Triton + TensorRT 推理模型部署
一、大模型研发流程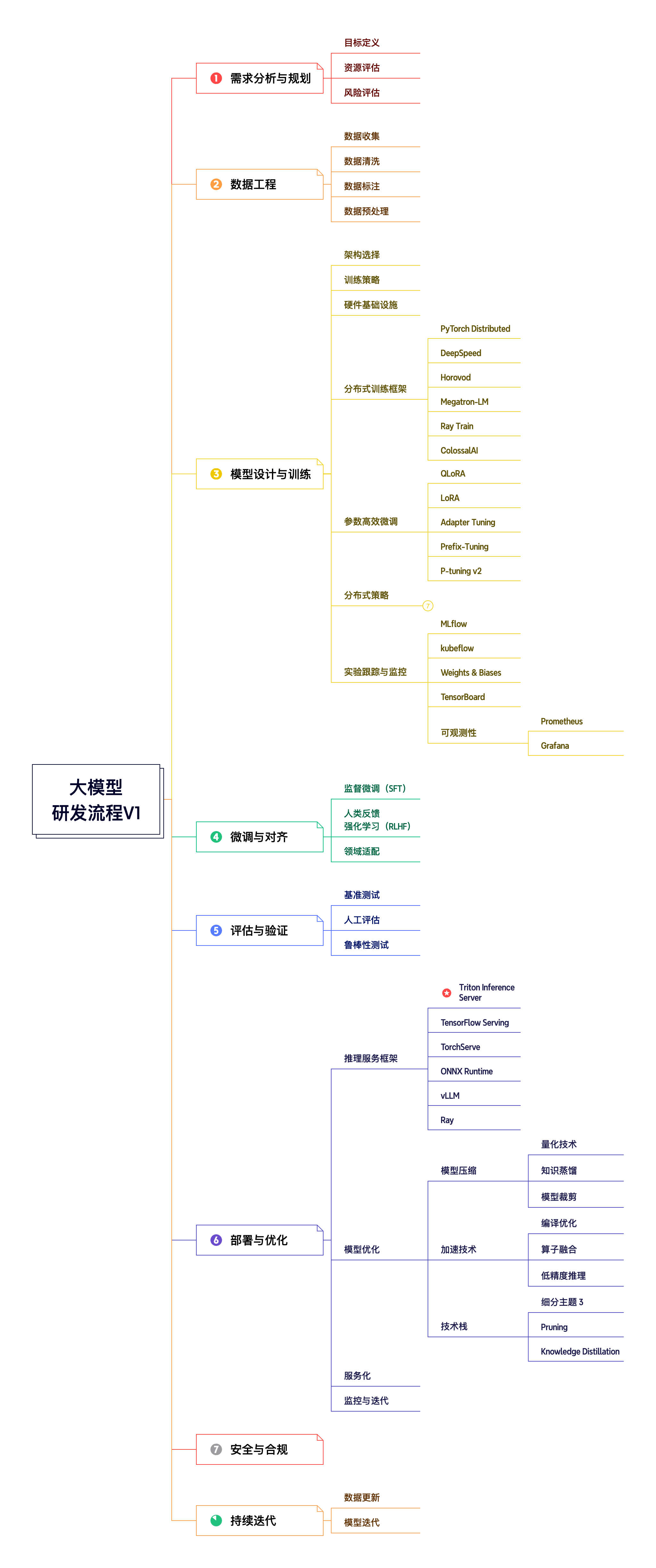
二、Triton 推理模型框架简介
2.1 Triton Inference Server
Triton Inference Server 是 NVIDIA 开发的一个开源推理服务软件,用于在生产环境中部署 AI 模型。它支持多种框架和硬件平台,提供高性能的推理服务。
主要特点:
-
多框架支持:支持 TensorRT、PyTorch、TensorFlow、ONNX Runtime 等多种后端
-
并发模型执行:可以同时运行多个模型,甚至同一模型的多个实例
-
动态批处理:自动将多个推理请求组合成批处理以提高吞吐量
-
模型流水线:支持将多个模型连接成处理流水线
-
云原生设计:支持 Kubernetes 部署,提供 Prometheus 监控指标
-
跨平台:支持 x86 和 ARM CPU,以及 NVIDIA GPU
典型应用场景:
-
大规模部署深度学习模型
-
需要低延迟高吞吐量的推理服务
-
多模型组合应用
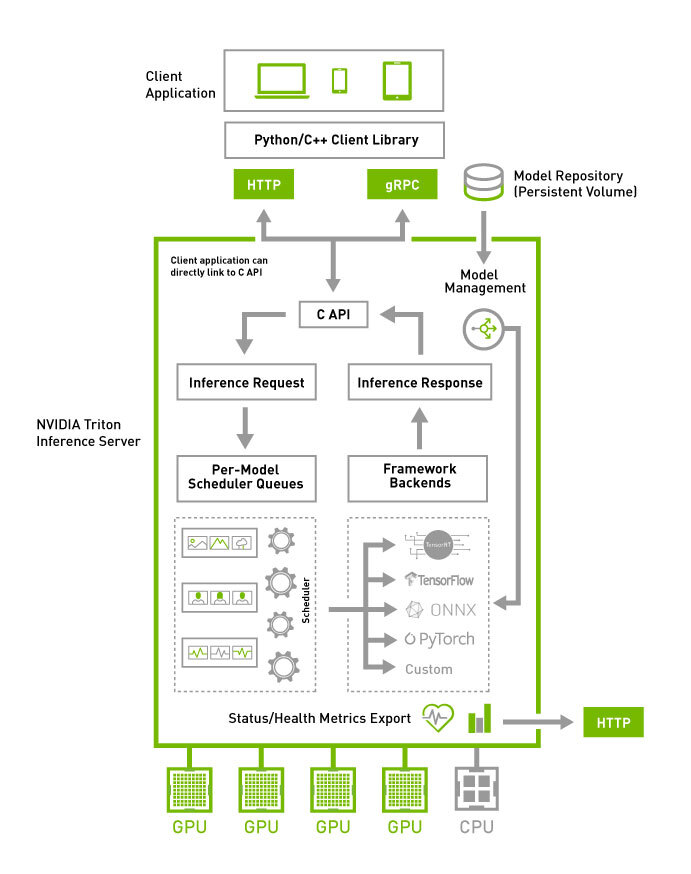
2.2 TensorRT-LLM
TensorRT-LLM 是 NVIDIA 推出的一个用于加速大型语言模型(LLM)推理的库,基于 TensorRT 构建。
主要特点:
-
LLM 优化:专门为大语言模型设计的优化技术
-
高性能推理:利用 TensorRT 的优化能力提供低延迟推理
-
量化支持:支持 INT8 和 FP8 量化以减少内存占用和提高速度
-
连续批处理:有效处理不同长度的输入序列
-
多GPU支持:支持多GPU并行推理
-
Python API:提供易于使用的 Python 接口
与 Triton 的关系:
TensorRT-LLM 可以作为 Triton Inference Server 的后端,两者结合可以构建高性能的 LLM 推理服务:
-
Triton 提供服务化能力和部署基础设施
-
TensorRT-LLM 提供针对 LLM 的核心推理加速
2.3 推理模型选型对比


三、实战测试(TensorRT + Triton)
3.1 阿里云 申请1台ECS 服务器
16C 60Gi A10 显卡,单机单卡
请参考我的另外一篇里面有介绍申请 ECS 服务器过程CSDN![]() https://mp.csdn.net/mp_blog/creation/editor/147115232
https://mp.csdn.net/mp_blog/creation/editor/147115232
3.2 基础环境配置初始化
请参考我的另外一篇里面有介绍conda 基础环境
CSDN![]() https://mp.csdn.net/mp_blog/creation/editor/147115232
https://mp.csdn.net/mp_blog/creation/editor/147115232
## 补充需要安装的组件
apt install libopenmpi-dev libopenmpi-dev -y
pip install tritonclient[all] grpcio
python3.10 -m pip install --no-binary mpi4py mpi4py
pip install --upgrade pip setuptools && pip install tensorrt_llm --extra-index-url https://pypi.nvidia.com3.3 容器环境配置安装
直接运行即可 ECS 宿主机是 ubuntu 22.04 版本的
### 安装容器运行时(Containerd) 安装依赖项
sudo apt install -y apt-transport-https ca-certificates curl gnupg lsb-release
# 添加 containerd 官方 GPG 密钥
curl -fsSL https://download.docker.com/linux/ubuntu/gpg | sudo gpg --dearmor -o /usr/share/keyrings/docker-archive-keyring.gpg
# 添加 containerd 仓库
echo "deb [arch=amd64 signed-by=/usr/share/keyrings/docker-archive-keyring.gpg] https://download.docker.com/linux/ubuntu $(lsb_release -cs) stable" | sudo tee /etc/apt/sources.list.d/docker.list > /dev/null
# 安装 containerd
sudo apt-get update
#sudo apt-get install -y docker-ce docker-ce-cli containerd.io
sudo apt-get install -y docker-ce-cli containerd.io
### 配置 Containerd
sudo mkdir -p /etc/containerd
containerd config default | sudo tee /etc/containerd/config.toml > /dev/null
sudo sed -i 's/SystemdCgroup = false/SystemdCgroup = true/g' /etc/containerd/config.toml
sudo systemctl enable containerd
sudo systemctl restart containerd
# 添加 NVIDIA 仓库
curl -fsSL https://nvidia.github.io/libnvidia-container/gpgkey | sudo gpg --dearmor -o /usr/share/keyrings/nvidia-container-toolkit-keyring.gpg
curl -s -L https://nvidia.github.io/libnvidia-container/stable/deb/nvidia-container-toolkit.list | \
sed 's#deb https://#deb [signed-by=/usr/share/keyrings/nvidia-container-toolkit-keyring.gpg] https://#g' | \
sudo tee /etc/apt/sources.list.d/nvidia-container-toolkit.list
sudo apt-get update
sudo apt-get install -y nvidia-container-toolkit
sudo nvidia-ctk runtime configure --runtime=containerd
sudo systemctl restart containerd
# 验证 GPU 支持
docker run --rm --gpus all nvidia/cuda:11.8.0-base-ubuntu22.04 nvidia-smi3.4 TensorRT_LLM格式转换
首先通过 huggingface 下载目标模型
huggingface-cli download Qwen/Qwen2.5-7B --resume-download \
--local-dir /data/models/Qwen2.5-7B
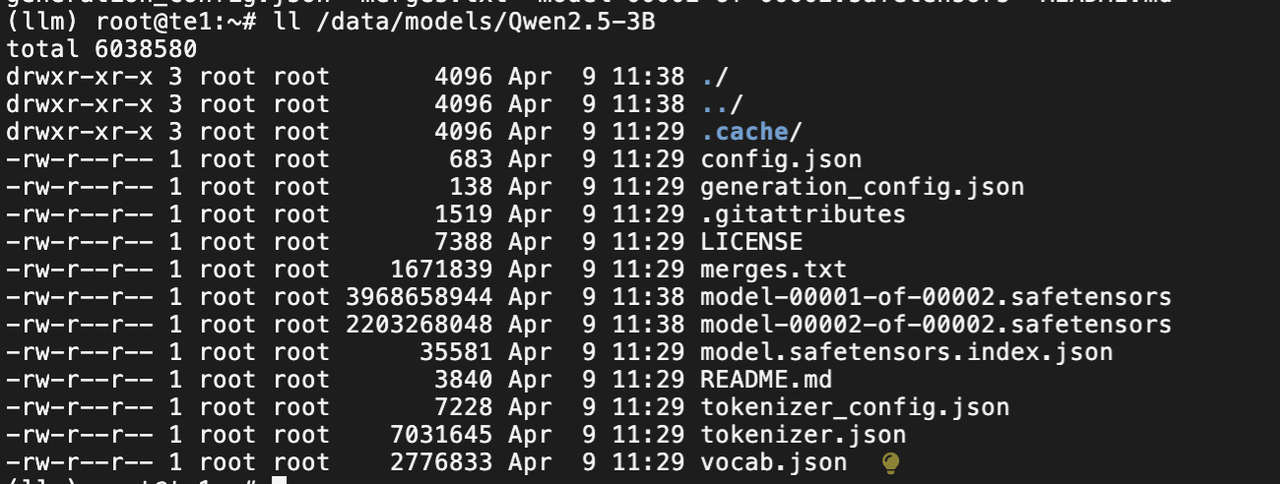
TensorRT_LLM 开始转化格式
https://github.com/NVIDIA/TensorRT-LLM/tree/main/examples/qwen
在github这个目录中下载convert_checkpoint.py 文件才能使用(尝试了很多次最后还是使用了官方提供的方法)
mkdir -p /models/triton_models/qwen2.5-7b-trt/1
python convert_checkpoint.py \
--model_dir /data/models/Qwen2.5-7B \
--output_dir /data/models/qwen2.5-7b-trt \
--dtype float16 \
--use_weight_only \
--weight_only_precision int4 \
--per_group \
--tp_size 1 \
--pp_size 1
trtllm-build \
--checkpoint_dir /data/models/qwen2.5-7b-trt \
--output_dir /data/models/triton_models/qwen2.5-7b-trt/1 \
--gemm_plugin float16 \
--gpt_attention_plugin float16 \
--max_batch_size 8 \
--max_input_len 1024#参数说明
--model_dir: 原始 HuggingFace 模型路径
--output_dir: 转换后 TensorRT 引擎输出路径
--dtype: 数据类型 (float16 或 float32)
--model_type: 指定模型类型为 qwen2
--use_weight_only: 使用权重量化
--weight_only_precision: 量化精度 (int4 或 int8)
--per_group: 按组量化
--tp_size: 张量并行大小 (单卡设为1)
--pp_size: 流水线并行大小 (单卡设为1)
--world_size: 总 GPU 数量 (单卡设为1)3.5 Triton 部署模型
注意:这里直接使用了容器方式进行测试的。将模型目录挂载到容器里面,然后运行的
nvcr.io/nvidia/tritonserver:25.02-trtllm-python-py3
/data/models/triton_models相当于是Triton仓库可以包含很多的模型
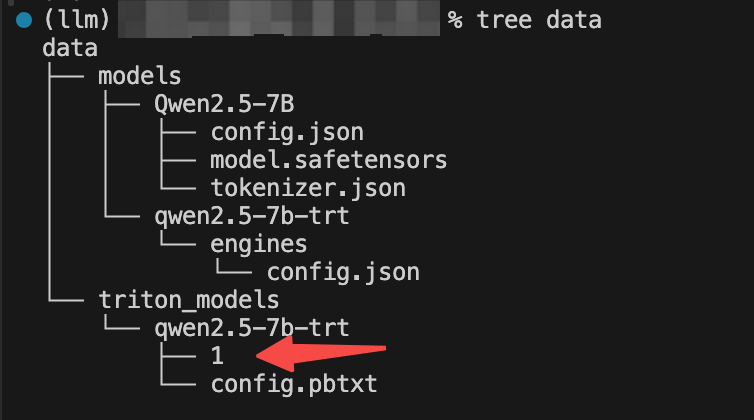
创建模型仓库结构
mkdir -p /data/models/triton_models/qwen2.5-7b-trt/1
复制引擎文件
cp -r /data/models/qwen2.5-7b-trt/* models/qwen2.5-7b-trt/1
创建配置文件
/data/models/triton_models/qwen2.5-7b-trt/config.pbtxt
大概类似于这样的目录结构。
/data/models 存储原始模型
/data/models/triton_models/ 模型仓库路径
/data/models/triton_models/qwen2.5-7b-trt/1 模型引擎存放路径
name: "qwen2.5-7b-trt"
backend: "tensorrtllm"
max_batch_size: 8
input [
{
name: "input_ids"
data_type: TYPE_INT32
dims: [ -1 ]
},
{
name: "input_lengths"
data_type: TYPE_INT32
dims: [ -1 ]
},
{
name: "request_output_len"
data_type: TYPE_INT32
dims: [ -1 ]
}
]
output [
{
name: "output_ids"
data_type: TYPE_INT32
dims: [ -1, -1 ]
},
{
name: "sequence_length"
data_type: TYPE_INT32
dims: [ -1 ]
}
]
instance_group [
{
count: 1
kind: KIND_GPU
}
]
parameters: {
key: "gpt_model_type"
value: {
string_value: "V1"
}
},
parameters: {
key: "gpt_model_path"
value: {
string_value: "/models/triton_models/qwen2.5-7b-trt/1"
}
},
parameters: {
key: "tokenizer_type"
value: {
string_value: "auto"
}
},
parameters: {
key: "tokenizer_dir"
value: {
string_value: "/models/Qwen2.5-7B"
},
}
parameters: {
key: "model_task"
value: {
string_value: "decoder-only"
}
},
parameters: {
key: "engine_dir"
value: { string_value: "/models/triton_models/qwen2.5-7b-trt/1" }
},
parameters: {
key: "decoder_model_path"
value: { string_value: "/models/triton_models/qwen2.5-7b-trt/1" }
},
parameters: {
key: "decoding_mode"
value: { string_value: "top_k_top_p" }
},
parameters: {
key: "gpu_weights_percent"
value: { string_value: "0.8" }
}docker run -d --gpus all \
-p 8000:8000 -p 8001:8001 -p 8002:8002 \
-v /data/models:/models \
nvcr.io/nvidia/tritonserver:25.02-trtllm-python-py3 \
tritonserver --model-repository=/models/triton_models \
--log-verbose=1 \
--strict-model-config=false
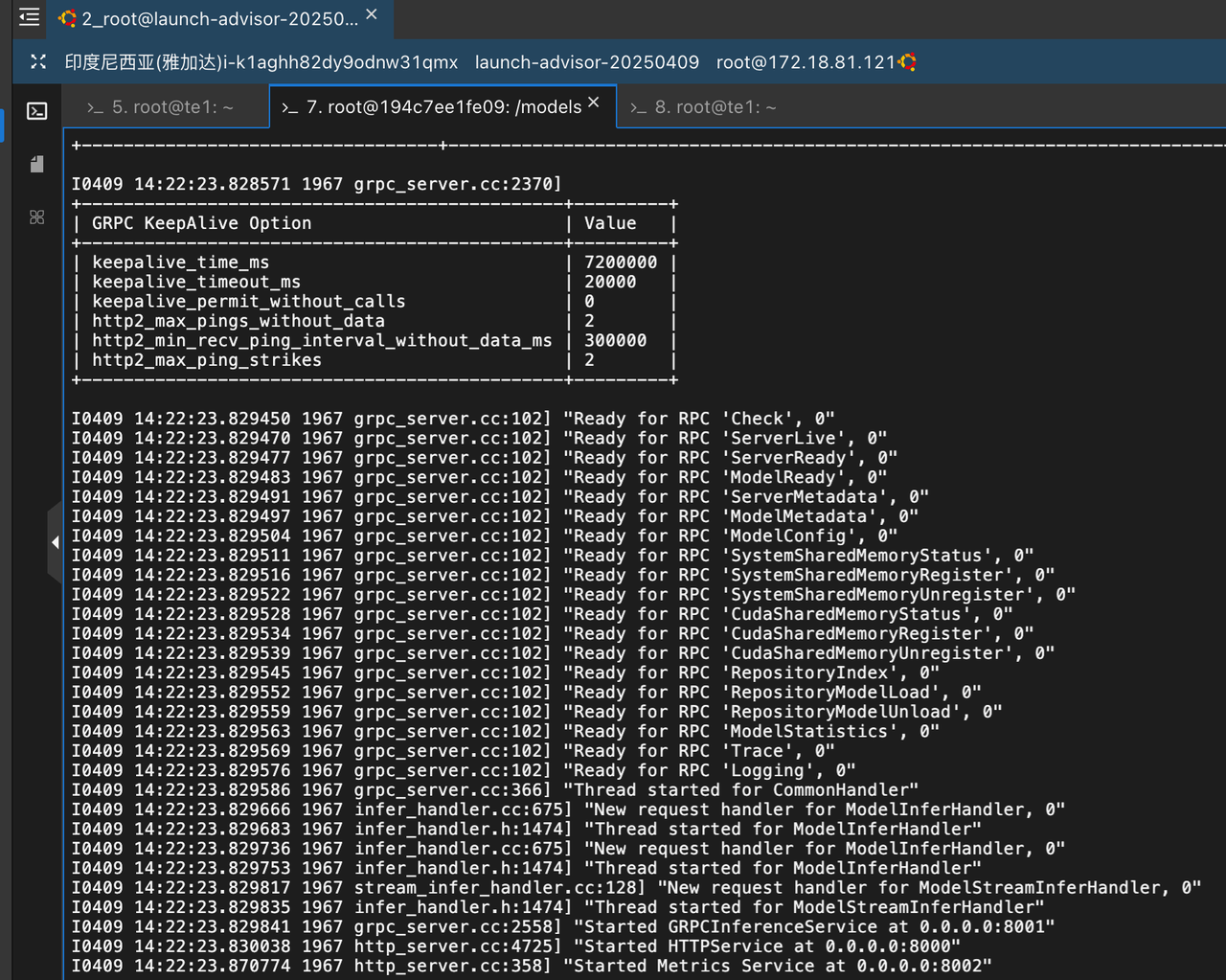
3.5 测试效果
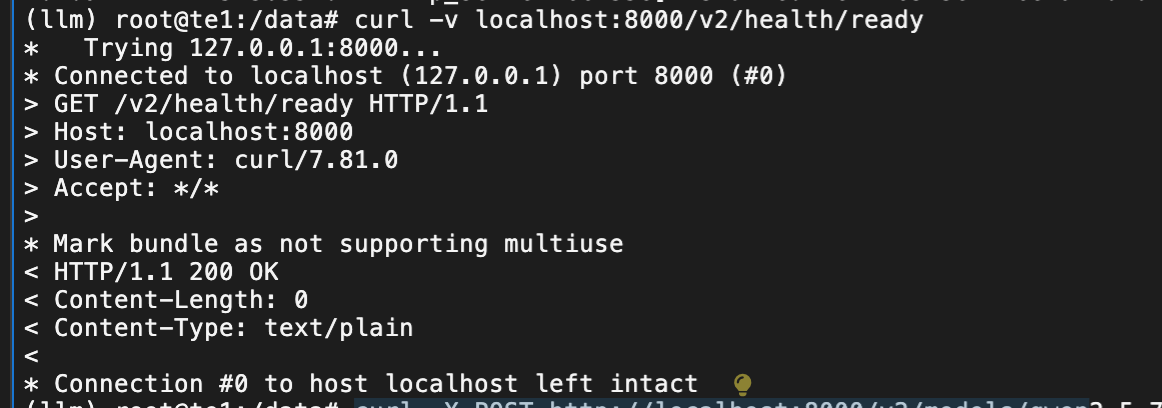
import tritonclient.grpc as grpcclient
from transformers import AutoTokenizer
import numpy as np
# 初始化客户端
triton_client = grpcclient.InferenceServerClient(url="localhost:8001")
# 加载 tokenizer
tokenizer = AutoTokenizer.from_pretrained("Qwen/Qwen2.5-7B", trust_remote_code=True)
# 准备输入
prompt = "介绍一下人工智能的历史"
input_ids = tokenizer.encode(prompt, return_tensors="np").astype(np.int32)
input_lengths = np.array([[len(input_ids[0])]], dtype=np.int32)
request_output_len = np.array([[512]], dtype=np.int32)
# 设置输入
inputs = [
grpcclient.InferInput("input_ids", input_ids.shape, "INT32"),
grpcclient.InferInput("input_lengths", input_lengths.shape, "INT32"),
grpcclient.InferInput("request_output_len", request_output_len.shape, "INT32"),
]
inputs[0].set_data_from_numpy(input_ids)
inputs[1].set_data_from_numpy(input_lengths)
inputs[2].set_data_from_numpy(request_output_len)
# 设置输出
outputs = [
grpcclient.InferRequestedOutput("output_ids"),
grpcclient.InferRequestedOutput("sequence_length"),
]
# 发送请求
response = triton_client.infer(
model_name="qwen2.5-7b-trt",
inputs=inputs,
outputs=outputs,
)
# 处理输出
output_ids = response.as_numpy("output_ids")
sequence_length = response.as_numpy("sequence_length")
# 解码输出
generated_text = tokenizer.decode(output_ids[0][0][:sequence_length[0][0]])
print("Generated text:", generated_text)
四、分布式场景测试
等空闲时再补充
五、小结
推理模型部署测试,整个过程应该来说比较短。qwen 2.5 模型由 huggingface 转换成TensorRT_LLM格式。然后再使用triton部署一下就行了。但是还是有很多坑不顺畅,宿主机换金和容器环境协作环境问题,版本不兼容问题。理顺了逻辑整个实验很快就能完成。后续把分布式场景,云原生场景再研究测试一下看看。
补充 (问题)
TensorRT-LLM 版本太低
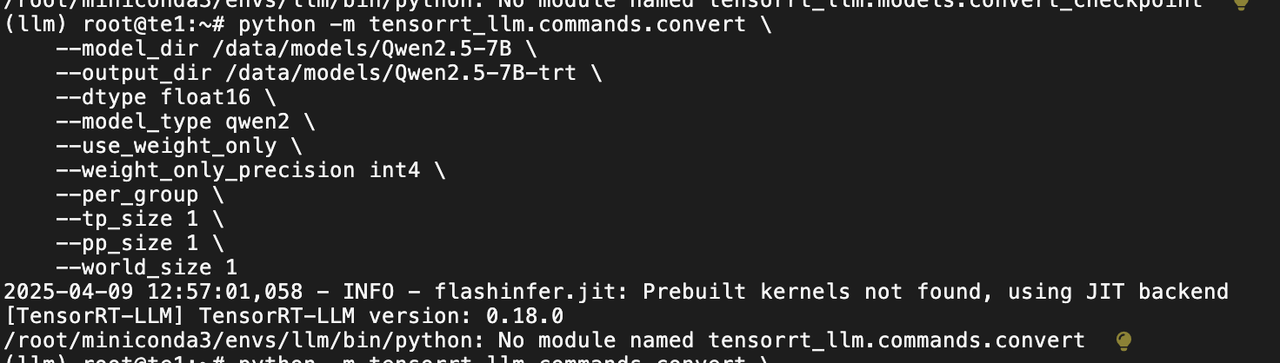
与 vllm 冲突报错
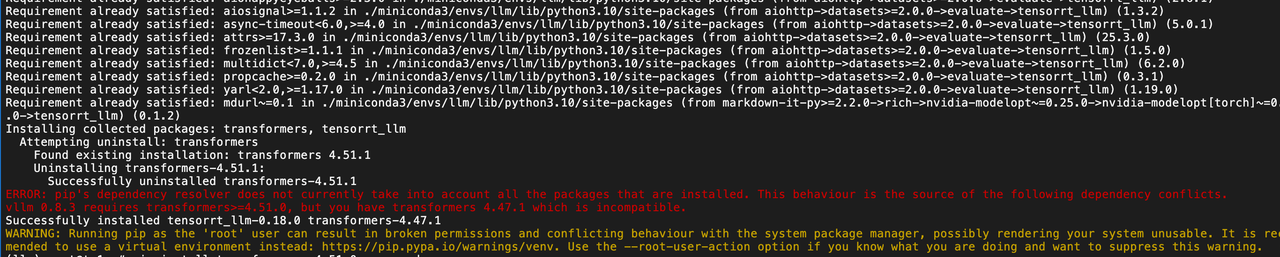
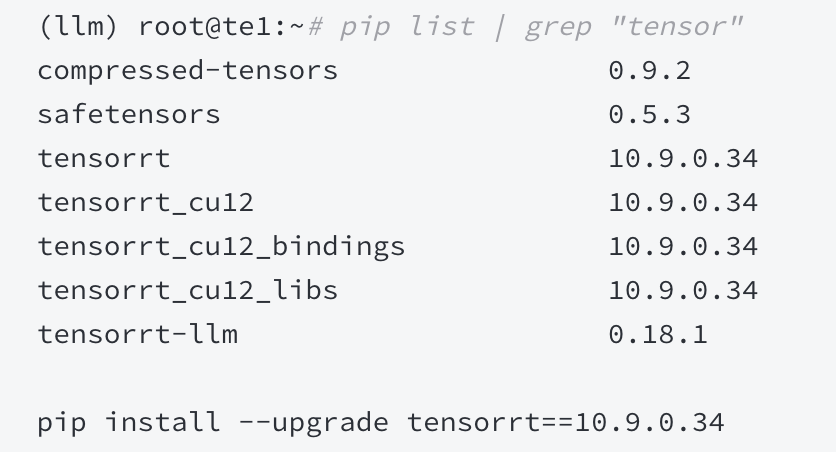
宿主机和容器 TensorRT版本不一致问题

魔乐社区(Modelers.cn) 是一个中立、公益的人工智能社区,提供人工智能工具、模型、数据的托管、展示与应用协同服务,为人工智能开发及爱好者搭建开放的学习交流平台。社区通过理事会方式运作,由全产业链共同建设、共同运营、共同享有,推动国产AI生态繁荣发展。
更多推荐


 16
16 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)