数据结构之图
一.图的基本知识
1.图的定义
在计算机科学中,图(Graph)是一种非常重要的非线性数据结构,用于表示对象(称为顶点或节点)以及它们之间的关系(称为边)
1.基本定义
图由两个集合组成:
- 顶点集(V, Vertices / Nodes):代表实体。例如城市、人、网页、计算机等
- 边(E, Edges):代表顶点之间的连接或关系。例如道路、友谊关系、超链接、网络链接等
2.图的分类
根据边的性质,图可以分为多种类型:
1.无向图(Undirected Graph):
- 边没有方向。如果A和B之间有边,意味着A可以到B,B也可以到A,像双向通道
A
边 / \ 边
/ \
B C
\ /
边 \ / 边
D
注:A、B、C、D为顶点
2.有向图(Directed Graph / Digraph)
- 边有方向,通常用箭头表示。从A到B的边并不意味着可以从B到A
A
| \
| \
v v
B C
^ |
| |
| v
D <---
|
E
不能直接从B到A,可以直接从A到B
不能直接从D到C,可以直接从C到E
注:C和E都指向D,但是C不指向E3.加权图(Weighted Graph)
- 每条边都有一个数值(权重),代表距离、时间、成本或强度等
5
A ------- B
| \ |
2| \ 3 | 4
| \ |
| \ |
C-------- D
1
解释:
A到B的距离(权重)是5
B到A的距离(权重)也是5
A到D的距离(权重)是3
D到A的距离(权重)也是3
注:加权只是给边增加了一个属性,它并不改变边的方向。上图表示的是无向加权图
4.无权图(Unweighted Graph)
- 边没有权重,通常只表示“有向”或“无向”
如前两幅图,都是无权图
3.图的常见术语
1.度(Degree)
与一个顶点相连的边的数量
在有向图中分为:
- 入度:指向该点的边数
- 出度:从该点指出的边数
A
| \
| \
v v
B C
^ |
| |
| v
D <---
|
E
D的度是3
D的出度是1,D的入度是2
C的度是2
C的出度是1,C的入度是12.路径(Path)
从一个顶点到另一个顶点所经过的边
- 简单路径:路径中不重复经过任何顶点
- 路径长度:经过的边的数量(如果是加权图,则是权重的总和)
A
| \
| \
v v
B C
^ |
| |
| v
D <------E
现在我们需要寻找从顶点A到顶点D的路径
路径一(经过C):A --> C --> D 可行√
路径二(经过B):A --> B --> D 不可行× 因为没有箭头从B指向D
路径三(经过E):A --> C --> E --> D 不可行× C没有指向E,E是一个源头,只能从E出,不能进入E
结论:从A到D的路径只有一条,长度为2,顶点序列为A、C、D3.环(Cycle)
一条起点和终点相同的路径(该路径起点和终点是同一个顶点,并且中间至少经过了一条边)
A<--------+
| \ |
| \ |
v v |
B C |
^ | |
| | |
| v |
D <-------E
这个图里面就没有环
如果让B也指向A,此时就有环了
A<--------+
^ |
| \ |
| \ |
v v |
B C |
^ | |
| | |
| v |
D <-------E
环路径:A --> C --> D --> B --> A
你可以无限地在这个环里绕圈圈加权图的最短路径:
如果给边加上权重,路径的选择就变了。我们要寻找总权重最小的路径
10
A --------> C
| \ |
1 | \ 100 | 1
| \ v
v `----> D
B ^
^ | 5
|___________|
(直接连)
从A到D
路径一:A --> C --> D 经过2条边,总代价为11
路径二:A --> D 经过1条边,总代价为100
路径三:A --> B --> D 经过2条边,总代价为6
所以在加权图中,最短路径不一定指的就是“经过的顶点数最少”的那条,而是“花费的总权重最小”
这就是导航软件为什么有时候会让你绕远路(因为那条路不堵车,权重小)的原因
4.连通性(Connectivity)
如果图中任意两个顶点都存在路径,则称该图为连通图(针对无向图) 或 强连通图(针对有向图)
连通图示例:
A ------- B
| |
| |
C ------- D
|
|
E强连通图示例:
A -------> B
^ |
| |
| v
D <------- C5.连通分量(Connected Component)
连通分量是图中“互相连通的最大子图”
核心定义:
对于无向图来说:
如果图是连通的(所有点都能互通),那么它只有一个连通分量(就是它自己)
如果图是不连通的(分成了几块),那么每一块都是一个连通分量
图示:
[组 1] [组 2] [组 3]
(A) ----- (B) (D) ----- (E) (G)
| | |
| | |
(C) (F) (H)
分析:
组1 {A,B,C,F} :A能走到B、C、F,B能走到A、C、F ... 它们内部完全连通
组2 {E,E,H} :它们内部连通,但跟组1没有关系
组3 {G} : 只有一个顶点,没有边。单个孤立的点也算连通分量!
结论:
这个图有3个连通分量:{A,B,C,F}、{E,E,H}、{G}对于有向图来说:
弱连通分量:忽略方向后,形成的连通块
强连通分量:在有向图中,极大的强连通子图。即在这个子图里,任意两点都能互相到达(顺着箭头去,也能顺着箭头回)
图示:
(A) -----> (B)
^ |
| v
(D) <----- (C)
(E) -----> (F)
分析左半部分{A,B,C,D}:
A --> B --> C --> D --> A
这四个点形成了一个完美的环。任意两点都能互达
所以,{A,B,C,D}是一个强连通分量
分析右半部分{E,F}:
E --> F
但是F不能回到E
所以{E,F}不是一个强连通分量
我们需要把它们拆开:{E}自己是一个强连通分量(单个点默认强连通);{F}也是一个强连通分量
只是它们两个不能合在一起,因为不满足“互相连通”
结论:这个图中共有3个强连通分量:{A,B,C,D}、{E}、{F}
4.图的存储方式
在计算机内存中,图主要有两种存储结构
1.邻接矩阵(Adjacency Matrix)
使用一个二维数组matrix[i][j]表示顶点i和顶点j之间是否有边
- 优点:判断两点之间是否有边非常快 O(1)
- 缺点:占用空间大 O(V^2) 适合稠密图(边非常多)
2.邻接表(Adjacency List)
使用链表加数组,每个顶点对应一个列表,列表中存储与该顶点相连的所有顶点
- 优点:节省空间 O(V + E) 适合稀疏图(边较少)
- 缺点:判断两点之间是否右边需要遍历列表
5.经典算法与场景应用
图论算法是解决许多实际问题的核心
1.遍历算法
- 深度优先搜索(DFS):常用于迷宫求解、拓补排序、检测环
- 广度优先搜索(BFS):常用于寻找无权图中的最短路径、层级遍历
2.最短路径算法
- Dijkstra算法:寻找带权图中的单源最短路径(如导航软件规划路线)
- Floyd-Warshall算法:寻找所有顶点对之间的最短路径
3.最小生成树(MST)
Prim算法和Kruskal算法:用于在网络设计中以最低成本链接所有节点(如铺设电缆,构建通信网)
4.拓扑排序 (Topological Sort)
用于解决依赖关系问题,如编译顺序、课程安排先修课。
5.实际应用
- 社交网络:分析人际关系、推荐好友。
- 搜索引擎:PageRank 算法利用网页链接图对网页进行排名。
- 地图导航:计算两地之间的最快或最短路线。
- 知识图谱:表示实体及其复杂的语义关系。
- 电路设计:逻辑门之间的连接。
总结来说,图是计算机科学中建模“关系”最强大的工具,几乎所有涉及网络、连接和依赖的问题都可以转化为图问题来求解。
二.Java代码
1.用Java代码表示图
+------------> B ----------+
| |
| v
A D
| ^
| |
+-----------> C -----------+package algorithm.datastructure.graph;
public class Edge {
Vertex linked; // 边所连接的顶点
int weight; // 边的权值
// 构造方法链,也称为构造方法重载
// this(linked, 1)表示调用当前类的另一个构造方法,传入linked和默认权值1
// 这样设计的好处是:当用户只需要指定连接的顶点而使用默认权值时,可以简化代码
public Edge(Vertex linked) {this(linked, 1);};
public Edge(Vertex linked, int weight) {
this.linked = linked;
this.weight = weight;
}
}
package algorithm.datastructure.graph;
import java.util.List;
public class Vertex {
String name; // 顶点名称
List<Edge> edges; // 顶点所连接的边
public Vertex(String name) {
this.name = name;
}
public String getName() {
return name;
}
public static void main(String[] args) { // IDEA中直接输入psv回车就可以快速生成main方法的框架
// 创建顶点对象
Vertex a = new Vertex("A"); // ctrl + d 向下快速复制当前行
Vertex b = new Vertex("B");
Vertex c = new Vertex("C");
Vertex d = new Vertex("D");
a.edges = List.of(new Edge(b), new Edge(c)); // List.of()是Java9引入的静态工厂方法,用于快速、便捷地创建不可变列表(不能添加、删除、修改元素)
b.edges = List.of(new Edge(d));
c.edges = List.of(new Edge(d));
d.edges = List.of(); // List.of()中什么都不写,表示创建一个空列表
}
}2.深度优先搜索(Depth First Search)
遍历的时候要尽可能走得更远
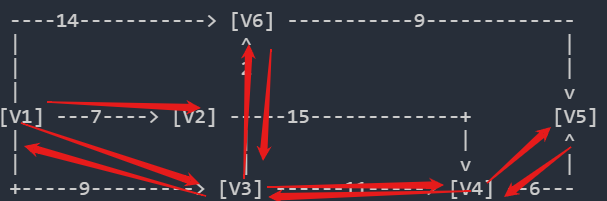
核心思想:尽可能深地探索图的分支,当节点v的所在边都已被探寻过,搜索将回溯到发现v的那条边的起始节点 ---> 一条路径走到底,走完了在走其他的路径,其他的路径同样要走到底然后再走另外其他的路径
----14-----------> [V6] -----------9-------------
| ^ |
| 2 |
| | v
[V1] ---7----> [V2] -----15-------------+ [V5]
| | | ^
| | v |
+-----9---------> [V3] ------11-----> [V4] --6---
这个图是有向加权图,图中一共有V1、V2、V3、V4、V5、V6,共6个顶点下图是遍历时的示意图,先从V1走到V3,按箭头顺序从V3到V4,从V4到V5,V5没有箭头指出去,所以就原路返回(虽然没有指向V4的箭头,但是这里返回并不是遍历,而是为了从前面的顶点找看看还有无其他路径)
V5返回V4,但是V4也没有指向其他的顶点,所以V4返回V3,再从V3遍历到V6,这里V6虽然有指向V5的箭头,但是V5已经遍历过了,不需要再遍历。所以V6原路返回V3,V3返回V1。V1有指向V2的箭头,所以从V1遍历到V2,V2有指向V4的箭头,所以V2返回V1 。V1有指向V6的箭头,但V6已经遍历过。
至此,V1所有的出口(指出去的)都已经遍历完,结束整个遍历
最终遍历的结果:V1、V3、V4、V5、V6、V2
Java代码表示上面这个加权有向图
package algorithm.datastructure.graph;
import java.util.List;
public class Vertex {
String name; // 顶点名称
List<Edge> edges; // 顶点所连接的边
public Vertex(String name) {
this.name = name;
}
public String getName() {
return name;
}
public static void main(String[] args) { // IDEA中直接输入psv回车就可以快速生成main方法的框架
Vertex v1 = new Vertex("V1");
Vertex v2 = new Vertex("V2");
Vertex v3 = new Vertex("V3");
Vertex v4 = new Vertex("V4");
Vertex v5 = new Vertex("V5");
Vertex v6 = new Vertex("V6");
v1.edges = List.of(
new Edge(v3, 9),
new Edge(v2, 5),
new Edge(v6, 14)
);
v2.edges = List.of(
new Edge(v4, 15)
);
v3.edges = List.of(
new Edge(v4, 11),
new Edge(v6, 2)
);
v4.edges = List.of(
new Edge(v5, 6)
);
v5.edges = List.of();
v6.edges = List.of(
new Edge(v5, 9)
);
}
}DFS:
给Vertex类增加一个visited属性,用来标记这个顶点是否为访问过,访问过就为true否则为false
public class Vertex {
String name; // 顶点名称
List<Edge> edges; // 顶点所连接的边
boolean visited; // 该顶点是否被访问过 注:布尔类型作为成员变量时默认值是false,作为局部变量时没有默认值需要手动初始化
public Vertex(String name) {
this.name = name;
}
public String getName() {
return name;
}
}递归版:
package algorithm.datastructure.graph;
import java.util.List;
public class DFS {
public static void main(String[] args) {
Vertex v1 = new Vertex("V1");
Vertex v2 = new Vertex("V2");
Vertex v3 = new Vertex("V3");
Vertex v4 = new Vertex("V4");
Vertex v5 = new Vertex("V5");
Vertex v6 = new Vertex("V6");
v1.edges = List.of(
new Edge(v3, 9),
new Edge(v2, 5),
new Edge(v6, 14)
);
v2.edges = List.of(
new Edge(v4, 15)
);
v3.edges = List.of(
new Edge(v4, 11),
new Edge(v6, 2)
);
v4.edges = List.of(
new Edge(v5, 6)
);
v5.edges = List.of();
v6.edges = List.of(
new Edge(v5, 9)
);
// 深度优先搜索
dfs(v1);
}
private static void dfs(Vertex v) {
v.visited = true;
System.out.print(v.name + " ");
for (Edge e: v.edges) {
if (!e.linked.visited) {
dfs(e.linked);
}
}
}
}
输出:
V1 V3 V4 V5 V6 V2
// 注:遍历的结果和你用代码表示顶点的先后顺序有关迭代版:
package algorithm.datastructure.graph;
import java.util.List;
import java.util.Deque;
import java.util.ArrayDeque;
public class DFS {
public static void main(String[] args) {
Vertex v1 = new Vertex("V1");
Vertex v2 = new Vertex("V2");
Vertex v3 = new Vertex("V3");
Vertex v4 = new Vertex("V4");
Vertex v5 = new Vertex("V5");
Vertex v6 = new Vertex("V6");
v1.edges = List.of(
new Edge(v3, 9),
new Edge(v2, 5),
new Edge(v6, 14)
);
v2.edges = List.of(
new Edge(v4, 15)
);
v3.edges = List.of(
new Edge(v4, 11),
new Edge(v6, 2)
);
v4.edges = List.of(
new Edge(v5, 6)
);
v5.edges = List.of();
v6.edges = List.of(
new Edge(v5, 9)
);
// 深度优先搜索
dfs(v1);
}
private static void dfs(Vertex v) {
Deque<Vertex> stack = new ArrayDeque<>();
stack.push(v);
while (!stack.isEmpty()) {
Vertex curr = stack.pop();
curr.visited = true;
System.out.print(curr.name + " ");
for (Edge edge: curr.edges) {
if (!edge.linked.visited) {
stack.push(edge.linked);
}
}
}
}
}
输出:
V1 V6 V5 V2 V4 V3 这看起来与递归版本的输出不一样
其实是因为我们用了栈,而栈的特性是后进先出
我们传入v1时,先遍历v1,然后在for循环中将v1指向的且没有被遍历的顶点加入栈中,由于我们在定义v1指向的其他顶点的时候的顺序是:v3、v2、v6,所以栈中的元素为【v3、v2、v6】,v6是最后入栈的,它要第一个出栈
所以遍历v1后,v6就被遍历了。然后同理找v6指向的顶点v5,v5没有被遍历过,所以入栈,然后出栈遍历。
接着遍历v2,然后找v2指向的顶点v4 ......
注意:队列无法实现深度优先搜索!
深度优先搜索的特点是“一条路走到黑”。即遍历完一个节点,接着就要遍历它的子节点,再遍历子节点的子节点...... 即遍历完一个节点后,要把它的子节点加入容器中,判断若子节点没有被访问过,于是立即遍历子节点。 这和栈的后进先出特性不谋而合
而如果用的是队列,你遍历完一个节点后,是把子节点加入到队尾,但是出是从队首出,子节点不能够立即被遍历
3.广度优先搜索(Breadth Frist Search)
按层来遍历,先遍历第一层,再遍历第二层......
DFS和BSF都用于系统地访问图的所有顶点,是两种最基础且重要的图遍历算法
BFS的核心思想:从起始节点开始,先访问所有相邻节点,再依次访问这些相邻节点的相邻节点,层层扩展
迭代版本:
package algorithm.datastructure.graph;
import java.util.List;
import java.util.Deque;
import java.util.ArrayDeque;
public class DFS {
public static void main(String[] args) {
Vertex v1 = new Vertex("V1");
Vertex v2 = new Vertex("V2");
Vertex v3 = new Vertex("V3");
Vertex v4 = new Vertex("V4");
Vertex v5 = new Vertex("V5");
Vertex v6 = new Vertex("V6");
v1.edges = List.of(
new Edge(v3, 9),
new Edge(v2, 5),
new Edge(v6, 14)
);
v2.edges = List.of(
new Edge(v4, 15)
);
v3.edges = List.of(
new Edge(v4, 11),
new Edge(v6, 2)
);
v4.edges = List.of(
new Edge(v5, 6)
);
v5.edges = List.of();
v6.edges = List.of(
new Edge(v5, 9)
);
// 广度优先搜索
bfs(v1);
}
private static void bfs(Vertex v) {
Deque<Vertex> deque = new ArrayDeque<>();
v.visited = true; // 标记起点,已被遍历
deque.add(v);
while (!deque.isEmpty()) {
Vertex curr = deque.poll();
System.out.print(curr.name + " ");
for (Edge edge : curr.edges) {
if (!edge.linked.visited) {
edge.linked.visited = true;
deque.add(edge.linked);
}
}
}
}
}
输出:
V1 V3 V2 V6 V4 V5递归版本:
哈哈哈哈,你被我骗到到
广搜没有递归版本,广度优先搜索不能通过递归实现
递归调用栈是深度优先的,无法做到同层节点优先于下层节点
假设有这样的图:
A (第0层)
/ \
B C (第1层)
/ /
D E (第2层)递归调用的顺序是:A B D C E
而BFS期待的顺序是A B C D E
伪递归实现:
package algorithm.datastructure.graph;
import java.util.ArrayList;
import java.util.List;
import java.util.Deque;
import java.util.ArrayDeque;
public class DFS {
public static void main(String[] args) {
Vertex v1 = new Vertex("V1");
Vertex v2 = new Vertex("V2");
Vertex v3 = new Vertex("V3");
Vertex v4 = new Vertex("V4");
Vertex v5 = new Vertex("V5");
Vertex v6 = new Vertex("V6");
v1.edges = List.of(
new Edge(v3, 9),
new Edge(v2, 5),
new Edge(v6, 14)
);
v2.edges = List.of(
new Edge(v4, 15)
);
v3.edges = List.of(
new Edge(v4, 11),
new Edge(v6, 2)
);
v4.edges = List.of(
new Edge(v5, 6)
);
v5.edges = List.of();
v6.edges = List.of(
new Edge(v5, 9)
);
// 广度优先搜索
v1.visited = true;
bfs(List.of(v1));
}
// 伪递归实现BFS
// 正确的"伪递归"BFS
private static void bfs(List<Vertex> levelVertex) {
if (levelVertex.isEmpty()) {
return;
}
List<Vertex> nextLevel = new ArrayList<>();
for (Vertex vertex : levelVertex) {
// 1. 访问当前节点
System.out.print(vertex.name + " ");
// 2. 收集下一层(去重 + 提前标记)
for (Edge edge : vertex.edges) {
Vertex neighbor = edge.linked;
if (!neighbor.visited) { // 入队前检查
neighbor.visited = true; // 立即标记,防止重复入队
nextLevel.add(neighbor);
}
}
}
bfs(nextLevel);
}
}
4.拓扑排序
拓扑排序是图论中的一种重要的算法,主要用于有向无环图
它的核心作用是将图中所有节点都排成一个线性序列,使得对于图中的每一条有向边(u, v),节点u在序列中都出现在节点v之前
适用场景:只有当图中不出现环时,才能进行拓扑排序。如果图中有环,如 A ---> B -----> C ----> D ,则无法进行拓扑排序。
直观理解:想象你要安排一系列任务,某些任务必须在其他任务之前完成(前置依赖)。拓扑排序就是找到一种满足所有依赖关系的执行顺序。
数据库 ---------------+
|
|
|
网页基础 ------------+ |
| |
| |
v v
Java Web --------> Spring框架 -------> 微服务框架 --------> 实战项目
^
|
Java基础 -----------+先用Java代码表示这个图
package algorithm.datastructure.graph;
import java.util.List;
import java.util.ArrayList;
public class TopologicalSort {
public static void main(String[] args) {
Vertex v1 = new Vertex("网页基础");
Vertex v2 = new Vertex("Java基础");
Vertex v3 = new Vertex("JavaWeb");
Vertex v4 = new Vertex("数据库");
Vertex v5 = new Vertex("Spring框架");
Vertex v6 = new Vertex("微服务框架");
Vertex v7 = new Vertex("项目实战");
v1.edges = List.of(new Edge(v3));
v2.edges = List.of(new Edge(v3));
v3.edges = List.of(new Edge(v5));
v4.edges = List.of(new Edge(v5));
v5.edges = List.of(new Edge(v6));
v6.edges = List.of(new Edge(v7));
v7.edges = List.of();
List<Vertex> graph = new ArrayList<>(List.of(v1, v2, v3, v4, v5, v6, v7));
}
}为了进行拓扑排序,需要在Vertx类中新增一个int类型的入度属性
public class Vertex {
String name; // 顶点名称
List<Edge> edges; // 顶点所连接的边
boolean visited; // 该顶点是否被访问过 注:布尔类型作为成员变量时默认值是false,作为局部变量时没有默认值需要手动初始化
int inDegree; // 该顶点的入度
public Vertex(String name) {
this.name = name;
}
public String getName() {
return name;
}
}统计每个顶点的入度
package algorithm.datastructure.graph;
import java.util.List;
import java.util.ArrayList;
public class TopologicalSort {
public static void main(String[] args) {
Vertex v1 = new Vertex("网页基础");
Vertex v2 = new Vertex("Java基础");
Vertex v3 = new Vertex("JavaWeb");
Vertex v4 = new Vertex("数据库");
Vertex v5 = new Vertex("Spring框架");
Vertex v6 = new Vertex("微服务框架");
Vertex v7 = new Vertex("项目实战");
v1.edges = List.of(new Edge(v3));
v2.edges = List.of(new Edge(v3));
v3.edges = List.of(new Edge(v5));
v4.edges = List.of(new Edge(v5));
v5.edges = List.of(new Edge(v6));
v6.edges = List.of(new Edge(v7));
v7.edges = List.of();
List<Vertex> graph = new ArrayList<>(List.of(v1, v2, v3, v4, v5, v6, v7));
// 统计每个顶点的入度
for (Vertex vertex: graph) {
for (Edge edge : vertex.edges) {
edge.linked.inDegree++; // 遍历顶点所连接的其他顶点,其他顶点是从这个顶点过来的,相当于其他每个顶点的入度都加1
}
}
for (Vertex vertex: graph) {
System.out.println(vertex.name + " " + vertex.inDegree);
}
}
}输出:
网页基础 0
Java基础 0
JavaWeb 2
数据库 0
Spring框架 2
微服务框架 1
项目实战 1实现拓扑排序:
package algorithm.datastructure.graph;
import java.util.List;
import java.util.ArrayList;
import java.util.Deque;
import java.util.ArrayDeque;
public class TopologicalSort {
public static void main(String[] args) {
Vertex v1 = new Vertex("网页基础");
Vertex v2 = new Vertex("Java基础");
Vertex v3 = new Vertex("JavaWeb");
Vertex v4 = new Vertex("数据库");
Vertex v5 = new Vertex("Spring框架");
Vertex v6 = new Vertex("微服务框架");
Vertex v7 = new Vertex("项目实战");
v1.edges = List.of(new Edge(v3));
v2.edges = List.of(new Edge(v3));
v3.edges = List.of(new Edge(v5));
v4.edges = List.of(new Edge(v5));
v5.edges = List.of(new Edge(v6));
v6.edges = List.of(new Edge(v7));
v7.edges = List.of();
List<Vertex> graph = new ArrayList<>(List.of(v1, v2, v3, v4, v5, v6, v7));
// 统计每个顶点的入度
for (Vertex vertex: graph) {
for (Edge edge : vertex.edges) {
edge.linked.inDegree++; // 遍历顶点所连接的其他顶点,其他顶点是从这个顶点过来的,相当于其他每个顶点的入度都加1
}
}
// for (Vertex vertex: graph) {
// System.out.println(vertex.name + " " + vertex.inDegree);
// }
// 将入度为0的顶点加入队列
Deque<Vertex> queue = new ArrayDeque<>();
for (Vertex vertex : graph) {
if (vertex.inDegree == 0) {
queue.addLast(vertex);
}
}
// 弹出入度为0的顶点,将入度为0的顶点的相邻顶点的入度减1
while (!queue.isEmpty()) {
Vertex v = queue.pollFirst();
System.out.println(v.name);
for (Edge edge: v.edges) {
edge.linked.inDegree--;
if (edge.linked.inDegree == 0) {
queue.addLast(edge.linked);
}
}
}
}
}
输出:
网页基础
Java基础
数据库
JavaWeb
Spring框架
微服务框架
项目实战5.拓扑排序-->检测环
如果加一个箭头,使得实战项目指向微服务框架
数据库 ---------------+
|
|
|
网页基础 ------------+ |
| |
| |
v v
Java Web --------> Spring框架 -------> 微服务框架 <--------> 实战项目
^
|
Java基础 -----------+这个时候图中就存在了环,拓扑排序会失败!
package algorithm.datastructure.graph;
import java.util.List;
import java.util.ArrayList;
import java.util.Deque;
import java.util.ArrayDeque;
public class TopologicalSort {
public static void main(String[] args) {
Vertex v1 = new Vertex("网页基础");
Vertex v2 = new Vertex("Java基础");
Vertex v3 = new Vertex("JavaWeb");
Vertex v4 = new Vertex("数据库");
Vertex v5 = new Vertex("Spring框架");
Vertex v6 = new Vertex("微服务框架");
Vertex v7 = new Vertex("项目实战");
v1.edges = List.of(new Edge(v3));
v2.edges = List.of(new Edge(v3));
v3.edges = List.of(new Edge(v5));
v4.edges = List.of(new Edge(v5));
v5.edges = List.of(new Edge(v6));
v6.edges = List.of(new Edge(v7));
v7.edges = List.of(new Edge(v6));
List<Vertex> graph = new ArrayList<>(List.of(v1, v2, v3, v4, v5, v6, v7));
// 统计每个顶点的入度
for (Vertex vertex: graph) {
for (Edge edge : vertex.edges) {
edge.linked.inDegree++; // 遍历顶点所连接的其他顶点,其他顶点是从这个顶点过来的,相当于其他每个顶点的入度都加1
}
}
for (Vertex vertex: graph) {
System.out.println(vertex.name + " " + vertex.inDegree);
}
}
}
输出:
网页基础 0
Java基础 0
JavaWeb 2
数据库 0
Spring框架 2
微服务框架 2
项目实战 1可以看到“微服务框架”这个顶点的入度变为2了
这时就算继续进行拓扑排序:将入度为0的顶点加入队列,然后将该顶点相邻的顶点的入度减1
但是当“Spring框架”的入度为0时,作为它相邻的顶点“微服务框架”的入度减1,变成1,仍然不为0,所以“微服务框架”不会入队,自然就不会被输出,而“实战项目”这个顶点只有“微服务框架”指向它,“微服务框架”的入度不为0,“实战项目”的入度永远都不会变化
代码验证:
package algorithm.datastructure.graph;
import java.util.List;
import java.util.ArrayList;
import java.util.Deque;
import java.util.ArrayDeque;
public class TopologicalSort {
public static void main(String[] args) {
Vertex v1 = new Vertex("网页基础");
Vertex v2 = new Vertex("Java基础");
Vertex v3 = new Vertex("JavaWeb");
Vertex v4 = new Vertex("数据库");
Vertex v5 = new Vertex("Spring框架");
Vertex v6 = new Vertex("微服务框架");
Vertex v7 = new Vertex("项目实战");
v1.edges = List.of(new Edge(v3));
v2.edges = List.of(new Edge(v3));
v3.edges = List.of(new Edge(v5));
v4.edges = List.of(new Edge(v5));
v5.edges = List.of(new Edge(v6));
v6.edges = List.of(new Edge(v7));
v7.edges = List.of(new Edge(v6));
List<Vertex> graph = new ArrayList<>(List.of(v1, v2, v3, v4, v5, v6, v7));
// 统计每个顶点的入度
for (Vertex vertex: graph) {
for (Edge edge : vertex.edges) {
edge.linked.inDegree++; // 遍历顶点所连接的其他顶点,其他顶点是从这个顶点过来的,相当于其他每个顶点的入度都加1
}
}
// for (Vertex vertex: graph) {
// System.out.println(vertex.name + " " + vertex.inDegree);
// }
// 将入度为0的顶点加入队列
Deque<Vertex> queue = new ArrayDeque<>();
for (Vertex vertex : graph) {
if (vertex.inDegree == 0) {
queue.addLast(vertex);
}
}
// 弹出入度为0的顶点,将入度为0的顶点的相邻顶点的入度减1
while (!queue.isEmpty()) {
Vertex v = queue.pollFirst();
System.out.println(v.name);
for (Edge edge: v.edges) {
edge.linked.inDegree--;
if (edge.linked.inDegree == 0) {
queue.addLast(edge.linked);
}
}
}
}
}
输出:
网页基础
Java基础
数据库
JavaWeb
Spring框架“微服务框架”、“实战项目”没有被排序,因此拓扑排序失败
如何检测图中是否出现环?
package algorithm.datastructure.graph;
import java.util.List;
import java.util.ArrayList;
import java.util.Deque;
import java.util.ArrayDeque;
public class TopologicalSort {
public static void main(String[] args) {
Vertex v1 = new Vertex("网页基础");
Vertex v2 = new Vertex("Java基础");
Vertex v3 = new Vertex("JavaWeb");
Vertex v4 = new Vertex("数据库");
Vertex v5 = new Vertex("Spring框架");
Vertex v6 = new Vertex("微服务框架");
Vertex v7 = new Vertex("项目实战");
v1.edges = List.of(new Edge(v3));
v2.edges = List.of(new Edge(v3));
v3.edges = List.of(new Edge(v5));
v4.edges = List.of(new Edge(v5));
v5.edges = List.of(new Edge(v6));
v6.edges = List.of(new Edge(v7));
v7.edges = List.of(new Edge(v6));
List<Vertex> graph = new ArrayList<>(List.of(v1, v2, v3, v4, v5, v6, v7));
// 统计每个顶点的入度
for (Vertex vertex: graph) {
for (Edge edge : vertex.edges) {
edge.linked.inDegree++; // 遍历顶点所连接的其他顶点,其他顶点是从这个顶点过来的,相当于其他每个顶点的入度都加1
}
}
// for (Vertex vertex: graph) {
// System.out.println(vertex.name + " " + vertex.inDegree);
// }
// 将入度为0的顶点加入队列
List<Vertex> result = new ArrayList<>(); // 用于存储拓扑排序的结果
Deque<Vertex> queue = new ArrayDeque<>();
for (Vertex vertex : graph) {
if (vertex.inDegree == 0) {
queue.addLast(vertex);
}
}
// 弹出入度为0的顶点,将入度为0的顶点的相邻顶点的入度减1
while (!queue.isEmpty()) {
Vertex v = queue.pollFirst();
result.add(v);
for (Edge edge: v.edges) {
edge.linked.inDegree--;
if (edge.linked.inDegree == 0) {
queue.addLast(edge.linked);
}
}
}
System.out.println("排序结果result的大小:" + result.size());
System.out.println("图中的顶点的个数:" + graph.size());
System.out.println(result.size() == graph.size()); // 返回true说明拓扑排序正确,否则说明图中存在环
}
}
输出:
排序结果result的大小:5
图中的顶点的个数:7
false6.拓扑排序---借助DFS
给Vertex类新增一个int类型的属性status,表示这个顶点的访问状态
public class Vertex {
String name; // 顶点名称
List<Edge> edges; // 顶点所连接的边
boolean visited; // 该顶点是否被访问过 注:布尔类型作为成员变量时默认值是false,作为局部变量时没有默认值需要手动初始化
int inDegree; // 该顶点的入度
int status; // 该顶点的访问状态,取值可以为0/1/2,分别表示未访问/正在访问/已访问
public Vertex(String name) {
this.name = name;
}
public String getName() {
return name;
}
// 重写顶点类的toString方法,便于输出
@Override
public String toString() {
return name;
}
}package algorithm.datastructure.graph;
import java.util.*;
public class TopologicalSort {
public static void main(String[] args) {
Vertex v1 = new Vertex("网页基础");
Vertex v2 = new Vertex("Java基础");
Vertex v3 = new Vertex("JavaWeb");
Vertex v4 = new Vertex("数据库");
Vertex v5 = new Vertex("Spring框架");
Vertex v6 = new Vertex("微服务框架");
Vertex v7 = new Vertex("项目实战");
v1.edges = List.of(new Edge(v3));
v2.edges = List.of(new Edge(v3));
v3.edges = List.of(new Edge(v5));
v4.edges = List.of(new Edge(v5));
v5.edges = List.of(new Edge(v6));
v6.edges = List.of(new Edge(v7));
v7.edges = List.of();
List<Vertex> graph = new ArrayList<>(List.of(v1, v2, v3, v4, v5, v6, v7));
Deque<Vertex> stack = new ArrayDeque<>(); // 存储DFS遍历的结果
for (Vertex v: graph) {
dfs(v, stack);
}
System.out.println(stack); // 重写了顶点类的toString()方法
}
private static void dfs(Vertex v, Deque<Vertex> stack) {
if (v.status == 2) {
return;
}
// 先DFS遍历依赖程度更重的顶点
for (Edge edge: v.edges) {
dfs(edge.linked, stack);
}
v.status = 2; // 将该顶点的遍历状况标记为已访问
stack.addFirst(v); // 注意栈元素的添加顺序!
}
}
输出:
[数据库, Java基础, 网页基础, JavaWeb, Spring框架, 微服务框架, 项目实战]- v1 (网页基础):
- 进入
dfs(v1)。 - 递归
v3-> 递归v5-> 递归v6-> 递归v7。 v7无边,标记status=2,stack.addFirst(v7)。栈:[v7]- 回溯到
v6,标记status=2,stack.addFirst(v6)。栈:[v6, v7] - 回溯到
v5,标记status=2,stack.addFirst(v5)。栈:[v5, v6, v7] - 回溯到
v3,标记status=2,stack.addFirst(v3)。栈:[v3, v5, v6, v7] - 回溯到
v1,标记status=2,stack.addFirst(v1)。栈:[v1, v3, v5, v6, v7]
- 进入
- v2 (Java基础):
- 进入
dfs(v2)。 - 递归
v3。发现v3.status == 2,直接返回。 - 标记
v2为status=2,stack.addFirst(v2)。栈:[v2, v1, v3, v5, v6, v7]
- 进入
- v4 (数据库):
- 进入
dfs(v4)。 - 递归
v5。发现v5.status == 2,直接返回。 - 标记
v4为status=2,stack.addFirst(v4)。栈:[v4, v2, v1, v3, v5, v6, v7]
- 进入
- 后续节点 (v3...v7):
- 循环继续,但进入
dfs后发现status == 2,直接返回,不做任何事。
- 循环继续,但进入
7.Dijkstra算法
迪杰斯特拉算法,是一种用于在图中寻找单源最短路径的经典算法
它由荷兰计算机科学家艾兹格·迪杰斯特拉(Edsger W. Dijkstra)在1956年提出。
简单来说,它的目标是:在一个带权重的图中,从一个指定的起点出发,计算出该节点到图中其他所有节点的最短距离
给Vertex类新增一个int类型的数组distance,表示初始顶点到该顶点的最短距离
public class Vertex {
String name; // 顶点名称
List<Edge> edges; // 顶点所连接的边
boolean visited; // 该顶点是否被访问过 注:布尔类型作为成员变量时默认值是false,作为局部变量时没有默认值需要手动初始化
int inDegree; // 该顶点的入度
int status; // 该顶点的访问状态,取值可以为0/1/2,分别表示未访问/正在访问/已访问
int distance; // 该顶点的最短距离
public Vertex(String name) {
this.name = name;
}
public String getName() {
return name;
}
// 重写顶点类的toString方法,便于输出
@Override
public String toString() {
return name;
}
}package algorithm.datastructure.graph;
import java.util.List;
import java.util.ArrayList;
public class Dijkstra {
public static void main(String[] args) {
Vertex v1 = new Vertex("V1");
Vertex v2 = new Vertex("V2");
Vertex v3 = new Vertex("V3");
Vertex v4 = new Vertex("V4");
Vertex v5 = new Vertex("V5");
Vertex v6 = new Vertex("V6");
v1.edges = List.of(
new Edge(v3, 9),
new Edge(v2, 5),
new Edge(v6, 14)
);
v2.edges = List.of(
new Edge(v4, 15)
);
v3.edges = List.of(
new Edge(v4, 11),
new Edge(v6, 2)
);
v4.edges = List.of(
new Edge(v5, 6)
);
v5.edges = List.of();
v6.edges = List.of(
new Edge(v5, 9)
);
List<Vertex> graph = List.of(v1, v2, v3, v4, v5, v6);
dijkstra(graph, v1);
}
private static void dijkstra(List<Vertex> graph, Vertex start) {
ArrayList<Vertex> list = new ArrayList<>(graph);
start.distance = 0;
while (!list.isEmpty()) {
// 选取当前的顶点
Vertex curr = getMinDistVertex(list);
// 更新相邻顶点的距离
for (Edge edge: curr.edges) {
Vertex neighbor = edge.linked;
int dist = curr.distance + edge.weight;
if (dist < neighbor.distance) {
neighbor.distance = dist;
}
}
// 输出当前顶点
//System.out.println(curr);
// 删除当前顶点
list.remove(curr);
}
for (Vertex v : graph) {
System.out.println(v.name + ": " + v.distance);
}
}
private static Vertex getMinDistVertex(List<Vertex> list) {
Vertex min = list.get(0);
for (int i = 1; i < list.size(); i++) {
if (list.get(i).distance < min.distance) {
min = list.get(i);
}
}
return min;
}
}
输出:
V1: 0
V2: 5
V3: 9
V4: 20
V5: 20
V6: 118.Bellman-Ford算法
是另一种解决单源最短路径的经典算法
最大的特点:能处理带有“负权边”的图,并且能检测出图中是否存在“负权环”。这是Dijkstra算法所做不到的(因为Dijkstra算法要求权非负)
如:
V1 ------1----> V3 ------+
| ^ |
| | 1
2 -2 |
| | |
V | |
V2 ------------ v
V4什么是“负环”?
图中有路径构成了环,且环的总权和为负数

魔乐社区(Modelers.cn) 是一个中立、公益的人工智能社区,提供人工智能工具、模型、数据的托管、展示与应用协同服务,为人工智能开发及爱好者搭建开放的学习交流平台。社区通过理事会方式运作,由全产业链共同建设、共同运营、共同享有,推动国产AI生态繁荣发展。
更多推荐


 8
8 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)