开源盛世!DeepSeek 2026 首篇论文,从 HC 到 FC 再到 mHC,破解残差连接瓶颈
从 Hyper-Connections 开启的高维连接,到 Frac-Connections 的效率优化,再到 DeepSeek 通过 mHC 引入的数学流形约束,神经网络的宏观架构设计正在经历从“暴力堆叠”向“精密路由”的进化。严谨结论:拓扑复杂性:单纯增加参数量已不再是 Scaling 的唯一路径,优化层间的信息路由宽度(Residual Stream Width)提供了新的增长点。约束的价值
引言:残差连接的局限性
在深度学习的十年演进中,ResNet 提出的残差连接(Residual Connection)是极深网络得以训练的基石。其标准形式为:
xl+1=xl+F(xl,Wl)x_{l+1} = x_l + F(x_l, W_l)xl+1=xl+F(xl,Wl)
虽然 Pre-Norm 和 Post-Norm 等变体在一定程度上缓解了梯度消失,但始终面临梯度稳定性与特征表征坍塌(Representation Collapse)之间的权衡。
一、 字节跳动:Hyper-Connections (HC) —— 开启高维残差时代

论文标题: HYPER-CONNECTIONS
论文链接: https://arxiv.org/abs/2409.19606
字节跳动 Seed 团队在论文 Hyper-Connections (arXiv:2409.19606) 中提出,不应将残差流局限于单一通道。HC 的核心是将残差流的宽度扩展 nnn 倍,并引入三个可学习的线性映射矩阵:HpreH_{pre}Hpre(读取)、HpostH_{post}Hpost(写入)和 HresH_{res}Hres(残差混合)。
核心演进公式:
xl+1=Hreslxl+Hpostl⊤F(Hprelxl,Wl)x_{l+1} = H_{res}^l x_l + H_{post}^{l\top} F(H_{pre}^l x_l, W_l)xl+1=Hreslxl+Hpostl⊤F(Hprelxl,Wl)
其中,xl∈Rn×Cx_l \in \mathbb{R}^{n \times C}xl∈Rn×C 是扩展后的残差流。通过这种方式,网络可以自主学习层与层之间的连接强度,解耦了计算量(FLOPs)与残差流宽度。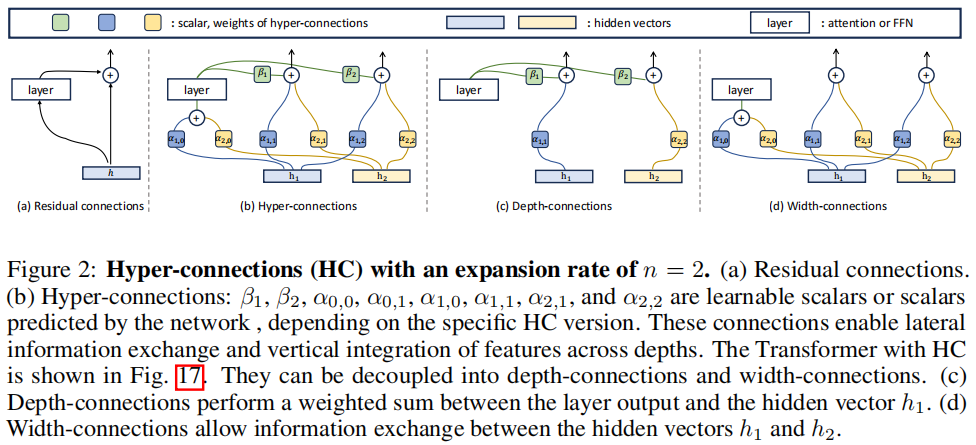
二、 轻量化演进:Frac-Connections (FC) —— 破解显存瓶颈

论文标题: Frac-Connections: Fractional Extension of Hyper-Connections
论文链接: https://arxiv.org/abs/2503.14125
尽管 HC 性能优异,但其通过复制副本扩展通道的方式带来了巨大的显存访问(I/O)开销。为此,字节跳动在后续工作 Frac-Connections (arXiv:2503.14125) 中提出了“分片(Split)”逻辑。
技术逻辑转变:
FC 不再通过 Repeat 操作增加宽度,而是将原始隐藏状态 h∈Rdh \in \mathbb{R}^dh∈Rd 直接分割为 mmm 个分片:
H=Reshape(h,(m,d/m))H = \text{Reshape}(h, (m, d/m))H=Reshape(h,(m,d/m))
这相当于将扩展率 nnn 推向了分数域(n=1/mn=1/mn=1/m)。FC 在保留了多路径连接(Width-connections)优势的同时,通过降低单路径的维度,实现了在不增加内存带宽负担的前提下增强模型表征能力
三、 DeepSeek 的解法:mHC —— 引入数学流形约束

DeepSeek 团队在将 HC 推向超大规模训练(如 27B 参数量)时发现,无约束的 HresH_{res}Hres 矩阵会导致严重的信号发散(Signal Explosion)。实验显示,HC 的 Amax Gain Magnitude(最大增益幅值)在深层网络中可达 3000 倍,导致训练崩溃。
在论文 mHC: Manifold-Constrained Hyper-Connections (arXiv:2512.24880) 中,DeepSeek 提出了流形约束方案。
1. 双随机矩阵约束(Doubly Stochastic Matrix)
为了恢复残差连接本质的“恒等映射”属性,mHC 要求残差映射矩阵 HresH_{res}Hres 必须落在 Birkhoff 多胞体(Birkhoff polytope)上:
Mres≔{M∈Rn×n∣M1n=1n,1n⊤M=1n⊤,M≥0}\mathcal{M}_{res} \coloneqq \{ M \in \mathbb{R}^{n \times n} \mid M\mathbf{1}_n = \mathbf{1}_n, \mathbf{1}_n^\top M = \mathbf{1}_n^\top, M \ge 0 \}Mres:={M∈Rn×n∣M1n=1n,1n⊤M=1n⊤,M≥0}
这意味着矩阵的每一行和每一列之和都必须为 1。
2. Sinkhorn-Knopp 迭代
为了在训练中动态满足上述约束,DeepSeek 引入了 Sinkhorn-Knopp 算法进行迭代归一化:
M(t)=Tr(Tc(M(t−1)))M^{(t)} = \mathcal{T}_r(\mathcal{T}_c(M^{(t-1)}))M(t)=Tr(Tc(M(t−1)))
这一约束确保了信号在通过多层传递时,其均值能够保持能量守恒,范数受到严格限制,从而消除了梯度爆炸风险。
四、 系统级优化:破解 I/O 墙
DeepSeek 的 mHC 方案不仅是数学上的改进,更是一套工程优化方案:
- Kernel Fusion:将 RMSNorm、线性映射与 Sinkhorn 迭代合并为一个 CUDA Kernel,减少显存读写。
- Selective Recomputing:针对 nnn 步残差流设计了分块重计算策略,通过公式 nL/(n+2)\sqrt{nL/(n+2)}nL/(n+2) 计算最优重计算块大小。
- DualPipe Overlap:在管道并行中,利用高优先级流(High Priority Stream)实现计算与通信的深度重叠。
五、 总结与观点
从 Hyper-Connections 开启的高维连接,到 Frac-Connections 的效率优化,再到 DeepSeek 通过 mHC 引入的数学流形约束,神经网络的宏观架构设计正在经历从“暴力堆叠”向“精密路由”的进化。
严谨结论:
- 拓扑复杂性:单纯增加参数量已不再是 Scaling 的唯一路径,优化层间的信息路由宽度(Residual Stream Width)提供了新的增长点。
- 约束的价值:DeepSeek 的工作证明,在大规模训练中,自由度的增加必须伴随严格的数学约束(如双随机流形),否则“灵活性”将转化为“不稳定性”。
- 软硬结合:未来的模型创新将高度依赖于如 TileLang 这样的底层算子开发工具,只有解决 I/O 瓶颈,先进的拓扑设计才能落地。

魔乐社区(Modelers.cn) 是一个中立、公益的人工智能社区,提供人工智能工具、模型、数据的托管、展示与应用协同服务,为人工智能开发及爱好者搭建开放的学习交流平台。社区通过理事会方式运作,由全产业链共同建设、共同运营、共同享有,推动国产AI生态繁荣发展。
更多推荐



 17
17 0
0- 0



 已为社区贡献20条内容
已为社区贡献20条内容

所有评论(0)