David Silver UCL强化学习课程学习笔记五之Model-Free Control 无模型控制
Lecture 5: Model-Free Controlhttps://www.davidsilver.uk/wp-content/uploads/2020/03/control.pdfIntroduction同策略和异策略概念,同策略说的是用于采样sample的p和要学习更新的policy一致,即learn on the job。异策略知道是学习和采样用不同的策略。On-Policy Mont
Lecture 5: Model-Free Control
https://www.davidsilver.uk/wp-content/uploads/2020/03/control.pdf
Introduction

同策略和异策略概念,同策略说的是用于采样sample的p和要学习更新的policy一致,即learn on the job。异策略知道是学习和采样用不同的策略。
On-Policy Monte-Carlo Control
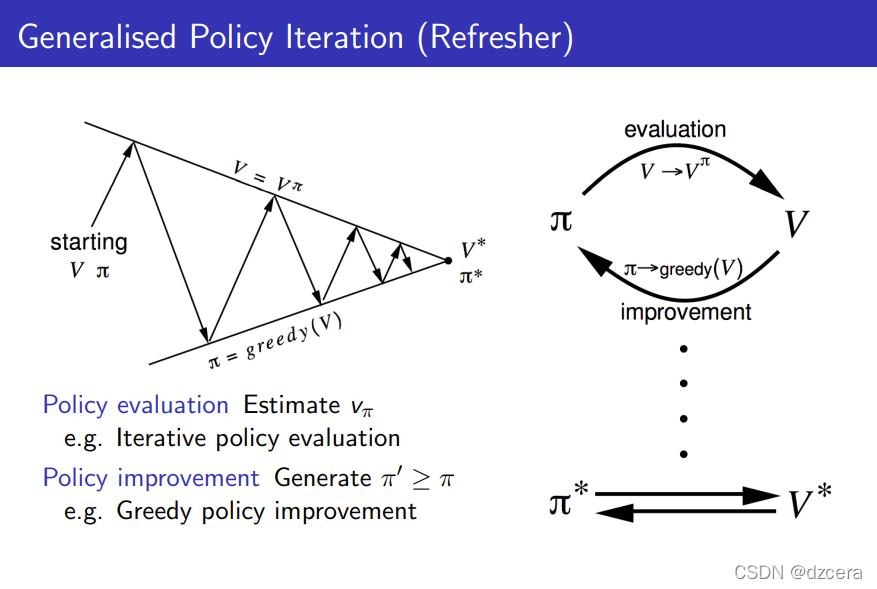
MC策略迭代在估计中用q函数 ,在策略改进中用的

GLIE用于解决学习开始时有足够的探索,最终得到的策略没有探索,是一个确定策略的问题。最终收敛到的greedy策略即为确定性策略。
On-Policy Temporal-Difference Learning
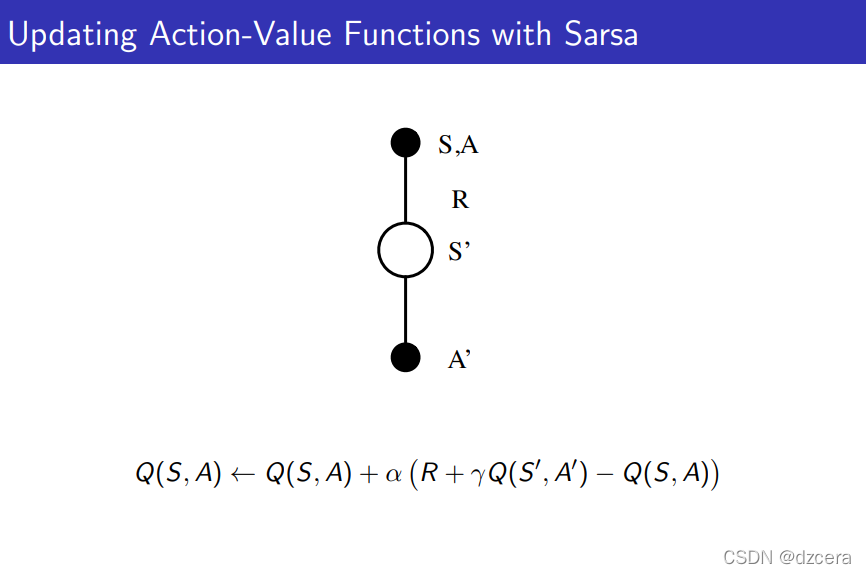
更改同策略MC控制中对值函数的估计的MC方法换位TD方法,将每个片段对值函数更新一次换位每个时间步更新一次。这里策略估计方法是sarsa。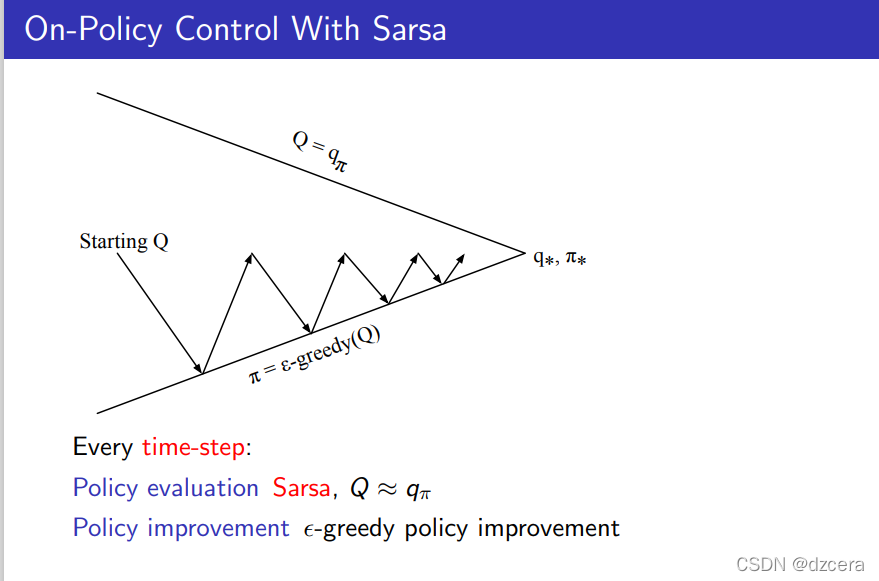
与TD类似 n步 sarsa

Sarsa(λ)算法
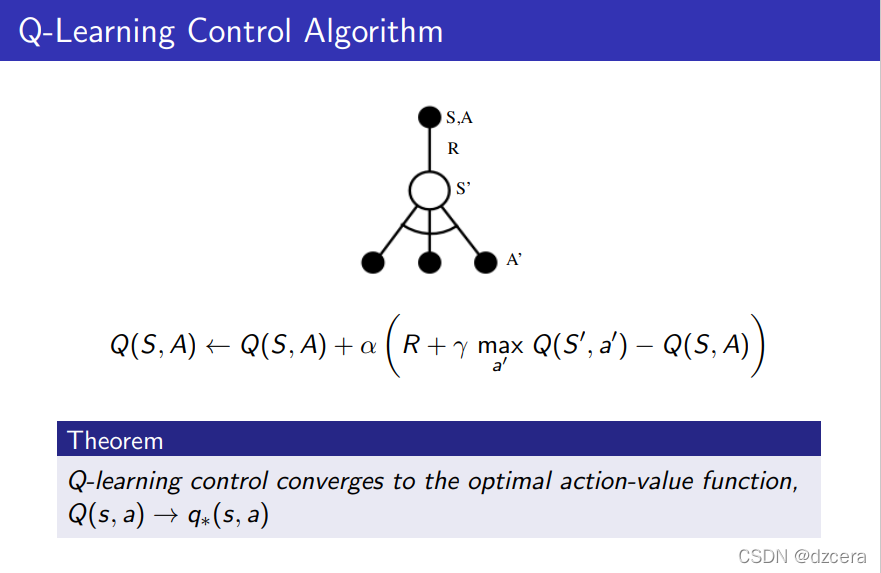
Off-Policy Learning

异策略学习的好处

这里是Q-learning的定义,学了这么多终于将回到q-learning了。具体的解释可以看之前博文的第一篇人工智能学习笔记一之强化学习(Q-learning)
https://blog.csdn.net/dzcera/article/details/122634257
其中最显著的好处在于使用一个探索性策略的同时学习了一个确定性策略。

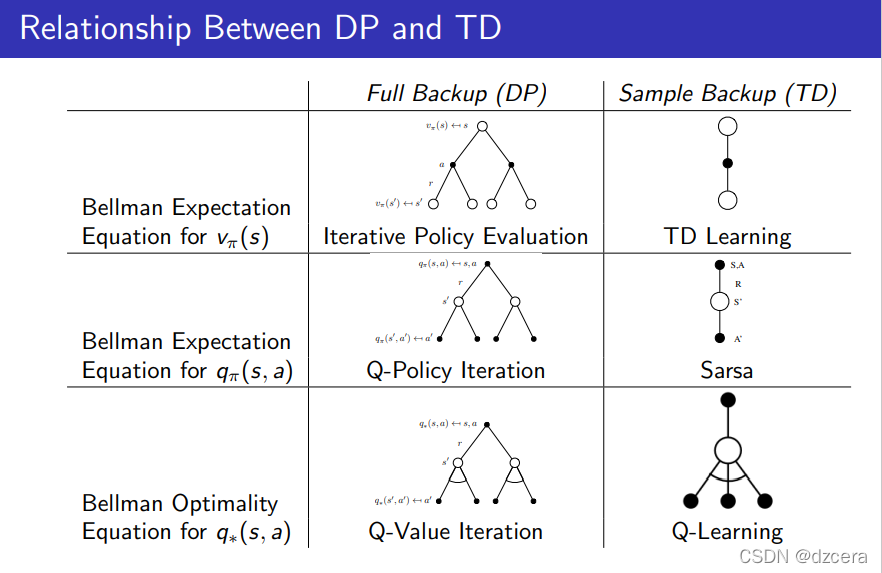
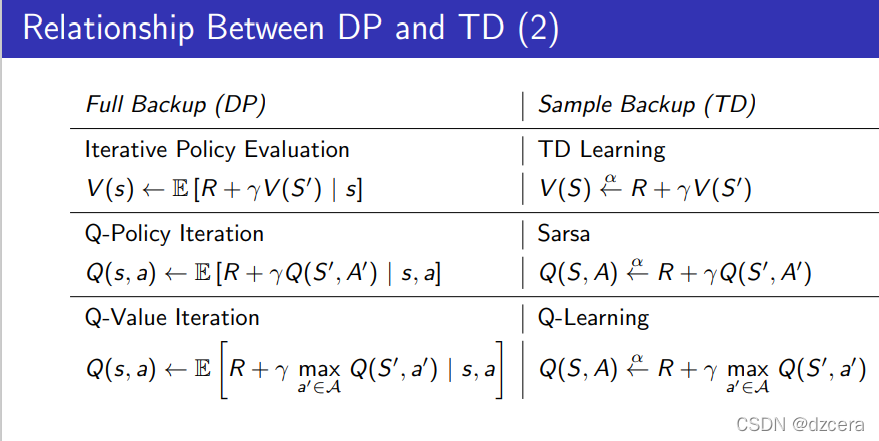
Summary

魔乐社区(Modelers.cn) 是一个中立、公益的人工智能社区,提供人工智能工具、模型、数据的托管、展示与应用协同服务,为人工智能开发及爱好者搭建开放的学习交流平台。社区通过理事会方式运作,由全产业链共同建设、共同运营、共同享有,推动国产AI生态繁荣发展。
更多推荐


 0
0 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)