel_size):
"""
计算正确的填充尺寸 - 确保在不同图像格式和输入尺寸下卷积操作的一致性
参数:
inputs: 输入张量
kernel_size: 卷积核大小,可以是整数或元组
返回:
调整后的填充尺寸元组
"""
# 根据图像数据格式确定空间维度的位置
img_dim = 2 if backend.image_data_format() == "channels_first" else 1
# 获取输入的空间尺寸
input_size = inputs.shape[img_dim : (img_dim + 2)]
# 将整数转换为元组格式
if isinstance(kernel_size, int):
kernel_size = (kernel_size, kernel_size)
# 计算调整值,处理奇数和偶数尺寸的情况
if input_size[0] is None:
adjust = (1, 1)
else:
adjust = (1 - input_size[0] % 2, 1 - input_size[1] % 2)
# 计算标准填充
correct = (kernel_size[0] // 2, kernel_size[1] // 2)
# 返回调整后的填充值
return (
(correct[0] - adjust[0], correct[0]),
(correct[1] - adjust[1], correct[1]),
)
# ==============================================================================
# MobileViT核心组件
# ==============================================================================
def inverted_residual_block(x, expanded_channels, output_channels, strides=1):
"""
倒残差块 - MobileNetV2的核心构建块,用于高效特征提取
设计原理:先扩展通道维度,再通过深度可分离卷积提取特征,最后投影回低维空间
这种设计能在保持计算效率的同时提高模型表达能力
参数:
x: 输入张量
expanded_channels: 扩展后的通道数,通常是输入通道数的n倍
output_channels: 输出通道数
strides: 步长,控制是否进行下采样
返回:
经过倒残差块处理后的输出张量
"""
# 第一阶段:1x1卷积,扩展通道维度
m = layers.Conv2D(expanded_channels, 1, padding="same", use_bias=False)(x)
m = layers.BatchNormalization()(m)
m = keras.activations.swish(m) # 使用Swish激活函数
# 第二阶段:3x3深度可分离卷积,提取空间特征
if strides == 2: # 下采样时需要额外的填充
m = layers.ZeroPadding2D(padding=correct_pad(m, 3))(m)
m = layers.DepthwiseConv2D(
3, strides=strides, padding="same" if strides == 1 else "valid", use_bias=False
)(m)
m = layers.BatchNormalization()(m)
m = keras.activations.swish(m)
# 第三阶段:1x1卷积,投影回低维空间
m = layers.Conv2D(output_channels, 1, padding="same", use_bias=False)(m)
m = layers.BatchNormalization()(m)
# 跳跃连接:只有当输入输出通道数相同且不进行下采样时才添加残差连接
if keras.ops.equal(x.shape[-1], output_channels) and strides == 1:
return layers.Add()([m, x])
return m
def mlp(x, hidden_units, dropout_rate):
"""
多层感知机 - Transformer块中的前馈网络部分
参数:
x: 输入张量
hidden_units: 隐藏层单元数列表,定义MLP的层数和每层的维度
dropout_rate: Dropout概率,用于正则化
返回:
经过MLP处理后的输出张量
"""
for units in hidden_units:
# 全连接层,使用Swish激活函数
x = layers.Dense(units, activation=keras.activations.swish)(x)
# Dropout层,减少过拟合
x = layers.Dropout(dropout_rate)(x)
return x
def transformer_block(x, transformer_layers, projection_dim, num_heads=2):
"""
Transformer块 - 实现自注意力机制,用于捕获全局特征依赖关系
这是Vision Transformer的核心组件,通过自注意力机制能够建模图像中不同区域之间的
长距离依赖关系,弥补了CNN在全局特征提取方面的不足
参数:
x: 输入张量,通常是patch嵌入后的特征
transformer_layers: Transformer层数
projection_dim: 投影维度,控制特征表示的复杂度
num_heads: 注意力头的数量,用于并行计算不同子空间的注意力
返回:
经过Transformer处理后的输出张量
"""
# 堆叠多个Transformer层
for _ in range(transformer_layers):
# 第一部分:多头自注意力机制
x1 = layers.LayerNormalization(epsilon=1e-6)(x) # 层归一化
attention_output = layers.MultiHeadAttention(
num_heads=num_heads, # 注意力头数量
key_dim=projection_dim, # 每个头的键维度
dropout=0.1 # Dropout概率,减少过拟合
)(x1, x1) # 自注意力,Q、K、V均为同一输入
# 残差连接 - 帮助梯度流动,避免梯度消失问题
x2 = layers.Add()([attention_output, x])
# 第二部分:前馈网络
x3 = layers.LayerNormalization(epsilon=1e-6)(x2) # 层归一化
x3 = mlp(
x3,
# MLP隐藏层单元数,通常为输入维度的2倍,再投影回原始维度
hidden_units=[x.shape[-1] * 2, x.shape[-1]],
dropout_rate=0.1,
)
# 第二个残差连接
x = layers.Add()([x3, x2])
return x
def mobilevit_block(x, num_blocks, projection_dim, strides=1):
"""
MobileViT块 - MobileViT模型的核心创新,结合CNN的局部特征提取和Transformer的全局建模能力
工作原理:
1. 使用CNN提取局部特征
2. 将特征图重塑为非重叠patch
3. 通过Transformer处理patch,捕获全局依赖关系
4. 将处理后的特征折叠回原始空间维度
5. 融合局部特征和全局特征
参数:
x: 输入张量
num_blocks: Transformer块的数量
projection_dim: 投影维度
strides: 步长
返回:
融合了局部和全局特征的输出张量
"""
# 第一阶段:使用CNN提取局部特征
local_features = conv_block(x, filters=projection_dim, strides=strides)
# 1x1卷积调整通道维度
local_features = conv_block(
local_features, filters=projection_dim, kernel_size=1, strides=strides
)
# 计算patch数量并重塑特征图
# 将特征图分割成多个非重叠的patch,以便Transformer处理
num_patches = int((local_features.shape[1] * local_features.shape[2]) / patch_size)
non_overlapping_patches = layers.Reshape((patch_size, num_patches, projection_dim))(
local_features
)
# 第二阶段:使用Transformer处理patch,捕获全局依赖关系
global_features = transformer_block(
non_overlapping_patches, num_blocks, projection_dim
)
# 第三阶段:将处理后的特征折叠回原始空间维度
folded_feature_map = layers.Reshape((*local_features.shape[1:-1], projection_dim))(
global_features
)
# 1x1卷积调整通道维度,与原始输入通道数匹配
folded_feature_map = conv_block(
folded_feature_map, filters=x.shape[-1], kernel_size=1, strides=strides
)
# 第四阶段:融合局部特征和全局特征
# 沿通道维度拼接原始输入和处理后的特征
local_global_features = layers.Concatenate(axis=-1)([x, folded_feature_map])
# 最终卷积调整输出通道数
local_global_features = conv_block(
local_global_features, filters=projection_dim, strides=strides
)
return local_global_features
def create_mobilevit(num_classes=5):
"""
创建MobileViT模型 - 轻量级视觉transformer,结合CNN和Transformer的优点
模型架构:
1. 输入层 - 接受RGB图像
2. 图像归一化 - 将像素值缩放到[0,1]范围
3. 初始卷积层 - 提取低级特征
4. Inverted Residual Blocks - 降低计算复杂度,类似MobileNetV2
5. MobileViT Blocks - 交替使用,捕获局部和全局特征
6. 全局平均池化 - 减少参数数量
7. 输出层 - 分类头
参数:
num_classes: 分类类别数量,默认为5
返回:
编译前的Keras模型
"""
# 输入层定义 - 接受指定大小的RGB图像
inputs = keras.Input((image_size, image_size, 3))
# 图像归一化 - 将像素值从[0,255]缩放到[0,1]范围
x = layers.Rescaling(scale=1.0 / 255)(inputs)
# 第一阶段:初始特征提取
# 使用默认3x3卷积核提取低级视觉特征
x = conv_block(x, filters=16)
# 第二阶段:使用Inverted Residual Blocks进行特征处理
# 这些块通过扩展通道维度并使用深度可分离卷积降低计算复杂度
x = inverted_residual_block(
x, expanded_channels=16 * expansion_factor, output_channels=16
)
# 下采样 - 步长为2,减小特征图尺寸,同时增加通道数
x = inverted_residual_block(
x, expanded_channels=16 * expansion_factor, output_channels=24, strides=2
)
# 连续使用Inverted Residual Blocks提取更丰富的局部特征
x = inverted_residual_block(
x, expanded_channels=24 * expansion_factor, output_channels=24
)
x = inverted_residual_block(
x, expanded_channels=24 * expansion_factor, output_channels=24
)
# 进一步下采样,增加通道数
x = inverted_residual_block(
x, expanded_channels=24 * expansion_factor, output_channels=48, strides=2
)
# 第三阶段:MobileViT块 - 结合CNN和Transformer的优势
# 第一个MobileViT块,使用2个Transformer子块和64维投影空间
x = mobilevit_block(x, num_blocks=2, projection_dim=64)
# 继续交替使用Inverted Residual Block和MobileViT Block
# 这种交替设计平衡了计算效率和全局特征提取能力
x = inverted_residual_block(
x, expanded_channels=64 * expansion_factor, output_channels=64, strides=2
)
# 第二个MobileViT块,使用4个Transformer子块以捕获更复杂的全局依赖
x = mobilevit_block(x, num_blocks=4, projection_dim=80)
# 进一步下采样和特征提取
x = inverted_residual_block(
x, expanded_channels=80 * expansion_factor, output_channels=80, strides=2
)
# 第三个MobileViT块,使用3个Transformer子块
x = mobilevit_block(x, num_blocks=3, projection_dim=96)
# 第四阶段:特征融合和分类
# 1x1卷积进行特征融合和维度调整
x = conv_block(x, filters=320, kernel_size=1, strides=1)
# 全局平均池化 - 减少特征维度,提高计算效率并减少过拟合
x = layers.GlobalAvgPool2D()(x)
# 输出层 - 全连接层配合softmax激活函数用于分类
outputs = layers.Dense(num_classes, activation="softmax")(x)
# 返回构建好的模型
return keras.Model(inputs, outputs)
mobilevit_xxs = create_mobilevit()
# ==============================================================================
# 数据集准备相关函数
# ==============================================================================
# 批量大小 - 控制每次训练迭代中使用的样本数量
batch_size = 64
# 自动调优 - 让TensorFlow自动选择最佳参数
auto = tf.data.AUTOTUNE
# 预处理时调整的较大尺寸 - 用于随机裁剪增强
resize_bigger = 280
# 分类类别数量 - 花数据集有5个类别
num_classes = 5
def preprocess_dataset(is_training=True):
"""
创建数据集预处理函数
参数:
is_training: 是否为训练集预处理,训练集需要数据增强
返回:
预处理函数,接收图像和标签,返回处理后的图像和标签
"""
def _pp(image, label):
if is_training:
# 训练集增强:
# 1. 先调整到更大尺寸
image = tf.image.resize(image, (resize_bigger, resize_bigger))
# 2. 随机裁剪到目标尺寸
image = tf.image.random_crop(image, (image_size, image_size, 3))
# 3. 随机水平翻转
image = tf.image.random_flip_left_right(image)
else:
# 验证集只需调整到目标尺寸
image = tf.image.resize(image, (image_size, image_size))
# 将标签转换为one-hot编码形式
label = tf.one_hot(label, depth=num_classes)
return image, label
return _pp
def prepare_dataset(dataset, is_training=True):
"""
准备数据集用于模型训练或评估
参数:
dataset: 原始数据集
is_training: 是否为训练集
返回:
处理好的批处理数据集
"""
if is_training:
# 训练集需要打乱数据顺序
dataset = dataset.shuffle(batch_size * 10)
# 应用预处理函数,使用并行调用提高效率
dataset = dataset.map(preprocess_dataset(is_training), num_parallel_calls=auto)
# 批处理并预取数据以加速训练
return dataset.batch(batch_size).prefetch(auto)
# 加载tf_flowers数据集,使用tensorflow_datasets
# 按90%/10%比例划分原始训练集为新的训练集和验证集
# as_supervised=True表示返回(image, label)格式的元组
train_dataset, val_dataset = tfds.load(
"tf_flowers", split=["train[:90%]", "train[90%:]"], as_supervised=True
)
# 计算训练集和验证集的样本数量
num_train = train_dataset.cardinality()
num_val = val_dataset.cardinality()
print(f"Number of training examples: {num_train}")
print(f"Number of validation examples: {num_val}")
# 应用数据集预处理函数
# 训练集使用数据增强,验证集不使用
train_dataset = prepare_dataset(train_dataset, is_training=True)
val_dataset = prepare_dataset(val_dataset, is_training=False)
# 训练配置
# -----------------------------------------------
# 学习率设置 - 控制模型权重更新的步长
learning_rate = 0.002
# 标签平滑因子 - 防止模型对标签过于自信,提高泛化能力
label_smoothing_factor = 0.1
# 训练轮次 - 整个数据集将被训练的次数
epochs = 30
# 创建优化器 - 使用Adam优化器,自适应学习率算法
optimizer = keras.optimizers.Adam(learning_rate=learning_rate)
# 创建损失函数 - 使用带标签平滑的交叉熵损失函数
loss_fn = keras.losses.CategoricalCrossentropy(label_smoothing=label_smoothing_factor)
# ==============================================================================
# 模型训练和评估
# ==============================================================================
def run_experiment(epochs=epochs):
"""
运行实验函数 - 处理模型创建、编译、训练和评估的完整流程
参数:
epochs: 训练轮次
返回:
训练好的模型
"""
# 重新创建模型实例
mobilevit_xxs = create_mobilevit(num_classes=num_classes)
# 编译模型 - 配置训练过程
# 1. 优化器: Adam
# 2. 损失函数: 带标签平滑的CategoricalCrossentropy
# 3. 评估指标: accuracy - 分类准确率
mobilevit_xxs.compile(optimizer=optimizer, loss=loss_fn, metrics=["accuracy"])
# 定义检查点回调 - 保存最佳模型权重
# checkpoint_filepath: 保存模型权重的文件路径
# monitor="val_accuracy": 监控验证准确率
# save_best_only=True: 只保存验证准确率最高的模型权重
# save_weights_only=True: 只保存模型权重,不保存整个模型结构
checkpoint_filepath = "/tmp/checkpoint.weights.h5"
checkpoint_callback = keras.callbacks.ModelCheckpoint(
checkpoint_filepath,
monitor="val_accuracy",
save_best_only=True,
save_weights_only=True,
)
# 开始模型训练
# train_dataset: 训练数据集
# validation_data: 验证数据集
# epochs: 训练轮次
# callbacks: 检查点回调函数
mobilevit_xxs.fit(
train_dataset,
validation_data=val_dataset,
epochs=epochs,
callbacks=[checkpoint_callback],
)
# 加载最佳模型权重
mobilevit_xxs.load_weights(checkpoint_filepath)
# 评估模型在验证集上的性能
_, accuracy = mobilevit_xxs.evaluate(val_dataset)
print(f"Validation accuracy: {round(accuracy * 100, 2)}%")
return mobilevit_xxs
# 执行实验流程
mobilevit_xxs = run_experiment()
# ==============================================================================
# 模型保存和部署
# ==============================================================================
# 保存模型为SavedModel格式
# 这种格式保存了完整的模型,包括模型结构、权重和优化器状态
# 保存路径: "mobilevit_xxs" 目录
# 用途: 用于后续的部署、推理、转换或继续训练
print("\n保存模型为SavedModel格式...")
tf.saved_model.save(mobilevit_xxs, "mobilevit_xxs")
print("模型保存完成!")
# TFLite模型转换 - 优化模型用于移动设备和边缘设备部署
# -----------------------------------------------
# 创建TFLite转换器
# 从SavedModel格式转换为TFLite格式
print("\n开始TFLite模型转换...")
converter = tf.lite.TFLiteConverter.from_saved_model("mobilevit_xxs")
# 应用默认优化
# 优化可以减少模型大小并提高推理性能
# 包括权重量化、操作融合等优化技术
converter.optimizations = [tf.lite.Optimize.DEFAULT]
# 指定支持的操作集
# 确保模型中的所有操作都能在目标平台上正常运行
# TFLITE_BUILTINS: TFLite原生操作
# SELECT_TF_OPS: 部分TensorFlow操作,用于处理TFLite不支持的操作
converter.target_spec.supported_ops = [
tf.lite.OpsSet.TFLITE_BUILTINS,
tf.lite.OpsSet.SELECT_TF_OPS,
]
# 执行模型转换
# 将Keras模型转换为轻量级的TFLite格式
# TFLite格式优势:
# 1. 更小的模型体积,适合资源受限设备
# 2. 优化的推理性能
# 3. 支持量化等高级优化技术
# 4. 可在移动设备、嵌入式设备上运行
tflite_model = converter.convert()
# 保存TFLite模型到文件
# 文件名: "mobilevit_xxs.tflite"
# 二进制格式,需要以二进制写入模式("wb")保存
with open("mobilevit_xxs.tflite", "wb") as f:
f.write(tflite_model)
print("TFLite模型转换完成!")
print("模型已保存为: mobilevit_xxs.tflite")
print("\n转换后的模型可在移动设备和边缘计算设备上部署使用。")

魔乐社区(Modelers.cn) 是一个中立、公益的人工智能社区,提供人工智能工具、模型、数据的托管、展示与应用协同服务,为人工智能开发及爱好者搭建开放的学习交流平台。社区通过理事会方式运作,由全产业链共同建设、共同运营、共同享有,推动国产AI生态繁荣发展。
更多推荐


 17
17 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)