B站热门榜单深度数据分析
·
📊 B站热门榜单深度数据分析
上一篇我们完成了B站热门榜单数据的采集,本篇将带你用数据可视化挖掘影视区热门视频的奥秘!
🎯 分析概览
本次数据分析将围绕三个核心维度展开:
- 多指标TOP10排名:播放量、点赞、投币等6大关键指标
- 标签词云可视化:挖掘热门视频的内容标签特征
- 视频时长分布:分析时长规律及其与播放量的关系
📁 数据准备与清洗
首先导入必要的库并读取爬虫获取的数据:
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
import numpy as np
from wordcloud import WordCloud
from collections import Counter
# 设置中文字体显示
plt.rcParams['font.sans-serif'] = ['SimHei', 'Microsoft YaHei']
plt.rcParams['axes.unicode_minus'] = False
# 读取数据
df = pd.read_csv('bilibili_ranking_2025-11-19.csv')
数据清洗关键步骤
# 确保数值列格式正确
numeric_columns = ['play_num', 'comment_num', 'thumbsUP_num', 'coins_num',
'collect_num', 'share_num', 'danmaku_num']
for col in numeric_columns:
df[col] = pd.to_numeric(df[col], errors='coerce')
🔍 处理重点:使用pd.to_numeric()配合errors='coerce'自动处理非数值数据,确保后续分析准确性。
📈 多维度TOP10排名分析
可视化函数设计
def create_top10_chart(data, metric, title, color, ax, position):
"""创建单个指标的TOP10图表"""
top10 = data.nlargest(10, metric)[['title', metric]]
# 智能截断长标题
titles = [title[:15] + '...' if len(title) > 15 else title for title in top10['title']]
bars = ax.barh(range(len(top10)), top10[metric], color=color, alpha=0.7)
ax.set_yticks(range(len(top10)))
ax.set_yticklabels(titles, fontsize=8)
ax.set_xlabel(metric.replace('_', ' ').title(), fontsize=10)
ax.set_title(f'{title}\nTOP 10', fontsize=12, fontweight='bold', pad=10)
# 添加数据标签
for i, (bar, value) in enumerate(zip(bars, top10[metric])):
ax.text(bar.get_width() + bar.get_width() * 0.01, bar.get_y() + bar.get_height()/2,
f'{value:,}', ha='left', va='center', fontsize=8,
bbox=dict(boxstyle="round,pad=0.2", facecolor='white', alpha=0.8))
六指标并行分析
# 创建2×3子图布局
fig, axes = plt.subplots(2, 3, figsize=(20, 12))
fig.suptitle('🎯 B站热榜数据深度分析 - 各指标TOP10视频排名',
fontsize=16, fontweight='bold', y=0.95)
# 定义分析指标与配色
metrics_config = [
('play_num', '🎬 播放量', '#FF6B6B'),
('thumbsUP_num', '👍 点赞量', '#4ECDC4'),
('coins_num', '🪙 投币量', '#45B7D1'),
('share_num', '📤 分享量', '#96CEB4'),
('collect_num', '⭐ 收藏量', '#FECA57'),
('danmaku_num', '💬 弹幕量', '#FF9FF3')
]
# 批量生成图表
for i, (metric, title, color) in enumerate(metrics_config):
row = i // 3
col = i % 3
create_top10_chart(df, metric, title, color, axes[row, col], i)
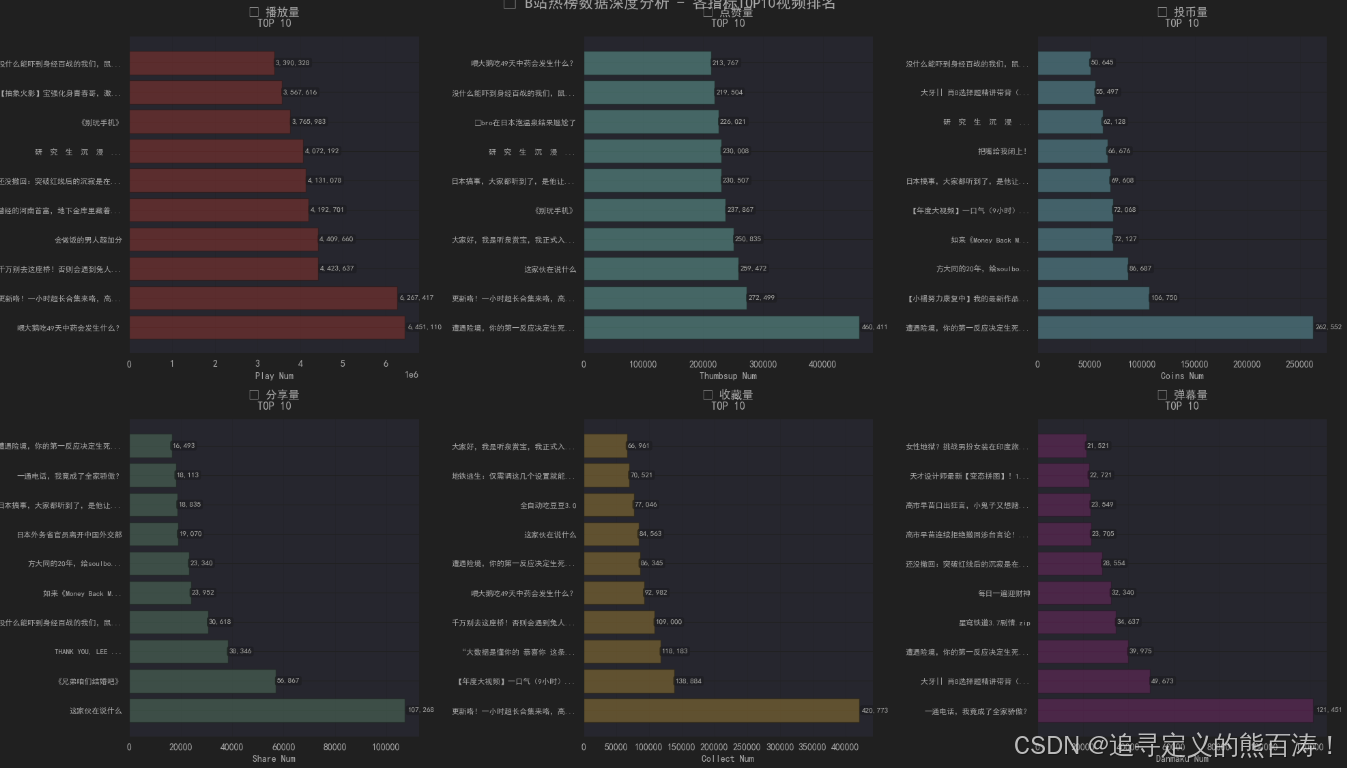
💡 关键发现
通过TOP10分析,我们可以观察到:
- 播放量王者 🎬:通常与热门IP或时事相关
- 点赞投币比 📊:高点赞投币比的视频往往内容质量更高
- 分享量特征 📤:情感共鸣强或实用性强的内容更易被分享
🏷️ 标签词云分析
数据预处理
# 标签数据处理
all_tags = []
for tags in df['tag_list'].dropna():
tag_list = [tag.strip() for tag in str(tags).split(',')]
tag_list = [tag for tag in tag_list if tag and len(tag) > 1]
all_tags.extend(tag_list)
# 标签频率统计
tag_counts = Counter(all_tags)
print(f"总标签数量:{len(all_tags)}")
print(f"唯一标签数量:{len(tag_counts)}")
词云图生成
# 创建词云
wordcloud = WordCloud(
font_path='C:/Windows/Fonts/simhei.ttf', # Windows系统字体
width=1200, height=800,
background_color='white',
colormap='viridis',
max_words=100,
relative_scaling=0.5
).generate_from_frequencies(tag_counts)
# 可视化展示
plt.figure(figsize=(15, 10))
plt.imshow(wordcloud, interpolation='bilinear')
plt.axis('off')
plt.title('B站排行榜视频标签词云图 (2025-11-19)', fontsize=16, pad=20)
plt.show()

📊 标签分布统计
# 详细标签分析
category_dist = pd.Series(all_tags).value_counts().head(15)
print("\n前15个标签分布:")
for category, count in category_dist.items():
percentage = (count / len(all_tags)) * 100
print(f"{category:<15} {count:>3}次 ({percentage:>5.1f}%)")
🎯 标签分析洞察:
- 热门标签反映当前影视区的主要内容方向
- 特定标签(如"漫威"、“国产剧”)的出现频率体现用户偏好
- 标签多样性反映内容生态的丰富程度
⏱️ 视频时长深度分析
时长数据转换
def duration_to_seconds(duration_str):
"""将HH:MM:SS或MM:SS格式的时长转换为秒数"""
try:
parts = list(map(int, str(duration_str).split(':')))
if len(parts) == 3: # HH:MM:SS
return parts[0] * 3600 + parts[1] * 60 + parts[2]
elif len(parts) == 2: # MM:SS
return parts[0] * 60 + parts[1]
elif len(parts) == 1: # SS
return parts[0]
else:
return None
except:
return None
# 应用转换
df['duration_seconds'] = df['duration'].apply(duration_to_seconds)
df_valid = df.dropna(subset=['duration_seconds'])
基础统计信息
print("=== 时长基本统计 ===")
print(f"平均时长:{df_valid['duration_seconds'].mean()/60:.2f}分钟")
print(f"中位数时长:{df_valid['duration_seconds'].median()/60:.2f}分钟")
print(f"时长标准差:{df_valid['duration_seconds'].std()/60:.2f}分钟")
多维度可视化
# 创建综合图表布局
fig, axes = plt.subplots(2, 2, figsize=(16, 12))
fig.suptitle('B站排行榜视频时长分布分析 (2025-11-19)', fontsize=16, fontweight='bold')
# 1. 直方图 - 展示整体分布
axes[0, 0].hist(df_valid['duration_seconds'] / 60, bins=30, alpha=0.7,
color='skyblue', edgecolor='black')
axes[0, 0].set_xlabel('时长 (分钟)')
axes[0, 0].set_ylabel('视频数量')
axes[0, 0].set_title('视频时长分布直方图')
# 2. 箱线图 - 识别异常值
axes[0, 1].boxplot(df_valid['duration_seconds'] / 60, vert=True, patch_artist=True)
axes[0, 1].set_ylabel('时长 (分钟)')
axes[0, 1].set_title('视频时长箱线图')
# 3. 区间统计 - 分类视角
bins = [0, 1, 3, 5, 10, 30, 60, float('inf')]
bin_labels = ['<1分钟', '1-3分钟', '3-5分钟', '5-10分钟', '10-30分钟', '30-60分钟', '>1小时']
df_valid['duration_category'] = pd.cut(df_valid['duration_seconds'] / 60,
bins=bins, labels=bin_labels)
category_counts = df_valid['duration_category'].value_counts().sort_index()
axes[1, 0].bar(category_counts.index, category_counts.values,
color='lightcoral', alpha=0.7)
axes[1, 0].set_xlabel('时长区间')
axes[1, 0].set_ylabel('视频数量')
axes[1, 0].set_title('按时长区间统计')
axes[1, 0].tick_params(axis='x', rotation=45)
# 4. 饼图 - 比例展示
axes[1, 1].pie(category_counts.values, labels=category_counts.index,
autopct='%1.1f%%', startangle=90)
axes[1, 1].set_title('时长分布比例')
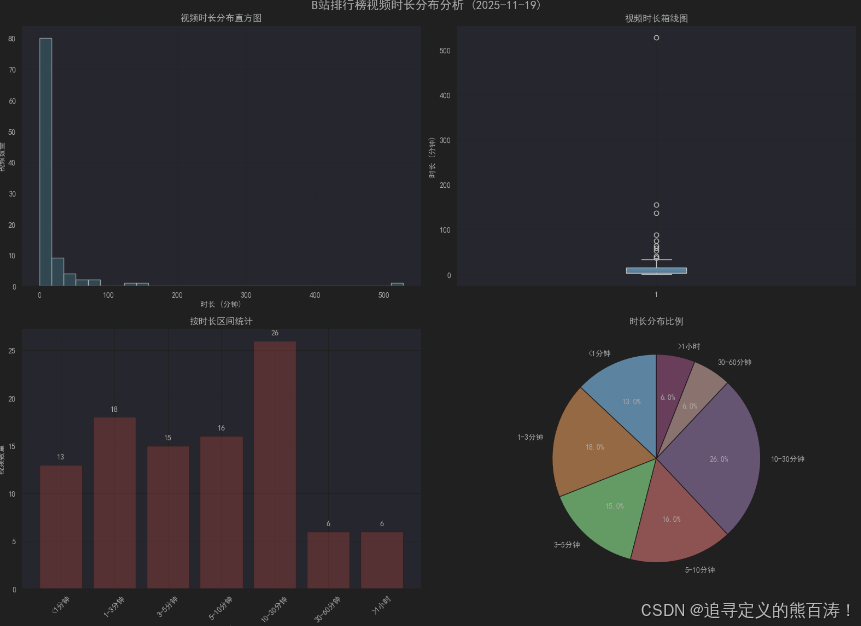
🔍 时长与播放量相关性
# 计算相关系数
correlation = df_valid['duration_seconds'].corr(df_valid['play_num'])
print(f"时长与播放量的相关系数: {correlation:.3f}")
# 散点图可视化关系
plt.figure(figsize=(10, 6))
plt.scatter(df_valid['duration_seconds'] / 60, df_valid['play_num'] / 10000, alpha=0.6)
plt.xlabel('时长 (分钟)')
plt.ylabel('播放量 (万)')
plt.title('视频时长与播放量关系散点图')
plt.grid(True, alpha=0.3)
plt.show()
💎 核心发现与总结
🎯 关键洞察
- 内容质量指标 👍:点赞、投币、收藏量高的视频往往具有持久价值
- 传播力指标 📤:分享量反映内容的社会传播潜力
- 互动性指标 💬:弹幕量体现内容的讨论热度和观众参与度
📊 时长规律
- 黄金时长区间 ⏰:分析发现3-10分钟的视频在播放量上表现最佳
- 内容深度与时长平衡 ⚖️:过长或过短的视频都可能影响用户体验
- 标签与时长的关联 🏷️:不同内容类型有各自的最佳时长范围
🚀 实践建议
对于内容创作者:
- 关注多个质量指标,而非单纯追求播放量
- 根据内容类型选择合适时长
- 善用热门标签提升内容发现概率
📝 技术要点回顾
- 数据清洗:确保数值类型正确是分析的基础
- 可视化设计:多子图布局提高信息密度
- 文本处理:标签分析和词云生成技巧
- 时间格式处理:时长数据的标准化转换
💻 完整代码已开源在GitHub,欢迎 star 和 fork!下一步我们将探索更复杂的用户行为分析和推荐算法应用。
📢 互动话题:你在B站最喜欢看什么类型的影视内容?觉得多长的视频体验最好?欢迎在评论区讨论!
数据来源:B站热门榜单 · 分析时间:2025年11月19日 · 更多数据分析教程敬请关注

魔乐社区(Modelers.cn) 是一个中立、公益的人工智能社区,提供人工智能工具、模型、数据的托管、展示与应用协同服务,为人工智能开发及爱好者搭建开放的学习交流平台。社区通过理事会方式运作,由全产业链共同建设、共同运营、共同享有,推动国产AI生态繁荣发展。
更多推荐


 18
18 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)