大模型本地部署经验小谈
分模型下载、模型部署和模型微调三部分介绍大模型在服务器上的部署
本文分模型下载、模型部署和模型微调三部分介绍大模型在服务器上的部署,如下:
一、模型下载
模型选择
首先,在模型下载前,可以估算一下可用计算资源(CPU内存、GPU显存等)的大小,选择一个合适参数量的模型(可以参考https://blog.csdn.net/2401_85373691/article/details/145449755,该网站给出了各参数量模型预计的内存和显存需求),然后选择该参数量下性能公认比较好的模型进行下载尝试(可以去https://lmarena.ai/leaderboard或者https://rank.opencompass.org.cn/home这些排名网站,它们会给所有大模型在各个领域上的能力进行排名,可以去适合自己任务的榜单上寻找合适的模型)。
下载
对于模型的下载,目前,许多网站都提供了各种开源模型用于本地下载部署,常用的网站有Ollama(https://ollama.com/)、魔搭社区(https://www.modelscope.cn/)、Hugging Face(https://huggingface.co/)等。
它们的下载流程几乎都是一致的,因此,下面就仅以使用 Hugging Face 模型下载gemma-2-2b-it模型为例演示模型的下载过程。
Hugging Face上模型下载大致有两种方式,分别是手动下载和命令行下载:
手动下载
由于网络连接问题,Hugging Face 需要连接梯子,服务器连接vpn比较麻烦, 因此手动下载需要先将模型下载到本机。打开 Hugging Face 官网(https://huggingface.co/),搜索gemma-2-2b-it,点击Files,然后将所有文件下载到本地。
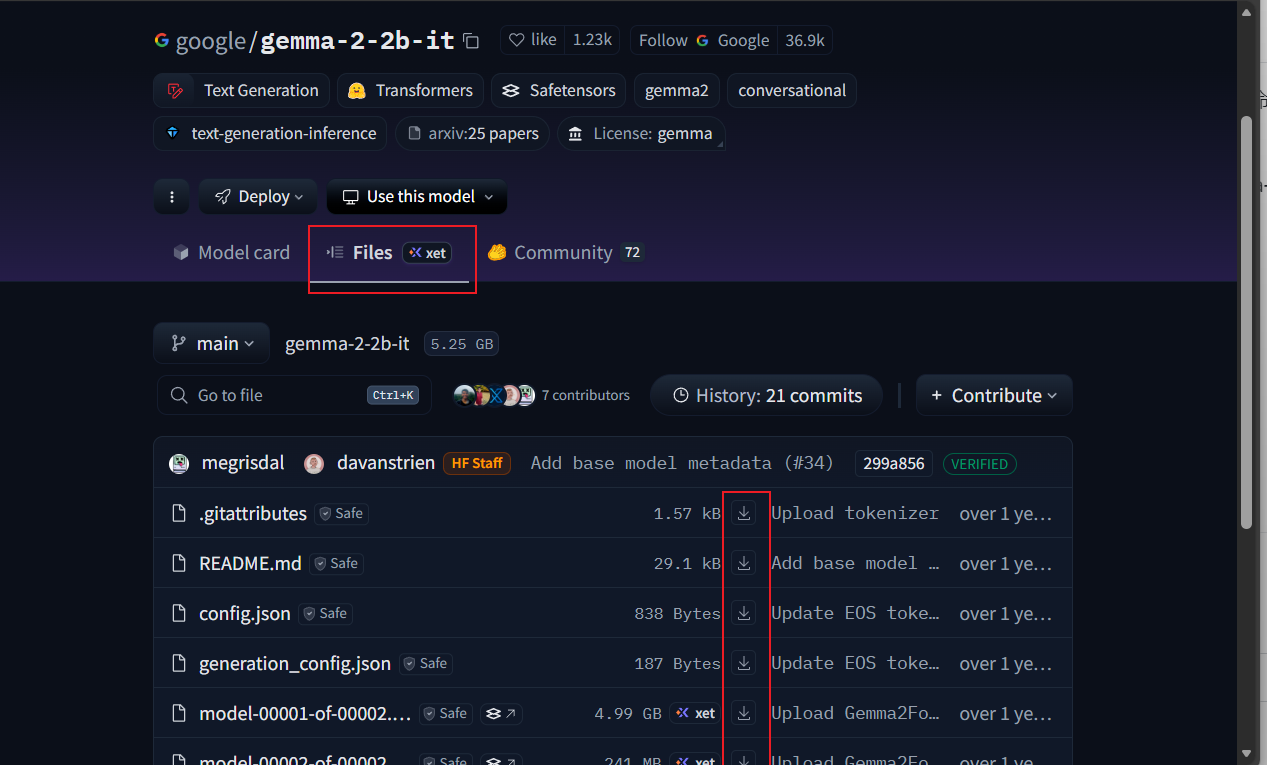
大部分的模型无需登录账号即可完成下载。不过部分模型,比如 gemma-2-2b-it 模型出于版权保护原因,需要登录账号,完成谷歌认证才能下载,此时正常注册账号登录验证即可。
下载完成后将文件上传到服务器即可。
命令行下载
1. 安装官方提供的命令行工具huggingface_hub
pip install -U huggingface_hub2.由于网络连接问题,服务器无法直接接入huggingface官网,因此,需要使用镜像网站
可以使用如下命令临时添加镜像网站
export HF_ENDPOINT=https://hf-mirror.com为了之后下载方便,建议将镜像网站写入~/.bashrc 文件
vim ~/.bashrc
敲击大写G跳至末尾,i进入编辑,复制export HF_ENDPOINT=https://hf-mirror.com,按 Esc 退出编辑模式,:wq退出vim
source ~/.bashrc #使bashrc文件生效3.下载模型
对于无需授权的模型,前往Hugging Face 官网搜索,复制完整名称
然后直接在终端输入命令行,即可开始下载
hf download 模型名称 --local-dir 要保存的文件位置不过部分模型,如gemma-2-2b-it,首先需要在官网搜索模型,在模型首页位置点击完成授权
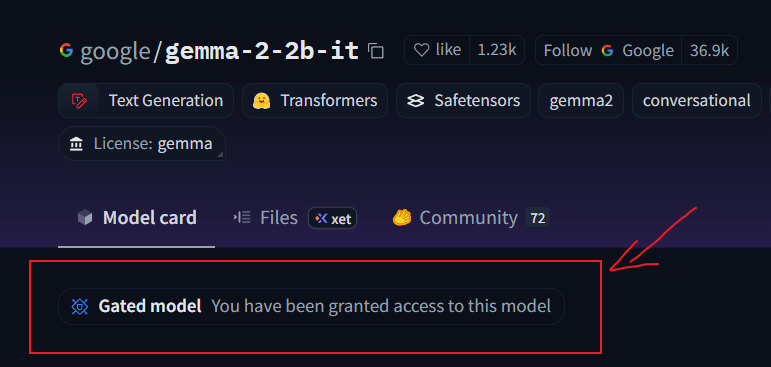
为了在命令行中使用,还需要Access Token,在官网点击右上角个人头像,点击setting -> Access Tokens生成token,复制该token值。
命令行输入
hf auth login随后会要求输入账号和token进行登录,登录后输入同样的命令即可 开始下载
hf download google/gemma-2-2b-it --local-dir gemma-2-2b-it
#其中 google/gemma-2-2b-it为模型名称,--local-dir后为保存的文件位置下载成功^_^
二、模型部署
模型下载完成后,调用模型的过程就非常简单了
安装依赖
首先安装运行所需的一些依赖
#安装torch、transformers 和 accelerate
pip install torch transformers accelerate -i https://mirrors.aliyun.com/pypi/simple/调用模型
在模型的README.md文件中有非常详细的调用代码,可以阅读其中的教程编写代码运行,不过最简便的方法就是直接将README文件发给AI, 让它编写运行代码即可。
还可以告知它使用temperature、top_p等参数调节模型的生成效果。
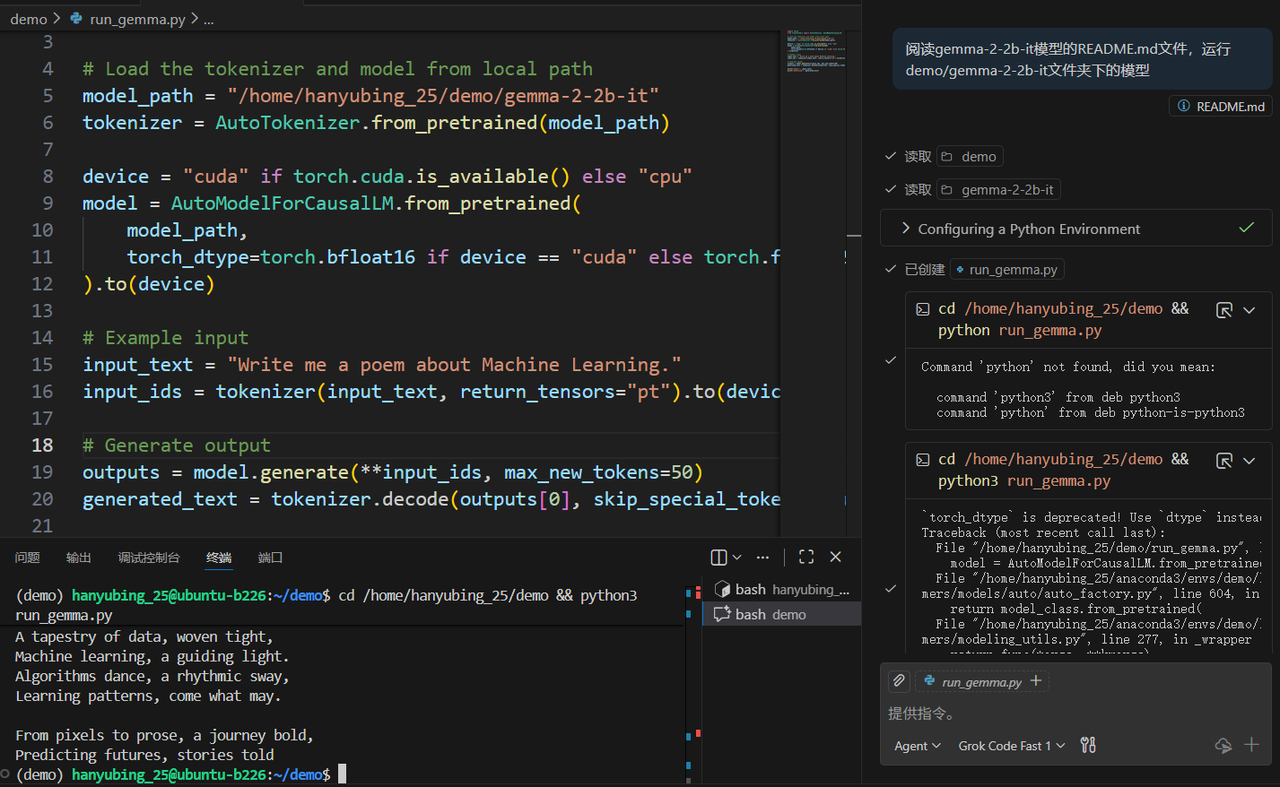
运行成功,非常easy(mac本 需要告知大模型,将cuda替换成mps)
在自己的训练任务中使用时代码几乎是一样的,复制过去即可。
多GPU运行
可以安装nvitop或nvidia-smi文件观察运行中的显存占用情况
pip install nvitop nvitop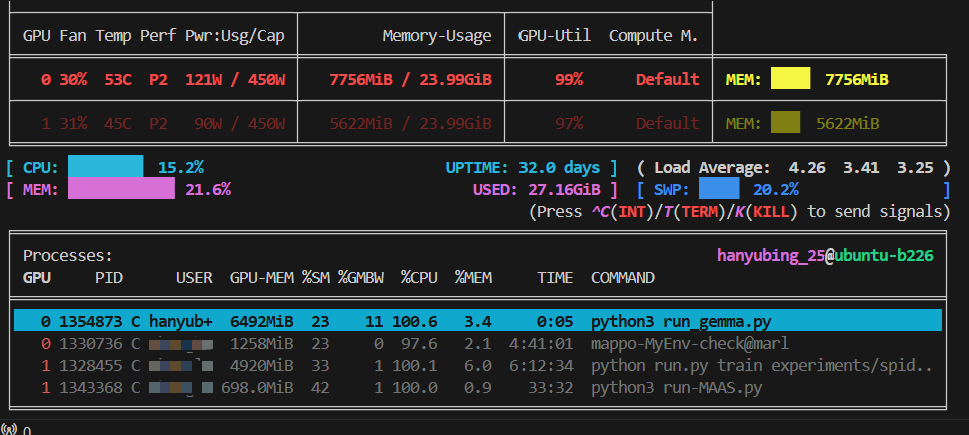
从显存使用情况看到目前代码只使用了一张GPU,有时GPU资源比较紧张,一张GPU的显存可能不够运行模型,此时可以修改代码使得模型在多张GPU上运行,只需在python代码模型调用部分加一行device_map="auto"即可,python 代码如下:
model = AutoModelForCausalLM.from_pretrained(
model_path,
device_map="auto",
dtype=torch.bfloat16 if torch.cuda.is_available() else torch.float32,
)运行后使用 nvitop 命令可以看到模型运行在两张GPU上
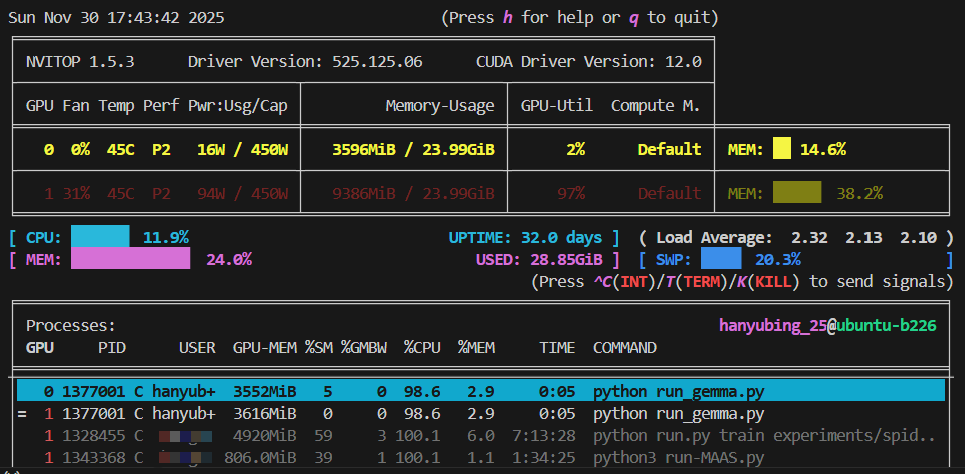
量化
如果此时模型占用显存仍然较大,可以使用"量化"技术进一步缩小模型显存占用(代码可以直接让AI生成),量化技术通过降低模型权重、激活值等参数的数值精度缩小运存,但同时也会导致模型能力下降。
#首先下载 bitsandbytes 依赖
pip install bitsandbytes -i https://mirrors.aliyun.com/pypi/simple/分别运行8bit量化和4bit量化代码:
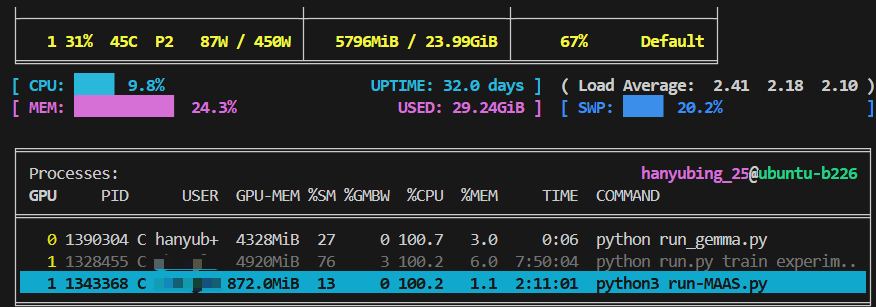
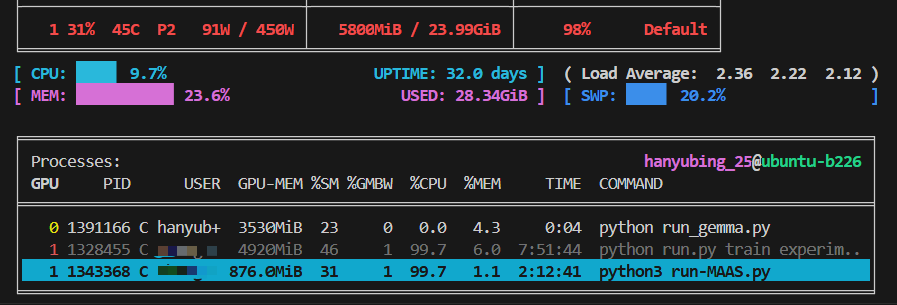
可以看到模型GPU占用有一定程度的降低。
不过注意使用量化后一定要测试一下模型的能力,有部分模型使用量化可能导致模型能力下降过多,回答无法使用,比如,有时会出现下面的情况:
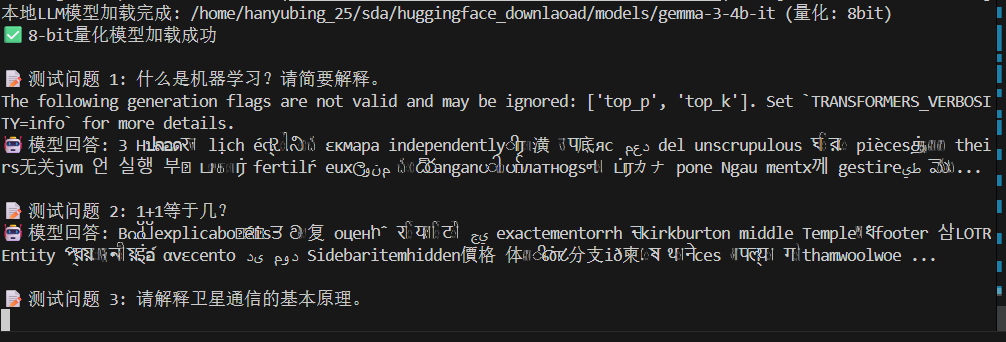
Advanced Usage
在README.md文件中,通常还会详细介绍模型的各种高级用法,gemma-2-2b-it 文档中介绍了fast run 技术,可以提高模型矩阵推理的速度,可以将模型回答速度提升至原来的6倍(实测相关环境配置处理冲突比较麻烦,会提升运行时所需的显存,有需求可以尝试一下)、Chat Template 会给出模型 prompt 模板书写相关的代码,按照提供的方式书写 prompt 会让使用更方便…… 还有很多详细的内容,感兴趣可以自行阅读。
三、模型微调
为了提升模型在特定任务上的能力,可以对模型进行微调,例如,可以先使用能力更强的大模型完成要处理的任务,然后挑选其中的高质量数据制作数据集,再将数据集喂给本地模型进行微调。
微调有多种方式,全参数微调(Full Fine-tuning)、LoRA(Low-Rank Adaptation)、QLoRA(Quantized LoRA)。
全参数微调会将模型所有参数全部更新,占用显存极大;LoRA冻结原模型参数,新增少量低秩矩阵参数更新;QLoRA会先量化原模型,再新增低秩矩阵参数更新。
通常微调占用的显存会比使用模型大得多,为了减少微调时的显存占用,下面采用QLoRA方式进行演示。
以下是具体示例:
-
首先安装相关依赖
# 安装 datasets,用于数据集读取相关操作 pip install datasets -i https://mirrors.aliyun.com/pypi/simple/ # peft用于LoRA相关操作 pip install peft -i https://mirrors.aliyun.com/pypi/simple/ -
制作数据集
数据集的形式其实并不严格,可以根据任务形式采用多种多样的格式,例如可以将数据集制作成instruction+response格式
-
编写微调代码
代码编写直接交给AI即可,和一个监督学习的过程没什么区别。设置一下数据集位置,模型位置和微调文件的存放位置就好。
-
部署微调后的模型
微调后会生成很多文件,存放在输出目录中,它们就相当于一个适配器(adapter), 因此想要使用微调后的模型,只需要指定基础模型文件位置和适配器文件位置即可,其他过程和基础模型部署没有区别。
不过需要注意,如果微调使用的是QLoRA,即微调时进行了量化操作,那这里部署的时候最好也用相同的量化,避免一些奇奇怪怪的报错。
运行成功,经过微调后的模型通常在相应任务上的表现会比基础模型好一些。
四、常见问题
1.AttributeError: 'XXX' object has no attribute 'XX'
可以检查一下镜像网站是否配置,可能由于网络问题,相关依赖未完整下载,配置好镜像后,使用 pip install --force-reinstall XXX, 重新下载相关依赖。
2.ERROR: Could not find a version that satisfies the requirement transformers≥4.35.0 (from versions: ...)
一般都是因为python版本太低了,升级一下python版本。
3.RuntimeError: Conflicting 'transformers' versions detected: 4.20.0 and 4.38.0
版本冲突,相同环境下有多个版本,此时卸载所有版本后重新下载即可。
pip uninstall -y transformers accelerate peft
pip install -U -y transformers accelerate peft -i 镜像源4.OSError: Error loading ./gemma-2-2b-it/model-00001-of-00002.safetensors: file does not exist RuntimeError: Error(s) in loading state_dict for GemmaForCausalLM: Missing key(s) in state_dict
模型文件损坏,可能是文件下载过程中中断了,重新下载一遍模型即可。

魔乐社区(Modelers.cn) 是一个中立、公益的人工智能社区,提供人工智能工具、模型、数据的托管、展示与应用协同服务,为人工智能开发及爱好者搭建开放的学习交流平台。社区通过理事会方式运作,由全产业链共同建设、共同运营、共同享有,推动国产AI生态繁荣发展。
更多推荐



 15
15 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)