【完整源码+数据集+部署教程】 叉车图像分割系统源码&数据集分享 [yolov8-seg-rtdetr等50+全套改进创新点发刊_一键训练教程_Web前端展示]
【完整源码+数据集+部署教程】 叉车图像分割系统源码&数据集分享[yolov8-seg-rtdetr等50+全套改进创新点发刊_一键训练教程_Web前端展示]
背景意义
随着工业自动化的快速发展,叉车作为现代物流和仓储管理中不可或缺的设备,其应用范围不断扩大。叉车在搬运、堆垛和分拣等环节中发挥着重要作用,因此对叉车的智能识别与监控技术的需求日益增加。传统的叉车识别方法多依赖于人工操作或简单的图像处理技术,效率低下且易受环境因素的影响,难以满足现代智能仓储的需求。因此,开发一种高效、准确的叉车图像分割系统显得尤为重要。
在这一背景下,基于深度学习的目标检测与图像分割技术逐渐成为研究热点。YOLO(You Only Look Once)系列模型因其高效的实时性和较强的检测能力,已被广泛应用于各类目标检测任务。YOLOv8作为该系列的最新版本,结合了多种先进的技术,具有更高的准确性和更快的推理速度。然而,针对叉车图像分割的特定需求,YOLOv8仍存在一些改进空间,尤其是在处理复杂背景、遮挡情况以及多叉车同时出现的场景时。因此,基于改进YOLOv8的叉车图像分割系统的研究具有重要的现实意义。
本研究将使用包含1300张图像的叉车图像分割数据集,该数据集涵盖了三类叉车目标,具体为类别0、1和2。这些图像不仅包括叉车的不同视角和状态,还涉及多种复杂的背景环境,如仓库、工厂和户外场景。这为模型的训练和测试提供了丰富的样本,有助于提高模型的泛化能力和鲁棒性。通过对这些图像进行实例分割,能够精确地识别出叉车的轮廓和位置,从而为后续的自动化操作提供基础数据支持。
此外,叉车图像分割系统的研究还具有广泛的应用前景。通过实现对叉车的精准识别与定位,可以为智能仓储系统提供实时监控和管理解决方案,提升物流效率,降低人工成本。同时,该系统也可以与其他智能设备进行联动,形成完整的智能物流生态系统。例如,在自动驾驶叉车的应用中,图像分割技术可以帮助其更好地理解周围环境,从而实现安全、高效的自主作业。
综上所述,基于改进YOLOv8的叉车图像分割系统的研究,不仅能够推动深度学习技术在工业领域的应用,还将为叉车的智能化管理提供重要的技术支持。通过深入探讨该系统的设计与实现,期望能够为未来的智能物流发展贡献新的思路与方法,推动工业自动化的进一步发展。
图片效果
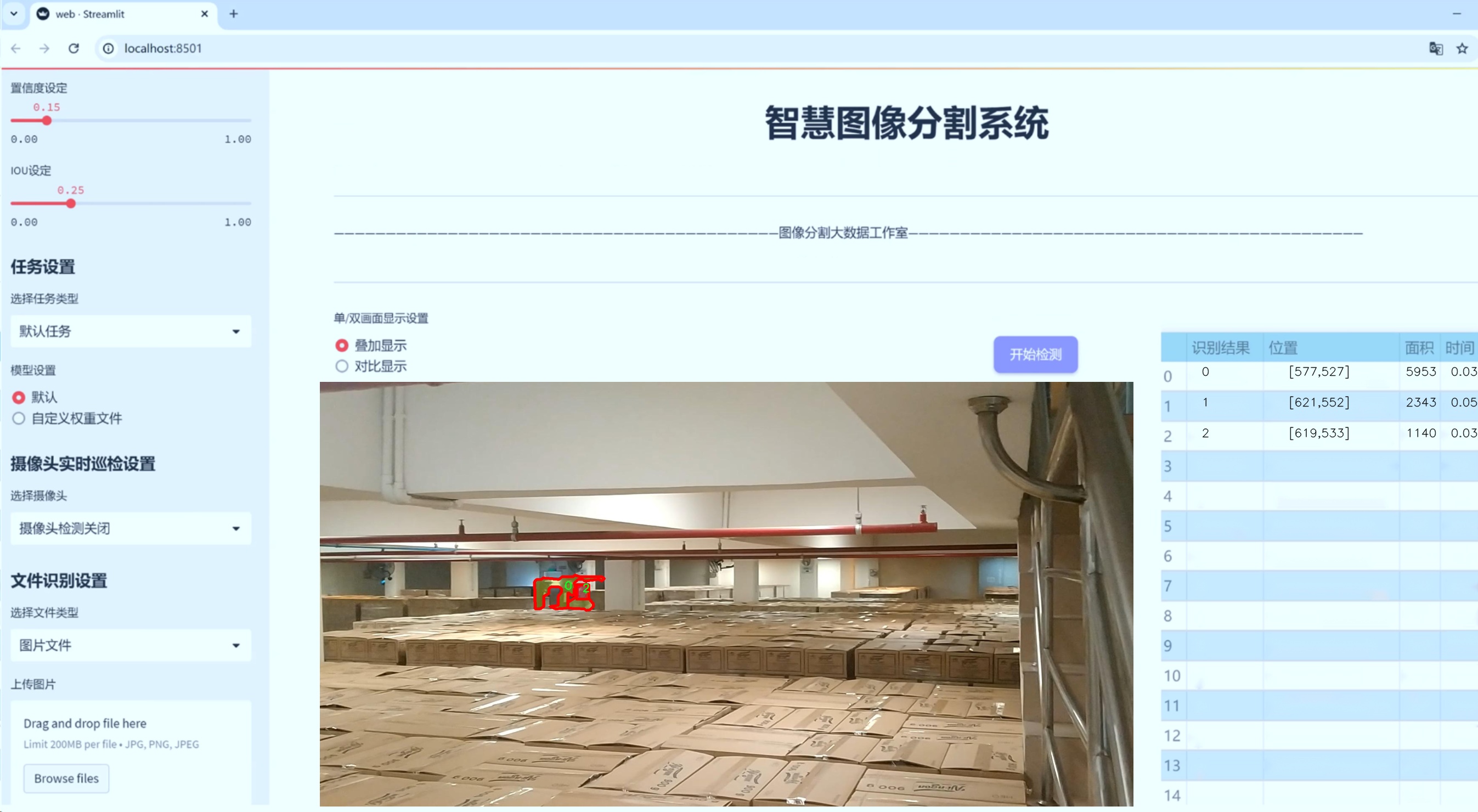
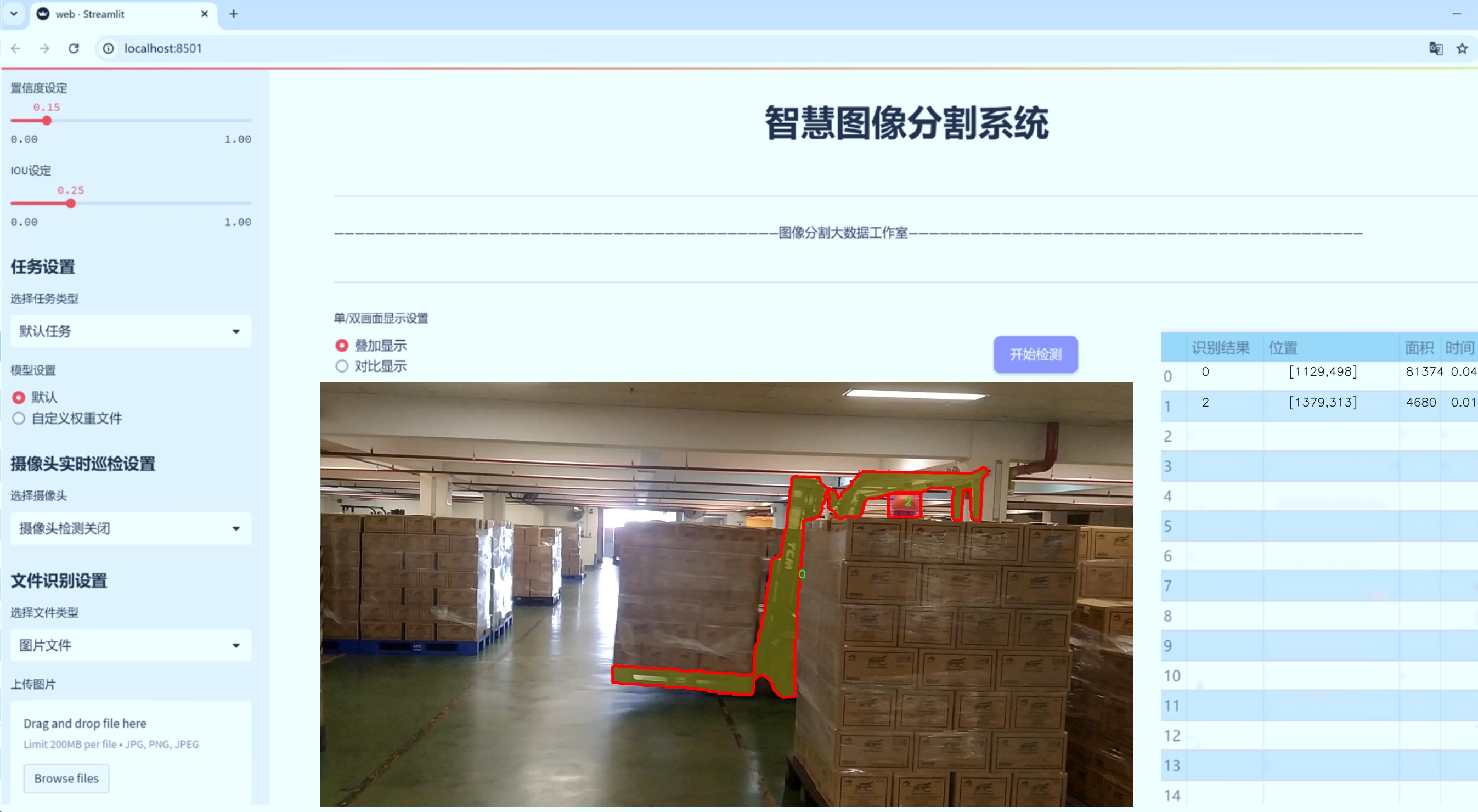
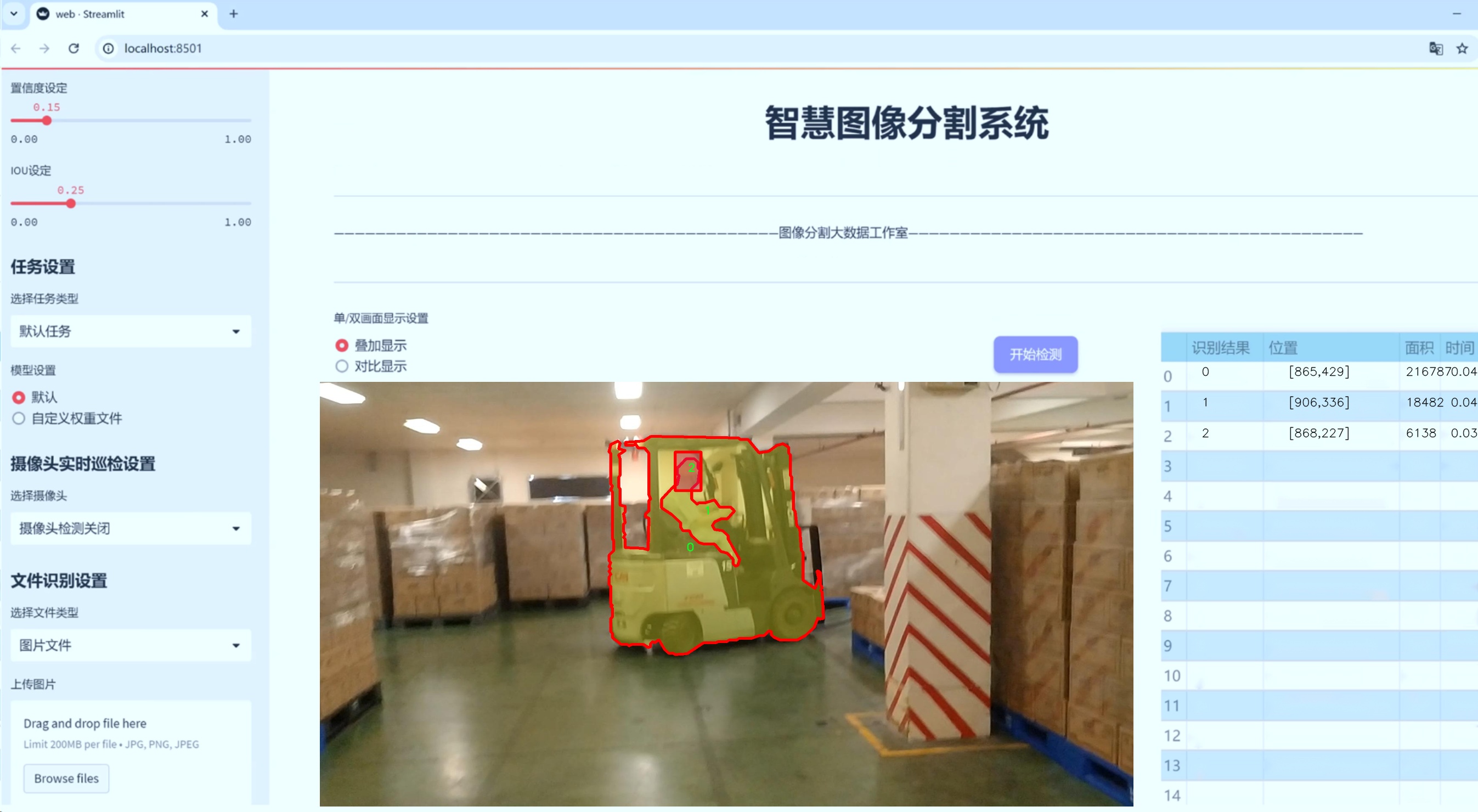
数据集信息
在现代计算机视觉领域,图像分割技术的进步为自动化和智能化应用提供了强有力的支持。为此,本研究所采用的数据集“forklift2_seg”专门用于训练和改进YOLOv8-seg叉车图像分割系统,旨在提升叉车识别与分割的准确性和效率。该数据集包含了多样化的叉车图像,涵盖了不同环境、角度和光照条件下的叉车样本,确保了模型在实际应用中的鲁棒性。
“forklift2_seg”数据集的类别数量为3,分别用数字“0”、“1”和“2”进行标识。这些类别的设计考虑到了叉车在不同场景中的多样性,具体来说,类别“0”可能代表某种特定类型的叉车,例如电动叉车,而类别“1”则可能对应于内燃叉车,类别“2”则可以是叉车的配件或其他相关设备。这样的分类不仅有助于模型在训练过程中学习到叉车的基本特征,还能使其在面对复杂场景时具备更强的辨识能力。
数据集中的图像经过精心挑选和标注,确保每个类别的样本都具备代表性和多样性。标注过程采用了先进的图像标注工具,确保每个叉车的轮廓和关键特征都被准确地勾勒出来。这样的高质量标注为YOLOv8-seg模型的训练提供了坚实的基础,使其能够在分割任务中实现更高的精度。此外,数据集中还包含了不同背景和环境的图像,以模拟叉车在实际工作中的多种应用场景,进一步增强模型的泛化能力。
在数据集的构建过程中,考虑到了图像的多样性和复杂性,确保模型在面对不同类型叉车时能够有效地进行分割。这种多样性不仅体现在叉车的外观上,还包括叉车与周围环境的互动,例如叉车在仓库、工厂、建筑工地等不同场景中的表现。通过这种方式,研究团队希望模型能够学习到叉车在各种环境下的特征,从而在实际应用中表现出色。
为了确保数据集的有效性和实用性,研究团队还进行了数据增强处理,包括旋转、缩放、翻转和亮度调整等。这些增强手段旨在增加数据集的样本数量和多样性,使得模型在训练过程中能够接触到更多的变异情况,从而提高其鲁棒性和适应性。经过这些处理后的数据集,不仅提升了模型的训练效果,也为后续的验证和测试提供了更为全面的样本支持。
总之,“forklift2_seg”数据集的构建充分考虑了叉车图像分割任务的实际需求,通过精心的样本选择和标注、丰富的类别设计以及有效的数据增强手段,为YOLOv8-seg模型的训练提供了坚实的基础。随着数据集的应用,研究团队期待能够在叉车图像分割领域取得突破性进展,为相关行业的自动化和智能化发展贡献力量。




核心代码
```python
import torch
import torch.nn as nn
import torch.nn.functional as F
from ..modules.conv import Conv
# 定义基本的卷积块
class BasicBlock(nn.Module):
def __init__(self, filter_in, filter_out):
super(BasicBlock, self).__init__()
# 定义两个卷积层
self.conv1 = Conv(filter_in, filter_out, 3) # 第一个卷积层
self.conv2 = Conv(filter_out, filter_out, 3, act=False) # 第二个卷积层,不使用激活函数
def forward(self, x):
residual = x # 保存输入以便后续残差连接
out = self.conv1(x) # 通过第一个卷积层
out = self.conv2(out) # 通过第二个卷积层
out += residual # 添加残差
return self.conv1.act(out) # 返回经过激活函数处理的输出
# 定义上采样模块
class Upsample(nn.Module):
def __init__(self, in_channels, out_channels, scale_factor=2):
super(Upsample, self).__init__()
# 定义上采样操作
self.upsample = nn.Sequential(
Conv(in_channels, out_channels, 1), # 1x1卷积
nn.Upsample(scale_factor=scale_factor, mode='bilinear') # 双线性插值上采样
)
def forward(self, x):
return self.upsample(x) # 直接返回上采样结果
# 定义自适应特征融合模块(ASFF)
class ASFF(nn.Module):
def __init__(self, num_levels, inter_dim=512):
super(ASFF, self).__init__()
self.inter_dim = inter_dim
compress_c = 8 # 压缩通道数
# 定义每个输入层的权重卷积
self.weight_layers = nn.ModuleList([Conv(inter_dim, compress_c, 1) for _ in range(num_levels)])
self.weight_levels = nn.Conv2d(compress_c * num_levels, num_levels, kernel_size=1) # 权重层
self.conv = Conv(inter_dim, inter_dim, 3) # 最后的卷积层
def forward(self, *inputs):
# 计算每个输入的权重
weights = [layer(input) for layer, input in zip(self.weight_layers, inputs)]
levels_weight_v = torch.cat(weights, dim=1) # 连接所有权重
levels_weight = self.weight_levels(levels_weight_v) # 计算最终权重
levels_weight = F.softmax(levels_weight, dim=1) # 归一化权重
# 进行加权融合
fused_out_reduced = sum(input * levels_weight[:, i:i+1, :, :] for i, input in enumerate(inputs))
return self.conv(fused_out_reduced) # 返回融合后的结果
# 定义主网络结构
class AFPN(nn.Module):
def __init__(self, in_channels, out_channels, factor=4):
super(AFPN, self).__init__()
# 定义输入通道的卷积层
self.convs = nn.ModuleList([Conv(in_channel, in_channel // factor, 1) for in_channel in in_channels])
self.body = BlockBody_P345([in_channel // factor for in_channel in in_channels]) # 主要处理体
# 定义输出通道的卷积层
self.output_convs = nn.ModuleList([Conv(in_channel // factor, out_channels, 1) for in_channel in in_channels])
def forward(self, x):
# 对输入进行卷积处理
x = [conv(input) for conv, input in zip(self.convs, x)]
out = self.body(x) # 通过主处理体
# 通过输出卷积层
return [output_conv(output) for output_conv, output in zip(self.output_convs, out)]
# 定义自定义的AFPN网络
class AFPN_Custom(AFPN):
def __init__(self, in_channels, out_channels, block_type='C2f', factor=4):
super().__init__(in_channels, out_channels, factor)
self.body = BlockBody_P345_Custom([in_channel // factor for in_channel in in_channels], block_type) # 使用自定义块
代码说明:
- BasicBlock: 这是一个基本的卷积块,包含两个卷积层和一个残差连接。
- Upsample: 这是一个上采样模块,使用1x1卷积和双线性插值进行上采样。
- ASFF: 自适应特征融合模块,能够根据输入特征的权重进行加权融合。
- AFPN: 主网络结构,负责将输入特征进行卷积处理,并通过BlockBody进行特征融合和处理。
- AFPN_Custom: 自定义的AFPN网络,允许使用不同类型的块。
以上代码为核心功能模块,便于理解和扩展。```
该文件定义了一些用于特征金字塔网络(FPN)的模块,主要用于计算机视觉任务中的特征提取和融合。代码使用了PyTorch框架,以下是对各个部分的详细说明。
首先,文件导入了一些必要的库和模块,包括OrderedDict、torch、torch.nn和一些自定义的卷积和块模块。接着,定义了一些类,这些类主要用于构建特征金字塔网络的各个组件。
BasicBlock类是一个基本的残差块,包含两个卷积层。它的前向传播方法中,输入经过两个卷积层处理后,与输入相加,形成残差连接,最后通过激活函数输出。
Upsample类实现了上采样操作,使用卷积层和双线性插值来增加特征图的尺寸。Downsample_x2、Downsample_x4和Downsample_x8类则分别实现了不同倍数的下采样,使用卷积层进行特征图的尺寸缩小。
ASFF_2、ASFF_3和ASFF_4类实现了自适应特征融合模块(ASFF),用于融合不同尺度的特征图。每个类的构造函数中定义了用于计算权重的卷积层,前向传播方法中通过计算输入特征图的权重,融合多个输入特征图并输出。
BlockBody_P345和BlockBody_P2345类是特征金字塔网络的主体部分,分别处理三个和四个尺度的特征图。它们的构造函数中定义了多个卷积层、下采样和上采样模块,以及自适应特征融合模块。前向传播方法中,输入的特征图经过多个处理步骤,包括卷积、下采样、上采样和特征融合,最终输出多个尺度的特征图。
AFPN_P345和AFPN_P2345类是特征金字塔网络的最终实现,分别对应于处理三个和四个输入通道的特征图。它们的构造函数中定义了输入通道的卷积层、主体部分以及输出通道的卷积层。在前向传播方法中,输入特征图经过卷积处理后传递给主体部分,最后输出经过处理的特征图。
BlockBody_P345_Custom、BlockBody_P2345_Custom、AFPN_P345_Custom和AFPN_P2345_Custom类是对前面类的扩展,允许用户自定义块类型,以便在构建特征金字塔网络时使用不同的模块。
整体来看,这个文件实现了一个灵活的特征金字塔网络结构,能够根据输入特征图的不同尺度进行有效的特征提取和融合,适用于各种计算机视觉任务,如目标检测和图像分割等。
```python
# 导入必要的库
from copy import copy
import torch
from ultralytics.models.yolo.detect import DetectionTrainer
from ultralytics.nn.tasks import RTDETRDetectionModel
from ultralytics.utils import RANK, colorstr
from .val import RTDETRDataset, RTDETRValidator
class RTDETRTrainer(DetectionTrainer):
"""
RT-DETR模型的训练类,继承自YOLO的DetectionTrainer类。
该模型由百度开发,旨在实现实时目标检测,利用视觉变换器(Vision Transformers)和其他特性。
"""
def get_model(self, cfg=None, weights=None, verbose=True):
"""
初始化并返回一个用于目标检测的RT-DETR模型。
参数:
cfg (dict, optional): 模型配置,默认为None。
weights (str, optional): 预训练模型权重的路径,默认为None。
verbose (bool): 是否详细日志记录,默认为True。
返回:
(RTDETRDetectionModel): 初始化后的模型。
"""
# 创建RT-DETR检测模型
model = RTDETRDetectionModel(cfg, nc=self.data['nc'], verbose=verbose and RANK == -1)
if weights:
model.load(weights) # 加载预训练权重
return model
def build_dataset(self, img_path, mode='val', batch=None):
"""
构建并返回用于训练或验证的RT-DETR数据集。
参数:
img_path (str): 包含图像的文件夹路径。
mode (str): 数据集模式,'train'或'val'。
batch (int, optional): 矩形训练的批量大小,默认为None。
返回:
(RTDETRDataset): 针对特定模式的数据集对象。
"""
# 创建RT-DETR数据集
return RTDETRDataset(img_path=img_path,
imgsz=self.args.imgsz,
batch_size=batch,
augment=mode == 'train', # 训练模式下进行数据增强
hyp=self.args,
rect=False,
cache=self.args.cache or None,
prefix=colorstr(f'{mode}: '), # 设置前缀以便于日志记录
data=self.data)
def get_validator(self):
"""
返回适合RT-DETR模型验证的检测验证器。
返回:
(RTDETRValidator): 用于模型验证的验证器对象。
"""
self.loss_names = 'giou_loss', 'cls_loss', 'l1_loss' # 定义损失名称
return RTDETRValidator(self.test_loader, save_dir=self.save_dir, args=copy(self.args))
def preprocess_batch(self, batch):
"""
预处理一批图像,将图像缩放并转换为浮点格式。
参数:
batch (dict): 包含一批图像、边界框和标签的字典。
返回:
(dict): 预处理后的批次数据。
"""
batch = super().preprocess_batch(batch) # 调用父类的方法进行预处理
bs = len(batch['img']) # 获取批次大小
batch_idx = batch['batch_idx'] # 获取批次索引
gt_bbox, gt_class = [], [] # 初始化真实边界框和类别列表
for i in range(bs):
# 收集每个图像的真实边界框和类别
gt_bbox.append(batch['bboxes'][batch_idx == i].to(batch_idx.device))
gt_class.append(batch['cls'][batch_idx == i].to(device=batch_idx.device, dtype=torch.long))
return batch # 返回预处理后的批次数据
代码说明:
- 导入部分:导入所需的库和模块,包括模型训练、数据集和验证器。
- RTDETRTrainer类:继承自YOLO的
DetectionTrainer,用于训练RT-DETR模型。 - get_model方法:初始化RT-DETR模型,支持加载预训练权重。
- build_dataset方法:构建训练或验证数据集,支持数据增强。
- get_validator方法:返回用于模型验证的验证器,定义损失名称。
- preprocess_batch方法:对输入的图像批次进行预处理,包括缩放和类型转换。```
这个程序文件是一个用于训练RT-DETR模型的Python脚本,属于Ultralytics YOLO框架的一部分。RT-DETR是一种实时目标检测模型,由百度开发,结合了视觉变换器(Vision Transformers)和一些特定的功能,如IoU感知查询选择和可调的推理速度。
文件中首先导入了一些必要的库和模块,包括PyTorch、检测训练器(DetectionTrainer)、RT-DETR模型以及数据集和验证器的定义。接着定义了一个名为RTDETRTrainer的类,该类继承自DetectionTrainer,以便适应RT-DETR模型的特性和架构。
在类的文档字符串中,提供了一些关于RT-DETR模型的背景信息和使用注意事项,例如,RT-DETR中的F.grid_sample不支持deterministic=True参数,以及AMP训练可能导致NaN输出的问题。
RTDETRTrainer类中定义了多个方法:
-
get_model方法用于初始化并返回一个RT-DETR模型,接受模型配置、预训练权重路径和日志详细程度作为参数。如果提供了权重路径,则会加载相应的权重。 -
build_dataset方法用于构建并返回一个RT-DETR数据集,接受图像路径、模式(训练或验证)和批量大小作为参数。该方法会根据传入的参数创建一个RTDETRDataset对象,并设置相应的增强和缓存选项。 -
get_validator方法返回一个适用于RT-DETR模型验证的验证器对象,设置了损失名称并使用RTDETRValidator进行模型验证。 -
preprocess_batch方法用于预处理一批图像,将图像缩放并转换为浮点格式。该方法首先调用父类的预处理方法,然后提取每个图像的边界框和类别,并将它们转换为适当的设备和数据类型。
整体来看,这个文件实现了RT-DETR模型的训练流程,包括模型的初始化、数据集的构建、验证器的获取以及批量数据的预处理,为使用RT-DETR进行目标检测提供了基础。
源码文件
源码获取
欢迎大家点赞、收藏、关注、评论啦 、查看👇🏻获取联系方式

魔乐社区(Modelers.cn) 是一个中立、公益的人工智能社区,提供人工智能工具、模型、数据的托管、展示与应用协同服务,为人工智能开发及爱好者搭建开放的学习交流平台。社区通过理事会方式运作,由全产业链共同建设、共同运营、共同享有,推动国产AI生态繁荣发展。
更多推荐


 25
25 0
0- 0



 已为社区贡献70条内容
已为社区贡献70条内容

所有评论(0)