行人重识别(Deep-Person-ReID)自定义数据集制作及训练全流程(包含利用自己的原始数据制作ReID数据集)
本文详细介绍了行人重识别(ReID)从数据集制作到模型训练的全流程。主要内容包括:1)将原始数据集转换为Market1501标准格式的脚本实现;2)Deep-Person-ReID框架的环境配置与训练参数详解;3)模型训练、测试评估及结果可视化方法;4)常见问题解决方案。文章提供了完整的Python代码实现数据格式转换,并详细解析了训练配置参数,帮助读者快速构建自己的ReID系统。
前言

行人重识别(Person Re-identification)作为计算机视觉领域的重要研究方向,在实际应用中具有重要意义。本文将详细介绍如何使用Deep-Person-ReID框架训练自己的行人重识别模型,并分享如何将原始数据集制作成Market1501格式的自定义数据集。
如果不需要制作自己的数据集,仅利用开源数据集Market1501复现Deep-Person-ReID可参考我的上一篇博客行人重识别(Deep-Person-ReID)环境搭建与实战教程:从环境配置到模型训练测试![]() https://blog.csdn.net/m0_57010556/article/details/156327717?spm=1001.2014.3001.5501
https://blog.csdn.net/m0_57010556/article/details/156327717?spm=1001.2014.3001.5501
一、数据集准备与格式转换
1.1 原始数据结构分析
原始数据集/
├── person_001/
│ ├── camera1_001.jpg
│ ├── camera1_007.jpg
│ ├── camera2_005.jpg
│ ├── camera2_009.jpg
│ ├── camera3_012.jpg
│ └── ...
├── person_002/
│ ├── camera1_003.jpg
│ ├── camera1_005.jpg
│ ├── camera2_008.jpg
│ └── ...
└── ...每个文件夹代表一个行人ID,内含不同摄像头拍摄的该行人图像。person_001/camera1_001.jpg代表camera1拍摄的第一个行人的001帧。
1.2 Market1501格式详解
Market1501标准格式要求:
Market1501/
├── bounding_box_train/ # 训练集
├── bounding_box_test/ # 测试集
├── query/ # 查询集
└── gt_bbox/ # 手工标注框(可选)命名规则:
pid_cXsY_frameid_序号.jpg
-
pid: 行人ID(从0001开始)
-
cXsY: X是摄像头ID,Y是序列号,例如c1s1
-
frameid: 6位数帧号
-
序号: 同一场景中的不同检测框编号
1.3 数据格式转换脚本
import os
import shutil
import random
from pathlib import Path
import argparse
import json
from collections import defaultdict
def parse_your_structure(root_path):
"""
解析原始数据结构
结构:
├── person_001/ # 行人ID
│ ├── camera1_001.jpg # 摄像头1拍摄
│ ├── camera1_007.jpg # 摄像头1,不同时间
│ ├── camera2_005.jpg # 摄像头2
│ └── ...
└── person_002/
├── camera1_003.jpg
└── ...
"""
data_records = []
# 遍历所有行人文件夹
for person_dir in os.listdir(root_path):
person_path = os.path.join(root_path, person_dir)
if not os.path.isdir(person_path):
continue
# 提取行人ID(从person_001中提取001)
if person_dir.startswith('person_'):
person_id_str = person_dir.replace('person_', '')
else:
person_id_str = person_dir
# 行人ID作为person_id
try:
person_id = int(person_id_str)
except ValueError:
print(f"跳过非标准文件夹: {person_dir}")
continue
# 遍历行人文件夹内的所有图片
for img_file in os.listdir(person_path):
if not img_file.lower().endswith(('.jpg', '.jpeg', '.png')):
continue
img_path = os.path.join(person_path, img_file)
# 解析文件名
# 格式:camera1_001.jpg 或 camera2_005.jpg
parts = img_file.split('_')
if len(parts) >= 2:
# 提取摄像头信息(例如:camera1)
camera_part = parts[0] # camera1
# 提取摄像头编号
camera_id = ""
for char in camera_part:
if char.isdigit():
camera_id = char
break
if not camera_id:
camera_id = "1" # 默认摄像头ID
# 提取图片序号
img_num = parts[1].split('.')[0]
data_records.append({
'src_path': img_path,
'original_person_id': person_id_str,
'person_id': person_id, # 数字ID
'camera_id': camera_id,
'img_num': img_num,
'person_dir': person_dir
})
return data_records
def assign_person_ids(records):
"""
分配行人ID
使用原始person_id,但转换为连续的数字ID
"""
person_to_pid = {}
pid_counter = 0
# 先按行人ID排序,确保一致性
unique_persons = sorted(set([r['person_id'] for r in records]))
for person in unique_persons:
person_to_pid[person] = pid_counter
pid_counter += 1
# 分配数字ID
for record in records:
record['person_id'] = person_to_pid[record['original_person_id']]
return records, pid_counter, person_to_pid
def assign_camera_ids(records):
"""
分配摄像头ID(1, 2, 3...)
"""
camera_mapping = {}
# Market-1501要求1 <= camid <= 6
cam_id = 1
# 先找到所有不同的摄像头
all_cameras = sorted(set([r['camera_id'] for r in records]))
for camera in all_cameras:
camera_mapping[camera] = cam_id
cam_id += 1
# 为每条记录分配摄像头ID
for record in records:
record['camera_id_num'] = camera_mapping[record['camera_id']]
return records, camera_mapping
def convert_to_market1501(records, output_dir, person_to_pid, camera_mapping):
"""
转换为Market-1501格式
严格按照Market-1501的标准划分:
1. 按行人ID划分训练集和测试集(约8:2)
2. 测试集行人:至少1张查询图片,其余为图库图片,测试集行人id与查询集行人id保持一致
"""
# 创建Market-1501-v15.09.15目录结构
market1501_dir = os.path.join(output_dir, "market1501")
train_dir = os.path.join(market1501_dir, "bounding_box_train")
test_dir = os.path.join(market1501_dir, "bounding_box_test")
query_dir = os.path.join(market1501_dir, "query")
for dir_path in [market1501_dir, train_dir, test_dir, query_dir]:
os.makedirs(dir_path, exist_ok=True)
# 按person_id分组
person_groups = defaultdict(list)
for record in records:
person_groups[record['person_id']].append(record)
print(f"总行人数: {len(person_groups)}")
# 检查每个行人的图片数量
person_stats = []
for pid, items in person_groups.items():
person_stats.append((pid, len(items)))
# 按图片数量排序
person_stats.sort(key=lambda x: x[1])
print(f"每个行人的图片数量统计:")
print(f" 最少: {person_stats[0][1]} 张")
print(f" 最多: {person_stats[-1][1]} 张")
print(f" 平均: {sum(x[1] for x in person_stats) / len(person_stats):.1f} 张")
# 筛选出有足够图片的行人(至少2张才能划分查询和图库)
min_images_for_test = 2 # 测试集行人至少需要2张图片
valid_persons = {pid: items for pid, items in person_groups.items()
if len(items) >= min_images_for_test}
print(f"有效行人(图片数≥{min_images_for_test}): {len(valid_persons)}")
# 获取所有有效行人ID
valid_person_ids = sorted(valid_persons.keys())
# 划分训练集和测试集(8:2比例)
split_idx = int(len(valid_person_ids) * 0.8)
train_person_ids = valid_person_ids[:split_idx]
test_person_ids = valid_person_ids[split_idx:]
print(f"\n数据集划分:")
print(f" 训练集行人: {len(train_person_ids)}")
print(f" 测试集行人: {len(test_person_ids)}")
# 收集训练集数据
train_records = []
for pid in train_person_ids:
train_records.extend(valid_persons[pid])
# 收集测试集数据(查询+图库)
test_records = [] # bounding_box_test(图库)
query_records = [] # query(查询)
for pid in test_person_ids:
items = valid_persons[pid]
# 按摄像头分组
cam_groups = defaultdict(list)
for item in items:
cam_groups[item['camera_id_num']].append(item)
# 策略:每个摄像头选择1张作为查询(如果可能)
query_for_person = []
for cam_id, cam_items in cam_groups.items():
if cam_items:
# 从该摄像头随机选择1张作为查询
random.shuffle(cam_items)
query_item = cam_items[0]
query_item['is_query'] = True # 标记为查询图片
query_for_person.append(query_item)
# 如果没有任何摄像头有图片,则随机选择1张
if not query_for_person and items:
query_item = items[0]
query_item['is_query'] = True
query_for_person.append(query_item)
# 添加到查询集
query_records.extend(query_for_person)
# 所有图片都添加到图库集(包括查询图片)
# 在Market-1501中,查询图片也出现在图库中
test_records.extend(items)
print(f"\n图片数量统计:")
print(f" 训练集: {len(train_records)} 张图片")
print(f" 查询集: {len(query_records)} 张图片")
print(f" 图库集: {len(test_records)} 张图片")
# 检查查询图片是否都在图库中
query_paths = set(r['src_path'] for r in query_records)
test_paths = set(r['src_path'] for r in test_records)
missing_in_gallery = query_paths - test_paths
if missing_in_gallery:
print(f"警告: {len(missing_in_gallery)} 张查询图片不在图库中")
# 将缺失的查询图片添加到图库
for record in query_records:
if record['src_path'] in missing_in_gallery:
test_records.append(record.copy())
print(f" 已添加到图库,现在图库集: {len(test_records)} 张图片")
else:
print("所有查询图片都在图库中")
# 辅助函数:确保frame_id是6位数字
def format_frame_id(frame_id, default_id):
"""格式化frame_id为6位数字"""
try:
frame_num = int(frame_id)
return f"{frame_num:06d}"
except (ValueError, TypeError):
return f"{default_id:06d}"
# 重命名并复制文件
def copy_and_rename(records, target_dir):
"""
重命名并复制文件
"""
# 为每个(person_id, camera_id)组合维护序号计数器
sequence_counters = defaultdict(lambda: 1)
for idx, record in enumerate(records):
# Market-1501命名格式: pid_cXsY_frameid_序号.jpg
pid = f"{record['person_id']:04d}" # 4位行人ID
camid = record['camera_id_num'] # 摄像头ID
# 获取frame_id
frame_id = record.get('img_num', str(idx))
formatted_frame_id = format_frame_id(frame_id, idx)
# 生成序号
key = (record['person_id'], record['camera_id_num'])
sequence_num = sequence_counters[key]
formatted_sequence = f"{sequence_num:02d}"
sequence_counters[key] += 1
# 构建完整文件名: pid_cXsY_frameid_序号.jpg
# 注意:序列号固定为1(s1),因为我们没有多个序列
new_name = f"{pid}_c{camid}s1_{formatted_frame_id}_{formatted_sequence}.jpg"
target_path = os.path.join(target_dir, new_name)
# 复制文件
shutil.copy2(record['src_path'], target_path)
# 更新记录中的新路径(用于调试)
record['new_path'] = target_path
print(f" {target_dir}: 已保存 {len(records)} 张图片")
# 复制文件到各个目录
print("\n复制文件...")
copy_and_rename(train_records, train_dir)
copy_and_rename(test_records, test_dir)
copy_and_rename(query_records, query_dir)
# 保存映射关系
meta_info = {
"total_persons": len(person_groups),
"valid_persons": len(valid_persons),
"total_images": len(records),
"camera_mapping": camera_mapping,
"person_to_pid": person_to_pid,
"dataset_split": {
"train_persons": len(train_person_ids),
"test_persons": len(test_person_ids),
"train_images": len(train_records),
"query_images": len(query_records),
"gallery_images": len(test_records)
},
"file_naming": {
"format": "pid_cXsY_frameid_sequence.jpg",
"example": "0001_c1s1_000001_01.jpg",
"note": "s1表示序列号1(固定)"
}
}
meta_path = os.path.join(market1501_dir, "meta_info.json")
with open(meta_path, 'w', encoding='utf-8') as f:
json.dump(meta_info, f, indent=2, ensure_ascii=False)
print(f"元信息已保存: {meta_path}")
# 保存划分信息
split_info = {
"train_persons": sorted(set([r['person_dir'] for r in train_records])),
"test_persons": sorted(set([r['person_dir'] for r in test_records])),
"query_persons": sorted(set([r['person_dir'] for r in query_records]))
}
split_path = os.path.join(market1501_dir, "split_info.json")
with open(split_path, 'w', encoding='utf-8') as f:
json.dump(split_info, f, indent=2, ensure_ascii=False)
print(f"划分信息已保存: {split_path}")
# 打印一些示例文件名
print("\n示例文件名:")
if train_records:
sample = os.path.basename(train_records[0].get('new_path', ''))
print(f" 训练集: {sample}")
if query_records:
sample = os.path.basename(query_records[0].get('new_path', ''))
print(f" 查询集: {sample}")
if test_records:
sample = os.path.basename(test_records[0].get('new_path', ''))
print(f" 图库集: {sample}")
# 打印最终统计
print(f"\n最终数据集结构:")
print(f" 数据集目录: {market1501_dir}")
print(f" 训练集图片: {len(train_records)} 张")
print(f" 查询集图片: {len(query_records)} 张")
print(f" 图库集图片: {len(test_records)} 张")
print(f" 查询/图库比例: {len(query_records)}/{len(test_records)} = {len(query_records)/len(test_records)*100:.1f}%")
return market1501_dir
def main():
parser = argparse.ArgumentParser(description='转换数据集为Market-1501格式')
parser.add_argument('--input', type=str, required=True,
help='输入数据集根目录(包含行人文件夹)')
parser.add_argument('--output', type=str, default='./reid_datasets',
help='输出目录')
parser.add_argument('--seed', type=int, default=42, help='随机种子,确保可重复性')
parser.add_argument('--train-ratio', type=float, default=0.8,
help='训练集比例(默认0.8,测试集比例=1-train_ratio)')
args = parser.parse_args()
# 设置随机种子
random.seed(args.seed)
# 1. 解析原始数据
print("=" * 60)
print("正在解析数据结构...")
records = parse_your_structure(args.input)
print(f"找到 {len(records)} 张图片")
if len(records) == 0:
print("错误:没有找到任何图片文件!")
print("请检查输入路径和文件格式")
return
# 2. 分配ID
print("\n分配行人ID和摄像头ID...")
records, num_persons, person_to_pid = assign_person_ids(records)
records, camera_mapping = assign_camera_ids(records)
print(f"共 {num_persons} 个不同行人")
print(f"共 {len(camera_mapping)} 个摄像头视角")
print("摄像头映射:", camera_mapping)
# 3. 转换格式
print("\n" + "=" * 60)
print("转换为Market-1501格式...")
market1501_dir = convert_to_market1501(records, args.output, person_to_pid, camera_mapping)
print("\n" + "=" * 60)
print("转换完成!")
print(f"数据集已创建到: {market1501_dir}")
print(f"\n目录结构:")
print(f" {market1501_dir}/")
print(f" ├── bounding_box_train/ # 训练集")
print(f" ├── bounding_box_test/ # 图库集")
print(f" ├── query/ # 查询集")
print(f" ├── meta_info.json # 元信息")
print(f" └── split_info.json # 划分信息")
print(f"\n使用时,请将数据集路径设置为: {market1501_dir}")
if __name__ == "__main__":
main()二、Deep-Person-ReID环境配置
具体训练环境配置细节可以参考我的上一篇博客
2.1 克隆仓库
git clone https://github.com/zhunzhong07/Deep-Person-ReID.git
cd Deep-Person-ReID2.2 安装依赖
# 创建conda环境(可选)
conda create -n reid python=3.10
conda activate reid
# 安装PyTorch(根据你的CUDA版本)
pip install torch==2.4.1 torchvision==0.19.1 torchaudio==2.4.1 --index-url https://download.pytorch.org/whl/cu124
# 安装其他依赖
pip install -r requirements.txt
# 安装额外的包
pip install scikit-learn matplotlib tqdm tensorboard三、模型训练
3.1 修改训练参数
在deep-person-reid/scripts/下有两个python文件
default_config.py 模型训练/测试参数配置;
main.py 模型启动训练/测试。
主要修改default_config.py中get_default_config()函数的相关参数来实现相关配置,下面详细解读一下相关配置参数。
# model - 模型配置
cfg.model = CN()
cfg.model.name = 'osnet_x1_0' # 模型名称,可选:'resnet50', 'resnet101', 'osnet_x1_0', 'mobilenetv2_x1_0', 'vit_base_patch16_224'等
cfg.model.pretrained = True # 是否使用ImageNet预训练权重,True自动下载,False随机初始化
cfg.model.load_weights = "/home/project/deep-person-reid/models/osnet_x1_0_imagenet.pth" # 手动指定预训练权重文件路径(.pth格式),优先级高于pretrained
cfg.model.resume = '' # 恢复训练检查点路径(包含模型、优化器、epoch等信息),用于断点续训
# data - 数据配置
cfg.data = CN()
cfg.data.type = 'image' # 数据类型:'image'图像ReID 或 'video'视频ReID
cfg.data.root = 'reid-data' # 数据集根目录路径,改为你的实际路径如:'/home/user/datasets'
cfg.data.sources = ['market1501'] # 训练数据集列表,支持多个:['market1501', 'duke', 'msmt17']
cfg.data.targets = ['market1501'] # 测试数据集列表,可与sources相同(同域)或不同(跨域)
cfg.data.workers = 8 # 数据加载线程数,建议4-8(根据CPU核心数)
cfg.data.split_id = 0 # 数据集划分ID,某些数据集(如CUHK03)有多个划分,通常用0
cfg.data.height = 256 # 输入图像高度,常用:256、384、512
cfg.data.width = 128 # 输入图像宽度,常用:128、192、256,保持高宽比≈2:1
cfg.data.combineall = False # 是否合并所有数据训练,True:训练集+查询集+画廊集;False:仅训练集
cfg.data.transforms = ['random_flip'] # 数据增强列表,可选:'random_flip','random_crop','color_jitter','random_erase'(可组合)
cfg.data.k_tfm = 1 # 增强重复次数,1:每图增强一次;>1:每图独立增强多次生成多视图
cfg.data.norm_mean = [0.485, 0.456, 0.406] # 图像归一化均值(ImageNet标准)
cfg.data.norm_std = [0.229, 0.224, 0.225] # 图像归一化标准差(ImageNet标准)
cfg.data.save_dir = 'log' # 训练日志和模型保存目录,建议改为具体路径如:'log/resnet50_market1501'
cfg.data.load_train_targets = False # 是否加载目标域训练数据,用于域适应(跨数据集)场景
# specific datasets - 数据集特定配置
cfg.market1501 = CN()
cfg.market1501.use_500k_distractors = False # Market1501:是否使用包含50万干扰项的扩展画廊集(难度更大)
cfg.cuhk03 = CN()
cfg.cuhk03.labeled_images = False # CUHK03:使用标注框(True)还是检测框(False),标注框更准,检测框更真实
cfg.cuhk03.classic_split = False # CUHK03:使用经典划分(767/700)还是新划分(1367/100)
cfg.cuhk03.use_metric_cuhk03 = False # CUHK03:使用原始评估指标(一对一)还是标准指标
# sampler - 采样器配置
cfg.sampler = CN()
cfg.sampler.train_sampler = 'RandomSampler' # 源域训练采样器:'RandomSampler'随机,'RandomIdentitySampler'按ID,'RandomDomainSampler'按相机
cfg.sampler.train_sampler_t = 'RandomSampler' # 目标域训练采样器(域适应场景)
cfg.sampler.num_instances = 4 # RandomIdentitySampler:每个ID采样的图像数,batch_size = num_ids × num_instances
cfg.sampler.num_cams = 1 # RandomDomainSampler:每批包含的相机数
cfg.sampler.num_datasets = 1 # RandomDatasetSampler:每批包含的数据集数
# video reid setting - 视频ReID配置
cfg.video = CN()
cfg.video.seq_len = 15 # 每个视频片段采样的帧数,典型值:4-32
cfg.video.sample_method = 'evenly' # 采样方法:'evenly'均匀,'random'随机,'dense'密集(测试用)
cfg.video.pooling_method = 'avg' # 多帧特征聚合方法:'avg'平均池化,'max'最大池化,'attention'注意力池化
# train - 训练配置
cfg.train = CN()
cfg.train.optim = 'adam' # 优化器:'adam'(推荐)、'sgd'、'amsgrad'、'adagrad'、'rmsprop'
cfg.train.lr = 0.0003 # 初始学习率,Adam典型值:0.0001-0.001,SGD:0.01-0.1
cfg.train.weight_decay = 5e-4 # 权重衰减(L2正则化),防止过拟合,范围:1e-4 ~ 5e-4
cfg.train.max_epoch = 60 # 最大训练轮数,根据数据集调整:小数据集60-80,大数据集40-60
cfg.train.start_epoch = 0 # 起始轮数,恢复训练时自动设置
cfg.train.batch_size = 128 # 训练批次大小,根据GPU显存调整:4GB→16,6GB→32,8GB→64,11GB→128
cfg.train.fixbase_epoch = 0 # 固定基础层的轮数,0:不固定;>0:前N轮只训练分类层
cfg.train.open_layers = ['classifier'] # 固定基础层时,可训练的层列表,通常为分类器
cfg.train.staged_lr = False # 是否使用分层学习率,True:不同层不同学习率;False:所有层相同
cfg.train.new_layers = ['classifier'] # staged_lr=True时,新添加的层(使用基础学习率)
cfg.train.base_lr_mult = 0.1 # staged_lr=True时,基础层学习率乘数,base_lr = lr × base_lr_mult
cfg.train.lr_scheduler = 'single_step' # 学习率调度器:'single_step'单步,'multi_step'多步,'cosine'余弦,'linear'线性
cfg.train.stepsize = [20] # 学习率下降的轮数,如:[20]在第20轮下降,[20,40]在第20和40轮下降
cfg.train.gamma = 0.1 # 学习率下降倍数,新学习率 = 旧学习率 × gamma
cfg.train.print_freq = 20 # 日志打印频率(每N个batch打印一次),建议:20-50
cfg.train.seed = 1 # 随机种子,确保实验可复现
# optimizer - 优化器详细参数
cfg.sgd = CN()
cfg.sgd.momentum = 0.9 # SGD动量参数,范围:0.0-1.0,典型值:0.9
cfg.sgd.dampening = 0. # SGD动量阻尼,通常为0
cfg.sgd.nesterov = False # 是否使用Nesterov动量,True:使用;False:不使用
cfg.rmsprop = CN()
cfg.rmsprop.alpha = 0.99 # RMSprop平滑常数
cfg.adam = CN()
cfg.adam.beta1 = 0.9 # Adam一阶矩估计指数衰减率,通常0.9
cfg.adam.beta2 = 0.999 # Adam二阶矩估计指数衰减率,通常0.999
# loss - 损失函数配置
cfg.loss = CN()
cfg.loss.name = 'softmax' # 损失函数类型:'softmax'交叉熵,'triplet'三元组,'softmax_triplet'混合损失
cfg.loss.softmax = CN()
cfg.loss.softmax.label_smooth = True # 是否使用标签平滑,True:防止过拟合;False:标准交叉熵
cfg.loss.triplet = CN()
cfg.loss.triplet.margin = 0.3 # Triplet损失边界值,典型值:0.3-1.0,值越大对困难样本惩罚越大
cfg.loss.triplet.weight_t = 1. # Triplet损失权重(多任务学习时调整)
cfg.loss.triplet.weight_x = 0. # 交叉熵损失权重(混合损失时使用),如:softmax_triplet需设为1.0
# test - 测试配置
cfg.test = CN()
cfg.test.batch_size = 100 # 测试批次大小,可设较大(不计算梯度)
cfg.test.dist_metric = 'euclidean' # 距离度量:'euclidean'欧氏距离,'cosine'余弦距离(推荐)
cfg.test.normalize_feature = False # 是否对特征向量L2归一化,True:提高余弦距离鲁棒性;False:原始特征
cfg.test.ranks = [1, 5, 10, 20] # CMC评估的rank值,Rank-k:前k个结果包含目标的概率
cfg.test.evaluate = False # 是否仅测试不训练,True:测试模式;False:训练+测试模式
cfg.test.eval_freq = -1 # 评估频率(每N个epoch评估一次),-1:仅训练后评估;10:每10轮评估
cfg.test.start_eval = 0 # 开始评估的轮数,0:从第0轮开始;20:前20轮不评估
cfg.test.rerank = True # 是否使用重排序技术,True:显著提高mAP但计算量大;False:不使用
cfg.test.visrank = True # 是否可视化排序结果,True:生成可视化图像;False:不生成
cfg.test.visrank_topk = 10 # 可视化结果展示的前K个,典型值:10-203.2 启动训练
cd scripts
python main.py脚本启动后会输出训练参数以及详细环境信息,然后开始训练
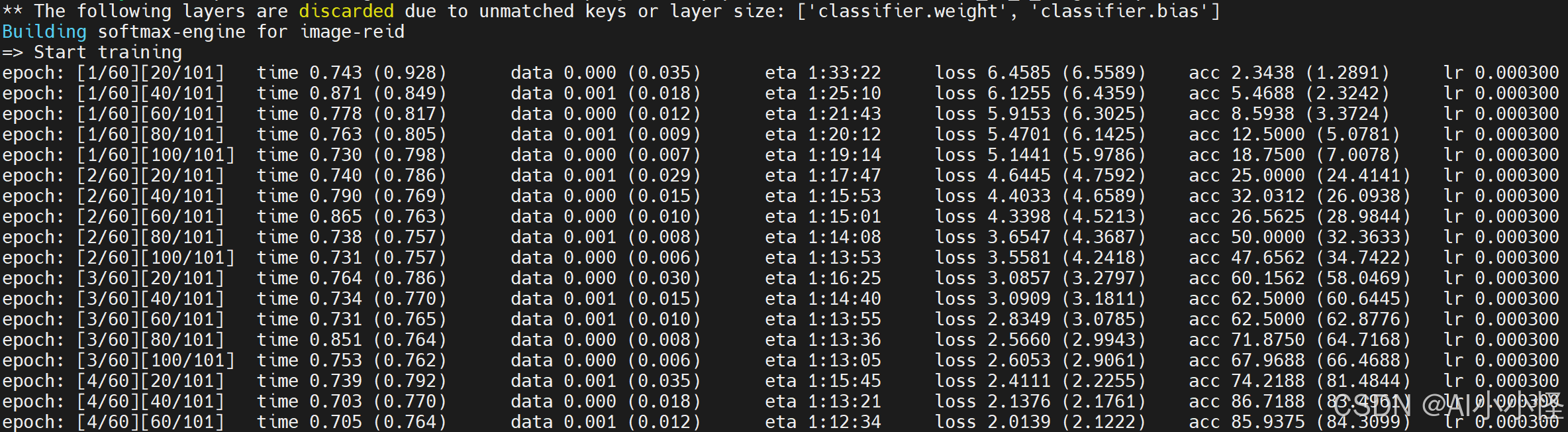
训练完成,权重自动保存
四、模型测试与评估
4.1 执行测试
修改default_config.py中get_default_config函数里的两处参数
cfg.model.load_weights = "/home/project/deep-person-reid/runs/osnet_x1_0_market1501/model/model.pth.tar-60"
cfg.test.evaluate = True # 启用测试模式
cfg.test.visrank = True # 启用可视化
运行测试
python main.py
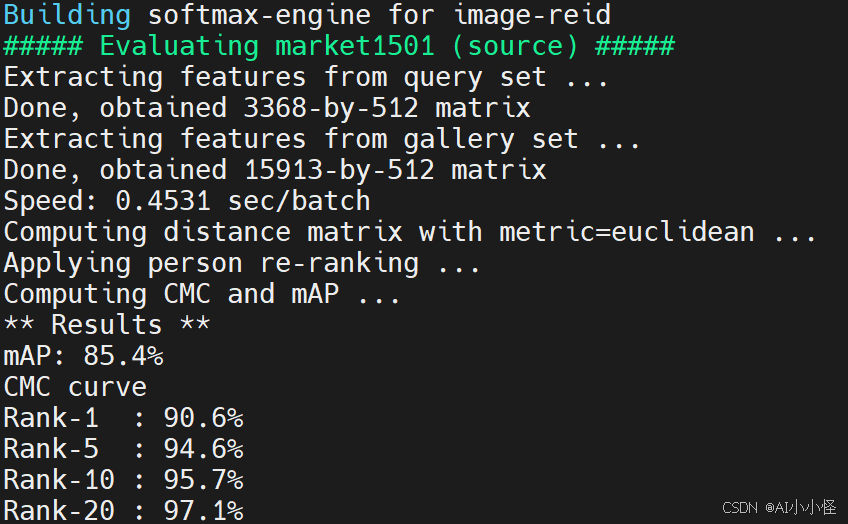
4.2 数据解读
-
mAP: 85.4% - 平均精度均值
-
这是ReID最重要的指标,衡量整体检索性能
-
85.4% 在 Market1501 上是非常不错的结果(SOTA在90%+,但需要复杂模型和技巧)
-
-
Rank-1: 90.6% - 首位命中率
-
查询图片在第一个结果就找到正确行人的概率
-
90.6% 是非常好的结果!
-
-
Rank-5: 94.6% - 前5命中率
-
前5个结果中包含正确行人的概率
-
94.6% 表示几乎总能找到
-
-
Rank-10: 95.7% - 前10命中率
-
前10个结果中包含正确行人的概率
-
-
Rank-20: 97.1% - 前20命中率
-
前20个结果中包含正确行人的概率
-
如果想提高测试精度可以修改以下参数
cfg.test.rerank = True # 启用重排序 (rerank),开启后可以提高mAP 5-10个百分点,但速度会降低
cfg.test.dist_metric = 'cosine' # 通常比euclidean更好
cfg.test.normalize_feature = True # 特征归一化4.3 测试结果可视化
在visrank_market1501中查看可视化测试结果






五、常见问题与解决方案
5.1 训练问题
Q1:训练过程中loss不下降
-
检查学习率是否过大或过小
-
验证数据预处理是否正确
-
检查模型初始化参数
Q2:过拟合
-
增加数据增强(随机翻转、裁剪、颜色抖动)
-
添加Dropout层
-
使用更小的模型或减少参数
-
早停策略
5.2 数据集问题
Q3:ID数量不足
# 数据增强策略
transform_train = T.Compose([
T.RandomHorizontalFlip(p=0.5),
T.Pad(10),
T.RandomCrop((256, 128)),
T.ColorJitter(brightness=0.1, contrast=0.1, saturation=0.1, hue=0),
T.RandomRotation(10),
T.ToTensor(),
T.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225])
])5.3 性能优化
Q4:提升模型精度
-
使用更强大的backbone(如ResNet101、IBN-Net)
-
添加注意力机制
-
使用多尺度特征融合
-
尝试不同的损失函数组合
六、总结
本文详细介绍了从数据集制作到模型训练的全流程,关键步骤包括:
-
数据集准备:严格按照Market1501格式组织数据
-
环境配置:确保所有依赖正确安装
-
模型训练:合理设置超参数,监控训练过程
-
评估测试:使用标准指标评估模型性能
-
应用部署:提取特征并进行相似度计算
通过以上流程,你可以成功训练自己的行人重识别模型。在实际应用中,建议根据具体场景调整数据预处理、模型架构和训练策略。
参考资料
如果觉得本文有帮助,欢迎点赞收藏!有任何问题可以在评论区留言讨论。

魔乐社区(Modelers.cn) 是一个中立、公益的人工智能社区,提供人工智能工具、模型、数据的托管、展示与应用协同服务,为人工智能开发及爱好者搭建开放的学习交流平台。社区通过理事会方式运作,由全产业链共同建设、共同运营、共同享有,推动国产AI生态繁荣发展。
更多推荐


 18
18 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)