Qwen-VL系列微调/推理/部署
可以直接用示例中的demo数据, 自己下载的数据也需要按照此格式组织好。
官方代码仓: https://github.com/QwenLM/Qwen3-VL
一、环境配置
git clone https://github.com/QwenLM/Qwen3-VL.git
cd Qwen3-VL-main
pip install qwen-vl-utils[decord]
pip install "transformers>=4.57.0"
中间训练缺库再安装即可
二、训练微调
2.1 数据准备
1. 数据集配置
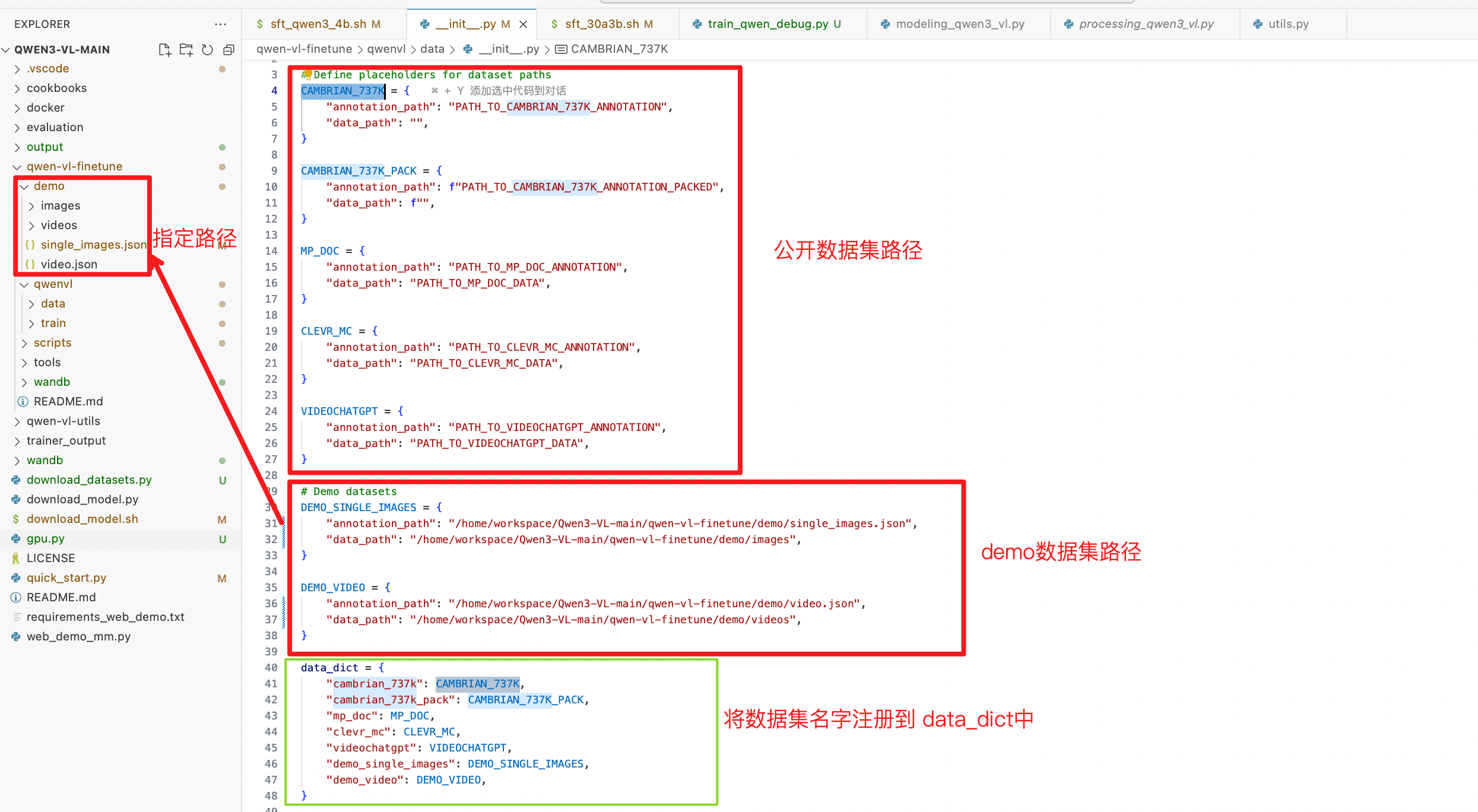
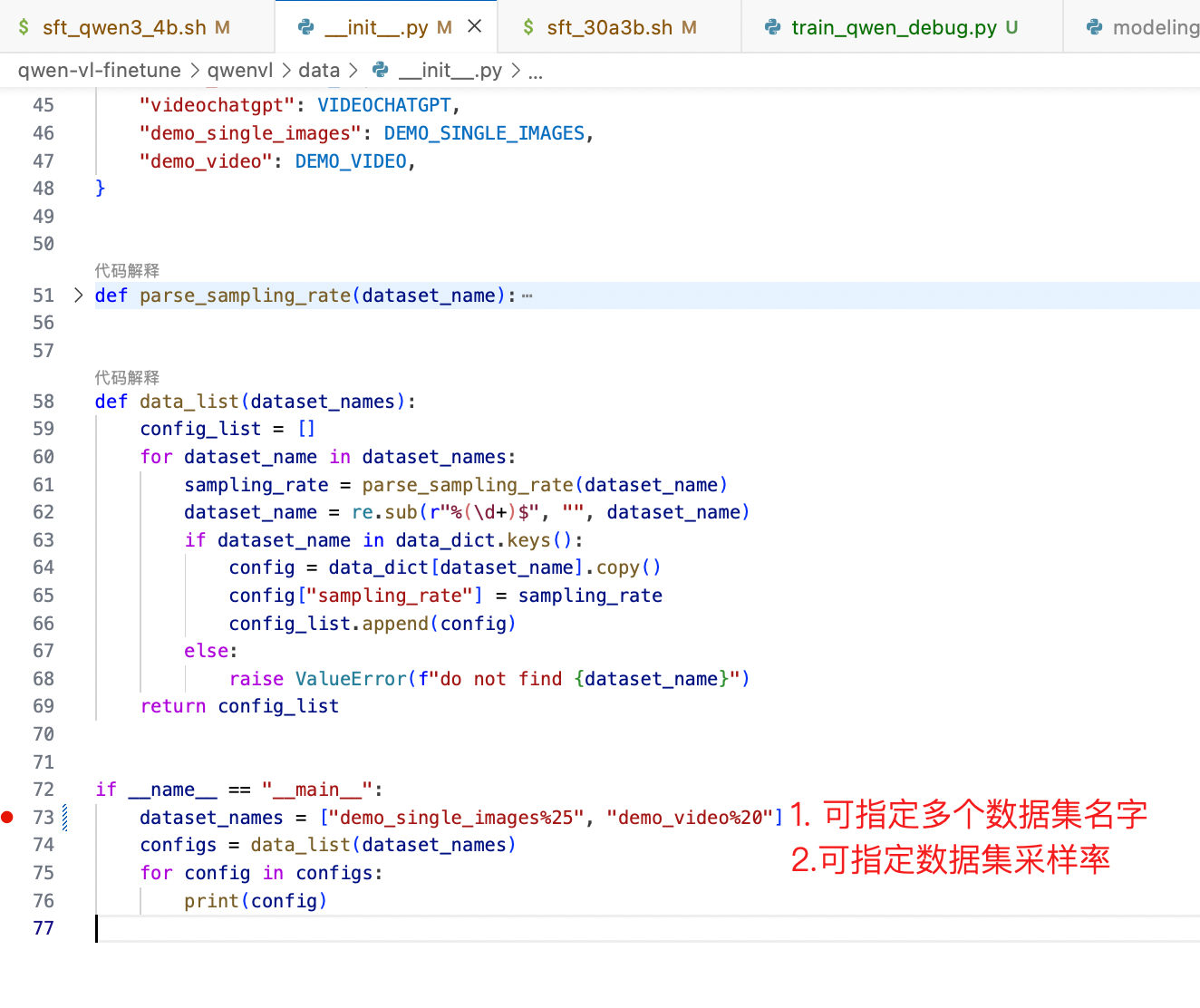
2. 使用自定义的数据集
可以直接用示例中的demo数据, 自己下载的数据也需要按照此格式组织好。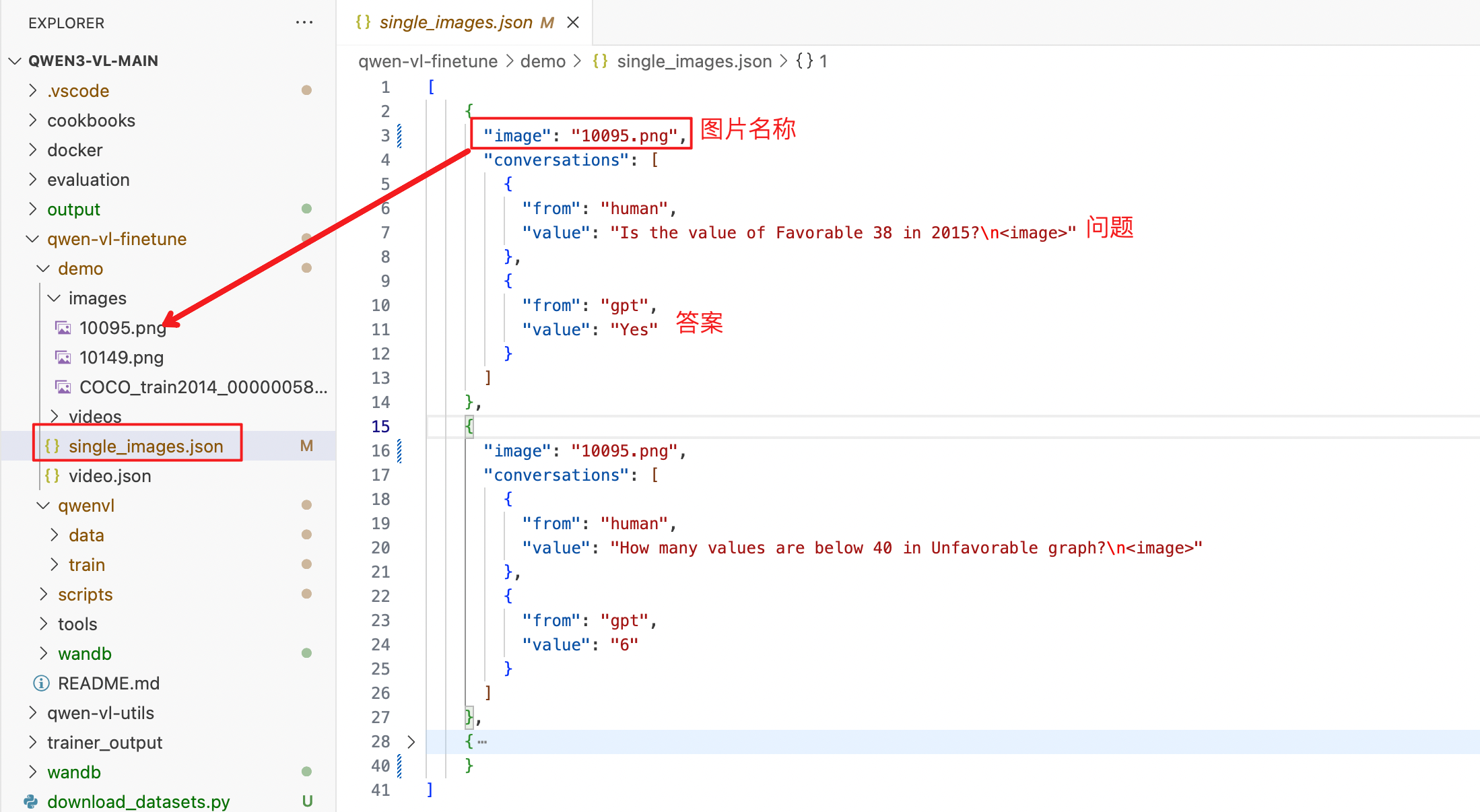
3. 使用公开数据集
huggingface 有很多公开的数据集,可以下载使用
下载脚本
from datasets import load_dataset
ds = load_dataset("mlabonne/FineTome-100k", cache_dir="/root/data") # 指定下载的路径
2.2 下载模型
先安装 modelscope
pip install modelscope
下面的脚本任选一个即可,注意指定下载的模型名字 和本地的下载路径
- python脚本
from modelscope import snapshot_download
model_dir = snapshot_download('Qwen/Qwen3-VL-2B-Instruct')
- 命令行
modelscope download --model Qwen/Qwen2.5-VL-7B-Instruct --local_dir /root/Qwen/Qwen2.5-VL-7B-Instruct
2.3 修改配置文件
微调的脚本在 qwen-vl-finetune/scripts/*.sh, 根据自己的电脑GPU配置情况修改脚本
# sft_7b.sh
#!/bin/bash
# Distributed training configuration
MASTER_ADDR=${MASTER_ADDR:-"127.0.0.1"}
MASTER_PORT=${MASTER_PORT:-$(shuf -i 20001-29999 -n 1)}
NNODES=${WORLD_SIZE:-1}
NPROC_PER_NODE=1 # 单个计算节点(机器)上启动的并行进程数量,通常等于该节点上可用的GPU数量
# DeepSpeed configuration
deepspeed=./scripts/zero3_offload.json # 最节省显存的配置
# Model configuration 下载好的模型路径
llm=/root/Qwen/Qwen2.5-VL-7B-Instruct # Using HuggingFace model ID
# Training hyperparameters
lr=2e-7
batch_size=4
grad_accum_steps=4
# Training entry point 训练入口脚本
entry_file=qwenvl/train/train_qwen.py
# Dataset configuration (replace with public dataset names)
# datasets=public_dataset1,public_dataset2
datasets=demo_single_images # 指定数据集名字,这个就是在__init__中注册过的数据集名字
# datasets=demo_single_images,demo_video # 指定多个数据集名字
# Output configuration
run_name="qwen2vl-baseline"
output_dir=./output
# Training arguments
args="
--deepspeed ${deepspeed} \
--model_name_or_path "${llm}" \
--dataset_use ${datasets} \
--data_flatten True \
--tune_mm_vision False \
--tune_mm_mlp True \
--tune_mm_llm True \
--bf16 \
--output_dir ${output_dir} \
--num_train_epochs 0.5 \
--per_device_train_batch_size ${batch_size} \
--per_device_eval_batch_size $((batch_size*2)) \
--gradient_accumulation_steps ${grad_accum_steps} \
--max_pixels 50176 \
--min_pixels 784 \
--eval_strategy "no" \
--save_strategy "steps" \
--save_steps 1000 \
--save_total_limit 1 \
--learning_rate ${lr} \
--weight_decay 0 \
--warmup_ratio 0.03 \
--max_grad_norm 1 \
--lr_scheduler_type "cosine" \
--logging_steps 1 \
--model_max_length 8192 \
--gradient_checkpointing True \
--dataloader_num_workers 2 \
--run_name ${run_name} \
--report_to wandb"
# Launch training
torchrun --nproc_per_node=${NPROC_PER_NODE} \
--master_addr=${MASTER_ADDR} \
--master_port=${MASTER_PORT} \
${entry_file} ${args}
DeepSpeed三个配置文件的含义,更多关于Deepspeed的学习记录可以看这里(待更新)
2.4 SFT微调
1. LoRA微调
训练参数中加上这几个参数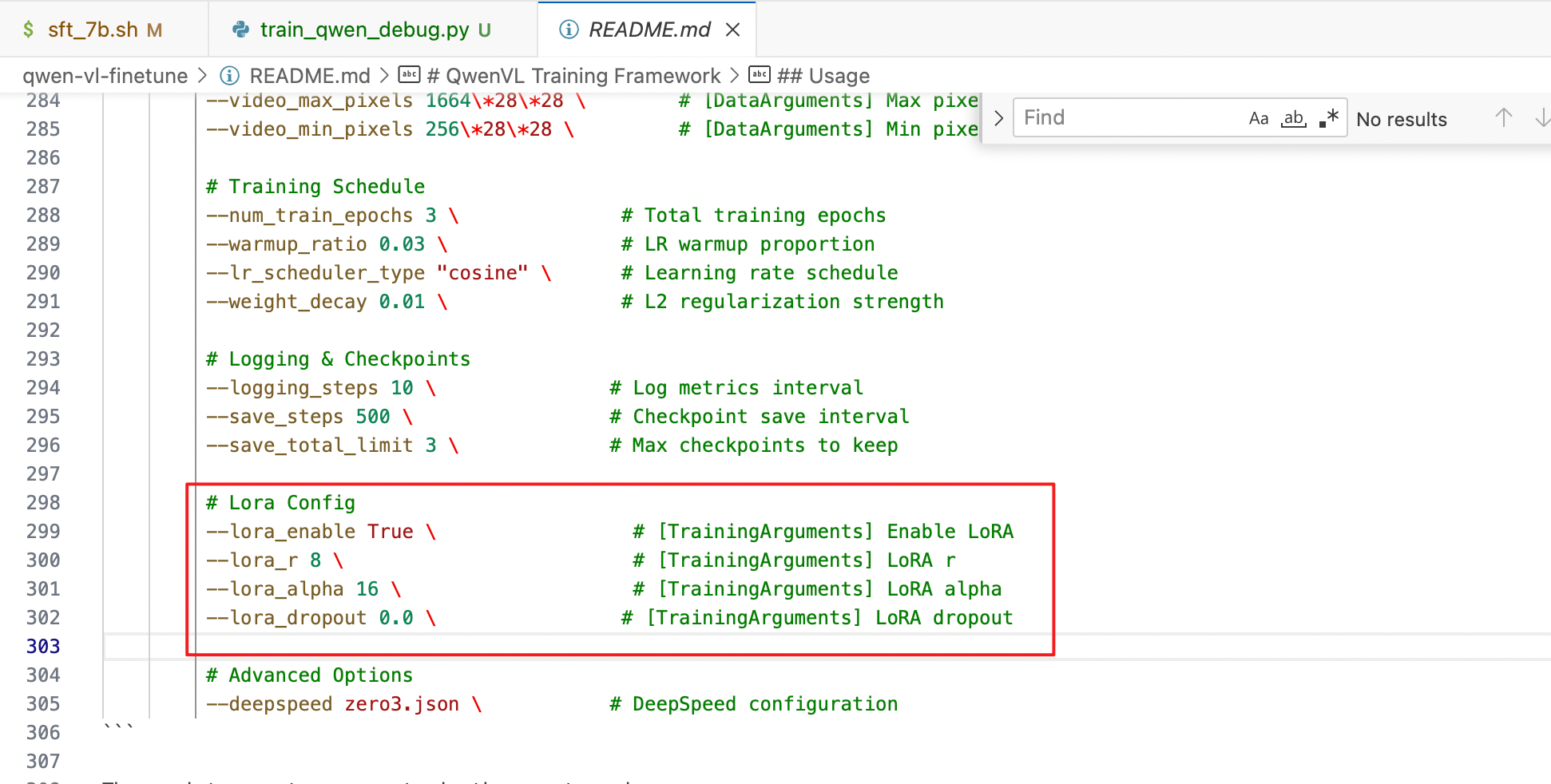
2. 全参微调
关闭lora, 设置以下几个参数, 决定哪个层冻结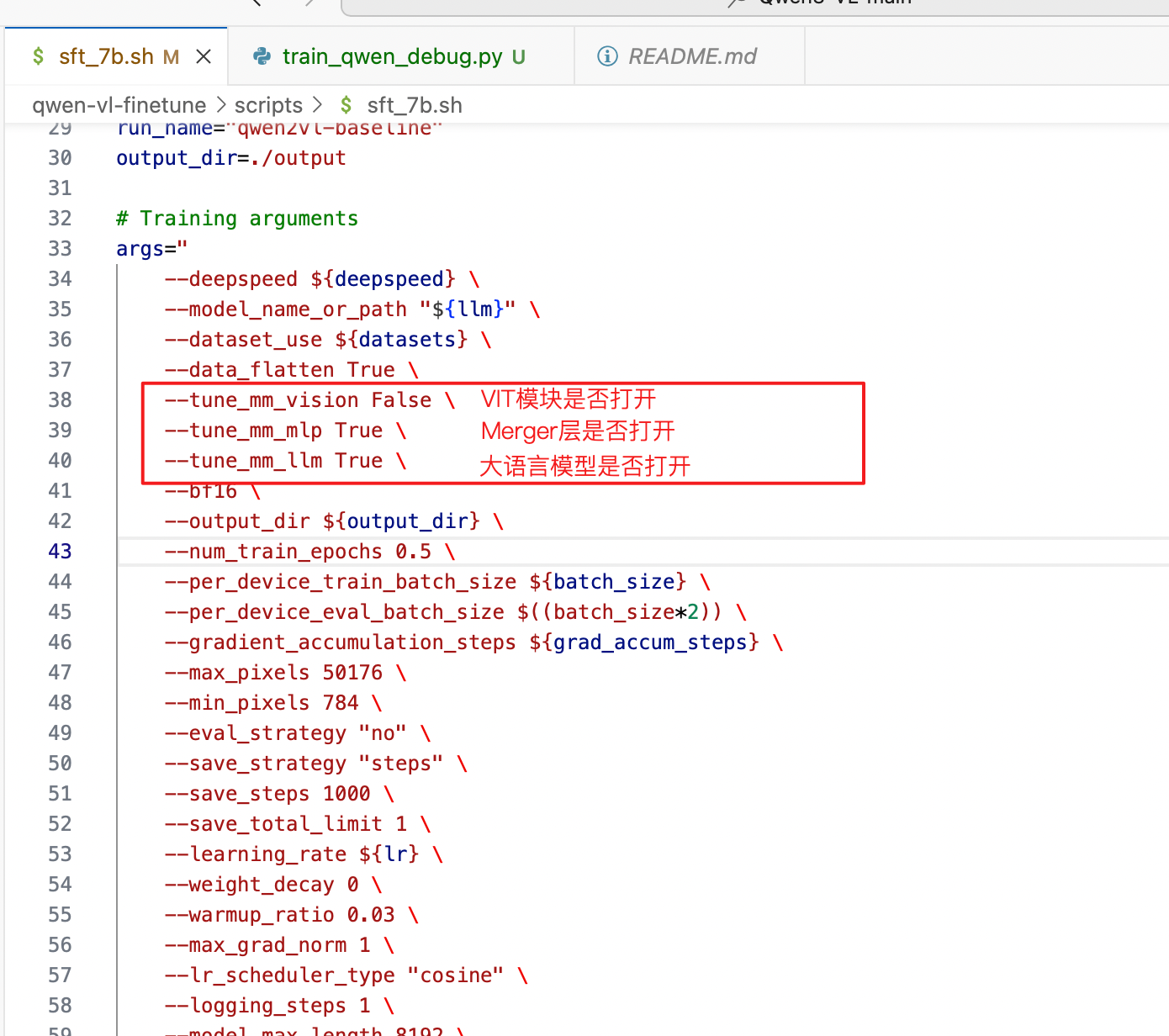
配置好后 运行 .sh文件即可训练,
训练过程中跳出来 API key , 点击终端打印出来的连接, 注册登陆一下,复制 key 后粘贴到终端, 按下 enter 即可继续训练。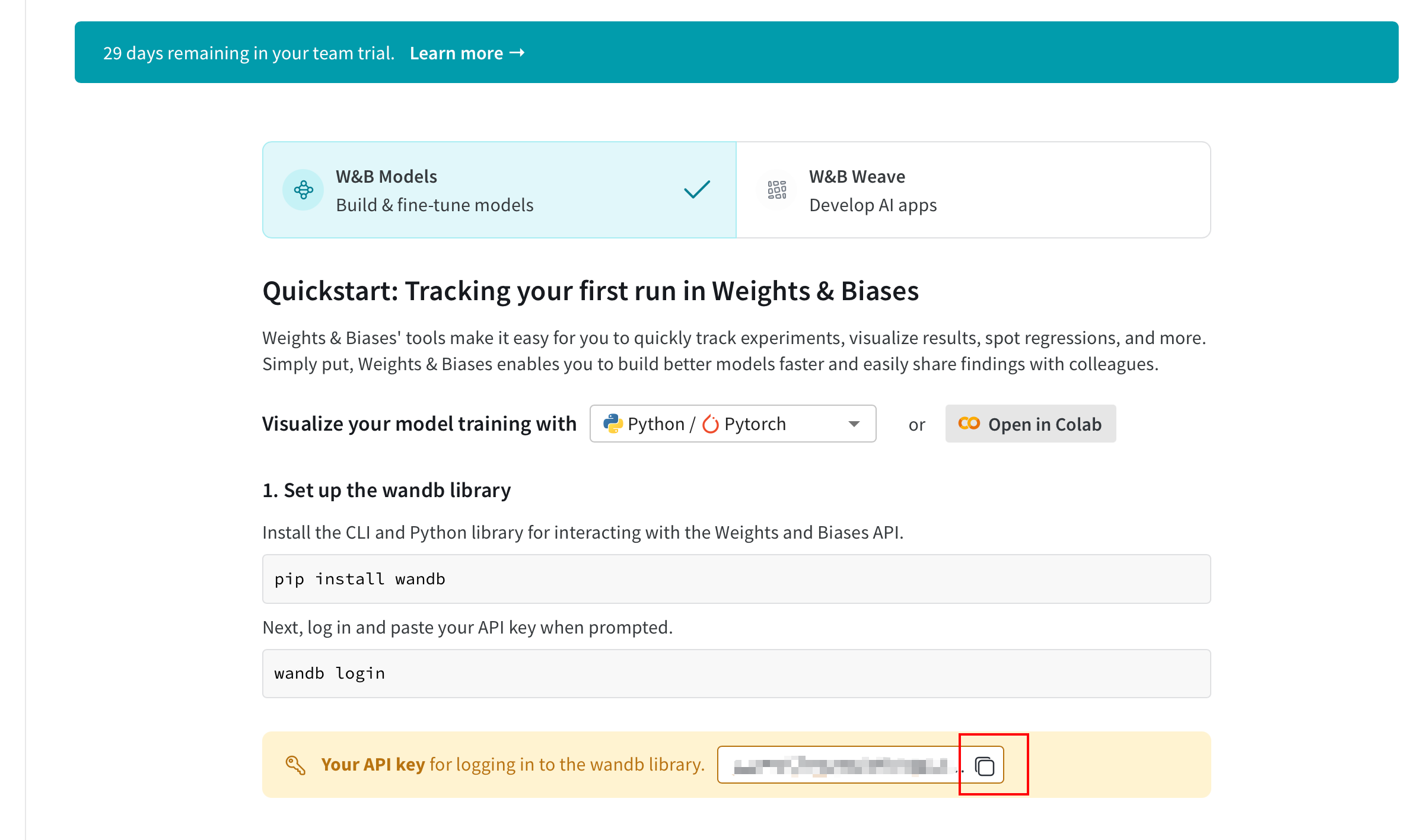
3. Loss对比
用demo数据LoRA微调的loss
用demo数据全参数微调的loss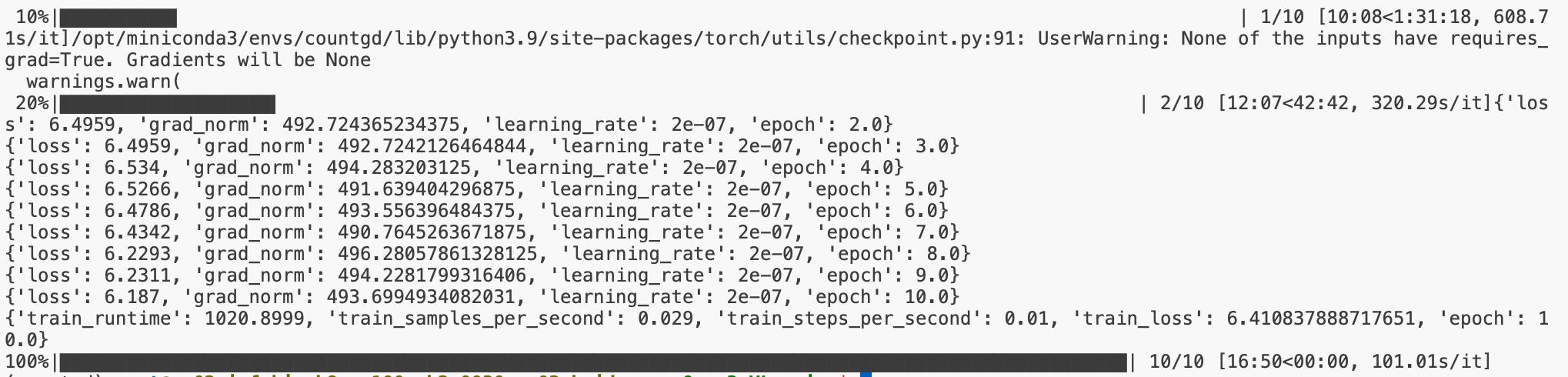
全参微调比LoRA微调的loss下降更快
2.5 强化学习微调
参考:https://github.com/OctopusMind/RLHF_PPO/tree/main
待更新
三、推理
3.1. 原始权重/LoRA微调/全参微调推理
原始权重和全参微调推理脚本
from transformers import AutoModelForImageTextToText, AutoProcessor
original_model_path = "/root/Qwen/Qwen3-VL-4B-Instruct"
model_path = "/root/Qwen/Qwen3-VL-4B-Instruct" # 原始权重路径
# model_path = "/home/workspace/Qwen3-VL-main/output/checkpoint-10" # 全参微调权重路径
# default: Load the model on the available device(s)
model = AutoModelForImageTextToText.from_pretrained(
model_path, dtype="auto", device_map="auto"
)
processor = AutoProcessor.from_pretrained(original_model_path)
messages = [
{
"role": "user",
"content": [
{
"type": "image",
"image": "https://qianwen-res.oss-cn-beijing.aliyuncs.com/Qwen-VL/assets/demo.jpeg",
},
{"type": "text", "text": "Describe this image."},
],
}
]
# Preparation for inference
inputs = processor.apply_chat_template(
messages,
tokenize=True,
add_generation_prompt=True,
return_dict=True,
return_tensors="pt"
)
inputs = inputs.to(model.device)
# Inference: Generation of the output""" """
generated_ids = model.generate(**inputs, max_new_tokens=128)
generated_ids_trimmed = [
out_ids[len(in_ids) :] for in_ids, out_ids in zip(inputs.input_ids, generated_ids)
]
# Decoding the output
output_text = processor.batch_decode(
generated_ids_trimmed, skip_special_tokens=True, clean_up_tokenization_spaces=False
)
print(output_text)
LoRA微调推理脚本
from transformers import AutoModelForImageTextToText, AutoProcessor
from peft import PeftModel
base_model_path = "/root/Qwen/Qwen3-VL-4B-Instruct"
lora_model_path = "/home/workspace/Qwen3-VL-main/output/checkpoint-10"
# 加载基础模型
base_model = AutoModelForImageTextToText.from_pretrained(
base_model_path, # 根据你的基础模型调整
dtype="auto", device_map="auto"
)
# 加载LoRA权重
model = PeftModel.from_pretrained(base_model, lora_model_path)
model = model.merge_and_unload() # 合并权重
processor = AutoProcessor.from_pretrained(base_model_path)
3.2 微调推理结果对比
推理图片
原始的Qwen3-VL-4B-Instruct推理结果:基础描述准确,能识别核心要素(女性、金毛犬、海滩场景),描述相对简洁直接,缺乏情感色彩词汇存在小错误("B eside her"中的空格问题)
LoRA微调10ep结果 :
词汇更丰富:使用"sun-drenched"等更具画面感的形容词
表达更流畅:修正了原始模型的格式错误
细节更准确:明确描述了"extending its paw to give a high-five"的具体动作
但省略了红绳细节,可能在细节捕捉上还有提升空间
全参微调10ep后的结果 :
情感描述最丰富:新增"serene"(宁静的)来形容氛围
细节最完整:明确提到了狗的红绳(red leash)
描述最细致:对狗的特征描述更加精准
结构化更好:整体描述逻辑更清晰
关键差异对比总结
4、部署
pip install accelerate
pip install vllm>=0.11.0
使用openAI兼容的服务器部署
python -m vllm.entrypoints.openai.api_server \
--model /home/workspace/Qwen3-VL-main/output/checkpoint-10 \
--served-model-name qwen3-vl-finetuned \
--host 0.0.0.0 \
--port 8000 \
--tensor-parallel-size 1 \
--gpu-memory-utilization 0.8 \
--max-num-batched-tokens 4096

魔乐社区(Modelers.cn) 是一个中立、公益的人工智能社区,提供人工智能工具、模型、数据的托管、展示与应用协同服务,为人工智能开发及爱好者搭建开放的学习交流平台。社区通过理事会方式运作,由全产业链共同建设、共同运营、共同享有,推动国产AI生态繁荣发展。
更多推荐


 4
4 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)