在python中读取matlab文件 — h5py读取.mat文件学习笔记
·
纯属个人学习python处理matlab笔记,欢迎指正交流!
matlab中读取的数据文件结构如下图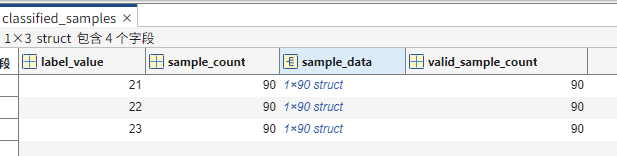
h5py读取.mat 文件关键字结构:
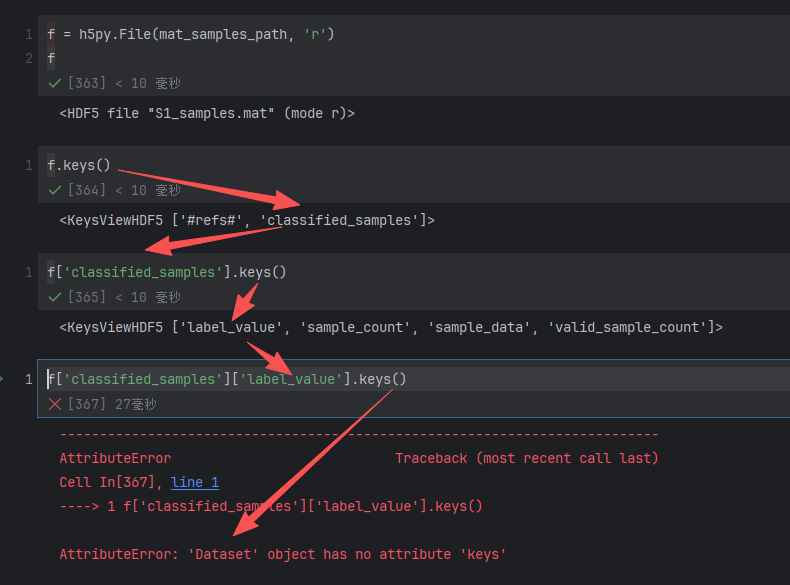
一路keys方法看下来,终于看到了h5py 数据集(Dataset)
看看这个结构下面放的啥?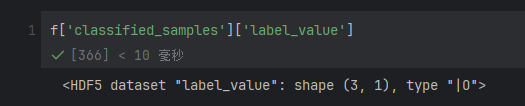
HDF5 dataset “label_value”:表示这是一个 h5py 数据集(Dataset),存储了名为 label_value 的数据,对应 MATLAB 中表格的某一列或变量名;
shape (3, 1):数据是 3 行 1 列的二维数组;
type “|O”:数据类型是 NumPy 的 object 类型(|O 是 NumPy 中 object 类型的简写)。
在 MATLAB 数据的语境下,object 类型通常对应引用(reference)—— 即该数据集存储的不是直接数据,而是指向实际数据的内部指针,因此要读取对应数据,则需要通过索引读取
读取数据集中的数据
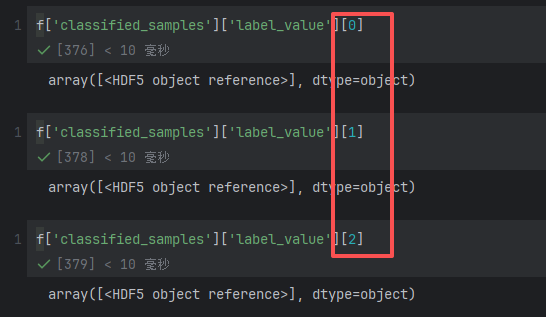
放的是reference,依然是object类型
取第一个元素的referenc出来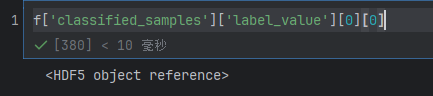 在f中读取引用内容
在f中读取引用内容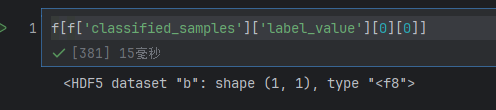
引用最终指向名称为b的数据集,是 1 行 1 列的二维数组,MATLAB 中常以二维矩阵形式存储单个数值,“<f8” 是 NumPy 对数据类型的简写,对应 64 位浮点数(float64)
取出数据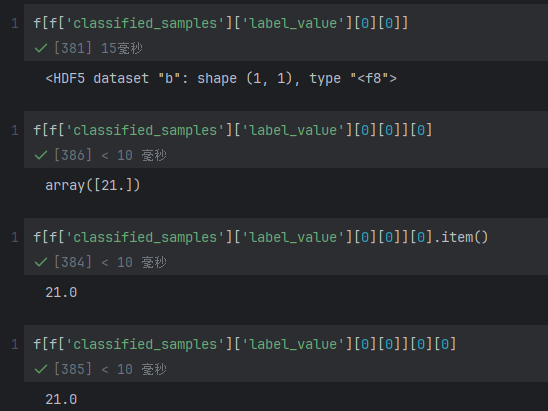
批量读取数据集的引用
import h5py
import numpy as np
def traverse_hdf5(obj, parent_key=""):
"""递归遍历 HDF5 对象,对数据集读取前5行值"""
if isinstance(obj, h5py.Group):
# 处理群组:遍历子键(跳过 '#refs#')
for key in obj.keys():
if key not in ['#refs#']: # 跳过内部引用表
current_key = f"{parent_key}/{key}" if parent_key else key
print(f"\n【群组】{current_key}")
traverse_hdf5(obj[key], current_key)
elif isinstance(obj, h5py.Dataset):
# 处理数据集:打印信息 + 读取前5行
print(f"\n【数据集】{parent_key}")
print(f" 形状:{obj.shape},数据类型:{obj.dtype}")
try:
# 判断数据集维度,确定如何取前5行
if len(obj.shape) == 0: # 数据集是标量 (无维度,len(obj.shape) == 0)
# 标量数据(无行维度)
data = obj[()]
print(f" 数据:{data}")
else:
# 数组数据:取第一维度的前5个元素(即前5行)
# 切片格式:前5行,其余维度全取
# top5 = obj[:5, ...] # ... 表示其余维度全部保留
all = obj[...] # ... 表示全部保留
# 打印前5行(简化显示,避免过长)
print(" 前5行数据:")
print(np.array2string(all, threshold=100, edgeitems=3)) # 控制显示长度
except Exception as e:
# 尝试解析引用类型数据集的前5行
try:
# 读取前5个引用(假设数据集形状为 (N, 1))
refs = obj[:5].flatten() # 取前5行并展平为一维
top5_data = [f[ref][()] for ref in refs] # 解析每个引用
print(" 前5行引用解析后的数据:")
print(np.array2string(np.array(top5_data), threshold=100, edgeitems=3))
except:
print(f" 无法读取数据(错误:{str(e)})")
# 使用示例
with h5py.File(mat_samples_path, 'r') as f:
print("HDF5 文件遍历(含数据集前5行):")
traverse_hdf5(f)
运行结果如下: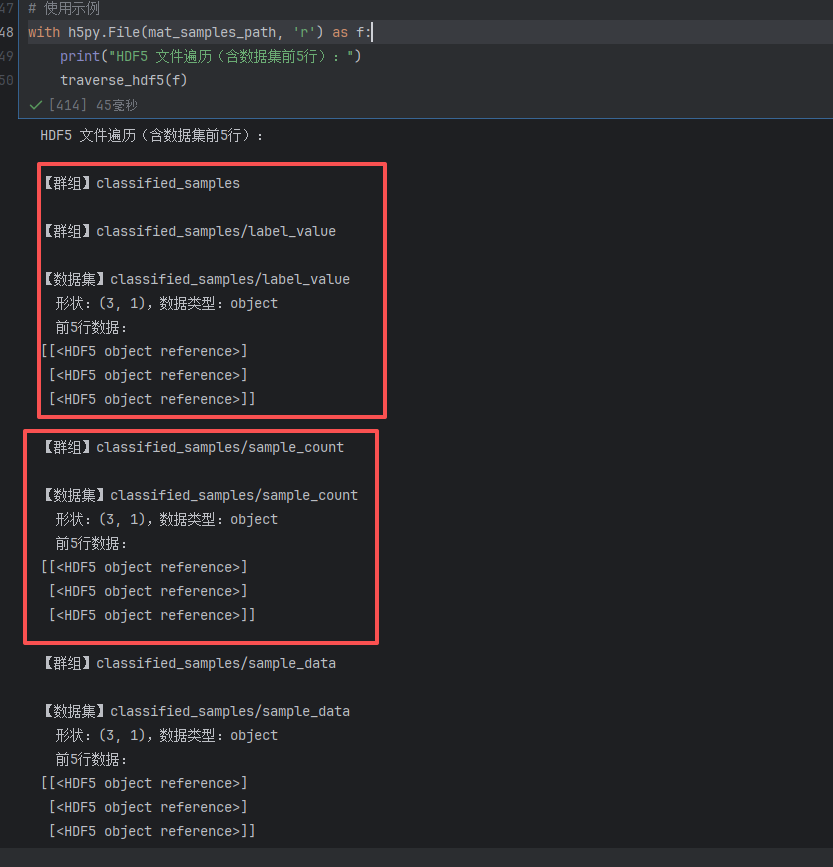
未完待续。。。。

魔乐社区(Modelers.cn) 是一个中立、公益的人工智能社区,提供人工智能工具、模型、数据的托管、展示与应用协同服务,为人工智能开发及爱好者搭建开放的学习交流平台。社区通过理事会方式运作,由全产业链共同建设、共同运营、共同享有,推动国产AI生态繁荣发展。
更多推荐


 5
5 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)