机器学习026:无监督学习【聚类算法】(DBSCAN)-- 像找“人群聚集地”一样发现数据中的自然群体
像人眼一样直观地发现数据中的自然聚集,不强行分割,也不遗漏异常。理解密度思想:忘掉“距离中心点远近”,记住“周围邻居多少”掌握三个角色:核心点、边界点、噪声点——这是理解算法的钥匙学会参数调节:ε和MinPts不是魔法数字,需要根据数据特点调整明确适用场景:知道什么时候该用DBSCAN,什么时候该选其他算法实践出真知:只有亲手在数据上尝试,才能真正理解算法的行为DBSCAN之美在于它的直观性。
生活中的“物以类聚”
想象一下周末的公园:孩子们聚集在游乐设施周围,跑步爱好者在跑道上形成流动的人群,老年人在树荫下围坐聊天,野餐的家庭散布在草地上……这些“人群”自然而然地形成了,彼此之间有着明显的空隙。
现在假设你是城市规划者,需要分析公园监控录像,找出这些人群聚集的热点区域,以便合理配置垃圾桶、休息椅和保安巡逻路线。你会怎么找?
一种方法是画格子:把公园分成大小相等的方格,统计每个方格的人数。但这样很笨拙——跑步道上的“人群”是长条形的,野餐区的人群是松散散布的,固定大小的方格要么捕捉不到真实群体,要么会把原本分开的群体硬凑在一起。
另一种更聪明的方法是这样:“以人为中心,看每个人周围有没有足够多的邻居,如果邻居够多,就认为这是一个密集区域,然后把这些密集区域连起来。” 这正是DBSCAN(Density-Based Spatial Clustering of Applications with Noise,基于密度的噪声应用空间聚类)算法的核心思想。
作为人工智能领域最经典、最直观的聚类算法之一,DBSCAN不需要预先指定要分多少组(这点比K-means强),能够发现任意形状的群体,还能识别出那些不属于任何群体的“孤独者”(噪声点)。今天,就让我们一起揭开这个算法的神秘面纱。
分类归属:DBSCAN在机器学习体系中的位置
首先明确一点:DBSCAN不是神经网络,它是一种无监督学习算法,属于聚类算法家族。让我们从几个维度来定位它:
从学习方式划分:属于无监督学习。与需要标签的监督学习不同,DBSCAN只输入数据,不告诉它“正确答案”,让它自己发现数据中的内在结构。
从算法原理划分:属于基于密度的聚类算法。与K-means(基于距离中心点的距离划分)和层次聚类(基于数据点间的距离层次合并)不同,DBSCAN的核心是“密度”——它寻找数据空间中那些“点密集”的区域。
从输出结果划分:能够识别任意形状的聚类,并且能分离噪声点。这是它最独特的能力之一。
从使用场景划分:主要用于探索性数据分析和数据预处理,帮助我们发现数据中的自然分组,识别异常值。
底层原理:三步理解DBSCAN如何工作
第一步:核心概念的生活化类比
理解DBSCAN只需要掌握三个核心概念,我用小区邻里关系来类比:
1. 核心点(Core Point)—— “人缘好的人”
- 定义:以某个点为中心,在指定半径(ε)内有至少指定数量(MinPts)邻居的点
- 生活类比:老张家——以他家为圆心,步行5分钟范围内有至少8户关系好的邻居,老张就是“核心点”
2. 边界点(Border Point)—— “朋友不多但被接纳的人”
- 定义:在核心点的邻域内,但自己邻域内邻居不足MinPts的点
- 生活类比:小王家——老张家步行5分钟范围内的小王,但以小王自己为中心,5分钟内只有3户邻居(不到8户)。小王是“边界点”,属于老张这个群体
3. 噪声点(Noise Point)—— “独居或社交圈独立的人”
- 定义:既不是核心点,也不在任何核心点邻域内的点
- 生活类比:独居在小区边缘的李爷爷,附近没什么邻居,也不属于任何邻里圈子
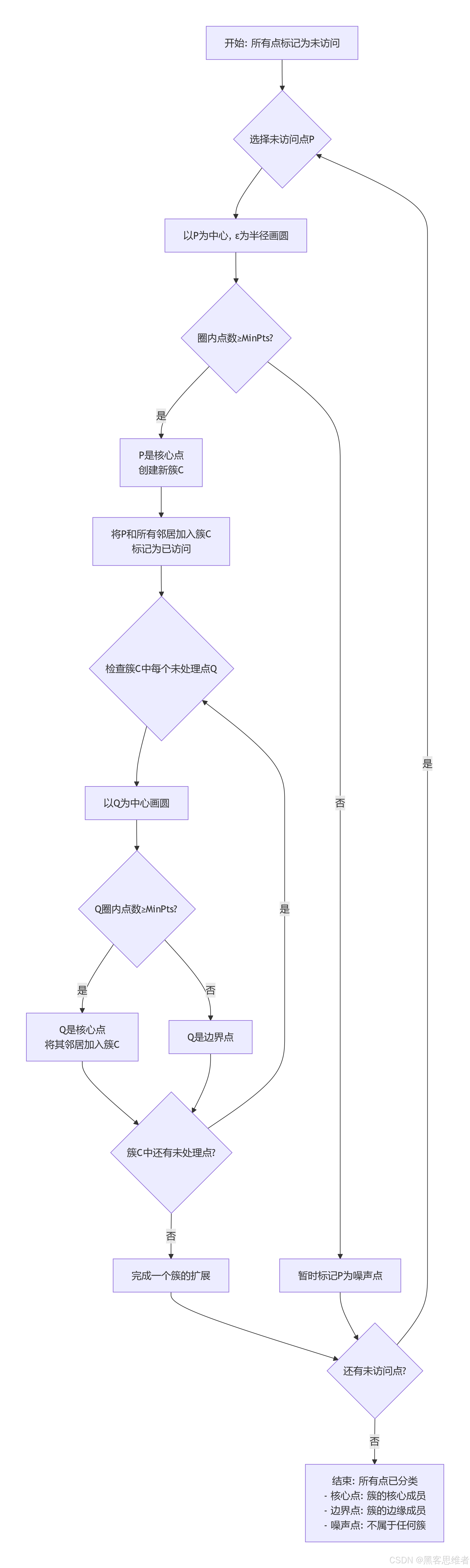
第二步:DBSCAN的工作流程(文字描述)
DBSCAN算法的执行就像“传染病的扩散”:
- 随机选择起点:从数据集中随便选一个还没被检查的点
- 判断是否核心点:以这个点为圆心,ε为半径画个圆,数数圈里有多少个点(包括自己)
- 如果点数 ≥ MinPts → 这是核心点,创建一个新簇(群体)
- 如果点数 < MinPts → 暂时标记为噪声点(可能后面会被重新分类)
- 密度扩展:如果找到了核心点,就开始“传染”:
- 把这个核心点的所有邻居(半径ε内的点)都加入当前簇
- 对每个新加入的点,如果它也是核心点,就把它的邻居也加进来
- 不断重复,直到不能再扩展为止
- 重复过程:选择下一个未被访问的点,重复上述过程
- 最终结果:
- 所有核心点和边界点被分配到各个簇中
- 剩下的噪声点不属于任何簇
第三步:用Mermaid图示理解算法
第四步:核心公式(简单理解)
虽然DBSCAN的核心思想很直观,但也有简单的数学表达:
-
距离函数:通常使用欧几里得距离
distance(p, q) = √[(x₁-x₂)² + (y₁-y₂)² + ...]就是两点间的直线距离
-
ε-邻域:点p的ε邻域是所有距离p小于ε的点的集合
N_ε(p) = {q ∈ 数据集 | distance(p, q) ≤ ε} -
核心点条件:
IF |N_ε(p)| ≥ MinPts THEN p是核心点其中|N_ε§|表示p的ε邻域中点的数量
局限性:DBSCAN的“力所不及”
DBSCAN虽然强大,但也有它的局限性。理解这些局限性,能帮助我们在正确的地方使用它:
1. 对参数敏感——“望远镜的调焦问题”
DBSCAN有两个关键参数:ε(半径)和MinPts(最小邻居数)。这两个参数需要人工设置,而且对结果影响很大:
- ε太小:每个点都成不了核心点,全是噪声(就像用显微镜看人群,每个人都离得很远)
- ε太大:所有点都连成一片,变成一个簇(就像用望远镜看人群,所有人挤成一团)
- MinPts太小:噪声点可能被误认为小簇
- MinPts太大:真正的簇可能被拆散
初学者建议:通常MinPts可以设为数据维度×2,ε可以通过“k距离图”来估计。
2. 处理密度不均的数据困难——“平原和山脉的差异”
如果数据中不同簇的密度差异很大,DBSCAN很难同时处理好:
- 设置ε适应密集区域 → 稀疏区域可能被当成噪声
- 设置ε适应稀疏区域 → 密集区域会合并成一个超大簇
类比:用同样的“人群密度标准”去分析市中心商业区(高密度)和郊区住宅区(低密度),很难得到合理结果。
3. 对高维数据效果下降——“维度的诅咒”
当数据维度很高时(比如超过10维),所有点之间的距离都趋于相似,基于距离的密度概念失效。
简单解释:在二维平面(长、宽)上,点与点之间距离差异明显;但在100维空间中,几乎所有点之间的距离都差不多,很难区分“密集”和“稀疏”。
4. 计算复杂度较高——“人海战术的代价”
DBSCAN需要计算每个点之间的距离,时间复杂度大致为O(n²),对于大数据集可能较慢。
使用范围:何时该用DBSCAN?
适合使用DBSCAN的场景:
- 数据有噪声/异常值:DBSCAN能自动识别并分离噪声点
- 簇的形状不规则:能发现任意形状的簇,不只是圆形
- 不知道簇的数量:无需预先指定要分多少类
- 空间/地理数据:天然适合基于距离的密度聚类
- 探索性数据分析:想了解数据中自然形成的分组
不适合使用DBSCAN的场景:
- 数据维度非常高:通常维度>10时效果下降明显
- 簇的密度差异很大:很难用一个ε参数处理好所有簇
- 对计算速度要求极高:大数据集上可能较慢
- 需要严格的簇划分:边界点可能同时靠近多个核心点,划分有一定模糊性
- 数据是球形分布且密度均匀:此时K-means更简单高效
应用场景:DBSCAN在现实世界中的应用
1. 城市规划:共享单车停放热点识别
问题:共享单车公司需要知道城市中哪些区域是高频使用区,以便合理调度车辆和设置推荐停车点。
DBSCAN的作用:
- 输入:一段时间内所有单车GPS位置数据
- 使用DBSCAN识别密集停放区域(热点)
- 区分偶尔停放(噪声)和长期聚集(簇)
- 输出:热点区域位置、大小和密度
价值:优化车辆调度,减少“有车无桩”或“有桩无车”的情况。
2. 电商平台:异常交易检测
问题:电商需要识别可能存在的刷单、欺诈交易。
DBSCAN的作用:
- 输入:交易数据(时间、金额、商品数量、用户行为序列等)
- 将正常交易聚成若干簇(不同购买模式)
- 识别离所有簇都很远的点 → 可能是异常交易
- 进一步人工审查这些异常点
价值:减少欺诈损失,维护平台公平性。
3. 天文学:星系团发现
问题:天文望远镜产生海量星空图像数据,需要自动识别星系团。
DBSCAN的作用:
- 输入:星体在天空中的位置坐标
- 识别密集的星体聚集区域 → 可能是星系团
- 区分前景星(相对稀疏)和背景星系团(密集)
- 能发现各种形状的星系团,不限于圆形
价值:自动化天文发现,处理人力无法处理的海量数据。
4. 医疗诊断:医学图像分析
问题:在病理切片图像中识别癌细胞聚集区域。
DBSCAN的作用:
- 输入:图像中检测到的细胞位置和特征
- 识别异常细胞密集区域(可能癌变区域)
- 区分孤立的异常细胞(可能是噪声)和真正的病灶
- 帮助医生重点关注可疑区域
价值:辅助早期癌症诊断,提高诊断效率和准确性。
5. 社交网络:社区发现
问题:在社交网络中找出紧密联系的用户群体。
DBSCAN的作用:
- 输入:用户互动数据(关注、点赞、评论、转发)
- 将频繁互动的用户聚类成社区
- 识别边缘用户和“社交孤岛”
- 发现社区的核心成员(核心点)和外围成员(边界点)
价值:精准推荐好友,理解社区结构,改善用户体验。
Python实践案例:用DBSCAN分析城市餐厅分布
让我们通过一个完整的Python示例,看看DBSCAN如何实际工作。这个案例中,我们将分析一个虚拟城市的餐厅位置数据,发现餐饮聚集区。
# 导入必要的库
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
from sklearn.cluster import DBSCAN
from sklearn.preprocessing import StandardScaler
from sklearn.datasets import make_moons # 生成模拟数据
# 设置中文字体(如果需要显示中文)
plt.rcParams['font.sans-serif'] = ['SimHei'] # 用来正常显示中文标签
plt.rcParams['axes.unicode_minus'] = False # 用来正常显示负号
# 1. 生成模拟数据:假设这是城市中餐厅的经纬度坐标
# 在实际应用中,这里应该是真实的餐厅位置数据
np.random.seed(42) # 设置随机种子,确保结果可重复
# 生成三个不同密度和形状的餐厅聚集区
# 区域1:市中心美食街(高密度,线状分布)
street_points = np.array([[i + np.random.normal(0, 0.1),
np.random.normal(5, 0.5)]
for i in np.linspace(1, 5, 30)])
# 区域2:购物中心美食广场(中等密度,团状分布)
mall_points = np.random.normal([8, 8], [0.6, 0.6], (40, 2))
# 区域3:郊区特色餐厅(低密度,松散分布)
suburb_points = np.random.uniform([2, 10], [4, 12], (20, 2))
# 一些孤立的餐厅(噪声点)
noise_points = np.random.uniform([0, 0], [10, 14], (15, 2))
# 合并所有数据
restaurant_data = np.vstack([street_points, mall_points, suburb_points, noise_points])
print(f"餐厅数据形状: {restaurant_data.shape}")
print(f"前5个餐厅坐标:\n{restaurant_data[:5]}")
# 2. 数据标准化(使不同维度的量纲一致)
scaler = StandardScaler()
data_scaled = scaler.fit_transform(restaurant_data)
# 3. 应用DBSCAN聚类
# 参数说明:
# eps: 邻域半径,这里设为0.3(经过标准化后的距离)
# min_samples: 核心点所需的最小邻居数,这里设为5
# metric: 距离度量方式,默认欧几里得距离
dbscan = DBSCAN(eps=0.3, min_samples=5, metric='euclidean')
clusters = dbscan.fit_predict(data_scaled)
# 4. 分析聚类结果
n_clusters = len(set(clusters)) - (1 if -1 in clusters else 0) # 簇的数量(排除噪声点-1)
n_noise = list(clusters).count(-1) # 噪声点的数量
print(f"\n聚类结果统计:")
print(f"发现的簇数量: {n_clusters}")
print(f"噪声点数量: {n_noise}")
print(f"每个簇的点数:")
for i in range(n_clusters):
count = list(clusters).count(i)
print(f" 簇{i}: {count}个餐厅")
# 5. 可视化结果
fig, axes = plt.subplots(1, 2, figsize=(15, 6))
# 原始数据分布
axes[0].scatter(restaurant_data[:, 0], restaurant_data[:, 1],
c='blue', alpha=0.6, edgecolors='w', s=50)
axes[0].set_title('原始餐厅位置分布', fontsize=14)
axes[0].set_xlabel('经度(模拟)', fontsize=12)
axes[0].set_ylabel('纬度(模拟)', fontsize=12)
axes[0].grid(True, alpha=0.3)
# DBSCAN聚类结果
# 为每个簇分配不同颜色
colors = plt.cm.tab10(np.linspace(0, 1, n_clusters))
# 绘制每个簇的点
for i in range(n_clusters):
cluster_points = restaurant_data[clusters == i]
axes[1].scatter(cluster_points[:, 0], cluster_points[:, 1],
c=[colors[i]], alpha=0.8, edgecolors='w', s=60,
label=f'餐饮聚集区 {i+1}')
# 绘制噪声点
noise_points = restaurant_data[clusters == -1]
axes[1].scatter(noise_points[:, 0], noise_points[:, 1],
c='gray', alpha=0.5, edgecolors='w', s=40,
label='孤立餐厅(噪声)')
axes[1].set_title('DBSCAN聚类结果', fontsize=14)
axes[1].set_xlabel('经度(模拟)', fontsize=12)
axes[1].set_ylabel('纬度(模拟)', fontsize=12)
axes[1].legend()
axes[1].grid(True, alpha=0.3)
plt.tight_layout()
plt.show()
# 6. 结果解读和应用建议
print("\n" + "="*60)
print("分析结论和应用建议:")
print("="*60)
# 识别不同类型的餐饮聚集区
cluster_info = []
for i in range(n_clusters):
cluster_points = restaurant_data[clusters == i]
# 计算每个簇的密度(点数/面积,这里用边界框近似)
x_min, x_max = cluster_points[:, 0].min(), cluster_points[:, 0].max()
y_min, y_max = cluster_points[:, 1].min(), cluster_points[:, 1].max()
area = (x_max - x_min) * (y_max - y_min) if (x_max > x_min and y_max > y_min) else 0.01
density = len(cluster_points) / area
# 根据密度和形状判断聚集区类型
if density > 2.0:
cluster_type = "高密度餐饮聚集区(如美食街、美食广场)"
elif density > 0.5:
cluster_type = "中密度餐饮区(如商业区餐饮集中地)"
else:
cluster_type = "低密度特色餐饮区"
cluster_info.append({
'id': i,
'size': len(cluster_points),
'density': round(density, 2),
'type': cluster_type,
'center': [round(cluster_points[:, 0].mean(), 2),
round(cluster_points[:, 1].mean(), 2)]
})
print(f"\n餐饮聚集区 {i+1}:")
print(f" - 包含餐厅数: {len(cluster_points)}家")
print(f" - 中心位置: {cluster_info[i]['center']}")
print(f" - 密度指数: {cluster_info[i]['density']}")
print(f" - 类型判断: {cluster_info[i]['type']}")
print(f" - 商业建议: 适合进行联合营销、配送站设置")
print(f"\n孤立餐厅分析:")
print(f" - 数量: {n_noise}家")
print(" - 特征: 位置分散,不成规模")
print(" - 建议: 可能是特色餐厅或位置不佳,需要单独分析经营策略")
print("\n整体城市规划建议:")
print("1. 在高密度聚集区增加公共设施(洗手间、休息区)")
print("2. 在中密度区域优化交通和停车安排")
print("3. 在低密度区域考虑引入更多餐饮品牌形成聚集效应")
print("4. 对孤立餐厅研究其特殊性,判断是否需要搬迁或特色强化")
代码运行结果解读:
当你运行这段代码时,你会看到:
- 左图:显示所有餐厅的原始分布,看起来像是随机散布的点
- 右图:DBSCAN聚类后的结果,不同颜色的点代表不同的餐饮聚集区,灰色的点是孤立餐厅
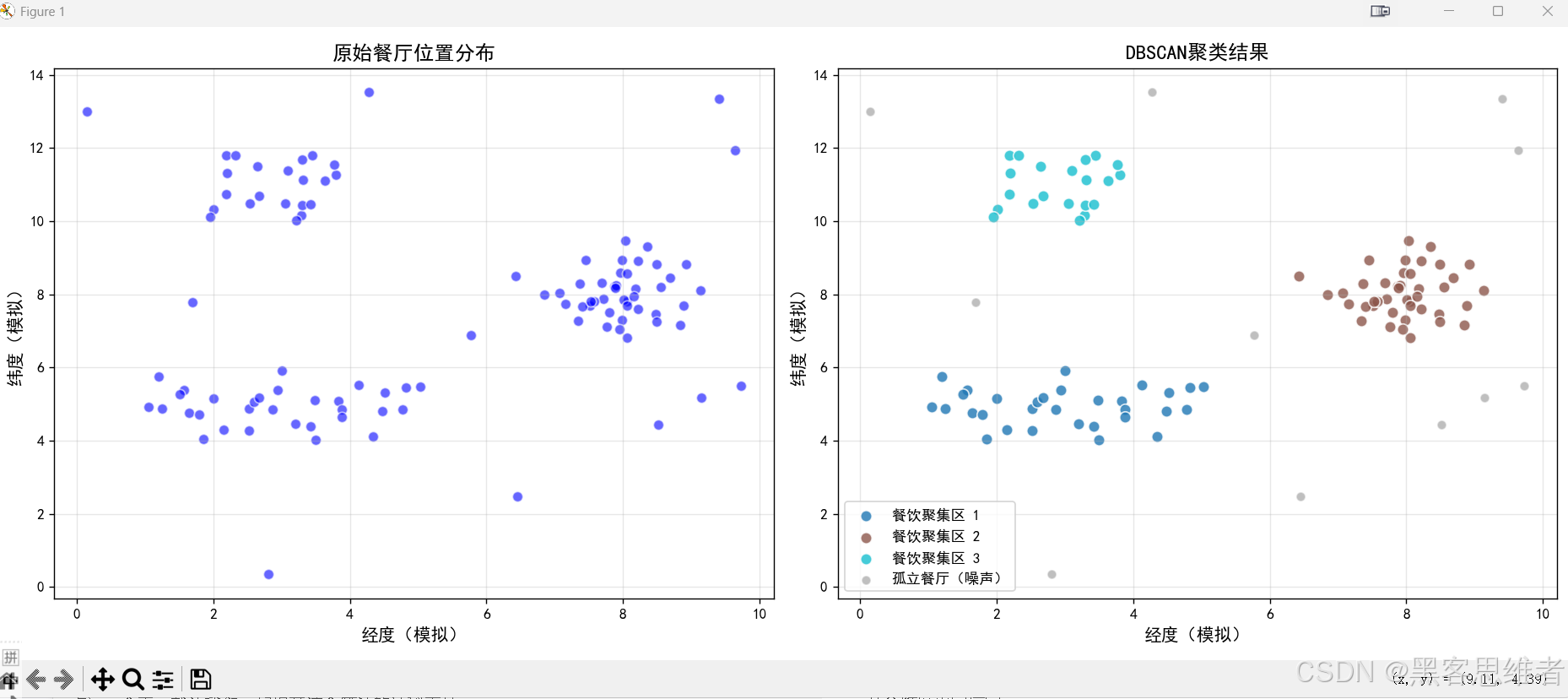
通过这个案例,你可以直观地看到DBSCAN如何:
- 自动发现不同形状的聚集区(线状的美食街、团状的美食广场)
- 识别出那些位置偏远的孤立餐厅(噪声点)
- 无需预先告诉算法要分多少类
思维导图:DBSCAN完整知识体系
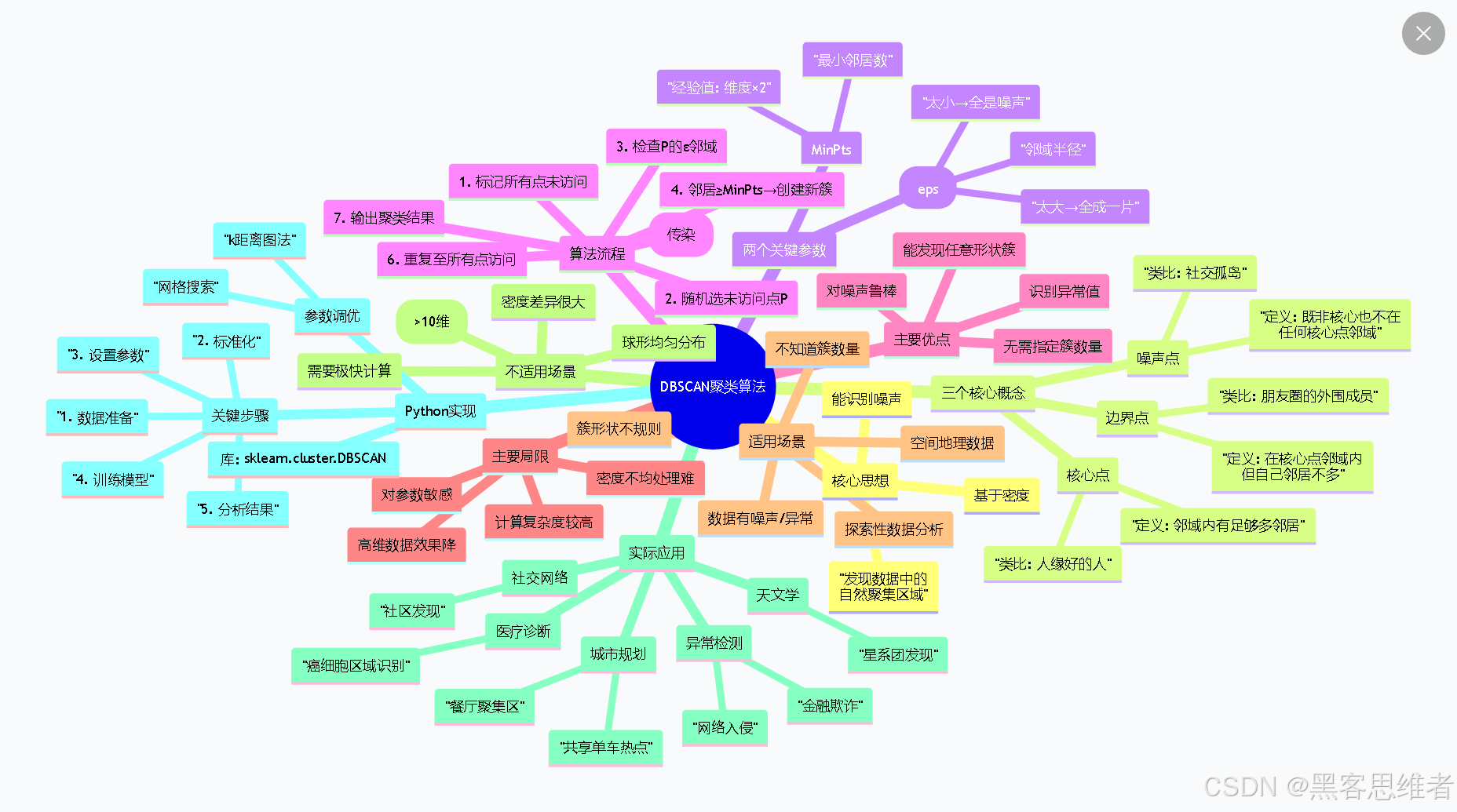
mindmap
root((DBSCAN聚类算法))
核心思想
基于密度
"发现数据中的<br>自然聚集区域"
能识别噪声
三个核心概念
核心点
"定义: 邻域内有足够多邻居"
"类比: 人缘好的人"
边界点
"定义: 在核心点邻域内<br>但自己邻居不多"
"类比: 朋友圈的外围成员"
噪声点
"定义: 既非核心也不在<br>任何核心点邻域"
"类比: 社交孤岛"
两个关键参数
ε(eps)
"邻域半径"
"太小→全是噪声"
"太大→全成一片"
MinPts
"最小邻居数"
"经验值: 维度×2"
算法流程
1. 标记所有点未访问
2. 随机选未访问点P
3. 检查P的ε邻域
4. 邻居≥MinPts→创建新簇
5. 密度扩展(传染)
6. 重复至所有点访问
7. 输出聚类结果
主要优点
无需指定簇数量
能发现任意形状簇
对噪声鲁棒
识别异常值
主要局限
对参数敏感
密度不均处理难
高维数据效果降
计算复杂度较高
适用场景
数据有噪声/异常
簇形状不规则
不知道簇数量
空间地理数据
探索性数据分析
不适用场景
高维数据(>10维)
密度差异很大
需要极快计算
球形均匀分布
实际应用
城市规划
"共享单车热点"
"餐厅聚集区"
异常检测
"金融欺诈"
"网络入侵"
天文学
"星系团发现"
医疗诊断
"癌细胞区域识别"
社交网络
"社区发现"
Python实现
库: sklearn.cluster.DBSCAN
关键步骤
"1. 数据准备"
"2. 标准化"
"3. 设置参数"
"4. 训练模型"
"5. 分析结果"
参数调优
"k距离图法"
"网格搜索"
总结:DBSCAN的核心价值与学习重点
DBSCAN算法的核心价值可以用一句话概括:“像人眼一样直观地发现数据中的自然聚集,不强行分割,也不遗漏异常。”
对于初学者来说,掌握DBSCAN的重点在于:
- 理解密度思想:忘掉“距离中心点远近”,记住“周围邻居多少”
- 掌握三个角色:核心点、边界点、噪声点——这是理解算法的钥匙
- 学会参数调节:ε和MinPts不是魔法数字,需要根据数据特点调整
- 明确适用场景:知道什么时候该用DBSCAN,什么时候该选其他算法
- 实践出真知:只有亲手在数据上尝试,才能真正理解算法的行为
DBSCAN之美在于它的直观性。它不要求数据呈球形分布,不要求预先知道分几类,不强行给每个点都分配类别——这种“顺其自然”的思路,在很多现实问题中恰恰是最合理的。
下次当你看到人群聚集、星星成团、店铺扎堆时,不妨想想DBSCAN算法是如何理解这些模式的。这种从生活直觉到数学算法的连接,正是机器学习最有魅力的地方。

魔乐社区(Modelers.cn) 是一个中立、公益的人工智能社区,提供人工智能工具、模型、数据的托管、展示与应用协同服务,为人工智能开发及爱好者搭建开放的学习交流平台。社区通过理事会方式运作,由全产业链共同建设、共同运营、共同享有,推动国产AI生态繁荣发展。
更多推荐



 48
48 0
0- 0



 已为社区贡献36条内容
已为社区贡献36条内容

所有评论(0)