从数据采集到增强
一、数据的获取方法
二、图片清洗
三、数据标签
四、数据增强
五、数据加载
一、数据的获取方法
1.公共数据集,比如ImageNet。
2.外包平台,阿里/百度/京东微工/Amazon等,花钱包人拍摄。
3.自己拍摄
4.去网络上,比如百度等浏览器,专业拍摄网站,视频平台等,但需要爬虫提高效率。
以下是常用的爬虫工具介绍
1.
https://github.com/QianyanTech/Image-Downloader 一分钟1k张图片,可以设置多个关键词,以","分割。还可以把关键词写入.txt文件中,逐一个爬取。
2.
视频爬取工具,使用方式:./lux https://www.bilibili.com/bangumi/play/ep706633?spm_id_from=333.337.0.0,可以爬去b站,爱奇异,腾讯等国内,以youtube等国外视频平台,它也可以一次爬取多个,可以写脚本。它其实还可以爬照片文件等,有点像迅雷。
https://github.com/iawia002/lux
3.
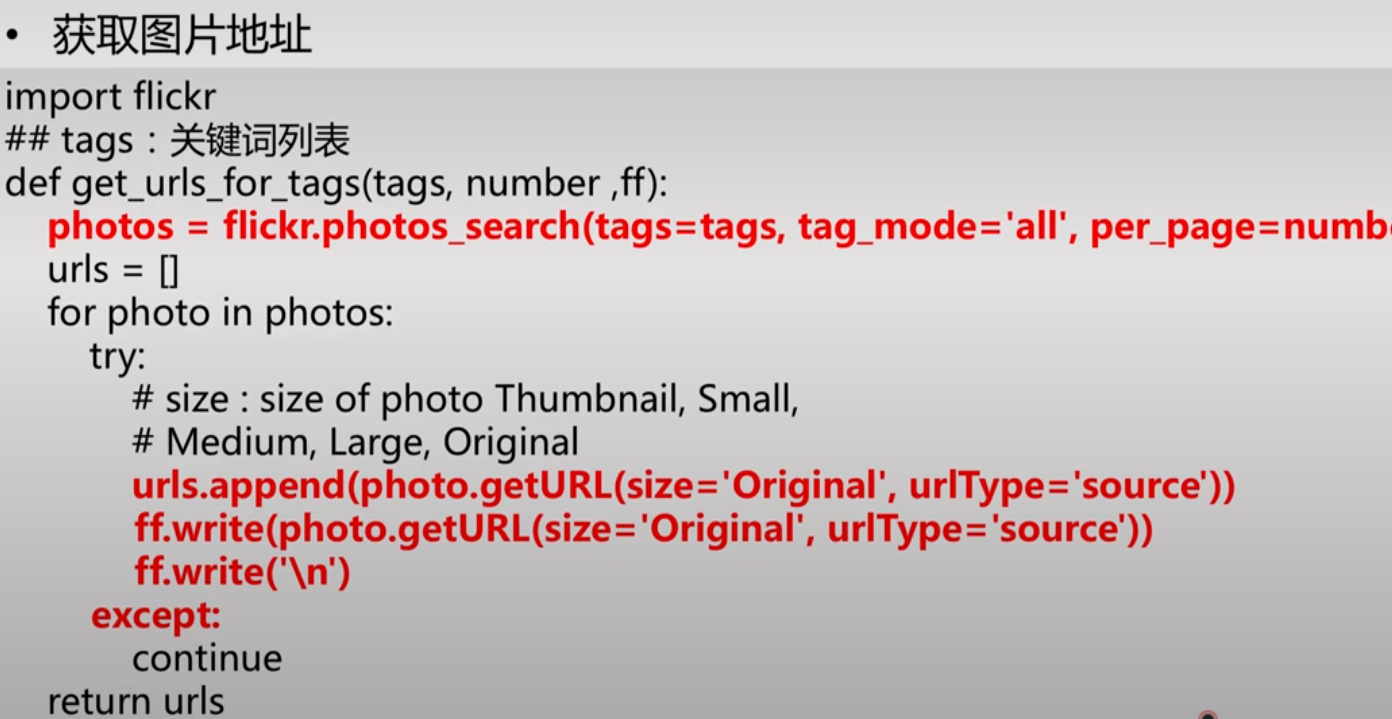
Flickr国外的图片网站,很多数据集都是用这个来组建的,比图ImageNet。
https://www.flickr.com/
网站官网提供了爬虫接口,但需要申请一下,用以下工具爬取,其中接口使用教程:
https://github.com/chenusc11/flickr-crawler
用它爬取需要这几个步骤:

这些国内的摄影网站也有不少高质量图片。

二、图片清洗
//名称递加,格式修改jpg,去除损坏的图片
#coding:utf8
# Copyright 2019 longpeng2008. All Rights Reserved.
# Licensed under the Apache License, Version 2.0 (the "License");
# If you find any problem,please contact us
#
# longpeng2008to2012@gmail.com
#
# or create issues
# =============================================================================
import os
import sys
import cv2
import numpy as np
def listfiles(rootDir,rename=False):
list_dirs = os.walk(rootDir)
num = 0
for root, dirs, files in list_dirs:
for d in dirs:
print os.path.join(root,d)
for f in files:
fileid = f.split('.')[0]
filepath = os.path.join(root,f)
try:
src = cv2.imread(filepath,1)
print "src=",filepath,src.shape
os.remove(filepath) #删除原来图片
if rename:
cv2.imwrite(os.path.join(root,str(num)+".jpg"),src) #写入新的图片,重新命名
num = num + 1
else:
cv2.imwrite(os.path.join(root,fileid+".jpg"),src) #写入新的图片,名字不变
except:
os.remove(filepath) #去除损坏图片
continue
listfiles(sys.argv[1],rename=True)
删除完全相同和相似度高的文件,通过缩放,对比来决定。
待改进的地方
1.相似度计算改进,基于MSE距离,leveshtein距离,DNN特征相似度
2.遍历方式的改进,基于文件物理大小,图像尺寸,文件名字,进行预先排序,搜索一定的深度或最近邻图片。因为视频图片一般排在一起。
#coding:utf8
# Copyright 2019 longpeng2008. All Rights Reserved.
# Licensed under the Apache License, Version 2.0 (the "License");
# If you find any problem,please contact us
#
# longpeng2008to2012@gmail.com
#
# or create issues
# =============================================================================
#coding:utf8
import os
import sys
import hashlib
# 获取文件的md5
def get_md5(file):
file = open(file,'rb')
md5 = hashlib.md5(file.read())
file.close()
md5_values = md5.hexdigest()
return md5_values
from collections import Counter
import numpy as np
import cv2
# 计算图像相似度
def compare_image(image1,image2,mode='same'):
## 比较是否完全相同
if mode == 'same':
assert(image1.shape == image2.shape)
diff = (image1 == image2).astype(np.int)
if cv2.countNonZero(diff) == image1.shape[0]*image1.shape[1]:
return 1.0
## 比较是否基于阈值
elif mode == 'abs':
assert(image1.shape == image2.shape)
diff = np.sum(np.abs((image1.astype(np.float) - image2.astype(np.float))))
return diff / (image1.shape[0]*image1.shape[1])
return 0
# 单文件夹去重
def remove_by_md5_singledir(file_dir):
file_list = os.listdir(file_dir)
md5_list =[]
print("去重前图像数量:"+str(len(file_list)))
for filepath in file_list:
filemd5 = get_md5(os.path.join(file_dir,filepath))
if filemd5 not in md5_list:
md5_list.append(filemd5)
else:
os.remove(os.path.join(file_dir,filepath))
print("去重后图像数量:"+str(len(os.listdir(file_dir))))
# 单文件夹去重
def remove_by_pixel_singledir(file_dir,mode,th=5.0):
file_list = os.listdir(file_dir)
print("去重前图像数量:"+str(len(file_list)))
for i in range(0,len(file_list)):
if i < len(file_list)-1:
imagei = cv2.imread(os.path.join(file_dir,file_list[i]),0)
imagei = cv2.resize(imagei,(128,128),interpolation=cv2.INTER_NEAREST)
print("testing image "+os.path.join(file_dir,file_list[i]))
for j in range(i+1,len(file_list)):
if j < len(file_list):
while j < len(file_list):
imagej = cv2.imread(os.path.join(file_dir,file_list[j]),0)
imagej = cv2.resize(imagej,(128,128),interpolation=cv2.INTER_NEAREST)
similarity = compare_image(imagei,imagej,mode=mode)
print("simi="+str(similarity))
if similarity >= 1.0 and mode == 'same':
os.remove(os.path.join(file_dir,file_list[j]))
print('删除'+os.path.join(file_dir,file_list[j]))
file_list.pop(j)
elif similarity < th and mode == 'abs':
os.remove(os.path.join(file_dir,file_list[j]))
print('删除'+os.path.join(file_dir,file_list[j]))
file_list.pop(j)
else:
break
print("去重后图像数量:"+str(len(os.listdir(file_dir))))
# 多文件夹去重
def remove_by_md5_multidir(file_list):
md5_list =[]
print("去重前图像数量:"+str(len(file_list)))
for filepath in file_list:
filemd5 = get_md5(filepath)
file_id = filepath.split('/')[-1]
file_dir = filepath[0:len(filepath)-len(file_id)]
if filemd5 not in md5_list:
md5_list.append(filemd5)
else:
os.remove(filepath)
print("去重后图像数量:"+str(len(md5_list)))
if __name__ == '__main__':
file_dir = sys.argv[1]
#remove_by_md5_singledir(file_dir)
remove_by_pixel_singledir(file_dir,mode='abs',th=10)
'''
file_dir1 = sys.argv[1]
file_list1 = os.listdir(file_dir1)
file_list1 = [ os.path.join(file_dir1,x) for x in file_list1 ]
file_dir2 = sys.argv[2]
file_list2 = os.listdir(file_dir2)
file_list2 = [ os.path.join(file_dir2,x) for x in file_list2 ]
remove_by_md5_multidir(file_list1+file_list2)
'''
//打乱数据集合
#coding:utf8
# Copyright 2019 longpeng2008. All Rights Reserved.
# Licensed under the Apache License, Version 2.0 (the "License");
# If you find any problem,please contact us
#
# longpeng2008to2012@gmail.com
#
# or create issues
# =============================================================================
import sys
import random
#file_in 输入txt文件
#file_out 输出txt文件
def shuffle(file_in,file_out):
fin = open(file_in,'r')
fout = open(file_out,'w')
lines = fin.readlines()
random.shuffle(lines)
for line in lines:
fout.write(line)
shuffle(sys.argv[1],sys.argv[2])
//分配数据集比例
#coding:utf8
# Copyright 2019 longpeng2008. All Rights Reserved.
# Licensed under the Apache License, Version 2.0 (the "License");
# If you find any problem,please contact us
#
# longpeng2008to2012@gmail.com
#
# or create issues
# =============================================================================
import sys
#valratio:验证集比例
def splittrain_val(fileall,valratio=0.1):
fileids = fileall.split('.')
fileid = fileids[len(fileids)-2]
f=open(fileall);
ftrain=open(fileid+"_train.txt",'w');
fval=open(fileid+"_val.txt",'w');
count = 0
if valratio == 0 or valratio >= 1:
valratio = 0.1
interval = (int)(1.0 / valratio)
while 1:
line = f.readline()
if line:
count = count + 1
if count % interval == 0:
fval.write(line)
else:
ftrain.write(line)
else:
break
splittrain_val(sys.argv[1],0.1)
更多参考:https://github.com/longpeng2008/yousan.ai.git
三、数据标签
笔者另外两个博客整理的在线网页标注工具:
roboflow标注工具使用
https://blog.csdn.net/weixin_43466192/article/details/154242167?spm=1001.2014.3001.5501
label-studio标注工具使用:
https://blog.csdn.net/weixin_43466192/article/details/154153170?spm=1001.2014.3001.5501
labelme的官网,但现在无法注册新账号了,也不能在线标注了,只能下载可执行程序:http://labelme2.csail.mit.edu/Release3.0/
源码:https://github.com/wkentaro/labelme
命令行安装
conda install pyqt
conda install labelme
它生成的是一个json文件,需要用命令把json文件转化成图片:
labelme_json_to_dataset 1.json -o 1
其中第一个连接是对众多标注工具的收集索引:https://awesomeopensource.com/project/jsbroks/awesome-dataset-tools
百度维护的智能标注:
有时需要精细标注,甚至扣图标注,需要智能化工具辅助。
老版维护github,有可执行工具release:https://github.com/PaddleCV-SIG/EISeg
新版本维护github,有编译说明:https://github.com/PaddlePaddle/PaddleSeg/tree/release/2.6/EISeg
它有以下支持:


如果没有工具合适,需要自己开发智能标注工具,用到的算法是Polygon-RNN和Pologon-RNN++,他们是基于RNN的半监督式交互工具。
这个算法的维护地址:https://github.com/fidler-lab/polyrnn-pp-pytorch
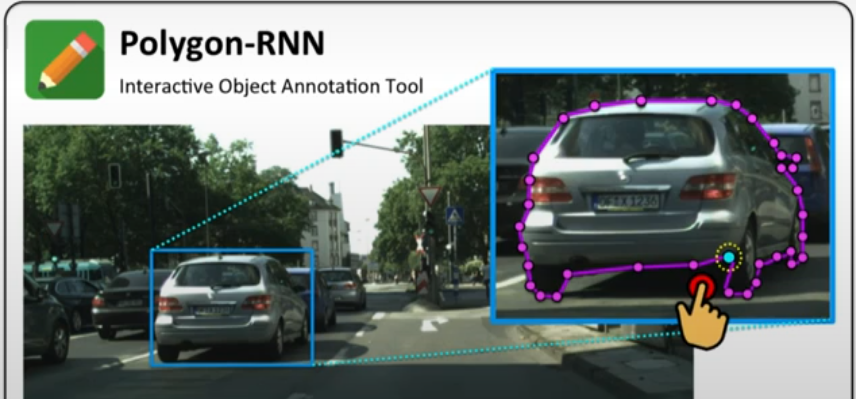
还有基于GCN的标注工具他不像上面RNN只能标注多边形,GCN可以以曲线的方式进行标注:
四、数据增强
不同的模型对不同的增强方法比较敏感。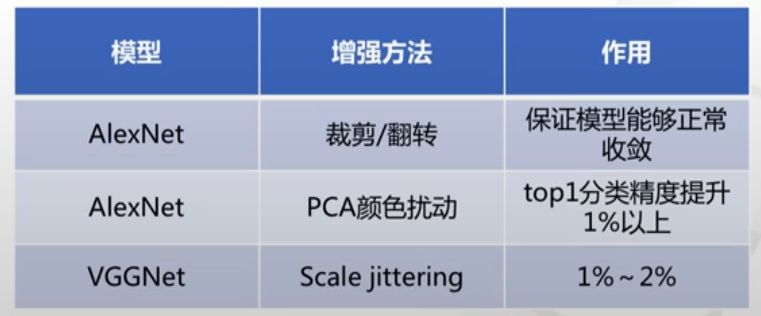
分为两大类:
单样本变换:
1.几何变换:翻转,旋转,裁减,缩放,仿射。其中翻转,旋转方向敏感类不可用。
2.像素变换:噪声,模糊,颜色扰动,对比度扰动,擦除。这几个也可能会起副作用。
多样本变换,SMOT算法:
这个算法用在图片上,有以下两种:
1.SamplePariring,随机抽两张照片,都进行单样本操作,然后两张图片叠加在一起,label用其中一个图片的标签。实验显示,这样对训练有增强帮助。
2.Mixup,Facebook提出,它不仅像SamplePariring对图像插值,对lable也进行插值。实验证明对图像,语言,GAN问题都有效。
图片插值操作如下: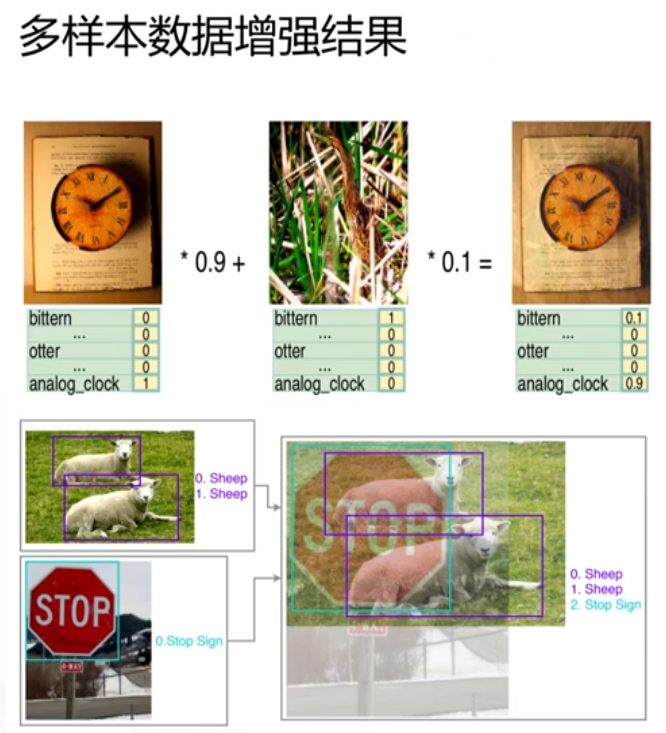
另外,这只有一个网球,可以多放几个:
综合使用几何颜色等变换的工具:
https://github.com/aleju/imgaug
它覆盖了主流的数据增强算法。
pip install imgaug
其中包含数学变换,几何变换,图像融合,模糊操作,颜色与亮度,尺度变换,卷积变换(池化等),艺术增强(卡通化等,用的少),分割增强,天气增强(加上下雨)
基本使用方法,以下代码官网有案例:
它还可以概率控制,对一个Bath中的图像,做不同的操作;对于列表操作中的顺序,是否随机顺序。
import imgaug.augmenters as iaa
seq = iaa.Sequential([
iaa.Crop(px=(1, 16), keep_size=False),
iaa.Fliplr(0.5),
iaa.GaussianBlur(sigma=(0, 3.0))
])
for batch_idx in range(100):
images = load_batch(batch_idx)
images_aug = seq(images=images) # done by the library 输入必须是tensor 格式是[N,H,W,C]
train_on_images(images_aug)
目标检测分为四类:关键点检测 分类 目标检测 分割。
前面的操作都适用于分类,但label中有对目标的矩形框标注的时候,变换目标的位置时,矩形框的位置也应该有变换,它也提供了函数,在变换目标的时候,对lable中的矩形框标签进行转换。
通过draw_on_image画关键点,通过BoundingBoxesOnImage变换矩形框,如下,如果裁减变换后,原来的框超出了边界,还需要超出部分裁掉,对分割也有专门的操作
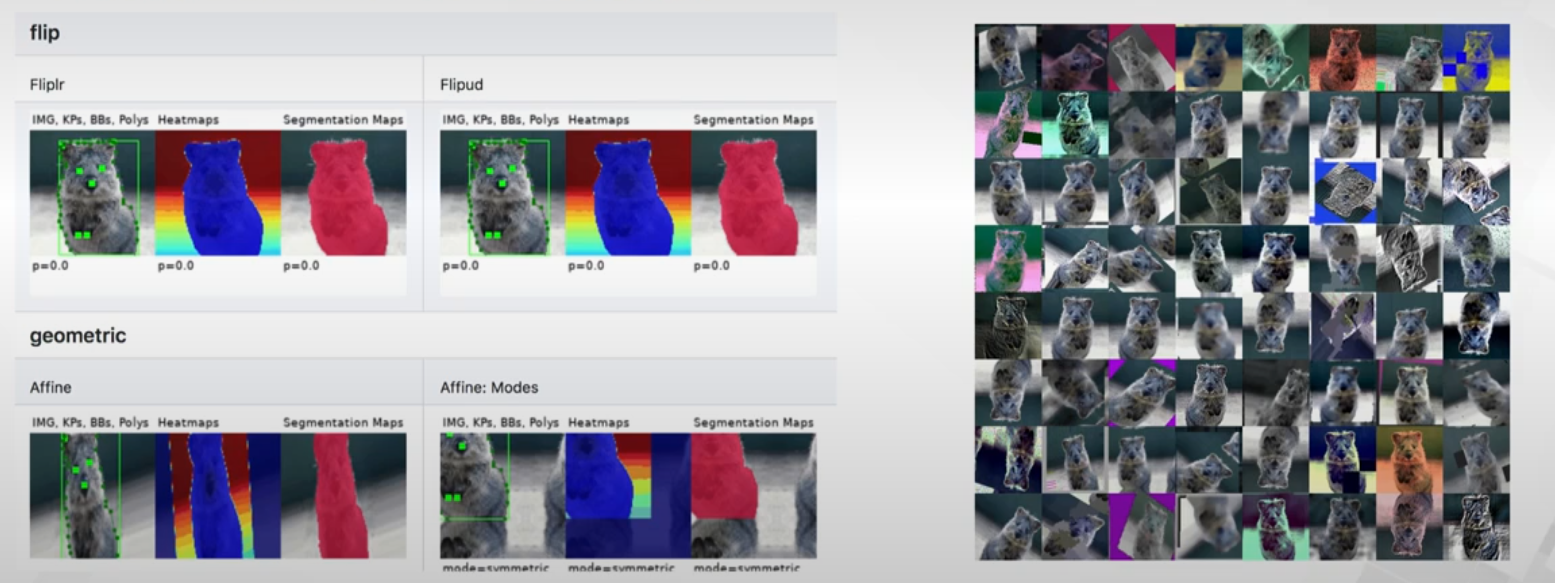
在Pytorch下,数据增强的方法:
data_transforms = {
'train': transforms.Compose([
transforms.RandomSizedCrop(48),
transforms.RandomHorizontalFlip(),
transforms.ToTensor(),
transforms.Normalize([0.5,0.5,0.5], [0.5,0.5,0.5])
]),
'val': transforms.Compose([
transforms.Scale(image_size),
transforms.CenterCrop(crop_size),
transforms.ToTensor(),
transforms.Normalize([0.5,0.5,0.5], [0.5,0.5,0.5]) #一般从0开始构建都是0.5,加载特定数据集需要根据官网标准
]),
}
数据预先处理不会改变原图,只是每次batch都执行预处理操作。这里有个问题,它其实花费时间,会阻塞住后面的流程,因此需要开启多线程,GPU每次来CPU拿数据,CPU都已经处理好了。如下num_workers=4。一般在CPU做预处理,如果是大图可以在GPU。
dataloader = DataLoader(dataset, batch_size=32, shuffle=True, num_workers=4)
#transform_train是一个可调用的对象,调用它就把下面函数依次调用
#Compose()组装流水线
transform_train = transforms.Compose([
transforms.RandomResizedCrop(32, scale=(0.8, 1.0)), # 随机裁剪的图片占原面积的80%~100%,将裁减后的图片缩放回32×32输出
transforms.RandomHorizontalFlip(), # 随机水平翻转
transforms.ToTensor(), # 转为Tensor
transforms.Normalize([0.5, 0.5, 0.5], [0.5, 0.5, 0.5]) # 归一化
])
transform_test = transforms.Compose([
transforms.ToTensor(),
transforms.Normalize([0.5, 0.5, 0.5], [0.5, 0.5, 0.5])
])
在pytorch中,有这些接口
transform = T.RandomOrder([
T.RandomHorizontalFlip(),
T.RandomVerticalFlip(),
T.RandomRotation(30)
])
# 假设你有一个图像 img
transformed_img = transform(img)
当你希望从一组变换中随机选择一个来应用于图像时,可以使用 RandomChoice
transform = T.RandomChoice([
T.RandomHorizontalFlip(),
T.RandomVerticalFlip(),
T.RandomRotation(30)
])
# 假设你有一个图像 img
transformed_img = transform(img)
RandomResizedCrop(32, scale=(0.8, 1.0), ratio=(3/4, 4/3))
其中scale表示裁减的面积在原面积的0.8~1.0之间,宽/高比在3/4到4/3之间。如果出现了内容的拉伸畸变会更加增强泛化能力。
RandomApple表示随机使用这些操作,RandomChoice表示随机使用某些操作。
但这些只能在目标分类中使用,一但label中含有矩形框位置,那么它们没有对label中的矩形框位置做对应的变换,label就失去意义,比如目标检测和目标分割,目标检测有其专门的库,可以对图像转换时,同步对标签转换。
torchvision.transforms 的确主要面向分类,但是目标检测 / 分割的数据增强 PyTorch 生态里有成熟库支持,不需要你自己写
主流有:Albumentations、Detectron2、MMDetection、YOLOv5/8/11,全部支持 bbox + mask + keypoints,如果是目标检测 / 分割任务,首先推荐Albumentations。
import albumentations as A
也可以使用pytorch的自定义目标增强函数,如下:
使用transforms.functional函数。
google的AutoAugment,它有约 16 种操作,例如:
Rotate(旋转)
Translate(平移)
Shear(错切)
Color(颜色变换)
Sharpness(锐化)
Contrast(对比度)
Brightness(亮度)
Solarize(曝光反转)
Invert(反转颜色)
Posterize(减少颜色 bit)
Cutout(遮挡增强)
基本都是对像素的操作,他使用了强化学习,RNN机制,随机选择一些增强组合,然后监看训练结果,来调整选择的策略,达到最佳策略选择。官方实验证明,效果明显:
CIFAR-10 +2.7%
ImageNet +1.5%
transform = transforms.Compose([
transforms.RandomResizedCrop(224),
transforms.RandomHorizontalFlip(),
transforms.AutoAugment(policy=AutoAugmentPolicy.IMAGENET),
transforms.ToTensor(),
transforms.Normalize((0.485, 0.456, 0.406),
(0.229, 0.224, 0.225)),
])
AutoAugment是google论文实现的高级增强技术,它假设你已经做了基本增强了,比如裁减和缩放。
AutoAugmentPolicy.CIFAR10 小图像(32×32)、颜色类别明显,不是只适用于CIFAR10,而是小图
AutoAugmentPolicy.IMAGENET 大图像(≥224×224)
AutoAugmentPolicy.SVHN 数字、街景文字图像
五、数据加载
pytorch支持多种方式,XML JSON XML等,也可以自定义加载类。
ImageFolder格式,他用文件夹名称来作为label,不需要专门的label,是目前最流像的格式之一,也是pytorch的默认标准格式之一,。ImageFolder()会自动给每个图片打上label。一般自建数据集合都用这种方式,但它只有类别,没有具体的标注框,一次不适合目标检测,只适合图片中只含有目标的任务。
目录结构如下:
其中classA会被自动映射为label 0 , classB映射成 1,依次。
dataset_root/
├── train/
│ ├── classA/
│ │ ├── img1.jpg
│ │ ├── img2.jpg
│ ├── classB/
│ ├── img3.jpg
│ ├── img4.jpg
├── val/
│ ├── classA/
│ │ ├── img5.jpg
│ │ ├── img6.jpg
│ ├── classB/
│ ├── img7.jpg
│ ├── img8.jpg
pytorch加载它的方式如下:
# 定义数据增强(或预处理)
data_transforms = {
'train': transforms.Compose([
transforms.RandomResizedCrop(224),
transforms.RandomHorizontalFlip(),
transforms.ToTensor(),
]),
'val': transforms.Compose([
transforms.Resize(256),
transforms.CenterCrop(224),
transforms.ToTensor(),
])
}
# 分别加载 train 和 val 数据
train_dataset = datasets.ImageFolder(
root=os.path.join(data_dir, 'train'),
transform=data_transforms['train']
)
val_dataset = datasets.ImageFolder(
root=os.path.join(data_dir, 'val'),
transform=data_transforms['val']
)
# 分别创建 DataLoader
train_loader = DataLoader(train_dataset, batch_size=batch_size, shuffle=True, num_workers=4)
val_loader = DataLoader(val_dataset, batch_size=batch_size, shuffle=False, num_workers=4)
# 放入字典中(方便统一访问)
image_datasets = {'train': train_dataset, 'val': val_dataset}
dataloaders = {'train': train_loader, 'val': val_loader}
用推导式更简洁:
## 使用torchvision的dataset ImageFolder接口读取数据
image_datasets = {x: datasets.ImageFolder(os.path.join(data_dir, x),
data_transforms[x]) for x in ['train', 'val']}
## 创建数据指针,设置batch大小,shuffle,多进程数量
dataloaders = {x: torch.utils.data.DataLoader(image_datasets[x],
batch_size=64,
shuffle=True,
num_workers=4) for x in ['train', 'val']}
## 获得数据集大小
dataset_sizes = {x: len(image_datasets[x]) for x in ['train', 'val']}
ImageFolder主要用在分类任务,有时用在不在乎标签,只要读到数据的生成式任务如DCGAN。
但它是每个batch都去打开对应的.peg / .png文件,每一张图片:打开文件 → 解码 jpeg/png → 转成 numpy → ToTensor花菲大量时间,IO读取慢,但GPU训练快,就会跟不上。
H5文件结构,它把文件全部打开,以二进制形式存储在一个连续的硬盘内存块中,读取速度更快。它专门为海量数据使用,比如几万~几百万张。
1.顺序 IO(Sequential I/O)远快于文件系统多次随机 IO
2.H5 可以预先存成numpy float32,不需要再解码 JPEG/PNG
将ImageFolder格式转化为H5文件:
import os
import h5py
import torch
from torchvision import datasets, transforms
from torch.utils.data import DataLoader
from tqdm import tqdm
# 输入 ImageFolder 路径
root = "./data"
# 输出 h5 文件路径
h5_path = "./dataset.h5"
# 设置图像尺寸(如果你想保持原图,可删掉 Resize)
transform = transforms.Compose([
transforms.Resize((128, 128)),
transforms.ToTensor()
])
# 用 ImageFolder 加载数据
dataset = datasets.ImageFolder(root=root, transform=transform)
loader = DataLoader(dataset, batch_size=1, shuffle=False)
N = len(dataset)
C, H, W = dataset[0][0].shape
print(f"共 {N} 张图片,尺寸 = {C}×{H}×{W}")
# 创建 H5 文件
with h5py.File(h5_path, "w") as h5f:
img_storage = h5f.create_dataset(
"images",
shape=(N, C, H, W),
dtype="float32"
)
label_storage = h5f.create_dataset(
"labels",
shape=(N,),
dtype="int"
)
idx = 0
for imgs, labels in tqdm(loader):
img_storage[idx] = imgs[0].numpy()
label_storage[idx] = int(labels[0])
idx += 1
print(f"H5 保存完成:{h5_path}")
如何加载H5文件:
class H5Dataset(torch.utils.data.Dataset):
def __init__(self, h5_path):
self.h5 = h5py.File(h5_path, 'r')
self.images = self.h5['images']
self.labels = self.h5['labels']
self.length = len(self.images)
def __len__(self):
return self.length
def __getitem__(self, idx):
img = torch.tensor(self.images[idx])
label = int(self.labels[idx])
return img, label
dataset = H5Dataset("./dataset.h5")
loader = DataLoader(dataset, batch_size=64, shuffle=True)
pickle是python的一种文件形式,也可以把图片保存成这样一种形式,但是当读取时,一次性只能把文件全部读完,因此小的数据集合才使用,如CIFAR10等。
加载.mat格式文件
import scipy.io as sio
class SIDDMatDataset(Dataset):
def __init__(self, mat_file, transform=None):
self.mat = sio.loadmat(mat_file)
self.noisy = self.mat['Noisy']
self.clean = self.mat['Gt']
self.transform = transform
def __len__(self):
return self.noisy.shape[0]
def __getitem__(self, idx):
noisy = self.noisy[idx]
clean = self.clean[idx]
noisy = torch.from_numpy(noisy).permute(2,0,1).float() / 255.
clean = torch.from_numpy(clean).permute(2,0,1).float() / 255.
return noisy, clean

魔乐社区(Modelers.cn) 是一个中立、公益的人工智能社区,提供人工智能工具、模型、数据的托管、展示与应用协同服务,为人工智能开发及爱好者搭建开放的学习交流平台。社区通过理事会方式运作,由全产业链共同建设、共同运营、共同享有,推动国产AI生态繁荣发展。
更多推荐


 11
11 0
0- 0



 已为社区贡献6条内容
已为社区贡献6条内容

所有评论(0)