LSTM模型实现光伏发电功率的预测完整数据集代码详细注释
本文介绍了一个基于LSTM的光伏发电功率预测项目。项目通过处理风速、温度等气象数据和电力历史数据,构建了多层LSTM模型(隐藏层64单元)来预测未来发电功率。创新点包括:1)采用差异化的缺失值处理策略;2)使用24小时滑动窗口构建时间序列;3)结合标准化和特征选择优化数据质量。模型训练使用Adam优化器和MSE损失函数,通过验证集评估性能。结果显示该方案能有效预测连续时间序列值,为光伏发电预测提供
本文来源:k学长的深度学习宝库,点击查看源码&详细教程。深度学习,从入门到进阶,你想要的,都在这里。包含学习专栏、视频课程、论文源码、实战项目、云盘资源等。
项目包截图:
更换数据或其他模型可点击:k学长的深度学习宝库

类似模型升级项目参见: A321-基于xgboost和lstm+attention创新对比的风机发电数据预测
- 项目简介
本项目旨在通过构建一个基于LSTM(长短期记忆网络)的深度学习模型来预测某个站点的光伏发电功率。背景数据包括站点的风速、温度、湿度、辐射强度等气象因素,以及电力传递的历史数据。通过对这些时间序列特征的学习,模型能够在给定时间窗口内对目标变量“有效功率(kW)”进行精确预测。
本项目主要分为以下几个部分:首先对数据进行预处理和特征工程,包括填补缺失值、标准化处理和序列数据构建。然后,设计一个自定义的Dataset类,并使用PyTorch的DataLoader模块实现数据加载。模型方面,选用了具有多层LSTM结构的模型架构,配合全连接层来捕捉复杂的时间序列关系。通过PyTorch的Adam优化器对均方误差(MSE)损失函数进行最小化,并使用交叉验证来评估模型的表现。在训练过程中,对模型参数进行优化,最后通过测试集对模型进行验证,并绘制预测结果与实际值的对比图。此项目适用于预测时间序列数据中的连续值,并能够为未来的光伏发电预测或其他类似场景提供借鉴。
2.技术创新点摘要
数据预处理策略创新:代码中使用了多种数据预处理方法,例如对原始数据进行缺失值填补、数据标准化及序列数据构造。在处理缺失值时,模型区分了不同列的处理方式:部分特征列采用零填充,而其他列使用最近邻插值法来填补缺失数据。此方法充分考虑了各列特征的实际含义和数据分布特征,保证了数据完整性和模型的学习效果。同时,针对时间序列数据特性,采用滑动窗口的方法生成特征序列(SEQ_LENGTH = 24),即利用过去24小时的特征数据来预测未来的有效功率。这种序列数据生成策略能够更好地捕捉时间序列数据中的周期性与趋势性,为模型提供更具时效性的输入。
模型设计上的改进:本项目采用了多层LSTM(Long Short-Term Memory)网络结构,结合全连接层来构建预测模型。LSTM能够有效捕捉长时间序列中的依赖关系,同时通过多层堆叠提升模型的表达能力。模型中的LSTM层设置了2层结构,并且利用了隐藏层维度(hidden_size=64)来增强模型对时间序列模式的记忆与捕捉能力。这种设置能够更好地学习复杂时间序列数据的特征,使模型在应对长时间依赖性时具有更好的性能。
多元时间序列特征融合:项目引入了多种气象因素和电力相关特征,包含了风速、温度、湿度、辐射强度等,并且在输入层采用了标准化方法,以减小不同特征量纲之间的影响。这种多元特征的结合能够帮助模型更全面地理解影响光伏发电功率的多种因素,从而提升预测精度。
自定义数据集与优化训练流程:代码中自定义了数据集(PowerDataset类)以及使用PyTorch的DataLoader模块进行批量数据加载,实现了模型的高效训练与验证。此外,模型采用了Adam优化器,并在每轮训练后进行了验证集评估,以实现最佳模型参数的选择,从而提升整体模型的收敛效果与泛化能力。
- 数据集与预处理
数据清洗与缺失值处理:针对原始数据中的缺失值,项目采取了不同的填补策略。对于某些关键特征(如“有效功率”和“降雨量”),采用零填充方式,以表示特征值为0的情况。而其他特征(如风速、温度等)则使用最近邻插值法进行填补。这种方法能够保证数据完整性,并减少由于缺失值带来的模型性能波动。
时间序列特征处理:在预处理阶段,模型使用滑动窗口法构建了特征序列(长度为24),即每次利用过去24小时的特征数据作为模型输入,用来预测下一时间步的发电功率。这种处理方式能够帮助模型捕捉时间序列数据中的趋势、周期性以及复杂依赖关系。
特征选择与标准化:项目通过筛选,选定了多种气象特征(例如风速、湿度、辐射量等)及电力相关特征作为输入变量,排除了无关或重复的特征。在特征标准化方面,采用StandardScaler对所有特征进行标准化处理,将其转换为均值为0、标准差为1的标准正态分布。这一操作能够平衡各特征的量纲差异,有助于提升模型的收敛速度和稳定性。
- 模型架构
模型结构:
输入层:输入特征的维度为 input_size = 9(表示9个气象及电力特征)。输入张量形状为 [BatchSize,Seq_Length,Input_Size],其中 Seq_Length = 24 代表时间序列的长度。
LSTM层:模型包含两层LSTM层(num_layers = 2),每层的隐藏单元数量为 hidden_size = 64。每个时间步输入一个特征向量 xt,其内部运算逻辑为:
{
f
t
σ
(
W
f
⋅
[
h
t
−
1
,
x
t
]
+
b
f
)
(遗忘门)
i
t
σ
(
W
i
⋅
[
h
t
−
1
,
x
t
]
+
b
i
)
(输入门)
C
~
t
tanh
(
W
c
⋅
[
h
t
−
1
,
x
t
]
+
b
c
)
(候选记忆单元)
C
t
f
t
⋅
C
t
−
1
+
i
t
⋅
C
~
t
(记忆单元更新)
o
t
σ
(
W
o
⋅
[
h
t
−
1
,
x
t
]
+
b
o
)
(输出门)
h
t
o
t
⋅
tanh
(
C
t
)
(当前隐藏状态)
⎩
⎨
⎧
f
t
=σ(W
f
⋅[h
t−1
,x
t
]+b
f
)(遗忘门)
i
t
=σ(W
i
⋅[h
t−1
,x
t
]+b
i
)(输入门)
C
~
t
=tanh(W
c
⋅[h
t−1
,x
t
]+b
c
)(候选记忆单元)
C
t
=f
t
⋅C
t−1
+i
t
⋅
C
~
t
(记忆单元更新)
o
t
=σ(W
o
⋅[h
t−1
,x
t
]+b
o
)(输出门)
h
t
=o
t
⋅tanh(C
t
)(当前隐藏状态)
其中:σ 表示 sigmoid 函数,tanh 表示双曲正切函数,Wf,Wi,Wc,Wo 为权重矩阵,bf,bi,bc,bo 为偏置项,ft,it,ot 分别表示遗忘门、输入门、输出门的激活值,Ct 为当前时刻的记忆单元状态,ht 为当前时刻的隐藏状态。
全连接层(Fully Connected Layer):最后一层全连接层将LSTM的隐藏状态(hidden_size = 64)映射到输出空间(output_size = 1),即单一的有效功率预测值:
y
W
⋅
h
t
+
b
y=W⋅h
t
+b
其中,W 是全连接层的权重矩阵,ht 为最后一个时间步的隐藏状态,b 是偏置项。
模型整体结构: 输入序列([Batch Size, Seq_Length, Input_Size]) -> LSTM 层 1 -> LSTM 层 2 -> 全连接层 -> 输出([Batch Size, 1])
- 模型的整体训练流程
数据准备:首先对原始数据进行预处理,填补缺失值,并使用滑动窗口法创建时间序列特征。然后,采用 train_test_split 将数据集划分为训练集(80%)和测试集(20%)。
数据加载与处理:使用 torch.utils.data.Dataset 和 DataLoader 将数据划分为批量(Batch Size = 64)并封装成可迭代数据集。在训练时,训练集的数据被打乱(shuffle=True),而验证集保持原有顺序(shuffle=False)。
模型初始化与配置:模型结构包括两层LSTM和一个全连接层。设备优先使用 GPU(若可用),否则使用 CPU。损失函数选用 MSELoss(均方误差),优化器选用 Adam(学习率为 0.001)。
模型训练流程:
每个 epoch 内,模型遍历训练集,执行以下步骤:
将当前批次的输入数据(X_batch)和目标数据(y_batch)传入模型。
计算模型输出值与真实值之间的均方误差(loss = criterion(outputs, y_batch))。
反向传播误差,计算每个参数的梯度(loss.backward())。
使用优化器更新模型参数(optimizer.step())。
累加并记录当前批次的损失。
每个 epoch 结束后,使用验证集数据进行模型评估,并记录验证集的平均损失(val_loss)。
模型评估指标:
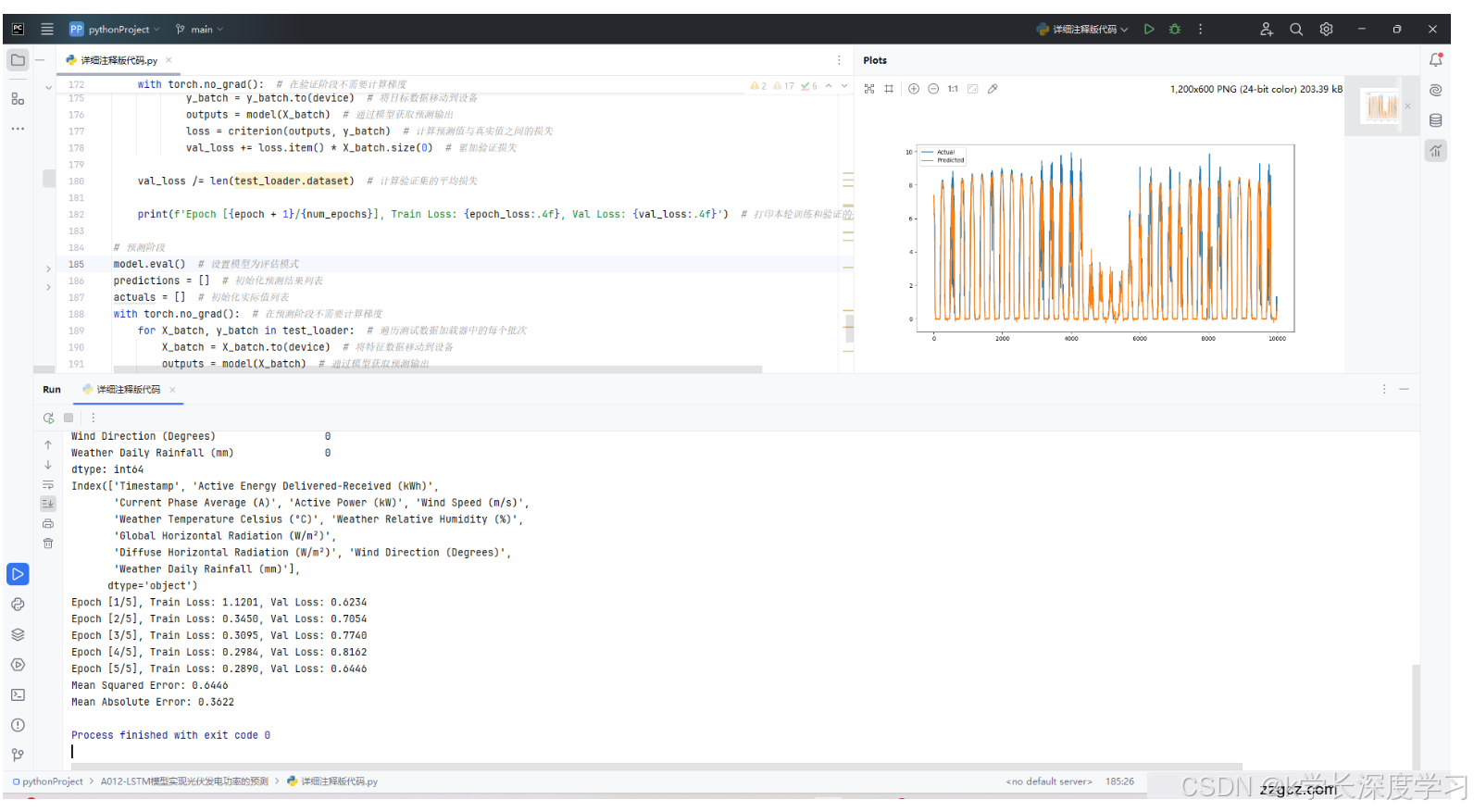
使用均方误差(MSE)和平均绝对误差(MAE)作为模型的主要评估指标。
计算公式为: (
M
S
E
1
N
∑
i
1
N
(
y
i
−
y
^
i
)
2
MSE=
N
1
∑
i=1
N
(y
i
−
y
^
i
)
2
)(
M
A
E
1
N
∑
i
1
N
∣
y
i
−
y
^
i
∣
MAE=
N
1
∑
i=1
N
∣y
i
−
y
^
i
∣) 其中,N 是样本总数,yi 为真实值,y^i 为预测值。
结果可视化与模型性能评估:在模型训练完成后,通过绘制实际值与预测值的曲线图直观展示模型性能,并打印评估指标(MSE和MAE),以判断模型的整体效果。
- 核心代码详细讲解
- 数据预处理和特征工程部分
col_set_zero:指定需要填充为0的列名列表,这些列包括Active Power (kW)(有效功率)和Weather Daily Rainfall (mm)(日降雨量)。
data[col_set_zero].fillna(0):将指定列(电力功率和降雨量)中所有缺失值替换为0,以表示数据记录时的“无降雨”和“无功率输出”状态。这种处理方式能够防止模型在学习时因缺失数据而引入噪声。
for col in data.columns:遍历数据表中的每一列。
data[col].interpolate(method=‘nearest’):采用最近邻插值法填补缺失值,即用与缺失值位置最接近的上下数据来填充。这种方法能够保持数据的连续性,并且适用于时间序列数据的填充,能够更好地维持数据在时间维度上的趋势性。
scaler = StandardScaler():初始化 StandardScaler 对象。StandardScaler 是一种常用的标准化工具,将特征数据转换为均值为0、标准差为1的标准正态分布。
scaler.fit_transform(df[feature_cols]):对 feature_cols 中指定的特征列进行标准化处理。标准化能够消除不同量纲特征之间的差异,使模型更易于训练。
该行调用了 create_sequences 函数,使用滑动窗口方法构建时间序列特征:
scaled_features:标准化后的特征数据。
targets:目标值(有效功率Active Power)。
SEQ_LENGTH:时间序列长度(即使用过去24个时间步的数据进行预测)。
X, y:分别为创建好的特征序列和对应的目标值序列。
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, shuffle=False)
train_test_split:将创建好的特征序列和目标值按照8:2的比例分为训练集和测试集,不打乱数据顺序(shuffle=False),这在处理时间序列数据时尤为重要。
2. 模型架构构建部分
super(LSTMModel, self).init():调用 nn.Module 的构造函数,以便在自定义模型中使用 PyTorch 提供的内置方法。
self.lstm = nn.LSTM(input_size, hidden_size, num_layers, batch_first=True):定义两层LSTM网络:
input_size:输入特征维度(9个特征)。
hidden_size:隐藏单元数量(64个神经元)。
num_layers:LSTM层数(2层)。
batch_first=True:指定输入数据格式为 [Batch Size, Seq Length, Input Size]。
self.fc = nn.Linear(hidden_size, output_size):定义全连接层,将隐藏状态的输出(维度为 hidden_size = 64)映射到输出空间(output_size = 1,即单一预测值)。
h0 = torch.zeros(self.num_layers, x.size(0), self.hidden_size).to(x.device):初始化隐藏状态为全零张量,形状为 [LSTM层数, Batch Size, 隐藏单元数量]。
out, _ = self.lstm(x, (h0, c0)):将输入数据 x 通过LSTM层,并得到输出 out(形状为 [Batch Size, Seq Length, Hidden Size])。
out = out[:, -1, :]:取出最后一个时间步的隐藏状态作为当前序列的特征表示。
out = self.fc(out):将LSTM的输出通过全连接层,映射到单一目标值。
- 模型训练与评估部分
model.train():将模型设置为训练模式。
loss = criterion(outputs, y_batch):计算当前批次的均方误差(MSELoss)损失值。
loss.backward():通过反向传播计算当前批次的梯度。
optimizer.step():使用 Adam 优化器更新模型参数。
- 模型优缺点评价
模型优点:
时间序列特征捕捉能力强:采用了两层LSTM结构,能够有效捕捉时间序列数据中的长期依赖关系,尤其在处理具有周期性和趋势性的光伏发电数据时表现出色。
多维特征输入融合:模型整合了包括风速、温度、湿度、辐射强度等多个气象特征及电力数据,使用标准化处理消除不同特征量纲间的差异,有助于模型更好地理解不同输入变量之间的关系。
优化训练流程:使用Adam优化器配合均方误差(MSE)损失函数,有效提升了模型训练的收敛速度和稳定性。此外,采用滑动窗口方法生成序列数据,使模型能够利用更长的历史数据进行预测。
模型缺点:
长序列依赖性不足:尽管LSTM能够捕捉长时间依赖关系,但随着时间序列长度的增加(如SEQ_LENGTH较大时),模型的记忆能力会下降,从而导致捕捉长期依赖信息的效果变差。
模型复杂度高:双层LSTM的隐藏状态数量较多,参数较为复杂,导致训练时间较长,对计算资源的需求较高,尤其在处理更大规模的数据集时,可能会出现效率瓶颈。
对噪声数据敏感:该模型使用零填充和插值法处理缺失值,但这两种方法可能引入噪声,尤其在数据质量较差的情况下,可能导致模型学习到不真实的模式,影响预测性能。
可能的改进方向:
引入注意力机制:可以尝试在LSTM后添加注意力层(Attention Mechanism),让模型能够更关注不同时间步的数据,从而提升对长时间序列中重要信息的捕捉能力。
增加超参数调优:通过Grid Search或Bayesian Optimization等方法,进一步优化LSTM的隐藏单元数量、层数和学习率等超参数,以提升模型性能。
数据增强与特征选择:尝试使用更多的数据增强方法(例如增加噪声、平移、时间序列数据平滑等)以及特征选择算法,筛选出对目标值影响最大的特征,从而降低数据维度,提高模型效率。
本文来源:k学长的深度学习宝库,点击查看源码&详细教程。深度学习,从入门到进阶,你想要的,都在这里。包含学习专栏、视频课程、论文源码、实战项目、云盘资源等。

魔乐社区(Modelers.cn) 是一个中立、公益的人工智能社区,提供人工智能工具、模型、数据的托管、展示与应用协同服务,为人工智能开发及爱好者搭建开放的学习交流平台。社区通过理事会方式运作,由全产业链共同建设、共同运营、共同享有,推动国产AI生态繁荣发展。
更多推荐


 40
40 0
0- 0



 已为社区贡献10条内容
已为社区贡献10条内容

所有评论(0)