计算机毕业设计之基于大数据的晋江文学城网站的采集与分析
本文基于大数据技术对晋江文学城网站进行数据采集与分析,构建了包含用户行为、内容互动等多维指标体系。研究采用分布式存储和Spark计算框架处理数据,并通过可视化看板展示关键指标。系统实现了数据采集、存储、分析和可视化功能,为网站运营决策提供支持。研究发现该平台用户群体多元,情感分析有效提升了内容匹配度,为网络文学数字化转型提供参考。
随着互联网的迅猛发展,网络文学已成为现代文化产业的重要组成部分。晋江文学城作为国内知名的原创文学网站,汇聚了大量的优秀作者和海量文学作品,形成了独特的网络文学生态。然而,面对如此庞大的数据量,如何有效地采集、整理和分析这些数据,以挖掘其背后的价值,成为亟待解决的问题。大数据技术的兴起为这一领域的研究提供了新的思路和方法,使得对晋江文学城网站的深入分析成为可能。
本研究基于大数据技术对微博网站的晋江文学城数据进行了全面的数据采集与分析。通过构建多维度的数据指标体系,包括用户行为、内容互动、情感倾向等方面,深入挖掘了网站运营的关键信息和用户特征。研究发现,晋江文学城用户群体多元化,情感分析有效提升了内容创作与用户需求的匹配度,同时大数据分析为网站运营决策提供了科学依据。本研究不仅揭示了晋江文学城的现状与趋势,也为网络文学行业的数字化转型提供了有益参考。
关键词: 大数据;晋江文学城;数据采集;情感分析
系统使用收集晋江文学城的基本信息、转发数、点赞数、评论数、博主学习等行为数据的公开数据集,来构建晋江文学城的数据分析。用户可以通过查询条件的方式,让系统实现对相关数据的筛选和查询,并将查询结果在前端以图表的可视化方式展示出来,进而帮助用户理解数据。系统通过对用户数据的分析与挖掘,实现了对于微博的解析和分类,系统提供了直观的晋江文学城数据展示界面,查看到相应的分析结果。
数据采集功能:实现对微博平台公共数据的采集,识别数据来源、区分数据类型,并进行数据完整性的验证,确保数据的准确性以及可靠性。
分布式存储功能:实现对已经处理过的数据进行分布式存储,采用MySQL、HDFS进行对数据的存储,以及支持异构端存储和具备高容错性,高可用性以及易扩展性。
数据分析功能:基于Spark分布式计算框架,实现对存储的数据进行了数据分析和挖掘。
数据可视化功能:使用ECharts、Vue、BootStrap等前端技术,对数据分析结果进行了可视化展示,以图表等可视化方式将数据展示,方便了用户分析和观察。系统功能模块图如图3-1所示。
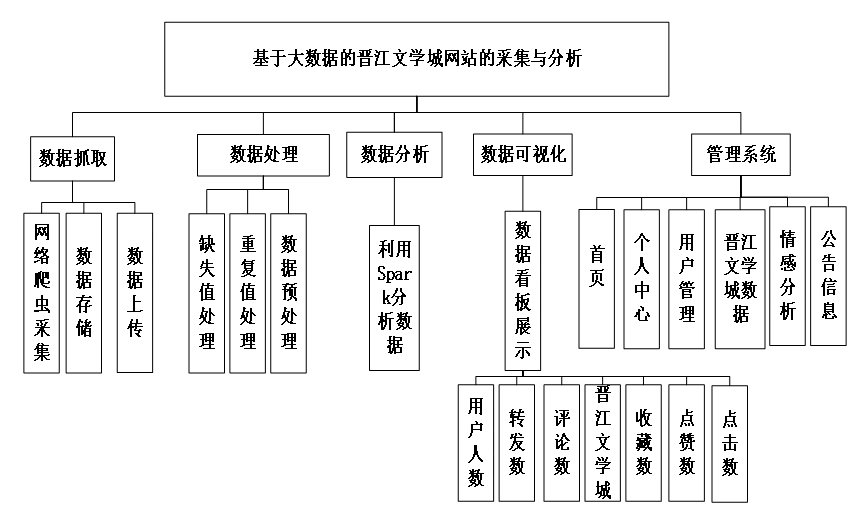
图3-1 系统功能模块图
在数据可视化面板界面可以查看到所有数据的详情。数据看板集成了多个功能模块,为用户提供直观的数据展示和分析能力。数据可视化模块的实现依赖于多种技术的协同工作,使用Python编写的爬虫程序负责从微博网站上抓取海量晋江文学城和评论数据,将这些非结构化数据导入到Hadoop分布式文件系统中进行存储和管理,利用Spark框架对这些大规模数据进行快速的计算和分析,将处理后的结果存入Hive数据库中以方便后续查询和检索,后端采用Django框架搭建Web应用服务器,前端则使用Vue.js库来创建交互式界面,并通过Echarts图表库绘制各种可视化图形。
该数据可视化面板通过多个功能模块展示了晋江文学城的各项关键指标。首先,“用户人数”模块以饼图形式呈现了不同类别的用户分布情况;其次,“转发数”和“评论数”模块分别通过柱状图和折线图直观地反映了社交媒体上的互动情况;“收藏数”模块则显示了作品的受欢迎程度。此外,还有关于“点击数”的信息,提供了对网站流量的深入洞察。这些模块共同构成了一个全面的数据分析平台,有助于更好地理解用户行为和市场趋势。可视化效果图如下所示:
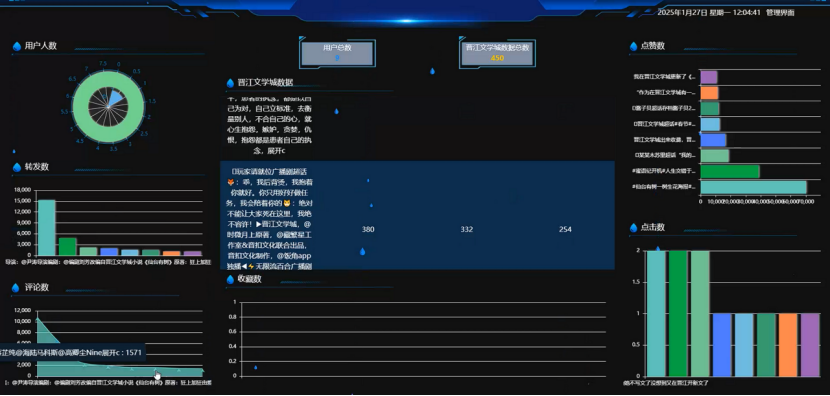
图5-1 数据可视化看板

魔乐社区(Modelers.cn) 是一个中立、公益的人工智能社区,提供人工智能工具、模型、数据的托管、展示与应用协同服务,为人工智能开发及爱好者搭建开放的学习交流平台。社区通过理事会方式运作,由全产业链共同建设、共同运营、共同享有,推动国产AI生态繁荣发展。
更多推荐


 3
3 0
0- 0



 已为社区贡献7条内容
已为社区贡献7条内容

所有评论(0)