LLM应用喂饭教程:使用 Easy Dataset 制作问答数据集
在当今人工智能快速发展的时代,大型语言模型(LLM)的应用越来越广泛。为了使这些模型更好地适应特定领域和任务,微调成为了一种重要的方法。而高质量的问答数据集是微调模型的关键。Easy Dataset 是一款强大的工具,能够帮助用户高效地创建用于微调 LLM 的问答数据集。以下是使用 Easy Dataset 制作问答数据集的具体步骤。
一、工具简介
Easy Dataset 是一款专为创建 LLM 微调数据集而设计的应用程序。它提供了直观的界面,支持多种文档格式(如 PDF、Markdown、DOCX 等)的智能识别与处理,能够智能分割文本、生成问题,并利用 LLM API 生成答案。该工具支持多种导出格式,兼容所有遵循 OpenAI 格式的 LLM API,适用于技术与非技术用户。
二、安装与部署
(一)前提条件
确保本地开发环境已安装 Node.js 和 npm(Node Package Manager),以满足 Easy Dataset 的运行需求。此外,Docker 用户需提前安装好 Docker 环境。
(二)安装步骤
1. 通过 NPM 安装 :
克隆 Easy Dataset 仓库到本地:`git clone https://github.com/ConardLi/easy-dataset.git`,进入项目目录 `cd easy-dataset`。
安装项目依赖:运行 `npm install` 命令,该命令会根据项目配置自动下载所需的依赖包,包括各种前端组件库、后端服务框架等,为项目运行提供基础支持。
启动开发服务器:依次执行 `npm run build`(构建项目,将源代码编译成可执行的文件)和 `npm run start`(启动服务器),在开发模式下运行 Easy Dataset 应用程序。在浏览器中访问 `http://localhost:1717`,即可进入 Easy Dataset 的界面,开始使用。
2. 使用 Docker 部署 :
克隆仓库后,利用项目根目录下的 Dockerfile 构建 Docker 镜像:`docker build -t easy-dataset .`。
运行 Docker 容器:`docker run -d -p 1717:1717 -v {YOUR_LOCAL_DB_PATH}:/app/local-db --name easy-dataset easy-dataset`,其中需将 `{YOUR_LOCAL_DB_PATH}` 替换为实际用于存储本地数据库的路径。这样可以将容器内的数据库数据挂载到本地目录,便于数据的持久化存储和管理。同样通过浏览器访问 `http://localhost:1717` 使用应用程序。
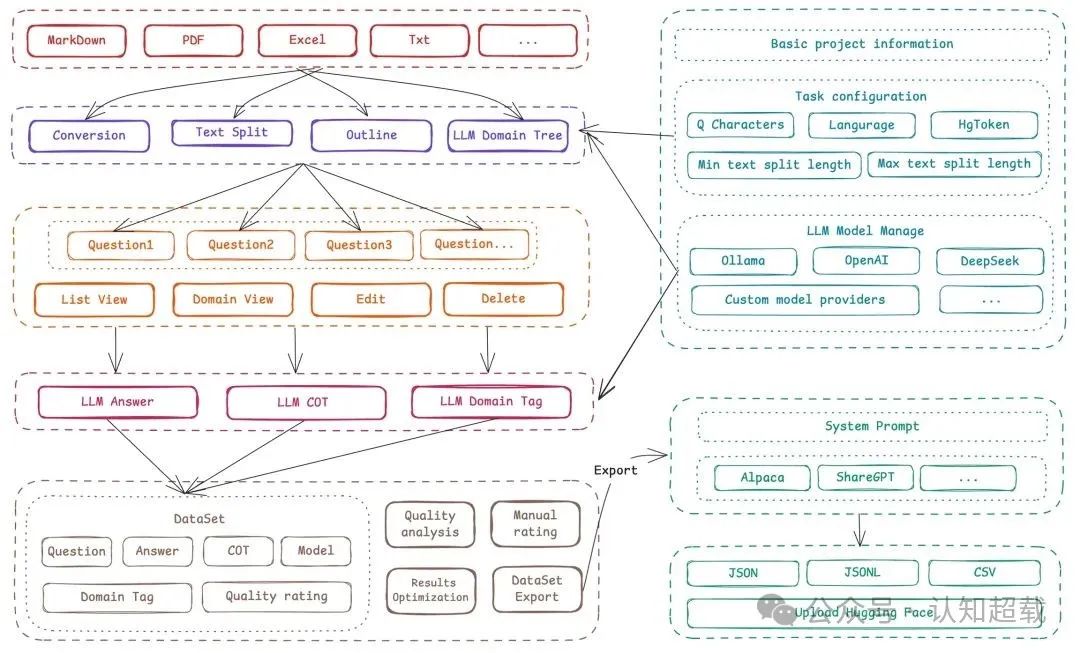
三、制作问答数据集的步骤
(一)创建项目
1. 登录 Easy Dataset 后,点击首页的 “创建项目” 按钮。
2. 输入项目名称和详细描述,帮助自己和其他团队成员清晰了解该项目的目的和范围,例如 “医疗领域问答数据集 - 用于微调医疗咨询模型”。
3. 配置 LLM API 设置,选择合适的模型(如 OpenAI 的 GPT 系列、DeepSeek 等)并填写相应的 API 密钥等参数,以便后续利用 LLM 进行答案生成等操作。
(二)处理文献
1. 在 “文本分割” 部分上传需要处理的文件,支持多种常见格式。比如上传一份医学研究论文的 PDF 文件,或者包含行业知识的 Markdown 文档。
2. 查看系统自动分割后的文本片段,可根据实际需求对分割结果进行调整,如合并或拆分某些段落,以确保每个文本块语义完整且长度适中,便于后续问题生成。
3. 查看并调整全局领域树,该领域树是基于上传文档内容自动生成的,用于对数据集进行领域分类和组织,如将医学文献划分为 “基础医学”“临床医学”“公共卫生” 等子领域,可手动修正以提高分类准确性。
(三)生成问题
1. 基于处理好的文本块,批量构建问题。Easy Dataset 会根据文本内容的语义信息,运用内置的智能算法生成一系列相关问题,如针对医学文本生成 “该病症的主要症状有哪些?”“如何进行有效诊断?” 等问题。
2. 查看并编辑生成的问题,剔除不符合要求或质量较低的问题,也可手动添加新的问题,完善问题列表。
3. 利用标签树对问题进行组织,将不同类型的问题归类到相应的领域标签下,方便后续管理和使用,如把 “药物副作用” 相关问题归入 “药物学” 标签下的 “副作用” 子标签。
(四)创建数据集
1. 依据编辑完善后的问题,批量构建数据集。系统会调用之前配置的 LLM API,将每个问题发送给模型,由模型生成对应的答案。
2. 查看生成的答案,对答案进行编辑和优化,确保答案准确、完整且逻辑清晰,符合实际应用场景的需求,如对医学答案中的专业术语进行补充解释,使其更易于非专业用户理解。
3. 还可进一步对数据集进行整体优化,如调整问题和答案的顺序,使其更符合某种逻辑结构或优先级。
(五)导出数据集
1. 在数据集页面点击 “导出” 按钮。
2. 选择导出的格式,如 Alpaca 或 ShareGPT 等常见格式,这些格式在不同的 LLM 平台或项目中有广泛应用,方便数据集的共享和使用。
3. 根据需求选择文件类型,如 JSON 或 JSONL,JSON 格式具有良好的可读性和易解析性,JSONL 则便于大规模数据的逐行处理。
4. 如有需要,添加自定义系统提示,用于引导模型更好地理解和使用该数据集,然后执行导出操作,即可得到完整的问答数据集文件,可用于模型微调等后续任务。
四、总结与展望
Easy Dataset 通过其强大的功能和直观的界面,极大地简化了问答数据集的制作流程,有效提高了数据集的质量和生产效率。无论是学术研究机构用于提升模型在特定学科领域的表现,还是企业为了优化内部知识库问答系统,亦或是开发者个人探索 LLM 的各种应用场景,它都提供了有力的支持。随着人工智能技术的不断发展,Easy Dataset 有望持续优化升级,集成更多先进的算法和模型,拓展更多的功能,如支持更多语言的问答数据集制作、提供更精细的数据评估指标等,为推动 LLM 在各个领域的深度应用和创新发展发挥更重要的作用。

魔乐社区(Modelers.cn) 是一个中立、公益的人工智能社区,提供人工智能工具、模型、数据的托管、展示与应用协同服务,为人工智能开发及爱好者搭建开放的学习交流平台。社区通过理事会方式运作,由全产业链共同建设、共同运营、共同享有,推动国产AI生态繁荣发展。
更多推荐


 16
16 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)