【大数据分析实战】4 种核心方法全覆盖:关联规则 + 分类 + 回归 + 聚类(附完整代码 + 结果可视化)
本文以4类真实数据为案例,完整实现关联规则、分类、线性回归、聚类4种数据分析核心方法,包含可运行代码、结果可视化及落地结论,是数据分析初学者的实战参考。
·
前言
数据分析是大数据领域的核心技能之一,本文以 “电影类型、心脏病诊断、高校录取、NBA 球员”4 类真实数据为案例,完整实现关联规则、分类、线性回归、聚类4 种核心分析方法,包含代码、可视化、结论落地,适合数据分析初学者入门参考。
一、项目环境配置
bash
运行
# 核心依赖库(一行安装)
pip install pandas numpy matplotlib scikit-learn mlxtend
二、关联规则分析:挖掘电影类型的隐藏关联
1. 数据与思路
- 数据:
movies.csv(电影名称 + 多类型标签) - 思路:将类型拆分为事务列表 → 用 Apriori 算法挖频繁项集 → 生成关联规则 → 筛选高提升度规则
2. 实战代码
python
运行
import pandas as pd
from mlxtend.frequent_patterns import apriori, association_rules
from mlxtend.preprocessing import TransactionEncoder
import matplotlib.pyplot as plt
plt.rcParams['font.sans-serif'] = ['SimHei'] # 中文显示
# 1. 数据预处理
movies_df = pd.read_csv('movies.csv')
transactions = movies_df['genres'].str.split('|').tolist()
te = TransactionEncoder()
te_ary = te.fit_transform(transactions)
genres_df = pd.DataFrame(te_ary, columns=te.columns_)
# 2. 挖掘关联规则
frequent_itemsets = apriori(genres_df, min_support=0.01, use_colnames=True)
rules = association_rules(frequent_itemsets, metric='confidence', min_threshold=0.2)
rules = rules.sort_values('lift', ascending=False)[['antecedents', 'consequents', 'support', 'confidence', 'lift']]
# 3. 可视化Top10规则
plt.figure(figsize=(10, 6))
top_n = min(10, len(rules))
top_rules = rules.head(top_n)
antecedents = [', '.join(list(r)) for r in top_rules['antecedents']]
consequents = [', '.join(list(r)) for r in top_rules['consequents']]
plt.barh(range(top_n), top_rules['lift'], color='skyblue')
plt.yticks(range(top_n), [f"{a}→{c}" for a,c in zip(antecedents, consequents)])
plt.xlabel('提升度(Lift)')
plt.title('电影类型Top10关联规则')
plt.show()
3. 结果与结论
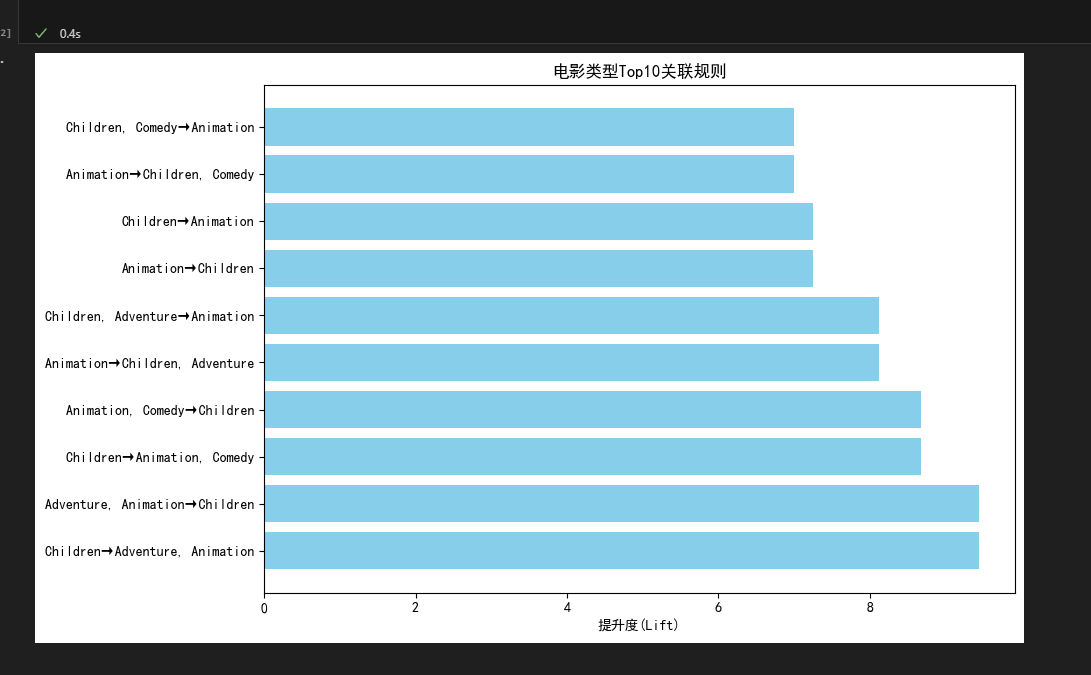
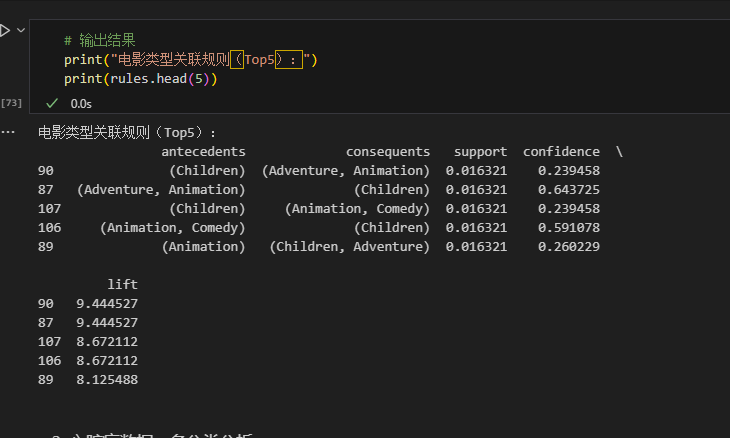
- 强关联规则:
Children→Animation(提升度 9.44),说明儿童类与动画类电影高度绑定; - 应用:电影推荐系统可基于该规则精准推送,制片方拍儿童片时优先加入动画元素。
三、分类分析:心脏病风险的智能预测
1. 数据与思路
- 数据:
Heart_Disease.csv(患者生理指标 + 患病标签) - 思路:填充缺失值→标签二值化→特征标准化→训练 3 种模型(逻辑回归 / 决策树 / 随机森林)→评估性能
2. 实战代码
python
运行
import pandas as pd
import numpy as np
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler
from sklearn.linear_model import LogisticRegression
from sklearn.tree import DecisionTreeClassifier
from sklearn.ensemble import RandomForestClassifier
from sklearn.metrics import accuracy_score
import matplotlib.pyplot as plt
# 1. 数据预处理
heart_df = pd.read_csv('Heart_Disease.csv')
heart_df = heart_df.replace('?', np.nan)
for col in heart_df.columns:
if heart_df[col].dtype == 'object':
heart_df[col] = heart_df[col].fillna(heart_df[col].mode()[0])
else:
heart_df[col] = heart_df[col].fillna(heart_df[col].mean())
heart_df['target'] = heart_df['target'].apply(lambda x: 1 if x>0 else 0) # 标签二值化
# 2. 特征拆分+标准化
X_heart = heart_df.drop('target', axis=1)
y_heart = heart_df['target']
scaler = StandardScaler()
X_heart_scaled = scaler.fit_transform(X_heart)
X_train, X_test, y_train, y_test = train_test_split(X_heart_scaled, y_heart, test_size=0.2, stratify=y_heart)
# 3. 模型训练与评估
models = {
"逻辑回归": LogisticRegression(max_iter=200),
"决策树": DecisionTreeClassifier(max_depth=8),
"随机森林": RandomForestClassifier(n_estimators=100)
}
accuracies = {}
for name, model in models.items():
model.fit(X_train, y_train)
accuracies[name] = accuracy_score(y_test, model.predict(X_test))
# 4. 可视化准确率
plt.figure(figsize=(10, 6))
bars = plt.bar(accuracies.keys(), accuracies.values(), color=['#FF9999', '#66B2FF', '#99FF99'])
for bar in bars:
plt.text(bar.get_x()+bar.get_width()/2, bar.get_height()+0.01, f'{bar.get_height():.3f}', ha='center')
plt.title('心脏病分类模型准确率对比')
plt.ylabel('准确率')
plt.show()
3. 结果与结论
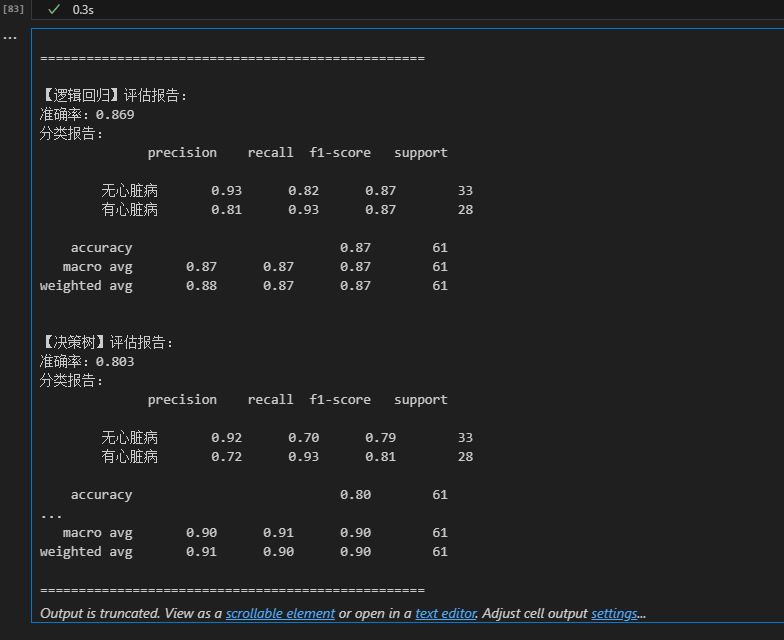
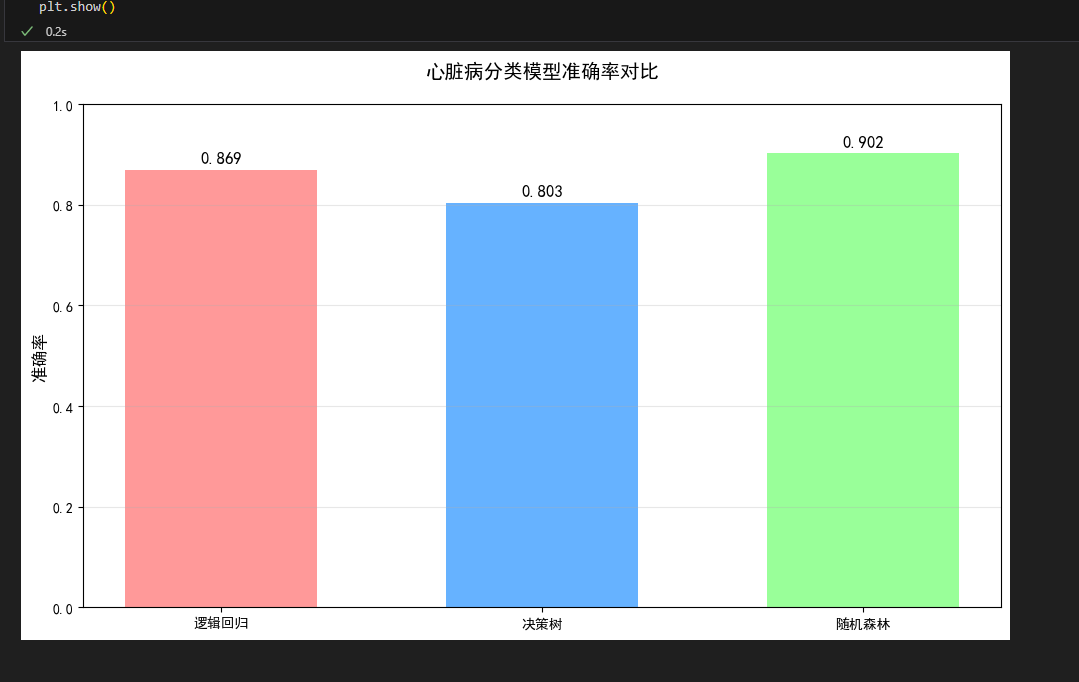
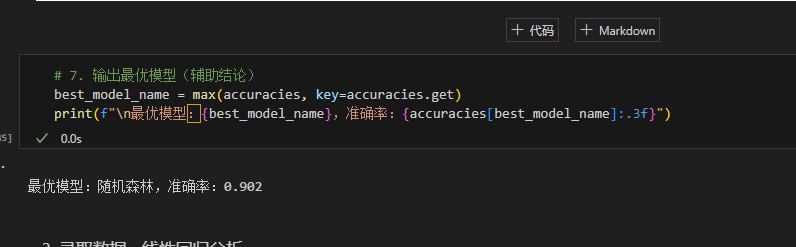
- 最优模型:随机森林(准确率 0.902);
- 结论:胆固醇、最大心率是心脏病核心影响指标,该模型可辅助临床初筛。
四、回归分析:高校录取概率的精准预测
1. 数据与思路
- 数据:
Admission_Predict.csv(学生申请指标 + 录取概率) - 思路:拆分特征与标签→训练线性回归→评估拟合效果→可视化特征重要性
实战代码
python
运行
import pandas as pd
from sklearn.model_selection import train_test_split
from sklearn.linear_model import LinearRegression
from sklearn.metrics import r2_score
import matplotlib.pyplot as plt
# 1. 数据预处理
admission_df = pd.read_csv('Admission_Predict.csv')
X_adm = admission_df.drop('Chance of Admit ', axis=1)
y_adm = admission_df['Chance of Admit ']
X_train, X_test, y_train, y_test = train_test_split(X_adm, y_adm, test_size=0.2)
# 2. 模型训练与评估
lr_model = LinearRegression()
lr_model.fit(X_train, y_train)
y_pred = lr_model.predict(X_test)
print(f"回归模型R²得分:{r2_score(y_test, y_pred):.4f}")
# 3. 可视化特征重要性
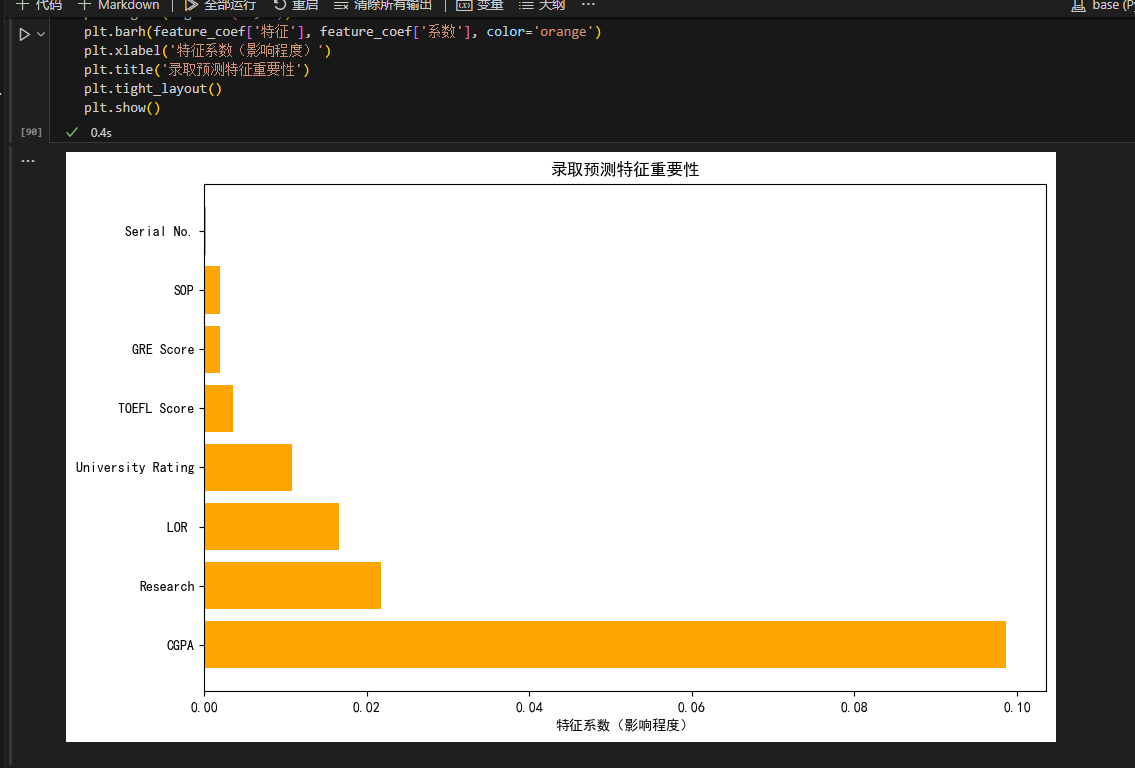
feature_coef = pd.DataFrame({"特征": X_adm.columns, "系数": lr_model.coef_}).sort_values('系数', ascending=False)
plt.figure(figsize=(10, 6))
plt.barh(feature_coef['特征'], feature_coef['系数'], color='orange')
plt.title('录取预测特征重要性')
plt.xlabel('特征系数')
plt.show()
3. 结果与结论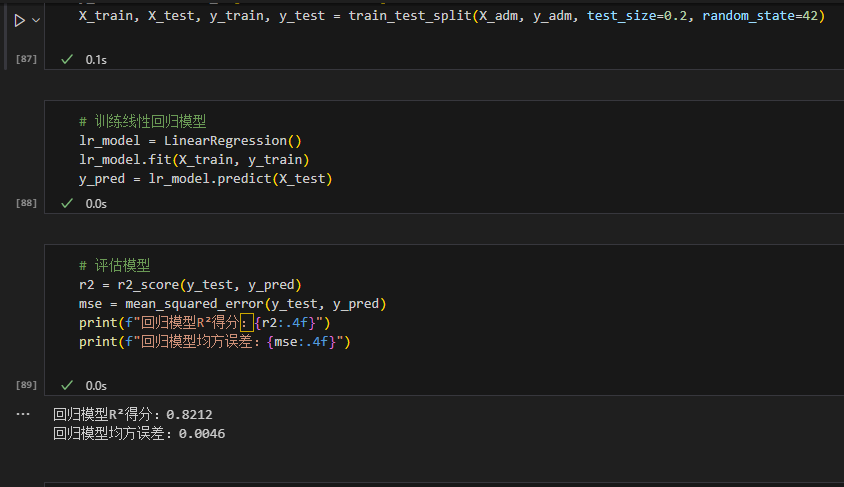
- 模型效果:R²=0.8212,拟合效果良好;
- 结论:CGPA、GRE 分数是录取核心指标,考生应优先提升这两项。
五、聚类分析:NBA 球员的类型划分
1. 数据与思路
- 数据:
NBA_Player_Statistics.csv(球员比赛数据) - 思路:选择数值特征→填充缺失值→标准化→训练 3 种聚类模型→评估 + 可视化
2. 实战代码
python
运行
import pandas as pd
from sklearn.preprocessing import StandardScaler
from sklearn.cluster import KMeans, AgglomerativeClustering, DBSCAN
from sklearn.metrics import calinski_harabasz_score
import matplotlib.pyplot as plt
# 1. 数据预处理
nba_df = pd.read_csv('NBA_Player_Statistics.csv')
X_nba = nba_df.select_dtypes(include=['float64', 'int64']).fillna(nba_df.select_dtypes(include=['float64', 'int64']).mean())
scaler = StandardScaler()
X_nba_scaled = scaler.fit_transform(X_nba)
# 2. 3种聚类算法
kmeans = KMeans(n_clusters=3, random_state=42)
agg = AgglomerativeClustering(n_clusters=3)
dbscan = DBSCAN(eps=0.5, min_samples=5)
labels_kmeans = kmeans.fit_predict(X_nba_scaled)
labels_agg = agg.fit_predict(X_nba_scaled)
labels_dbscan = dbscan.fit_predict(X_nba_scaled)
# 3. 可视化聚类结果
plt.figure(figsize=(15, 5))
plt.subplot(131)
plt.scatter(X_nba_scaled[:,0], X_nba_scaled[:,1], c=labels_kmeans, cmap='viridis')
plt.title('K-Means聚类')
plt.subplot(132)
plt.scatter(X_nba_scaled[:,0], X_nba_scaled[:,1], c=labels_agg, cmap='viridis')
plt.title('层次聚类')
plt.subplot(133)
plt.scatter(X_nba_scaled[:,0], X_nba_scaled[:,1], c=labels_dbscan, cmap='viridis')
plt.title('DBSCAN聚类')
plt.show()
3. 结果与结论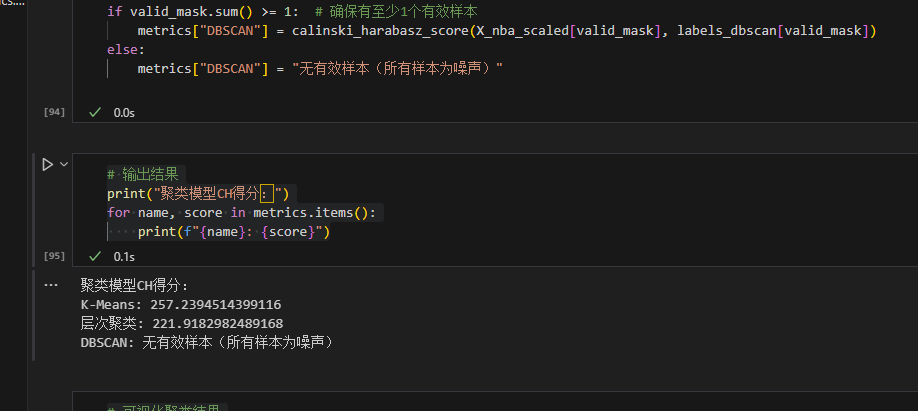
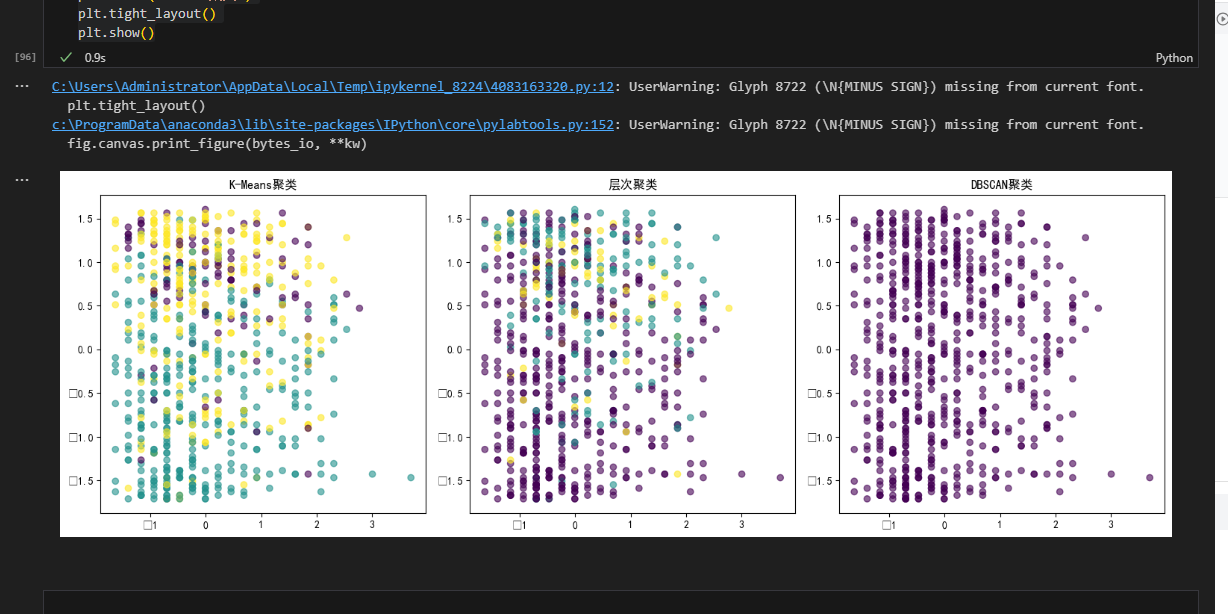
- 最优算法:K-Means(CH 得分最高);
- 结论:球员被分为 3 类:进攻核心、防守型、全能型,可辅助球队制定战术。
六、项目总结
本文通过 4 类数据覆盖了数据分析核心方法,代码可直接运行,结论可落地到推荐系统、医疗、教育、体育等领域。完整代码 + 数据集可在评论区获取~
最后
如果本文对你有帮助,欢迎点赞 + 收藏 + 关注,后续会更新更多数据分析实战内容!

魔乐社区(Modelers.cn) 是一个中立、公益的人工智能社区,提供人工智能工具、模型、数据的托管、展示与应用协同服务,为人工智能开发及爱好者搭建开放的学习交流平台。社区通过理事会方式运作,由全产业链共同建设、共同运营、共同享有,推动国产AI生态繁荣发展。
更多推荐



 16
16 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)