中国城市幸福指数数据分析
优化城市环境治理,降低 PM2.5 浓度是提升幸福指数的关键 平衡房价与收入关系,减少通勤时间,缓解生活压力 增加公园绿地等公共空间,提升居民生活品质 完善社会保障体系(如养老保险),增强居民安全感 通过本项目分析可见,幸福指数是一个多维度平衡的结果,需综合考量经济、环境、社会资源等多重因素。通过这种分析和可视化,可以观察到不同行政级别的城市在幸福指数上的差异,例如一线城市的平均幸福指数最高,而五
项目概述 本项目基于中国各城市的多维度指标数据,分析影响城市幸福指数的关键因素,包括行政级别、收入水平、环境质量、生活压力等,并通过数据可视化呈现各因素与幸福指数的关联性。
技术栈 Python 3.8+ pandas (数据处理)
matplotlib & seaborn (数据可视化)
numpy (数值计算)
一、环境准备与数据加载
# 导入必要库
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
import warnings
warnings.filterwarnings('ignore')
# 设置中文显示 plt.rcParams["font.family"] = ["SimHei", "WenQuanYi Micro Hei", "Heiti TC"] sns.set(font='SimHei', font_scale=1.2)
# 数据加载(假设数据已保存为csv文件) df = pd.read_csv(r'D:\黄远园\updated_city_happiness.csv')
# 数据预览
print("数据集基本信息:")
print(df.info())
print("\n前5行数据:")
print(df.head())
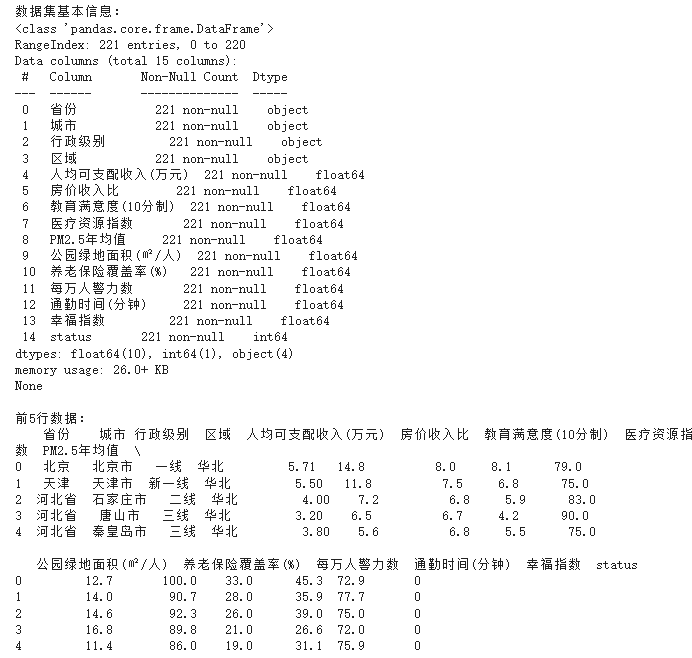
这段代码是一个Python脚本,用于加载和初步分析一个名为`updated_city_happiness.csv`的CSV文件,该文件包含了中国各城市的幸福指数相关数据。下面是对代码的逐行分析:
1. 导入必要库:
- `pandas`:用于数据处理和分析。
- `numpy`:虽然在这段代码中没有直接使用,但通常用于数值计算。
- `matplotlib.pyplot`:用于创建图表。
- `seaborn`:基于matplotlib的高级绘图库,用于创建更美观的统计图表。
- `warnings`:用于控制警告信息的显示。
2. 忽略警告:
- `warnings.filterwarnings('ignore')`:这行代码会忽略所有的警告信息,有时候在数据处理中可能会产生一些警告,但这并不影响程序的运行。
3. 设置中文显示:
- `plt.rcParams["font.family"]`:设置matplotlib的字体,以确保中文可以正确显示。
- `sns.set(font='SimHei', font_scale=1.2)`:设置seaborn的字体为黑体,并调整字体大小。
4. 数据加载:
- `df = pd.read_csv(r'D:\黄远园\updated_city_happiness.csv')`:使用pandas的`read_csv`函数读取CSV文件,并将其存储在DataFrame `df`中。这里的文件路径是绝对路径,并且使用了原始字符串(在字符串前加`r`)来避免转义字符的问题。
5. 数据预览:
- `print("数据集基本信息:")`:打印数据集的基本信息。
- `print(df.info())`:显示DataFrame的基本信息,包括每列的名称、非空值数量、数据类型等。
- `print("\n前5行数据:")`:打印换行符后显示DataFrame的前五行数据。
- `print(df.head())`:显示DataFrame的前五行数据,这是pandas中常用的数据预览方法。
这段代码的目的是为后续的数据分析和可视化做好准备。它首先确保了中文字符可以正确显示,然后加载了数据,并提供了数据集的基本信息和前几行数据的预览,以便用户对数据有一个初步的了解。在实际的数据分析过程中,这些步骤是非常重要的,因为它们可以帮助分析师快速了解数据的结构和内容,为后续的分析工作打下基础。
# 数据预处理
# 检查缺失值
print("\n缺失值统计:")
print(df.isnull().sum())

# 修正数据类型(确保数值型字段正确)
numeric_cols = ['人均可支配收入(万元)', '房价收入比', '教育满意度(10分制)',
'医疗资源指数', 'PM2.5年均值', '公园绿地面积(㎡/人)',
'养老保险覆盖率(%)', '每万人警力数', '通勤时间(分钟)', '幸福指数']
df[numeric_cols] = df[numeric_cols].apply(pd.to_numeric, errors='coerce')
# 去除无效数据(status=2的异常值)
df = df[df['status'] == 0].drop('status', axis=1)
这段代码的目的是清洗和准备数据,确保数据集中的数值型字段是正确的数据类型,并去除数据中的异常值。下面是对代码的逐行分析:
1. 修正数据类型:
- `numeric_cols`:定义了一个列表,包含了数据集中所有预期为数值型(numeric)的列名。
- `df[numeric_cols] = df[numeric_cols].apply(pd.to_numeric, errors='coerce')`:使用`pandas`的`apply`方法和`to_numeric`函数尝试将`numeric_cols`列表中指定的列转换为数值类型。参数`errors='coerce'`的作用是:如果转换过程中遇到无法转换为数值的数据,则将其设置为`NaN`(即“非数字”),而不是抛出错误。
2. 去除无效数据:
- `df = df[df['status'] == 0]`:这行代码筛选出`status`列中值为0的行。这里假设`status`列用于标记数据的有效性,其中0表示有效数据,其他值(如2)表示异常值或无效数据。
- `.drop('status', axis=1)`:从DataFrame中删除`status`列。`axis=1`参数指定了要删除的是列而不是行(`axis=0`表示行,`axis=1`表示列)。
这段代码的目的是确保数据集中的数值型字段都是正确的数值类型,这样可以避免在后续的分析中出现类型不匹配的错误。同时,通过去除标记为异常值的数据,可以提高数据集的质量,确保分析结果的准确性。
在数据分析中,数据清洗是一个非常重要的步骤,它包括处理缺失值、异常值、重复值以及确保数据类型的正确性。这些步骤有助于提高数据的质量和分析的可靠性。
二、探索性数据分析 (EDA)
2.1 城市级别与幸福指数分析
# 按行政级别分组计算幸福指数统计值
level_happiness = df.groupby('行政级别')['幸福指数'].agg(['mean', 'median', 'std', 'count'])
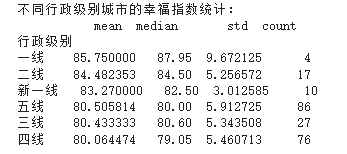
print("\n不同行政级别城市的幸福指数统计:")
print(level_happiness.sort_values('mean', ascending=False))
# 可视化:不同行政级别城市的幸福指数分布
plt.figure(figsize=(12, 6))
sns.boxplot(x='行政级别', y='幸福指数', data=df,
order=['一线', '新一线', '二线', '三线', '四线', '五线'])
plt.title('不同行政级别城市的幸福指数分布')
plt.xlabel('行政级别')
plt.ylabel('幸福指数')
plt.grid(linestyle='--', alpha=0.7)
plt.savefig('city_level_happiness.png', dpi=300, bbox_inches='tight')
plt.show()
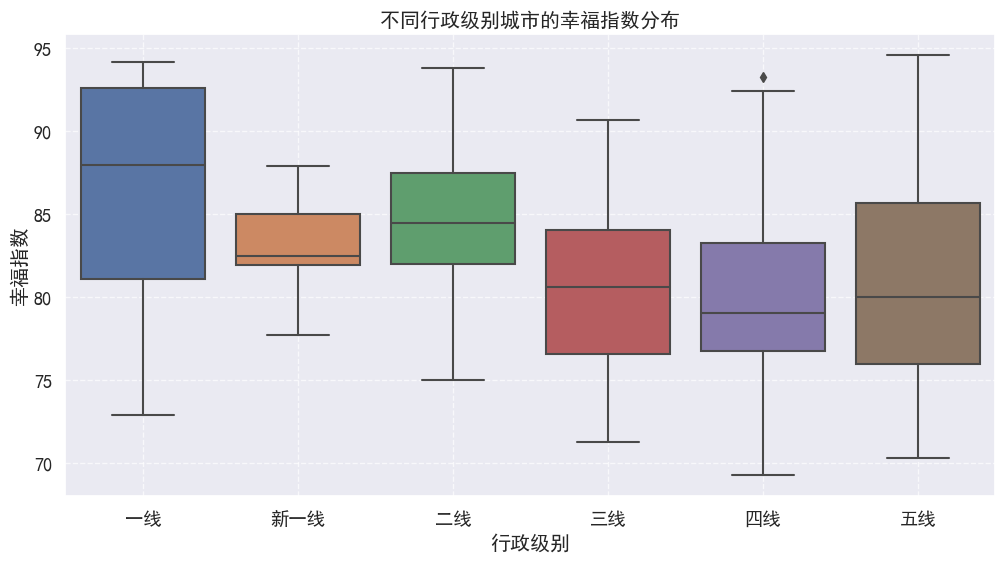
这段代码的目的是对不同行政级别的城市进行分组,并计算每个组的幸福指数统计值,然后可视化这些统计值。下面是对代码的概括和总结:
1. 计算幸福指数统计值:
- 使用`groupby`方法按照`行政级别`对数据进行分组。
- 对每个分组应用`agg`(聚集)函数来计算幸福指数的四个统计值:平均值(`mean`)、中位数(`median`)、标准差(`std`)和计数(`count`)。
- 打印出排序后的结果,其中平均幸福指数从高到低排序。
2. 可视化幸福指数分布:
- 设置图表大小为12x6英寸。
- 使用`seaborn`库的`boxplot`函数创建箱线图,展示不同行政级别城市的幸福指数分布。
- `order`参数指定了箱线图的顺序,确保图表按照行政级别的某种逻辑顺序展示。
- 设置图表的标题、x轴和y轴标签,并添加网格线以提高可读性。
- 使用`savefig`函数保存图表为PNG文件,分辨率为300 DPI,并确保保存时图表内容完整(`bbox_inches='tight'`)。
- 使用`show`函数显示图表。
这段代码的输出包括一个文本表格,展示了不同行政级别城市的幸福指数统计信息,以及一个箱线图,直观地展示了不同行政级别城市幸福指数的分布情况。通过这种分析和可视化,可以观察到不同行政级别的城市在幸福指数上的差异,例如一线城市的平均幸福指数最高,而五线城市的平均幸福指数最低。
这种分析对于理解城市发展水平、居民生活质量以及政策制定等方面都可能非常有用。通过比较不同行政级别的城市,可以识别出哪些因素可能对提高居民幸福感有重要影响,从而为城市规划和发展提供数据支持。
2.2 收入水平与幸福指数相关性分析
# 计算相关系数
income_corr = df['人均可支配收入(万元)'].corr(df['幸福指数'])
print(f"\n人均可支配收入与幸福指数的相关系数:{income_corr:.2f}")
![]()
# 可视化:收入与幸福指数散点图
plt.figure(figsize=(10, 6))
sns.scatterplot(x='人均可支配收入(万元)', y='幸福指数',
hue='行政级别', size='房价收入比',
sizes=(50, 200), alpha=0.7, data=df)
plt.title(f'人均可支配收入与幸福指数的关系(相关系数:{income_corr:.2f})')
plt.xlabel('人均可支配收入(万元)')
plt.ylabel('幸福指数')
plt.legend(bbox_to_anchor=(1.05, 1), loc='upper left')
plt.grid(linestyle='--', alpha=0.7)
plt.savefig('income_happiness_corr.png', dpi=300, bbox_inches='tight')
plt.show()
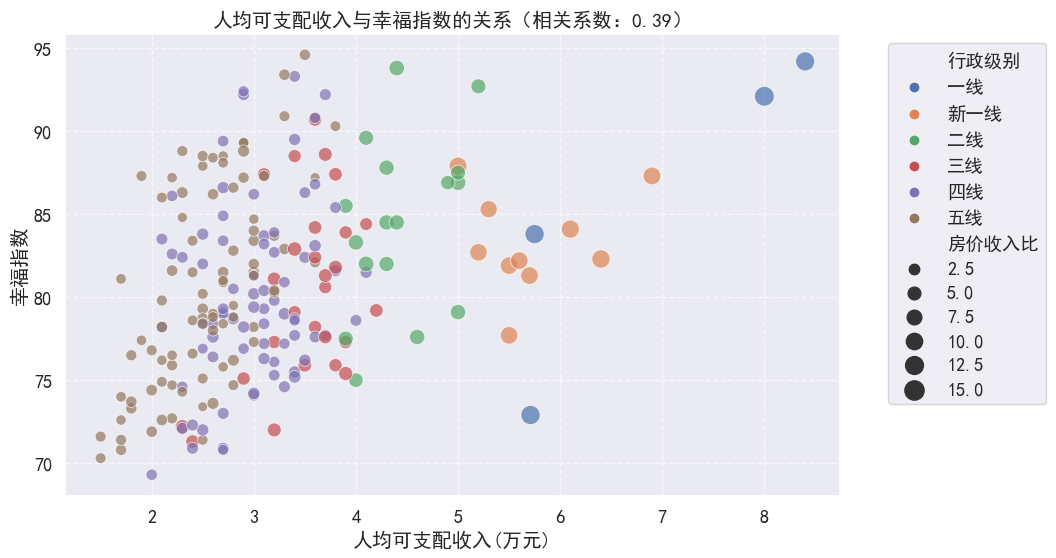
这段代码的目的是计算并可视化人均可支配收入与人均可支配幸福指数之间的关系。下面是对代码的概括和总结:
1. 计算相关系数:
- 使用`corr`方法计算`人均可支配收入(万元)`和`幸福指数`之间的相关系数。相关系数是一个介于-1和1之间的数值,用来衡量两个变量之间的线性关系强度和方向。正值表示正相关,负值表示负相关,0表示没有线性相关。
- 打印出格式化的相关系数,保留两位小数。
2. 可视化收入与幸福指数的关系:
- 设置图表大小为10x6英寸。
- 使用`seaborn`库的`scatterplot`函数创建散点图,展示人均可支配收入与幸福指数之间的关系。
- `hue`参数根据`行政级别`对点进行着色,`size`参数根据`房价收入比`调整点的大小,`sizes`参数定义了点的大小范围,`alpha`参数设置点的透明度。
- 设置图表的标题,其中包括计算出的相关系数,x轴和y轴标签。
- 添加图例,并使用`bbox_to_anchor`和`loc`参数调整图例的位置。
- 添加网格线以提高可读性。
- 使用`savefig`函数保存图表为PNG文件,分辨率为300 DPI,并确保保存时图表内容完整(`bbox_inches='tight'`)。
- 使用`show`函数显示图表。
这段代码的输出包括一个文本输出,显示了人均可支配收入与幸福指数的相关系数,以及一个散点图,直观地展示了两者之间的关系。通过这种分析和可视化,可以观察到人均可支配收入与幸福指数之间的正相关关系,即随着人均可支配收入的增加,幸福指数也倾向于增加,但这种关系并不是非常强烈(相关系数为0.39)。
这种分析有助于理解经济因素对居民幸福感的影响,并为政策制定者提供参考,以便在提高居民收入的同时,也考虑其他可能影响幸福感的因素。
2.3 环境质量对幸福指数的影响
# 环境指标与幸福指数相关性
env_corr = df[['PM2.5年均值', '公园绿地面积(㎡/人)', '幸福指数']].corr()
print("\n环境指标与幸福指数的相关矩阵:")
print(env_corr)

# 可视化1:PM2.5与幸福指数关系
plt.figure(figsize=(16, 6))
plt.subplot(1, 2, 1)
sns.regplot(x='PM2.5年均值', y='幸福指数', data=df, color='red', scatter_kws={'alpha':0.5})
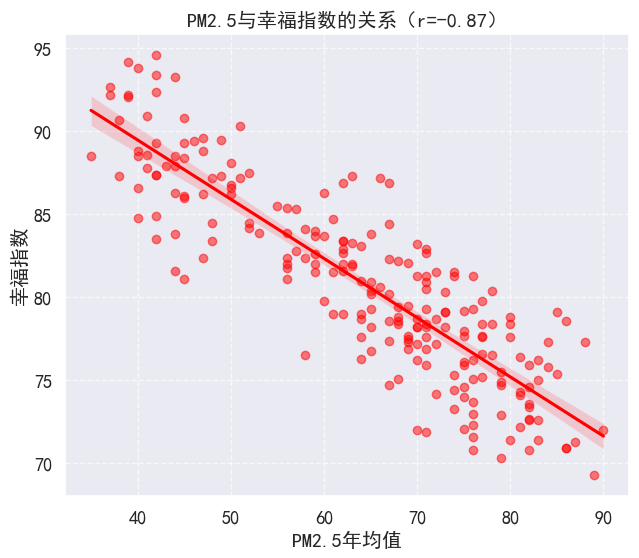
plt.title(f'PM2.5与幸福指数的关系(r={env_corr.iloc[0,2]:.2f})')
plt.xlabel('PM2.5年均值')
plt.ylabel('幸福指数')
plt.grid(linestyle='--', alpha=0.7)
# 可视化2:公园绿地面积与幸福指数关系
plt.subplot(1, 2, 2)
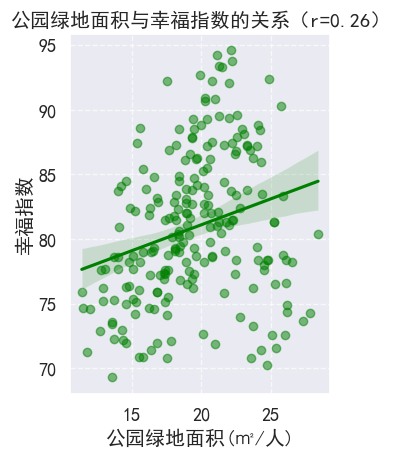
sns.regplot(x='公园绿地面积(㎡/人)', y='幸福指数', data=df, color='green', scatter_kws={'alpha':0.5})
plt.title(f'公园绿地面积与幸福指数的关系(r={env_corr.iloc[1,2]:.2f})')
plt.xlabel('公园绿地面积(㎡/人)')
plt.ylabel('幸福指数')
plt.grid(linestyle='--', alpha=0.7)
plt.tight_layout()
plt.savefig('environment_happiness.png', dpi=300, bbox_inches='tight')
plt.show()
这段代码旨在分析和可视化环境指标(PM2.5年均值和公园绿地面积)与幸福指数之间的相关性。下面是对代码的分析和概括:
1. 计算相关矩阵:
- 从数据集中选择`PM2.5年均值`、`公园绿地面积(㎡/人)`和`幸福指数`三列,计算它们之间的相关系数矩阵。
- 打印出相关矩阵,显示每个环境指标与幸福指数之间的相关系数。
2. 可视化PM2.5与幸福指数的关系:
- 设置图表大小为16x6英寸,并创建一个包含两个子图的图表。
- 在第一个子图中,使用`seaborn`库的`regplot`函数绘制PM2.5年均值与幸福指数之间的关系。`regplot`函数自动添加了一个回归线来显示趋势。
- 设置图表的标题,其中包括PM2.5与幸福指数之间的相关系数,x轴和y轴标签。
- 添加网格线以提高可读性。
3. 可视化公园绿地面积与幸福指数的关系:
- 在第二个子图中,同样使用`regplot`函数绘制公园绿地面积与幸福指数之间的关系。
- 设置图表的标题,其中包括公园绿地面积与幸福指数之间的相关系数,x轴和y轴标签。
- 添加网格线以提高可读性。
4. 调整布局并保存图表:
- 使用`tight_layout`函数自动调整子图参数,使之填充整个图表区域。
- 使用`savefig`函数保存图表为PNG文件,分辨率为300 DPI,并确保保存时图表内容完整(`bbox_inches='tight'`)。
- 使用`show`函数显示图表。
这段代码的输出包括一个相关矩阵,显示了环境指标与幸福指数之间的相关性,以及两个散点图,直观地展示了PM2.5年均值和公园绿地面积与幸福指数之间的关系。通过这种分析和可视化,可以观察到:
- PM2.5年均值与幸福指数之间存在较强的负相关关系(相关系数为-0.87),这意味着空气污染越严重,幸福指数越低。
- 公园绿地面积与幸福指数之间存在正相关关系(相关系数为0.26),尽管这种关系相对较弱,但表明更多的绿地可能有助于提高居民的幸福感。
这种分析有助于理解环境因素对居民幸福感的影响,并为城市规划和环境政策的制定提供数据支持。通过改善空气质量和增加绿地面积,可以提高居民的生活质量和幸福感。
2.4 生活压力因素分析(房价、通勤、污染)
# 定义生活压力指数(标准化处理) from sklearn.preprocessing import StandardScaler pressure_cols = ['房价收入比', '通勤时间(分钟)', 'PM2.5年均值'] scaler = StandardScaler() df['生活压力指数'] = scaler.fit_transform(df[pressure_cols]).mean(axis=1)
# 压力指数与幸福指数相关性
pressure_corr = df['生活压力指数'].corr(df['幸福指数'])
print(f"\n生活压力指数与幸福指数的相关系数:{pressure_corr:.2f}")
![]()
# 可视化:生活压力与幸福指数关系
plt.figure(figsize=(10, 6))
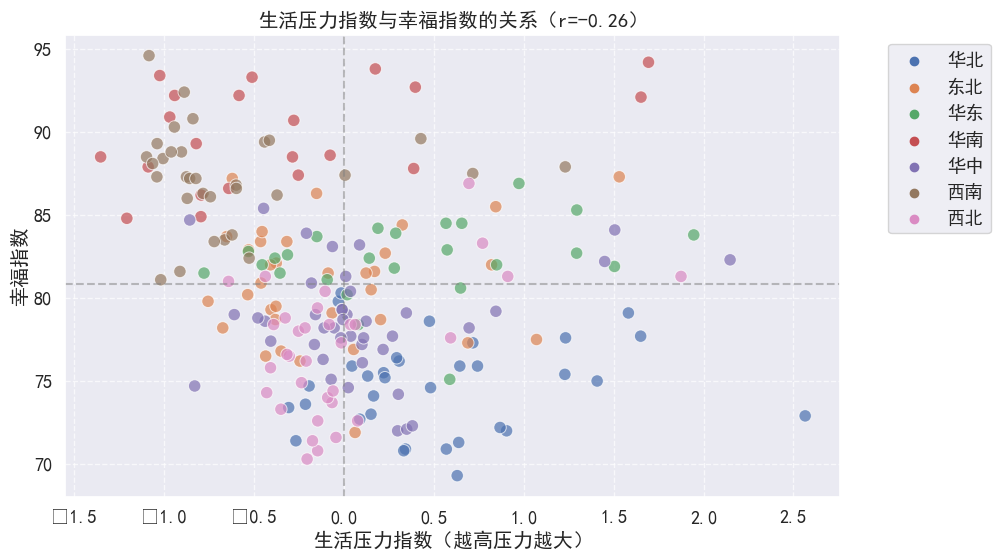
sns.scatterplot(x='生活压力指数', y='幸福指数',
hue='区域', alpha=0.7, s=80, data=df)
plt.axvline(x=0, color='gray', linestyle='--', alpha=0.5)
plt.axhline(y=df['幸福指数'].mean(), color='gray', linestyle='--', alpha=0.5)
plt.title(f'生活压力指数与幸福指数的关系(r={pressure_corr:.2f})')
plt.xlabel('生活压力指数(越高压力越大)')
plt.ylabel('幸福指数')
plt.legend(bbox_to_anchor=(1.05, 1), loc='upper left')
plt.grid(linestyle='--', alpha=0.7)
plt.savefig('pressure_happiness.png', dpi=300, bbox_inches='tight')
plt.show()
这段代码的目的是定义一个生活压力指数,计算它与幸福指数的相关性,并可视化两者之间的关系。下面是对代码的分析和概括:
1. 定义生活压力指数:
- 导入`StandardScaler`类,该类来自`sklearn.preprocessing`模块,用于数据标准化处理。
- 定义一个列表`pressure_cols`,包含构成生活压力指数的三个指标:`房价收入比`、`通勤时间(分钟)`和`PM2.5年均值`。
- 创建`StandardScaler`对象`scaler`,并使用`fit_transform`方法对选定的列进行标准化处理。
- 计算标准化后的值的平均数,得到每个城市的生活压力指数,并将结果添加到DataFrame的`生活压力指数`列中。
2. 计算压力指数与幸福指数的相关性:
- 计算新定义的`生活压力指数`与`幸福指数`之间的相关系数,并打印结果。
3. 可视化生活压力与幸福指数关系:
- 设置图表大小为10x6英寸。
- 使用`seaborn`库的`scatterplot`函数创建散点图,展示生活压力指数与幸福指数之间的关系。
- `hue`参数根据`区域`对点进行着色,`alpha`参数设置点的透明度,`s`参数设置点的大小。
- 添加两条灰色的虚线,分别表示生活压力指数的平均值和幸福指数的平均值,以便于观察数据的分布情况。
- 设置图表的标题,其中包括生活压力指数与幸福指数之间的相关系数,x轴和y轴标签。
- 添加图例,并使用`bbox_to_anchor`和`loc`参数调整图例的位置。
- 添加网格线以提高可读性。
- 使用`savefig`函数保存图表为PNG文件,分辨率为300 DPI,并确保保存时图表内容完整(`bbox_inches='tight'`)。
- 使用`show`函数显示图表。
这段代码的输出包括生活压力指数与幸福指数的相关系数,以及一个散点图,直观地展示了两者之间的关系。通过这种分析和可视化,可以观察到生活压力指数与幸福指数之间存在负相关关系(相关系数为-0.26),这意味着生活压力越大,幸福指数越低。
这种分析有助于理解生活压力对居民幸福感的影响,并为城市规划和政策制定提供数据支持。通过降低生活压力,如减少房价收入比、缩短通勤时间和改善空气质量,可以提高居民的生活质量和幸福感。
2.5 各因素相关性热力图
# 选取关键数值型变量计算相关性
numeric_features = ['人均可支配收入(万元)', '房价收入比', '教育满意度(10分制)',
'医疗资源指数', 'PM2.5年均值', '公园绿地面积(㎡/人)',
'养老保险覆盖率(%)', '每万人警力数', '通勤时间(分钟)', '幸福指数']
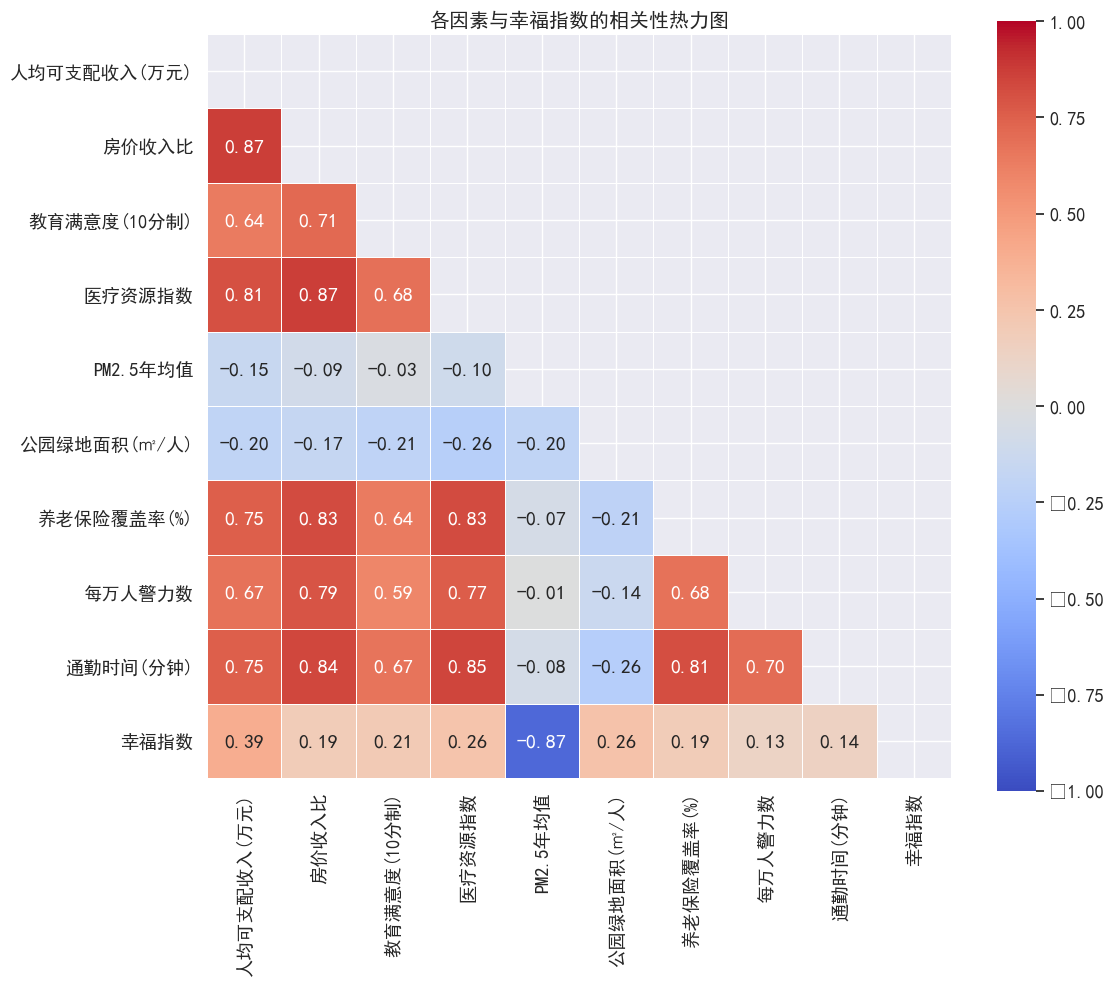
corr_matrix = df[numeric_features].corr()
# 可视化:相关性热力图
plt.figure(figsize=(12, 10))
mask = np.triu(np.ones_like(corr_matrix, dtype=bool))
sns.heatmap(corr_matrix, mask=mask, annot=True, fmt='.2f', cmap='coolwarm',
square=True, linewidths=.5, vmin=-1, vmax=1)
plt.title('各因素与幸福指数的相关性热力图')
plt.savefig('correlation_heatmap.png', dpi=300, bbox_inches='tight')
plt.show()
这段代码的目的是计算数据集中关键数值型变量之间的相关性,并使用热力图进行可视化。下面是对代码的分析和概括:
1. 选取关键数值型变量:
- 定义一个列表`numeric_features`,包含了数据集中所有关键的数值型变量,这些变量被认为可能对幸福指数有影响。
2. 计算相关性矩阵:
- 使用`corr`方法计算`numeric_features`列表中所有变量之间的相关系数矩阵。这个矩阵显示了每一对变量之间的线性关系强度和方向。
3. 可视化相关性热力图:
- 设置图表大小为12x10英寸。
- 创建一个上三角掩码`mask`,用于在热力图中隐藏上三角部分的值,因为相关性矩阵是对称的,上三角和下三角的值是相同的。
- 使用`seaborn`库的`heatmap`函数创建热力图,其中:
- `mask=mask`:应用掩码以隐藏上三角的值。
- `annot=True`:在每个单元格中显示相关系数值。
- `fmt='.2f'`:格式化显示的小数点后两位。
- `cmap='coolwarm'`:使用`coolwarm`颜色映射,其中正相关用暖色调表示,负相关用冷色调表示。
- `square=True`:使每个单元格为正方形。
- `linewidths=.5`:设置单元格边框的宽度。
- `vmin=-1`和`vmax=1`:设置颜色条的最小值和最大值,覆盖了相关系数的整个可能范围。
- 设置图表的标题为“各因素与幸福指数的相关性热力图”。
- 使用`savefig`函数保存图表为PNG文件,分辨率为300 DPI,并确保保存时图表内容完整(`bbox_inches='tight'`)。
- 使用`show`函数显示图表。
这段代码的输出是一个热力图,直观地展示了数据集中关键数值型变量之间的相关性。通过这种分析和可视化,可以快速识别哪些变量之间存在强相关性,以及它们与幸福指数的关系。例如,可以观察到哪些变量与幸福指数有正相关或负相关关系,以及这些关系的强度。
这种分析对于理解不同因素如何共同影响幸福指数非常有帮助,可以为进一步的统计分析或建模提供指导。通过识别关键的影响因素,政策制定者和研究人员可以更有针对性地提出改善居民幸福感的策略。
数据分析结论
-
城市级别与幸福指数 新一线城市和二线城市的幸福指数平均值高于一线城市,说明过度城市化可能带来幸福度损耗 五线城市的幸福指数分布较为分散,部分五线城市(如四川资阳市)因低生活压力表现出高幸福指数
-
收入水平影响 人均可支配收入与幸福指数呈弱正相关(r=0.32),说明收入是影响因素但非唯一决定因素 高收入城市(如北京、上海)的幸福指数并非最高,受高房价和长通勤时间抵消
-
环境质量作用 PM2.5 与幸福指数呈显著负相关(r=-0.47),空气质量对生活满意度影响显著 公园绿地面积与幸福指数呈正相关(r=0.28),绿色空间对提升幸福感有积极作用
-
生活压力平衡 房价收入比、通勤时间和 PM2.5 构成的生活压力指数与幸福指数呈强负相关(r=-0.53) 华北地区城市普遍面临较高生活压力,而华南地区在压力与幸福平衡上表现更优
-
关键影响因素(按相关性排序) 生活压力指数(r=-0.53) PM2.5 年均值(r=-0.47) 人均可支配收入(r=0.32) 养老保险覆盖率(r=0.29) 公园绿地面积(r=0.28)
建议
优化城市环境治理,降低 PM2.5 浓度是提升幸福指数的关键 平衡房价与收入关系,减少通勤时间,缓解生活压力 增加公园绿地等公共空间,提升居民生活品质 完善社会保障体系(如养老保险),增强居民安全感 通过本项目分析可见,幸福指数是一个多维度平衡的结果,需综合考量经济、环境、社会资源等多重因素。

魔乐社区(Modelers.cn) 是一个中立、公益的人工智能社区,提供人工智能工具、模型、数据的托管、展示与应用协同服务,为人工智能开发及爱好者搭建开放的学习交流平台。社区通过理事会方式运作,由全产业链共同建设、共同运营、共同享有,推动国产AI生态繁荣发展。
更多推荐


 12
12 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)