【清华代码熊】解析|DeepSeek大模型原生Memory论文Engram
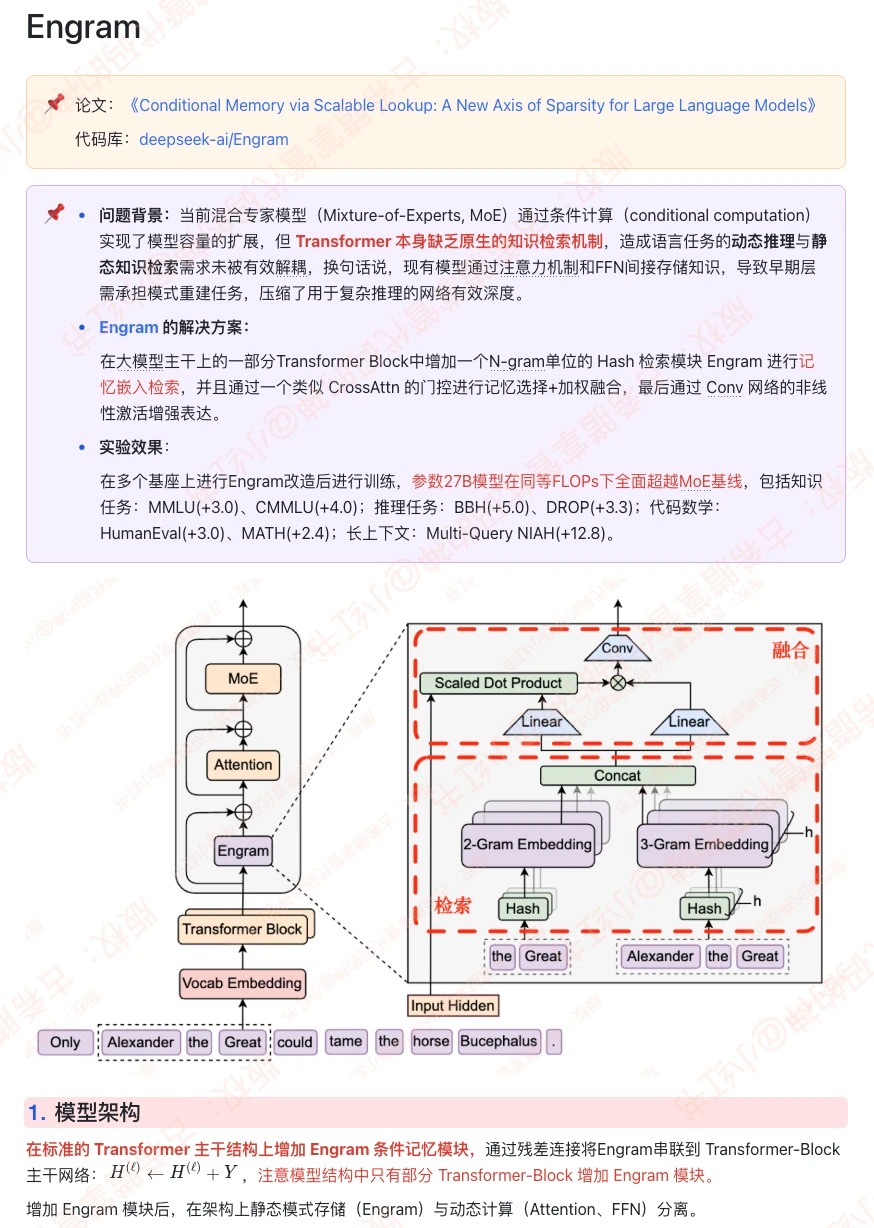
📌 今天来解析 DeepSeek 的新论文 Engram,最近 DeepSeek 频发论文,是不是要为发布模型预热📌 论文背景:当前MoE模型通过条件计算实现了模型容量的扩展,但 Transformer 本身缺乏原生的知识检索机制,造成语言任务的动态推理与静态知识检索需求未被有效解耦。🔥Engram 的解决方案:在大模型主干上的一部分Transformer Block中增加一个N-gram单
·
📌 今天来解析 DeepSeek 的新论文 Engram,最近 DeepSeek 频发论文,是不是要为发布模型预热
📌 论文背景:当前MoE模型通过条件计算实现了模型容量的扩展,但 Transformer 本身缺乏原生的知识检索机制,造成语言任务的动态推理与静态知识检索需求未被有效解耦。
🔥Engram 的解决方案:在大模型主干上的一部分Transformer Block中增加一个N-gram单位的 Hash 检索模块 Engram 进行记忆嵌入检索,并且通过一个类似 CrossAttn 的门控进行记忆选择+加权融合,最后通过 Conv 网络的非线性激活增强表达。
🎯 相关内容已经总结到下方学习笔记中,持续更新!在平台提供大模型一手、原创、深度解析!



魔乐社区(Modelers.cn) 是一个中立、公益的人工智能社区,提供人工智能工具、模型、数据的托管、展示与应用协同服务,为人工智能开发及爱好者搭建开放的学习交流平台。社区通过理事会方式运作,由全产业链共同建设、共同运营、共同享有,推动国产AI生态繁荣发展。
更多推荐


 2
2 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)