sklearn数据集随机切分(train_test_split)
sklearn学习给定数据集X和类别标签y,将数据集按一定比例随机切分为训练集和测试集。代码#!/usr/bin/env python# -*- coding: utf-8 -*-"""功能:数据集按比例切分为训练集和测试集时间:2017年3月11日 12:48:57"""from sklearn.cross_validation import trai
·
sklearn学习
给定数据集X和类别标签y,将数据集按一定比例随机切分为训练集和测试集。
代码
#!/usr/bin/env python
# -*- coding: utf-8 -*-
"""
功能:数据集按比例切分为训练集和测试集
时间:2017年3月11日 12:48:57
"""
from sklearn.cross_validation import train_test_split
# 生成200个句子,前100个和后100个类别分别对应1和2
X = [[u"这是", u"第1个", u"测试"]] * 100 + [[u"这是", u"第2个", u"测试"]] * 100
y = [1] * 100 + [2] * 100
# 随机抽取20%的测试集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2)
print len(X_train), len(X_test)
# 查看句子和标签是否仍然对应
for i in range(len(X_test)):
print "".join(X_test[i]), y_test[i]
if __name__ == "__main__":
pass
- 1
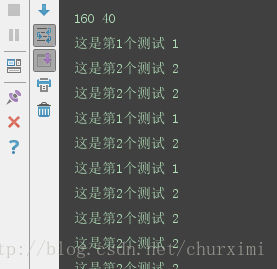
实验结果
切分后的训练集和测试集标签仍然一一对应。

魔乐社区(Modelers.cn) 是一个中立、公益的人工智能社区,提供人工智能工具、模型、数据的托管、展示与应用协同服务,为人工智能开发及爱好者搭建开放的学习交流平台。社区通过理事会方式运作,由全产业链共同建设、共同运营、共同享有,推动国产AI生态繁荣发展。
更多推荐


 2
2 0
0- 0



 已为社区贡献5条内容
已为社区贡献5条内容

所有评论(0)