AI耳机变身翻译官+会议总结大师?涂鸦AI音频开发方案,让耳机升级到下一个level
传统耳机在接入AI能力后,其功能边界得到极大拓展。涂鸦AI音频开发方案,使耳机类设备能够实现:为助力开发者及品牌商快速开发具备上述AI能力的音频设备(包括耳机、录音设备、眼镜、音箱等),涂鸦正式发布AI音频转录与总结解决方案。开发者通过简洁易用的涂鸦API,在面板小程序中进行少量配置,即可在App端实现音频采集,并集成以下核心功能:戳视频,查看涂鸦赋能AI耳机功能演示:【插入视频】兼容AI模型:涂
传统耳机在接入AI能力后,其功能边界得到极大拓展。涂鸦AI音频开发方案,使耳机类设备能够实现:
- 多语言实时互译: 轻松应对全球外语与地方方言,打破语言壁垒。
- 语音高精度转写: 将语音内容实时、准确地转化为文字。
- 智能内容摘要: 自动提炼会议、讲座核心要点,生成结构化会议纪要和思维导图。
该方案适用于办公协作、语言学习、跨语言交流及日常生活记录等多类场景,成为用户强大的智能音频助手。
为助力开发者及品牌商快速开发具备上述AI能力的音频设备(包括耳机、录音设备、眼镜、音箱等),涂鸦正式发布AI音频转录与总结解决方案。开发者通过简洁易用的涂鸦API,在面板小程序中进行少量配置,即可在App端实现音频采集,并集成以下核心功能:
- 语音识别(ASR)
- 多语言翻译
- 内容摘要提取
- 思维导图生成
方案内置强大的AI引擎,开箱即用,显著降低开发门槛。
戳视频,查看涂鸦赋能AI耳机功能演示:
涂鸦AI耳机三大核心功能演示
兼容AI模型:
- 国内: DeepSeek-R1、豆包、通义千问、Kimi、元宝等。
- 海外: ChatGPT、Claude、Gemini等。
一、典型应用场景
1. AI 翻译耳机
涂鸦方案赋能AI耳机,可将设备采集的音频数据传输至App,并利用云端高精度ASR(语音识别)技术进行实时处理。语音被转写为文字后,识别结果即时反馈至App界面。依托先进的大语言模型(LLM)技术,方案可对转写文本进行精准翻译与内容总结,最终通过耳机将翻译结果或摘要信息播报给用户。此方案极大提升了跨语言沟通效率,满足线上及线下面对面交流需求。
2. AI 智能会议记录器
涂鸦赋能AI智能会议记录器,超越传统录音设备。它能实时分析会议音频内容,智能生成精炼的文字摘要和详细的会议纪要。该方案显著简化了会议记录与信息整理流程,提升工作效率,为用户节省大量时间与精力。
戳视频,查看涂鸦AI会议记录器功能演示:
涂鸦AI录音卡片最新版视频
二、App 核心功能演示
连接涂鸦赋能的AI音频设备(如AI耳机)后,App可提供以下核心功能(持续迭代更新中):

1. 音频实时转写
在通话、会议、讲座或收听广播等场景下,AI耳机实时采集语音。App接收音频后,立即进行高精度语音转写(ASR),结果文字同步显示在屏幕上,支持查看、复制与保存。此功能对语言学习者、听障人士及需要文字记录的场景极具价值。
功能动态示意:
2. 面对面实时翻译
在跨语言交流场景中,双方佩戴涂鸦AI耳机(或各佩戴单只),即可启动“你说我译”双向实时翻译模式。一方语音通过耳机传输至App,App完成实时转写、翻译,并通过TTS将翻译结果播报给另一方。该功能大幅降低语言沟通障碍,适用于出境旅行、商务接待、跨境会议等场景。

3. 智能会议记录
在多人会议或访谈中,AI耳机可作为便捷的拾音设备,清晰捕捉多方语音。App端同步进行语音转写,并利用AI能力自动生成结构化会议纪要及思维导图,支持内容检索与存档,显著提升会议效率与信息管理能力。

三、涂鸦 AI 音频方案技术架构
涂鸦AI音频方案由三大核心模块构成:设备端、App端、云端AI能力。
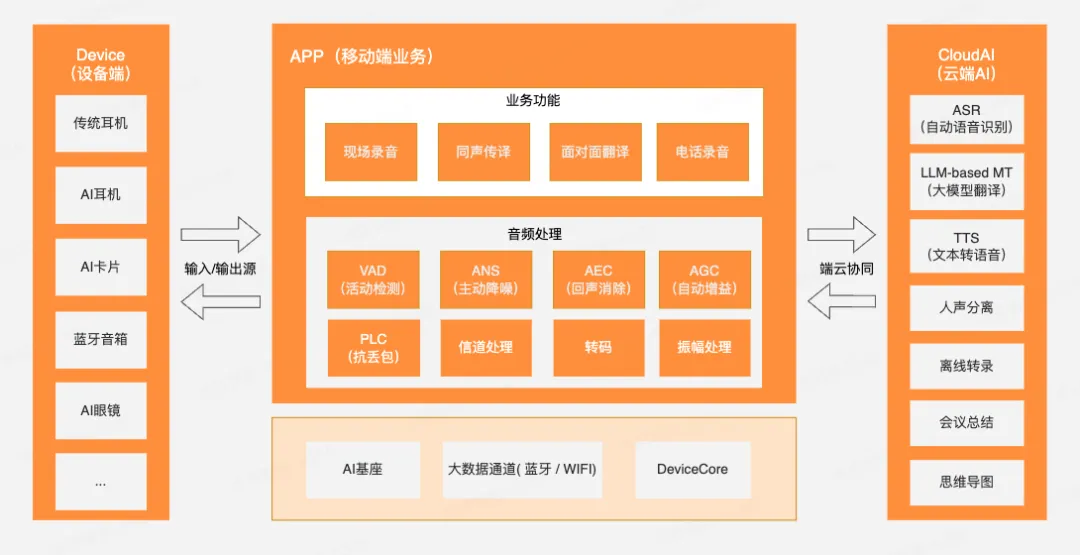
1. 设备端
作为音频输入/输出载体,设备支持通过传统蓝牙(BT)或低功耗蓝牙(BLE)连接App。涂鸦赋能AI Pro耳机通过预设的DP(Data Point) 实现与App的双向指令传输与状态同步,突破传统蓝牙耳机的功能限制,例如:
- 启动/停止录音控制。
- 独立控制单耳麦克风收音与音频播放。
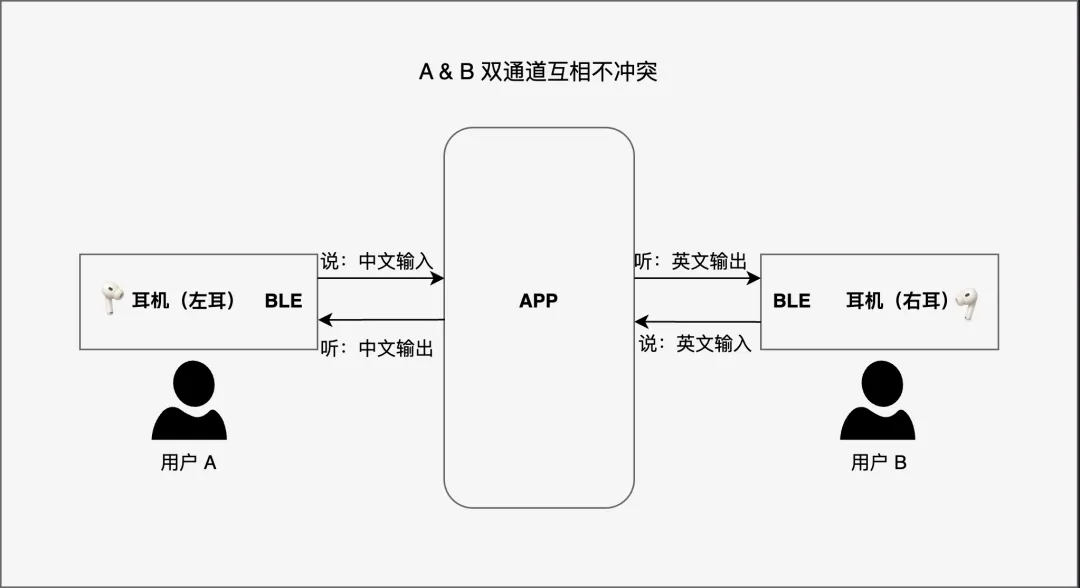
- 支持双声道独立处理,实现同声翻译功能(左右耳可同时播放不同语言,两人各戴一只耳机即可完成实时互译)。
2. App 端
App承担核心数据处理与业务逻辑执行:
- 功能模块: 集成现场录音、同声传译、面对面翻译、电话录音等业务功能。
- 音频处理: 本地执行VAD(语音活动检测)、AEC(回声消除)、ANS(背景噪声抑制)、AGC(自动增益控制)、PLC(丢包补偿)、振幅处理、转码、信道管理等技术,确保输出音质清晰、稳定、连贯。
- 基础能力: 支持设备连接管理(蓝牙/Wi-Fi)、设备通信协议、以及与云端AI服务交互的API/协议。
3. 云端 AI 能力
涂鸦云端集成多项先进AI能力:
- ASR(语音识别): 高精度将语音实时转写为文本。
- LLM-based MT(大模型机器翻译): 利用大语言模型进行上下文感知翻译,支持超过65种语言,持续扩展中。
- TTS(文本转语音): 支持多种音色选择与情绪化播报,使语音输出更自然拟人。
- 扩展功能: 语音分离、内容摘要、会议总结、思维导图生成等。
通过高效的端云协同与统一协议,方案提供低延迟、高效率、高智能的AI语音服务。
四、AI音频处理流程
涂鸦AI音频处理流程分为三个阶段:
- 拾音 + 3A处理 + 转码: 声音采集与预处理。
- VAD + 音频切片: 有效语音检测与切片。
- ASR + 翻译 + TTS: 智能识别、翻译与语音合成。
![[图:涂鸦AI音频数据处理完整流程图]](https://i-blog.csdnimg.cn/direct/7d90d96749a54f6d856b313de83ceff9.png)
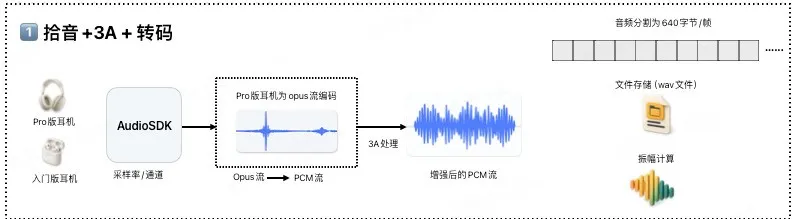
1. 拾音 + 3A处理 + 转码
- 耳机或App采集原始音频。
- 经过降噪、回声消除等3A处理模块预处理。
- 统一转换为PCM音频流。
- 处理后的音频保存为WAV文件(便于计算幅值/电平)。
- 为提升处理效率,音频数据被分割为每帧640字节的数据块。
- 说明(640字节/帧): 基于16KHz采样率(每秒16000样本),16位采样位深,单通道音频。每20ms帧包含样本数:16000样本/秒 * 0.02秒 = 320样本。每样本2字节(16位/8)。因此每帧大小:320样本 * 2字节/样本 = 640字节。
- (注:涂鸦AI Pro耳机采集音频格式为Opus流)
2. VAD + 音频切片
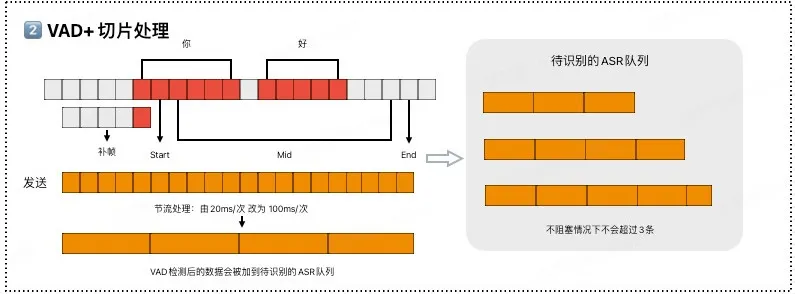
- 对连续的PCM音频流进行精准的VAD检测,识别有效人声片段,区分语音与静音/背景噪声。
- 将有效语音按规则(如每100ms)切片。
- 切片数据缓存并送入待识别的ASR队列。
3. ASR + 翻译 + TTS
- 语音切片发送至云端进行ASR识别。
- 若用户启用翻译功能,ASR转写文本后立即调用大模型进行翻译。
- 翻译后的文本通过TTS引擎合成为目标语言语音,播报给用户。
- 所有识别、翻译结果通过预设接口/协议与App业务逻辑层通信,并回调至面板小程序展示。
五、开发者资源
1. 开发教程
详细了解集成与开发流程:
点击查看详细开发教程
[开发流程示意图1 - 如设备接入流程]
[开发流程示意图2 - 如API调用示例]
2. 技术支持
开发过程中遇到任何技术问题,欢迎访问:
涂鸦开发者技术论坛
我们的技术团队将及时为您提供支持。

魔乐社区(Modelers.cn) 是一个中立、公益的人工智能社区,提供人工智能工具、模型、数据的托管、展示与应用协同服务,为人工智能开发及爱好者搭建开放的学习交流平台。社区通过理事会方式运作,由全产业链共同建设、共同运营、共同享有,推动国产AI生态繁荣发展。
更多推荐



 14
14 0
0- 0



 已为社区贡献5条内容
已为社区贡献5条内容

所有评论(0)