基于AI实现知识图谱的实战与原理解析
基于AI自动实现知识图谱

文章首发公众号 风间技术私享 。期待您的关注。
一、项目介绍
知识图谱是一种强大的信息表示方式。它们由实体(节点)及其之间的关系(边)组成,使得人们更容易看出事物之间的联系,而不是简单地将其视为非结构化文本。
传统上,从原始文本构建知识图谱并不容易。它需要识别实体及其关系、手动编码的提取规则或专门的机器学习模型。然而,大型语言模型(LLMs)非常灵活,可用于此目的。LLMs 可以读取自由形式的文本并输出结构化信息,我们可以使用它们作为自动化管道的一部分来创建知识图谱。
在本文中介绍的项目,便能将非结构化文本转换为交互式知识图谱网页。此项目的所有代码都位于 AI-Knowledge-Graph 项目存储库中。
二、部署使用
2.1 本地部署
git clone https://github.com/robert-mcdermott/ai-knowledge-graph.git
# 如果是windows版本 建议使用win-encoding-bug分支
git clone -b win-encoding-bug https://github.com/robert-mcdermott/ai-knowledge-graph.git
# 进入目录
cd ai-knowledge-graph
使用 uv 安装依赖项:
uv sync
2.2 项目配置
编辑 config.toml 文件填写模型的链接信息,如下。只要修改llm的部分,其他部分保持默认。
[llm]
model = "Qwen/Qwen3-32B"
api_key = "sk-xxx"
base_url = "https://xxx"
max_tokens = 8192
temperature = 0.8
2.3 创建知识图谱
现在你已经安装并配置了 ai-knowledge-graph ,就可以创建你的第一个知识图谱了。获取一个纯文本文档(目前只支持文本文档),你想要为其创建知识图谱。
需要运行 generate-graph.py 脚本。以下是该脚本的帮助信息:
generate-graph.py [-h] [--test] [--config CONFIG] [--output OUTPUT] [--input INPUT] [--debug] [--no-standardize] [--no-inference]
在执行脚本之前,记得激活uv创建的虚拟环境
# windows执行下面的命令
.venv\Scripts\activate
我从百科找了关于周杰伦的文档,保存为jaychou.txt。
周杰伦(JayChou),1979年1月18日出生于台湾省新北市,祖籍福建省永春县,华语流行乐男歌手、音乐人、演员、导演、编剧,毕业于淡江中学。2000年,发行个人首张音乐专辑《Jay》。2001年,凭借专辑《范特西》奠定其融合中西方音乐的风格。2002年,举行“The One”世界巡回演唱会。2003年,成为美国《时代》杂志的封面人物;同年,全亚洲发行音乐专辑《叶惠美》,该专辑获得第15届台湾金曲奖最佳流行音乐演唱专辑奖。2004年,发行音乐专辑《七里香》,该专辑在全亚洲的首月销量达到300万张;同年,获得世界音乐大奖中国区最畅销艺人奖。2005年,主演个人首部电影《头文字D》,凭借该片获得第25届香港电影金像奖和第42届台湾电影金马奖的最佳新演员奖。2006年起,连续三年获得世界音乐大奖中国区最畅销艺人奖 。2007年,自编自导爱情片《不能说的秘密》,同年,成立杰威尔音乐有限公司。2008年,凭借歌曲《青花瓷》获得第19届台湾金曲奖最佳作曲人奖。2009年,被美国CNN评为“25位亚洲最具影响力人物”;同年,凭借专辑《魔杰座》获得第20届台湾金曲奖最佳国语男歌手奖 。2010年,入选美国《Fast Company》杂志评出的“全球百大创意人物”。2011年,凭借专辑《跨时代》获得第22届台湾金曲奖最佳国语男歌手奖。2012年,登上福布斯中国名人榜榜首。2023年,凭借专辑《最伟大的作品》成为首位获得国际唱片业协会“全球畅销专辑榜”冠军的华语歌手。2024年,成为首位在台北大巨蛋举办演唱会的歌手。
简单案例如下:
python generate-graph.py --input jaychou.txt --output jaychou.html
程序正在对文本进行处理,如下图:

经过一段时间的等待,获取下面的运行结果:
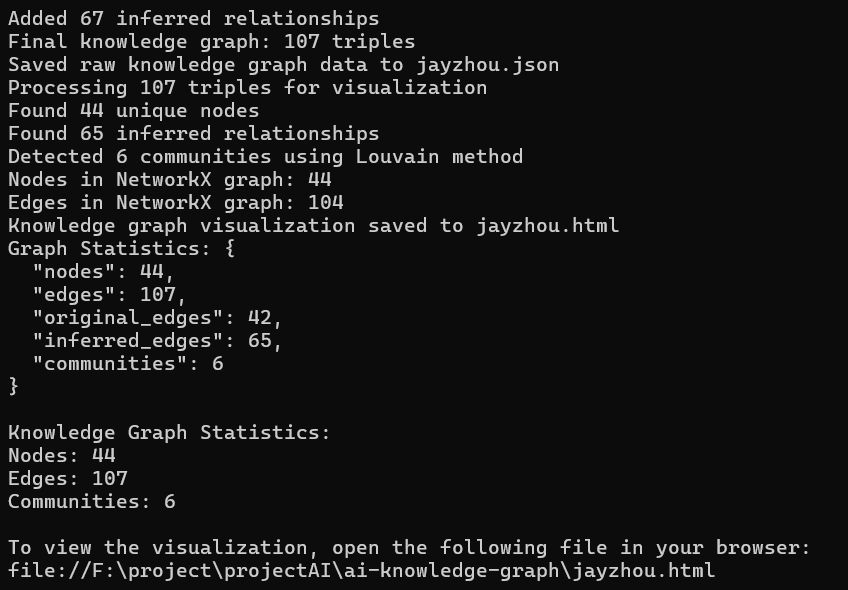
三、结果呈现
当程序执行完成之后,会获得html与json两个文件。
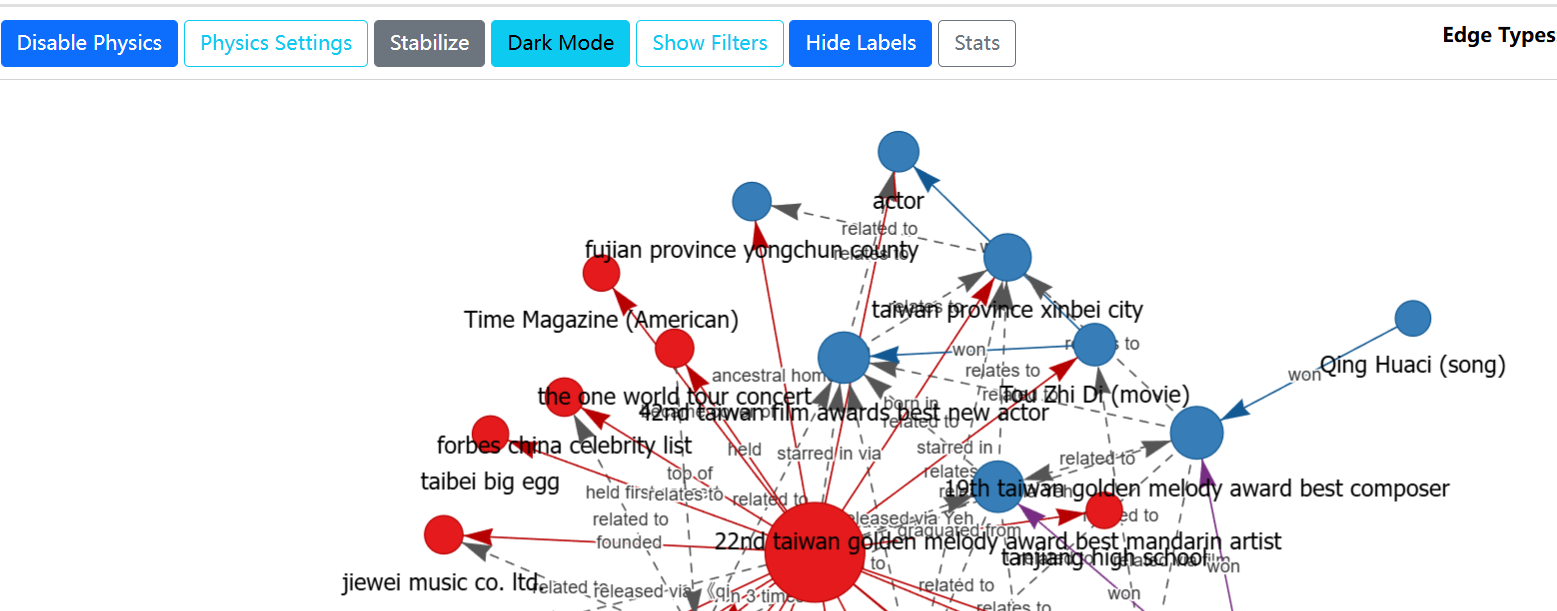
其中html文件,就是上文命令的输出文件,是已经生成的知识图谱。样式如下图,不但有图片的拖拉拽,还能按条件进行筛选。
另外一个是json文件,如下图,就是平时做图谱项目时必不可少的json。
[
{
"subject": "Jay Chou",
"predicate": "born in",
"object": "taiwan province xinbei city",
"chunk": 1
},
{
"subject": "Jay Chou",
"predicate": "ancestral home is",
"object": "fujian province yongchun county",
"chunk": 1
},
...
]
四、原理解释
整体工作大致分为以下流程:
- 文本分块:自动将大型文档分割成可管理的块以进行处理
- 知识提取:然后由 LLM 识别并从每个块中提取主语–谓词–宾语三元组(事实)。
- 实体标准化:相同实体(例如,“AI”和“人工智能”)的提及被统一为一个名称。
- 关系推断:通过简单的逻辑规则(例如,传递性)和 LLM 推理推断出额外的关系,以连接断开的子图。
- 交互式可视化:生成的图在您的浏览器中显示为交互式网络。
4.1 文本分块
LLMs 有一个上下文窗口限制(本地系统也有内存限制)。为了处理大型文档,该工具会自动将文本分割成多个片段(例如,每个片段 500 个单词,并有一定重叠)。重叠有助于在边界句子中保持上下文。然后,每个片段都会被发送给 LLM,并附带一个提示,指示它提取 SPO 三元组。
4.2 LLM 驱动的提取
对于每个片段,该工具会要求 LLM 输出一个包含三元组的 JSON 数组,并说明信息是从哪个片段提取的。示例如下:
[
{
"subject": "Jay Chou",
"predicate": "is a",
"object": "mandarin pop male singer",
"chunk": 1
},
{
"subject": "Jay Chou",
"predicate": "is a",
"object": "musician",
"chunk": 1
}
]
提示鼓励使用一致的实体命名、简短的关系短语(1-3 个单词),并且不使用代词引用。从所有片段中提取的三元组随后会被合并成一个初始的原始知识图谱。
4.3 跨片段标准化实体
提取后,你经常会发现许多相同的实体的变体(例如,“AI”、“A.I.”、“人工智能”)。为了避免碎片化或重复的节点,该工具提供了一个实体标准化步骤。
- 基本规范化:小写转换、去除空白等操作会合并明显的重复项。
- 标准化(可选):当启用时,LLM 会将可能指向同一实体的不同提及进行聚类。例如,“New York”、“NYC”和“New York City”会合并为一个规范节点,而“United States”、“U.S.”和“USA”会合并为另一个。
这可以提高图谱的连贯性,通常建议启用。如果你需要严格原始的提取结果,可以在配置文件中禁用它。
4.4 推断隐藏连接以丰富图谱
即使仔细阅读文本也可能无法捕捉到隐含的关系。该工具通过两种方式解决这个问题:
基于规则的推理:
- 传递关系:如果 A 使 B 成为可能,并且 B 驱动 C,系统可以推断 A 影响 C。
- 词汇相似性:名称相似的实体可能通过一个通用的“相关”关系连接。
LLM 辅助推理:
- 该工具可以提示 LLM 在原本不相连的子图中提出连接。例如,如果一个集群关于工业革命,另一个关于人工智能,LLM 可能会推断出历史或概念上的联系(“人工智能是工业革命开始的技术创新的结果”)。
- 这些边会用不同的方式标记(例如,虚线),以区别于明确陈述的事实。
这一推断步骤通常会添加大量新的关系,大大减少了孤立的子网络。如果你想要一个纯粹由文本推导出的图,可以在配置文件中禁用它。推断出的关系会包含一个属性,表明该关系是推断出来的。这个属性很重要,因为它将在可视化过程中用于用虚线边表示推断出的关系。
4.5 LLM 提示
如果所有选项都启用,会向 LLM 发送四个提示。初始的主谓宾(SPO)知识提取。
4.5.1 提取系统提示
本项目使用下面的系统提示词,为了方便阅读,也提供了中文版本。
原文:
You are an advanced AI system specialized in knowledge extraction and knowledge graph generation.
Your expertise includes identifying consistent entity references and meaningful relationships in text.
CRITICAL INSTRUCTION: All relationships (predicates) MUST be no more than 3 words maximum. Ideally 1-2 words. This is a hard limit.
译文:
你是一个高级人工智能系统,专注于知识提取和知识图谱生成。
你的专长包括识别文本中一致的实体引用和有意义的关系。
重要说明:所有关系(谓词)的长度不得超过 3 个词。理想情况下,1-2 个词。这是一个硬性限制。
4.5.2 提取用户提示
下面是项目使用的用户提示词,同样提供了原文与中文版本。
原文:
Your task: Read the text below (delimited by triple backticks) and identify all Subject-Predicate-Object (S-P-O) relationships in each sentence. Then produce a single JSON array of objects, each representing one triple.
译文:
你的任务:阅读下面的文本(以三个反引号分隔),并识别每个句子中所有主语-谓语-宾语 (S-P-O) 关系。然后生成一个 JSON 对象数组,每个对象代表一个三元组。
这里还有三个未列出的提示,用于指导 LLM 进行标准化和关系推理。你可以在 src/knowledge_graph/prompts.py 源文件中检查(并调整)所有提示。
4.6 交互式图可视化
有了完整的 SPO 三元组列表(原始的加上推断的),该工具使用 PyVis(一个用于 Vis.js 的 Python 接口)生成交互式 HTML 可视化。在浏览器中打开生成的文件,你会看到:
- 彩色社区:同一集群中的节点共享相同颜色。集群通常映射到文本中的子主题或主题。
- 按重要性调整节点大小:连接数较多(或中心性较高)的节点显示得更大。
- 边样式:实线表示文本衍生关系,虚线表示推断关系。
- 交互控制:平移、缩放、拖动节点、切换物理效果、切换明暗模式以及过滤视图。
这使得探索关系变得容易,并以视觉上吸引人的格式呈现。
4.7 程序流程
以下是程序的基本流程
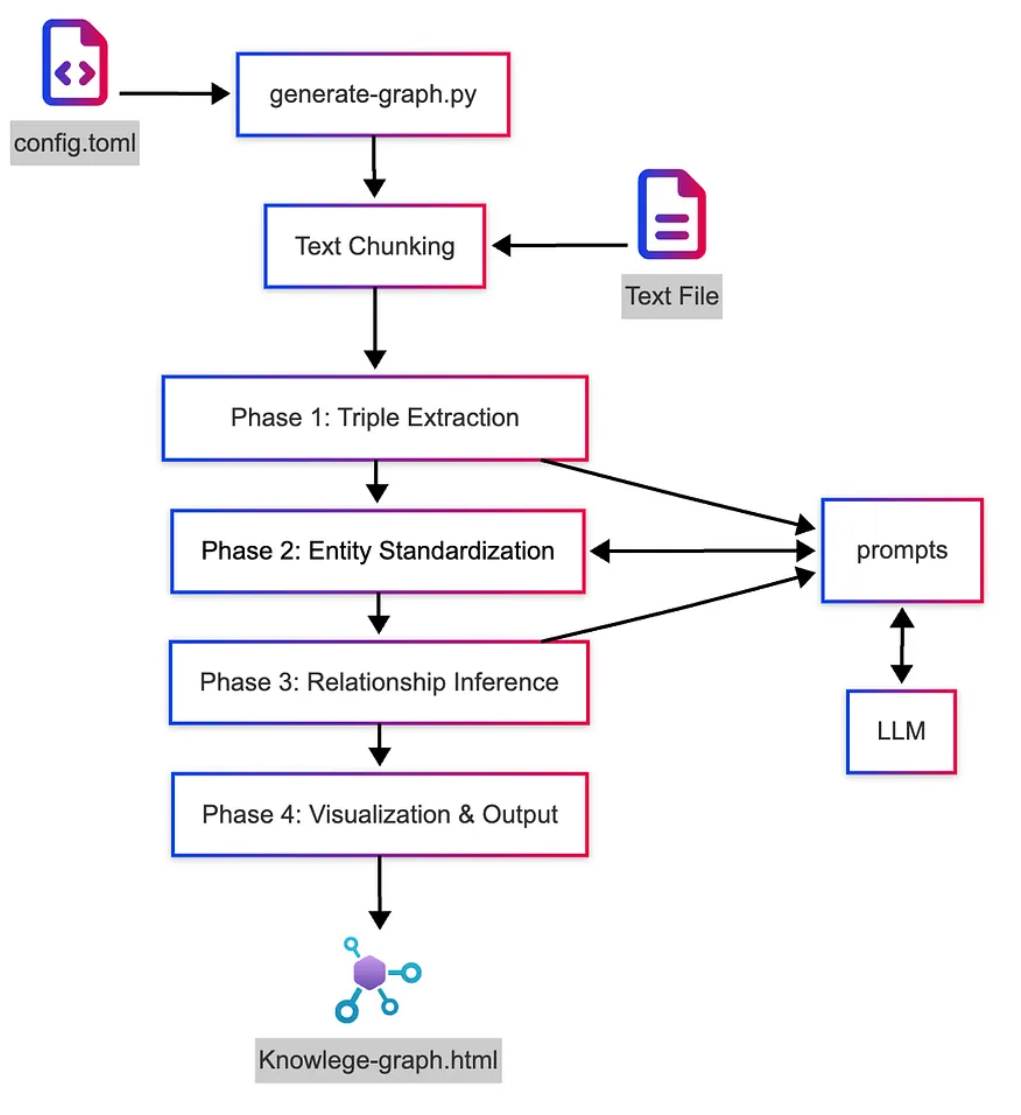
五、调优
5.1 参数调优
项目的config.toml文档,有关于块大小/重叠大小的参数,在使用中可以做不同的尝试,根据模型和文本的不同,效果也不尽相同。通常将重叠设置为块大小的 10%。较小的文档块大小(100-200)似乎能提取更多关系,但这可能会导致其他事物和跨越小块的碎片概念/社区之间的关系减少。
5.2 语言修改
如果在使用中,觉得英文结果很不方便,也可以修改项目中用到的提示词,在 src/knowledge_graph/prompts.py 源文件中可以找到所有提示词,在每个提示词后面增加下面一段话:
Please note that the answer should be in Chinese.
通过修改提示词,可以快速获得中文版的知识图谱,效果如下:
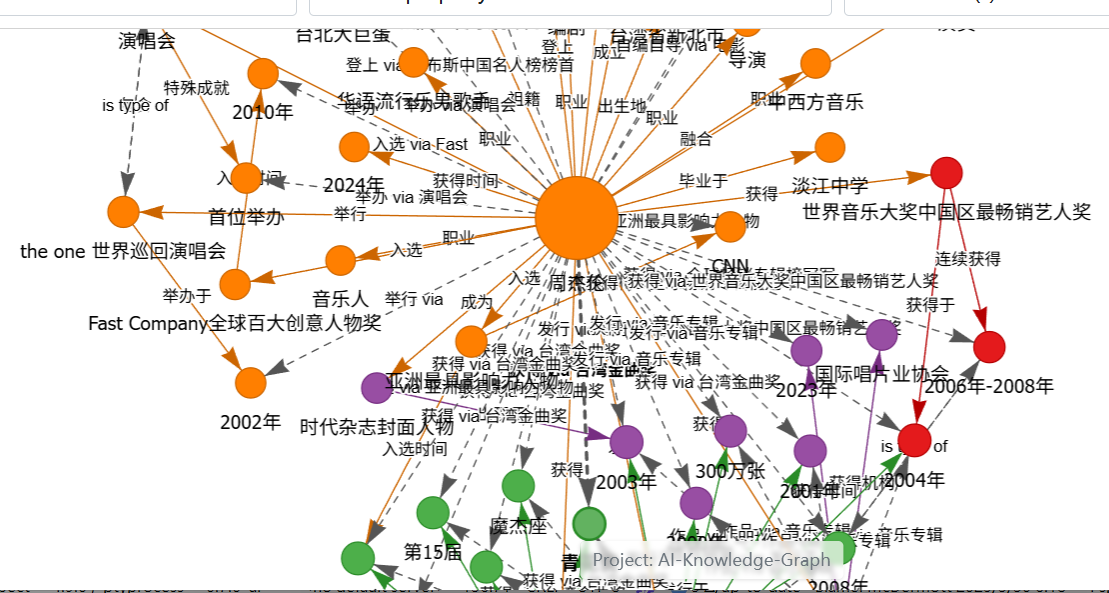

魔乐社区(Modelers.cn) 是一个中立、公益的人工智能社区,提供人工智能工具、模型、数据的托管、展示与应用协同服务,为人工智能开发及爱好者搭建开放的学习交流平台。社区通过理事会方式运作,由全产业链共同建设、共同运营、共同享有,推动国产AI生态繁荣发展。
更多推荐


 34
34 0
0- 0



 已为社区贡献6条内容
已为社区贡献6条内容

所有评论(0)