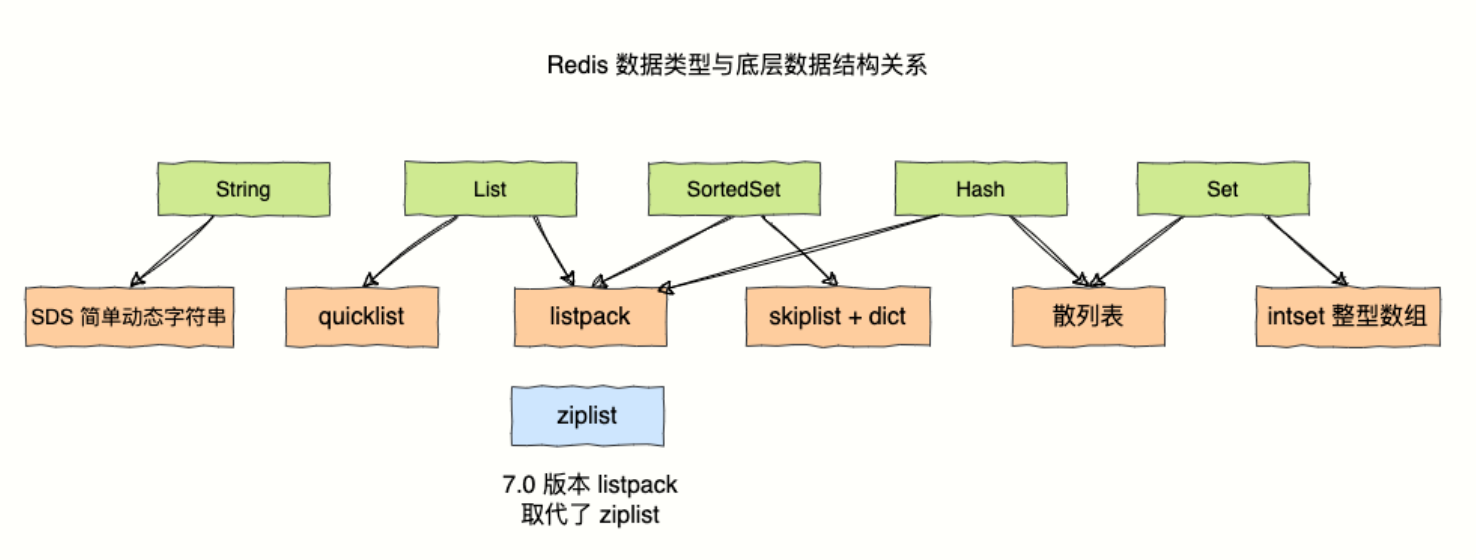
redis数据结构及底层实现结构
(4)每次执行新增、查询、修改、删除操作时,都检查一下dict.rehashidx是否大于-1,如果是则将dict.ht[0].table[rehashidx]的entry链表rehash到dict.ht[1],并且将rehashidx++,直至dict.ht[0]的所有数据都rehash到dict.ht[1](一次迁移一个元素,该元素只能出现在dict.ht[1]或者dict.ht[0]中)(由
一、字符串(String)
最简单的键值对存储,常用于缓存、计数器等场景。
命令
SET key value//设置指定key的值
GET key//获取指定key的值
MSET key value [key value ...]//同时设置一个或多个key-value对
MGET key [key ...]//获取所有给定key的值
SETNX key value//只有在key不存在时设置key的值
INCR key//将key中储存的数字值增1
DECR key//将key中储存的数字值减1
APPEND key value//如果key已经存在并且是一个字符串,将指定的value追加到该key原来值的末尾
STRLEN key//返回key所储存的字符串值的长度简单动态字符串(SDS:Simple Dynamic String)


优点
1.获取字符串长度的时间复杂度为O(1),长度保存在len字段里。
2.支持动态扩容,当字符串修改时,会根据字符串长度进行扩容。
3.减少内存分配次数,会提前内存预分配。
4.二进制安全,根据字符串长度读取字段,而不是根据\0标志判断结束。
底层实现

1.RAW
基本的编码方式是RAW,基于简单动态字符串(SDS)实现,存储上限为512MB。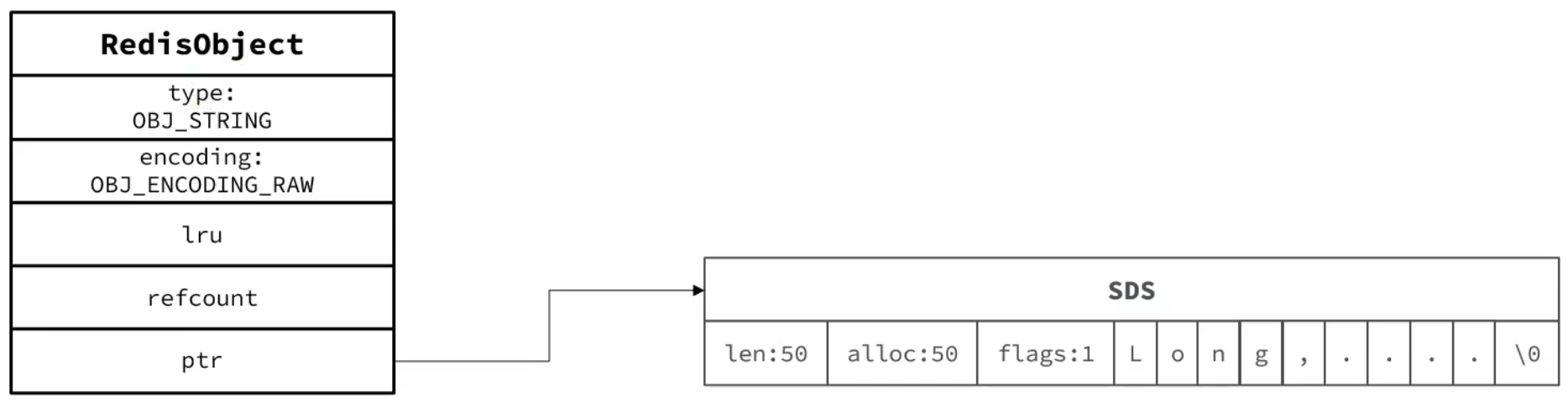
2.EMBSTR
如果存储的SDS长度小于44字节,则会才用EMBSTR编码,此时object head与SDS是一段连续空间,申请内存时只需要调用一次内存分配函数,效率更高。
3.INT
如果存储的字符串是整数值,并且大小在LONG_MAX范围内,则会采用INT编码:直接将数据保存在RedisObject的ptr指针位置(刚好8字节),不再需要SDS了。

二、列表(List)
有序链表结构,支持两端操作,适用于消息队列、时间轴等场景。
命令
LPUSH key value [value ...]//将一个或多个值插入到列表头部
RPUSH key value [value ...]//在列表中添加一个或多个值到尾部
LPOP key//移出并获取列表的第一个元素
RPOP key//移除列表的最后一个元素,返回值为移除的元素
LRANGE key start stop//获取列表指定范围内的元素
LLEN key//获取列表长度
ZipList
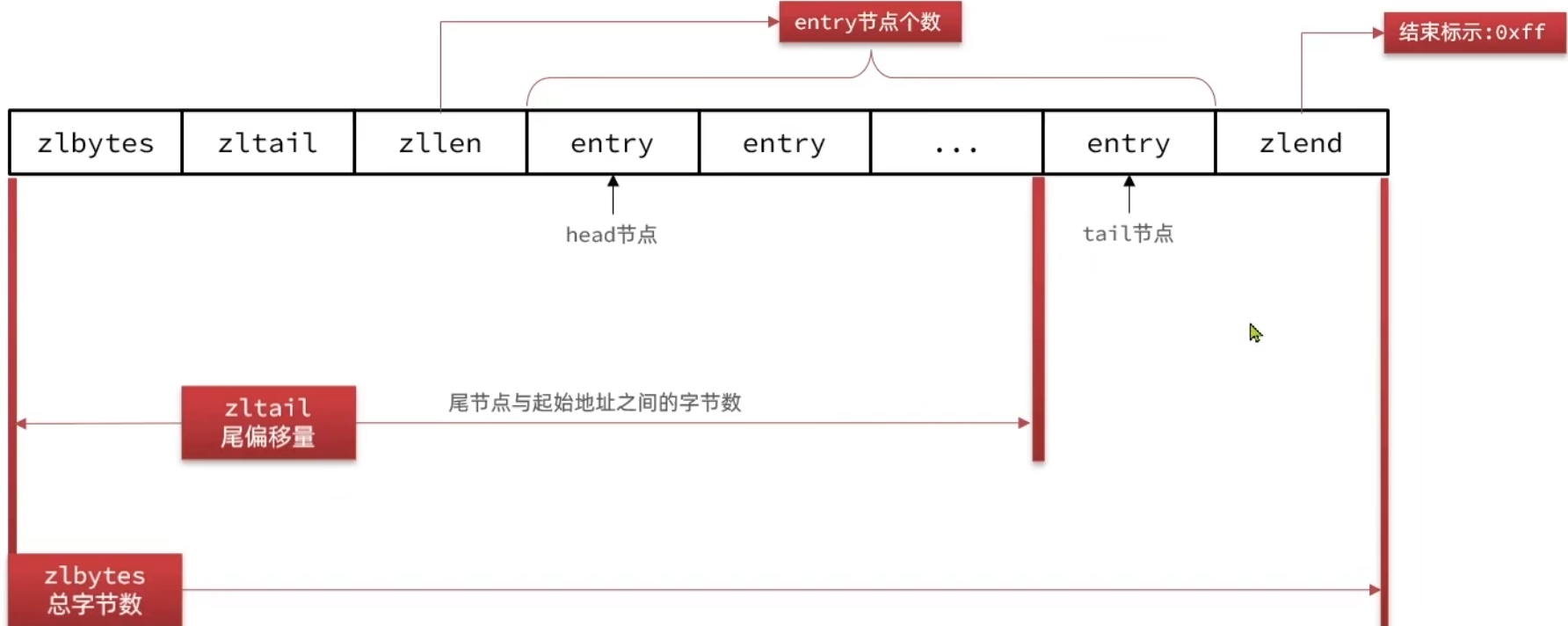
entry的数据结构:前一个节点长度,编码属性,内容。
![]()
连锁更新
当在前面插入一个新的数据时,会导致后面每一个数据空间也需要改变,就可能造成了连锁更新。连锁更新会导致ziplist的内存空间需要多次重新分配,直接影响ziplist的查询性能。(由于前一节点长度增加,后一个节点要保存前一个节点的长度,也会增加,再后一个保存前面的大小随着都需要增加。。。)

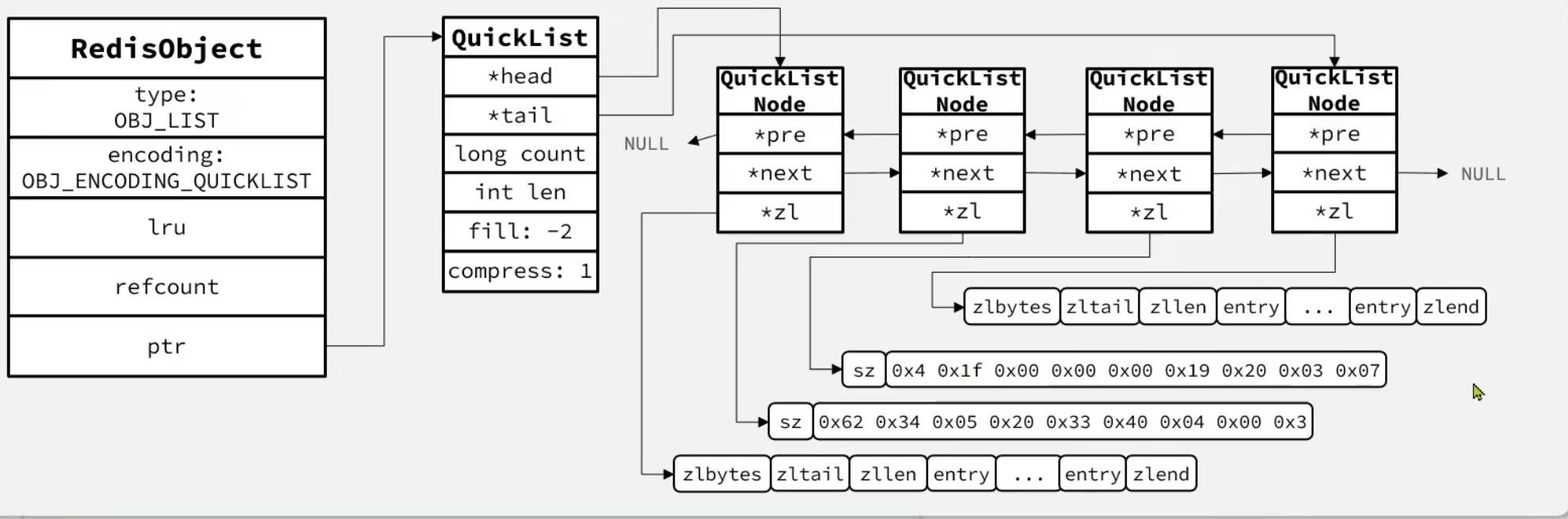
QuickList
通过QuickList里面再包含一个ZipList,既优化了查询速度,又节省了内存空间。
compress=1:压缩深度为1,首位只有一个元素不压缩,其他都压缩。fill=-2:大小为8kb。
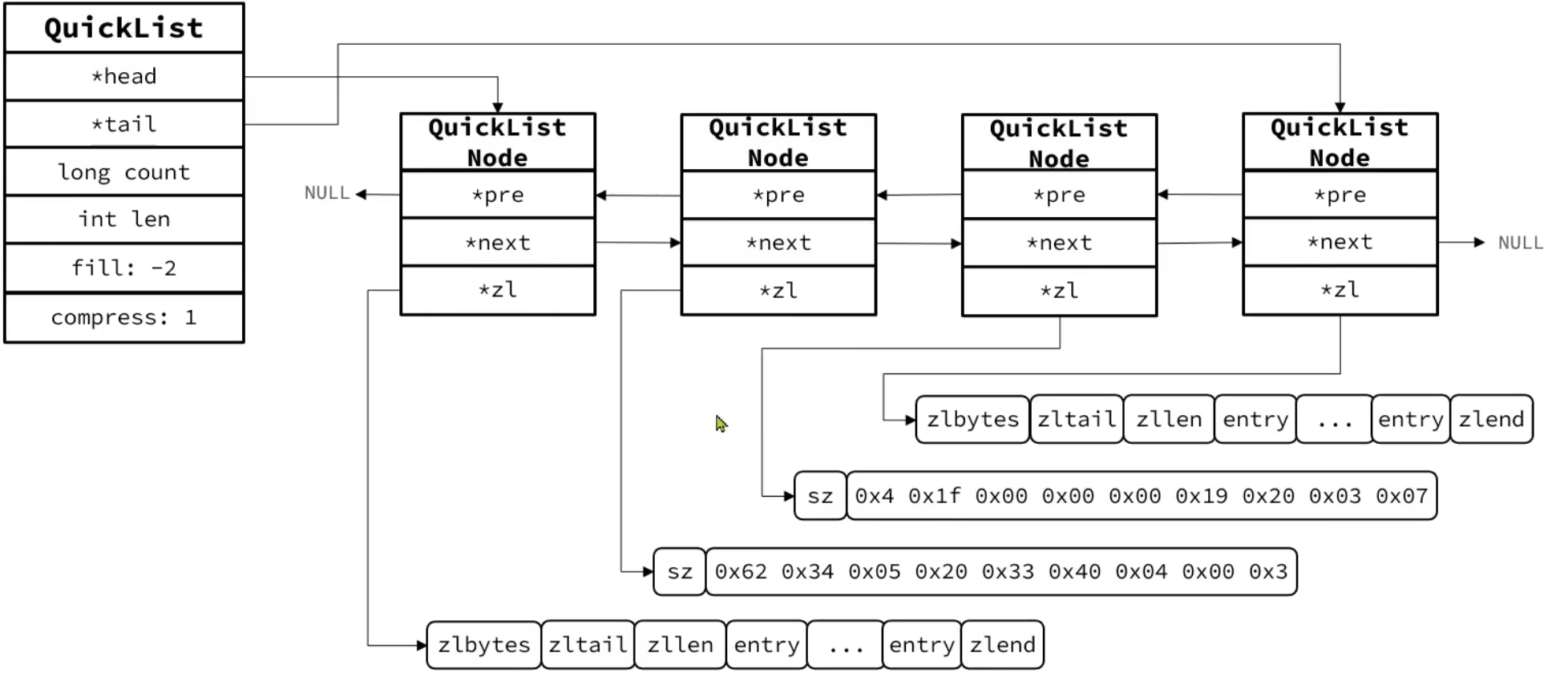
是一个节点为ZipList的双端链表。
节点采用ZipList,解决了传统链表的内存占用问题。
控制了ZipList大小,解决连续内存空间申请效率问题。
中间节点可以压缩,进一步节省了内存。
底层实现
LinkedList:普通链表,可以从双端访问,内存占用较高,内存碎片较多;每个节点都用指针相连,指针占用内存较高,且数据不连续。
ZipList:压缩列表,可以从双端访问,内存占用低,内存上限低;没有指针,根据节点大小推算位置,存储在连续的空间里。
QuickList:LinkedList+ZipList,可以双端访问,内存占用较低,包含多个ZipList,存储上限高。
三、哈希表(Hash)
存储字段-值映射,适合表示对象(如用户信息),支持部分更新。
命令
HSET key field value//将哈希表key中的字段field的值设为value
HGET key field//获取存储在哈希表中指定字段的值
HGETALL key//获取在哈希表中指定key的所有字段和值
HMSET key field value [field value ...]//同时将多个field-value对设置到哈希表key中
HMGET key field [field ...]//获取所有给定字段的值
HKEYS key//获取所有哈希表中的字段
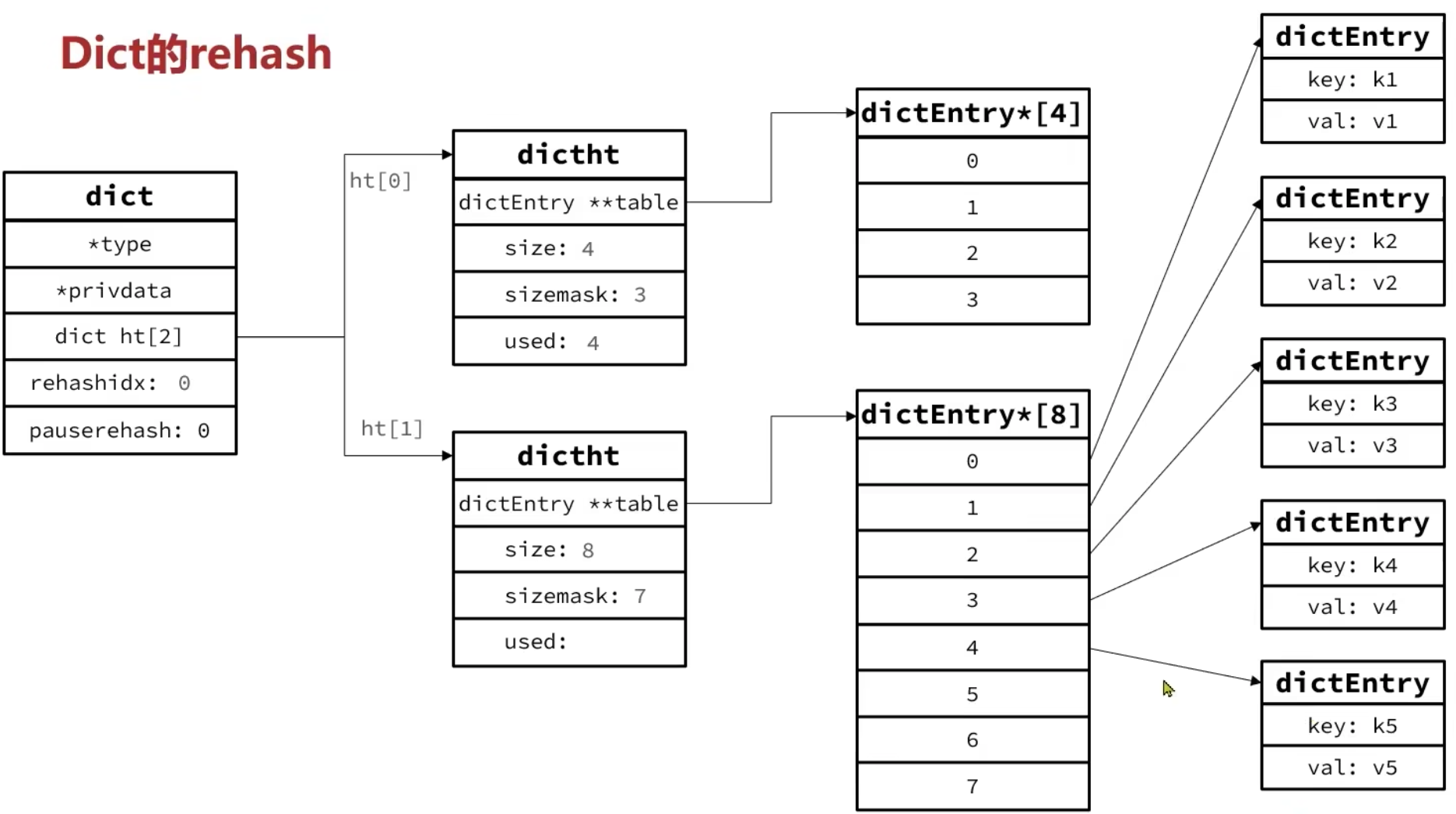
Dict(Hash Table)
Dict在每次新增键值对的时候会检查负载因子(LoadFactor=used/size),满足以下两种情况时会触发哈希表扩容。
渐进式ReHash
Redis中的渐进式rehash是一种平滑的哈希表扩容机制,它通过分批次迁移数据的方式,避免在rehash过程中造成服务阻塞。
ReHash触发条件:
(1)哈希表的LoadFactor>=1,并且服务器没有执行BGSAVE或者BGREWRITEAOF等后台进程
(2)哈希表的LoadFactor>5
ReHash流程:
(1)计算新的hash表的size,判断要扩容还是缩容。
扩容:新size为第一个大于等于dict.ht[0].used + 1的2的n次方(不小于4)
收缩:新size为第一个大于等于dict.ht[0].used的2的n次方
(2)按照新的size申请内存空间,创建dictht,并赋值给dict.ht[1]。
(3)设置dict.rehashidx=0.标识开始rehash。
(4)每次执行新增、查询、修改、删除操作时,都检查一下dict.rehashidx是否大于-1,如果是则将dict.ht[0].table[rehashidx]的entry链表rehash到dict.ht[1],并且将rehashidx++,直至dict.ht[0]的所有数据都rehash到dict.ht[1](一次迁移一个元素,该元素只能出现在dict.ht[1]或者dict.ht[0]中)
(5)将dict.ht[1]赋值给dict.ht[0],给dict.ht[1]初始化为空哈希表,释放原来的dict.ht[0]的内存。
(6)将rehashidx赋值为-1,代表rehash结束。
(7)在rehash过程中,新增操作,则直接写入ht[1],查询、修改和删除则会在dict.ht[0]和dict.ht[1]依次查找并执行。这样可以确保ht[0]的数据只增不减,随着rehash最终为空。
ListPack
listpack 也是一种紧凑型数据结构,用一块连续的内存空间来保存数据,并且使用多种编码方式来表示不同长度的数据来节省内存空间。
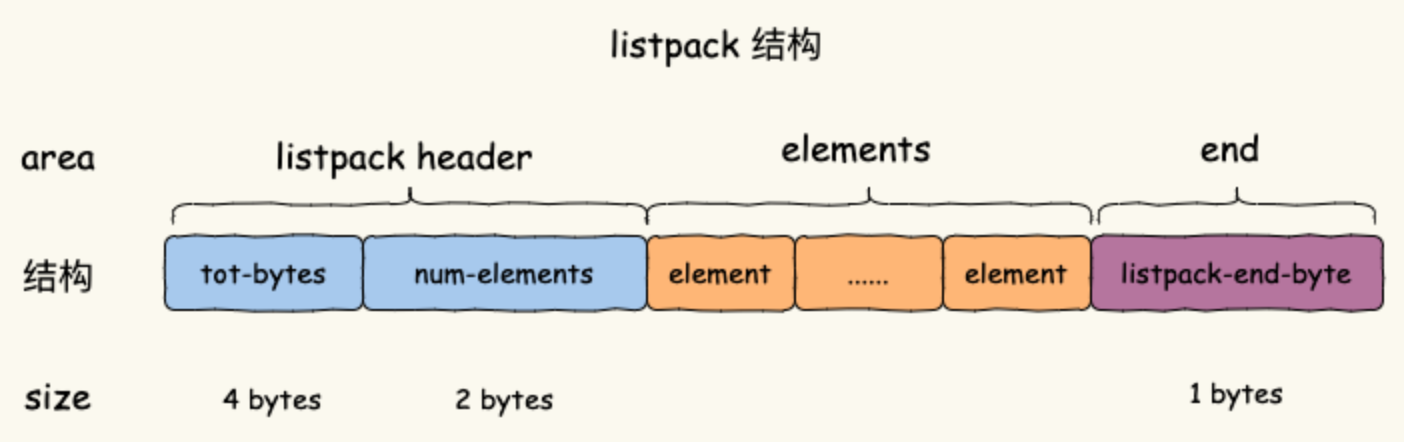
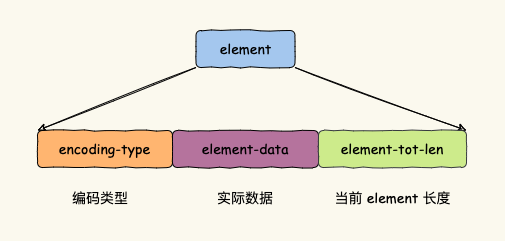
listpack 没有压缩列表中记录前一个节点长度的字段了,listpack 只记录当前节点的长度,当我们向 listpack 加入一个新元素的时候,不会影响其他节点的长度字段的变化,从而避免了压缩列表的连锁更新问题。为了节省内存的开销,listpack 节点会采用不同编码方式保存不同大小的数据。
底层实现
1.默认采用ZipList编码,节省内存空间,ZipList相邻两个entry分别保存field和value。7.0 版本的时候使用 listpack 取代 ziplist。
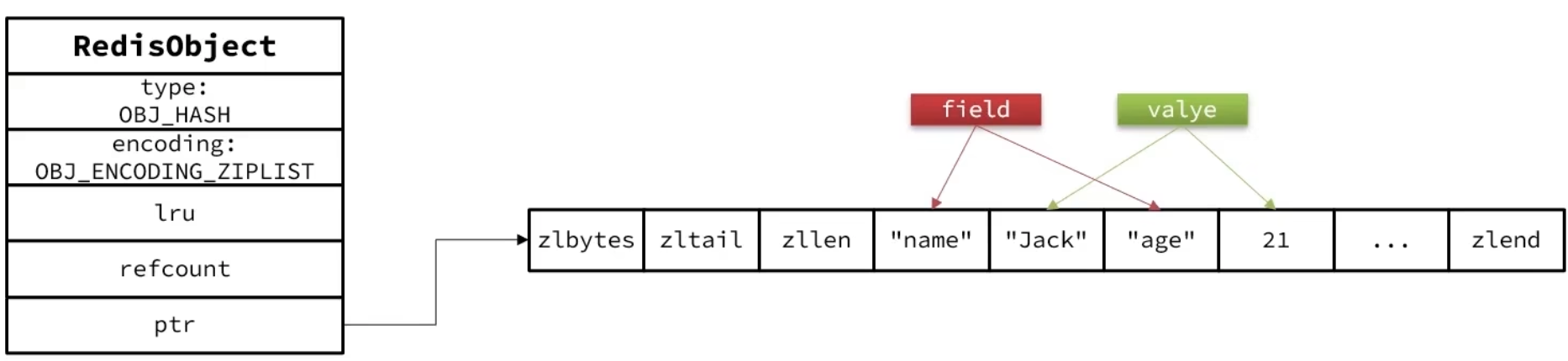
2.当数据量较大时,Hash结构会转为HT编码,也就是Dict,出发条件为:(1)ZipList中的元素数量超过了hash-max-ziplist-entries(默认512)(2)ZipList中的任意entry大小超过了hash-max-ziplist-value(默认64字节)。
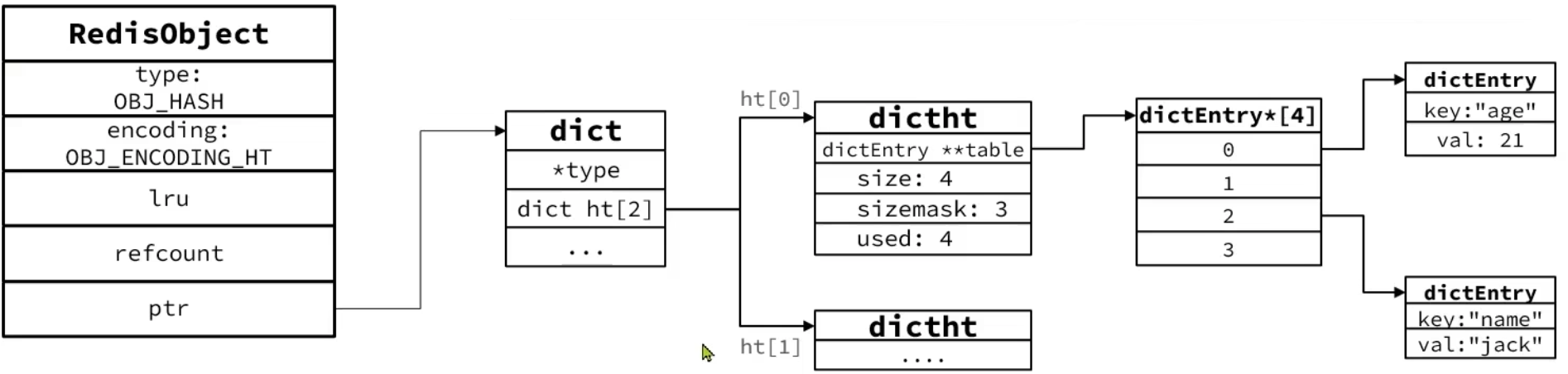
基于字典(dict)结构,采用链地址法解决哈希冲突。
四、集合(Set)
无序且元素唯一,用于去重、标签系统等。
命令
SADD key member [member ...]//向集合添加一个或多个成员
SMEMBERS key//返回集合中的所有成员
SISMEMBER key member//判断member元素是否是集合key的成员
SREM key member [member ...]//移除集合中一个或多个成员
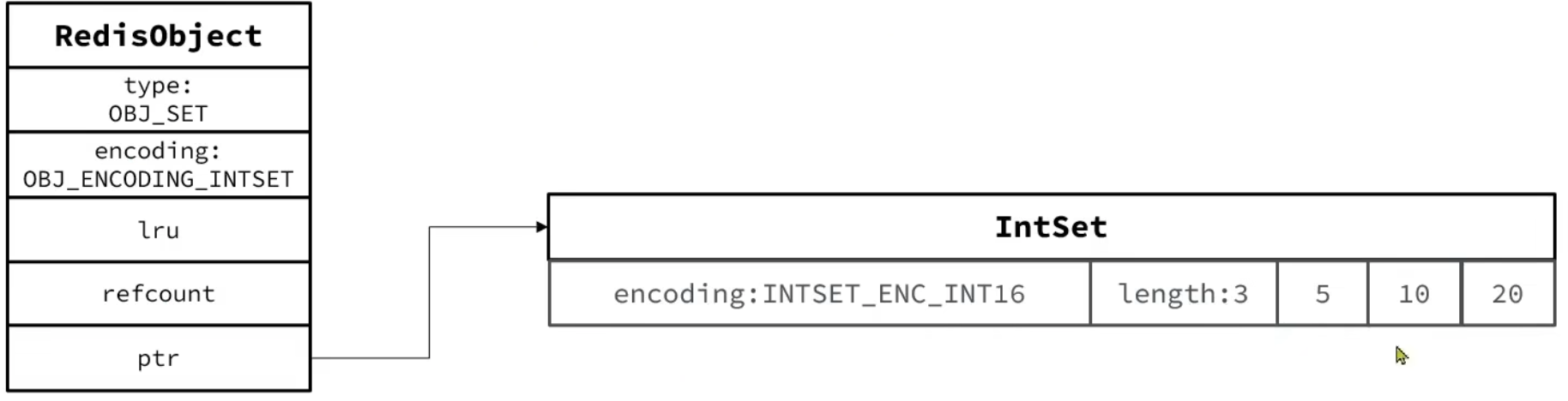
IntSet
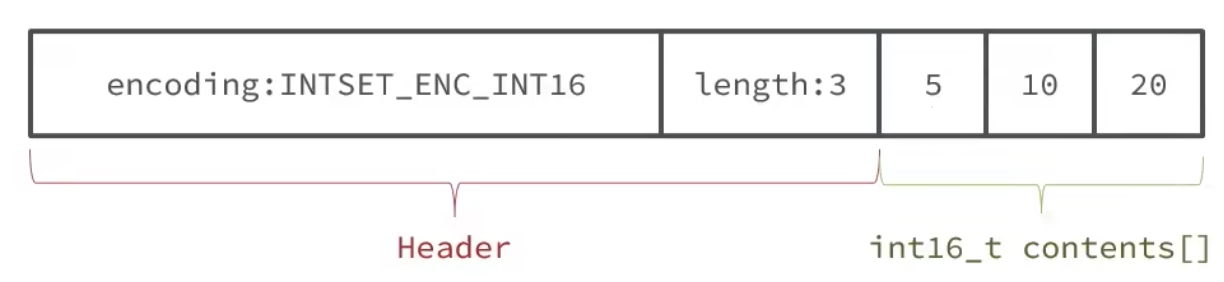
IntSet升级
(1)升级编码为INTSET_ENC_INT32,每个整数占4字节,并按照新的编码方式及元素个数扩容数组。
(2)倒序一次将数组中的元素拷贝到扩容后的正确位置。
(3)将待添加的元素放入数组末尾。
(4)最后将intset的encoding属性改为INTSET_ENC_INT32,将length属性改为4。


底层实现
1.Hash Table
为了查询效率和唯一性,set采用HT编码(Dict),dict中的key用来存储元素,value统一为null。
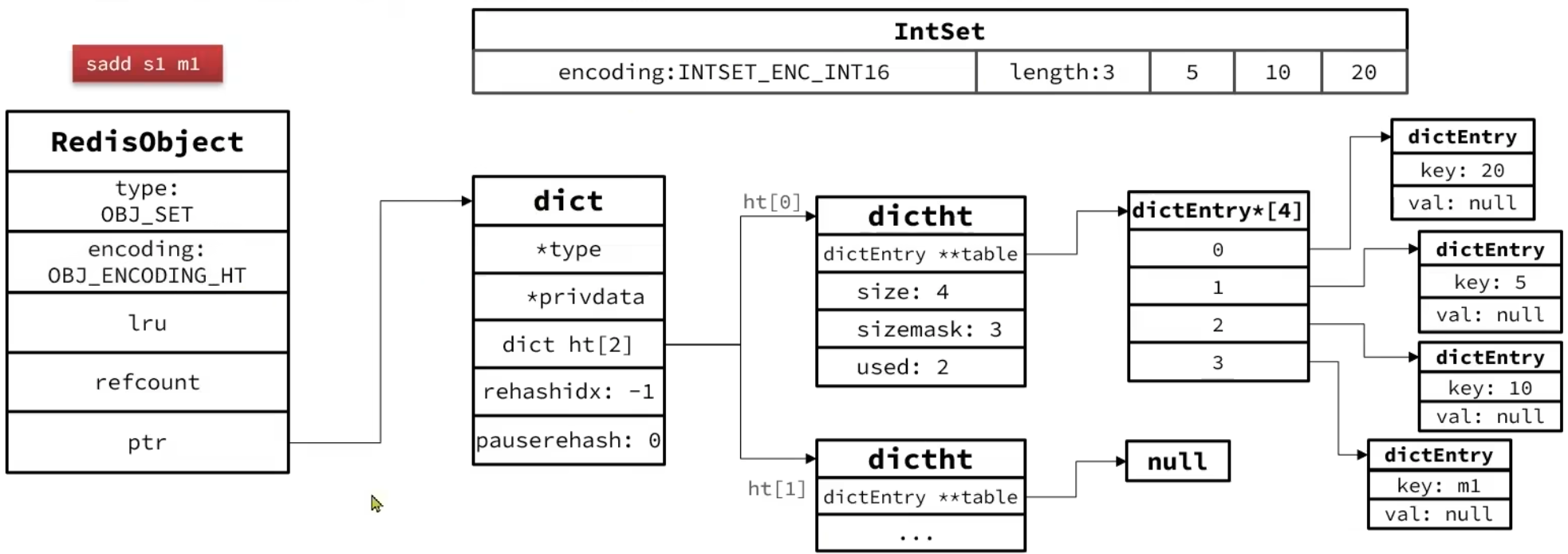
2.IntSet
当存储的所有数据都是整数,并且元素数量不超过set-max-intset-entries时,set会采用IntSet编码,以节省内存。
五、有序集合(ZSet)
元素按分数排序,支持范围查询,适用于排行榜等场景。
命令
ZADD key score member [score member ...]//向有序集合添加一个或多个成员,或者更新已存在成员的分数
ZRANGE key start stop//通过索引区间返回有序集合指定区间内的成员
ZRANK key member//返回有序集合中指定成员的索引跳表(skipList)
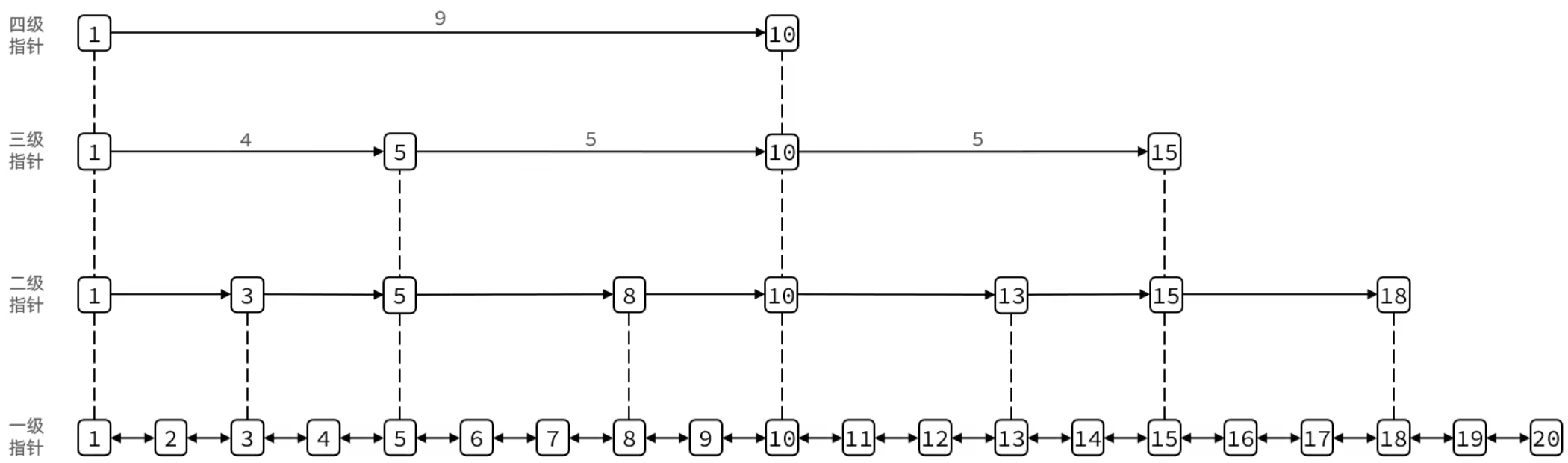
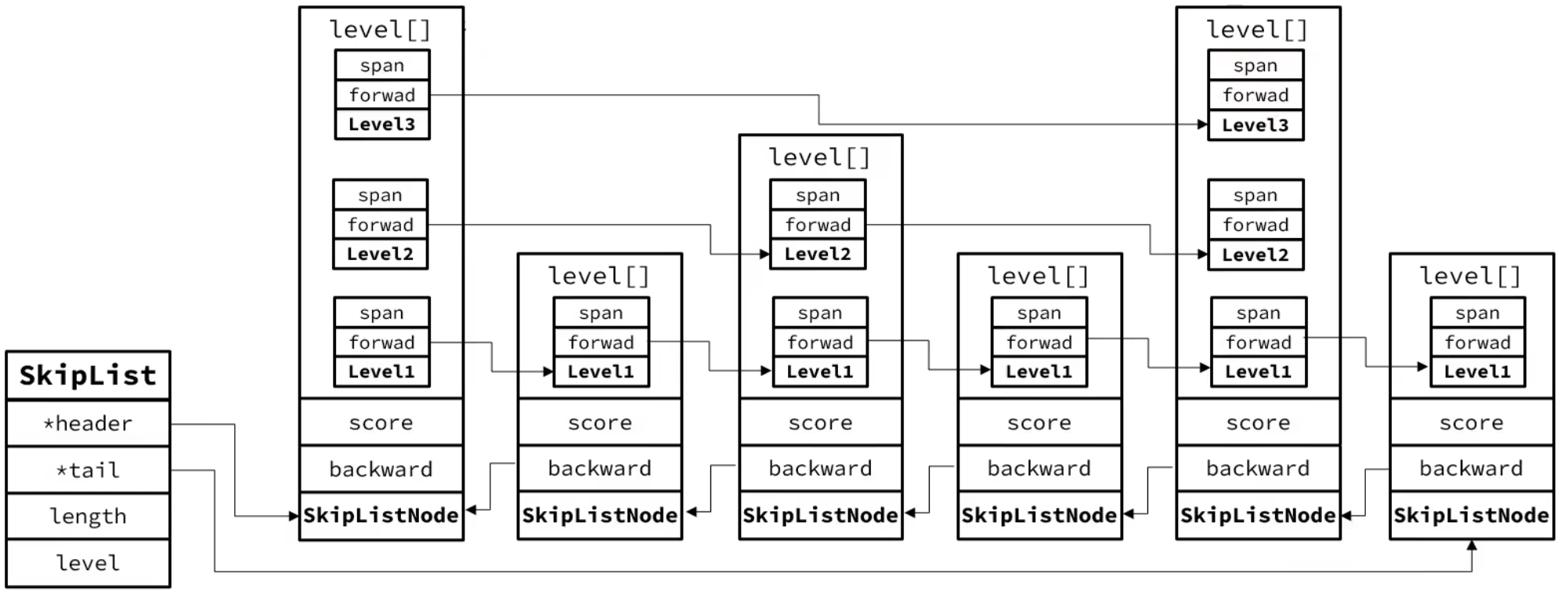
跳跃表是一个双向链表,每个节点都包含score和element值
节点按照score值排序,score值一样则按照element字典排序
每个节点可包含多层指针,层数是1~32之间的随机数
不同层指针到下一个节点的跨度不同,层级越高,跨度越大
增删改查效率与红黑树基本一致,实现却更简单
底层实现
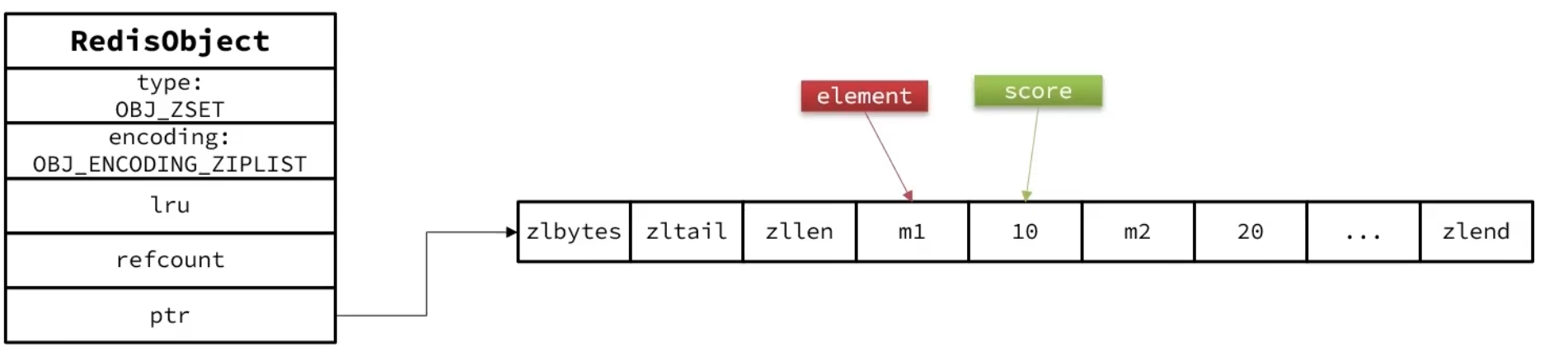
1.zipList
满足条件:
(1)元素数量小于zset_max_ziplist_entries,默认值128
(2)每个元素都小于zset_max_ziplist_value字节,默认值64
ziplist本身没有排序功能,而且没有键值对的概念,因此需要有zset通过编码实现:
ZipList是连续内存,因此score和element是紧凑在一起的两个entry,element在前,score在后
score越小越接近首,score越大越接近尾,按照score值升序排列
2. 跳表+哈希表
结合跳跃表(skiplist)和哈希表实现高效排序与查找。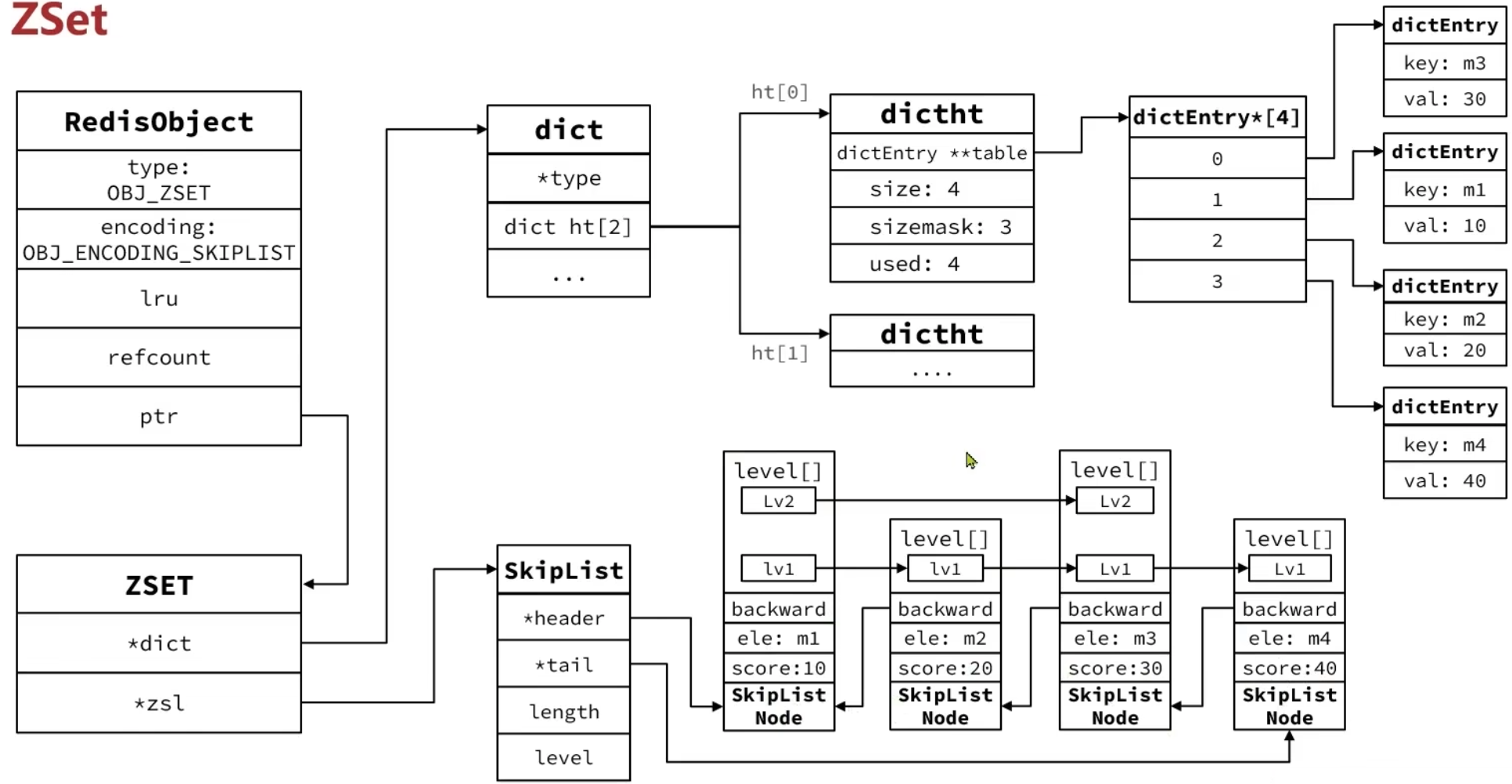
参考:【黑马程序员Redis入门到实战教程,深度透析redis底层原理+redis分布式锁+企业解决方案+黑马点评实战项目】 https://www.bilibili.com/video/BV1cr4y1671t/?p=151&share_source=copy_web&vd_source=554f6cfaea00d504c732eb9b35cd6e8b

魔乐社区(Modelers.cn) 是一个中立、公益的人工智能社区,提供人工智能工具、模型、数据的托管、展示与应用协同服务,为人工智能开发及爱好者搭建开放的学习交流平台。社区通过理事会方式运作,由全产业链共同建设、共同运营、共同享有,推动国产AI生态繁荣发展。
更多推荐


 35
35 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)