随机森林(RF)特征重要性排序 数据回归预测 matlab代码 替换自己的数据 上手简单 只代码
比如在房价预测里,把"面积"这个特征打乱,模型误差可能暴涨30%,而"离地铁站距离"打乱只涨5%,那明显面积更重要。这事儿对搞特征筛选的人来说贼方便,尤其是当你面对几百个特征不知道先砍哪个的时候。如果R²低于0.7,可能需要回去检查特征工程,或者加树的数量(把代码里的100调大到500试试)。但别无脑堆数量,超过500棵之后提升会越来越小,反而影响训练速度。特征重要性排完不是终点,建议用前5-10
随机森林(RF)特征重要性排序 数据回归预测 matlab代码 替换自己的数据 上手简单 只代码 不负责
直接甩代码前咱先唠两句。随机森林这玩意儿有个天然优势——训练完模型能顺手把特征重要性排名给吐出来。这事儿对搞特征筛选的人来说贼方便,尤其是当你面对几百个特征不知道先砍哪个的时候。
上Matlab代码(别慌,就10行):
% 老铁先把数据塞进来
data = readmatrix('你的数据.xlsx'); % 路径自己改
X = data(:,1:end-1); % 最后一列是y
y = data(:,end);
% 搓个随机森林
rf = TreeBagger(100, X, y, 'Method','regression', 'OOBPredictorImportance','on');
% 掏特征重要性
imp = rf.OOBPermutedPredictorDeltaError;
[~, idx] = sort(imp, 'descend');
% 画个直方图更直观
figure
bar(imp(idx))
xticks(1:length(imp))
xticklabels(rf.PredictorNames(idx))
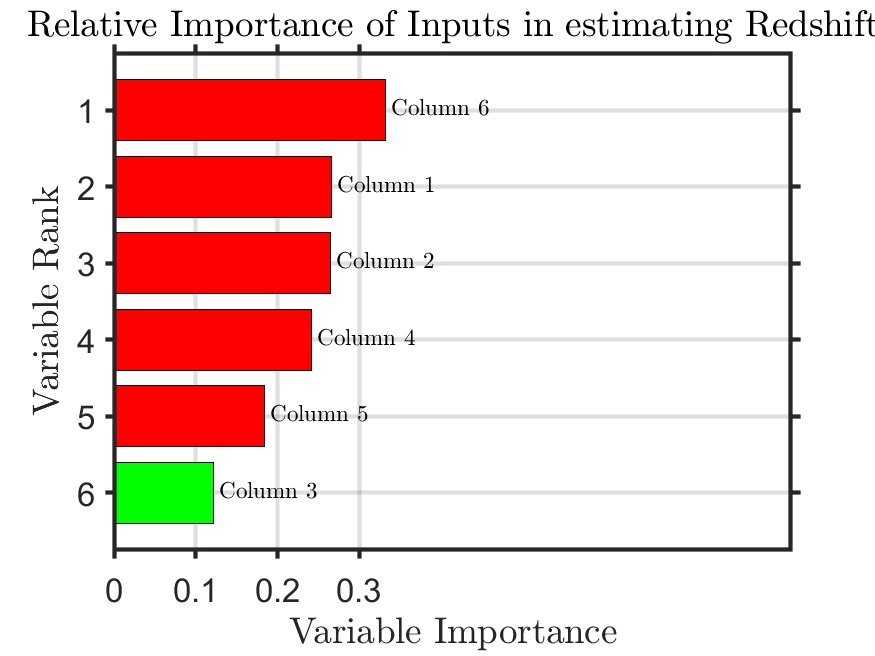
title('Feature Importance Ranking')重点说下OOBPermutedPredictorDeltaError这个参数。它表示打乱某个特征后,模型误差增加了多少。误差涨得越狠,说明这特征越重要。比如在房价预测里,把"面积"这个特征打乱,模型误差可能暴涨30%,而"离地铁站距离"打乱只涨5%,那明显面积更重要。
代码里藏了个小技巧:TreeBagger默认不返回特征名称,如果数据没有列名的话,建议在导入数据时用readtable代替readmatrix,然后保留列名。举个栗子:
data = readtable('房价数据.csv');
rf.PredictorNames = data.Properties.VariableNames(1:end-1); % 手动塞特征名新手常踩的坑是数据没预处理。随机森林虽然对量纲不敏感,但如果有缺失值还是会报错。建议加个清洗步骤:
% 删缺失行
data(any(ismissing(data),2),:) = [];
% 或者用均值填充
data = fillmissing(data,'constant',mean(data,'omitnan'));最后说下效果验证。训练完可以顺手算个R²:
y_pred = predict(rf, X);
rsq = 1 - sum((y - y_pred).^2)/sum((y - mean(y)).^2)如果R²低于0.7,可能需要回去检查特征工程,或者加树的数量(把代码里的100调大到500试试)。但别无脑堆数量,超过500棵之后提升会越来越小,反而影响训练速度。
特征重要性排完不是终点,建议用前5-10个重要特征重新训练模型,对比效果。有时候去掉冗余特征反而能提升模型泛化能力,尤其是在样本量少的时候。

魔乐社区(Modelers.cn) 是一个中立、公益的人工智能社区,提供人工智能工具、模型、数据的托管、展示与应用协同服务,为人工智能开发及爱好者搭建开放的学习交流平台。社区通过理事会方式运作,由全产业链共同建设、共同运营、共同享有,推动国产AI生态繁荣发展。
更多推荐



 15
15 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)