Apache Doris+OSS VS VictoriaLogs 2025 深度选型:从架构本质到落地避坑,云原生日志系统不再踩坑(附 ELK/Loki/ClickHouse 竞品对比)
2025年的日志系统选型,早已不是“ELK一家独大”,而是“场景化细分”——凭借“日志-业务数据一体化分析”,成为需要深度分析场景的首选;凭借“云原生极致效率”,成为轻量检索、成本敏感场景的黑马。VictoriaLogs集群模式将进一步成熟,支持更多复杂聚合功能,有望在中大规模场景替代ELK/Loki;Apache Doris将强化日志冷存能力,与数据湖生态(如Iceberg)的联动更紧密,成为“
Apache Doris+OSS VS VictoriaLogs 2025深度选型:从架构本质到落地避坑,云原生日志系统不再踩坑(附ELK/Loki/ClickHouse竞品对比)
在云原生架构普及的2025年,日志系统早已不是“存起来、查得到”这么简单——日均千亿条日志的检索延迟、PB级存储的成本失控、多团队共享的权限隔离、跨Zone部署的高可用需求,正在倒逼架构师重新审视日志工具选型。传统ELK栈“高成本低扩展”、Loki“功能残缺难聚合”的痛点日益凸显,而Apache Doris+OSS的“日志-业务数据一体化分析”与VictoriaLogs的“云原生日志极致效率”,逐渐成为两类核心场景的优选方案。
本文基于360、京东、某头部券商等企业的实战案例,结合ELK/Loki/ClickHouse等竞品的横向对比,从架构本质、核心维度PK、场景适配、落地避坑四个层面,为架构师提供可直接落地的选型指南,帮你避开**“选贵了”“用废了”“扩崩了”**三大陷阱。
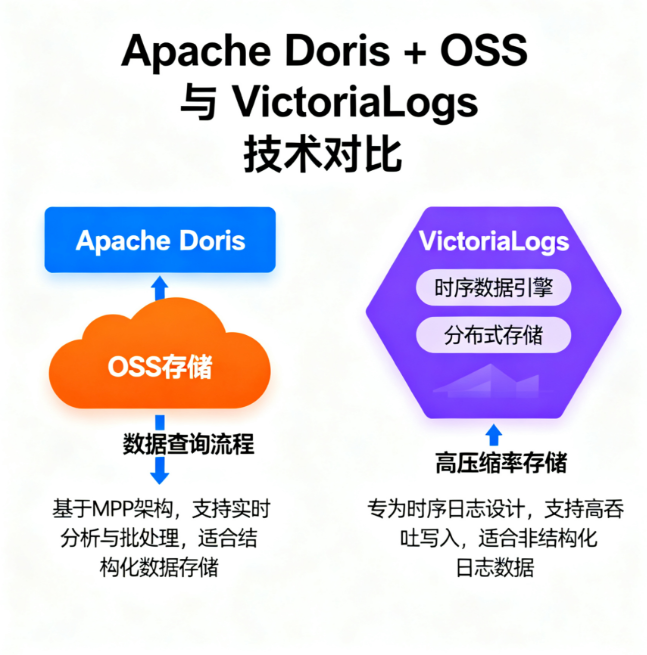
一、架构本质:两种设计理念的根本差异
日志系统的选型,本质是“场景需求”与“架构设计”的匹配——Doris+OSS的核心是“一体化分析”,VictoriaLogs的核心是“日志极致效率”,两者的产品基因从根源上决定了适用边界。
1.1 产品基因对比(2025最新状态)
| 维度 | Apache Doris+OSS | VictoriaLogs(集群模式已落地) |
|---|---|---|
| 核心定位 | 实时分析型数据库+对象存储,聚焦“日志-业务数据联动分析” | 云原生专用日志系统,聚焦“采集-存储-查询-高可用全链路效率” |
| 架构设计 | MPP分布式架构(FE调度+BE计算存储)+ OSS冷热分层 | 轻量级分布式架构(vlinsert写入+vlselect查询+vlstorage存储)+ vmauth负载均衡 |
| 设计目标 | 支持多表JOIN、复杂聚合(如日志关联用户表做归因分析) | 单节点/集群均实现“低资源占用+高吞吐+亚秒级查询” |
| 技术依赖 | 需搭配Filebeat/Fluentd采集+OSS存储,依赖Doris Manager运维 | 兼容ES Bulk API,内置vlogscli,集群依赖K8s/Helm部署 |
| 集群成熟度 | 生产级成熟(Apache顶级项目,多年迭代,360/PDD等企业大规模落地) | 集群模式2025年正式GA,跨Zone高可用已验证(某云厂商多区域部署案例) |
| 核心优势基因 | 分析能力强(标准SQL+UDF+窗口函数) | 效率极致(RAM低30倍+磁盘低15倍+查询<500ms) |
1.2 架构原理图:从数据流向看差异
1.2.1 Apache Doris+OSS架构:冷热分层+一体化分析
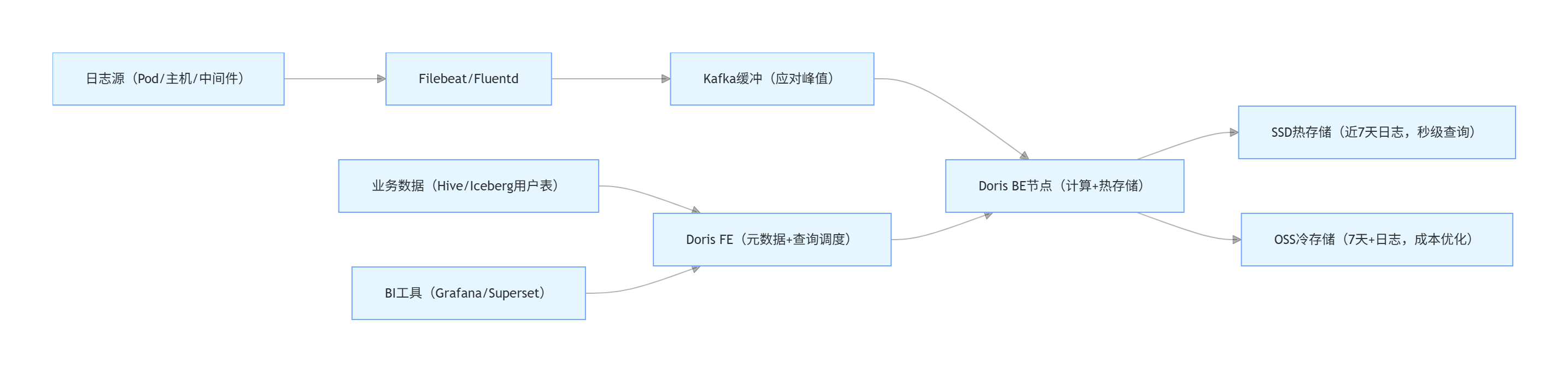
核心逻辑:通过MPP架构实现“日志+业务数据”的统一分析,比如将Nginx访问日志与用户画像表JOIN,实时计算“不同会员等级的接口错误率”,无需跨系统同步数据。
1.2.2 VictoriaLogs集群架构:跨Zone高可用+轻量高效
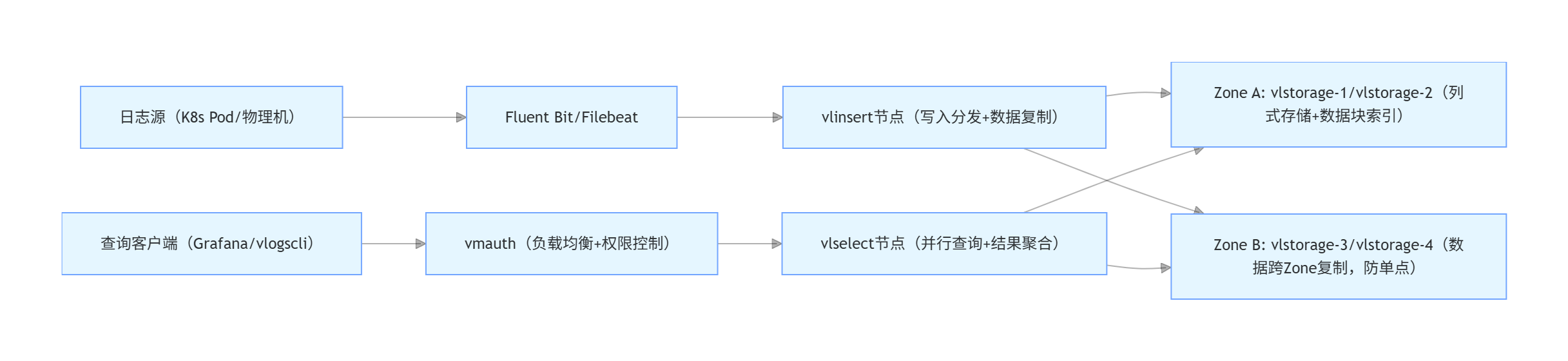
核心逻辑:通过“写入分发-跨Zone存储-并行查询”实现高可用与高效率,单vlstorage节点支持数百TB日志存储,查询时仅读取目标字段数据块,避免全量扫描。
1.3 设计理念差异:为什么不能“二选一”?
- Doris+OSS的妥协:为了支持多表JOIN和复杂聚合,牺牲了部分轻量检索性能(纯日志关键词查询比VictoriaLogs慢30%左右),且运维成本更高(需维护FE/BE/OSS);
- VictoriaLogs的妥协:为了极致效率,放弃了跨数据源分析能力(无法直接关联Hive/Iceberg表),复杂聚合(如多维度窗口函数)支持较弱。
两者的设计理念差异,决定了选型的核心判断标准:是否需要日志与业务数据联动分析。
二、七大核心维度PK:数据驱动选型(附实战案例)
脱离数据的选型都是“拍脑袋”。以下从性能、成本、生态、多租户等七大维度,结合360、京东、某云厂商的实战数据,帮你量化对比。
2.1 性能:检索快VS分析强
| 指标 | Apache Doris+OSS | VictoriaLogs | 竞品参考(ELK/Loki) |
|---|---|---|---|
| 写入吞吐 | 单BE节点550MB/s(360案例),集群支持GB/s级 | 单节点写入吞吐与27节点ES持平(某企业替换案例),集群线性扩展 | ELK(单节点100-200MB/s),Loki(单节点300MB/s) |
| 查询延迟 | 纯日志检索:秒级(如54亿行日志关键词查询1.2s);复杂聚合:亚秒级(多表JOIN+窗口函数0.32s) | 99%查询<500ms(含全文检索),Loki替换后查询速度提升3-5倍 | ELK(5-10s),Loki(1-3s) |
| 索引特性 | 倒排索引(全文检索)+ 列式存储(聚合优化),支持动态Schema(JSONB字段) | 字段级数据块索引(无倒排索引,通过数据块过滤实现高效检索) | ELK(倒排索引,存储膨胀率100%+),Loki(标签索引,无全文检索) |
| 优势场景性能 | 日志关联业务数据:某电商“订单日志+用户表”分析延迟从ELK的15s降至0.8s | 云原生故障排查:K8s Pod日志检索比Doris快30%,比ELK快10倍 | - |
实战案例:360将安全日志迁移至Doris+OSS后,54亿行日志的“IP归属地聚合+威胁标签关联”查询,从ELK的18s降至0.9s;某云厂商用VictoriaLogs替换Loki,Pod故障排查时“error日志检索”从2.3s降至0.4s。
2.2 成本:TCO拆解(存储+计算+运维)
日志系统的成本陷阱,往往藏在“隐性开销”(如ELK的JVM调优人力、Loki的冷数据迁移)里。以下是PB级日志场景的TCO对比(按1年存储计算):
| 成本维度 | Apache Doris+OSS | VictoriaLogs | ELK Stack |
|---|---|---|---|
| 存储成本 | 压缩比5-10:1 + OSS冷存(7天+日志),1PB原始日志年成本≈8万元 | 压缩比15-20:1(结构化日志可达20:1),1PB原始日志年成本≈4万元 | 压缩比2-3:1,1PB原始日志年成本≈25万元 |
| 计算成本 | 集群需预留20%峰值资源(MPP架构),10节点集群年成本≈15万元 | 单节点RAM占用比ES低30倍(10TB日志仅需4GB RAM),10节点集群年成本≈5万元 | JVM资源密集(10TB日志需64GB RAM),10节点集群年成本≈30万元 |
| 运维成本 | 需专职DBA/运维(2-3人),年人力成本≈40万元 | 单节点无需运维,集群运维仅需1人(Helm一键部署),年人力成本≈15万元 | 需专职运维(3-4人,含JVM调优),年人力成本≈60万元 |
| 1PB日志TCO | ≈63万元 | ≈24万元 | ≈115万元 |
成本陷阱规避:某券商曾因ELK存储成本失控(1PB日志年成本超120万元),迁移至VictoriaLogs+OSS冷存后,TCO降至30万元,降幅75%。
2.3 生态适配:兼容现有体系VS轻量集成
日志系统的落地效率,取决于与现有工具链的适配程度——是否需要修改采集配置?能否复用可视化平台?
| 适配能力 | Apache Doris+OSS | VictoriaLogs |
|---|---|---|
| 采集工具 | 支持Filebeat/Logstash/Fluentd/OpenTelemetry,需配置Doris Stream Load接口 | 兼容ES Bulk API,现有Filebeat/Fluentd无需修改配置(仅改输出地址),支持Syslog直接接入 |
| 可视化工具 | 支持Grafana/Superset/Tableau(标准SQL协议),可复用现有BI报表 | 支持Grafana插件(官方提供)+ 内置Web UI(LogsQL编辑器),无需额外开发 |
| 数据联动 | 可直接JOIN Hive/Iceberg数据湖、MySQL业务库,无需数据同步 | 仅支持日志数据,复杂分析需对接Doris/ClickHouse |
| 查询语言 | 标准SQL(支持UDF、窗口函数、CTE),分析师无需学习新语法 | LogsQL(Pipe风格,如`{app=“nginx”} |
实战适配案例:京东智联云在Loki迁移至VictoriaLogs时,仅修改Filebeat输出地址(从Loki API改为VictoriaLogs的ES Bulk API),1小时完成全量切换,无业务中断。
2.4 多租户与权限:精细管控VS轻量隔离
多团队共享日志系统时,“数据隔离”与“权限管控”是核心需求——避免运维团队看到业务日志,防止开发团队误删数据。
| 权限特性 | Apache Doris+OSS | VictoriaLogs |
|---|---|---|
| 隔离机制 | 库表级物理隔离 + Resource Group资源管控(CPU/内存配额) | 流标签(_stream,如namespace="dev")逻辑隔离 + AccountID+ProjectID双维度权限 |
| 权限粒度 | 支持行级权限(如仅允许某团队查看自身业务日志)、列级权限(隐藏敏感字段如手机号) | API级权限(查询/写入分离)+ 流标签过滤(租户仅能查询自身标签日志) |
| 审计能力 | 内置操作日志(如谁查询了哪张表),支持对接第三方审计系统(如Syslog) | vmauth审计日志(记录查询IP/账号/语句),需二次开发对接企业审计平台 |
| 适用团队规模 | 大型企业多业务线(10+团队),需严格权限管控 | 中小型团队(3-5团队)或云原生环境(按Namespace隔离) |
2.5 运维复杂度:重量级部署VS轻量运维
日志系统的“隐性成本”很大程度来自运维——ELK的JVM调优、Loki的Chunk迁移,都是运维的噩梦。
| 运维维度 | Apache Doris+OSS | VictoriaLogs |
|---|---|---|
| 部署成本 | 需部署FE(3节点高可用)、BE(3节点起)、Doris Manager,约2-3小时 | 单节点:Docker/二进制5分钟部署;集群:Helm一键部署(含vlinsert/vlselect/vmauth),约30分钟 |
| 扩缩容 | BE节点在线扩容(新增节点后自动负载均衡),缩容需手动迁移数据 | 集群横向扩容(新增vlstorage节点,自动同步配置),无需停机 |
| 故障恢复 | FE元数据镜像+BE副本机制,RTO<10分钟(360案例) | 跨Zone数据复制,节点故障时vmauth自动切换,RTO<1分钟 |
| 版本迭代 | 稳定迭代(每季度1个大版本),升级无需停机 | 快速迭代(每月1-2个版本),集群升级支持滚动更新 |
运维案例:某创业公司运维团队(2人)通过Helm部署VictoriaLogs集群(3个vlstorage节点,跨2个Zone),仅需1小时完成部署,后续扩缩容无需停机,节省90%运维时间。
2.6 安全与信创:合规需求不可忽视
2025年信创政策深化,日志系统的“自主可控”与“数据安全”成为金融、政务等行业的必选项。
| 安全维度 | Apache Doris+OSS | VictoriaLogs | ELK Stack(风险点) |
|---|---|---|---|
| 开源协议 | Apache License 2.0(完全开源,可二次开发) | Apache License 2.0(开源可控) | Elastic License(2021年后非完全开源,存在商业绑定风险) |
| 数据安全 | 支持数据加密(传输TLS+存储AES),敏感字段脱敏 | 传输TLS加密,存储加密需依赖底层文件系统(如EBS加密) | 历史漏洞频发(2024年暴露10+高危漏洞,涉及数据泄露) |
| 信创适配 | 支持国产化服务器(华为鲲鹏、海光)、操作系统(麒麟) | 兼容国产化硬件,但信创认证进度滞后于Doris | 无国产化适配,存在“卡脖子”风险(2022年曾对俄断供) |
信创案例:某国有银行因ELK的信创风险,将核心业务日志系统迁移至Doris+OSS,适配鲲鹏服务器与麒麟OS,通过等保三级认证。
2.7 核心缺陷与规避方案
没有完美的工具,只有“适合的工具+规避缺陷的方案”。
| 方案 | 核心缺陷 | 实战规避建议 |
|---|---|---|
| Apache Doris+OSS | 1. 纯日志检索性能不如专用日志系统;2. 运维成本高;3. 冷数据查询延迟高 | 1. 热点日志(7天内)缓存至SSD,冷数据(7天+)存OSS;2. 部署Doris Manager可视化运维;3. 冷数据查询前预热至BE节点 |
| VictoriaLogs | 1. 无跨数据源分析能力;2. 复杂聚合支持弱;3. 集群文档较少 | 1. 复杂分析场景对接Doris(VictoriaLogs存日志,Doris做关联);2. 聚合需求优先用LogsQL的基础函数(如count/sum);3. 参考官方跨Zone部署文档(避免自定义配置) |
三、横向竞品对比:不止Doris和VictoriaLogs
在选型时,需明确Doris+OSS和VictoriaLogs与ELK/Loki/ClickHouse的定位差异,避免“用错场景”。
| 特性 | Apache Doris+OSS | VictoriaLogs | ELK Stack | Loki | ClickHouse |
|---|---|---|---|---|---|
| 核心定位 | 日志-业务数据一体化分析 | 云原生日志极致效率 | 全功能日志搜索引擎 | 云原生日志聚合(标签索引) | 大规模日志OLAP分析 |
| 存储效率 | ★★★★☆(5-10:1+OSS) | ★★★★★(15-20:1) | ★★☆☆☆(2-3:1) | ★★★☆☆(3-5:1) | ★★★★☆(8-12:1) |
| 查询延迟 | 秒级(检索)/亚秒级(聚合) | <500ms(99%查询) | 5-10s | 1-3s | 亚秒级(聚合)/秒级(检索) |
| 部署复杂度 | 高(3节点起,需运维FE/BE) | 低(单节点/Helm集群) | 极高(5+组件,需调JVM) | 中(需Cortex集群) | 中(需配置分片) |
| 成本(TCO) | 中(PB级有优势) | 低(全规模场景) | 极高 | 中 | 中(大规模聚合有优势) |
| 适用场景 | 日志关联业务数据、复杂报表 | 云原生故障排查、轻量日志检索 | 全功能日志分析(小规模) | 云原生日志聚合(无全文检索) | 千亿级日志大规模聚合 |
| 核心坑点 | 运维成本高 | 无跨源分析 | 存储膨胀、JVM故障 | 无全文检索、复杂聚合弱 | 检索性能弱、运维复杂 |
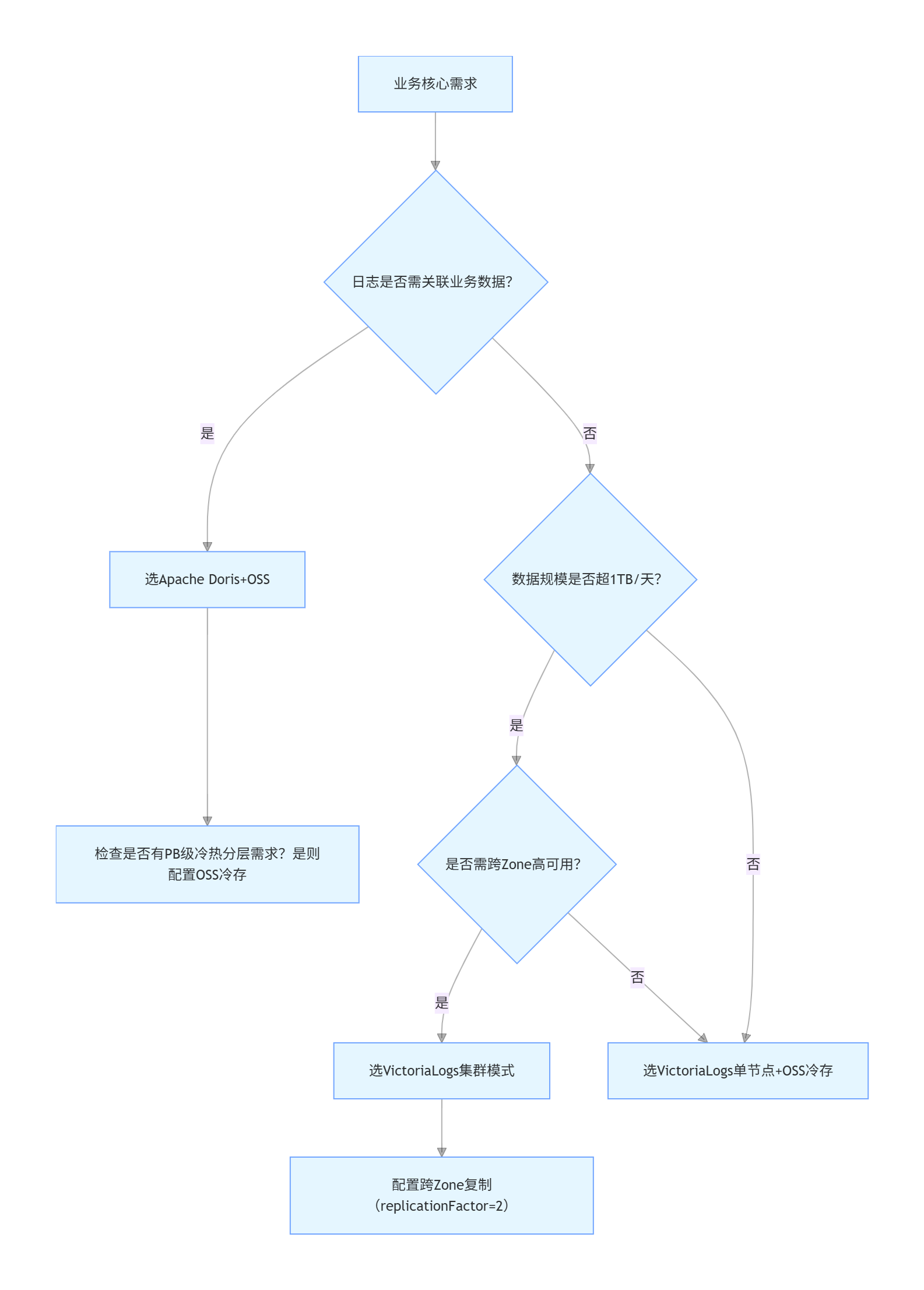
四、场景适配:3步锁定最佳方案
选型的核心是“匹配场景”,而非“追求全能”。以下是三类核心场景的适配建议,附实战案例参考。
4.1 必选Apache Doris+OSS的3种场景
场景1:日志需关联业务数据做深度分析
需求特征:日志不能孤立存在,需结合用户表、订单表等业务数据做归因分析,如“分析某支付失败日志对应的用户等级、支付方式分布”。
实战案例:某电商平台将Nginx访问日志(含user_id)与MySQL用户表(含user_level)、Hive订单表(含pay_type)关联,通过Doris的多表JOIN实现“不同用户等级的支付失败率”实时计算,分析延迟从ELK的15s降至0.8s,支撑运营决策。
选型理由:VictoriaLogs无法直接关联业务数据,需跨系统同步,延迟高且易出错;Doris的MPP架构支持实时JOIN,无需数据同步。
场景2:PB级日志冷热分层存储(合规需求)
需求特征:日志需留存1年以上(如金融合规要求),且热数据(7天内)需秒级查询,冷数据(7天+)需低成本存储。
实战案例:360安全日志系统采用Doris+OSS架构,热数据(7天内)存BE节点SSD(秒级查询),冷数据(7天+)自动迁移至OSS(成本降低82%),1年存储10PB日志,TCO比ELK低65%。
选型理由:VictoriaLogs虽存储效率高,但冷数据无分层机制,长期存储成本高于OSS;Doris的冷热分层可自动调度,兼顾性能与成本。
场景3:多团队需复杂报表与精细权限管控
需求特征:运维、业务、安全团队共用日志系统,需不同报表(如运维看错误率、业务看转化率),且权限隔离(如安全团队看不到订单日志)。
实战案例:某券商通过Doris的库表隔离+行级权限,为运维团队配置“服务器日志查看权限”,为业务团队配置“交易日志查看权限”,为安全团队配置“异常登录日志查看权限”,同时通过Superset生成各团队专属报表,满足合规要求。
选型理由:VictoriaLogs的权限粒度较粗(仅API级+流标签),无法满足多团队精细报表需求;Doris的RBAC权限+标准SQL报表能力更适配。
4.2 必选VictoriaLogs的3种场景
场景1:云原生环境轻量日志检索(故障排查)
需求特征:K8s环境下Pod动态变化,需快速检索Pod日志排查故障,如“查询某Pod的error日志,定位接口超时原因”。
实战案例:某创业公司K8s集群(500+Pod)采用VictoriaLogs单节点部署,Filebeat采集Pod日志(stdout输出),通过LogsQL快速检索“{pod=“gateway-xxx”} | regexp “504 timeout””,响应时间<300ms,资源占用仅为ELK的1/30(RAM从16GB降至500MB)。
选型理由:Doris运维成本高(小团队无专职运维),VictoriaLogs单节点部署无需运维,且检索速度更快。
场景2:大规模跨Zone日志高可用部署
需求特征:日志需跨区域存储(如华东/华北Zone),避免单Zone故障导致日志丢失,且跨Zone查询延迟低。
实战案例:某云厂商采用VictoriaLogs集群架构(跨2个Zone,每个Zone 3个vlstorage节点),日志写入时自动跨Zone复制,单Zone故障时vmauth自动切换至另一Zone,查询延迟<500ms,RTO<1分钟,满足高可用需求。
选型理由:Doris跨Zone部署需配置多集群同步,复杂度高;VictoriaLogs原生支持跨Zone存储,部署简单。
场景3:中小团队成本敏感(无专职运维)
需求特征:团队规模小(2-5人),无专职DBA/运维,需低成本、易维护的日志系统,年预算<10万元。
实战案例:某SaaS公司(10人团队)用VictoriaLogs单节点部署,Docker启动5分钟完成,日志存储成本比ELK低90%,运维仅需1人(每月花1小时检查备份),年预算仅5万元,满足业务需求。
选型理由:Doris需2-3人运维,人力成本高;VictoriaLogs几乎无需运维,成本低。
4.3 混合架构:1+1>2的最佳实践
场景需求:既需要实时故障排查(轻量检索),又需要日志关联业务数据做深度分析。
架构设计:VictoriaLogs负责实时日志检索(故障排查),Doris负责日志与业务数据关联分析(深度报表),通过Doris的Stream Load接口从VictoriaLogs同步日志数据(延迟<1分钟)。
实战案例:某互联网公司采用该混合架构,运维团队用VictoriaLogs排查Pod故障(响应<300ms),运营团队用Doris关联用户表做“故障用户的留存率分析”(延迟<1s),兼顾效率与深度,TCO比纯ELK低70%。
五、落地避坑指南:从0到1实战(附代码示例)
选型后落地的“坑”往往比选型本身更多。以下是Doris+OSS和VictoriaLogs的核心落地避坑建议,附实战配置代码。
5.1 Apache Doris+OSS落地避坑
避坑1:表结构设计不合理导致查询慢
问题:日志表用Aggregate模型,导致动态字段(如trace_id)无法存储,查询时需全表扫描。
解决方案:日志表用Duplicate模型,动态字段用JSONB类型,分区按日期(dt),分桶按日志源(source)。
示例代码:
CREATE TABLE logs (
dt DATE COMMENT '日志日期',
log_time DATETIME COMMENT '日志时间',
source STRING COMMENT '日志源(如nginx/k8s)',
content JSONB COMMENT '日志内容(动态字段)'
) ENGINE=OLAP
DUPLICATE KEY(dt, log_time, source) -- 排序键,优化查询
PARTITION BY RANGE(dt) (
START ('2025-01-01') END ('2025-12-31') EVERY (INTERVAL 1 DAY)
)
DISTRIBUTED BY HASH(source) BUCKETS 32 -- 分桶按日志源,避免数据倾斜
PROPERTIES (
"storage_medium" = "HDD", -- 热数据存HDD(或SSD)
"storage_cooldown_time" = "604800" -- 7天后(604800秒)迁移至OSS冷存
);
避坑2:冷数据查询延迟高
问题:OSS冷数据查询时需从对象存储加载,延迟高(10s+)。
解决方案:通过Doris的“预加载”功能,将高频查询的冷数据预热至BE节点内存。
示例代码:
-- 预热2025-01-01的冷数据至BE节点
ALTER TABLE logs
PARTITION p20250101
SET PROPERTIES ("preload" = "true");
5.2 VictoriaLogs落地避坑
避坑1:集群跨Zone部署数据不一致
问题:跨Zone部署时,vlinsert写入失败导致数据丢失。
解决方案:配置vlinsert的“跨Zone复制”参数,确保数据至少写入2个Zone。
Helm配置示例(values.yaml):
vlinsert:
extraArgs:
- --replicationFactor=2 # 数据至少复制2份(跨Zone)
- --zoneCount=2 # 2个Zone
- --storageNodes=vlstorage-zone1-0:8481,vlstorage-zone1-1:8481,vlstorage-zone2-0:8481,vlstorage-zone2-1:8481
避坑2:日志采集格式不规范导致查询难
问题:非结构化日志(如纯文本)无法按字段查询,需手动写正则,效率低。
解决方案:强制日志结构化(JSON格式),通过Filebeat/Fluent Bit自动解析字段。
Filebeat配置示例(结构化日志):
filebeat.inputs:
- type: log
paths: ["/var/log/nginx/access.log"]
json:
keys_under_root: true # JSON字段提至顶层
overwrite_keys: true # 覆盖默认字段
fields:
app: "nginx"
env: "prod"
output.http:
hosts: ["http://victoria-logs:9428/api/v1/import/es"] # 对接VictoriaLogs ES API
format: "json"
5.3 通用避坑:日志采集3个最佳实践
- 容器日志必用stdout输出:K8s环境下,容器日志不要写文件(Pod销毁日志丢失),通过stdout输出,由kubelet自动rotate,Filebeat DaemonSet采集。
- 日志必须结构化(JSON格式):非结构化日志解析复杂、性能差,JSON格式支持字段级查询(如
level="error"),无需正则。 - 日志带上trace_id/request_id:分布式系统排查时,通过trace_id串联全链路日志,避免断层(如
{trace_id="xxx"}查询全链路日志)。
五、选型决策树:3步锁定方案
六、总结与展望
2025年的日志系统选型,早已不是“ELK一家独大”,而是“场景化细分”——Apache Doris+OSS凭借“日志-业务数据一体化分析”,成为需要深度分析场景的首选;VictoriaLogs凭借“云原生极致效率”,成为轻量检索、成本敏感场景的黑马。
未来趋势:
- VictoriaLogs集群模式将进一步成熟,支持更多复杂聚合功能,有望在中大规模场景替代ELK/Loki;
- Apache Doris将强化日志冷存能力,与数据湖生态(如Iceberg)的联动更紧密,成为“湖仓一体”中的日志分析核心;
- 混合架构(VictoriaLogs实时检索+Doris深度分析)将成为大规模场景的主流,兼顾效率与深度。
选型的最终目标是“解决问题”——无论是Doris+OSS还是VictoriaLogs,只要能匹配你的业务需求、控制成本、降低运维复杂度,就是最佳方案。

魔乐社区(Modelers.cn) 是一个中立、公益的人工智能社区,提供人工智能工具、模型、数据的托管、展示与应用协同服务,为人工智能开发及爱好者搭建开放的学习交流平台。社区通过理事会方式运作,由全产业链共同建设、共同运营、共同享有,推动国产AI生态繁荣发展。
更多推荐


 27
27 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)