深度学习实验——猴痘病识别
前一个实验还感觉自己熟悉了一点,但随着这次实验一些细小错误的出现才发现自己根本没有很好的理解一些内置函数的用法,感觉还越学越难了怎么说。。。不过对于搭建一个神经网络的流程已经比较熟悉了,接下来是尝试了解各种超参数的设置,尝试通过超参数的调整来提升训练效果。
- 🍨 本文为🔗365天深度学习训练营 中的学习记录博客
- 🍖 原作者:K同学啊
目录
一、实验
1、实验目的
①了解如何保存模型参数并保存训练过程中效果最好的模型参数
②加载保存的最佳模型参数识别本地的一张图片
③调整网络结构使测试集精度达到88%
2、相关知识点
①transforms.compose()函数详解
transforms.compose()是PyTorch中torchvision.transforms模块的一个重要函数,用于将多个图像变换操作组合在一起,形成一个连贯的数据预处理流水线,包括尺寸调整类、翻转旋转类、颜色变换类、标准化类等等,可以看这个博客
②class_to_dix
class_to_dix是PyTorch数据管道中的重要组成部分,它确保了类别名称和数字标签之间的一致性映射,在模型训练、评估和预测过程中都有很大的作用
③torch.squeeze()和torch.unsqueeze()
这两个函数都是用于改变张量的维度,squeeze()是移除大小为1的维度,用于"压缩"张量unsqueeze()则是插入大小为1的新维度,用于"扩展"张量
④为什么要保存并加载模型
保存并加载最优模型可以避免重复训练,多次使用,节省大量计算资源和时间,而且可以防止训练中断导致的数据丢失,如果利用预训练模型加速新任务开发的话也能实现迁移学习
本实验的网络结构
输入-卷积1-卷积2-池化1-卷积3-卷积4-池化2-view操作-全连接
实验结果
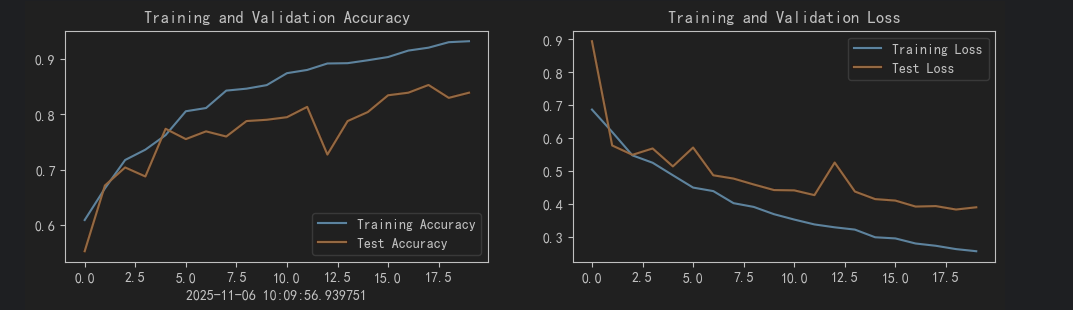
3、错误及解决方案
①TqdmWarning: IProgress not found. Please update jupyter and ipywidgets.
解决方法:还是版本问题,不用管,不影响后续程序的运行
②AttributeError: 'Conv2d' object has no attribute 'dim'
错误原因:在forward函数中中没有传入x导致维度出错了
③TypeError: view() received an invalid combination of arguments - got (float), but expected one of:
* (tuple of ints size)
didn't match because some of the arguments have invalid types: (!float!)
* (torch.dtype dtype)
didn't match because some of the arguments have invalid types: (!float!)
错误原因:这是因为在前文打字打快了,把“,”达成“.”了
④TypeError: 'builtin_function_or_method' object is not subscriptable
通常是因为对一个内置函数或方法对象使用了下标([])操作,但函数 / 方法本身不支持这种操作
错误原因:test_acc+=(target_pred.argmax(1)==target).type(torch.float).sum().item()
Argmax后面是()不是[]
4、总结
前一个实验还感觉自己熟悉了一点,但随着这次实验一些细小错误的出现才发现自己根本没有很好的理解一些内置函数的用法,感觉还越学越难了怎么说。。。不过对于搭建一个神经网络的流程已经比较熟悉了,接下来是尝试了解各种超参数的设置,尝试通过超参数的调整来提升训练效果
二、代码实现
1、前期准备
①导入库并设置GPU
import torch
import torch.nn as nn
import torchvision.transforms as transforms
import torchvision
from torchvision import datasets, transforms
import os,PIL,pathlib,random
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
device②导入数据
#先把data_dir转换为Path对象
data_dir='./data/'
data_dir=pathlib.Path(data_dir)
#把文件名存储到列表当中
data_paths=list(data_dir.glob('*'))
classeNames=[str(path).split("\\")[1] for path in data_paths]
print(classeNames)导入之后的结果如图所示

③将文件夹导入并对图片进行重塑
total_datadir='./data/'
#对输入图像进行操作
train_transforms=transforms.Compose([
transforms.Resize((224,224)),
transforms.ToTensor(),
transforms.Normalize(
mean=[0.485, 0.456, 0.406],
std=[0.229, 0.224, 0.225])
])
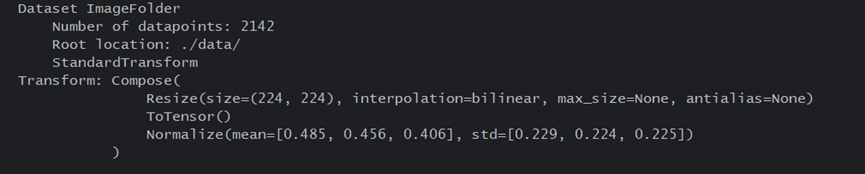
total_data=datasets.ImageFolder(total_datadir,transform=train_transforms)
total_data可以看到数据的结构
④对数据集进行划分
#开始划分数据集
train_size=int(0.8*len(total_data))
test_size=len(total_data)-train_size
train_dataset,test_dataset=torch.utils.data.random_split(total_data,[train_size,test_size])
train_dataset,test_dataset2、构建网络
*原理几乎跟前几次实验一样,因此省略代码只放结果了
①了解网络架构
输入-卷积1-卷积2-池化1-卷积3-卷积4-池化2-view操作-全连接
②实现并打印模型(可以清晰的看到网络构成)
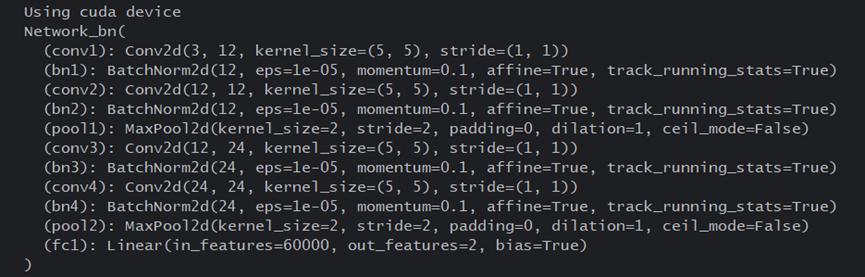
3、训练模型
*训练过程和前几次代码几乎一样,训练轮次为20,这里省略代码
总的来说可以分为以下几个部分以及需要注意的内容
①设置超参数:包括损失函数、学习率和优化器
②编写训练函数:梯度清零、反向传播、更新权重
③编写测试函数:不用传入优化器
④正式训练
训练结果如下
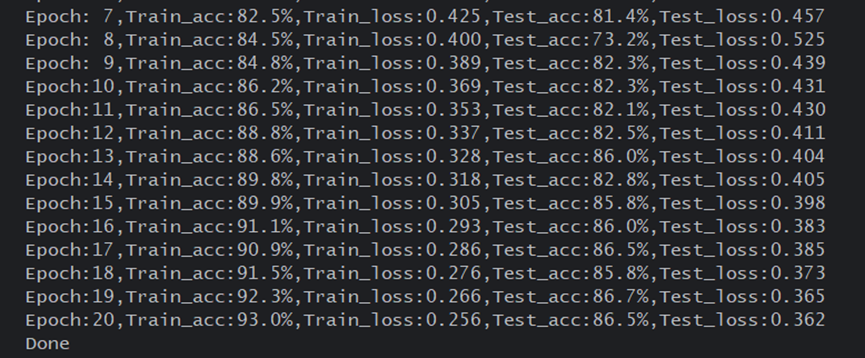
4、结果可视化
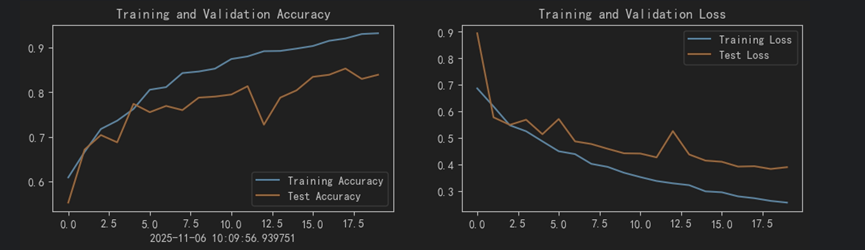
①损失变化图和精度变化图(该部分原理一致,省略代码)
②指定图片进行预测
#接下来指定图片进行预测
from PIL import Image
classes=list(total_data.class_to_idx)
def predict_one_image(image_path,model,transform,calsses):
test_img=Image.open(image_path).convert('RGB')
test_img=transform(test_img)
img=test_img.to(device).unsqueeze(0)
model.eval()
output=model(img)
_,pred=torch.max(output,1)
pred_class=classes[pred]
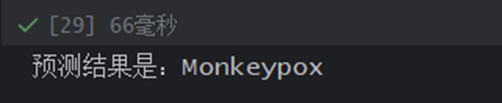
print(f'预测结果是:{pred_class}')#选择训练集当中的某张照片
predict_one_image(image_path='./data/Monkeypox/M06_02_05.jpg',
model=model,
transform=train_transforms,
calsses=classes)结果如图所示
5、保存并加载模型
#保存并加载模型
#首先是模型的保存
PATH='./model.pth'
torch.save(model.state_dict(), PATH)
#将参数加载到model当中
model.load_state_dict(torch.load(PATH,map_location=device))保存成功之后结果如图所示


魔乐社区(Modelers.cn) 是一个中立、公益的人工智能社区,提供人工智能工具、模型、数据的托管、展示与应用协同服务,为人工智能开发及爱好者搭建开放的学习交流平台。社区通过理事会方式运作,由全产业链共同建设、共同运营、共同享有,推动国产AI生态繁荣发展。
更多推荐


 22
22 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)