CVPR 2025 Highlight | 超大幅面的遥感多模态大模型评测与训练
此外,该评测集还特别设计了变化检测任务,充分体现了对遥感图像时空信息的建模能力,即通过前后两幅高分辨率影像,考察模型对时序变化的理解与判断能力。AI TIME源起于2019年,旨在发扬科学思辨精神,邀请各界人士对人工智能理论、算法和场景应用的本质问题进行探索,加强思想碰撞,链接全球AI学者、行业专家和爱好者,希望以辩论的形式,探讨人工智能和人类未来之间的矛盾,探索人工智能领域的未来。同时,我们也设
点击蓝字

关注我们
AI TIME欢迎每一位AI爱好者的加入!

点击 阅读原文 观看作者讲解回放!
个人信息
作者:王奉祥,国防科技大学博士生
项目简介
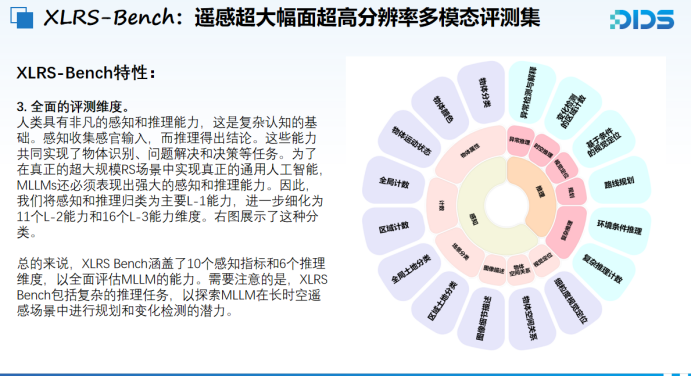
多模态大语言模型(MLLMs)的突破性进展促使研究者亟需构建新的评测基准,以定量评估其能力、揭示其局限性,并指明未来的研究方向。然而,在遥感(RS)场景下实现这一目标仍面临诸多挑战,因为遥感图像具有超高分辨率,并蕴含极为复杂的语义关系。现有评测基准通常采用远小于真实遥感场景的图像尺寸,标注质量有限,且评估维度不够全面。为解决上述问题,本文提出了 XLRS-Bench:一个用于评估多模态大模型在超高分辨率遥感场景中感知与推理能力的综合性基准。XLRS-Bench 拥有迄今为止最大平均图像尺寸(8500×8500),所有评估样本均由人工精细标注,并辅以创新的半自动化超高分辨率遥感图像描述工具。在此基础上,我们定义了16个子任务,用以评估模型的10类感知能力与6类推理能力,重点关注有助于真实决策与时空变化理解的高级认知过程。多种通用及遥感领域专用的多模态模型在 XLRS-Bench 上的评测结果表明,当前模型距满足真实遥感应用的需求仍存在显著差距。我们已将 XLRS-Bench 开源,以支持遥感多模态大模型研究的持续推进。
论文链接:
https://arxiv.org/pdf/2503.23771
代码链接:
https://xlrs-bench.github.io/
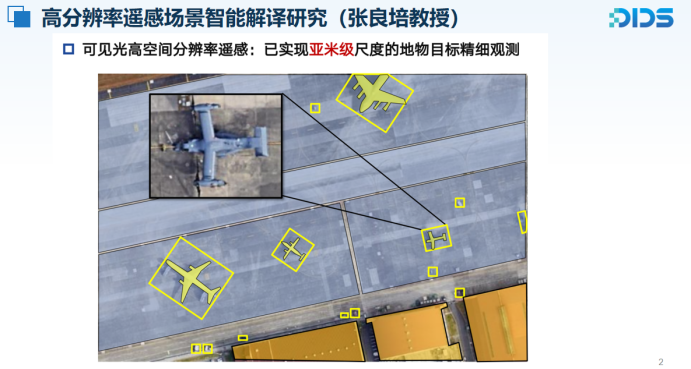
目前,高分辨率遥感影像已经能够实现亚米级别的精细目标观测,使得地物的详细结构得以直接呈现。依托于这一能力,遥感影像在高精度地物目标提取、灾害评估以及城市地图制作等多个领域已得到广泛应用,并展现出较强的实用性与前景。
在此基础上,张良培教授提出了自然图像解译与遥感图像解译之间的根本区别:自然图像的处理以视觉语义理解为核心,而遥感图像的解译则以地表信息测量为中心。这一根本差异揭示了遥感图像解译在目标和方法论上的独特性,也构成了其与通用图像领域的重要分界。
基于上述认知,目前在遥感领域推动多模态大模型的发展仍面临诸多挑战。首先是超大幅面数据的处理问题。以开源的SAR影像数据集为例,其覆盖区域可达1万平方公里,原始影像尺寸通常达到1万×1万像素。例如,在一张原始影像中,通过两次局部放大后可观察到一艘船只。理想的处理方式应是在无需人工切片的前提下,模型能够直接对整幅影像中的目标进行分析与理解,而非将其预先裁剪成若干小块再分别输入模型进行 grounding 或视觉问答(VQA)等任务,这种做法违背了遥感领域对于整体感知与推理能力的基本需求。
另一个典型场景是地震灾害的遥感评估任务。在此类任务中,卫星每次获取的影像可能高达2万×2万像素,任务目标是对整幅影像中的受灾建筑、人员分布等情况进行全面判断与评估。目前主流大模型普遍仅能处理尺寸在2000×2000像素以内的图像,常规方法需将大图切割为512×512或类似大小的小图块后进行分析。然而,从遥感实际需求出发,更理想的方式是能够直接处理整幅大图,实现端到端的整体性理解。

当前多模态模型在遥感领域的应用仍主要集中于中低分辨率影像。以传统目标检测任务DOTA为例,其所使用的最低分辨率影像为4096×4096像素,而目前主流多模态模型的训练与评测数据大多采用512×512像素的切片图像。这种切片方式与完整大图在信息密度和表达能力上存在数量级的差异,难以有效支撑真实遥感场景中的下游任务。因此,现有遥感多模态模型的发展面临着与实际应用脱节的问题,亟需向更加贴近实际任务需求的评测机制过渡。
基于上述考虑,我们构建了一个新型评测集,并在构建过程中识别出当前遥感多模态模型评测中存在的三个主要问题。首先,现有评测集普遍采用512×512像素图像作为输入,极少数样本尺寸达到1000像素以上,但传统遥感目标检测任务普遍在4000像素级别,而分割任务甚至常见于10000像素以上的分辨率。这使得现有多模态模型的评估结果无法有效映射到遥感领域长期以来研究的下游任务上,造成评测体系与应用需求之间的断层。
其次,遥感视觉-语言问答对的构建成本极高,若在标注过程中大量依赖GPT等生成式工具辅助,虽可提升效率,但也可能导致数据集生命周期缩短。例如当前部分模型在已有数据集上已可达到60%–70%的准确率,模型对数据集的快速拟合将使评测效果很快失去区分度与挑战性,降低其在未来研究中的持续价值。
第三,现有评测集在能力考察上仍以感知能力为主,对推理能力的测评尚不充分。因此,我们尝试进一步拓展模型在互动感知与复杂推理任务上的评估能力。例如,在输入超大幅面遥感图像后,用户可通过交互方式(如画红圈)聚焦特定区域,并提出如“该区域内有多少艘船只”等问题。在此过程中,船只在图像中往往仅占据1至2个像素的极小空间,模型需具备极高的感知精度与区域定位能力。同时,我们也设计了涉及物体间相对位置关系的问题,这些任务考察的是模型在超大图像中对微小目标之间空间结构的细致理解。

此外,评测任务还包含全局统计类问题,如对图像中所有车辆、建筑物或特定物种进行全面计数。在某些样本中,船只总数可达40至49艘,需标注人员逐一核查,耗时较长。同时,我们也设计了针对环境推理和异常检测(如道路堵塞、水患预测)等任务,进一步评估模型的逻辑推理与路径规划能力。在标注过程中,即使由具备本科学历的熟练标注员完成一张图像中13至16个任务样本的标注,也需耗费3至4小时。整个评测集的构建过程投入了大量人力资源和质检工作。
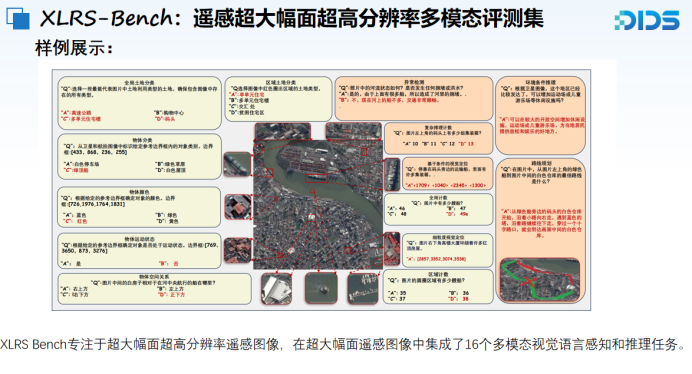
我们进一步展示了该评测集在遥感领域中的核心优势,首要体现在其所支持的超大幅面图像分辨率。正如前文所述,在真实应用场景中,处理超大幅面遥感影像是当前亟需解决的关键问题。本评测集在图像分辨率上达到了现有MME-RealWorld数据集的24倍,包含了840张分辨率为10000×10000像素的大幅面图像。此外,该评测集还特别设计了变化检测任务,充分体现了对遥感图像时空信息的建模能力,即通过前后两幅高分辨率影像,考察模型对时序变化的理解与判断能力。由于此类任务本身极具复杂性,即使经验丰富的标注人员在标注过程中也容易出错,因此我们采用了多轮质检机制,确保每一项标注均经过重复确认与审核,以保障整体标注质量的可靠性与一致性。

本评测集共构建了三种主要任务形式,分别为图像字幕生成(caption)、图像定位(grounding)和视觉问答(VQA),以支持多模态模型在不同任务下的全面评估。在标注流程方面,caption任务采用半自动化标注工具结合人工修订,以实现对图像内容的高质量描述;而grounding与VQA任务则由人工完成标注、自检及后续抽检,确保数据的准确性与高可信度。
在评测维度方面,该评测集覆盖了16个基础能力指标,具体包括10项感知指标与6项推理指标,基本构成了对遥感多模态模型处理超大幅面影像能力的初步全面评估体系。值得特别指出的是,该评测集中的图像描述任务明显区别于以往的通用图文caption。我们的描述方式更加贴合遥感实际需求,采取“从整体到局部”的结构化表达方式,首先对整幅图像进行全局描述,如影像中部是否存在河流、两侧是否为山地等环境信息,然后将图像划分为九个子区域,对每个子图中的地物目标进行细粒度描述。
最后,这些图像描述与前述针对该图像的VQA问题共同构成了对单幅遥感影像的全面解析与汇报,涵盖了目标识别、数量统计、空间关系、异常变化等多方面内容,并结合实际场景需求对潜在风险进行初步研判。因此,我们认为该类caption任务的设计更加符合遥感图像在真实使用场景中的应用需求,远非传统简单的图文对任务所能涵盖。

在遥感影像中,物体的运动状态是一项具有研究价值的特征。以船只为例,其是否处于运动状态通常可通过尾流信息进行判断:若船只后方存在明显尾流,则可推断其正处于运动状态。我们在构建评测集时亦特意筛选并纳入了部分此类具有运动特征的样本,供模型通过图像上下文线索进行识别与判别。
关于视觉定位任务,由于高分辨率遥感图像中许多目标(如船只)在整幅图像中仅占据5至10个像素,若将原始分辨率为10000×10000的图像压缩至多模态模型普遍支持的2000×2000尺寸,将导致目标信息在最终图像中仅保留1至2个像素,从而造成严重的信息损失,尤其是关键细节的丢失。因此,我们认为遥感领域亟需发展能够原生支持大幅面图像处理的多模态大模型体系。同时,我们还展示了评测集中所涵盖的时空推理任务,强调这是遥感影像独有的能力要求。该任务聚焦于对大尺度图像中随时间演化的地物变化的理解和推理,进一步凸显遥感数据在时序建模上的独特挑战。
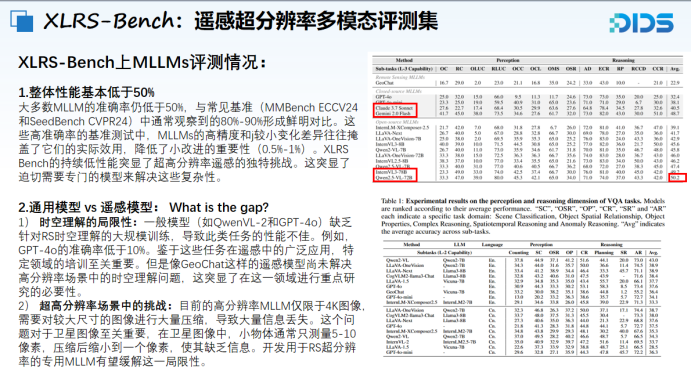
目前,我们在该评测集上对InternVL3-78B和Qwen2.5-VL-72B等最新多模态模型进行了评估,结果显示其准确率普遍低于50%,表明本评测集具有较强的挑战性,同时也体现出推动该领域技术发展的必要性与紧迫性。
关于后续工作,我们初步思考了两个训练大规模遥感多模态模型面临的核心限制:其一是缺乏超高分辨率的遥感图像数据,其二是视觉Token序列过长,导致训练难度大幅上升。虽然目前已有多种视觉Token压缩策略,我们在此不再赘述,但我们在工作中针对遥感图像的特性进行了更进一步的分析。
我们的前期消融实验表明,遥感图像普遍存在“低语义密度”的问题,主要体现在两个方面。首先,视觉编码器会生成大量冗余的虚拟Token,这些Token大多属于背景区域,既不包含语义信息,反而会对模型建模造成干扰。我们通过语义检索和可视化分析发现,例如在大面积海面区域中,仅有1至2个Token具备有效语义,其余Token多为噪声。
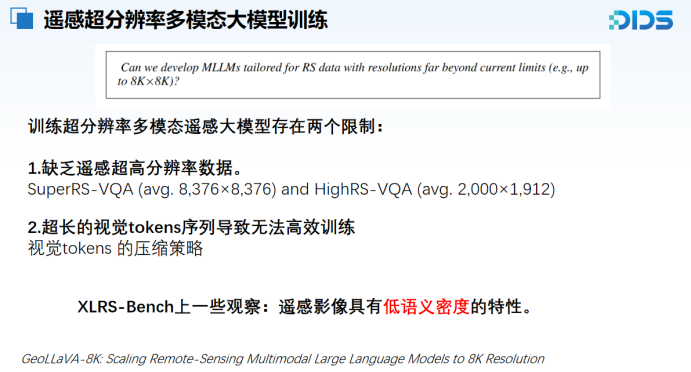
进一步实验发现,这些冗余背景Token的存在不仅没有为模型性能带来提升,甚至会抑制模型表现。以LLaVA-Next系列模型为例,若直接处理2K分辨率图像,在使用默认Pooling层的条件下会导致显存和梯度的爆炸;而通过提高Pooling压缩比可勉强完成训练,但若在此基础上进一步采用语义筛选方法,去除掉约一半的无效背景Token,我们观察到模型在多个评测指标上反而出现了性能提升。这一结果提示,背景Token在遥感多模态任务中可能具有“负贡献”,其适当剔除对模型训练具有正向作用。

此外,我们还借鉴了ICLR 2025的一项研究,对遥感图像中目标Token的重要性进行了分析,探索其在图像建模中的作用与分布特征。我们在LLaVA-Next系列模型上进行了初步验证,为今后进一步挖掘遥感数据的语义结构提供了基础依据。

近期精彩活动
关于AI TIME
AI TIME源起于2019年,旨在发扬科学思辨精神,邀请各界人士对人工智能理论、算法和场景应用的本质问题进行探索,加强思想碰撞,链接全球AI学者、行业专家和爱好者,希望以辩论的形式,探讨人工智能和人类未来之间的矛盾,探索人工智能领域的未来。
迄今为止,AI TIME已经邀请了2000多位海内外讲者,举办了逾800场活动,超1000万人次观看。

我知道你
在看
提出观点,表达想法,欢迎
留言

点击 阅读原文 观看作者讲解回放!

魔乐社区(Modelers.cn) 是一个中立、公益的人工智能社区,提供人工智能工具、模型、数据的托管、展示与应用协同服务,为人工智能开发及爱好者搭建开放的学习交流平台。社区通过理事会方式运作,由全产业链共同建设、共同运营、共同享有,推动国产AI生态繁荣发展。
更多推荐



 0
0 0
0- 0



 已为社区贡献76条内容
已为社区贡献76条内容

所有评论(0)