百度飞桨PaddleOCR在自己的数据库上微调全流程
一、数据准备
1.1 数据格式要求
PaddleOCR 识别模块支持两种主流数据格式, LMDB 格式,也支持简单易操作的 TXT 格式。
TXT 格式(入门首选)
• 数据目录结构:
train_data/
├── images/ # 存放所有训练图像
│ ├── img_1.jpg
│ ├── img_2.png
│ └── ...
├── train_label.txt # 训练集标注文件
└── val_label.txt # 验证集标注文件
• 标注文件格式(每行对应 1 张图像):
格式:图像相对路径\t标注文本(编码为UTF-8)
images/img_1.jpg\t身份证123456789012345678
images/img_2.png\t营业执照统一社会信用代码91110105MA01234567
如下图所示,分为两列,第一列为图像路径,第二列为图像内容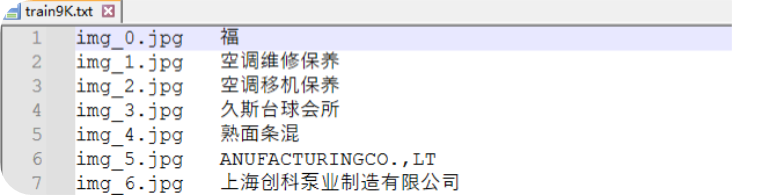
• 注意事项:
a. 图像路径与标注文本用 Tab 键(\t) 分隔,不可用空格
b. 标注文本需与图像实际内容完全一致,不可包含无关字符
c. 支持的图像格式:jpg、png、jpeg、bmp
1.2 数据集划分
• 比例要求:训练集:验证集 = 8:2 或 9:1
• 数据量建议:
d. 通用场景(如印刷体文字):至少 5000 张样本
e. 特定场景(如手写体、特殊字体):至少 10000 张样本
f. 小样本场景:可结合数据增强(见 1.3 节)补充至 3000 张以上
1.3 数据增强
PaddleOCR 内置数据增强策略,无需额外编码,可通过配置文件启用(见第三章),核心增强方式:
• 常用增强:随机裁剪、亮度 / 对比度调整、高斯模糊、随机旋转(±3°)
• 文本相关增强:文本拉伸、文本模糊、随机加噪
• 配置建议:小样本场景启用全部增强,大数据集可仅启用基础增强
二、环境配置
已经配置好环境的直接略过,去往第三章节。
2.1 基础环境要求
依赖项 版本要求
Python 3.10
PaddlePaddle 2.5.0
PaddleOCR 2.8.0
CUDA 11.8
CUDNN 9.4.0
NCCL 2.21.5
配置NIVIDIA环境
export PATH="$HOME/env/cuda_nvcc-linux-x86_64-11.8.89-archive/bin:$PATH"
export LD_LIBRARY_PATH="$HOME/env/cuda_nvcc-linux-x86_64-11.8.89-archive/lib:$LD_LIBRARY_PATH"
export XLA_FLAGS=--xla_gpu_cuda_data_dir="$HOME/env/cuda_nvcc-linux-x86_64-11.8.89-archive"
export PATH="$HOME/env/cudnn-linux-x86_64-9.4.0.58_cuda11-archive/bin:$PATH"
export LD_LIBRARY_PATH="$HOME/env/cudnn-linux-x86_64-9.4.0.58_cuda11-archive/lib:$LD_LIBRARY_PATH"
export LD_LIBRARY_PATH="$HOME/env/nccl_2.21.5-1+cuda11.0_x86_64/lib:$LD_LIBRARY_PATH"
export PATH="$PATH:$HOME/env/ffmpeg-N-118385-g0225fe857d-linux64-gpl/bin"
export LD_LIBRARY_PATH="$HOME/env/lib_so:$LD_LIBRARY_PATH"
检查nvcc版本
(py310_env) test@aitest:~/PaddleOCR-release-2.8$ nvcc --version
nvcc: NVIDIA (R) Cuda compiler driver
Copyright (c) 2005-2022 NVIDIA Corporation
Built on Wed_Sep_21_10:33:58_PDT_2022
Cuda compilation tools, release 11.8, V11.8.89
Build cuda_11.8.r11.8/compiler.31833905_0
2.2 预训练模型下载
微调需基于 PaddleOCR 提供的预训练模型,避免从零训练,下载地址:
• 官方模型库:
PaddleOCR: 基于飞桨的OCR和文档解析工具库,包含文字识别PP-OCR系列模型、文档解析PaddleOCR-VL、PP-Structure系列方案和关键信息抽取PP-ChatOCR系列方案 - Gitee.com
https://gitee.com/link?target=https%3A%2F%2Fpaddleocr.bj.bcebos.com%2FPP-OCRv4%2Fchinese%2Fch_PP-OCRv4_rec_train.tar
下载后解压至指定目录(如./pretrained_models/),目录结构如下:
pretrained_models/
└── ch_PP-OCRv4_rec_train/
├── student.pdparams
三、配置文件修改
PaddleOCR 微调通过配置文件指定数据集、模型、训练参数,核心配置文件路径:PaddleOCR-release-2.8/configs/rec/PP-OCRv4/ch_PP-OCRv4_rec.yml(中文识别)。
3.1 数据集配置
修改Train和Eval部分,指定数据格式和路径:
Train:
dataset:
name: MultiScaleDataSet
ds_width: false
data_dir: ./train_data/chdata/images20W
ext_op_transform_idx: 1
label_file_list:
- ./train_data/chdata/train20W.txt
transforms:
- DecodeImage:
img_mode: BGR
channel_first: false
- RecConAug:
prob: 0.5
ext_data_num: 2
image_shape: [48, 320, 3]
max_text_length: *max_text_length
- RecAug:
- MultiLabelEncode:
gtc_encode: NRTRLabelEncode
- KeepKeys:
keep_keys:
- image
- label_ctc
- label_gtc
- length
- valid_ratio
sampler:
name: MultiScaleSampler
scales: [[320, 32], [320, 48], [320, 64]]
first_bs: &bs 128
fix_bs: false
divided_factor: [8, 16] # w, h
is_training: True
loader:
shuffle: true
batch_size_per_card: *bs
drop_last: true
num_workers: 8
Eval:
dataset:
name: SimpleDataSet
data_dir: ./train_data/chdata/images20W
label_file_list:
- ./train_data/chdata/val5K.txt
transforms:
- DecodeImage:
img_mode: BGR
channel_first: false
- MultiLabelEncode:
gtc_encode: NRTRLabelEncode
- RecResizeImg:
image_shape: [3, 48, 320]
- KeepKeys:
keep_keys:
- image
- label_ctc
- label_gtc
- length
- valid_ratio
loader:
shuffle: false
drop_last: false
batch_size_per_card: 20
num_workers: 4
data_dir:图像文件夹
label_file_list:txt文件路径
batch_size_per_card:batchsize大小
num_workers:几个线程加载数据
注意:data_dir的值和 label_file_list第一列的值组合需要是完整的图像路径
即./train_data/chdata/images20W+./train_data/chdata/train20W.txt里按照行读取的第一列的值是完整的图像路径
3.2 模型配置
指定预训练模型路径和输出路径:
Global:
debug: false
use_gpu: true
epoch_num: 200
log_smooth_window: 20
print_batch_step: 100
save_model_dir: ./output/rec_ppocr_v4
save_epoch_step: 20
eval_batch_step: [0, 2000]
cal_metric_during_train: true
pretrained_model: /SE/py_module/shh/PaddleOCR-release-2.8/pretrained_model/ch_PP-OCRv4_rec_train/student.pdparams
checkpoints:
save_inference_dir:
use_visualdl: false
infer_img: doc/imgs_words/ch/word_1.jpg
character_dict_path: ppocr/utils/ppocr_keys_v1.txt
max_text_length: &max_text_length 25
infer_mode: false
use_space_char: true
distributed: true
save_res_path: ./output/rec/predicts_ppocrv3.txt
use_gpu: true #启动gpu
epoch_num: 200 #训练轮数
print_batch_step: 100 #每100步打印一次
save_model_dir: ./output/rec_ppocr_v4 #中间模型输出路径文件夹
save_epoch_step: 20 #每20个epoch保存一次模型参数
eval_batch_step: [0, 2000]#从第0步开始,每训练2000步就验证一次,并保存验证集最好的模型
pretrained_model: #下载的预训练模型
character_dict_path:#字典路径
3.3 训练超参数配置
根据数据量和硬件调整:
Optimizer:
name: Adam
beta1: 0.9
beta2: 0.999
lr:
name: Cosine
learning_rate: 0.00001
warmup_epoch: 5
regularizer:
name: L2
factor: 3.0e-05
learning_rate: 学习率
warmup_epoch: 学习率预热轮数,避免一开始学习率较大
四、启动微调训练
4.1 训练命令
在 PaddleOCR 根目录执行以下命令,启动训练:
单卡训练
python3 tools/train.py -c configs/rec/PP-OCRv4/ch_PP-OCRv4_rec.yml -o Global.pretrained_model=./pretrained_models/ch_PP-OCRv4_rec_train/student
多卡训练
python3 -m paddle.distributed.launch --gpus '0,1' tools/train.py -c configs/rec/PP-OCRv4/ch_PP-OCRv4_rec.yml -o Global.pretrained_model=./pretrained_models/ch_PP-OCRv4_rec_train/student
• 参数说明:
◦ -c:指定配置文件路径
◦ -o:覆盖配置文件中的参数(优先级高于配置文件)
◦ --gpus:指定使用的 GPU 卡号(多卡时用逗号分隔)
4.2 训练过程监控
训练日志输出示例:
[2025/11/04 17:35:09] ppocr INFO: epoch: [1/200], global_step: 100, lr: 0.000000, acc: 0.414062, norm_edit_dis: 0.664962, CTCLoss: 18.261278, NRTRLoss: 2.635521, loss: 20.873051, avg_reader_cost: 0.10939 s, avg_batch_cost: 0.34546 s, avg_samples: 49.28, ips: 142.64952 samples/s, eta: 12:32:31, max_mem_reserved: 12494 MB, max_mem_allocated: 8514 MB
[2025/11/04 17:35:39] ppocr INFO: epoch: [1/200], global_step: 200, lr: 0.000001, acc: 0.405506, norm_edit_dis: 0.665934, CTCLoss: 20.458240, NRTRLoss: 2.684018, loss: 23.159084, avg_reader_cost: 0.08147 s, avg_batch_cost: 0.29976 s, avg_samples: 45.88, ips: 153.05334 samples/s, eta: 11:42:13, max_mem_reserved: 12494 MB, max_mem_allocated: 8514 MB
# 验证集准确率
[2025/11/04 17:39:34] ppocr INFO: cur metric, acc: 0.6037244681543363, norm_edit_dis: 0.759965194531697, fps: 899.3473670254149
[2025/11/04 17:39:35] ppocr INFO: save best model is to ./output/rec_ppocr_v4/icdar2017_best_model1104/best_accuracy
[2025/11/04 17:39:35] ppocr INFO: best metric, acc: 0.6037244681543363, is_float16: False, norm_edit_dis: 0.759965194531697, fps: 899.3473670254149, best_epoch: 2
• 关键指标:
◦ acc:识别准确率(越高越好),预测结果和真值比较,完全一样才行
◦ loss:训练损失(逐步下降至稳定)
◦ norm_edit_dis:编辑距离(越低越好,衡量预测与真实标签的差异)
模型输出

4.3 断点续训
若训练中断,可通过以下命令续训(自动加载最新保存的模型):
python3 -m paddle.distributed.launch --gpus '1' tools/train.py -c configs/rec/PP-OCRv4/ch_PP-OCRv4_rec.yml -o Global.checkpoints=./output/rec_ppocr_v4/best_model/model
不用加模型后缀
五、模型评估与推理
5.1 模型评估
训练完成后,使用验证集评估模型性能:
python3 -m paddle.distributed.launch --gpus '0' tools/eval.py -c configs/rec/PP-OCRv4/ch_PP-OCRv4_rec_test.yml -o Global.checkpoints=./output/rec_ppocr_v4/best_model/model
加载最优模型,不用加模型后缀
评估输出示例:
[2025/11/11 13:35:41] ppocr INFO: metric eval ***************
[2025/11/11 13:35:41] ppocr INFO: acc:0.6341500991922483
[2025/11/11 13:35:41] ppocr INFO: norm_edit_dis:0.7898709468674697
[2025/11/11 13:35:41] ppocr INFO: fps:805.4414229878968
LAUNCH INFO 2025-11-11 13:35:42,421 Pod completed
LAUNCH INFO 2025-11-11 13:35:42,421 Exit code 0
5.2 模型推理(测试单张图像)
使用微调后的模型识别单张图像:
python3 tools/infer_rec.py -c configs/rec/PP-OCRv4/ch_PP-OCRv4_rec.yml -o Global.pretrained_model=./output/rec_ppocr_v4/best_model/model Global.infer_img=doc/imgs_words/ch/word_3.jpg
不用加模型后缀
推理输出示例:
Predicted text: 营业执照统一社会信用代码91110105MA01234567, Score: 0.987
• Score:识别置信度(越高越可靠,通常≥0.8 为有效识别)
5.3 模型导出(部署用)
将训练后的模型导出为推理模型(支持 C++/Python 部署):
python3 tools/export_model.py -c configs/rec/PP-OCRv4/ch_PP-OCRv4_rec.yml -o Global.pretrained_model=./output/rec_ppocr_v4/best_model/model Global.save_inference_dir=./output/rec_ppocr_v4/my_model/
指定到文件夹即可。
导出后目录结构:
my_model/
├── inference.pdiparams
├── inference.pdiparams.info
└── inference.pdmodel

5.4 导出模型推理
python3 tools/infer/predict_rec.py --image_dir=./doc/imgs_words/ch/word_3.jpg --rec_model_dir=./output/rec_ppocr_v4/my_model/
指定到文件夹即可
也可直接调用
ocr = PaddleOCR(
use_angle_cls=True,
lang='ch',
use_gpu= True if int(gpu_id) >= 0 else False,
gpu_id= int(gpu_id),
det_model_dir=project_dir + '/pkg/ocr_model/det_model/',
cls_model_dir=project_dir + '/pkg/ocr_model/cls_model/',
rec_model_dir=./output/rec_ppocr_v4/my_model/, #自己训练并导出的识别模型路径
)
六、常见问题排查
6.1 训练报错:找不到图像 / 标注文件
• 检查data_dir和label_file_list路径是否正确(相对路径基于 PaddleOCR 根目录)
• 标注文件中图像路径是否与实际文件一致(区分大小写)
• 标注文件编码是否为 UTF-8(避免中文乱码)
6.2 训练不收敛(loss 不下降 / 准确率低)
• 数据量不足:增加样本数或加强数据增强
• 学习率过高 / 过低:调整learning_rate(建议 0.000001~0.00001)
• 预训练模型不匹配:确认预训练模型与配置文件对应(如中文模型对应中文配置)
• 标注错误:检查标注文本与图像内容是否一致,剔除错误标注
6.3 GPU 显存不足
• 减小batch_size_per_card(如从 64 调整为 32/16)
• 减小输入图像尺寸(如image_shape: [3, 32, 256])
• 关闭不必要的数据增强(如RecConAug)
6.4 推理结果错误较多
• 验证集与测试集场景差异过大:增加测试集对应场景的训练样本
• 字符集缺失:检查字典文件是否包含所有待识别字符
• 图像质量问题:预处理测试图像(如去模糊、调整亮度)
附录:
完整可用ch_PP-OCRv4_rec.yml内容
Global:
debug: false
use_gpu: true
epoch_num: 200
log_smooth_window: 20
print_batch_step: 100
save_model_dir: ./output/rec_ppocr_v4
save_epoch_step: 20
eval_batch_step: [0, 2000]
cal_metric_during_train: true
pretrained_model: /SE/py_module/shh/PaddleOCR-release-2.8/pretrained_model/ch_PP-OCRv4_rec_train/student.pdparams
checkpoints:
save_inference_dir:
use_visualdl: false
infer_img: doc/imgs_words/ch/word_1.jpg
character_dict_path: ppocr/utils/ppocr_keys_v1.txt
max_text_length: &max_text_length 25
infer_mode: false
use_space_char: true
distributed: true
save_res_path: ./output/rec/predicts_ppocrv3.txt
Optimizer:
name: Adam
beta1: 0.9
beta2: 0.999
lr:
name: Cosine
learning_rate: 0.00001
warmup_epoch: 5
regularizer:
name: L2
factor: 3.0e-05
Architecture:
model_type: rec
algorithm: SVTR_LCNet
Transform:
Backbone:
name: PPLCNetV3
scale: 0.95
Head:
name: MultiHead
head_list:
- CTCHead:
Neck:
name: svtr
dims: 120
depth: 2
hidden_dims: 120
kernel_size: [1, 3]
use_guide: True
Head:
fc_decay: 0.00001
- NRTRHead:
nrtr_dim: 384
max_text_length: *max_text_length
Loss:
name: MultiLoss
loss_config_list:
- CTCLoss:
- NRTRLoss:
PostProcess:
name: CTCLabelDecode
Metric:
name: RecMetric
main_indicator: acc
Train:
dataset:
name: MultiScaleDataSet
ds_width: false
data_dir: ./train_data/chdata/images20W
ext_op_transform_idx: 1
label_file_list:
- ./train_data/chdata/train20W.txt
transforms:
- DecodeImage:
img_mode: BGR
channel_first: false
- RecConAug:
prob: 0.5
ext_data_num: 2
image_shape: [48, 320, 3]
max_text_length: *max_text_length
- RecAug:
- MultiLabelEncode:
gtc_encode: NRTRLabelEncode
- KeepKeys:
keep_keys:
- image
- label_ctc
- label_gtc
- length
- valid_ratio
sampler:
name: MultiScaleSampler
scales: [[320, 32], [320, 48], [320, 64]]
first_bs: &bs 128
fix_bs: false
divided_factor: [8, 16] # w, h
is_training: True
loader:
shuffle: true
batch_size_per_card: *bs
drop_last: true
num_workers: 8
Eval:
dataset:
name: SimpleDataSet
data_dir: ./train_data/chdata/images20W
label_file_list:
- ./train_data/chdata/val5K.txt
transforms:
- DecodeImage:
img_mode: BGR
channel_first: false
- MultiLabelEncode:
gtc_encode: NRTRLabelEncode
- RecResizeImg:
image_shape: [3, 48, 320]
- KeepKeys:
keep_keys:
- image
- label_ctc
- label_gtc
- length
- valid_ratio
loader:
shuffle: false
drop_last: false
batch_size_per_card: 20
num_workers: 4

魔乐社区(Modelers.cn) 是一个中立、公益的人工智能社区,提供人工智能工具、模型、数据的托管、展示与应用协同服务,为人工智能开发及爱好者搭建开放的学习交流平台。社区通过理事会方式运作,由全产业链共同建设、共同运营、共同享有,推动国产AI生态繁荣发展。
更多推荐


 26
26 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)