1.2python网络爬虫-复杂的网页解析
面对复杂的页面解析,千万不要不假思索地直接编写代码,从而使得爬虫代码变得难以调试和维护。我们可以在编写代码前,做一些准备工作,例如,寻找更加友好的网页样式版本,从查看JS里的文件信息,从别处寻找更加友好的数据源和查看是否有“打印网页”链接等等。BeautifulSoup库findAll(),find(),lambda函数的应用
目录:
前言:
对于复杂的网页,我们需要过滤掉不需要的信息,通过对复杂网页的解析,抽取到我们所需要的信息。
面对复杂的页面解析,千万不要不假思索地直接编写代码,从而使得爬虫代码变得难以调试和维护。我们可以在编写代码前,做一些准备工作,例如,寻找更加友好的网页样式版本,从查看JS里的文件信息,从别处寻找更加友好的数据源和查看是否有“打印网页”链接等等。如果这样还不行的话,我们编写更好质量的爬虫代码才行了,让我们现在开始学习下面的内容吧!
一,更深入地了解BeautifulSoup
1.BeautifulSoup实例运用及分析
在前面的内容里,我们快速演示了 BeautifulSoup 的安装与运行过程,同时也实现了每次选择一个对象的解析方法。接下来,我们将介绍通过属性查找标签的方法,标签组的使用,以 及标签解析树的导航过程。
基本上,每个网站都会有层叠样式表(Cascading Style Sheet,CSS)。虽然这是专门为了让浏览器和人类可以理解网站内容而设计一个展现样式的层,但是 CSS 的发明却是网络爬虫的福音。CSS 可以让 HTML 元素呈现出差异化, 使那些具有完全相同修饰的元素呈现出不同的样式。比如,有一些标签看起来是这样:
<span class="green"></span>
而另一些标签看起来是这样:
<span class="red"></span>
网络爬虫可以通过 class 属性的值(样式导致的差异化结果),轻松地区分出两种不同的标签。例如,它们可以用 BeautifulSoup 抓取网页上所有的红色文字,而绿色文字一个都不抓。因为 CSS 通过属性准确地呈现网站的样式,而大多数新式网站上的 class 和 id 属性资源都非常丰富,所以这是一种抽取信息的途径。
下面我们通过一个爬取实例(《战争与和平》小说英文版),进行练习,链接地址:http://www.pythonscraping.com/pages/warandpeace.html
(注:在这个页面里,小说人物的对话内容都是红色的,人物名称都是绿色的。所以对应的标签(CSS)属性有差异)
from urllib.request import urlopen
from bs4 import BeautifulSoup
html=urlopen("http://www.pythonscraping.com/pages/warandpeace.html")
soup=BeautifulSoup(html)#解析HTML页面;
nameList=soup.findAll("span",{"class":"green"})#在soup对象里,findAll函数查找出符合的全部结果,并返回到一个列表中,结果是包含标签及里面的信息;
for name in nameList:
print(name.get_text())#get_text()使所处理的内容里的标签全部去掉,类似格式化文本输出;
输出效果如下(出场人物顺序):
Anna
Pavlovna Scherer
Empress Marya
Fedorovna
Prince Vasili Kuragin
Anna Pavlovna
St. Petersburg
the prince
Anna Pavlovna
Anna Pavlovna
the prince
the prince
the prince
Prince Vasili
Anna Pavlovna
Anna Pavlovna
the prince
Wintzingerode
King of Prussia
le Vicomte de Mortemart
Montmorencys
Rohans
Abbe Morio
the Emperor
the prince
Prince Vasili
Dowager Empress Marya Fedorovna
the baron
Anna Pavlovna
the Empress
the Empress
Anna Pavlovna's
Her Majesty
Baron
Funke
The prince
Anna
Pavlovna
the Empress
The prince
Anatole
the prince
The prince
Anna
Pavlovna
Anna Pavlovna
>>>
代码分析:
(1)一般地,bsobj.nameTag只能返回取页面中的第一个指定的标签,而findAll函数返回的是页面中的全部指定的标签,并将结果放在一个列表中,所以一般后面会遍历循环列表而打印出信息,
(2)什么时候使用 get_text() 与什么时候应该保留标签:
.get_text() 会把你正在处理的 HTML 文档中所有的标签(包含的超链接、段落和标签)都清除,然后返回 一个只包含文字(标签的文本内容)的字符串。 通常在你准备打印、存储和操作数据时,应该最后才使 用 .get_text()。一般情况下要后续对标签内容的操作前,你应尽可能地保留 HTML 文档的标签结构。
2.BeautifulSoup的find()和findAll()的使用
BeautifulSoup 里的 find() 和 findAll()两个函数,参数丰富,可以使你很准确迅速地抽取出所需要的单个标签或标签组。两个函数非常相似,他们的BeautifulSoup 文档定义如下:
findAll(tag, attributes, recursive, text, limit, keywords)
find(tag, attributes, recursive, text, keywords)
对于这两个函数,每个参数使用频率都有所不同,下面将详细地介绍这些参数的使用:
注意:参数里面的描述标签内容,属性都要是字符串形式;
(1)标签参数 tag 前面已经介绍过——你可以传一个标签的名称或多个标签名称组成的 Python 列表做标签参数。例如,下面的代码将返回一个包含 HTML 文档中所有标题标签的列表:
.findAll({"h1","h2","h3","h4","h5","h6"})
(2)属性参数 attributes 是用一个 Python 字典封装一个标签的若干属性(键)和对应的属性值(键值)。例 如,下面这个函数会返回 HTML 文档里红色与绿色两种颜色的 span 标签:
.findAll("span", {"class":{"green", "red"}})
(3)递归参数 recursive 是一个布尔变量。你想抓取 HTML 文档标签结构里多少层的信息?如果 recursive 设置为 True,findAll 就会根据你的要求去查找标签参数的所有子标签,以及子标签的子标签。如果 recursive 设置为 False,findAll 就只查找文档的一级标签。findAll 默认是支持递归查找的(recursive 默认值是 True);一般情况下这个参数不需要设置,除 非你真正了解自己需要哪些信息,而且抓取速度非常重要,那时你可以设置递归参数。
(4)文本参数 text 有点不同,它是用标签的文本内容去匹配,而不是用标签的属性。假如我们 想查找前面网页中包含“the prince”内容的标签数量,我们可以把之前的 findAll 方法换 成下面的代码:
nameList = bsObj.findAll(text="the prince")
print(len(nameList))
输出结果为:7
(5)范围限制参数 limit,显然只用于 findAll 方法。find 其实等价于 findAll 的 limit 等于 1 时的情形。如果你只对网页中获取的前 x 项结果感兴趣,就可以设置它。但是要注意, 这个参数设置之后,获得的前几项结果是按照网页上的顺序排序的,未必是你想要的那 前几项。
(6)还有一个关键词参数 keyword,可以让你选择那些具有指定属性的标签。例如:
allText = bsObj.findAll(id="text")
print(allText[0].get_text())
关键词参数的注意事项:
虽然关键词参数 keyword 在一些场景中很有用,但是,它是 BeautifulSoup 在 技术上做的一个冗余功能,类似属性参数作用。
例如,下面两行代码是完全一样的:
bsObj.findAll(id="text")
bsObj.findAll("", {"id":"text"})
另外,用 keyword 偶尔会出现问题,尤其是在用 class 属性查找标签的时候,因为class 是 Python 语言 的保留字,在 Python 程序里是不能当作变量或参数名使用的(和前面介绍 的 BeautifulSoup.findAll() 里的 keyword 无关,只是网页所查找的是class属性而已,但是有解决方法)假如你运行下面的代码, Python 就会因为你误用 class 保留字而产生一个语法错误:
bsObj.findAll(class_="green")
不过,你可以用 BeautifulSoup 提供的有点儿臃肿的方案,在 class 后面增加 一个下划线:
另外,你也可以用属性参数把 class 用引号包起来:
bsObj.findAll("", {"class":"green"})
通过前面的内容可知道,标签参数 tag 把标签列表传到 .findAll() 里获取一列标签,其实就是一个“或”关系的过滤器(即选择所有带标签 1 或标签 2 或标签 3……的一列标 签)。如果你的标签列表很长,就需要花很长时间才能写完。而增加关键词参数 keyword 可以让 你增加一个“与”关系的过滤器来简化工作。
3.其他BeautifulSoup对象
(1)BeautifulSoup 对象:
前面代码示例中的 bsObj,BeautifulSoup直接解析网页所得到的对象;
(2)标签 Tag 对象:
BeautifulSoup 对象通过 find 和 findAll,或者直接调用子标签获取的一列对象或单个对象,就像:
bsObj.div.h1
(3)NavigableString 对象:
用来表示标签里的文字,不是标签(有些函数可以操作和生成 NavigableString 对象,而不是标签对象)。
(4)Comment 对象:
用来查找 HTML 文档的注释标签
其中在第三第四个对象很少被用到,了解一下即可。
3.导航树
findAll和find 函数通过标签的名称和属性来查找标签 。但是如何通过标签在文档中的位置来查找标签?这就是导航树(Navigating Trees)的作用。
现在我们用虚拟的在线购物网站 http://www.pythonscraping.com/pages/page3.html 作为要抓取的示例网页,演示 HTML 导航树的纵向和横向导航(如下图所示)。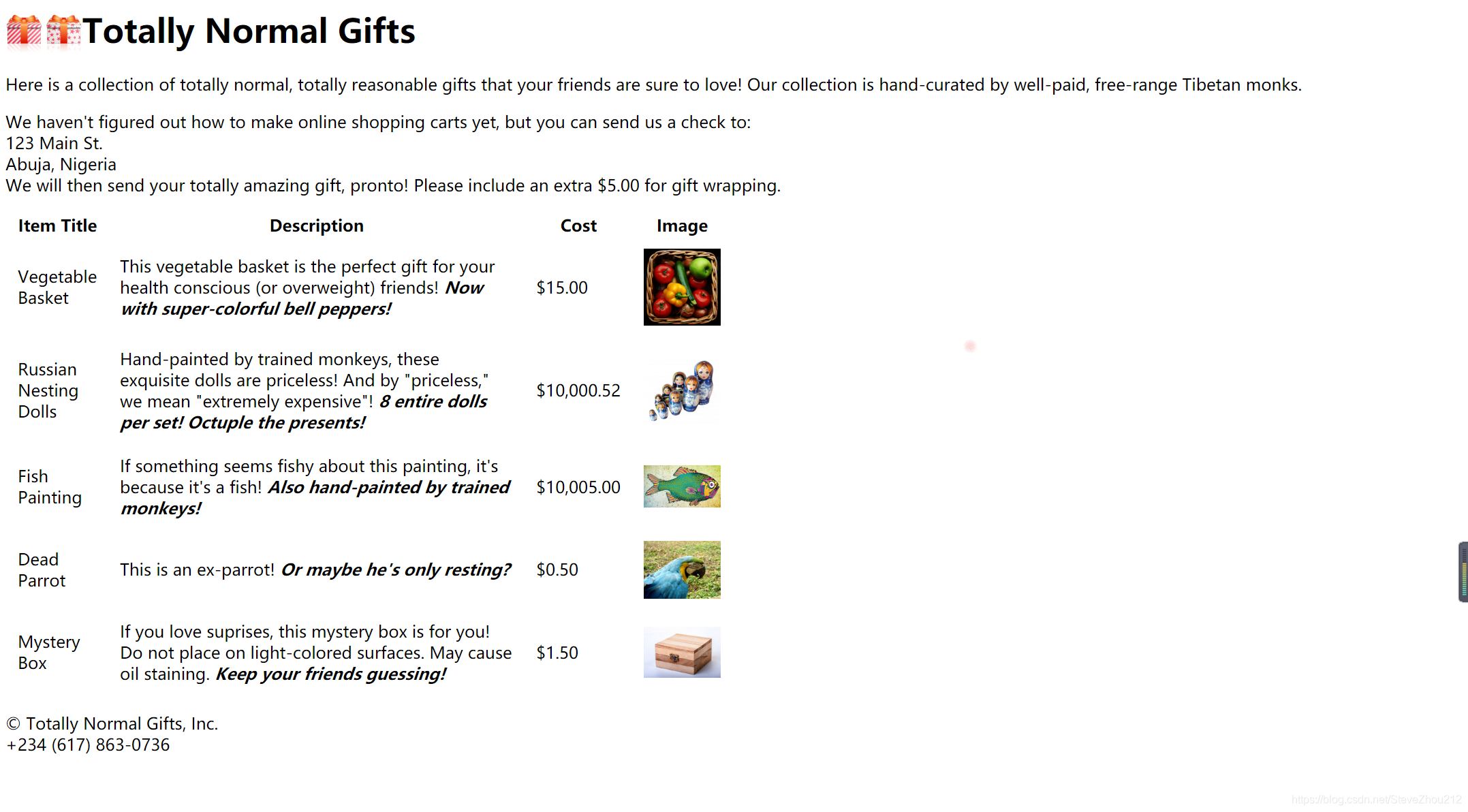
这个 HTML 页面可以映射成一棵树(为了简洁,省略了一些标签),如下所示:
(1)在 BeautifulSoup 里,子标签的处理方式有些许不同。 和许多其他库一样,在 BeautifulSoup 库里,孩子(child)和后代(descendant)有显著的不同:子标签就是一个父标签的下一级,而后代标签是指一个父标签 下面所有级别的标签。例如,tr 标签是 table 标签的子标签,而 tr、th、td、img 和 span 标签都是 table 标签的后代标签(我们的示例页面中就是如此)。
所有的子标签都是后代标 签,但不是所有的后代标签都是子标签。
一般情况下,BeautifulSoup 函数总是处理当前标签的后代标签。例如,bsObj.body.h1 选 择了 body 标签后代里的第一个 h1 标签,不会去找 body 外面的标签。 类似地,bsObj.div.findAll(“img”) 会找出文档中第一个 div 标签,然后获取这个 div 后 代里所有的 img 标签列表。如果你只想找出子标签,可以用 .children 标签:
from urllib.request import urlopen
from bs4 import BeautifulSoup
html = urlopen("http://www.pythonscraping.com/pages/page3.html")
bsObj = BeautifulSoup(html)
for child in bsObj.find("table",{"id":"giftList"}).children:
print(child)
这段代码会打印 giftList 表格中所有产品的数据行。如果你用 descendants() 函数而不是 children() 函数,那么就会有二十几个标签打印出来,包括 img 标签、span 标签,以及每 个 td 标签。掌握子标签与后代标签的差别十分重要!
(2)处理兄弟标签
BeautifulSoup 的 next_siblings() 函数可以让收集表格数据成为简单的事情,尤其是处理 带标题行的表格:
from urllib.request import urlopen
from bs4 import BeautifulSoup
html = urlopen("http://www.pythonscraping.com/pages/page3.html")
bsObj = BeautifulSoup(html)
for sibling in bsObj.find("table",{"id":"giftList"}).tr.next_siblings:
print(sibling)
这段代码会打印产品列表里的所有行的产品,但第一行表格标题除外。首先,对象不能把自己作为兄弟标签。任何时候你获取一个标签的兄 弟标签,都不会包含这个标签本身。其次,这个函数只调用后面的兄弟标签。因此,选择标签行然后调用 next_siblings,可以选择表 格中除了标题行以外的所有行。
如何让标签的选择更具体:
如果我们选择 bsObj.table.tr 或直接就用 bsObj.tr 来获取表格中的第一行, 都可以获得正确的结果。但是,我们还是采用更长的形式写了一 行代码,这可以避免各种意外:
bsObj.find("table",{"id":"giftList"}).tr
即使页面上只有一个表格(或其他目标标签),只用标签也很容易丢失细节。 另外,页面布局总是不断变化的。如果想让你的爬虫更稳定,最好还是让 标签的选择更加具体。如果有属性,就利用标签的属性。和 next_siblings 一样,如果你很容易找到一组兄弟标签中的最后一个标签,那么 previous_siblings 函数也会很有用。
当然,还有 next_sibling 和 previous_sibling 函数,与 next_siblings 和 previous_siblings 的作用类似,只是它们返回的是单个标签,而不是一组标签。
(3)父标签处理
在抓取网页的时候,查找父标签的需求比查找子标签和兄弟标签要少很多。通常情况 下,如果以抓取网页内容为目的来观察 HTML 页面,我们都是从最上层标签开始的,然 后思考如何定位我们想要的数据块所在的位置。但是,偶尔在特殊情况下你也会用到 BeautifulSoup 的父标签查找函数,parent 和 parents。例如:
from urllib.request import urlopen
from bs4 import BeautifulSoup
html = urlopen("http://www.pythonscraping.com/pages/page3.html")
bsObj = BeautifulSoup(html)
print(bsObj.find("img",{"src":"../img/gifts/img1.jpg" }).parent.previous_sibling.get_text())
这段代码会打印 …/img/gifts/img1.jpg 这个图片对应商品的价格(这个示例中价格是 $15.00)。
这是如何实现的呢?下面的图形是我们正在处理的 HTML 页面的部分结构,用数字表示步 骤的话:
(1) 选择图片标签 src="…/img/gifts/img1.jpg";
(2) 选择图片标签的父标签(在示例中是 标签);
(3) 选择 标签的前一个兄弟标签 previous_sibling(在示例中是包含美元价格的 标签);
(4) 选择标签中的文字,“$15.00”。
二,正则表达式与BeautifulSoup的结合使用
1.正则表达式
之所以叫正则表达式,是因为它们可以识别正则字符串(regular string);也就是说,它们可以这么定义:“如果你给我的字符串符合规则,我就返回它”,或者是“如果字符串不符 合规则,我就忽略它”。这在要求快速浏览大文档,以查找像电话号码和邮箱地址之类的 字符串时是非常方便的。
练习正则表达式:
在学习书写正则表达式的时候,做一些练习感受一下它们如何工作,这是至关重要的。 如果你不想打开代码编辑器,写完再运行程序检查正则表达式的运行是否符合预期,那么你可以去 RegexPal(http://regexpal.com/)这类网站上在线测试 正则表达式。
正则表达式在实际中的一个经典应用是识别邮箱地址。虽然不同邮箱服务器的邮箱地址的 具体规则不尽相同,但是我们还是可以创建几条通用规则。每条规则对应的正则表达式如 下图第 2 列所示:
把上面的规则连接起来,就获得了完整的正则表达式:
[A-Za-z0-9._+]+@[A-Za-z]+.(com|org|edu|net)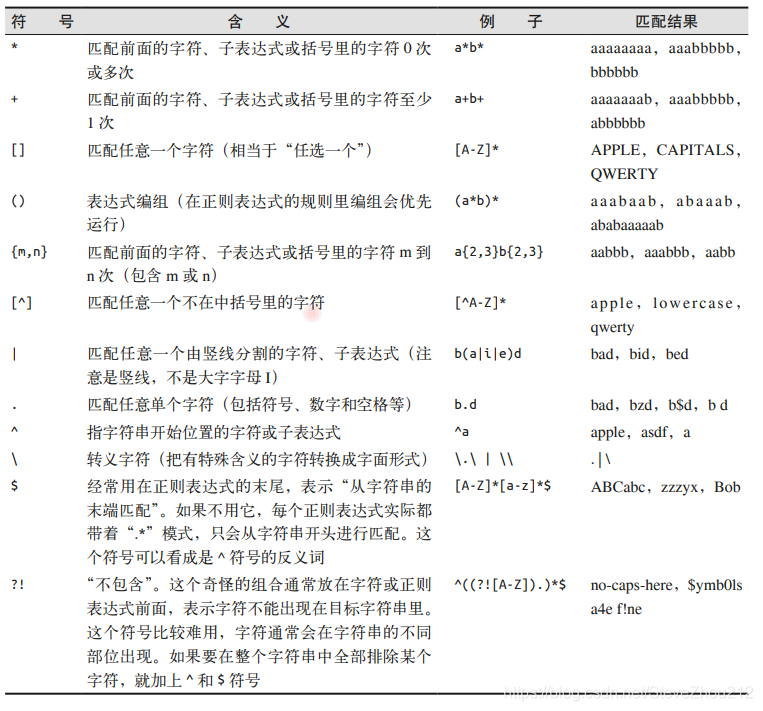
这个列表并不是全部符号,另外就像之前所说的,可能在不同编程语言中会遇到一些变化。但是,这 12 个符号 是 Python 的正则表达式中最常用的,可以用来查找和收集绝大多数数据类型。
正则表达式,并非处处正则:
正则表达式的标准版(本书使用的版本,用于 Python 和 BeautifulSoup)是基于 Perl 语法演变而来的。绝大多数主流编程语言都使用与之相同或近似的版 本。但是,在其他语言中使用这些正则表达式时需要当心,否则可能会出问 题。有些语言,比如 Java,其正则表达式就和 Python 不太一样。总之,遇 到问题时看文档!
2.正则表达式与BeautifulSoup使用实例
在抓取网页的时候,BeautifulSoup 和正则表达式总是配合使用的。
其实,大多数支持字符串参数的函数(比如,find(id=“aTagIdHere”))都可以用正则表达式实现。 让我们看几个例子,待抓取的网页是 http://www.pythonscraping.com/pages/page3.html。 注意观察网页上有几个商品图片——它们的源代码形式如下:
<img src="../img/gifts/img3.jpg">
如果我们想抓取所有图片的 URL 链接,非常直接的做法就是用 findAll(“img”) 抓取所有 图片,对吗?但是,有个问题。除了那些明显“多余的”图片(比如,LOGO)之外,新 式的网站里都有一些隐藏图片,用于网页布局留白和元素对齐的空白图片,以及一些不容 易察觉到的图片标签。总之,你不能仅用商品图片来统计网页上所有的图片。 而且网页的布局也可能会变化,或者,因为某些原因,我们不想通过图片在网页中的位置 来查找标签。那么当你想抓取随机分布在网站里的某个元素或数据时,就会出现问题。例 如,一些网页的最上面可能有一张商品图片,但是在另一些网页上没有。 解决这类问题的办法,就是直接定位那些标签来查找信息。在本例中,我们直接通过商品 图片的文件路径来查找:
from urllib.request import urlopen
from bs4 import BeautifulSoup
import re
html = urlopen("http://www.pythonscraping.com/pages/page3.html")
bsObj = BeautifulSoup(html)
images = bsObj.findAll("img",{"src":re.compile("\.\.\/img\/gifts\/img.*\.jpg")})
for image in images:
print(image["src"])
这段代码会打印出图片的相对路径,都是以 …/img/gifts/img 开头,以 .jpg 结尾,其结果如 下所示:
../img/gifts/img1.jpg
../img/gifts/img2.jpg
../img/gifts/img3.jpg
../img/gifts/img4.jpg
../img/gifts/img6.jpg
>>>
正则表达式可以作为 BeautifulSoup 语句的任意一个参数,让你的目标元素查找工作极具灵活性。
3.对标签获取属性
到目前为止,我们已经介绍过如何获取和过滤标签,以及获取标签里的内容。但是,在网 络数据采集时你经常不需要查找标签的内容,而是需要查找标签属性。比如标签 指向 的 URL 链接包含在 href 属性中,或者 错误!未指定文件名。标签的图片文件包含在 src 属性中,这时获 取标签属性就变得非常有用了。
对于一个标签对象,可以用下面的代码获取它的全部属性:
myTag.attrs
要注意这行代码返回的是一个 Python 字典对象,可以获取和操作这些属性。比如要获取图 片的资源位置 src,可以用下面这行代码:
myImgTag.attrs["src"]
4.lambda函数使用介绍
Lambda 表达式本质上就是一个函数,可以作为其他函数的变量使用;也就是说,一个函数不是定义成 f(x, y),而是定义成 f(g(x), y),或 f(g(x), h(x)) 的形式。
BeautifulSoup 允许我们把特定函数类型当作 findAll 函数的参数。唯一的限制条件是这些 函数必须把一个标签作为参数且返回结果是布尔类型。BeautifulSoup 用这个函数来评估它 遇到的每个标签对象,最后把评估结果为“真”的标签保留,把其他标签剔除。
例如,下面的代码就是获取有两个属性的标签:
soup.findAll(lambda tag: len(tag.attrs) == 2)
这行代码会找出下面的标签:
<div class="body" id="content"></div>
<span style="color:red" class="title"></span>
如果你愿意多写一点儿代码,那么在 BeautifulSoup 里用 Lambda 表达式选择标签,将是正则表达式的完美替代方案。
5.其他的网页解析库介绍
除了BeautifulSoup库外,还有另外两个解析库,可供选择,并被不时之需。
(1)lxml
这个库(http://lxml.de/)可以用来解析 HTML 和 XML 文档,以非常底层的实现而闻名 于世,大部分源代码是用 C 语言写的。虽然学习它需要花一些时间(其实学习曲线越陡峭,表明你可以越快地学会它),但它在处理绝大多数 HTML 文档时速度都非常快。
(2)HTML
parser 这是 Python 自带的解析库(https://docs.python.org/3/library/html.parser.html)。因为它不 用安装(只要装了 Python 就有),所以可以很方便地使用。
6.拓展:
Python学习系列之lambda表达式
Python–lxml库的简单介绍及基本使用
python3中的RE(正则表达式)-总结
BeautifulSoup的高级应用 之 find findAll
最后,文中如有不足,敬请批评指正!!!
后面也会不断更新文章的内容,请多多关注和点赞啊!!!

魔乐社区(Modelers.cn) 是一个中立、公益的人工智能社区,提供人工智能工具、模型、数据的托管、展示与应用协同服务,为人工智能开发及爱好者搭建开放的学习交流平台。社区通过理事会方式运作,由全产业链共同建设、共同运营、共同享有,推动国产AI生态繁荣发展。
更多推荐


 2
2 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)