视觉语言导航的新突破:NaVILA框架详解与实现
NaVILA框架创新性地结合了视觉语言模型与运动控制系统,为腿式机器人提供高效的视觉语言导航能力。该框架采用两级架构:高层视觉语言模型处理自然语言指令和视觉输入,生成高层次动作指令;低层运动控制策略将这些指令转换为精确的关节控制命令。NaVILA通过特殊设计的导航提示、从人类视频中学习的方法,以及单阶段强化学习训练,显著提升了机器人在复杂环境中的导航性能。该框架已开源,支持多种机器人平台,在模拟和
0. 摘要
本文详细介绍了一种名为NaVILA(Navigation Vision-Language-Action)的创新框架,该框架针对腿式机器人的视觉语言导航任务,结合了视觉-语言-动作模型与运动控制的两级系统。NaVILA通过视觉语言模型(VLM)生成高层次动作指令,再由运动控制策略将其转换为精确的关节控制命令,显著提高了机器人在复杂环境中的导航能力。

1. 引言
随着人工智能和机器人技术的迅猛发展,使机器人能够理解人类语言指令并在复杂环境中导航已成为当前研究的重点方向。视觉语言导航(Vision-and-Language Navigation, VLN)作为智能机器人的一项关键能力,要求机器人根据自然语言指令和视觉观察来规划路径并导航至目标位置。
传统的VLN系统多集中于轮式机器人,通常依赖预计算地图或复杂的几何地图构建过程。然而,在现实世界的复杂场景中,尤其是对于腿式机器人,如四足机器人或人形机器人,这类方法往往面临严峻挑战。腿式机器人在导航过程中需要协调多个关节的精确运动,同时解决环境感知、路径规划和障碍物避开等问题,这使得其控制更为复杂。
来自加州大学圣地亚哥分校、南加利福尼亚大学和NVIDIA的研究团队针对这一挑战,提出了NaVILA(Legged Robot Vision-Language Action Model for Navigation)框架。这一框架创新性地结合了视觉语言模型(VLM)的强大语义理解能力与专业的运动控制系统,实现了从自然语言指令到精确关节控制的端到端映射。相关的代码已经在Github上开源了。
2. NaVILA框架详解
2.1 总体架构
NaVILA框架采用两级架构,将视觉语言理解与运动控制分离,如图1所示。这种设计使高层视觉语言模型能够以较低频率(10Hz)运行,处理复杂的语言指令和视觉信息,而低层运动控制则以较高频率(50Hz)运行,确保机器人动作的精确性和稳定性。
整个框架的工作流程可概括为以下几个步骤:
-
输入处理:系统接收自然语言导航指令和单视图RGB图像作为输入。
-
高层规划:视觉语言模型(VLM)处理当前图像和历史图像,并结合语言指令,生成中间层动作指令,如"向前移动0.5米"、"向右转30度"等。
-
低层控制:运动控制策略接收来自VLM的中间层指令,并将其转换为精确的关节动作,以控制机器人的运动。
-
感知与执行:控制器利用激光雷达传感器或视觉传感器感知环境,避开障碍物,并执行动作。
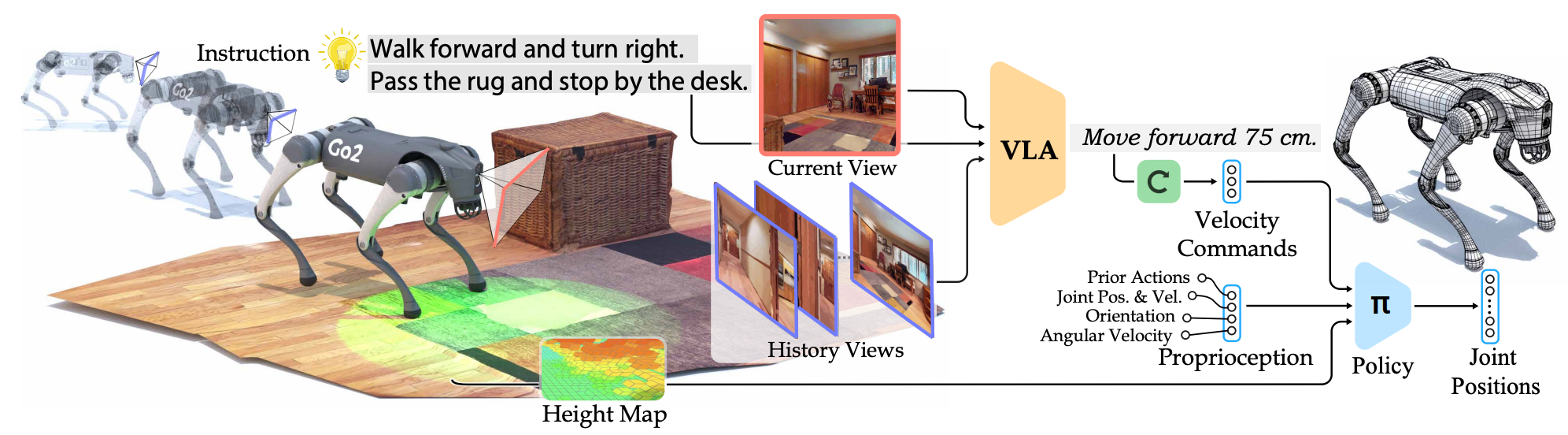
2.2 高层视觉语言模型
NaVILA的高层组件基于VILA(视觉语言模型)构建,用于处理视觉输入和语言指令,并生成中间层动作指令。该组件的关键创新点包括:
2.2.1 VILA基础
VILA由三个主要组件组成:视觉编码器、投影器和大型语言模型(LLM)。
- 视觉编码器:处理输入图像,将其转换为视觉标记序列。
- 投影器:通过多层感知机(MLP)将视觉标记映射到语义空间。
- 大型语言模型:接收投影后的视觉标记和文本标记,进行自回归生成。
VILA采用三阶段训练过程:
- 首先,使用对齐数据对冻结的LLM和视觉骨干之间的连接器进行预训练。
- 然后,使用文本-图像交错语料库对连接器和LLM进行联合预训练。
- 最后,使用指令调整数据对所有模块(视觉编码器、连接器、LLM)进行微调。
2.2.2 导航提示设计
在视觉语言导航中,不同时刻的图像具有不同作用:当前时刻的图像用于立即决策,而之前的帧则作为记忆库帮助智能体追踪整体进度。NaVILA采用特殊的提示设计来区分这两种表示:
- 首先提取最近的帧作为当前观察,然后从之前的帧中均匀采样,确保始终包括第一帧。
- 在任务提示中使用文本线索区分历史观察和当前观察,如"历史观察的视频:“和"当前观察:”。
- 将LLM的输入和输出保持在语言领域,充分利用预训练LLM的推理能力。
这种设计使模型能够更好地理解导航上下文,提高决策准确性。

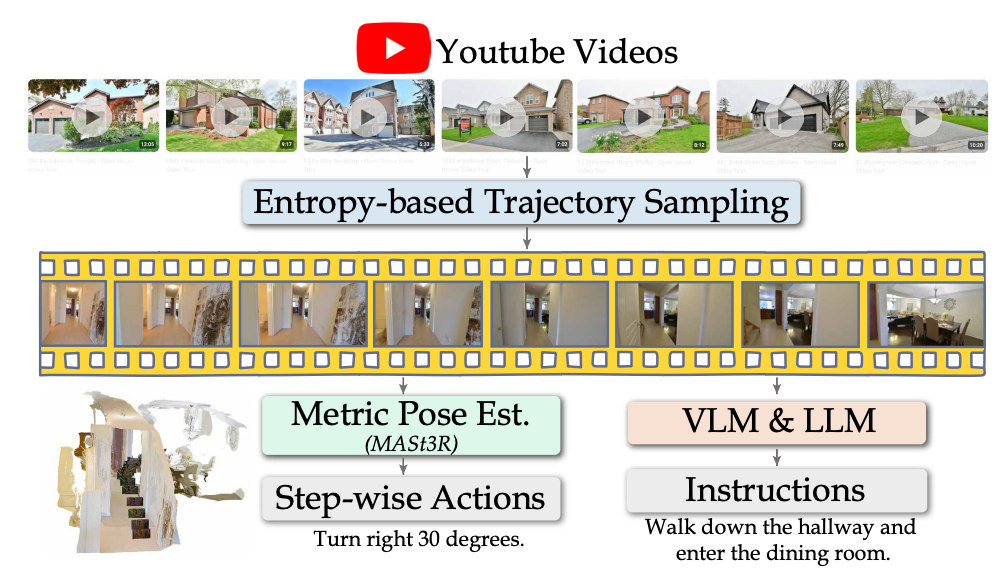
2.2.3 从人类视频中学习
NaVILA创新地利用了真实世界的人类导航视频来增强模型的导航能力。研究团队从YouTube上收集了2000个自我中心的旅游视频,并通过以下步骤处理成训练数据:
- 使用基于熵的采样方法对视频进行处理,提取20,000个多样且有代表性的样本。
- 利用MASt3R估计相机姿态,提取逐步操作。
- 通过基于VLM的字幕生成技术为每个轨迹生成自然语言指令,再通过LLM进行优化或改写。
这种方法使NaVILA能够从人类示范中学习连续导航技能,这在以往的研究中难以实现。
2.2.4 训练与推理
NaVILA的训练过程从VILA的第二阶段模型开始,该模型已经经过视觉-语言语料库的预训练。然后,应用监督微调(SFT)数据混合对整个VLM进行训练。
在推理阶段,使用正则表达式解析器从LLM输出中提取动作类型及其对应的参数。这种方法在模拟环境和真实世界实验中均展现出良好的有效性。
2.3 低层运动控制策略
低层运动控制策略负责将高层生成的语言形式导航指令转换为精确的关节运动。该组件的核心设计包括:
2.3.1 机器人平台
研究团队使用Go2机器人作为主要实验平台。该机器人在头部底部配备了激光雷达传感器,频率为15Hz,具有18个自由度(DoFs),其中腿部有12个DoFs。在训练过程中,策略仅控制腿部的12个关节电机,而基座的6个DoFs保持不受约束。
2.3.2 命令解释
VLM输出如"向前移动"、"左转"等动作词,低层策略将其转换为固定的命令速度(如0.5 m/s、π/6 rad/s等),并执行相应的时间以匹配VLM指定的值。
2.3.3 动作和观察空间
- 动作空间:定义为期望的关节位置,通过刚度和阻尼参数转换为模拟器的扭矩输入。
- 观察空间:包括当前的本体感受数据和地形高度扫描。采用PPO算法训练策略,其中critic观察特权环境信息生成价值函数,而actor仅接收现实世界中可获得的传感器数据。
2.3.4 激光雷达高度图
为了增强环境感知能力,NaVILA使用激光雷达传感器创建2.5D高度图。高度图通过选择每个体素网格内的最低点值并进行最大滤波来生成,这使机器人能够准确感知周围地形并确保安全导航。

2.3.5 单阶段强化学习训练
与现有工作中普遍采用的两阶段教师-学生训练范式不同,NaVILA采用单阶段强化学习框架直接与环境交互进行训练。这种方法不仅省去了策略蒸馏的需求,还使策略能够通过直接探索发现潜在的最优控制策略。
在Isaac Sim模拟器的支持下,训练过程能够在RTX 4090 GPU上实现超过60K FPS的高吞吐量,大大提高了训练效率。
3. 代码实现深度解析
NaVILA框架的开源实现主要包括以下几个部分:核心模块、机器人配置、MDP组件和强化学习算法。以下对代码的关键部分进行解析。
3.1 NaVILA核心模块
NaVILA的代码库主要分为以下几个部分:
isaaclab_exts/ - Isaac Lab的扩展
rsl_rl/ - 强化学习框架
scripts/ - 训练和演示脚本
src/ - 资源文件
其中isaaclab_exts/是Isaac Lab的核心扩展模块,包含了机器人配置和控制逻辑:
isaaclab_exts/
omni.isaac.leggedloco/ - 主要扩展模块
config/ - 不同机器人的配置
g1/ - G1机器人配置
go1/ - Go1机器人配置
go2/ - Go2机器人配置
h1/ - H1机器人配置
leggedloco/ - 核心功能实现
mdp/ - MDP相关实现
actions/ - 动作空间定义
commands/ - 命令生成器
rewards/ - 奖励函数
utils/ - 工具函数
每种机器人(G1, Go1, Go2, H1)都有两类主要配置:
- 基础配置(
*_low_base_cfg.py) - 包含基础运动控制,不使用视觉信息 - 视觉配置(
*_low_vision_cfg.py) - 基础配置基础上增加视觉感知能力
这种模块化设计使系统能够灵活适应不同机器人平台和感知需求。
3.2 H1人形机器人配置解析
以H1人形机器人配置为例,详细分析其基础配置和视觉配置的核心差异:
3.2.1 基础配置 (h1_low_base_cfg.py)
基础配置主要包括以下几个部分:
- PPO训练配置:定义了PPO算法的核心参数,如步数、迭代次数、神经网络架构等。
class H1RoughPPORunnerCfg:
num_steps_per_env = 32
max_iterations = 50000
save_interval = 500
actor_hidden_dims = [512, 256, 128]
critic_hidden_dims = [512, 256, 128]
# 其他PPO参数...
- 地形配置:定义了简单的地形类型混合,主要是平坦地形和轻微随机粗糙地形。
BASE_TERRAIN_CFG = TerrainGeneratorCfg(
terrain_proportions=[0.5, 0.5], # 50%平坦, 50%随机粗糙
terrain_types=["flat", "random_rough"],
# 其他地形参数...
)
- 观察空间配置:定义了策略网络的输入,包含基本动作信息和噪声,如线速度、角速度、重力、关节状态等。
class ObservationsCfg:
class PolicyCfg(ObsGroup):
base_lin_vel = ObsTerm(func=mdp.base_lin_vel)
base_ang_vel = ObsTerm(func=mdp.base_ang_vel)
# 其他观察项...
- 奖励与指令配置:定义了各种奖励函数,包括速度跟踪、姿态保持和能量效率等。
class CustomH1Rewards(H1Rewards):
feet_stumble = RewTerm(
func=mdp.feet_stumble,
weight=-0.5,
# 其他参数...
)
3.2.2 视觉配置 (h1_low_vision_cfg.py)
视觉配置基于基础配置进行扩展,主要增加了以下功能:
- 复杂地形配置:定义了七种不同类型的地形,包括阶梯、斜坡和障碍物等。
ROUGH_TERRAINS_CFG = TerrainGeneratorCfg(
terrain_proportions=[0.2, 0.2, 0.2, 0.2, 0.1, 0.1, 0.2],
terrain_types=["pyramid_stairs", "inverse_pyramid_stairs", "random_boxes", "random_rough", "pyramid_slope", "inverse_pyramid_slope", "discrete_obstacles"],
# 复杂地形参数...
)
- 视觉传感器配置:添加了高度扫描器,使用射线投射技术检测地形高度。
height_scanner = RayCasterCfg(
prim_path="{ENV_REGEX_NS}/Robot/base",
offset=RayCasterCfg.OffsetCfg(pos=(0.0, 0.0, 20.0)),
pattern_cfg=patterns.GridPatternCfg(resolution=0.1, size=[1.6, 1.0]),
# 其他参数...
)
- 观察空间扩展:策略网络输入增加了地形高度扫描信息。
height_scan = ObsTerm(
func=mdp.height_scan,
params={"sensor_cfg": SceneEntityCfg("height_scanner")},
clip=(-1.0, 1.0),
)
两种配置的主要区别在于:视觉配置通过环境感知增强了H1机器人的感知能力,使其能够"看到"并适应更加复杂多变的地形,而基础配置则更多依赖于反应式控制策略,缺乏对环境的前瞻性认知。
3.3 马尔可夫决策过程(MDP)组件
mdp目录包含了马尔可夫决策过程的关键组件,这是强化学习环境的核心部分。这些组件主要包括:
3.3.1 动作空间定义
actions目录下实现了多种动作空间定义,以navigation_actions.py为例,它实现了一个分层控制系统:
class NavigationAction:
def __init__(self, cfg, env):
# 加载低层策略
self.low_level_policy = torch.jit.load(file_bytes, map_location=self.device)
self.low_level_policy = torch.jit.freeze(self.low_level_policy.eval())
# 准备动作缓冲区
self._raw_navigation_velocity_actions = torch.zeros(self.num_envs, self._action_dim, device=self.device)
self._processed_navigation_velocity_actions = torch.zeros((self.num_envs, 3), device=self.device)
def process_actions(self, actions):
# 处理高层导航动作,10Hz频率
self._raw_navigation_velocity_actions[:] = actions
self._processed_navigation_velocity_actions[:] = actions.clone().view(self.num_envs, 3)
def apply_actions(self):
# 应用低层动作,50Hz频率(通过200Hz的4:1抽样)
if self._counter % self.cfg.low_level_decimation == 0:
self._counter = 0
self._env.command_manager.compute(dt=self._low_level_step_dt)
self._low_level_actions[:] = self.low_level_policy(
self._env.observation_manager.compute_group(group_name="low_level_policy")
)
self.low_level_action_term.process_actions(self._low_level_actions)
self.low_level_action_term.apply_actions()
self._counter += 1
这种分层设计将复杂的导航问题分解为"决策"和"执行"两个相对独立的子问题,大大简化了系统的开发和维护。
3.3.2 奖励函数设计
rewards目录下包含了各种奖励函数的实现,如objnav_rewards.py中定义了机器人目标导航的奖励设计:
# 存活奖励
def is_alive(env: ManagerBasedRLEnv) -> torch.Tensor:
return (~env.termination_manager.terminated).float()
# 终止惩罚
def is_terminated(env: ManagerBasedRLEnv) -> torch.Tensor:
return env.termination_manager.terminated.float()
# 平面方向保持奖励
def flat_orientation_l2(env: ManagerBasedRLEnv, asset_cfg: SceneEntityCfg = SceneEntityCfg("robot")) -> torch.Tensor:
asset: RigidObject = env.scene[asset_cfg.name]
return torch.sum(torch.square(asset.data.projected_gravity_b[:, :2]), dim=1)
# 目标距离奖励
def goal_distance(env: ManagerBasedRLEnv, command_name: str, asset_cfg: SceneEntityCfg = SceneEntityCfg("robot")) -> torch.Tensor:
asset: RigidObject = env.scene[asset_cfg.name]
goal_track_error_pos = torch.norm(env.command_manager.get_command(command_name)[:,:2], dim=1)
reward = torch.where(goal_track_error_pos < 1.0, torch.tensor(1.0, device=env.device), torch.exp(-0.2*goal_track_error_pos))
return reward
这些奖励函数从多个方面引导机器人的行为,包括基本生存、姿态稳定、动作平滑和目标导向等,共同构成了一个全面的奖励系统,使机器人能够学习到有效的导航策略。
3.4 PPO强化学习算法实现
NaVILA的低层运动控制策略使用PPO(近端策略优化)算法进行训练。rsl_rl/algorithms/ppo.py中实现了完整的PPO算法:
class PPO:
def __init__(self, actor_critic, learning_rate=1e-3, clip_param=0.2, gamma=0.99, lam=0.95, ...):
# 初始化PPO组件
self.actor_critic = actor_critic
self.optimizer = optim.Adam(self.actor_critic.parameters(), lr=learning_rate)
self.clip_param = clip_param
self.gamma = gamma
self.lam = lam
def update(self):
# 多个epoch迭代更新
for (obs_batch, critic_obs_batch, actions_batch, ...) in generator:
# 重新计算当前策略下的值
actions_log_prob_batch = self.actor_critic.get_actions_log_prob(actions_batch)
value_batch = self.actor_critic.evaluate(critic_obs_batch, ...)
# 计算重要性采样比率
ratio = torch.exp(actions_log_prob_batch - torch.squeeze(old_actions_log_prob_batch))
# 计算代理损失(未裁剪和裁剪)
surrogate = -torch.squeeze(advantages_batch) * ratio
surrogate_clipped = -torch.squeeze(advantages_batch) * torch.clamp(ratio, 1.0 - self.clip_param, 1.0 + self.clip_param)
surrogate_loss = torch.max(surrogate, surrogate_clipped).mean()
# 计算价值损失
if self.use_clipped_value_loss:
value_clipped = target_values_batch + (value_batch - target_values_batch).clamp(-self.clip_param, self.clip_param)
value_losses = (value_batch - returns_batch).pow(2)
value_losses_clipped = (value_clipped - returns_batch).pow(2)
value_loss = torch.max(value_losses, value_losses_clipped).mean()
else:
value_loss = (returns_batch - value_batch).pow(2).mean()
# 计算总损失并更新
loss = surrogate_loss + self.value_loss_coef * value_loss - self.entropy_coef * entropy_batch.mean()
self.optimizer.zero_grad()
loss.backward()
nn.utils.clip_grad_norm_(self.actor_critic.parameters(), self.max_grad_norm)
self.optimizer.step()
PPO算法的关键特点是使用裁剪目标函数,避免策略更新过大导致训练不稳定。此外,实现中还包含了自适应学习率调整、价值函数裁剪和熵正则化等高级特性,进一步提高了训练的稳定性和效率。
3.5 视觉增强的神经网络架构
NaVILA框架中的视觉处理能力主要通过几种专门的神经网络架构实现,这些架构使机器人能够从深度图像中提取关键特征,从而实现更高效的导航。以下是核心网络组件的详细解析:
3.5.1 基础Actor-Critic架构
在NaVILA中,最基础的神经网络模型是ActorCritic类,它实现了标准的策略网络(Actor)和价值网络(Critic):
class ActorCritic(nn.Module):
def __init__(self, num_actor_obs, num_critic_obs, num_actions,
actor_hidden_dims=[256, 256, 256],
critic_hidden_dims=[256, 256, 256],
activation="elu", init_noise_std=1.0, **kwargs):
# ...初始化代码...
# 策略网络(Actor)构建
actor_layers = []
actor_layers.append(nn.Linear(mlp_input_dim_a, actor_hidden_dims[0]))
actor_layers.append(activation)
# ...构建剩余层...
self.actor = nn.Sequential(*actor_layers)
# 价值网络(Critic)构建
critic_layers = []
# ...构建各层...
self.critic = nn.Sequential(*critic_layers)
# 动作分布参数
self.std = nn.Parameter(init_noise_std * torch.ones(num_actions))
self.distribution = None
这种架构通过多层全连接网络处理低维状态观察,适用于不需要视觉输入的场景。
3.5.2 深度CNN增强的Actor-Critic
为了处理深度图像,NaVILA实现了ActorDepthCNN类,它将传统的本体感受(proprioceptive)观察与深度视觉特征相结合:
class ActorDepthCNN(nn.Module):
def __init__(self, num_obs_proprio, obs_depth_shape, num_actions,
activation, hidden_dims=[256, 256, 128]):
# ...初始化代码...
# 处理本体感受输入的MLP
self.prop_mlp = nn.Sequential(
nn.Linear(num_obs_proprio, hidden_dims[0]),
activation,
# ...其他层...
)
# 处理深度图像的CNN骨干
self.depth_backbone = DepthOnlyFCBackbone(
output_dim=hidden_dims[2],
hidden_dim=hidden_dims[1],
activation=activation,
num_frames=1,
)
# 合并特征并输出动作
self.action_head = nn.Linear(2 * hidden_dims[2], num_actions)
这个设计的核心思想是双通道处理:
- 本体感受通道:通过MLP处理关节状态和其他传感器读数
- 视觉通道:通过CNN处理深度图像
- 特征融合:将两个通道的特征连接起来,共同决策最终动作
ActorCriticDepthCNN类整合了上述Actor设计和一个标准的Critic网络:
class ActorCriticDepthCNN(nn.Module):
def __init__(self, num_actor_obs, num_critic_obs, num_actions,
num_actor_obs_prop=48, obs_depth_shape=(15, 15),
actor_hidden_dims=[256, 256, 128],
critic_hidden_dims=[256, 256, 128],
activation="elu", init_noise_std=1.0, **kwargs):
# ...初始化代码...
# 构建Actor网络
self.actor = ActorDepthCNN(num_actor_obs_prop, obs_depth_shape,
num_actions, activation, actor_hidden_dims)
# 构建Critic网络(仍使用MLP处理高维特权观察)
critic_layers = []
# ...构建各层...
self.critic = nn.Sequential(*critic_layers)
3.5.3 循环记忆增强的视觉处理
为了处理时序信息,NaVILA实现了ActorCriticDepthCNNRecurrent类,它在上述深度CNN架构的基础上增加了循环神经网络(RNN)组件:
class ActorCriticDepthCNNRecurrent(ActorCriticDepthCNN):
is_recurrent = True
def __init__(self, num_actor_obs, num_critic_obs, num_actions,
# ...其他参数...
rnn_type="lstm", rnn_input_size=256,
rnn_hidden_size=256, rnn_num_layers=1,
init_noise_std=1.0, **kwargs):
# 初始化基础CNN架构
super().__init__(...)
# 添加Actor和Critic的记忆模块
self.memory_a = Memory(rnn_input_size, type=rnn_type,
num_layers=rnn_num_layers,
hidden_size=rnn_hidden_size)
self.memory_c = Memory(rnn_input_size, type=rnn_type,
num_layers=rnn_num_layers,
hidden_size=rnn_hidden_size)
这种设计的关键优势在于:
- 时序记忆:能够记住之前的观察和动作,在连续决策中保持一致性
- 上下文理解:理解环境的动态变化,而不仅仅是单帧信息
- 长期规划:基于历史信息做出更好的长期决策
3.5.4 视觉处理与决策流程
在实际运行过程中,视觉增强的神经网络按以下流程处理信息:
-
输入分离:将原始观察分为本体感受数据和深度图像
prop_input = observations[..., :self.num_obs_proprio] depth_input = observations[..., self.num_obs_proprio:] -
并行处理:本体感受数据通过MLP处理,深度图像通过CNN处理
prop_latent = self.prop_mlp(prop_input) depth_latent = self.depth_backbone(depth_input) -
特征融合:将两个通道的特征连接起来
combined_features = torch.cat((prop_latent, depth_latent), dim=-1) -
时序处理(如果使用循环网络):通过RNN处理时序信息
input_a = self.memory_a(observations, masks, hidden_states) -
动作生成:基于处理后的特征生成动作分布
actions_mean = self.actor.action_head(features) self.distribution = Normal(actions_mean, mean * 0.0 + self.std)
这种多层次、多通道的神经网络架构使NaVILA能够高效处理复杂的视觉信息,为腿式机器人提供精准的导航决策支持。
4. 总结与展望
本文详细介绍了NaVILA框架,一种创新的腿式机器人视觉语言导航方法。NaVILA通过将视觉语言模型与运动控制策略有机结合,实现了从自然语言指令到精确机器人控制的端到端映射。
NaVILA为腿式机器人在复杂环境中的自主导航开辟了新的道路。随着技术的进一步发展,我们可以期待看到更加智能、自然和高效的机器人导航系统,这将极大地扩展机器人在家庭服务、灾难救援、勘探等领域的应用潜力。

魔乐社区(Modelers.cn) 是一个中立、公益的人工智能社区,提供人工智能工具、模型、数据的托管、展示与应用协同服务,为人工智能开发及爱好者搭建开放的学习交流平台。社区通过理事会方式运作,由全产业链共同建设、共同运营、共同享有,推动国产AI生态繁荣发展。
更多推荐


 18
18 0
0- 0



 已为社区贡献60条内容
已为社区贡献60条内容

所有评论(0)